
Stroke Risk Prediction with Machine Learning Techniques



Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Dataset Description
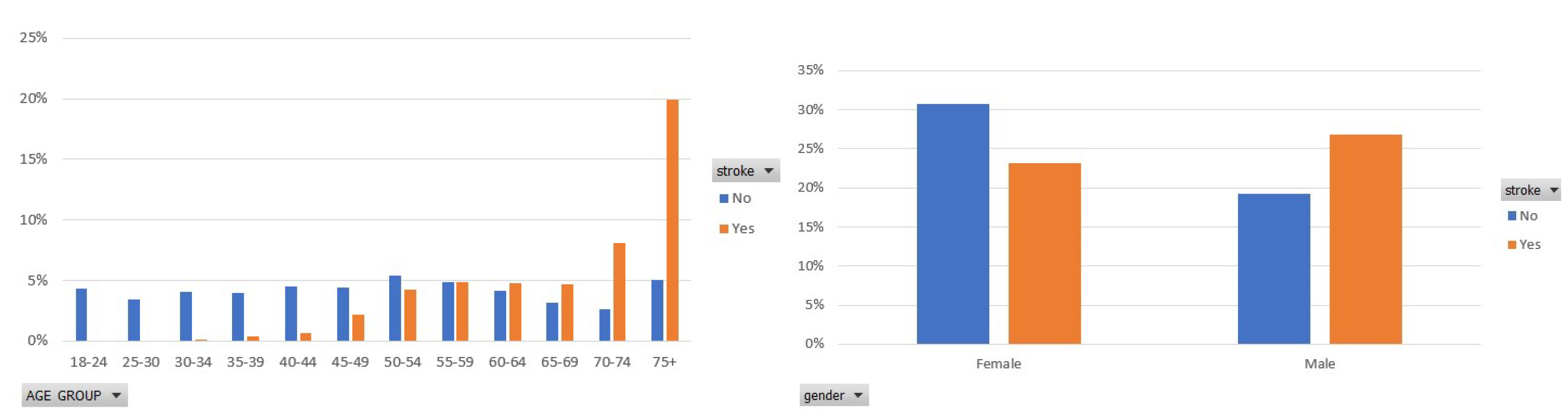
- Age (years) [39]: This feature refers to the age of the participants who are over 18 years old.
- Gender [39]: This feature refers to the participant’s gender. The number of men is 1260, whereas the number of women is 1994.
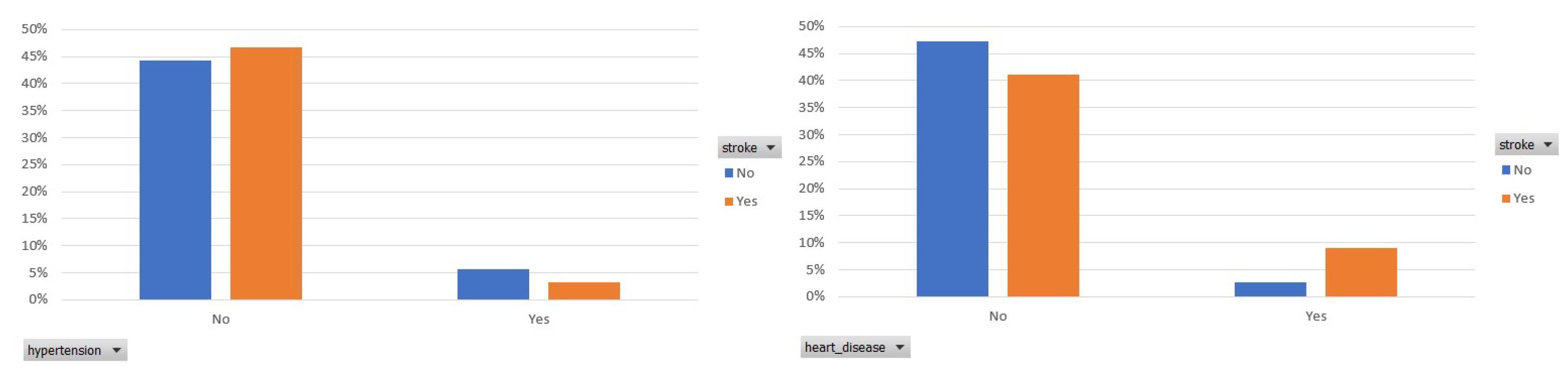
- Hypertension [40]: This feature refers to whether this participant is hypertensive or not. The percentage of participants who have hypertension is 12.54%.
- Heart_disease [41]: This feature refers to whether this participant suffers from heart disease or not. The percentage of participants suffering from heart disease is 6.33%.
- Ever married [42]: This feature represents the marital status of the participants, 79.84% of whom are married.
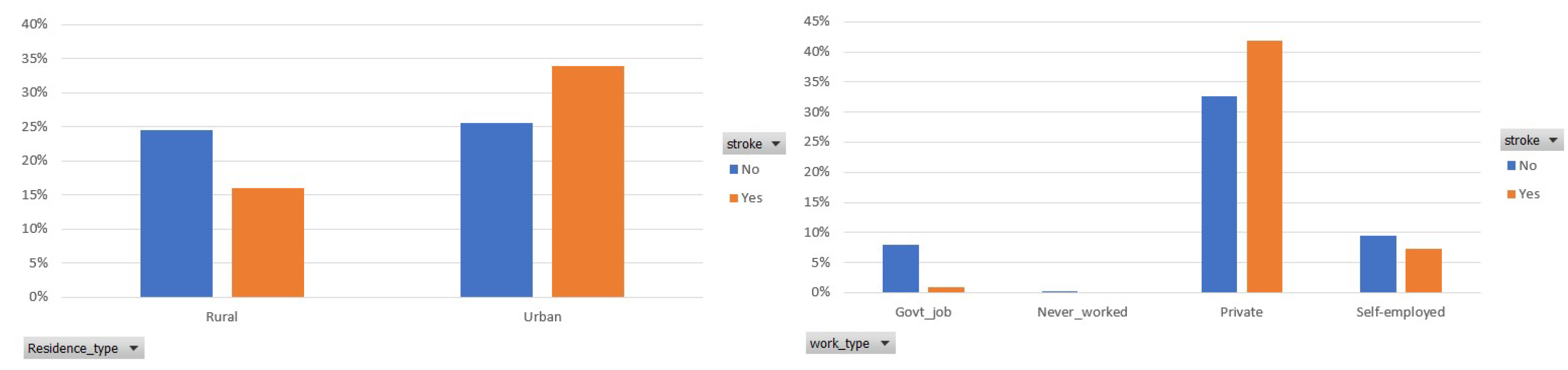
- Work type [43]: This feature represents the participant’s work status and has 4 categories (private 65.02%, self-employed 19.21%, govt_job 15.67% and never_worked 0.1%).
- Residence type [44]: This feature represents the participant’s living status and has 2 categories (urban 51.14%, rural 48.86%).
- Avg glucose level (mg/dL) [45]: This feature captures the participant’s average glucose level.
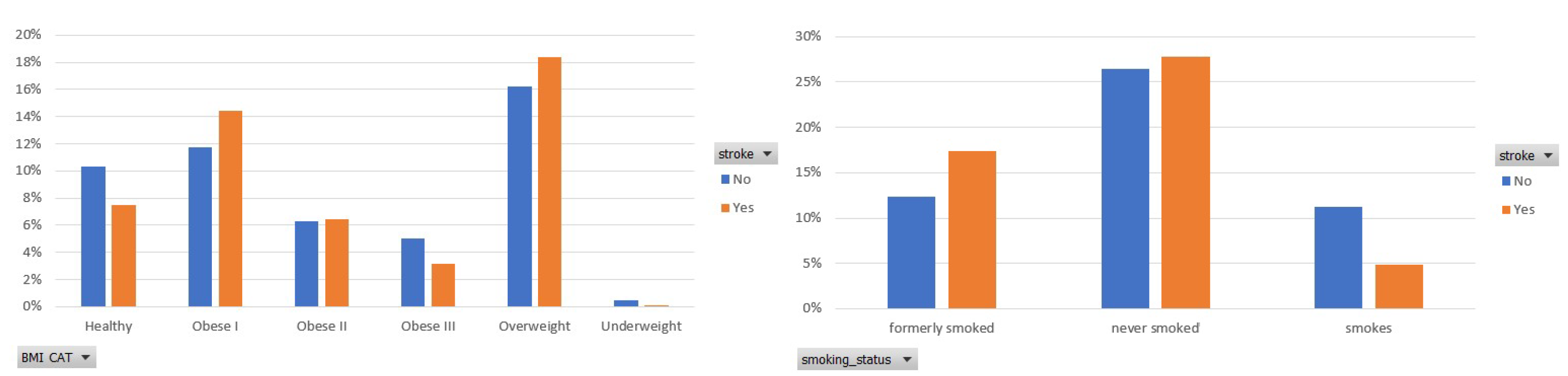
- BMI (Kg/m2) [46]: This feature captures the body mass index of the participants.
- Smoking Status [47]: This feature captures the participant’s smoking status and has 3 categories (smoke 22.37%, never smoked 52.64% and formerly smoked 24.99%).
- Stroke: This feature represents if the participant previously had a stroke or not. The percentage of participants who have suffered a stroke is 5.53%.
3.2. Long-Term Stroke Risk Assessment
Data Preprocessing
3.3. Machine Learning Models
3.3.1. Naive Bayes
3.3.2. Random Forest
3.3.3. Logistic Regression
3.3.4. K-Nearest Neighbors
3.3.5. Stochastic Gradient Descent
3.3.6. Decision Tree
3.3.7. Multilayer Percepton
3.3.8. Majority Voting
3.3.9. Stacking
3.4. Evaluation Metrics
4. Results and Discussion
4.1. Experiments Setup
4.2. Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Learn about Stroke. Available online: https://www.world-stroke.org/world-stroke-day-campaign/why-stroke-matters/learn-about-stroke (accessed on 25 May 2022).
- Elloker, T.; Rhoda, A.J. The relationship between social support and participation in stroke: A systematic review. Afr. J. Disabil. 2018, 7, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Katan, M.; Luft, A. Global burden of stroke. In Seminars in Neurology; Thieme Medical Publishers: New York, NY, USA, 2018; Volume 38, pp. 208–211. [Google Scholar]
- Bustamante, A.; Penalba, A.; Orset, C.; Azurmendi, L.; Llombart, V.; Simats, A.; Pecharroman, E.; Ventura, O.; Ribó, M.; Vivien, D.; et al. Blood biomarkers to differentiate ischemic and hemorrhagic strokes. Neurology 2021, 96, e1928–e1939. [Google Scholar] [CrossRef] [PubMed]
- Xia, X.; Yue, W.; Chao, B.; Li, M.; Cao, L.; Wang, L.; Shen, Y.; Li, X. Prevalence and risk factors of stroke in the elderly in Northern China: Data from the National Stroke Screening Survey. J. Neurol. 2019, 266, 1449–1458. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alloubani, A.; Saleh, A.; Abdelhafiz, I. Hypertension and diabetes mellitus as a predictive risk factors for stroke. Diabetes Metab. Syndr. Clin. Res. Rev. 2018, 12, 577–584. [Google Scholar] [CrossRef]
- Boehme, A.K.; Esenwa, C.; Elkind, M.S. Stroke risk factors, genetics, and prevention. Circ. Res. 2017, 120, 472–495. [Google Scholar] [CrossRef]
- Mosley, I.; Nicol, M.; Donnan, G.; Patrick, I.; Dewey, H. Stroke symptoms and the decision to call for an ambulance. Stroke 2007, 38, 361–366. [Google Scholar] [CrossRef]
- Lecouturier, J.; Murtagh, M.J.; Thomson, R.G.; Ford, G.A.; White, M.; Eccles, M.; Rodgers, H. Response to symptoms of stroke in the UK: A systematic review. BMC Health Serv. Res. 2010, 10, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Gibson, L.; Whiteley, W. The differential diagnosis of suspected stroke: A systematic review. J. R. Coll. Physicians Edinb. 2013, 43, 114–118. [Google Scholar] [CrossRef]
- Rudd, M.; Buck, D.; Ford, G.A.; Price, C.I. A systematic review of stroke recognition instruments in hospital and prehospital settings. Emerg. Med. J. 2016, 33, 818–822. [Google Scholar] [CrossRef]
- Delpont, B.; Blanc, C.; Osseby, G.; Hervieu-Bègue, M.; Giroud, M.; Béjot, Y. Pain after stroke: A review. Rev. Neurol. 2018, 174, 671–674. [Google Scholar] [CrossRef]
- Kumar, S.; Selim, M.H.; Caplan, L.R. Medical complications after stroke. Lancet Neurol. 2010, 9, 105–118. [Google Scholar] [CrossRef]
- Ramos-Lima, M.J.M.; Brasileiro, I.d.C.; Lima, T.L.d.; Braga-Neto, P. Quality of life after stroke: Impact of clinical and sociodemographic factors. Clinics 2018, 73, e418. [Google Scholar] [CrossRef]
- Gittler, M.; Davis, A.M. Guidelines for adult stroke rehabilitation and recovery. JAMA 2018, 319, 820–821. [Google Scholar] [CrossRef]
- Pandian, J.D.; Gall, S.L.; Kate, M.P.; Silva, G.S.; Akinyemi, R.O.; Ovbiagele, B.I.; Lavados, P.M.; Gandhi, D.B.; Thrift, A.G. Prevention of stroke: A global perspective. Lancet 2018, 392, 1269–1278. [Google Scholar] [CrossRef]
- Feigin, V.L.; Norrving, B.; George, M.G.; Foltz, J.L.; Roth, G.A.; Mensah, G.A. Prevention of stroke: A strategic global imperative. Nat. Rev. Neurol. 2016, 12, 501–512. [Google Scholar] [CrossRef]
- Fazakis, N.; Kocsis, O.; Dritsas, E.; Alexiou, S.; Fakotakis, N.; Moustakas, K. Machine learning tools for long-term type 2 diabetes risk prediction. IEEE Access 2021, 9, 103737–103757. [Google Scholar] [CrossRef]
- Alexiou, S.; Dritsas, E.; Kocsis, O.; Moustakas, K.; Fakotakis, N. An approach for Personalized Continuous Glucose Prediction with Regression Trees. In Proceedings of the 2021 6th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM), Preveza, Greece, 24–26 September 2001; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Dritsas, E.; Alexiou, S.; Konstantoulas, I.; Moustakas, K. Short-term Glucose Prediction based on Oral Glucose Tolerance Test Values. In Proceedings of the International Joint Conference on Biomedical Engineering Systems and Technologies—HEALTHINF, Lisbon, Portugal, 12–15 January 2022; Volume 5, pp. 249–255. [Google Scholar]
- Dritsas, E.; Fazakis, N.; Kocsis, O.; Fakotakis, N.; Moustakas, K. Long-Term Hypertension Risk Prediction with ML Techniques in ELSA Database. In Proceedings of the International Conference on Learning and Intelligent Optimization, Athens, Greece, 20–25 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 113–120. [Google Scholar]
- Fazakis, N.; Dritsas, E.; Kocsis, O.; Fakotakis, N.; Moustakas, K. Long-Term Cholesterol Risk Prediction with Machine Learning Techniques in ELSA Database. In Proceedings of the 13th International Joint Conference on Computational Intelligence (IJCCI), Valletta, Malta, 25–27 October 2021; SCIPTRESS: Atlanta, GA, USA, 2021; pp. 445–450. [Google Scholar]
- Kwekha-Rashid, A.S.; Abduljabbar, H.N.; Alhayani, B. Coronavirus disease (COVID-19) cases analysis using machine-learning applications. Appl. Nanosci. 2021, 2021, 1–13. [Google Scholar] [CrossRef]
- Moll, M.; Qiao, D.; Regan, E.A.; Hunninghake, G.M.; Make, B.J.; Tal-Singer, R.; McGeachie, M.J.; Castaldi, P.J.; Estepar, R.S.J.; Washko, G.R.; et al. Machine learning and prediction of all-cause mortality in COPD. Chest 2020, 158, 952–964. [Google Scholar] [CrossRef]
- Dritsas, E.; Alexiou, S.; Moustakas, K. Cardiovascular Disease Risk Prediction with Supervised Machine Learning Techniques. In Proceedings of the 8th International Conference on Information and Communication Technologies for Ageing Well and e-Health—ICT4AWE, INSTICC, Online, 22–24 April 2022; SciTePress: Setúbal, Portugal, 2022; pp. 315–321. [Google Scholar]
- Speiser, J.L.; Karvellas, C.J.; Wolf, B.J.; Chung, D.; Koch, D.G.; Durkalski, V.L. Predicting daily outcomes in acetaminophen-induced acute liver failure patients with machine learning techniques. Comput. Methods Programs Biomed. 2019, 175, 111–120. [Google Scholar] [CrossRef]
- Konstantoulas, I.; Kocsis, O.; Dritsas, E.; Fakotakis, N.; Moustakas, K. Sleep Quality Monitoring with Human Assisted Corrections. In Proceedings of the International Joint Conference on Computational Intelligence (IJCCI), Valletta, Malta, 25–27 October 2021; SCIPTRESS: Atlanta, GA, USA, 2021; pp. 435–444. [Google Scholar]
- Konerman, M.A.; Beste, L.A.; Van, T.; Liu, B.; Zhang, X.; Zhu, J.; Saini, S.D.; Su, G.L.; Nallamothu, B.K.; Ioannou, G.N.; et al. Machine learning models to predict disease progression among veterans with hepatitis C virus. PLoS ONE 2019, 14, e0208141. [Google Scholar] [CrossRef]
- Wang, W.; Chakraborty, G.; Chakraborty, B. Predicting the risk of chronic kidney disease (ckd) using machine learning algorithm. Appl. Sci. 2020, 11, 202. [Google Scholar] [CrossRef]
- Maldonado, S.; López, J.; Vairetti, C. An alternative SMOTE oversampling strategy for high-dimensional datasets. Appl. Soft Comput. 2019, 76, 380–389. [Google Scholar] [CrossRef]
- Shoily, T.I.; Islam, T.; Jannat, S.; Tanna, S.A.; Alif, T.M.; Ema, R.R. Detection of stroke disease using machine learning algorithms. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Pradeepa, S.; Manjula, K.; Vimal, S.; Khan, M.S.; Chilamkurti, N.; Luhach, A.K. DRFS: Detecting risk factor of stroke disease from social media using machine learning techniques. Neural Process. Lett. 2020, 2020, 1–19. [Google Scholar] [CrossRef]
- Li, X.; Bian, D.; Yu, J.; Li, M.; Zhao, D. Using machine learning models to improve stroke risk level classification methods of China national stroke screening. BMC Med. Inf. Decis. Mak. 2019, 19, 1–7. [Google Scholar] [CrossRef]
- Stroke Prediction Dataset. Available online: https://www.kaggle.com/datasets/fedesoriano/stroke-prediction-dataset (accessed on 25 May 2022).
- Sailasya, G.; Kumari, G.L.A. Analyzing the performance of stroke prediction using ML classification algorithms. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 539–545. [Google Scholar] [CrossRef]
- Govindarajan, P.; Soundarapandian, R.K.; Gandomi, A.H.; Patan, R.; Jayaraman, P.; Manikandan, R. Classification of stroke disease using machine learning algorithms. Neural Comput. Appl. 2020, 32, 817–828. [Google Scholar] [CrossRef]
- Nwosu, C.S.; Dev, S.; Bhardwaj, P.; Veeravalli, B.; John, D. Predicting stroke from electronic health records. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 5704–5707. [Google Scholar]
- Lee, H.; Lee, E.J.; Ham, S.; Lee, H.B.; Lee, J.S.; Kwon, S.U.; Kim, J.S.; Kim, N.; Kang, D.W. Machine learning approach to identify stroke within 4.5 hours. Stroke 2020, 51, 860–866. [Google Scholar] [CrossRef]
- Rexrode, K.M.; Madsen, T.E.; Yu, A.Y.; Carcel, C.; Lichtman, J.H.; Miller, E.C. The impact of sex and gender on stroke. Circ. Res. 2022, 130, 512–528. [Google Scholar] [CrossRef]
- Dubow, J.; Fink, M.E. Impact of hypertension on stroke. Curr. Atheroscler. Rep. 2011, 13, 298–305. [Google Scholar] [CrossRef]
- Tsao, C.W.; Aday, A.W.; Almarzooq, Z.I.; Alonso, A.; Beaton, A.Z.; Bittencourt, M.S.; Boehme, A.K.; Buxton, A.E.; Carson, A.P.; Commodore-Mensah, Y.; et al. Heart Disease and Stroke Statistics—2022 Update: A Report From the American Heart Association. Circulation 2022, 145, e153–e639. [Google Scholar] [CrossRef]
- Andersen, K.; Olsen, T. Stroke case-fatality and marital status. Acta Neurol. Scand. 2018, 138, 377–383. [Google Scholar] [CrossRef]
- Cox, A.M.; McKevitt, C.; Rudd, A.G.; Wolfe, C.D. Socioeconomic status and stroke. Lancet Neurol. 2006, 5, 181–188. [Google Scholar] [CrossRef]
- Howard, G. Rural-urban differences in stroke risk. Prev. Med. 2021, 152, 106661. [Google Scholar] [CrossRef]
- Cai, Y.; Wang, C.; Di, W.; Li, W.; Liu, J.; Zhou, S. Correlation between blood glucose variability and the risk of death in patients with severe acute stroke. Rev. Neurol. 2020, 176, 582–586. [Google Scholar] [CrossRef]
- Elsayed, S.; Othman, M. The effect of body mass index (BMI) on the mortality among patients with stroke. Eur. J. Mol. Clin. Med. 2021, 8, 181–187. [Google Scholar]
- Shah, R.S.; Cole, J.W. Smoking and stroke: The more you smoke the more you stroke. Expert Rev. Cardiovasc. Ther. 2010, 8, 917–932. [Google Scholar] [CrossRef]
- Fan, C.; Chen, M.; Wang, X.; Wang, J.; Huang, B. A review on data preprocessing techniques toward efficient and reliable knowledge discovery from building operational data. Front. Energy Res. 2021, 9, 652801. [Google Scholar] [CrossRef]
- Trabelsi, M.; Meddouri, N.; Maddouri, M. A new feature selection method for nominal classifier based on formal concept analysis. Procedia Comput. Sci. 2017, 112, 186–194. [Google Scholar] [CrossRef]
- Berrar, D. Bayes’ theorem and naive Bayes classifier. In Encyclopedia of Bioinformatics and Computational Biology: ABC of Bioinformatics; Elsevier: Amsterdam, The Netherlands, 2018; p. 403. [Google Scholar]
- Nusinovici, S.; Tham, Y.C.; Yan, M.Y.C.; Ting, D.S.W.; Li, J.; Sabanayagam, C.; Wong, T.Y.; Cheng, C.Y. Logistic regression was as good as machine learning for predicting major chronic diseases. J. Clin. Epidemiol. 2020, 122, 56–69. [Google Scholar] [CrossRef]
- Cunningham, P.; Delany, S.J. k-Nearest neighbour classifiers-A Tutorial. ACM Comput. Surv. (CSUR) 2021, 54, 1–25. [Google Scholar] [CrossRef]
- Deepa, N.; Prabadevi, B.; Maddikunta, P.K.; Gadekallu, T.R.; Baker, T.; Khan, M.A.; Tariq, U. An AI-based intelligent system for healthcare analysis using Ridge-Adaline Stochastic Gradient Descent Classifier. J. Supercomput. 2021, 77, 1998–2017. [Google Scholar] [CrossRef]
- Al Snousy, M.B.; El-Deeb, H.M.; Badran, K.; Al Khlil, I.A. Suite of decision tree-based classification algorithms on cancer gene expression data. Egypt. Inf. J. 2011, 12, 73–82. [Google Scholar] [CrossRef] [Green Version]
- Dinesh, K.G.; Arumugaraj, K.; Santhosh, K.D.; Mareeswari, V. Prediction of cardiovascular disease using machine learning algorithms. In Proceedings of the 2018 International Conference on Current Trends towards Converging Technologies (ICCTCT), Coimbatore, India, 1–3 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–7. [Google Scholar]
- Abirami, S.; Chitra, P. Energy-efficient edge based real-time healthcare support system. In Advances in Computers; Elsevier: Amsterdam, The Netherlands, 2020; Volume 117, pp. 339–368. [Google Scholar]
- Shankar, K.; Zhang, Y.; Liu, Y.; Wu, L.; Chen, C.H. Hyperparameter tuning deep learning for diabetic retinopathy fundus image classification. IEEE Access 2020, 8, 118164–118173. [Google Scholar] [CrossRef]
- Dogan, A.; Birant, D. A weighted majority voting ensemble approach for classification. In Proceedings of the 2019 4th International Conference on Computer Science and Engineering (UBMK), Samsun, Turkey, 11–15 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Rajagopal, S.; Kundapur, P.P.; Hareesha, K.S. A stacking ensemble for network intrusion detection using heterogeneous datasets. Secur. Commun. Netw. 2020, 2020, 4586875. [Google Scholar] [CrossRef] [Green Version]
- Pandey, P.; Prabhakar, R. An analysis of machine learning techniques (J48 & AdaBoost)-for classification. In Proceedings of the 2016 1st India International Conference on Information Processing (IICIP), Delhi, India, 12–14 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Hossin, M.; Sulaiman, M.N. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1. [Google Scholar]
- Weka Tool. Available online: https://www.weka.io/ (accessed on 25 May 2022).
- Raj, P.; David, P.E. The Digital Twin Paradigm for Smarter Systems and Environments: The Industry Use Cases; Academic Press: Cambridge, MA, USA, 2020. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Random Forest | Information Gain | ||
|---|---|---|---|
| Attribute | Rank | Attribute | Rank |
| Age | 0.4702 | Age | 0.75627 |
| BMI | 0.404 | Ever_married | 0.09382 |
| Avg_glucose_level | 0.1139 | BMI | 0.06991 |
| Ever_married | 0.0929 | Avg_glucose_level | 0.06265 |
| Work_type | 0.0898 | Work_type | 0.05651 |
| Smoking_status | 0.0661 | Heart_disease | 0.02777 |
| Residence_type | 0.0537 | Smoking_status | 0.02554 |
| Gender | 0.0500 | Residence_type | 0.02129 |
| Heart_disease | 0.0499 | Gender | 0.01667 |
| Hypertension | 0.0177 | Hypertension | 0.00523 |
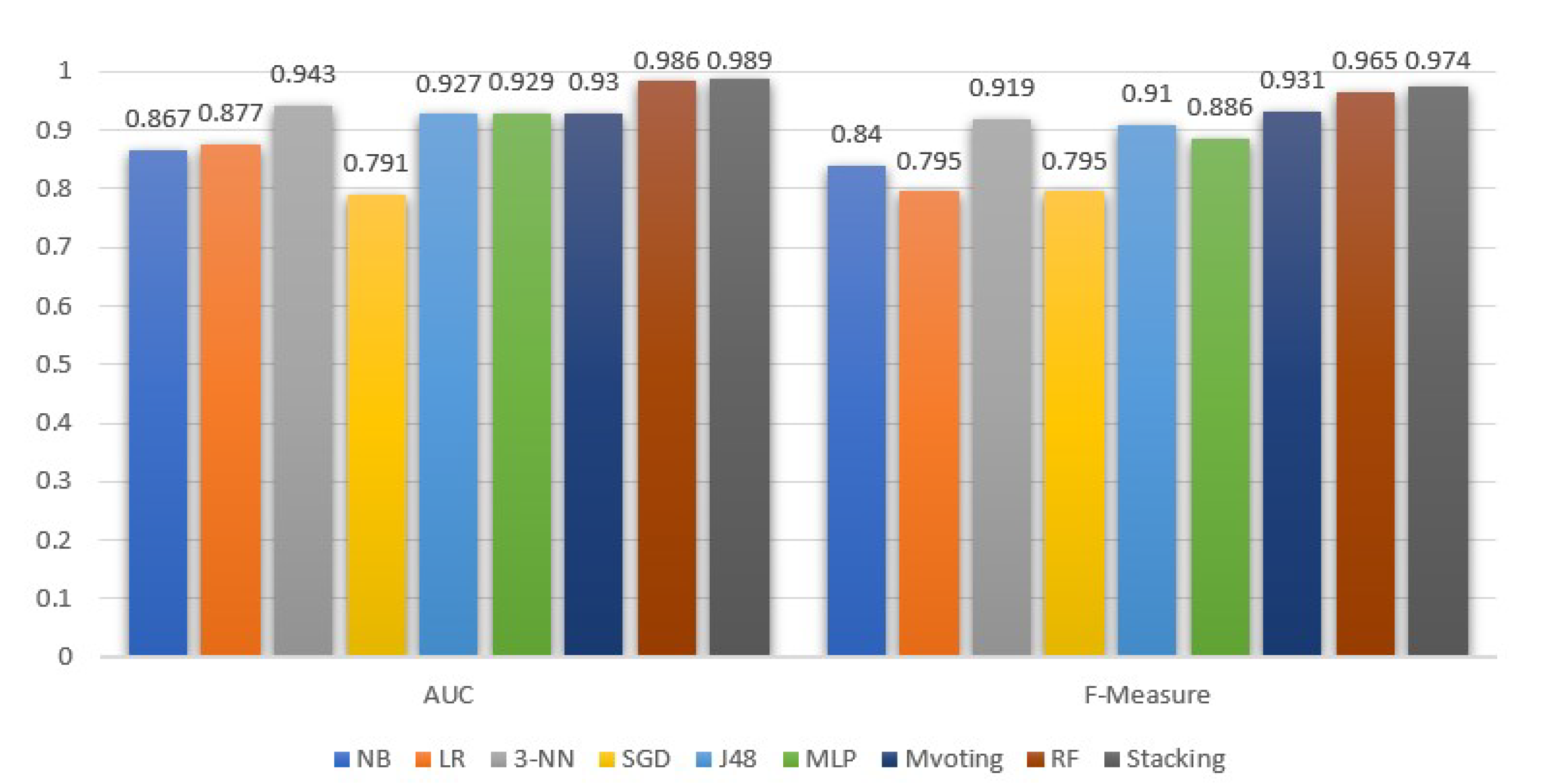
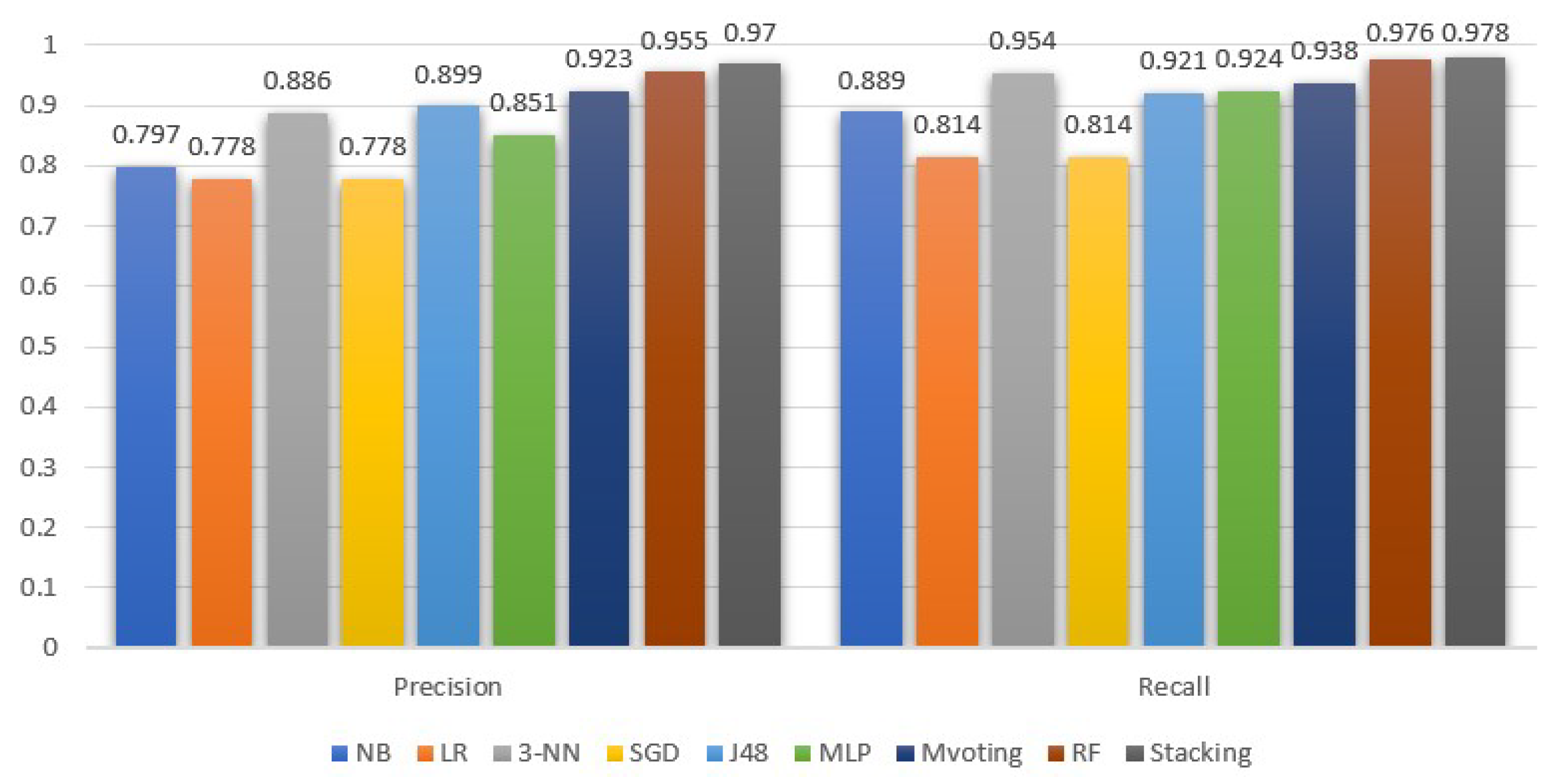
| Precision | Recall | F-Measure | AUC | Accuracy | |
|---|---|---|---|---|---|
| NB | 0.812 | 0.860 | 0.835 | 0.867 | 0.84 |
| LR | 0.791 | 0.791 | 0.791 | 0.877 | 0.79 |
| 3-NN | 0.918 | 0.916 | 0.915 | 0.943 | 0.81 |
| SGD | 0.791 | 0.791 | 0.791 | 0.791 | 0.88 |
| DT(J48) | 0.909 | 0.909 | 0.909 | 0.927 | 0.91 |
| MLP | 0.884 | 0.881 | 0.881 | 0.929 | 0.92 |
| MVoting | 0.93 | 0.93 | 0.93 | 0.93 | 0.93 |
| RF | 0.966 | 0.966 | 0.966 | 0.986 | 0.97 |
| Stacking | 0.974 | 0.974 | 0.974 | 0.989 | 0.98 |
| Precision | Recall | F-Measure | Accuracy | |||||
|---|---|---|---|---|---|---|---|---|
| Proposed | [35] | Proposed | [35] | Proposed | [35] | Proposed | [35] | |
| NB | 0.812 | 0.786 | 0.860 | 0.857 | 0.835 | 0.823 | 0.84 | 0.82 |
| LR | 0.791 | 0.775 | 0.791 | 0.760 | 0.791 | 0.776 | 0.79 | 0.78 |
| 3-NN | 0.918 | 0.774 | 0.916 | 0.838 | 0.915 | 0.804 | 0.81 | 0.80 |
| DT | 0.909 | 0.909 | 0.909 | 0.775 | 0.909 | 0.776 | 0.88 | 0.66 |
| RF | 0.974 | 0.720 | 0.974 | 0.735 | 0.974 | 0.727 | 0.98 | 0.73 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dritsas, E.; Trigka, M. Stroke Risk Prediction with Machine Learning Techniques. Sensors 2022, 22, 4670. https://doi.org/10.3390/s22134670
Dritsas E, Trigka M. Stroke Risk Prediction with Machine Learning Techniques. Sensors. 2022; 22(13):4670. https://doi.org/10.3390/s22134670
Chicago/Turabian StyleDritsas, Elias, and Maria Trigka. 2022. "Stroke Risk Prediction with Machine Learning Techniques" Sensors 22, no. 13: 4670. https://doi.org/10.3390/s22134670
APA StyleDritsas, E., & Trigka, M. (2022). Stroke Risk Prediction with Machine Learning Techniques. Sensors, 22(13), 4670. https://doi.org/10.3390/s22134670