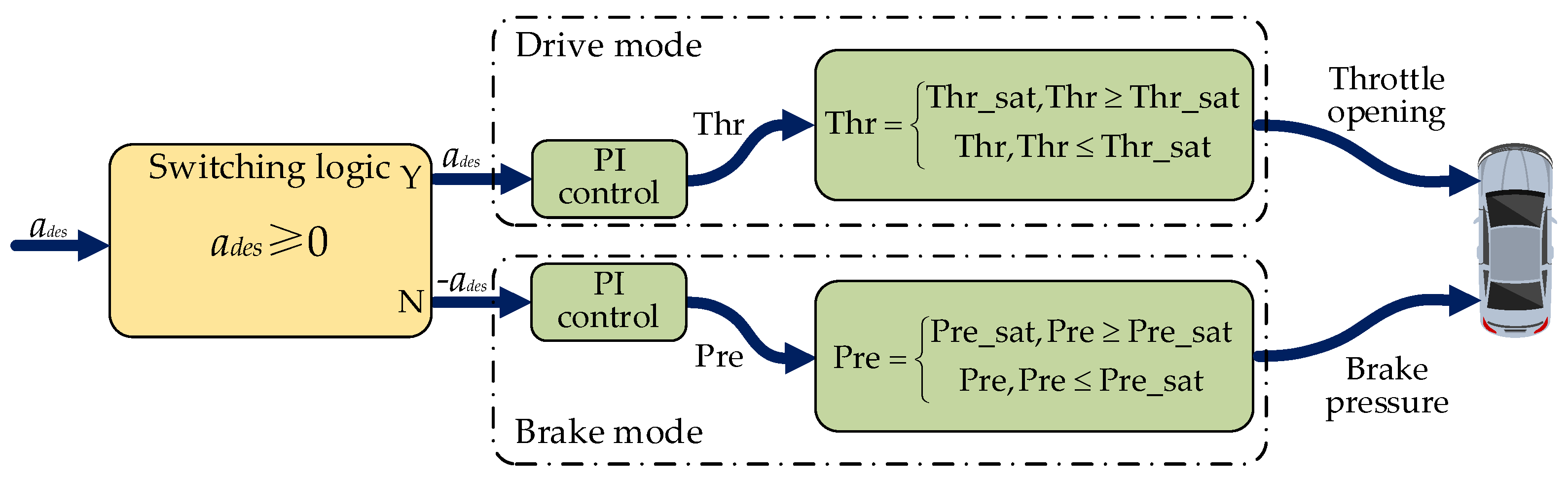
4.2. Upper Level Controller Design
Since longitudinal velocity is time-varying, Equation (10) is rewritten as a linear time-varying system as follows:
The controller is used in the discrete-time model. Thus, the continuous system needs to be converted into a discrete system. Ignoring the influence of term
, by using the midpoint Euler method and the forward Euler method on Equation (19) and simplifying it, the discretization model for the lateral tracking error can be obtained as follows:
where
The optimal control performance function for LQR is established as follows:
where
is the state variable of the system,
is the control variable of the system, and
and
are the weighting matrices of the state error and the control quantity, respectively. According to several experiments, the weighting matrices must be set to
and
. When
is minimum, the control quantity
is the desired front wheel steering angle.
Substituting Equation (20) into (22) as a constraint, the Lagrangian control problem with multiplicative constraints is constructed as follows:
Now, the Hamiltonian function can be constructed as follows:
Substituting Equation (24) into (23) and simplification obtains:
Now, the extreme value of Equation (25) can be obtained as follows:
where
is the solution of Riccati equation
.
Setting
, the control quantity of the LQR controller can be obtained as follows:
where
is the gain of the LQR controller.
Substituting Equation (27) into (19) obtains:
According to the above equation, no matter what the value of gain is, the distance error and heading error of the intelligent vehicle cannot be guaranteed to be zero in the control process; that is, there is a steady-state error in the system. Hence, in this paper, the feedforward controller based on feedback is designed to eliminate the steady-state error.
The actual control quantity after introducing feedforward
is:
Substitute Equation (29) into (19) so that
; that is, assume that the system reaches a steady state where the steady-state error is:
By solving Equation (30) and simplifying it, the following can be obtained:
The analytic Equation (31) shows that when the lateral distance error
, the feedforward control quantity
is:
In Equation (5), the actual heading error is assumed to be
for ease of calculation. When the vehicle reaches the steady state, it is necessary to make the heading error
, and there is
. Thus, it is not necessary to design a feedforward controller to eliminate the steady-state error of
. Meanwhile, the authors of [
30] proved that the steady-state equilibrium can still be achieved where the values of lateral error and heading angle error are nonzero.
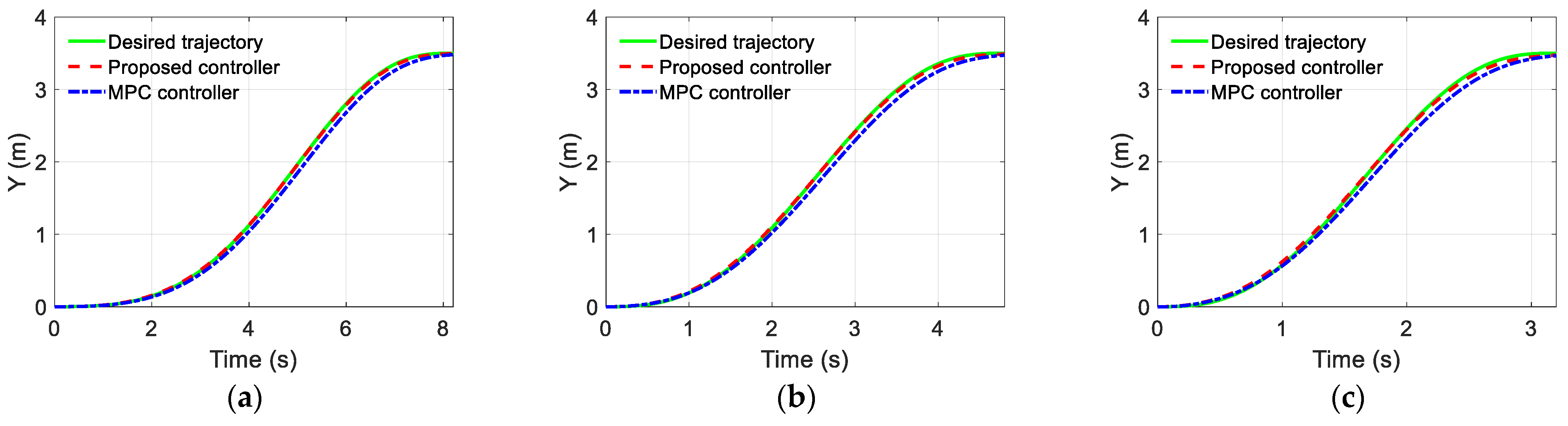
The proposed MPC is a discrete-time strategy, and the continuous system should be discretized.
By using the forward Euler method on Equation (12) and simplifying it, the discretization model for a longitudinal control system can be obtained as follows:
where
where
is the sampling period.
The output equation of the longitudinal control system can be expressed as:
We next track the desired speed accurately and smoothly by penalizing acceleration or excessive changes in acceleration. Formulating the control problem with a cost function:
where
is the prediction time domain;
is the control time domain;
is the prediction for the control output variable;
is the reference for the control output variable;
represent the fact that the value at sampling time
is predicted based on the information from the sampling time
, where
;
is the weight matrix of the system output, reflecting the tracking accuracy of the control system to the reference velocity; and
is the weight matrix of the system control increment.
Considering the comfort of the driver, the acceleration and the acceleration increment should be constrained, and the constraints can be formulated as follows:
where
and
are the minimum and maximum acceleration, respectively, and
and
are the minimum and maximum acceleration increment, respectively.
Notice that the longitudinal velocity and yaw rate are time-varying during the driving process. As presented in the introduction, the time-varying characteristic of the vehicle states is a critical issue in the trajectory-tracking controller design, so the EKF observer is designed to estimate them.
As can be seen from the geometric relationship in
Figure 2, the slip angles of the front and rear tires and the slip angle of the centroid of the vehicle can be expressed as:
Through calculation and simplification in combination with Equation (4), the state equation and observation equation based on a 3-DOF nonlinear vehicle model can be obtained:
where
is the yaw rate of the vehicle,
is the longitudinal acceleration of the vehicle, and
is the lateral acceleration of the vehicle.
The state Equation (41) and the observation Equation (42) are discretized to obtain:
Rewriting the discretized state equation and observation equation into the form of state space equation yields:
where
is the state variable,
is the input variable, and
is the observation variable.
and
are the system noise and measurement noise, respectively, and they are independent of each other and their mean value is zero, the variance of
is
, and the variance of
is
.
Then, the state equation and observation equation are linearized to obtain the Jacobian matrix:
The Extended Kalman Filter consists of a prediction step and an update step.
The prediction step first predicts the state variable
at time
k by the state variable
at time (
k − 1):
The prediction error covariance matrix
is then computed:
In the update step, the state variable
is modified by Kalman gain
, and the state variable
at time
k is then computed:
where Kalman gain
.
The state error covariance matrix
is then computed:
where
and
are both Gaussian white noise with zero mean and independence.
For the EKF observer, the appropriate system noise covariance matrix
and measurement noise covariance matrix
need to be selected, and the algorithm starts with the initial values
and
. In this paper, we consider that
and
are constants and that the setting of these parameters follows the method proposed by Schneider and Georgakis [
31].
and
depend on the system and the sensors and should be determined by the user’s system and sensors. After constant debugging, we obtain two values:
and
. The initial value of the state error covariance matrix is set as
[0.001, 0.001, 0.001].














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}