1. Introduction
In recent years, the rapid development of multi-sensor technologies has opened up the possibility of observing interest regions on the Earth’s surface from different perspectives. These technologies include mainly synthetic aperture radar (SAR) [
1], light detection and ranging (LiDAR) [
2], hyperspectral (HS) imagery [
3] and multispectral (MS) imagery [
4], which all contain several different types of information about the target area. Among them, HS, which is a passive remote sensing technique, samples the reflective part of the electromagnetic spectrum through hyperspectral sensors, resulting in rich and continuous spectral information. This spectral information can range from the visible region (0.4–0.7 μm) to the shortwave infrared region (nearly 2.4 μm) over hundreds of narrow, contiguous spectral channels (typically 10 nm wide). This detailed spectral information makes HS image a valuable data source for remote sensing image classification in complex scenes [
5]. However, it is often difficult to obtain satisfactory and fine classification results from single-modal data [
6]. For example, there are often many misclassifications in classification tasks of objects consisting of similar materials (e.g., grass, shrubs and trees). Therefore, there is a need to further refine or improve the classification results by combining information from other different sensors. LiDAR, as active remote sensing technology, uses lasers to detect and measure the target area, and obtains exact height and shape information about the scene. Therefore, the comprehensive utilization of HS and LiDAR data has become an active topic in the remote sensing community. Many studies have shown that LiDAR data can be used as an excellent complement to HS data to enhance or improve scene classification performance effectively [
7,
8]. Due to its significant advantages, multimodal data have also been applied in many other fields, such as crop cover [
9] and forest fire management [
10].
The fusion methods for multimodal data can currently be divided into two main categories: feature-level fusion and decision-level fusion [
11,
12]. The former first pre-processes and extracts features from different sources of remote sensing data, then fuses them through feature superposition or reconstruction, and finally sends them to a classifier to complete scene classification. The latter first employs multiple classifiers to classify remote sensing data from multiple sources independently, and finally fuses or integrates these multiple classification results (or decisions) to produce the final classification result. For example, Pedergnana et al. [
13] proposed a technique for classifying features extracted from extended attribute profiles (EAPs) on optical and LiDAR images, thus enabling the fusion of spectral, spatial and elevation data. Rasti et al. [
14] presented the fusion of the datasets using orthogonal total variance component analysis (OTVCA). It first automatically extracts spatial and elevation information from HS and rasterized LiDAR features, then uses the OTVCA feature fusion method to fuse the extracted spatial and elevation information with the spectral information to generate the final classification map. Rasti et al. [
8] put forward a new sparse low-rank based multi-source feature fusion method. It first extracts spatial and elevation information from hyperspectral and LiDAR data using extinction profiles, respectively. Then, low-rank fusion features are estimated from the extracted features using sparse low-rank techniques, which are finally used to generate the final classification map. Sturari et al. [
15] introduced a decision-level fusion method using elevation data and multispectral high-resolution imagery, thus enabling the joint use of multispectral, spatial and elevation data. However, most of these studies belong to shallow learning methods, which make it difficult to obtain more refined classification results in complex scenes.
In the last decades, deep learning techniques, represented by convolutional neural networks (CNN), have been able to model high-level feature representations through a hierarchical learning framework and have gradually replaced hand design-based approaches. It has been impressively successful in various fields of computer vision, such as image recognition [
16], object detection [
17] and natural language processing [
18]. In particular, CNN can stack a series of specially designed layers (e.g., the convolutional layers, the batch normalization layer) to form deep models and automatically mine robust and high-level spatial features from a large number of samples, which are typically invariant to most local variations in the data. These deep learning techniques also significantly affect the field of scene classification for multimodal remote sensing data. For example, Xu et al. [
19] adopted a two-branch convolutional neural network for extracting features from HS and LiDAR data, respectively, and fed the cascaded features into a standard classifier for pixel-level classification. Li et al. [
20] proposed to use deep CNN to learn the features of a pixel pair composed of a central pixel and its surrounding pixels, and then determine the final label based on a voting strategy. Lee et al. [
21] developed local contextual interactions by jointly exploiting the local spectral–spatial relationships of adjacent single-pixel vectors, and achieved significant results. In addition, Hong et al. [
22] proposed a deep model (EndNet) based on an encoder-decoder structure to extract features from HS and LiDAR data in an unsupervised training manner, and achieved better results. However, deep learning-based methods usually require a large number of labelled samples, which is challenging to meet for remote sensing data.
In recent years, graph convolutional networks (GCN) have developed rapidly and have excelled in the field of unstructured data processing, e.g., social networks [
23]. Based on the graph structure, GCN can aggregate and propagate information between any two nodes in a semi-supervised manner, and thus extracting structural features of the data in the middle- and long-range region. This is entirely different from CNN, which extracts neighborhood spatial features in the short-range region [
24]. There have been several studies using GCN for the scene classification of HS data. For example, Qin et al. [
25] developed a new method of constructing graphs based on combining spatial and spectral features, and improved the ability to classify remote sensing images. Wang et al. [
26] designed an architecture to encode the multiple spectral contextual information in a spectral pyramid of multiple embedding spaces with a graph attention mechanism. Wan et al. [
27,
28] proposed a multi-scale graph convolution operation in the super-pixel technology, which allows for the adjacency matrix to be updated dynamically with network iteration. Besides, miniGCN, proposed by Hong et al. [
24], adopted mini-batch learning to train GCN with a fixed scale, combining with local convolutional features for pixel-level classification, and obtaining satisfactory classification results. However, there is currently very little research on the direct use of GCN for multimodal data classification in the remote sensing community.
In summary, the nature of the data captured by different sensors is entirely different, which raises a severe challenge to the effective processing of multi-source remote sensing data [
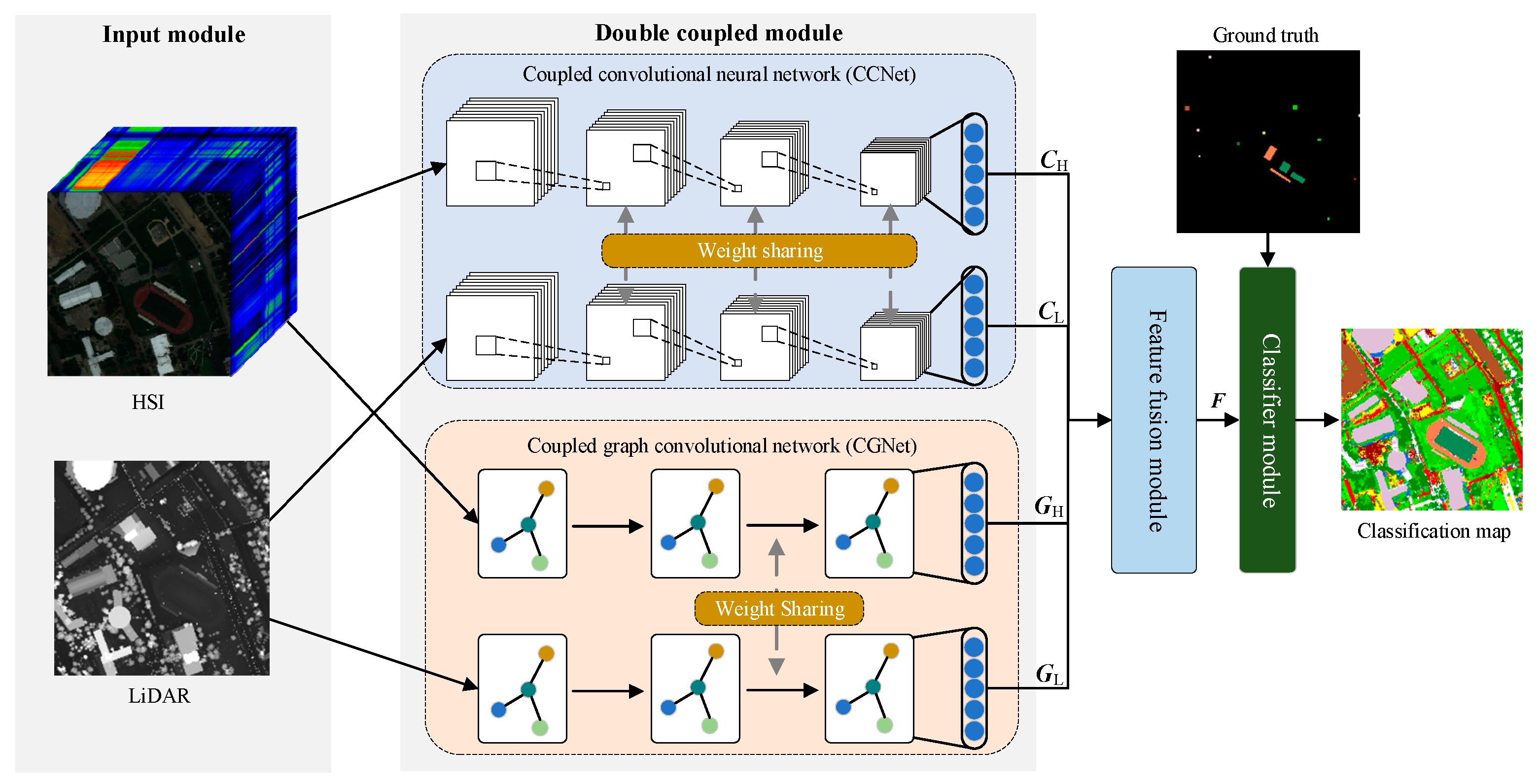
29]. However, it is still a problematic issue to design an effective deep classification model for multimodal data. In this paper, a hyperspectral and LiDAR data classification method based on a dual-coupled CNN-GCN structure (DCCG) is proposed. The model employs two sets of networks with similar structures for structure-level fusion, which can be divided into two parts: a coupled CNN and a coupled GCN. The former utilizes a weight-sharing mechanism to structurally fuse and simplify the dual CNN model and to extract spatial features from hyperspectral and LiDAR images, respectively. The latter first concatenates the HS and LiDAR data for constructing a uniform graph structure. Then, the dual GCN models perform structural fusion by sharing the graph structures and weight matrices of some layers to extract their structural information, respectively. Finally, the final hybrid features are fed into a standard classifier for the pixel-level classification task under a unified feature fusion module. The main contributions can be summarized as follows:
A dual-coupled network is proposed for the classification of hyperspectral and LiDAR images. The network adopts a weight-sharing strategy to significantly reduce the number of trainable parameters and alleviate the overfitting of the network. In addition, since CNN and GCN are used, both spatial and structural features can be extracted from hyperspectral and LiDAR data. This brings a richer set of input features to the subsequent classifier and helps to improve the classification performance of the whole network.
Several simple and effective multiple feature fusion strategies were developed to effectively utilize the four features extracted from the previous step. These strategies include traditional single fusion strategy and hybrid fusion strategy. Comparative analysis shows that a good feature fusion strategy can effectively improve classification performance.
Extensive experiments on two real-world HS and LiDAR data show that the proposed method exhibits significant superiority compared to state-of-the-art baseline methods, such as two-branch CNN and context CNN. In particular, the performance obtained on Trento data is comparable to that of the state-of-the-art methods reported so far.
The remainder of the paper is organized as follows.
Section 2 describes the proposed methodology. The dataset and experimental results are presented in
Section 3. The proposed method is analyzed and discussed in
Section 4. Conclusions are summarized in
Section 5.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}