
Single Camera Face Position-Invariant Driver’s Gaze Zone Classifier Based on Frame-Sequence Recognition Using 3D Convolutional Neural Networks


{kind=link}
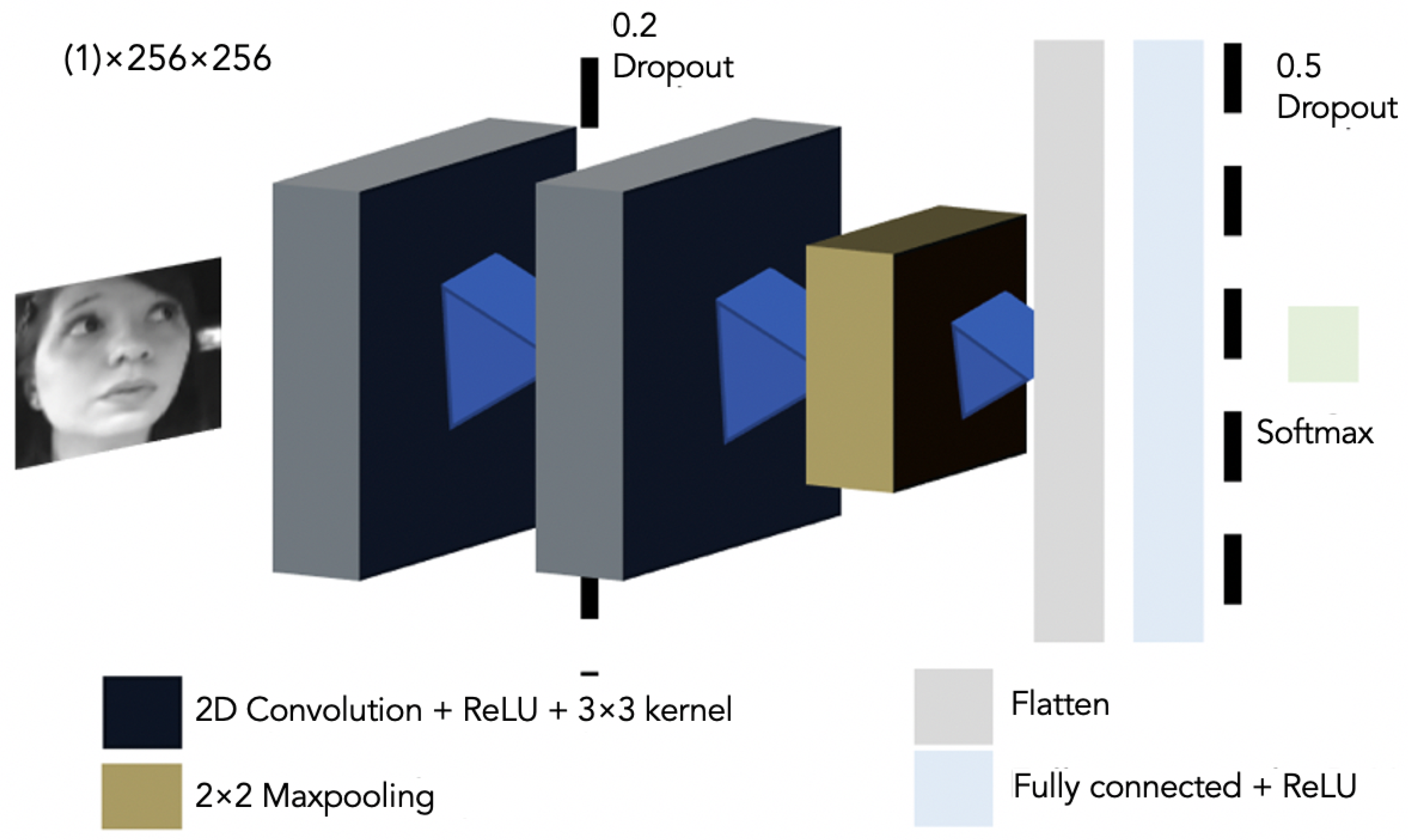{kind=link}
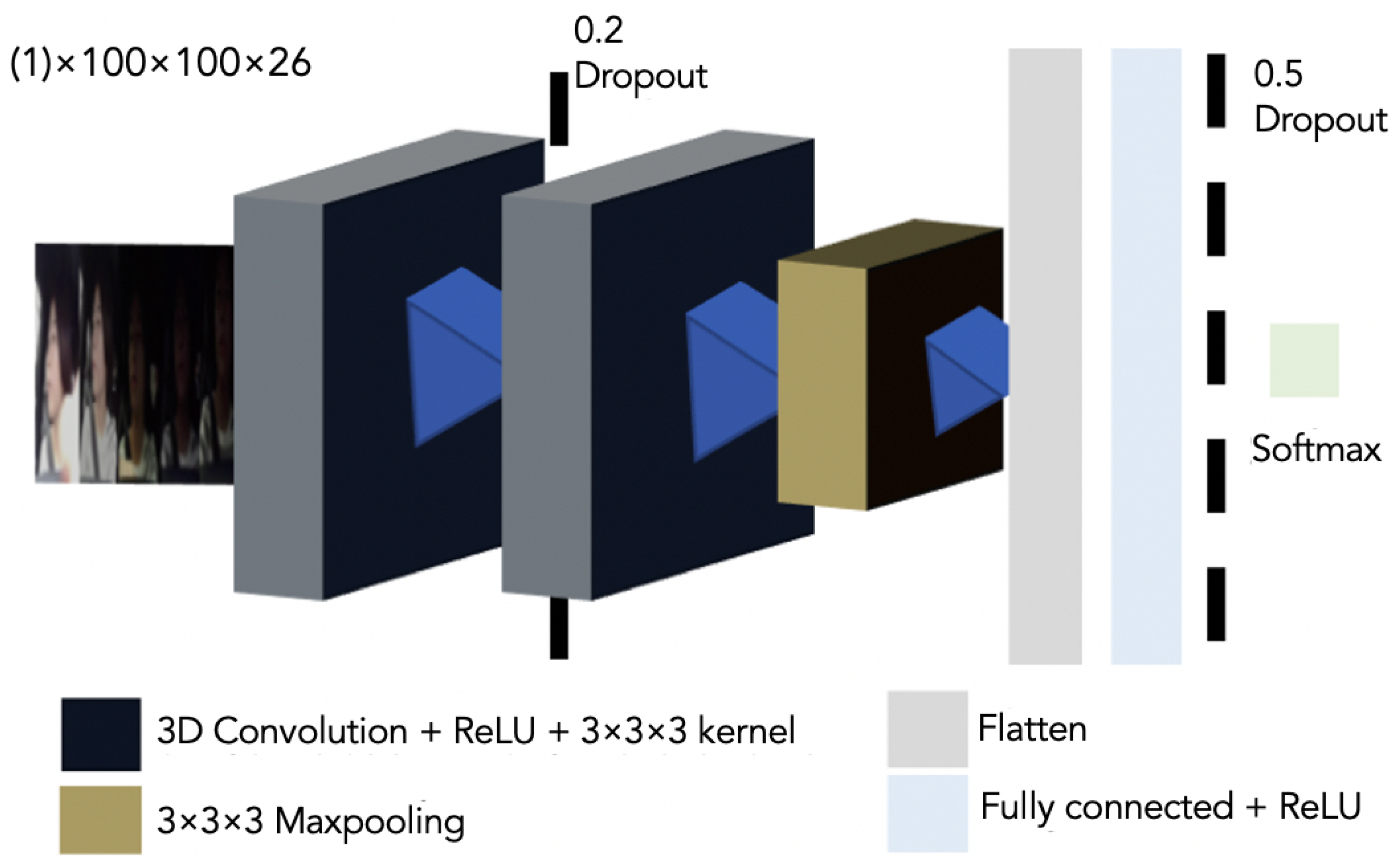{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
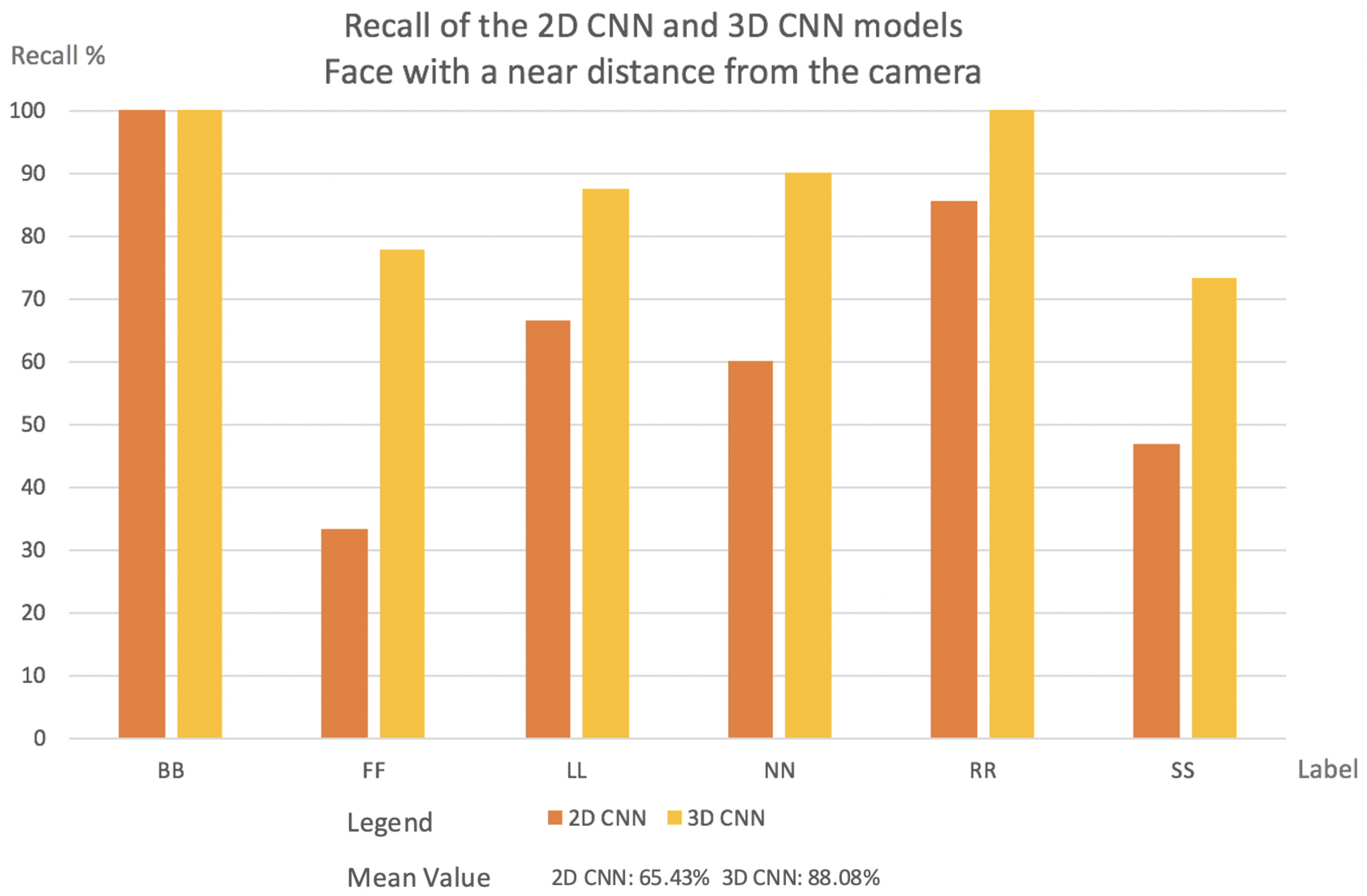{kind=link}
{kind=link}
Abstract
Share and Cite
Lollett, C.; Kamezaki, M.; Sugano, S. Single Camera Face Position-Invariant Driver’s Gaze Zone Classifier Based on Frame-Sequence Recognition Using 3D Convolutional Neural Networks. Sensors 2022, 22, 5857. https://doi.org/10.3390/s22155857
Lollett C, Kamezaki M, Sugano S. Single Camera Face Position-Invariant Driver’s Gaze Zone Classifier Based on Frame-Sequence Recognition Using 3D Convolutional Neural Networks. Sensors. 2022; 22(15):5857. https://doi.org/10.3390/s22155857
Chicago/Turabian StyleLollett, Catherine, Mitsuhiro Kamezaki, and Shigeki Sugano. 2022. "Single Camera Face Position-Invariant Driver’s Gaze Zone Classifier Based on Frame-Sequence Recognition Using 3D Convolutional Neural Networks" Sensors 22, no. 15: 5857. https://doi.org/10.3390/s22155857
APA StyleLollett, C., Kamezaki, M., & Sugano, S. (2022). Single Camera Face Position-Invariant Driver’s Gaze Zone Classifier Based on Frame-Sequence Recognition Using 3D Convolutional Neural Networks. Sensors, 22(15), 5857. https://doi.org/10.3390/s22155857