
A Review of Vision-Laser-Based Civil Infrastructure Inspection and Monitoring


Abstract
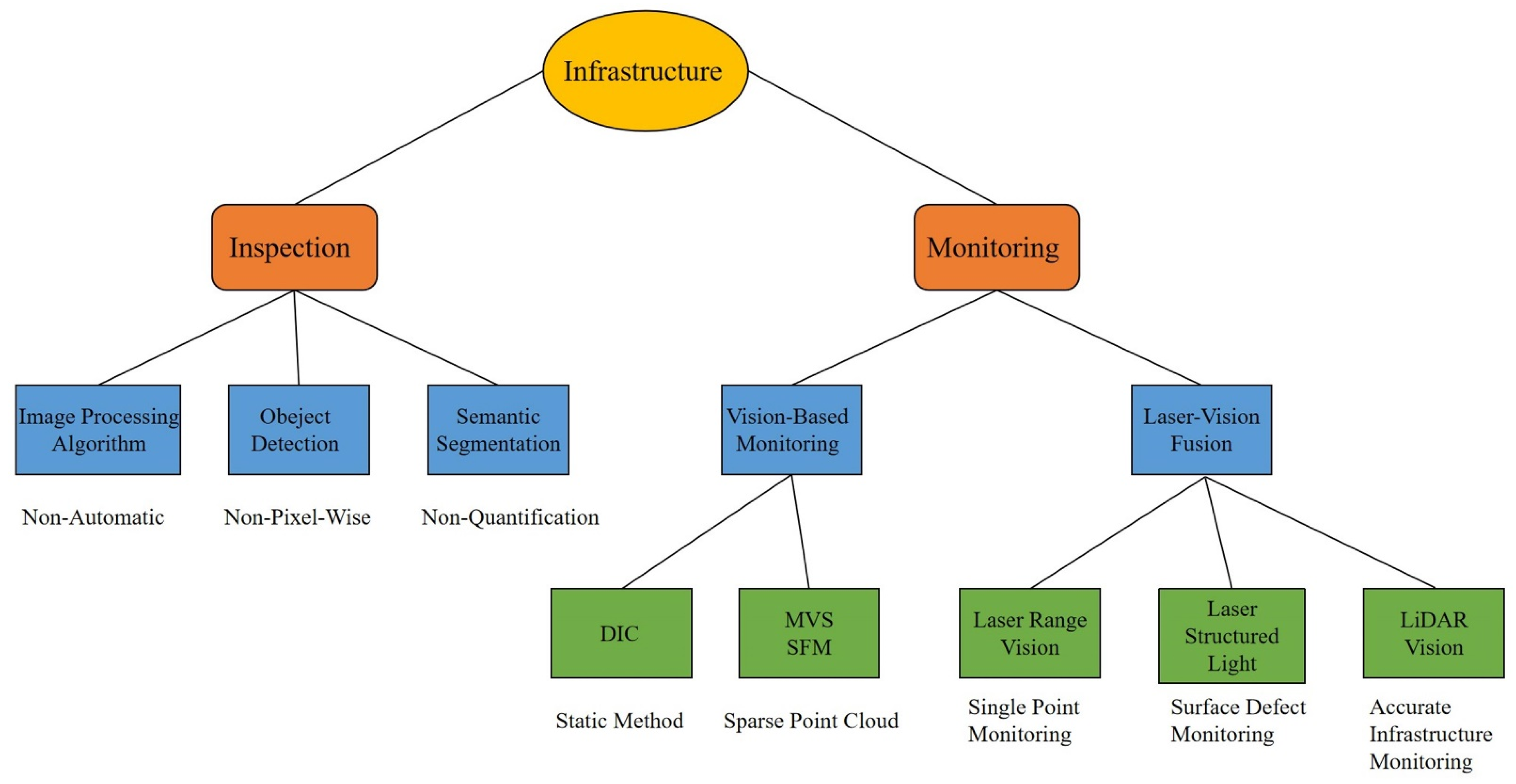
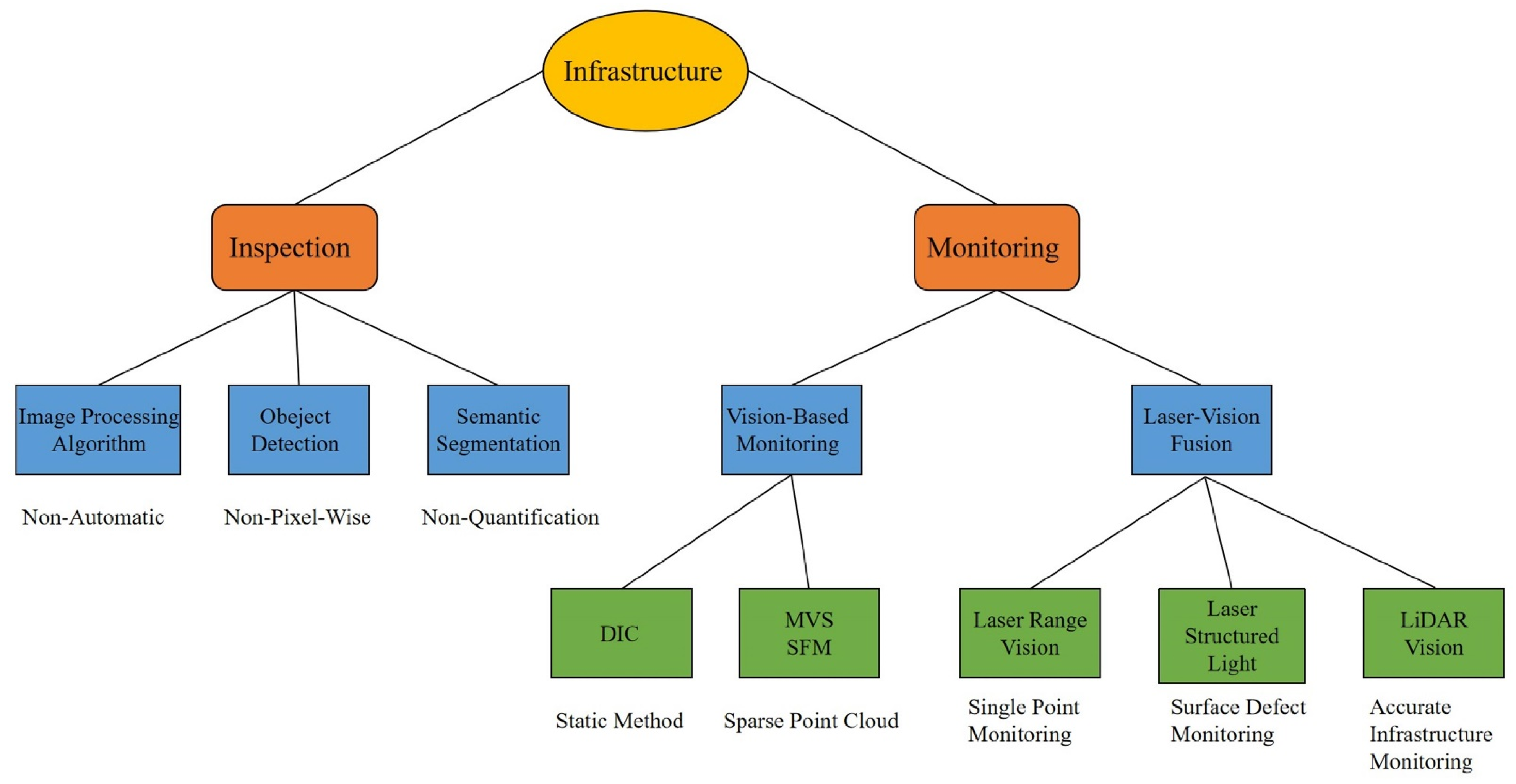
:1. Introduction
- Machine vision-based infrastructure inspection, especially semantic segmentation.
- Infrastructure monitoring and a quantitative understanding of the current state of the infrastructure.
- Vision–laser fusion technologies and their applications.
- The challenges and ongoing works toward automated non-contact infrastructure inspection and monitoring.
2. Vision-Based Infrastructure Inspection
2.1. Image Processing Algorithms
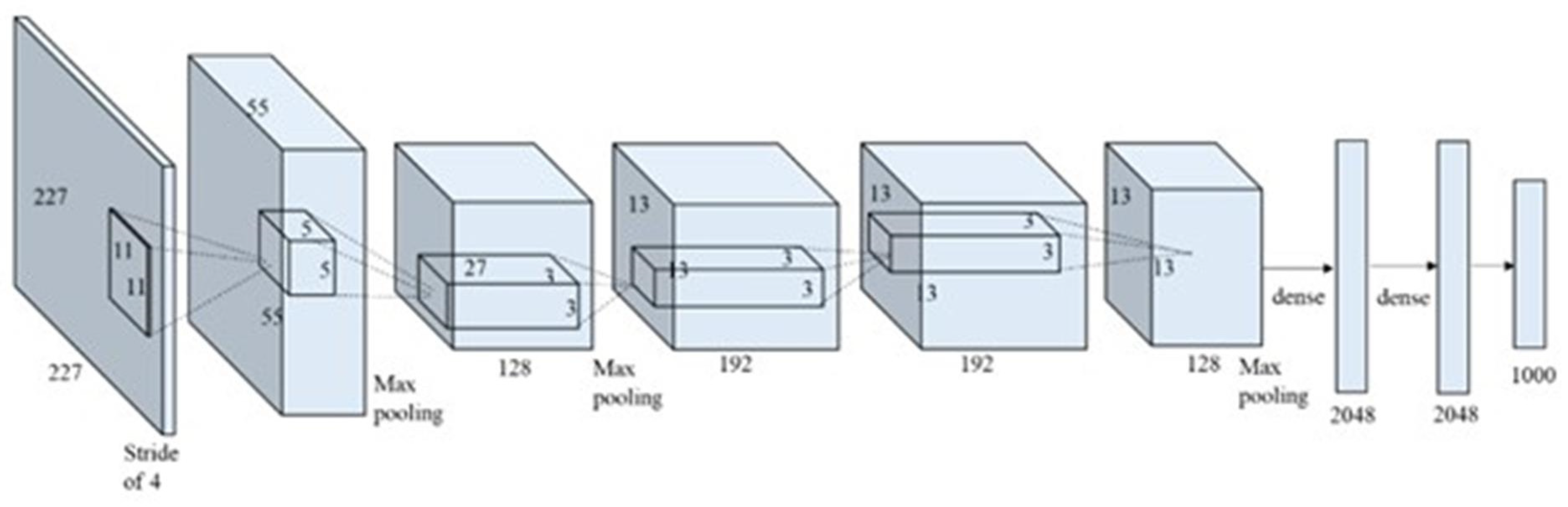
2.2. Object Detection
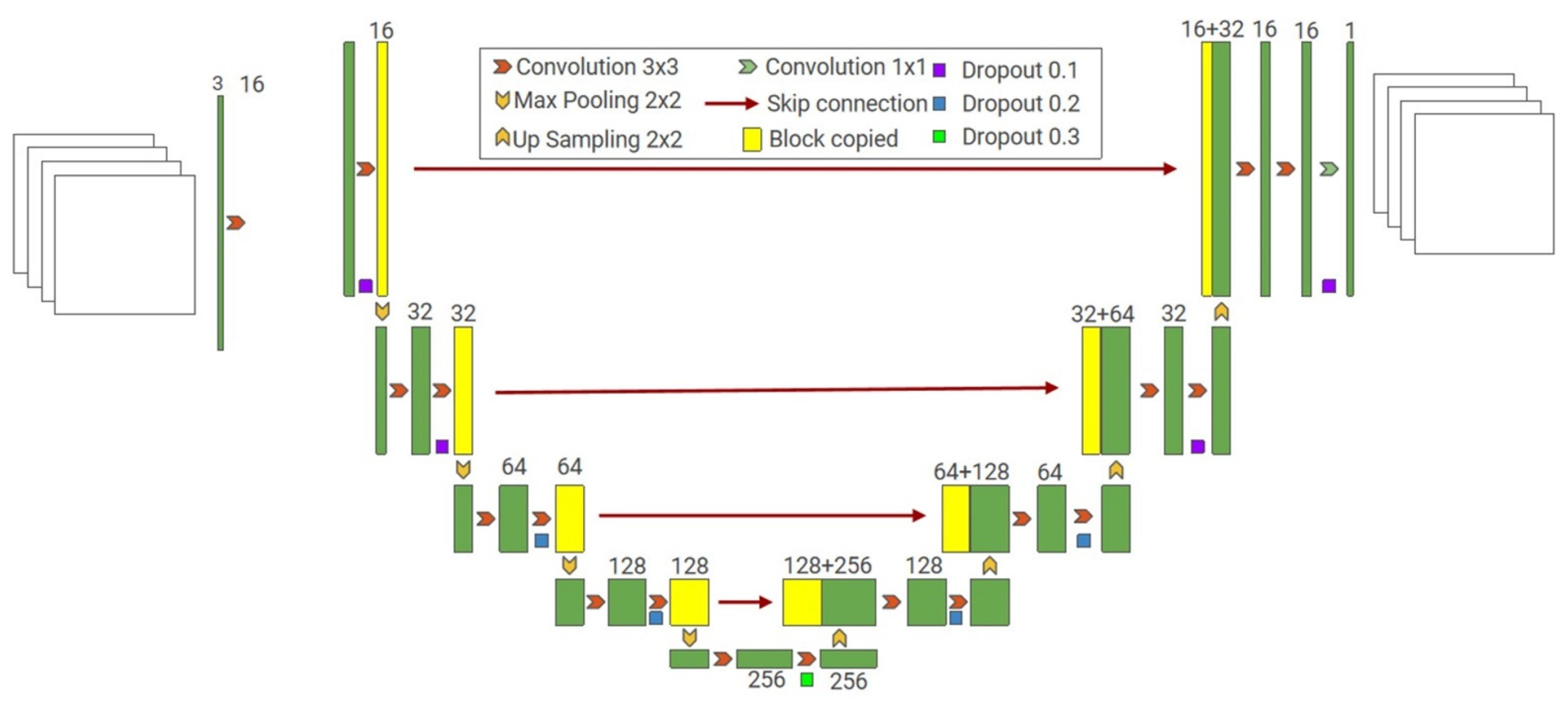
2.3. Semantic Segmentation
2.4. Summary
3. Vision–Laser-Based Infrastructure Monitoring
3.1. Vision-Based Monitoring
3.1.1. DIC
3.1.2. MVS and SFM
3.2. Laser–Vision Fusion
3.2.1. Laser Range Vision
3.2.2. Laser Structured Light
3.2.3. LiDAR Vision
4. Challenges of Non-Contact Monitoring
4.1. Model Training Requires Large Amounts of Data
4.2. Model Transferability
4.3. Noise Influence
4.4. Expensive Sensors
4.5. Decision-Making Problem
4.6. Sensor Fusion
5. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Flah, M.; Nunez, I.; Ben Chaabene, W.; Nehdi, M.L. Machine Learning Algorithms in Civil Structural Health Monitoring: A Systematic Review. Arch. Comput. Methods Eng. 2020, 28, 2621–2643. [Google Scholar] [CrossRef]
- Spencer, B.F.; Hoskere, V.; Narazaki, Y. Advances in Computer Vision-Based Civil Infrastructure Inspection and Monitoring. Engineering 2019, 5, 199–222. [Google Scholar] [CrossRef]
- Wang, H.; Jiang, L.; Xiang, P. Improving the durability of the optical fiber sensor based on strain transfer analysis. Opt. Fiber Technol. 2018, 42, 97–104. [Google Scholar] [CrossRef]
- Wang, H.; Jiang, L.; Xiang, P. Priority design parameters of industrialized optical fiber sensors in civil engineering. Opt. Laser Technol. 2018, 100, 119–128. [Google Scholar] [CrossRef]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3d object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2147–2156. [Google Scholar]
- Liu, Z.; Wu, Z.; Tóth, R. Smoke: Single-stage monocular 3d object detection via keypoint estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 996–997. [Google Scholar]
- Wang, L.; Du, L.; Ye, X.; Fu, Y.; Guo, G.; Xue, X.; Feng, J.; Zhang, L. Depth-conditioned dynamic message propagation for monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 454–463. [Google Scholar]
- Akyildiz, I.F.; Pompili, D.; Melodia, T. Underwater acoustic sensor networks: Research challenges. Ad Hoc Netw. 2005, 3, 257–279. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, Y.; Niu, Q. Multi-sensor fusion in automated driving: A survey. IEEE Access 2019, 8, 2847–2868. [Google Scholar] [CrossRef]
- Yoneda, K.; Yanase, R.; Aldibaja, M.; Suganuma, N.; Sato, K. Mono-camera based vehicle localization using lidar intensity map for automated driving. Artif. Life Robot. 2019, 24, 147–154. [Google Scholar] [CrossRef]
- Marti, E.; De Miguel, M.A.; Garcia, F.; Perez, J. A review of sensor technologies for perception in automated driving. IEEE Intell. Transp. Syst. Mag. 2019, 11, 94–108. [Google Scholar] [CrossRef] [Green Version]
- Haris, M.; Glowacz, A. Navigating an Automated Driving Vehicle via the Early Fusion of Multi-Modality. Sensors 2022, 22, 1425. [Google Scholar] [CrossRef] [PubMed]
- Wang, X. Intelligent multi-camera video surveillance: A review. Pattern Recognit. Lett. 2013, 34, 3–19. [Google Scholar] [CrossRef]
- He, Y.; Wei, X.; Hong, X.; Shi, W.; Gong, Y. Multi-target multi-camera tracking by tracklet-to-target assignment. IEEE Trans. Image Process. 2020, 29, 5191–5205. [Google Scholar] [CrossRef]
- Walser, B.H. Development and Calibration of an Image Assisted Total Station. Ph.D. Dissertation, ETH Zurich, Zürich, Switzerland, 2004. [Google Scholar]
- Zschiesche, K. Image Assisted Total Stations for Structural Health Monitoring—A Review. Geomatics 2021, 2, 1–16. [Google Scholar] [CrossRef]
- Wagner, A.A. New Geodetic Monitoring Approaches Using Image Assisted Total Stations. Ph.D. Dissertation, Technische Universität München, Munich, Germany, 2017. [Google Scholar]
- Schiano, F.; Natter, D.; Zambrano, D.; Floreano, D. Autonomous Detection and Deterrence of Pigeons on Buildings by Drones. IEEE Access 2021, 10, 1745–1755. [Google Scholar] [CrossRef]
- Samaras, S.; Diamantidou, E.; Ataloglou, D.; Sakellariou, N.; Vafeiadis, A.; Magoulianitis, V.; Lalas, A.; Dimou, A.; Zarpalas, D.; Votis, K.; et al. Deep Learning on Multi Sensor Data for Counter UAV Applications—A Systematic Review. Sensors 2019, 19, 4837. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kopsida, M.; Brilakis, I.; Vela, P.A. A review of automated construction progress monitoring and inspection methods. In Proceedings of the 32nd CIB W78 Conference, Eindhoven, The Netherlands, 27–29 October 2015; pp. 421–431. [Google Scholar]
- Ham, Y.; Han, K.K.; Lin, J.J.; Golparvar-Fard, M. Visual monitoring of civil infrastructure systems via camera-equipped Unmanned Aerial Vehicles (UAVs): A review of related works. Vis. Eng. 2016, 4, 1. [Google Scholar] [CrossRef] [Green Version]
- Yiyang, Z. The design of glass crack detection system based on image preprocessing technology. In Proceedings of the 2014 IEEE 7th Joint International Information Technology and Artificial Intelligence Conference, Chongqing, China, 20–21 December 2014; pp. 39–42. [Google Scholar]
- Salman, M.; Mathavan, S.; Kamal, K.; Rahman, M. Pavement crack detection using the Gabor filter. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), The Hague, The Netherlands, 6–9 October 2013; pp. 2039–2044. [Google Scholar]
- Li, L.; Sun, L.-J.; Tan, S.-G.; Ning, G.-B. An efficient way in image preprocessing for pavement crack images. In Proceedings of the CICTP 2012: Multimodal Transportation Systems—Convenient, Safe, Cost-Effective, Efficient, Beijing, China, 3–6 August 2012; pp. 3095–3103. [Google Scholar]
- Kim, H.; Ahn, E.; Cho, S.; Shin, M.; Sim, S.-H. Comparative analysis of image binarization methods for crack identification in concrete structures. Cem. Concr. Res. 2017, 99, 53–61. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Hashimoto, S. Fast crack detection method for large-size concrete surface images using percolation-based image processing. Mach. Vis. Appl. 2009, 21, 797–809. [Google Scholar] [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Yeum, C.M.; Dyke, S.J. Vision-Based Automated Crack Detection for Bridge Inspection. Comput.-Aided Civ. Infrastruct. Eng. 2015, 30, 759–770. [Google Scholar] [CrossRef]
- Zhu, Z.; German, S.; Brilakis, I. Visual retrieval of concrete crack properties for automated post-earthquake structural safety evaluation. Autom. Constr. 2011, 20, 874–883. [Google Scholar] [CrossRef]
- Nishikawa, T.; Yoshida, J.; Sugiyama, T.; Fujino, Y. Concrete Crack Detection by Multiple Sequential Image Filtering. Comput.-Aided Civ. Infrastruct. Eng. 2012, 27, 29–47. [Google Scholar] [CrossRef]
- Medeiros, F.N.S.; Ramalho, G.L.B.; Bento, M.P.; Medeiros, L.C.L. On the Evaluation of Texture and Color Features for Nondestructive Corrosion Detection. EURASIP J. Adv. Signal Process. 2010, 2010, 817473. [Google Scholar] [CrossRef] [Green Version]
- Jahanshahi, M.R.; Masri, S.F. Parametric Performance Evaluation of Wavelet-Based Corrosion Detection Algorithms for Condition Assessment of Civil Infrastructure Systems. J. Comput. Civ. Eng. 2013, 27, 345–357. [Google Scholar] [CrossRef]
- Shen, H.-K.; Chen, P.-H.; Chang, L.-M. Automated steel bridge coating rust defect recognition method based on color and texture feature. Autom. Constr. 2013, 31, 338–356. [Google Scholar] [CrossRef]
- Li, Q.; Ren, S. A Real-Time Visual Inspection System for Discrete Surface Defects of Rail Heads. IEEE Trans. Instrum. Meas. 2012, 61, 2189–2199. [Google Scholar] [CrossRef]
- Koch, C.; Brilakis, I. Pothole detection in asphalt pavement images. Adv. Eng. Inform. 2011, 25, 507–515. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Gibert, X.; Patel, V.M.; Chellappa, R. Robust Fastener Detection for Autonomous Visual Railway Track Inspection. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 694–701. [Google Scholar]
- Feng, H.; Jiang, Z.; Xie, F.; Yang, P.; Shi, J.; Chen, L. Automatic Fastener Classification and Defect Detection in Vision-Based Railway Inspection Systems. IEEE Trans. Instrum. Meas. 2014, 63, 877–888. [Google Scholar] [CrossRef]
- Inkoom, S.; Sobanjo, J.; Barbu, A.; Niu, X. Pavement Crack Rating Using Machine Learning Frameworks: Partitioning, Bootstrap Forest, Boosted Trees, Naïve Bayes, and K-Nearest Neighbors. J. Transp. Eng. Part B Pavements 2019, 145, 4019031. [Google Scholar] [CrossRef]
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A learning algorithm for Boltzmann machines. Cogn. Sci. 1985, 9, 147–169. [Google Scholar] [CrossRef]
- Xu, Y.; Li, S.; Zhang, D.; Jin, Y.; Zhang, F.; Li, N.; Li, H. Identification framework for cracks on a steel structure surface by a restricted Boltzmann machines algorithm based on consumer-grade camera images. Struct. Control Health Monit. 2018, 25, e2075. [Google Scholar] [CrossRef]
- Bao, Y.; Tang, Z.; Li, H.; Zhang, Y. Computer vision and deep learning–based data anomaly detection method for structural health monitoring. Struct. Health Monit. 2018, 18, 401–421. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Cha, Y.-J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Yeum, C.M.; Dyke, S.J.; Ramirez, J. Visual data classification in post-event building reconnaissance. Eng. Struct. 2018, 155, 16–24. [Google Scholar] [CrossRef]
- Kim, H.; Ahn, E.; Shin, M.; Sim, S.-H. Crack and Noncrack Classification from Concrete Surface Images Using Machine Learning. Struct. Health Monit. 2018, 18, 725–738. [Google Scholar] [CrossRef]
- Chen, F.-C.; Jahanshahi, M.R. NB-CNN: Deep Learning-Based Crack Detection Using Convolutional Neural Network and Naïve Bayes Data Fusion. IEEE Trans. Ind. Electron. 2018, 65, 4392–4400. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Ali, L.; Harous, S.; Zaki, N.; Khan, W.; Alnajjar, F.; Jassmi, H.A. Performance Evaluation of different Algorithms for Crack Detection in Concrete Structures. In Proceedings of the 2021 2nd International Conference on Computation, Automation and Knowledge Management (ICCAKM), Dubai, United Arab Emirates, 19–21 January 2021; pp. 53–58. [Google Scholar]
- Kim, B.; Cho, S. Automated Vision-Based Detection of Cracks on Concrete Surfaces Using a Deep Learning Technique. Sensors 2018, 18, 3452. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Atha, D.J.; Jahanshahi, M.R. Evaluation of deep learning approaches based on convolutional neural networks for corrosion detection. Struct. Health Monit. 2017, 17, 1110–1128. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Hoskere, V.; Narazaki, Y.; Hoang, T.; Spencer, B., Jr. Vision-based structural inspection using multiscale deep convolutional neural networks. arXiv 2018, arXiv:1805.01055. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Hoskere, V.; Narazaki, Y.; Hoang, T.A.; Spencer, B.F., Jr. Towards automated post-earthquake inspections with deep learning-based condition-aware models. arXiv 2018, arXiv:1809.09195. [Google Scholar]
- Giben, X.; Patel, V.M.; Chellappa, R. Material classification and semantic segmentation of railway track images with deep convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 621–625. [Google Scholar]
- Islam, M.M.M.; Kim, J.M. Vision-Based Autonomous Crack Detection of Concrete Structures Using a Fully Convolutional Encoder-Decoder Network. Sensors 2019, 19, 4251. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liang, X. Image-based post-disaster inspection of reinforced concrete bridge systems using deep learning with Bayesian optimization. Comput.-Aided Civ. Infrastruct. Eng. 2018, 34, 415–430. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Enshaei, N.; Ahmad, S.; Naderkhani, F. Automated detection of textured-surface defects using UNet-based semantic segmentation network. In Proceedings of the 2020 IEEE International Conference on Prognostics and Health Management (ICPHM), Detroit, MI, USA, 8–10 June 2020; pp. 1–5. [Google Scholar]
- Pan, G.; Zheng, Y.; Guo, S.; Lv, Y. Automatic sewer pipe defect semantic segmentation based on improved U-Net. Autom. Constr. 2020, 119, 103383. [Google Scholar] [CrossRef]
- Wei, C.; Li, S.; Wu, K.; Zhang, Z.; Wang, Y. Damage inspection for road markings based on images with hierarchical semantic segmentation strategy and dynamic homography estimation. Autom. Constr. 2021, 131, 103876. [Google Scholar] [CrossRef]
- Yang, L.; Li, B.; Li, W.; Jiang, B.; Xiao, J. Semantic metric 3d reconstruction for concrete inspection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1543–1551. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhang, X.; Rajan, D.; Story, B. Concrete crack detection using context-aware deep semantic segmentation network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 951–971. [Google Scholar] [CrossRef]
- Wang, W.; Su, C. Semi-supervised semantic segmentation network for surface crack detection. Autom. Constr. 2021, 128, 103786. [Google Scholar] [CrossRef]
- Sutton, M.A.; Orteu, J.J.; Schreier, H. Image Correlation for Shape, Motion and Deformation Measurements: Basic Concepts, Theory and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Hoult, N.A.; Andy Take, W.; Lee, C.; Dutton, M. Experimental accuracy of two dimensional strain measurements using Digital Image Correlation. Eng. Struct. 2013, 46, 718–726. [Google Scholar] [CrossRef]
- Dutton, M.; Take, W.A.; Hoult, N.A. Curvature Monitoring of Beams Using Digital Image Correlation. J. Bridge Eng. 2014, 19, 5013001. [Google Scholar] [CrossRef] [Green Version]
- Mahal, M.; Blanksvärd, T.; Täljsten, B.; Sas, G. Using digital image correlation to evaluate fatigue behavior of strengthened reinforced concrete beams. Eng. Struct. 2015, 105, 277–288. [Google Scholar] [CrossRef]
- Yoneyama, S.; Kitagawa, A.; Iwata, S.; Tani, K.; Kikuta, H. Bridge deflection measurement using digital image correlation. Exp. Tech. 2007, 31, 34–40. [Google Scholar] [CrossRef]
- Chen, F.; Chen, X.; Xie, X.; Feng, X.; Yang, L. Full-field 3D measurement using multi-camera digital image correlation system. Opt. Lasers Eng. 2013, 51, 1044–1052. [Google Scholar] [CrossRef]
- Helfrick, M.N.; Niezrecki, C.; Avitabile, P.; Schmidt, T. 3D digital image correlation methods for full-field vibration measurement. Mech. Syst. Signal Process. 2011, 25, 917–927. [Google Scholar] [CrossRef]
- Ghorbani, R.; Matta, F.; Sutton, M.A. Full-Field Deformation Measurement and Crack Mapping on Confined Masonry Walls Using Digital Image Correlation. Exp. Mech. 2014, 55, 227–243. [Google Scholar] [CrossRef]
- Wang, N.; Ri, K.; Liu, H.; Zhao, X. Structural Displacement Monitoring Using Smartphone Camera and Digital Image Correlation. IEEE Sens. J. 2018, 18, 4664–4672. [Google Scholar] [CrossRef]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zeinali, Y.; Story, B.A.; Rajan, D. Measurement of three-dimensional structural displacement using a hybrid inertial vision-based system. Sensors 2019, 19, 4083. [Google Scholar] [CrossRef] [Green Version]
- Del Sal, R.; Dal Bo, L.; Turco, E.; Fusiello, A.; Zanarini, A.; Rinaldo, R.; Gardonio, P. Structural vibration measurement with multiple synchronous cameras. Mech. Syst. Signal Process. 2021, 157, 107742. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Shan, B.; Zheng, S.; Ou, J. A stereovision-based crack width detection approach for concrete surface assessment. KSCE J. Civ. Eng. 2015, 20, 803–812. [Google Scholar] [CrossRef]
- Liu, Y.-F.; Cho, S.; Spencer, B.F.; Fan, J.-S. Concrete Crack Assessment Using Digital Image Processing and 3D Scene Reconstruction. J. Comput. Civ. Eng. 2016, 30, 04014124. [Google Scholar] [CrossRef]
- Jahanshahi, M.R.; Masri, S.F.; Padgett, C.W.; Sukhatme, G.S. An innovative methodology for detection and quantification of cracks through incorporation of depth perception. Mach. Vis. Appl. 2011, 24, 227–241. [Google Scholar] [CrossRef]
- Torok, M.M.; Golparvar-Fard, M.; Kochersberger, K.B. Image-Based Automated 3D Crack Detection for Post-disaster Building Assessment. J. Comput. Civ. Eng. 2014, 28, A4014004. [Google Scholar] [CrossRef]
- Parente, L.; Chandler, J.H.; Dixon, N. Optimising the quality of an SfM-MVS slope monitoring system using fixed cameras. Photogramm. Rec. 2019, 34, 408–427. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.V. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Ozcan, B.; Schwermann, R.; Blankenbach, J. A Novel Camera-Based Measurement System for Roughness Determination of Concrete Surfaces. Materials 2020, 14, 158. [Google Scholar] [CrossRef] [PubMed]
- Golparvar-Fard, M.; Bohn, J.; Teizer, J.; Savarese, S.; Peña-Mora, F. Evaluation of image-based modeling and laser scanning accuracy for emerging automated performance monitoring techniques. Autom. Constr. 2011, 20, 1143–1155. [Google Scholar] [CrossRef]
- Mistretta, F.; Sanna, G.; Stochino, F.; Vacca, G. Structure from Motion Point Clouds for Structural Monitoring. Remote Sens. 2019, 11, 1940. [Google Scholar] [CrossRef] [Green Version]
- Khaloo, A.; Lattanzi, D.; Cunningham, K.; Dell’Andrea, R.; Riley, M. Unmanned aerial vehicle inspection of the Placer River Trail Bridge through image-based 3D modelling. Struct. Infrastruct. Eng. 2017, 14, 124–136. [Google Scholar] [CrossRef]
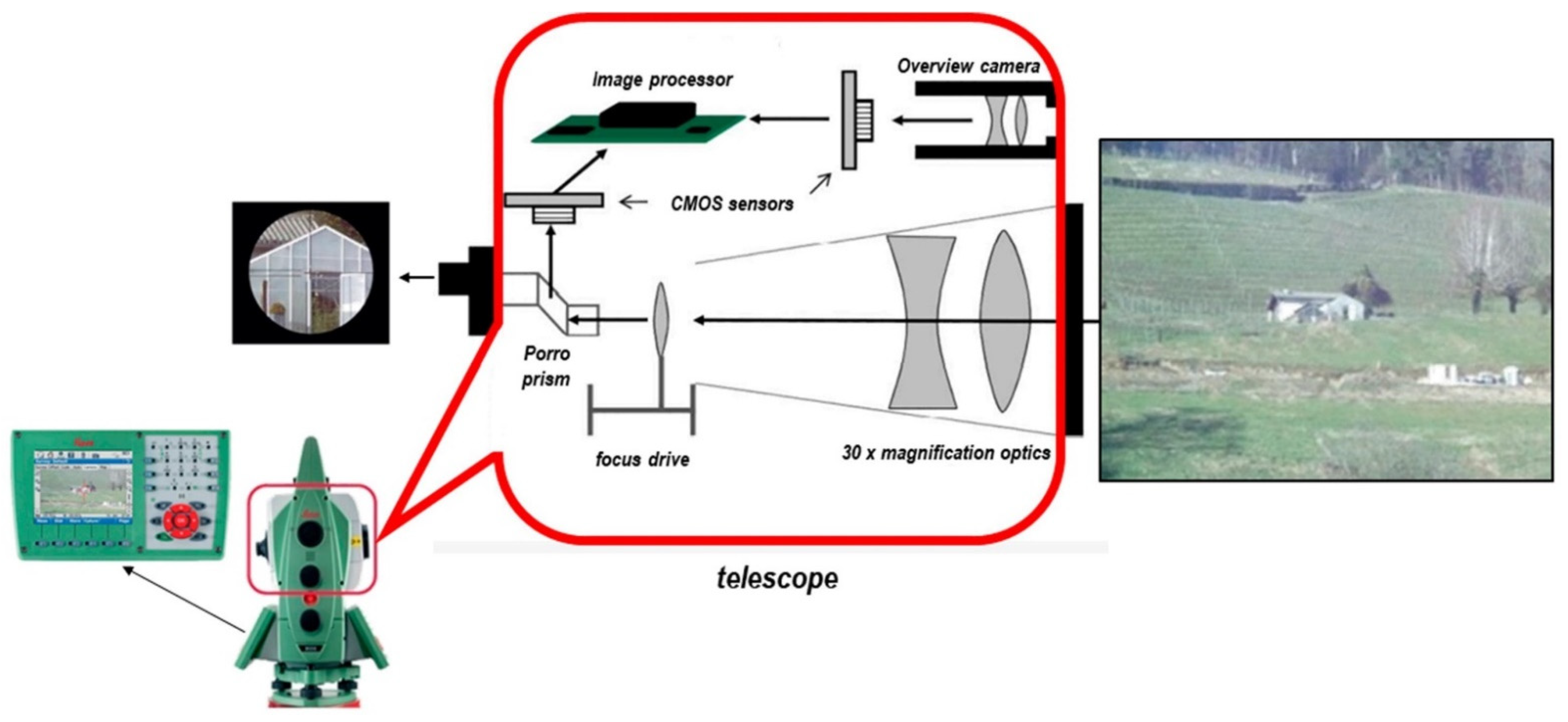
- Sakimura, R.; Maruyama, K. Development of a new generation imaging total station system. J. Surv. Eng. 2007, 133, 14–22. [Google Scholar] [CrossRef]
- Paar, R.; Roić, M.; Marendić, A.; Miletić, S. Technological development and application of photo and video theodolites. Appl. Sci. 2021, 11, 3893. [Google Scholar] [CrossRef]
- Wagner, A.; Wasmeier, P.; Reith, C.; Wunderlich, T. Bridge monitoring by means of video-tacheometer—A case study. Avn-Allg. Vermess.-Nachr. 2013, 120, 283–292. [Google Scholar]
- Wagner, A.; Huber, B.; Wiedemann, W.; Paar, G. Long-range geo-monitoring using image assisted total stations. J. Appl. Geod. 2014, 8, 223–234. [Google Scholar] [CrossRef]
- Wagner, A. A new approach for geo-monitoring using modern total stations and RGB+ D images. Measurement 2016, 82, 64–74. [Google Scholar] [CrossRef] [Green Version]
- Vasileva, A.V.; Vasilev, A.S.; Konyakhin, I.A. Vision-based system for long-term remote monitoring of large civil engineering structures: Design, testing, evaluation. Meas. Sci. Technol. 2018, 29, 115003. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Z.; Qi, D.; Liu, Y. Automatic crack detection and classification method for subway tunnel safety monitoring. Sensors 2014, 14, 19307–19328. [Google Scholar] [CrossRef]
- Myung, H.; Lee, S.; Lee, B. Paired structured light for structural health monitoring robot system. Struct. Health Monit. 2011, 10, 49–64. [Google Scholar] [CrossRef]
- Ding, S.; Wang, K.C.P.; Yang, E.; Zhan, Y. Influence of effective texture depth on pavement friction based on 3D texture area. Constr. Build. Mater. 2021, 287, 123002. [Google Scholar] [CrossRef]
- Arezoumand, S.; Mahmoudzadeh, A.; Golroo, A.; Mojaradi, B. Automatic pavement rutting measurement by fusing a high speed-shot camera and a linear laser. Constr. Build. Mater. 2021, 283, 122668. [Google Scholar] [CrossRef]
- Vilaça, J.L.; Fonseca, J.C.; Pinho, A.C.M.; Freitas, E. 3D surface profile equipment for the characterization of the pavement texture—TexScan. Mechatronics 2010, 20, 674–685. [Google Scholar] [CrossRef] [Green Version]
- Zhan, D.; Yu, L.; Xiao, J.; Chen, T. Multi-camera and structured-light vision system (MSVS) for dynamic high-accuracy 3D measurements of railway tunnels. Sensors 2015, 15, 8664–8684. [Google Scholar] [CrossRef] [PubMed]
- Fernald, F.G. Analysis of atmospheric lidar observations: Some comments. Appl. Opt. 1984, 23, 652–653. [Google Scholar] [CrossRef] [PubMed]
- Wulder, M.A.; Bater, C.W.; Coops, N.C.; Hilker, T.; White, J.C. The role of LiDAR in sustainable forest management. For. Chron. 2008, 84, 807–826. [Google Scholar] [CrossRef] [Green Version]
- Jaboyedoff, M.; Oppikofer, T.; Abellán, A.; Derron, M.-H.; Loye, A.; Metzger, R.; Pedrazzini, A. Use of LIDAR in landslide investigations: A review. Nat. Hazards 2012, 61, 5–28. [Google Scholar] [CrossRef] [Green Version]
- Deems, J.S.; Painter, T.H.; Finnegan, D.C. Lidar measurement of snow depth: A review. J. Glaciol. 2013, 59, 467–479. [Google Scholar] [CrossRef] [Green Version]
- Soilán, M.; Sánchez-Rodríguez, A.; del Río-Barral, P.; Perez-Collazo, C.; Arias, P.; Riveiro, B. Review of Laser Scanning Technologies and Their Applications for Road and Railway Infrastructure Monitoring. Infrastructures 2019, 4, 58. [Google Scholar] [CrossRef] [Green Version]
- Debeunne, C.; Vivet, D. A Review of Visual-LiDAR Fusion based Simultaneous Localization and Mapping. Sensors 2020, 20, 2068. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Unnikrishnan, R.; Hebert, M. Fast extrinsic calibration of a laser rangefinder to a camera. Robot. Inst. Pittsburgh PA Tech. Rep. CMU-RI-TR-05-09. July 2005. Available online: https://www.ri.cmu.edu/publications/fast-extrinsic-calibration-of-a-laser-rangefinder-to-a-camera/ (accessed on 5 July 2022).
- Kassir, A.; Peynot, T. Reliable automatic camera-laser calibration. In Proceedings of the 2010 Australasian Conference on Robotics & Automation, Brisbane, Australia, 1–3 December 2010; pp. 1–10. [Google Scholar]
- Park, K.; Kim, S.; Sohn, K. High-precision depth estimation using uncalibrated LiDAR and stereo fusion. IEEE Trans. Intell. Transp. Syst. 2019, 21, 321–335. [Google Scholar] [CrossRef]
- Pusztai, Z.; Eichhardt, I.; Hajder, L. Accurate Calibration of Multi-LiDAR-Multi-Camera Systems. Sensors 2018, 18, 2139. [Google Scholar] [CrossRef] [Green Version]
- Omidalizarandi, M.; Kargoll, B.; Paffenholz, J.-A.; Neumann, I. Robust external calibration of terrestrial laser scanner and digital camera for structural monitoring. J. Appl. Geod. 2019, 13, 105–134. [Google Scholar] [CrossRef]
- Valença, J.; Puente, I.; Júlio, E.; González-Jorge, H.; Arias-Sánchez, P. Assessment of cracks on concrete bridges using image processing supported by laser scanning survey. Constr. Build. Mater. 2017, 146, 668–678. [Google Scholar] [CrossRef]
- Rabah, M.; Elhattab, A.; Fayad, A. Automatic concrete cracks detection and mapping of terrestrial laser scan data. NRIAG J. Astron. Geophys. 2019, 2, 250–255. [Google Scholar] [CrossRef] [Green Version]
- Kang, B.-H.; Choi, S.-I. Pothole detection system using 2D LiDAR and camera. In Proceedings of the 2017 Ninth International Conference on Ubiquitous and Future Networks (ICUFN), Milan, Italy, 4–7 July 2017; pp. 744–746. [Google Scholar]
- Wu, H.; Yao, L.; Xu, Z.; Li, Y.; Ao, X.; Chen, Q.; Li, Z.; Meng, B. Road pothole extraction and safety evaluation by integration of point cloud and images derived from mobile mapping sensors. Adv. Eng. Inform. 2019, 42, 100936. [Google Scholar] [CrossRef]
- Kashani, A.G.; Graettinger, A.J. Cluster-Based Roof Covering Damage Detection in Ground-Based Lidar Data. Autom. Constr. 2015, 58, 19–27. [Google Scholar] [CrossRef]
- Guldur Erkal, B.; Hajjar, J.F. Laser-based surface damage detection and quantification using predicted surface properties. Autom. Constr. 2017, 83, 285–302. [Google Scholar] [CrossRef]
- Zhangyu, W.; Guizhen, Y.; Xinkai, W.; Haoran, L.; Da, L. A Camera and LiDAR Data Fusion Method for Railway Object Detection. IEEE Sens. J. 2021, 21, 13442–13454. [Google Scholar] [CrossRef]
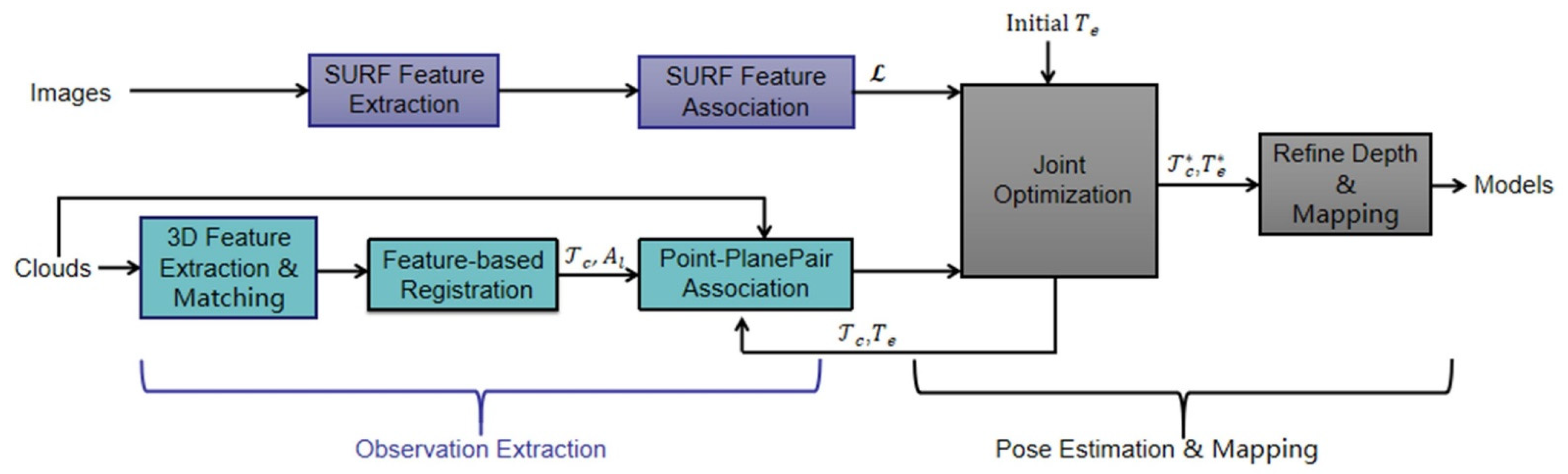
- Zhen, W.; Hu, Y.; Liu, J.; Scherer, S. A Joint Optimization Approach of LiDAR-Camera Fusion for Accurate Dense 3-D Reconstructions. IEEE Robot. Autom. Lett. 2019, 4, 3585–3592. [Google Scholar] [CrossRef] [Green Version]
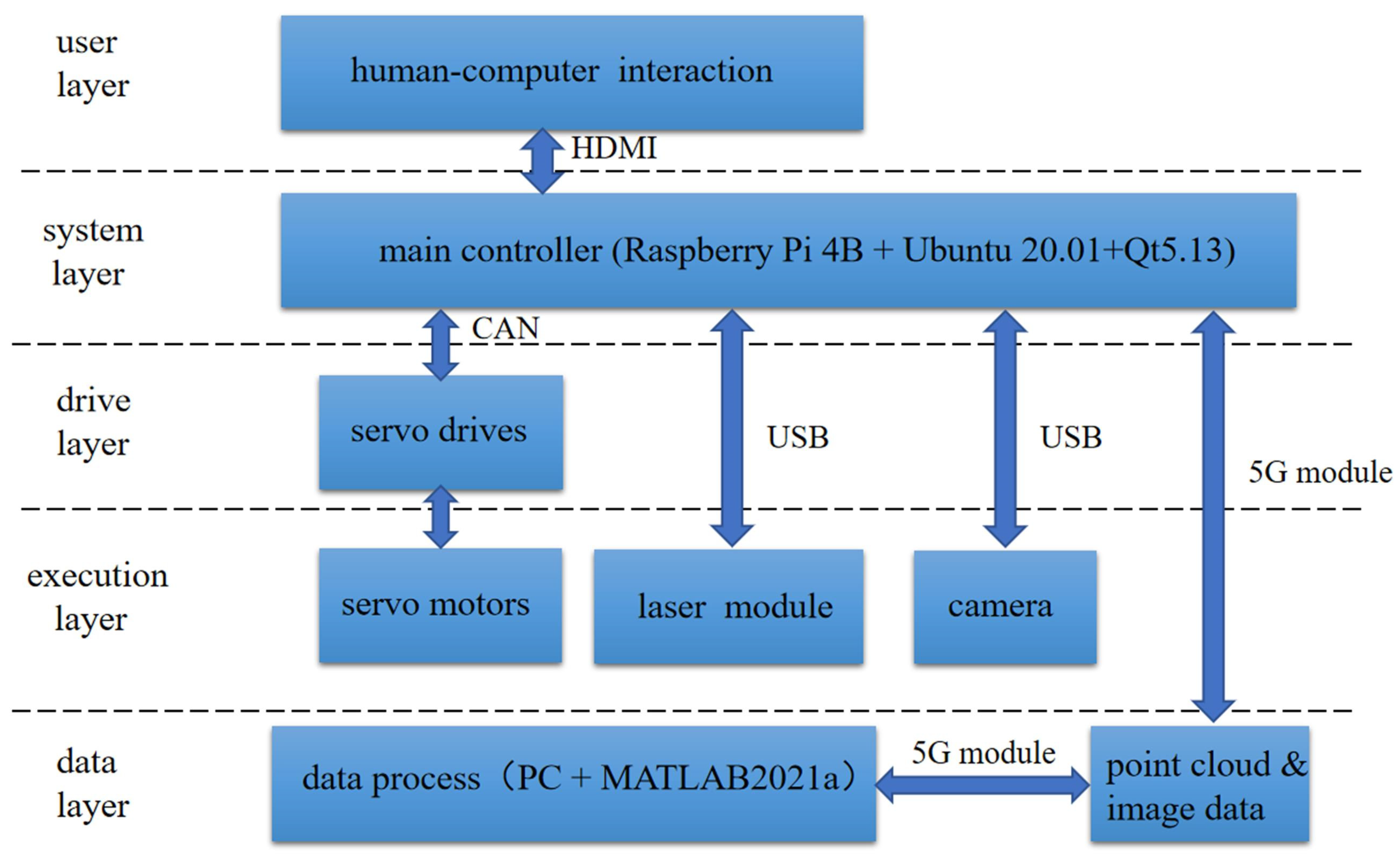
- Jung, S.; Song, S.; Kim, S.; Park, J.; Her, J.; Roh, K.; Myung, H. Toward Autonomous Bridge Inspection: A framework and experimental results. In Proceedings of the 2019 16th International Conference on Ubiquitous Robots (UR), Jeju, Korea, 24–27 June 2019; pp. 208–211. [Google Scholar]
- Yan, Y.; Mao, Z.; Wu, J.; Padir, T.; Hajjar, J.F. Towards automated detection and quantification of concrete cracks using integrated images and lidar data from unmanned aerial vehicles. Struct. Control Health Monit. 2021, 28, e2757. [Google Scholar] [CrossRef]
- Özaslan, T.; Mohta, K.; Keller, J.; Mulgaonkar, Y.; Taylor, C.J.; Kumar, V.; Wozencraft, J.M.; Hood, T. Towards fully autonomous visual inspection of dark featureless dam penstocks using MAVs. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4998–5005. [Google Scholar]
- Li, M.; Cheng, L.; Gong, J.; Liu, Y.; Chen, Z.; Li, F.; Chen, G.; Chen, D.; Song, X. Post-earthquake assessment of building damage degree using LiDAR data and imagery. Sci. China Ser. E Technol. Sci. 2008, 51, 133–143. [Google Scholar] [CrossRef]
- Hirose, M.; Xiao, Y.; Zuo, Z.; Kamat, V.R.; Zekkos, D.; Lynch, J. Implementation of UAV localization methods for a mobile post-earthquake monitoring system. In Proceedings of the 2015 IEEE Workshop on Environmental, Energy, and Structural Monitoring Systems (EESMS), Trento, Italy, 9–10 July 2015; pp. 66–71. [Google Scholar]
- Murtiyoso, A.; Grussenmeyer, P.; Suwardhi, D.; Awalludin, R. Multi-Scale and Multi-Sensor 3D Documentation of Heritage Complexes in Urban Areas. ISPRS Int. J. Geo-Inf. 2018, 7, 483. [Google Scholar] [CrossRef] [Green Version]
- Bertinetto, L.; Henriques, J.F.; Valmadre, J.; Torr, P.; Vedaldi, A. Learning feed-forward one-shot learners. Adv. Neural Inf. Process. Syst. 2016, 29, 523–531. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Fink, M. Object classification from a single example utilizing class relevance metrics. Adv. Neural Inf. Process. Syst. 2004, 17, 449–456. [Google Scholar]
- Kim, J.; Chi, S. A few-shot learning approach for database-free vision-based monitoring on construction sites. Autom. Constr. 2021, 124, 103566. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. 2014, 27, 3320–3328. [Google Scholar] [CrossRef]
- Yang, Q.; Shi, W.; Chen, J.; Lin, W. Deep convolution neural network-based transfer learning method for civil infrastructure crack detection. Autom. Constr. 2020, 116, 103199. [Google Scholar] [CrossRef]
- Aliyari, M.; Droguett, E.L.; Ayele, Y.Z. UAV-Based Bridge Inspection via Transfer Learning. Sustainability 2021, 13, 11359. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Yan, W.; Tan, R.T.; Yang, W.; Dai, D. Self-Aligned Video Deraining with Transmission-Depth Consistency. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11966–11976. [Google Scholar]
- Jianyong, B.; Runfeng, Y.; Yang, Y. A novel vehicle’s shadow detection and removal algorithm. In Proceedings of the 2012 2nd International Conference on Consumer Electronics, Communications and Networks (CECNet), Yichang, China, 21–23 April 2012; pp. 822–826. [Google Scholar]
- Finlayson, G.D.; Drew, M.S.; Lu, C. Entropy minimization for shadow removal. Int. J. Comput. Vis. 2009, 85, 35–57. [Google Scholar] [CrossRef] [Green Version]
- Lydon, D.; Lydon, M.; Taylor, S.; Del Rincon, J.M.; Hester, D.; Brownjohn, J. Development and field testing of a vision-based displacement system using a low cost wireless action camera. Mech. Syst. Signal Process. 2019, 121, 343–358. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, V.N.; Drews, P.L.J.; Gomes, S.C.P.; Cunha, M.A.B.; Botelho, S.S.D.C. Automatic control of a ROV for inspection of underwater structures using a low-cost sensing. J. Braz. Soc. Mech. Sci. Eng. 2015, 37, 361–374. [Google Scholar] [CrossRef]
- Lei, B.; Ren, Y.; Wang, N.; Huo, L.; Song, G. Design of a new low-cost unmanned aerial vehicle and vision-based concrete crack inspection method. Struct. Health Monit. 2020, 19, 1871–1883. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhou, H.; Wang, S.; Xu, C.; Lv, Y.; Han, J. Design and Research of Low-Cost and Self-Adaptive Terrestrial Laser Scanning for Indoor Measurement Based on Adaptive Indoor Measurement Scanning Strategy and Structural Characteristics Point Cloud Segmentation. Adv. Civ. Eng. 2022, 2022, 5681771. [Google Scholar] [CrossRef]
- Hamdi, A.; Giancola, S.; Ghanem, B. Mvtn: Multi-view transformation network for 3d shape recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1–11. [Google Scholar]
- Giordano, J.; Lazzaretto, M.; Michieletto, G.; Cenedese, A. Visual Sensor Networks for Indoor Real-Time Surveillance and Tracking of Multiple Targets. Sensors 2022, 22, 2661. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.-K.; Kim, K.-S.; Kim, S. A portable and remote 6-DOF pose sensor system with a long measurement range based on 1-D laser sensors. IEEE Trans. Ind. Electron. 2015, 62, 5722–5729. [Google Scholar] [CrossRef]
- Bai, X.; Hu, Z.; Zhu, X.; Huang, Q.; Chen, Y.; Fu, H.; Tai, C.-L. Transfusion: Robust lidar-camera fusion for 3d object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 1090–1099. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Defects Types | Ref. | Advantages |
|---|---|---|
| Crack | [22,23] | Detecting multi-scale cracks |
| [25] | Comparing different binarization methods | |
| [24,26] | Threshold select, fast detection | |
| [27,28] | Remove noise (fog, rain, and shadow) | |
| [29,30] | Crack quantification | |
| Corrosion | [31,32,33] | Fast color feature processing regardless of noise and illumination |
| Others | [34] | Railway defects detection |
| [35] | Pavement pits detection |
| Algorithms | Ref. | Results | |
|---|---|---|---|
| Non Neural Network | SVM | [37] | Nine classes of the fastener, 98% |
| Comparing Algorithms | [38] | STM fastener defects detection, 99.4% | |
| [39] | pavement crack, KNN > boosted tree > Recursive partitioning > bootstrap forest > linear regression > naive Bayes | ||
| Neural Network | Shallow NN | [40,41] | Boltzmann crack identification, 90.95% |
| Deep NN | [42] | Deep NN process time-domain signal, 87% | |
| [47,48] | CNN-based defects detection, 98% | ||
| [53,54] | Different size sliding window combination | ||
| [55] | Faster RCNN detects different defects | ||
| Comparing Algorithms | [49,50,51,52] | Comparing CNN, SURF-based, NB-CNN, LBP-SVM, SVM, boosting, logistic regression, random forest, KNN |
| Semantic Segmentation Network | Ref. | Advantages |
|---|---|---|
| CNN-based | [56] | CNN with ResNet23 and VGG19_reduced |
| [60] | VGGNet with decoder | |
| FCN | [57,58] | FCN, deconvolution up-sample |
| [59,61] | end-to-end semantic segmentation | |
| U-Net | [63,64] | Textured-surface defects |
| [61] | U-Net with Faster RCNN | |
| [66] | 3D semantic segmentation | |
| [69] | Semi-supervised segmentation, 83.21% | |
| Seg-net | [68] | Coordinate pooling |
| Measurement Algorithms | Ref. | Measurement Types | Disadvantages |
|---|---|---|---|
| DIC | [71,72,73,74] | 2D-DIC | Strict experimental layout and measurement environment |
| [75,76,77,78] | 3D-DIC | ||
| MVS | [81] | Using landmarks | Landmarks disposal |
| [82,83] | SIFT-based measurement | Not accurate | |
| SFM | [84,85,86,87] | SIFT-based 3D reconstruction | Time-consuming |
| [88,89] | SURF-based monitoring | Not accurate | |
| [90,91,92] | Comparing SFM and Laser scanner | Laser scanner more accurate but time-consuming |
| Fusion Methods | Ref. | Monitoring Types |
|---|---|---|
| Vision Range Laser | [95,96,97] | Total station-based deformation measurement |
| [98] | Low-temperature environment deformation monitoring | |
| [99] | Railway crack detection | |
| Structured Light Vision | [100] | Point laser structured light |
| [101,102,103] | Texture surface monitoring | |
| [104] | Railway tunnels monitoring | |
| LiDAR Vision | [111,112,113,114] | LiDAR camera calibration |
| [115] | Infrastructure deformation | |
| [116,117] | Crack monitoring | |
| [118,119] | Pavement pit monitoring | |
| [120,121] | Surface defects monitoring with color information | |
| [122] | Subway obstacles and vehicles | |
| [123] | Large structures monitoring | |
| [124,125,126] | UAV with LiDAR and cameras | |
| [127,128,129] | Post-earthquake and urban area monitoring |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, H.; Xu, C.; Tang, X.; Wang, S.; Zhang, Z. A Review of Vision-Laser-Based Civil Infrastructure Inspection and Monitoring. Sensors 2022, 22, 5882. https://doi.org/10.3390/s22155882
Zhou H, Xu C, Tang X, Wang S, Zhang Z. A Review of Vision-Laser-Based Civil Infrastructure Inspection and Monitoring. Sensors. 2022; 22(15):5882. https://doi.org/10.3390/s22155882
Chicago/Turabian StyleZhou, Huixing, Chongwen Xu, Xiuying Tang, Shun Wang, and Zhongyue Zhang. 2022. "A Review of Vision-Laser-Based Civil Infrastructure Inspection and Monitoring" Sensors 22, no. 15: 5882. https://doi.org/10.3390/s22155882
APA StyleZhou, H., Xu, C., Tang, X., Wang, S., & Zhang, Z. (2022). A Review of Vision-Laser-Based Civil Infrastructure Inspection and Monitoring. Sensors, 22(15), 5882. https://doi.org/10.3390/s22155882