2.1. Side-Channel Analysis and Power Analysis Attack
Side-channel analysis, proposed as the timing attack by P. Kocher in 1996, is a type of passive attack that extracts secret information in the device by analyzing side-channel signals leaking from the hardware [
1]. Here, the side-channel signal refers to all kinds of signals that are unintentionally leaked through illegitimate channels from the hardware. There are some representative examples of the side-channel signal such as electromagnetic radiation, power consumption, heat, sound, operating timing, and so on. Side-channel analysis has been mainly studied in the field of cryptanalysis to recover the secret key embedded in the cryptographic device and to design countermeasures against it. In addition, early side-channel analysis research was conducted targeting smart cards and microprocessors having a simple hardware architecture. However, some research shows that commercial computer processors, as well as smartphones can be vulnerable to side-channel analysis. Therefore, research on high-performance devices has been actively conducted in recent years [
2,
3,
4,
5].
The power analysis attack, the most active research field of side-channel analysis, is an analysis method using the power consumption signal of a device. Examples of the power analysis attack include differential power analysis (DPA) [
6], correlation power analysis (CPA) [
7], and differential deep learning analysis (DDLA) [
8,
9]. The power analysis attack is performed based on the fact that the side-channel signal is dependent on the instruction or data processed on the device, and these two dependencies are called operation dependency and data dependency, respectively. For example, the total power consumption of the microcontroller
can be described by Equation (1). Here,
is the power consumption by the operation dependency,
is the power consumption by the data dependency,
is the electrical noise, and
is the constant power consumption factor [
10].
In our simple experiments (using the ChipWhisperer CW308T-XMEGA), the degree of influence on power consumption is large in the order of , and the electrical noise has a normal distribution, i.e., . In fact, as a result of the experiment using an 8-bit microcontroller ATxmega128, we confirmed that is and is , approximately. The specific degree of influence will be different for each type of microcontroller, but it is common to have a large degree of influence in the order of . In addition, the power consumption includes only the signal for the entire microcontroller, not the signal of a specific component of the microcontroller due to the limitation of the measurement environment. Note that microcontrollers produced in different processes are likely to have different characteristics. Most microcontrollers use pipeline technology to execute instructions in parallel, so the power is consumed by behavior that is not related to the instruction or data to be analyzed. The power consumption due to this behavior is an obstacle to side-channel analysis, so it can be regarded as noise, which is called switching noise.
Side-channel analysis targeting the cryptographic algorithm can be performed using
or
. In the power analysis attack targeting
, a model that can calculate the predicted power consumption according to the processed value is required. Due to the limited information of the microcontroller, the Hamming distance and the Hamming weight models, which can calculate the relative difference in the predicted power consumption using only the data values, are mainly used. In the power analysis attack targeting
, timing information or data-dependent information can be utilized in SPA, single-trace attack (using correlation coefficient), and so on. To protect cryptographic algorithms from side-channel analysis, software-based [
11] and hardware-based [
12] countermeasures have been continuously developed. These countermeasures based on their specific design protect not only
, but also
from the advanced side-channel analysis attacks including DPA, CPA, etc.
The Hamming distance is a power model based on the characteristics of a complementary metal–oxide-semiconductor (CMOS). It is based on the assumption that is proportional to the number of flipped bits because the power is consumed in the process of flipping bits of data. On the other hand, the Hamming weight model is based on the assumption that the power is consumed proportional to the number of “1”s in the bit string because the bus is pre-charged. Using this power model, the predicted power consumption for the intermediate operation value of the cryptographic algorithm can be calculated, and the secret key can be recovered by analyzing it with the side-channel signal. In fact, the leakage mechanism of the processor is too complex to model, but data-dependent attacks targeting cryptographic algorithms can adopt a simple data-driven power model. Our disassembler needs to use much information such as instructions and data. In this case, the modeling process for the power signal can be omitted by using deep learning techniques (analysis of standard deviation caused by random instruction/data).
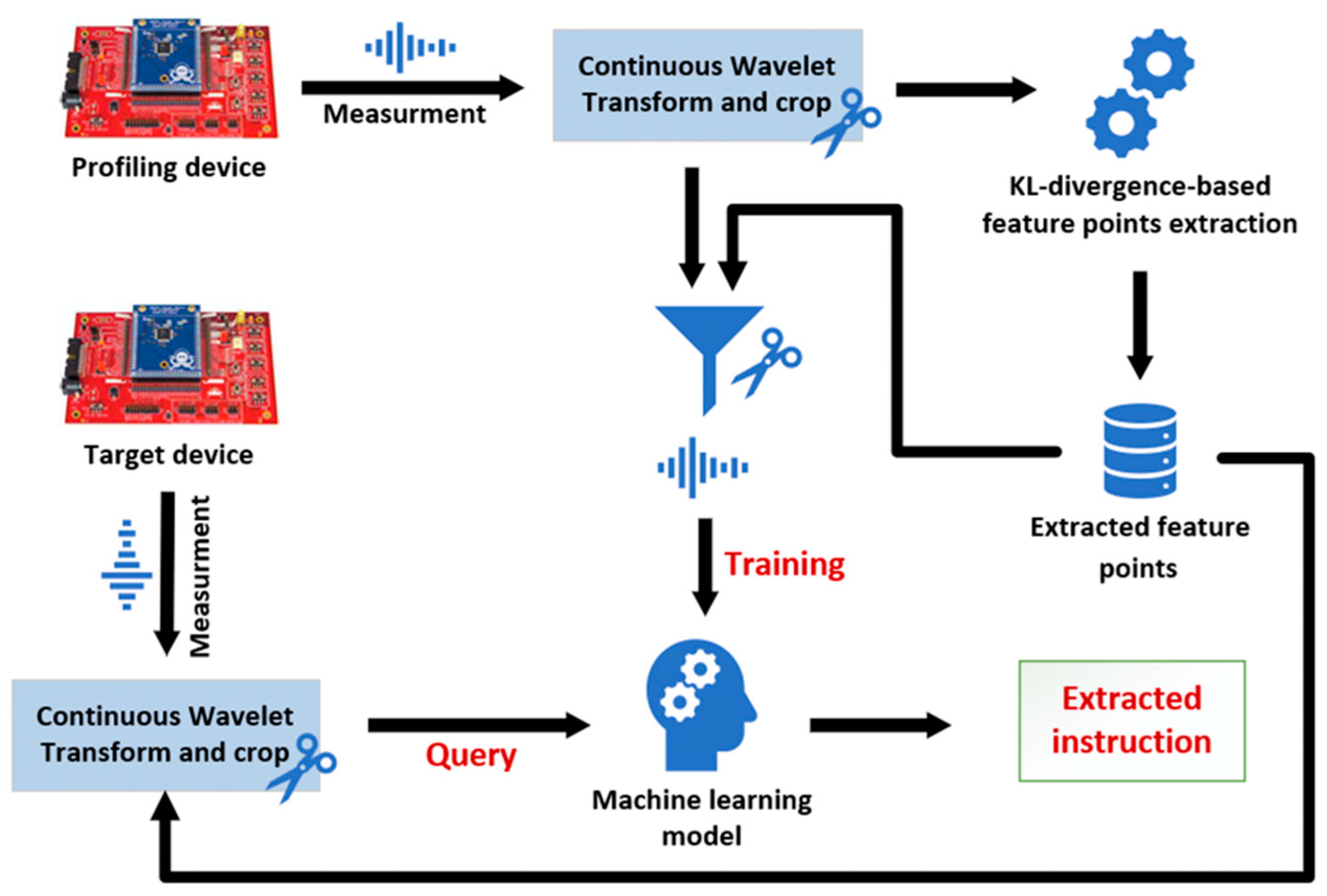
2.2. Side-Channel-Based Disassembler
Side-channel analysis can also be used to develop an instruction disassembler rather than cryptanalysis, and software that recovers the instruction from a side-channel signal is called a side-channel-based disassembler. This is premised on the fact that there is a slight difference in the power consumption because when the different machine code is fetched, decoded, and executed, different types of logic circuits are operating. This means that the instruction executed inside the microcontrollers can be recovered using , which occupies the largest portion in the above Equation (1).
As a research case of the SCBD, the power consumption and the electromagnetic radiation were used as side-channel signals, and attempts have been made at the machine code level and the opcode level as a recovery unit. The machine-code-level recovery treats the instruction as only a bit string and recovers the encoded code. Therefore, the instruction template building phase can be performed only by generating a random bit string, so it is not dependent on a specific microcontroller and is flexible. In addition, since machine code includes all operands such as literal constants and the registers, it can also be recovered without additional work. However, much effort is required in the signal acquisition phase because a side-channel signal in the instruction fetch process with small switching noise is required. On the other hand, the opcode-level SCBD recovers the identifier assigned according to the mnemonic. For this, much effort for template building is required because it is necessary to compose an assembly language that conforms to the grammar of a specific microcontroller. In addition, a model for recovering operands, e.g., the registers and literal constants, is additionally required for each instruction (opcode). However, there is an advantage that recovery is possible even if a power consumption signal with much switching noise is used.
A study on the SCBD was first attempted by Vermoen et al. in 2007 [
13]. Vermoen et al. attempted power consumption signal analysis on Java cards and showed that they could recognize 10 different Java bytecodes with at least 90% accuracy. They correlated the power consumption signal with the average power template of each byte code and classified it as a byte code. However, they did not propose a specific instruction recovery algorithm. Eisenbarth et al. implemented an instruction classifier by performing a template attack on a PIC16F687 microcontroller using the power consumption signal [
14]. They achieved a recognition rate of 70.1% in 35 test instructions by applying statistical models such as the hidden Markov model (HMM). Strobel et al. implemented an instruction-level disassembler for the PIC16F687 microcontroller using multiple electromagnetic channels [
15]. They showed a recognition rate of 96.24% in the test instruction without the usage of a statistical model such as the HMM. Park et al. showed that 112 instruction codes and 64 registers can be recovered with an accuracy of 99.0% for the ATMega328P microcontroller using signal preprocessing techniques such as the CWT, principal component analysis, and the classification model proposed by McCann et al. [
16,
17]. Recently, in 2019, V. Cristiani et al. implemented a disassembler through a machine-code-level (bit-level) approach for the first time, showing a new development potential that is more flexible and can fully recover all operands, including literal constants [
18]. However, there is a difficulty in that it is necessary to collect a local side-channel signal leaking only during the instruction fetching process.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}