1. Introduction
As rail transportation plays an increasingly important role in China, the safety of rail transit operations has also attracted more and more attention. However, in some remote areas, the train track crosses the highway and pedestrian passage. In particular, pedestrians still stay on the track when the train is about to arrive, which will bring huge potential safety hazards, and accidents occur frequently. These pedestrians usually move fast and irregularly on the railway track, while the target is very small and has a high degree of coincidence of body positions within the visual range of the machine’s vision. In addition, complex and uncertain environmental factors such as trees, weeds, and telephone poles around the railway track have caused huge obstacles to pedestrian detection. It is of great significance to carry out research on pedestrian detection and abnormal state monitoring at railway stations to ensure the safety of pedestrians.
Traditional machine learning target detection algorithms, such as the Viola–Jones Detector, generally use the sliding window method to extract candidate frames. They first extract and learn low and intermediate features in candidate frames, and then use classifiers to identify and select objects, which makes it difficult to solve the problems caused by fast movement, small targets, high randomness of appearance, and the high degree of coincidence of body positions. In order to better deal with these difficulties, we propose a detection algorithm based on deep learning, which can help us to obtain a better detection effect by learning the higher-level features of the object through Convolutional Neural Networks (CNNs) [
1]. The deep learning target detection algorithm has been in development since R. Girshick et al. proposed Region-CNN (RCNN) [
2] in 2014. Since then, Fast R-CNN [
3], Faster R-CNN [
4], Spatial Pyramid Pooling (SPP) [
5], two-stage detectors, You Only Look Once (YOLO) [
6,
7,
8,
9], Single Shot MultiBox Detector (SSD) [
10], and other single-stage detectors have emerged. The two-stage detector uses a convolutional neural network to extract the features of the markers, and then uses Region Proposal Net (RPN) to recommend candidate boxes, which returns the candidate boxes to the predicted position through a gradient descent at the end. Conversely, the single-stage detector directly performs the regression of the bounding box after extracting the features by ignoring the RPN. The two-stage detector uses two different networks to classify and locate objects, so the detection accuracy is at a high level while the speed is very slow, requiring at least 100 ms to detect an image, such as the Faster RCNN. The single-stage detector uses only one network to perform classification and positioning at the same time, so detection speed is guaranteed. The detection speed of YOLOv1 can reach 45–120 fps, which can process video or camera images in real-time, requiring less equipment and achieving better performance in field deployment.
With the development of transportation, pedestrian detection has gradually become a hot spot in the field of target table detection, where many experts and scholars have put forward their views and opinions. Jin, Xianjian et al. proposed a pedestrian detection algorithm based on YOLOv5 in an autonomous driving environment [
11]; Gai Y et al. proposed a method of pedestrian detection + tracking + counting based on YOLOv5 with Deepsort [
12]; Sukar et al. proposed an improved YOLOv5 algorithm for real-time pedestrian detection [
13]. Zhi Xu et al. proposed a method of CAP-YOLO based on channel attention for Coal Mine Real-Time Intelligent Monitoring [
14]. Masoomeh Shireen Ansarnia et al. proposed a deep learning algorithm for contextual detection in orthophotography [
15]. Kamil Roszyk et al. adopted a method for low-latency multispectral pedestrian detection in autonomous driving by YOLOv4 [
16]. Luying Que et al. proposed a lightweight pedestrian detection engine of a two-stage low-complexity detection network and adaptive region focusing technique [
17]. Yang Liu et al. used a thermal infrared vehicle and pedestrian detection method in complex scenes [
18]. Jingwei Cao et al. proposed a pedestrian detection algorithm for intelligent vehicles in complex scenarios [
19]. Isamu Kamoto et al. used a deep learning method to predict crowd behavior based on LSTM [
20]. Gopal, D.G. et al. proposed a method of selfish node detection based on evidence by trust authority and selfish replica allocation in DANET [
21]. Jerlin, M.A. et al. created a smart parking system based on IoT [
22]. Nagarajan, S.M. et al. applied an intelligent anomaly detection framework to cyber physical systems [
23]. Selvaraj, A. et al. put forward a swarm intelligence approach of optimal virtual machine selection for anomaly detection [
24]. Nagarajan, S.M. et al. put forward an effective task scheduling algorithm with deep learning for IoHT in sustainable smart cities [
25]. The above algorithms have put forward corresponding practical innovations in pedestrian detection and processing, but few achievements have been made in railway pedestrian detection, which is one of the most high-risk scenarios. This paper aims to carry on the corresponding research and experiments for this scene.
Aimed at the problem of the low detection accuracy caused by the rapid movement of the target or the prediction frame completely deviating from the target, as well as the missed detection of the target caused by the high coincidence of body positions, an improved target detection algorithm based on YOLOv5s is proposed.
- (1)
L1 [
26] regularization is added to constrain the scaling factor of the BN [
27] layer to make the activation coefficients sparse. Next, the modified model is sparsely trained to cut out the sparse layers. We end up with a very compact model with repeated cutting.
- (2)
In Backbone, the CEM module is introduced to fully extract the features of different scales. The CxAM module is introduced to extract context semantic information to improve recognition accuracy. The CnAM module is introduced to correct the position of F5 layer features and improve the accuracy of target box regression.
- (3)
DIoU_NMS is used instead of NMS to filter prediction boxes to avoid eliminating different target prediction boxes with high consistency.
- (4)
We collected a certain number of datasets along with a certain number of relevant public datasets to provide data support for the verification of the actual effect of the improved model.
- (5)
According to the direction of improvement, a number of related ablation experiments were designed to verify the validity of each contribution.
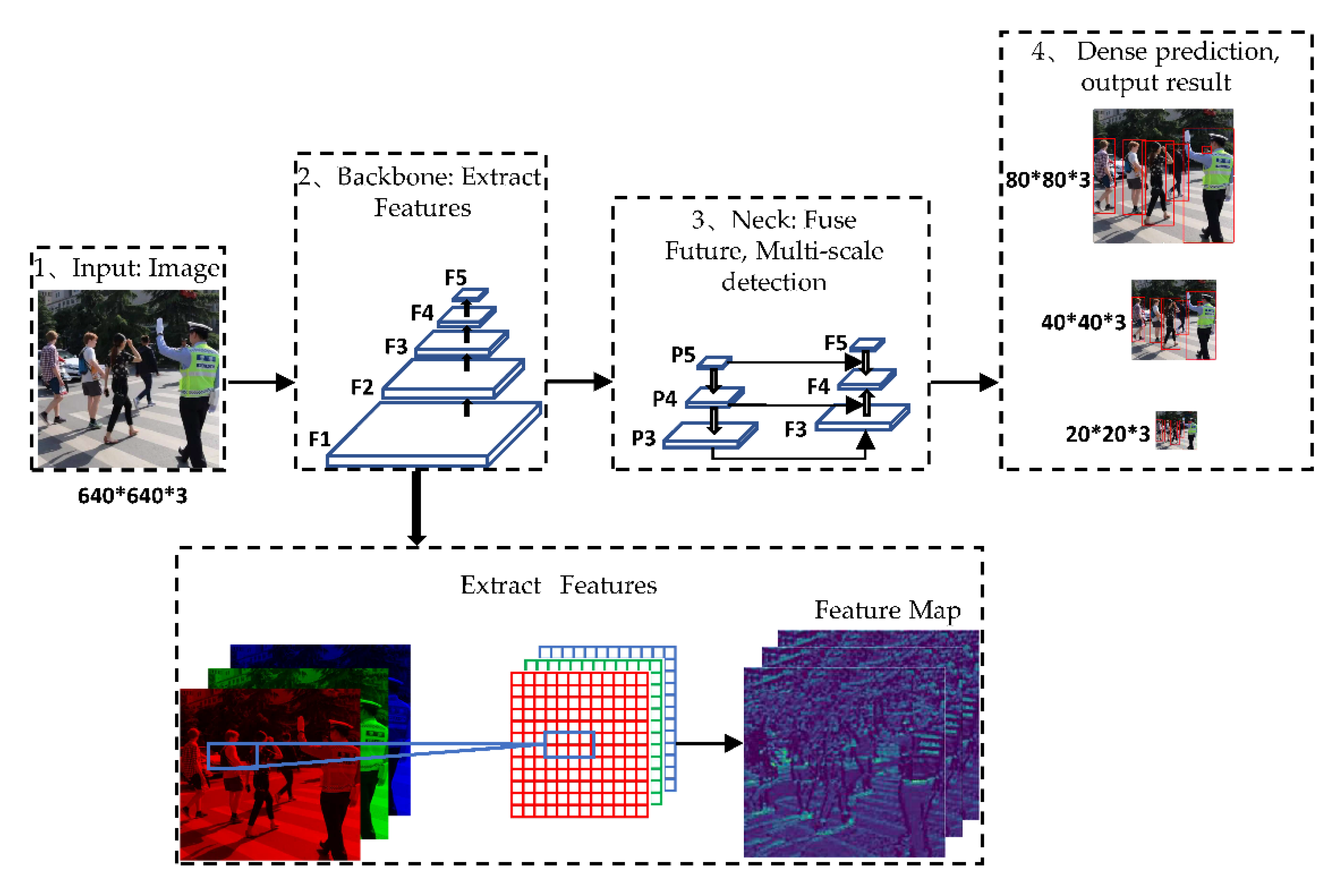
3. Method
3.1. Data Augmentation
The most important part of the data augmentation used by YOLOv5 is the mosaic, which is improved from cutmix. Cutmix is used to scale and crop two pictures and stitch them together according to the pixel ratio.
Mosaic can greatly improve the problem of inaccurate small-target detection by stitching four pictures using the methods of random scaling, random cropping, and random arrangement.
3.2. Adaptive Image Scaling
The length and width of the input images are different when performing target detection, which will affect the efficiency of network computing. Therefore, they are usually scaled to the same standard size and then sent to the detection network. The commonly used input sizes of the YOLO algorithm are 416 × 416 and 608 × 608. Image transformation with a size of 800 × 600 is shown in
Figure 4.
In actual projects, many images have different aspect ratios. The black borders at both ends are padded in different sizes after scaling and filling, where there will be information redundancy if there is too much padding, which will affect the inference speed. In YOLOv5, the author proposes a nice trick to help with training by modifying the letterbox function to add minimal black borders to the original image, which can be divided into the following steps:
- (1)
Calculate the scaling ratio.
- (2)
Calculate the scaled size.
- (3)
Calculate the black border fill value.
The scaling process is shown in
Figure 5.
3.3. Loss Function
The loss function is an important indicator for evaluating regression and classification problems. The loss function of YOLOv5 includes Classification Loss, Localization Loss, and Confidence Loss. Classification loss and confidence loss use the binary cross entropy function, its expression is seen in Formula (1):
where
is the binary label 0 or 1 and
is the probability of the label. The binary cross entropy function is used to judge the quality of the prediction results of the binary classification model. If the predicted label probability is close to 1, then the loss function is close to 0. The target box regression loss uses the CIoU_Loss [
33] (Complete Intersection over Union) function as the evaluation index, and its expression is seen in Formula (2),
where
is the area intersection ratio of Ground True box A and Bounding box B, and
is the penalty factor, which acts as a block of variables that distinguishes different regression loss functions. With different
IoU_Loss, the form of the penalty function appears different,
is defined as
where
and
denote the central points of
and
,
is the Euclidean distance, and
is the diagonal length of the smallest enclosing box covering the two boxes.
is the trade-off parameter and
is the relationship factor between the width and height of the prediction frame and the coordinates of the center point
Then, the relationship factor
is defined as
where
is the width of the prediction box,
is the height of the prediction box,
is the width of the ground truth box, and
is the height of the ground truth box.
3.4. Sparse Training and Model Pruning
YOLOv5 is already a cracking lightweight detection network where the trained weight model generally does not exceed 30 MB, which is still too large for some embedded devices. If we simply choose to reduce the size of the network input, such as 640 to 320, as the size of the model is reduced accordingly the detection effect will also have a greater loss at the same time. Therefore, according to a method of network slimming proposed by Zhuang Liu et al. [
34], we add L1 regularization parameters to the model to constrain the scaling factor of the BN layer, which can cause the coefficients close to 0 to become smaller. These pairs of parameter layers with little influence on forward propagation are eliminated through sparse training. We can obtain a very compact and efficient network model by repeating the above operations.
The loss function expression with L1 regularization is seen in Formula (7)
Among them, the former term is the usual network loss function and the latter term is the regularization of the scale factor where
denote the train input and target,
denotes the trainable weights,
is a sparsity-induced penalty on the scaling factors,
is the scale factor, and
is the penalty sparse parameter that determines the size of the penalty term. The L1 regular expression is seen in Formula (8)
BN layer parameters are calculated as follows:
where
and
are the mean and variance of the activations, while
and
are the trainable affine transformation parameters.
and
are the input and output of a BN layer. We choose to use the BN layer
as the scale factor for sparsity clipping directly.
The principle of YOLOv5 network channel clipping is shown in the
Figure 6.
Above all, we append L1 regularization to the model to perform corresponding sparse training. Then, channel pruning is performed on the trained model. Ultimately, the training hyperparameters are fine-tuned to ensure the model inference results are optimal. The algorithm implementation process is shown in
Figure 7.
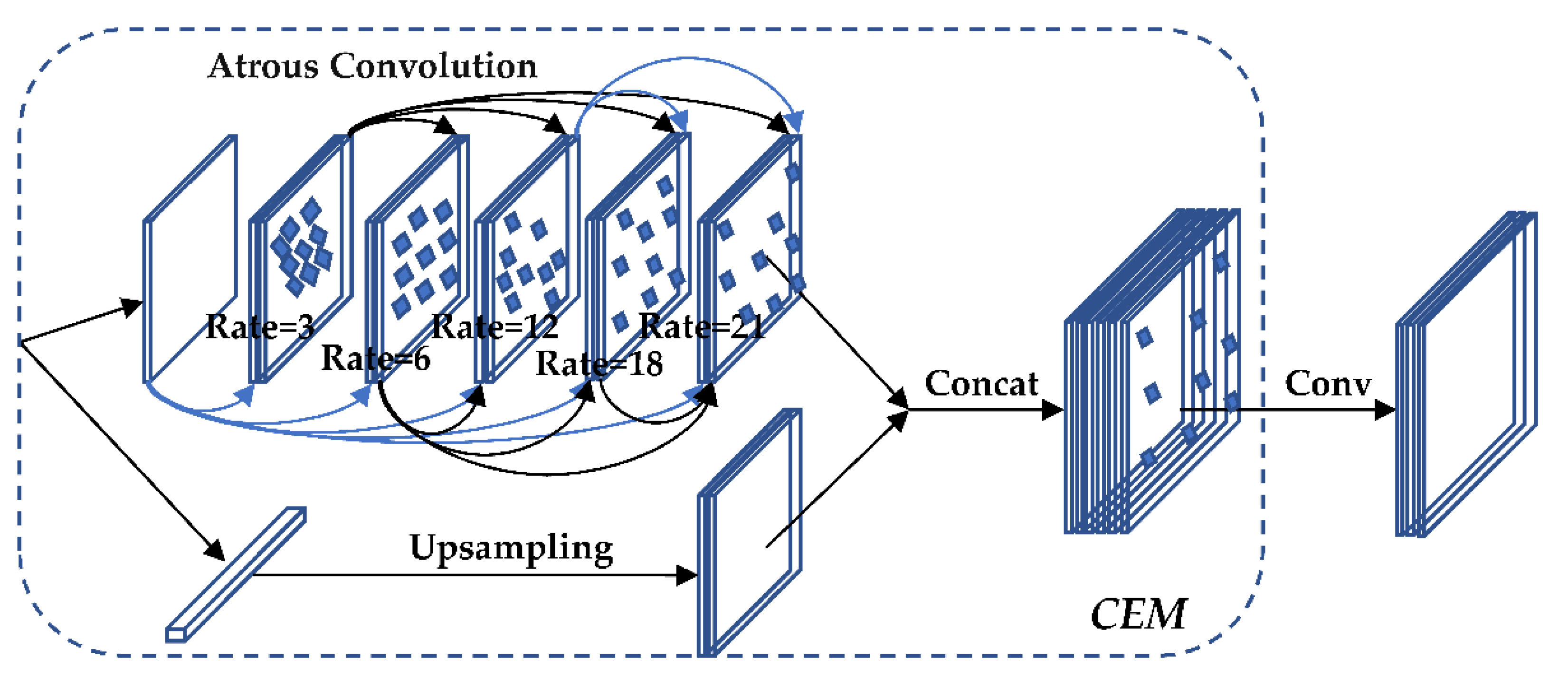
3.5. Improved AC_FPN
The higher the resolution of the input image in the training network, the more feature information needs to be extracted, and the more requirements are put forward for the receptive field of the convolution layer. The general convolutional neural network uses multiple convolution and pooling operations. In order to improve the receptive field, the size of the feature map should be reduced. However, when up-sampling the feature map to restore its original size, a great deal of feature information is lost, which causes bias in the final classification result and prediction regression. In order to avoid this situation, this paper improves the Feature Pyramid Networks (FPN) structure and sends the feature map of the highest F5 layer of the feature pyramid to the Context Extraction Module (CEM) for multi-scale hole convolution so the features of different scales will be fully extracted. Then, the extracted feature information is sent to Context Attention Modules (CxAM) for contextual semantic information extraction to determine the target more accurately. At the same time, it is sent to Content Attention Modules (CnAM) to compare the features of the F and F5 layers, correcting the position shift that occurs in the feature extraction process, performing more accurate frame selection on the target. Finally, the processed feature map and the feature map of the deconvolution layer are multi-scale fusion, which outputs the prediction result after the algorithm process. FPN is composed of an upward convolution pyramid and a downward deconvolution pyramid. The feature maps of the same size are fused at multiple scales through horizontal connections in the middle. FPN can enhance the effect of feature extraction compared with traditional convolutional networks.
3.5.1. CEM
The CEM module is a feature pyramid structure composed of separable convolutional layers with different void rates. The void rate gradually increases from 3 → 6 → 12 → 24 where the layers are connected by a multi-path, and the different receptive fields of each layer are used to fully extract the features so as to realize the diversity of features in scale. The structure of the CEM is shown in
Figure 8.
3.5.2. CxAM
Since there is no screening mechanism, many useless features will be sent to the end of the network for prediction after features are fully extracted by CEM, which will affect the accuracy of the output results. Therefore, the attention module (AM) is set to eliminate useless features. AM contains two submodules, CxAM and CnAM.
CxAM: Contextual Attention Module, which inputs the same feature of different scales extracted by CEM, extracts the semantic relationship between different feature sub-regions, and uses the feature map to generate the attention matrix. As a result, the output feature map will contain clear semantic information. The structure of the CxAM is shown in
Figure 9.
3.5.3. CnAM
CnAM: Content Attention Module, which uses the F-layer feature map to calibrate the position offset that occurs in the feature extraction process to obtain more accurate box selection positioning when it is used for target detection. The structure of the CnAM is shown in
Figure 10.
3.5.4. AC_FPN Structure
The output is sent to the deconvolution layer of the FPN network for feature fusion after the feature maps are processed by the above three modules. The improved AC_FPN [
35] structure is shown in
Figure 11.
3.6. Improved NMS
Non-Maximum Suppression (NMS) needs to be performed for the screening of many target boxes in the post-processing process of target detection. YOLOv5 adopts the traditional NMS [
36] method. The occluded target selection box is usually removed when facing two different targets with a high degree of coincidence by using this method. For an environment with a large number of targets, where there will be many targets with a high degree of coincidence, the occlusion target candidate boxes that are obscured will be removed as redundant information by NMS, which is not suitable for models that want to detect accurately. In this paper, DIoU_NMS is used to replace the NMS. DIoU_NMS introduces the parameter
β of the center point distance between the two boxes. When
β → ∞, DIoU_NMS degenerates into traditional NMS. Otherwise, as long as the center points of the two frames do not coincide perfectly when
β → 0, they will be retained by DIoU_NMS. As a consequence, the value of
β can be adjusted to 0 → ∞ according to the actual situation to achieve the best effect to restrain redundant boxes. Its classification score update formula is defined as Formula (11):
where
is the classification score and
is the NMS threshold,
is the penalty item,
is the predicted box with the highest score, and
is the other box.
Among them is the highest-class score of the prediction box, which is the threshold of the distance between the center points of the two prediction boxes. DIoU_NMS suggests that the two boxes with farther center points may be located on different objects, thus it should not be deleted, which is the biggest difference between DIoU_NMS and NMS.
3.7. Improved YOLOv5-AC Network Structure
The features are further extracted by adding a context extraction model (CEM) in Backbone. CxAM is added to extract the context semantics. CnAM is applied to correct the feature positions of the F and F5 layers. Post-processing uses DIoU_NMS to replace NMS. The improved YOLOv5-AC structure is shown in
Figure 12.
6. Discussion
Compared with YOLOv5s, the improved YOLOv5-AC model has been greatly improved in terms of precision, recall, model size, and FPS. Moreover, the missed detection rate of overlapping targets has been greatly improved, which is a greatly effective algorithm improvement. However, during the experiment, we also found that the algorithm’s ability to recognize small overlapping targets at long distances still needs to be improved. In the future, we will further improve our YOLOv5-AC based on this problem, which is mainly divided into the following two points: First, there are fewer small-target feature areas, so we will perform further data enhancement to improve the sample quality; second, we will use the idea of a sliding window, where the image is divided into n small areas to be detected separately, and the normal image size is concatenated in the end.
Furthermore, we will use the intelligent robot based on jetson nano as the research object. In the meantime, cooperating with the SLAM algorithm and the path planning algorithm to realize pedestrian detection in the process of automatic driving of the robot, we will test the actual effect of our YOLOv5-AC algorithm to help the development and application of pedestrian detection methods in railway traffic.
7. Conclusions and Future Works
In view of the accuracy and recall rate of pedestrian detection on train tracks, the corresponding train track datasets were collected, and Labelme was used for manual annotation. We have made improvements to the YOLOv5s deep learning framework. Above all, the L1 regularization function is added to the BN layer, which can remove the network layer with a small impact factor, reducing the size of the model to improve the inference speed. Then, a CEM module is applied to the FPN layer to extract as many features as possible. At the same time, CxAM and CnAM, which are two attention modules, are deployed to filter out the useless features, which can correct the position shift that occurs in the process of feature restoration and improve the detection accuracy. In the end, the DIoU_NMS algorithm is used as the prediction box screening algorithm to reduce the loss rate of non-redundant boxes and improve the recall rate. The final experimental results show that the AP can reach 95.14% and the recall rate can reach 94.22% for the improved YOLOv5-AC algorithm. In addition, the trained weight file is 13.1 MB, and the FPS is 63.1 f/s. YOLOv5-AC shows great improvement in each detection performance compared with YOLOv5s, and the model size and inference speed are better, which facilitate the deployment of actual projects. Our YOLOv5-AC can be used in practical projects related to pedestrian detection on train tracks to improve detection accuracy, reduce missed detection rates, reduce accidents caused by pedestrians randomly crossing the track, and ensure the safety of life and property.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}