1. Introduction
Controlling a robotic platform in a marine environment is a particularly challenging task since it is a hostile environment. It is strongly unstructured, meaning that the lack of structure makes the environment difficult to model. Moreover, this environment includes many uncertainties and external disturbances that cannot be easily predicted or modeled: the wind, the waves on the surface, the ocean currents, the seabed topography, the potential presence of objects, fishes, rocks, etc. Another specific problem found in marine robotics is the lack of positioning since the GPS signals cannot be propagated in the water. Without a valid or accurate model of the environment, the control task is more difficult and the controllers become harder to tune. Finally, as in many other control tasks, all of the input, output, and state signals include random noises, due to the environment or even the robot itself.
Robotics is a vast domain; mobile robotics is one of its subfields [
1], where the studied robots are able to move by themselves, either on the ground, in the air, or in the water. Therefore, marine robotics [
2] is itself a subfield of mobile robotics [
3]. Various robotic platforms can be the objects of marine robotics [
4], such as autonomous underwater vehicles (AUVs) [
5], remotely operated underwater vehicles (ROVs) [
6], unmanned surface vehicles (USVs) [
7], autonomous sailboats [
8], and underwater gliders [
9].
In this paper, we only focus on AUVs as the other marine robots have different scientific issues. The development of AUVs began in the 1950s and has not stopped evolving; scientists are continuously improving the mechanical designs, actuators, sensors, electronics, communication, power supply, and control algorithms. Their uses have also diversified, i.e., from research (hydrography, oceanography) and military applications (communication/navigation network nodes, mine countermeasures), to commercial and hobby uses.
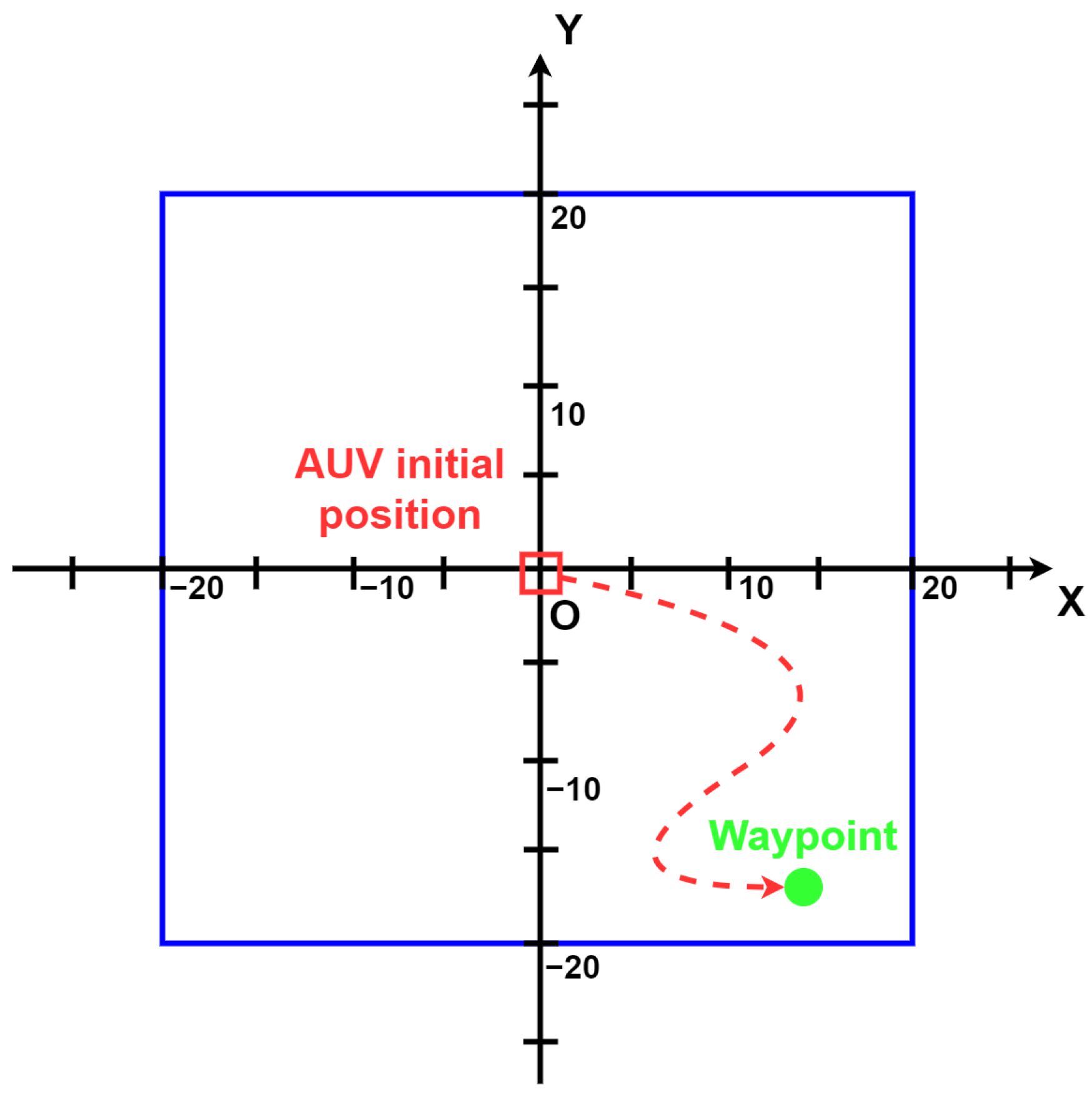
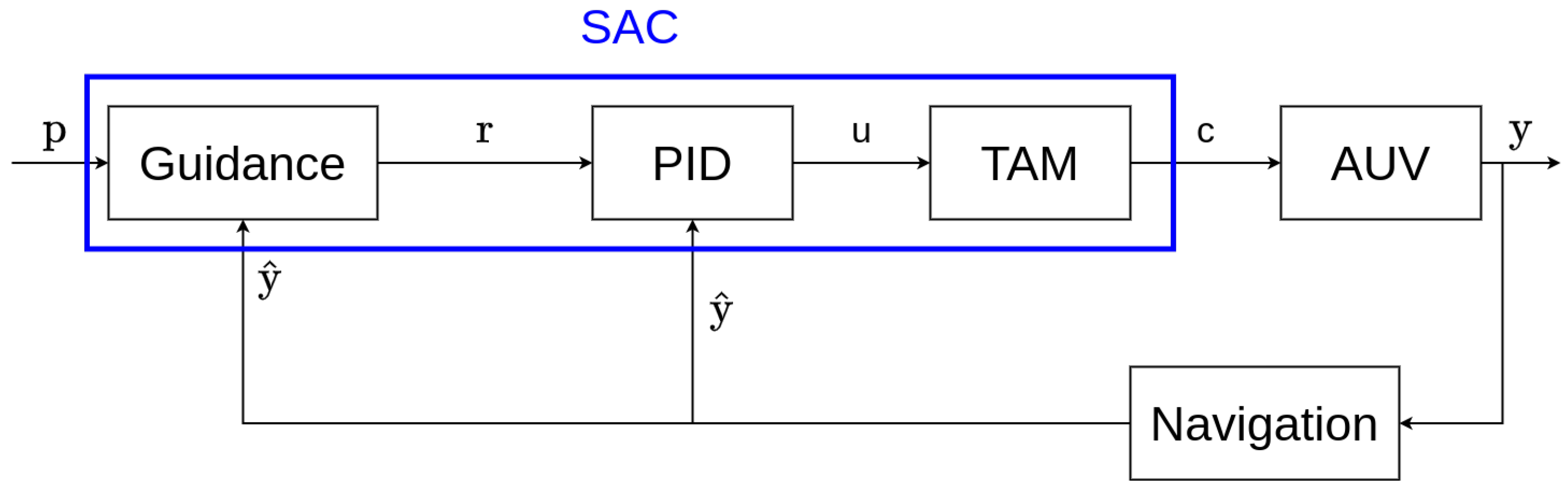
In this work, we compare a machine learning-based controller (the SAC algorithm) and a classical controller (the PID controller) on a waypoint tracking task performed by an AUV. This control task can be generalized to a large number of marine robotics missions since every path can be decomposed into successive waypoints to follow. Every mission where trajectories need to be followed or specific targets need to be reached can be reduced to a waypoint tracking task composed of one or more waypoints.
2. Related Works
The use of machine learning and its subfields (deep learning, reinforcement learning, and deep reinforcement learning, which will be detailed in the following sections) applied to robotics and control theory has grown exponentially in the past few years. Machine learning can either replace or improve the control algorithms used in robotics: its modeling power and its ability to generalize to new events or behaviors can overcome the limits of certain control approaches.
Several surveys on deep learning applied to robotics can be found in the literature, such as [
10,
11,
12,
13] (in chronological order).
Reference [
14] provided an interesting discussion about the limits and the potentials of deep learning approaches for robotics. The authors mainly dealt with the learning challenges, robotic vision challenges, and reasoning challenges (the inferences or conclusions generated by the processing of any input information).
The authors detailed the need for better evaluation metrics, as well as better simulations for robotic vision. They reviewed the perception, planning, and control in robotics, and concluded by saying that neural networks generally do not perform well when the state of the robot falls outside the training dataset. The work also defined the concepts of programming and data as spectra, allowing to automatically derive deep learning algorithms from reasonable amounts of data and suitable priors.
Reference [
15] presented a large comparative study of reinforcement learning applied to control theory. A controller based on neural networks and reinforcement learning was tested on several systems, i.e., an AUV, a plane, the magnetic levitation of a steel ball, and the heating coil (belonging to the set of heating, ventilation, and air conditioning (HVAC) problems). These benchmarks allowed the evaluation of several control theory aspects:
the effects of nonlinear dynamics, the reaction to varying setpoints, long-term dynamic effects,
the influence of external variables and the evaluation of the precision.
Reference [
16] presented a survey on reinforcement learning applied to robotics (it is a good entry point). However, this article was published in 2013 and the deep reinforcement learning (DRL) approaches were never mentioned since the majority of modern DRL algorithms were not yet published at that time.
In the literature, we can find many works dealing with machine learning applied to the control of unmanned aerial vehicles (UAV) since UAVs have one of the largest communities of researchers in the mobile robotics field.
Reference [
17] presented an interesting review on DRL applied to UAVs. The authors divided UAV tasks into several categories: path planning (using real-time images, with or without ground maps), navigation (for discrete or continuous action spaces), and control (for attitude control, longitudinal and lateral control, image processing, or UAV swarm control).
Reference [
18] presented a review on a more specific subject: the use of UAVs for obstacle detection and collision avoidance in the Internet of Things (IoT) field. They provided many useful resources, such as a list of available datasets or different hardware and communication architectures. The review mainly listed convolutional neural network (CNN) works applied in a number of industrial applications. The UAVs controlled in these industrial environments need to be aware of the possible collisions with workers, mobile vehicles, robots, or even heavy-duty tools.
Reference [
19] used reinforcement learning to control the attitudes of UAVs. Both works implemented PPO, TRPO, and DDPG algorithms for this task, and compared them to a PID controller.
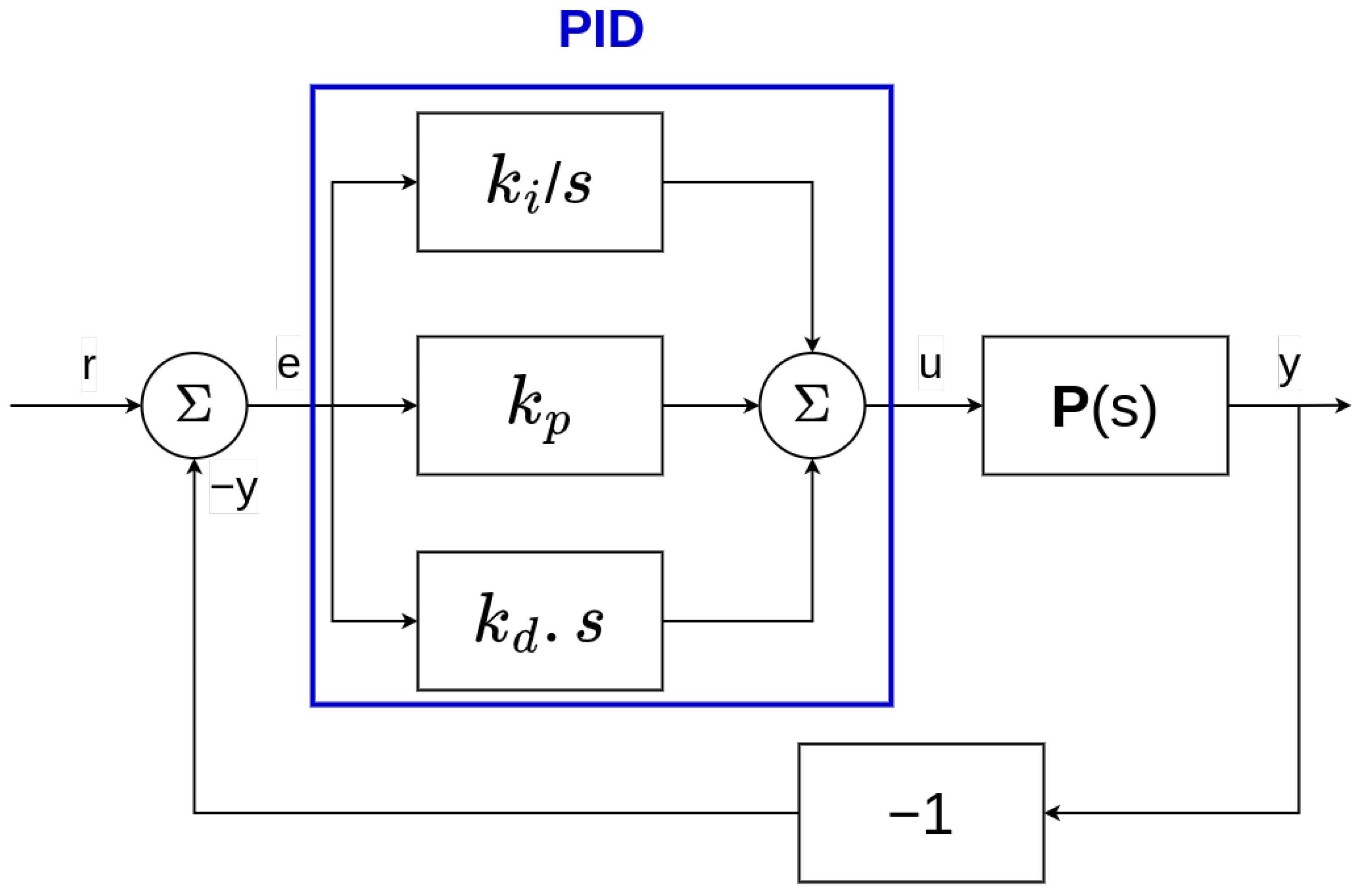
In our work, we also compare RL algorithms to PID controllers since it is one of the most used controllers in the literature.
Reference [
20] is a good example of reinforcement learning applied to the navigation of a UAV.
An exact mathematical model of the environment is not always available in unknown environments, so this work applied Q-learning to indicate the position of a UAV based on the previous position, by learning its own model of the environment. This information was then given to a PID controller.
Some research studies deal with higher levels of control. For example, Reference [
21] used the SAC algorithm to directly generate trajectories for UAVs. The authors focused their efforts on generating trajectories—allowing to save energy—since their use case was a data collection system based on UAVs. They wanted to optimize the UAV trajectory to minimize the time required to complete the task, which ensured that the robot used less energy.
SAC is the algorithm we implemented in our work, which further confirms that it can be successfully applied to mobile robots, such as UAVs or AUVs.
Reference [
22] presented another example of a deep reinforcement learning algorithm used to make UAVs energy-efficient. The use case studied in this paper involved the control of a group of UAVs to create a communication network. The DDPG algorithm was used to make the whole group energy-efficient and to make the communication better (in terms of coverage and fairness).
This work shows that machine learning can help to save energy when ML algorithms are used as the controllers of the robots. Energy management is one of the main challenges of robotics.
Finally, Reference [
23] presented a recent survey that studied the machine learning methods applied to groups or flocks of UAVs. The authors listed approaches taken from the three main subfields of machine learning: supervised learning, unsupervised learning, and reinforcement learning.
More researchers are experimenting with implementing machine learning algorithms inside autonomous underwater vehicle (AUV) systems. As said in the introduction, the marine environment has its own constraints, which differ from the aerial and terrestrial environments; thus, the use of machine learning techniques can help exceed these difficulties.
Reference [
24] is an example of deep learning applied to AUVs: A neural network was used to perform an AUV trajectory tracking task using a neural network control approach. Two neural networks (NNs), called the
actor and the
critic, were implemented based on the AUV model derived in the discrete-time domain. The critic was used to evaluate the long-time performance of the designed control, while the actor compensated for the unknown external disturbances.
Reference [
25] used a neural network to tune the PID controller of an AUV in real-time. The neural network was implemented in parallel to the PID to perform an auto-tuning control of the AUV. This interesting approach was able to mix both control theory and machine learning techniques inside the same AUV controller.
Since many reinforcement learning (RL) algorithms are more appropriate to continuous control tasks [
26], most of the machine-learning-based controllers for AUV fall into this category.
Many works can be found for the low-level control of AUVs. Reference [
27] involved an early trial, allowing to control the AUV thrusters in response to command and sensor inputs. The authors used a Q-learning approach based on a neural network, which was a rare instance of DRL at that time (in 1999).
The RL controller created in [
28] was robust to thruster failures. It was based on model-based evolutionary methods. The problem was modeled by a Markov decision process (MDP) and the controller was based on a parametrized policy updated by a direct policy search method. The controller was able to operate under-actuated AUVs with fully or partially broken thrusters.
References [
29,
30] both implemented the DDPG algorithm to control an AUV. The first paper used it to create a depth controller, allowing track desired depth trajectories, while the second paper allowed the AUV to follow linear velocities and angular velocity reference signals.
Reference [
31] proposed a specific reward function design to perform AUV docking tasks. The authors tested their reward function formulation by comparing its implementation inside the PPO, TD3, and SAC algorithms, and managed to achieve successful results.
In many of these low-level control problems, the input vectors given to the RL controllers were often composed of many variables to correctly follow the reference signals given by the guidance components. The reward must be specifically designed for each control task.
In the literature, we also found papers applying RL to the guidance or high-level control of AUVs. These approaches are often able to replace both the control and guidance components of the systems, but this is not systematic.
Reference [
32] implemented a classic actor–critic architecture to carry out the waypoint tracking and obstacle avoidance tasks of an AUV. Reference [
33] was also able to make an AUV fulfill the ‘path following’ and ‘collision avoidance’ missions but using a PPO algorithm.
Reference [
34] performed a trajectory tracking task of an AUV using the DPG algorithm and recurrent neural networks. The motion control was only conducted in a 2D horizontal plane. It compared this method with a PID controller and other non-recurrent methods.
Reference [
35] was a rather creative work since it used the DDPG algorithm to plan the trajectories of multiple AUVs. The goal was to estimate a water parameter field inside an under-ice environment.
5. Results
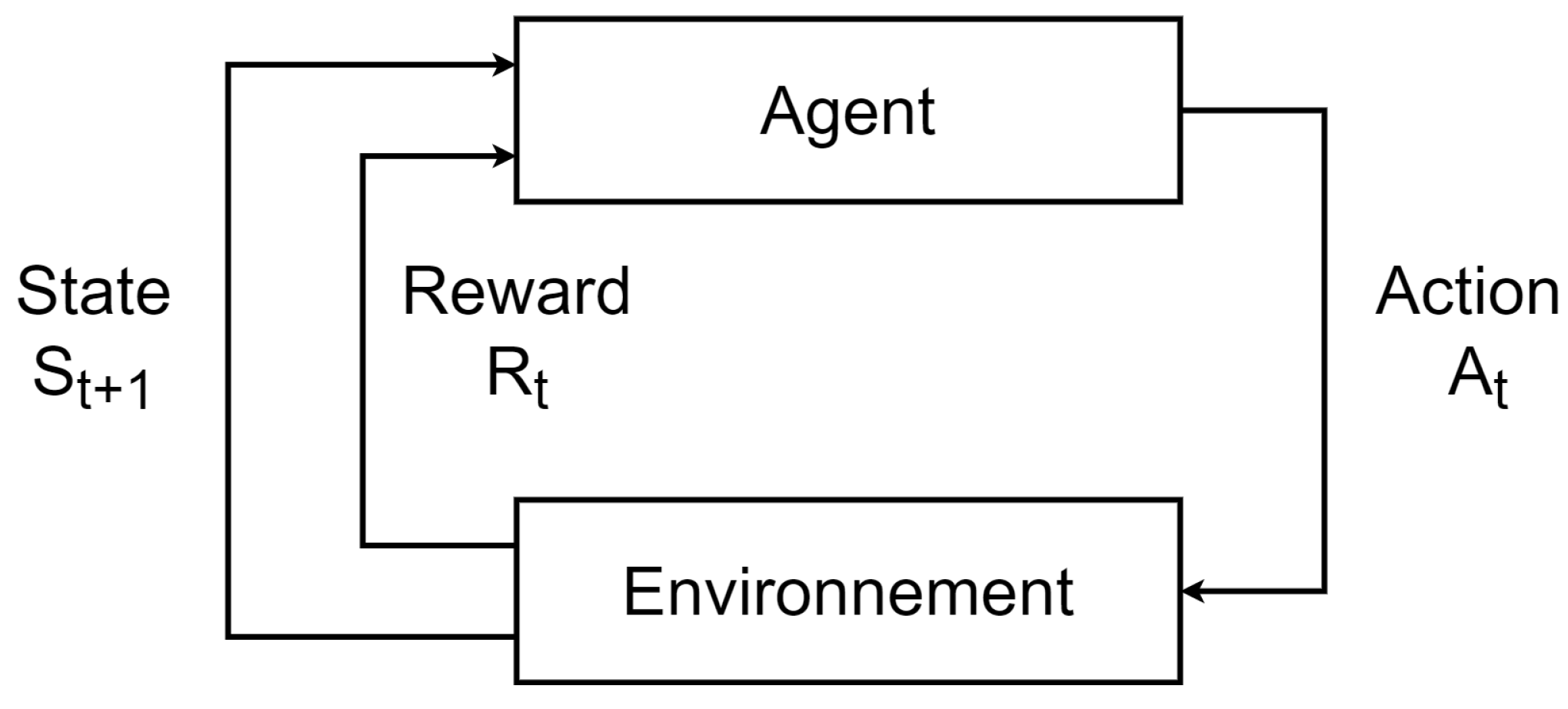
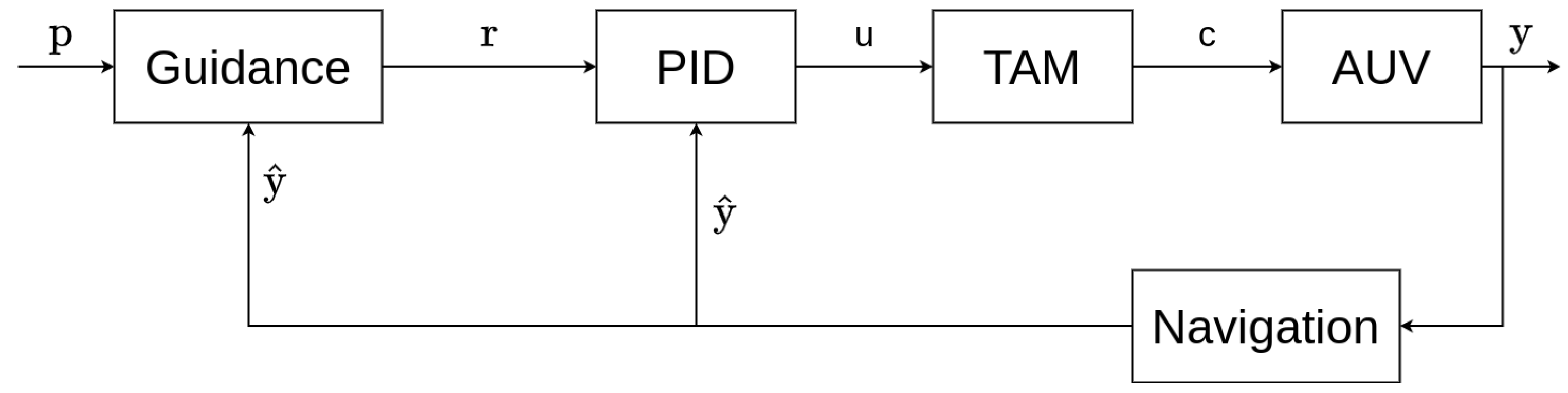
In this section, we describe the results of the comparison of the SAC with the PID controller on the waypoint tracking task of the RexROV 2. Moreover, we studied the impact of the state vector components on the performance of the SAC in this task. We conducted many different trials, during which, we changed the composition of the stat vector given by the environment to the agent.
We started with the same state vector
(the vector defined in
Section 4.2.2), and we successively removed variables until the agent was no more capable of learning the task. We wanted to know the maximum number of variables we could remove from the state vector while still being able to fulfill the control task. The task became harder for the agent when it obtained less information. If the SAC was able to learn the task with fewer variables, this meant that some sensors could be removed from the RexROV 2, and it allowed identifying which sensors were the more useful for understanding the AUV dynamics.
In this section, we display a selection of all the trials we performed (only the most interesting trials are shown). All of the training and testing simulations were performed in real-time.
5.1. Initial State Vector
We first trained the SAC algorithm with the new changes described previously but with the same state vector
as for the task of
Section 4.2.2:
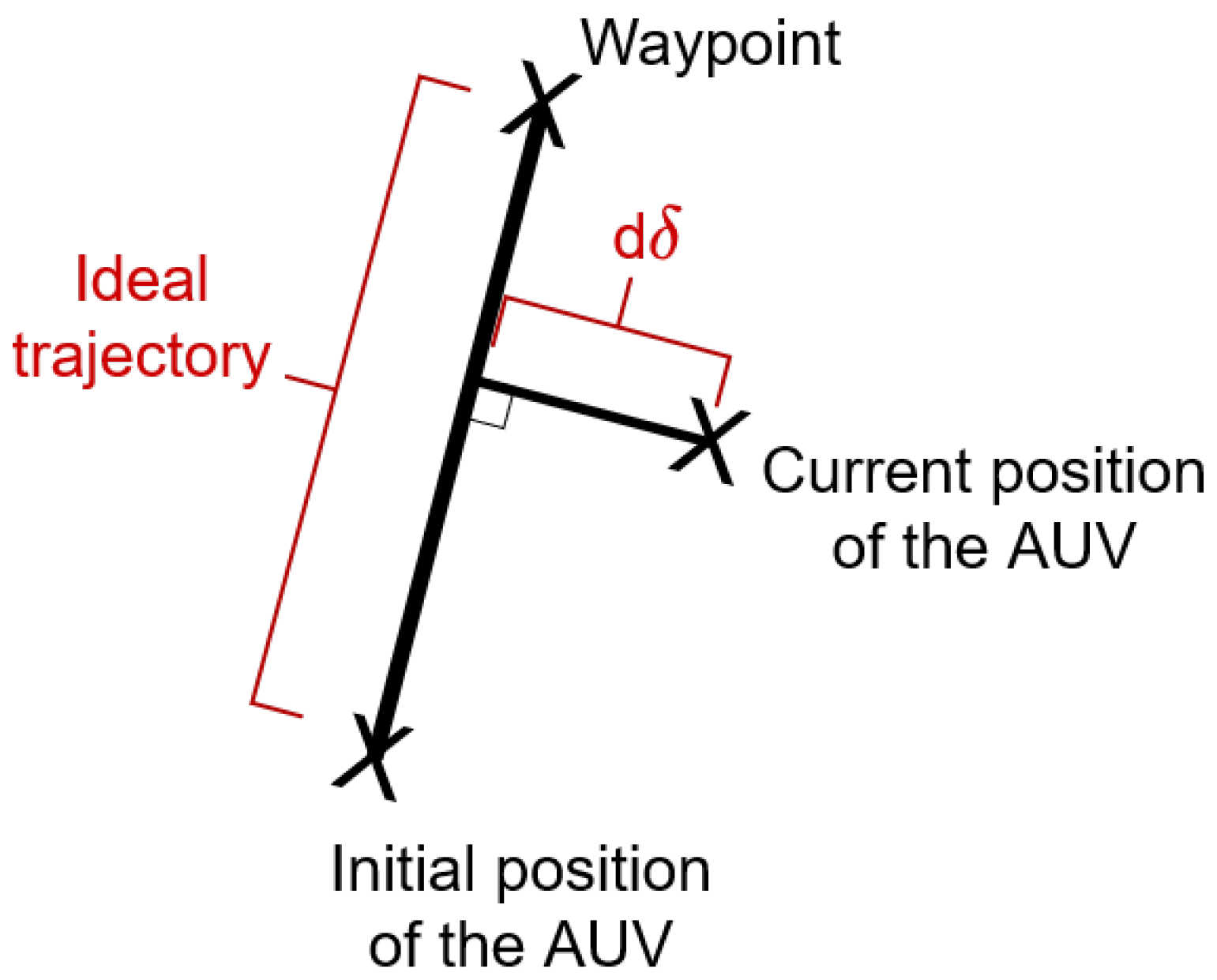
Let us recall that is the position vector of the RexROV 2, is its orientation vector (the Euler angles), is the linear velocity vector, is the angular velocity vector, , and are the tracking errors of the pitch and the yaw angles, respectively, is the error between the position vector and the position vector of the waypoint, and is the action vector of the inputs sent at the previous time step. This vector is composed of 23 dimensions.
We trained the SAC algorithm for 2700 training episodes, and we had the following number of successes.
Number of successes for every 100 episodes: [12, 60, 85, 95, 99, 99, 98, 99, 98, 100, 100, 100, 100, 100, 99, 100, 100, 100, 99, 99, 100, 100, 100, 100, 99, 100, 100]
The number of episodes after which we stopped the training phase varied during the following trials since there was no rule of thumb for the number of training episodes needed for this task. Here, the SAC managed to converge rapidly towards good behavior. It reached an 85% success rate after only 300 episodes. This shows that the SAC algorithm is sample efficient, which means that it needs a few episodes to learn this control task.
After the training process, we tested three different models to see how the number of training episodes performed by the agent could affect its performance during the testing phase. We tested a model after 600 training episodes, a model after 1300 training episodes, and a model after 2500 training episodes. These three models of the SAC algorithm were compared with the PID controller during 1000 episodes, which corresponds to 500 testing episodes for each controller. Here are the three results (
Table 1,
Table 2 and
Table 3).
These tables display satisfying results. For each metric, we highlighted the controllers with the best results (highlighted in green). First, the primary goal of the task was fulfilled: for the SAC to have a success rate superior or equal to the PID controller. On this run, model 600 had the same success rate as the PID (within 0.2%), and models 1300 and 2500 performed slightly better (1% and 1.2% better, respectively). Moreover, even if the PID remained closer to the ideal trajectory (the mean and SD of of the PID controller were always lower than of the SAC), the mean of was always lower than the PID. The SAC managed to save more energy than the PID controller, which was our secondary objective for this task. These observations stayed true when we took into account all episodes, but also with only the successful episodes (it corresponded to the metrics with the tag Success). The models 1300 and 2500 also had slightly fewer collision failures and took smaller numbers of time steps to finish their test episodes, which was always good (even if it was not the focus of this work).
The SAC performed as well as the PID controller in terms of success, and even better for some models. However, we did not expect to have better energy consumption while having such success rates. This means that the SAC algorithm was able to find a good trade-off between fulfilling the control task (reaching waypoints) and saving energy (generating smaller cumulative inputs during each episode).
5.2. Removing the Measure of the Position Vector, the Euler Angles, and the Pitch Tracking Error
After a successful trial where we only removed the position vector
of the AUV from the state vector of the SAC (this trial is not detailed here), we then removed the measure of the Euler angles, given by the orientation vector
, and the pitch tracking error
(the number of pitch angles lacking to make the AUV point towards the waypoint).
became a 16-dimensional vector:
After 3400 training episodes, the SAC had the following number of successes during the training phase:
Number of successes for every 100 episodes: [43, 100, 98, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 99, 99, 100, 100, 100, 99, 100, 100, 100, 100, 99, 100, 100, 99, 100, 99, 100, 100, 100, 100]
The SAC algorithm was faster at converging towards good behavior than during the trial of
Section 5.1. It had more than 40% during the first 100 episodes, and it managed to reach a 100% success rate after only 200 episodes.
The SAC algorithm had good learning abilities on this control task since the agent managed to learn the task faster than during the previous trial, but with less information given from the environment.
The models selected after 600, 1300, and 2500 training episodes were tested and compared with the PID controller. Here are the results of these three test phases (
Table 4,
Table 5 and
Table 6).
The three models had better success and collision rates than the PID controller, and the model trained on 1300 episodes even achieved a success rate of 99.4%, meaning that it did not reach the waypoint during the three test episodes. The PID controller had a better mean and a better SD for the distance error . The models 600 and 1300 managed to save more energy than the PID since they had a lower mean , but for the first time, the PID managed to beat model 2500 on this criterion (on all episodes and successful episodes).
These results show that the SAC algorithm does not need to know its orientation vector or the pitch tracking error to perform the task. The only angle it needs to know is the yaw tracking error . It can also control the RexROV 2 without knowing its true global position vector. However, it still needs to know its position relative to the waypoint, given by the error position vector .
5.3. Removing the Measure of the Angular and the Linear Speeds
After a successful trial where we only removed the angular velocity vector
(this trial is not detailed here), we removed the linear velocity vector
. The vector
now has 10 dimensions:
After 2500 training episodes, the SAC had the following number of successes during the training phase:
Number of successes for every 100 episodes: [1, 26, 48, 76, 78, 87, 89, 90, 72, 77, 81, 85, 89, 90, 91, 95, 96, 96, 62, 68, 24, 47, 45, 61, 46]
The SAC never reached a success rate of 100% during this training phase, but it managed to have more than a 95% success rate several times.
Since the training phase was less successful than during the previous trials, we only tested one model. We chose to test model 1750 by examining the success rates obtained during the learning process. The SAC had a 96% success rate in 200 successive episodes, between episodes 1601 and 1800. Here are the corresponding results (
Table 7).
Model 1750 reached a 97.6% success rate. Even if the PID performed slightly better (with a difference of 1.6% between the two success rates), it was still an excellent performance from the SAC algorithm. The success rate did not reach the symbolic 100% barrier during this training phase, but the task was performed just as well as in the previous testing phases. The PID controller saved more energy than the SAC on all episodes but it was the contrary if we took into account only the successful episodes. For us, the mean of computed on the successful episodes was more meaningful than when it was computed on all of the episodes. It allowed us to better compare the tracking abilities of the controllers, without being biased by the episodes where the AUV went outside of the box, or stagnated without reaching the target waypoint. We can also note that the SAC had surprisingly better success rates during the testing phase than during the training phase, where it reached 96% at most.
The SAC algorithm was still able to learn the waypoint tracking task and understand the AUV dynamics without any velocity information (angular or linear).
5.4. Removing the Values of the Previous Inputs
For this last trial, we removed the vector of the past inputs
from
, leaving the state vector with only four dimensions:
After 2500 training episodes, the SAC had the following number of successes during the training phase:
Number of successes for every 100 episodes: [6, 16, 45, 67, 65, 70, 70, 65, 68, 68, 71, 77, 52, 53, 54, 58, 45, 45, 57, 36, 53, 73, 63, 63, 46].
The learning process was not more than 80%, so we cannot say that the SAC agent converged towards satisfactory behavior. However, it still reached more than 75% and it is still worth it to compare it with the PID controller. We can assume that this state vector configuration made the agent struggle during the training phase.
Similar to the previous trial, we only tested model 1100. During the training phase, the success rate reached 71% before episode 1100 and 77% afterward. Here is the corresponding results table (
Table 8).
Compared to the results of
Section 5.3 (where the SAC obtained a success rate of 97.6%),
removing the past inputs from the state vector made the success drop to 75.4%. The collision and timeout failure rates strongly increased, which further confirmed the drop in performance. Moreover,
the SAC-based controller was not able to save more energy than the PID controller, making it worst than the PID in all of the criteria.
Even if the PID performed better in this trial, the SAC algorithm managed to have sub-optimal behavior with a state vector of only four dimensions. A success rate of 75.4% still showed that the SAC algorithm was able to learn the task and understand the dynamics of the RexROV 2 with a minimal amount of information. Its performance was just not good enough to challenge the PID controller.
7. Conclusions and Openings
The sensitivity analysis of the state vector presented in this work allowed analyzing which sensors are mandatory to allow the SAC algorithm to control the RexROV 2. After having successfully challenged the PID controller inside marine robotics simulations, our next objective will be to embed our SAC-based controller in a real-world AUV.
We had this next step in mind since the beginning of this work and we implemented choices allowing to facilitate the transfer towards real-world robots.
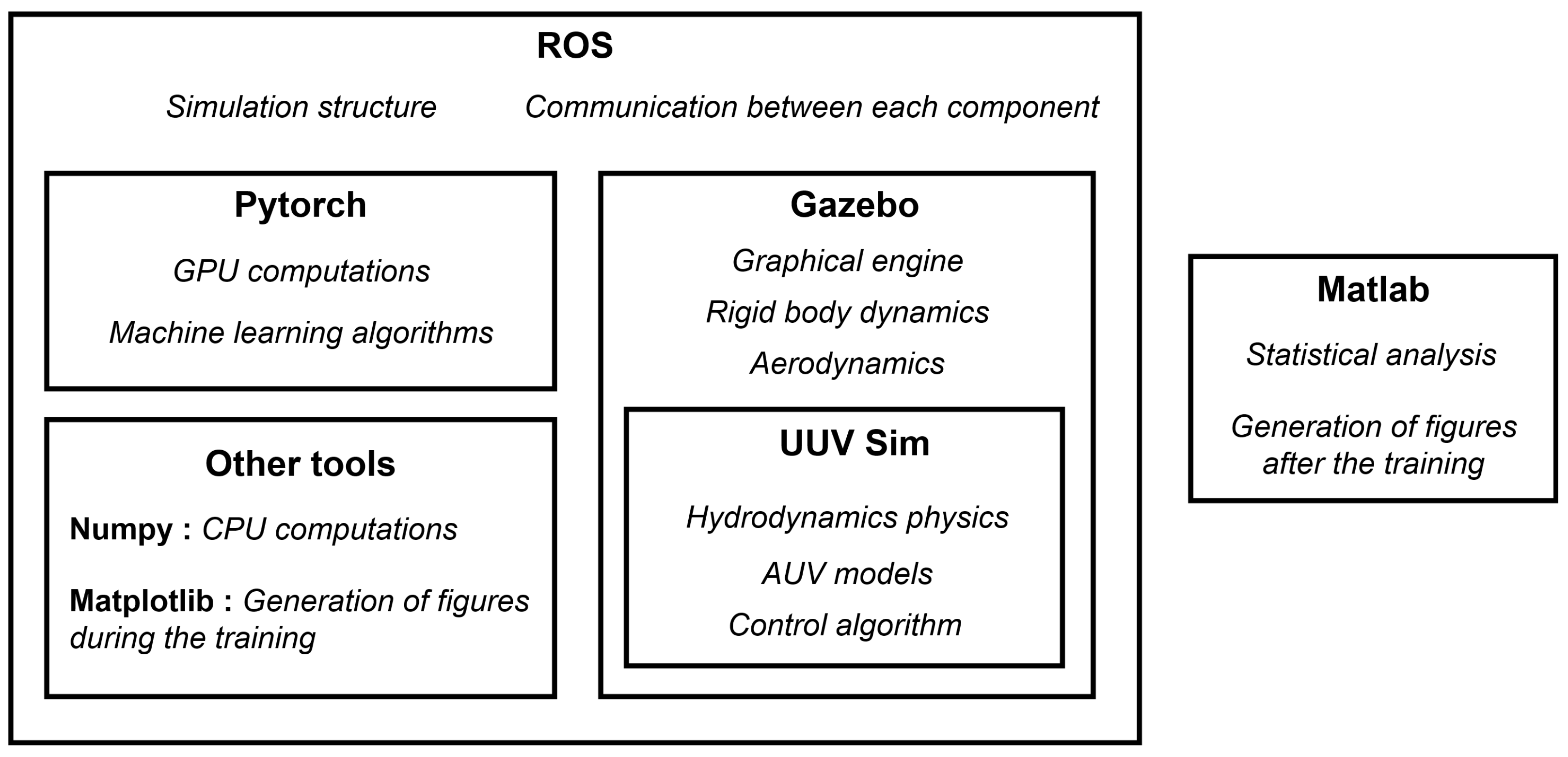
First, we coded our controllers using ROS middleware (mentioned in
Section 4.1.1), which is known for providing great flexibility and allowing to easily transfer its software components (called
nodes) towards embedded systems. Its component-based architecture also allows easily changing the type of robot, sensors, actuators, as well as the algorithms used in the GNC system. We will only have to change several hyperparameters to make the transfer from the simulation to the real world, even if the real AUV is not the same as the RexROV 2.
Moreover, we set our simulations to be computed in real-time. After many observations, we noticed that changing the speed at which the simulation was computed could change the behavior of the SAC algorithm. This was due to the fact that ROS executed its nodes in an asynchronous way. When the simulation is computed at a different speed, the SAC (executed in an independent node) samples the environment at a different rate than before the change, and its actions are not maintained during the same number of time steps.
This means that a DRL-based controller, which obtained good results during the simulated testing phases, will not necessarily perform the same when it is embedded in a real robotic platform. From the point of view of the agent of the DRL algorithm, the environment does not act the same as during its training phase.
Therefore, executing the simulation in real-time guarantees that the behavior of the SAC-based controller will be the same in a real-world robot as during our simulation results.
In terms of architecture, the three neural networks (NNs) implemented by the SAC algorithm (detailed in
Section 4.2.2) are shallow networks. They are all composed of only two hidden layers of 256 neurons. These are light NNs in terms of the number of parameters needed to be updated during the learning process.
Moreover, the smaller the state vector is (as in our results), the smaller the input layer of these NNs will be. This means that less memory usage and computational resources will be needed.
These two elements allow the SAC algorithm to be embedded inside platforms with less memory (RAM) and computational (CPU) resources. Thus, this DRL-based controller can be applied to a broader range of robots. For an example of the memory usage used by this DRL-based controller, the SAC algorithm used 3.6 GB of RAM and 600 MB of V-RAM (the RAM dedicated to the GPU).
We included in our pipeline more ideas taken from works about the sim-to-real transfer of deep reinforcement learning algorithms [
90]. This includes elements from the subfields of domain randomization, domain adaptation, imitation learning, meta reinforcement learning, and knowledge distillation.
For example, the concept behind domain randomization [
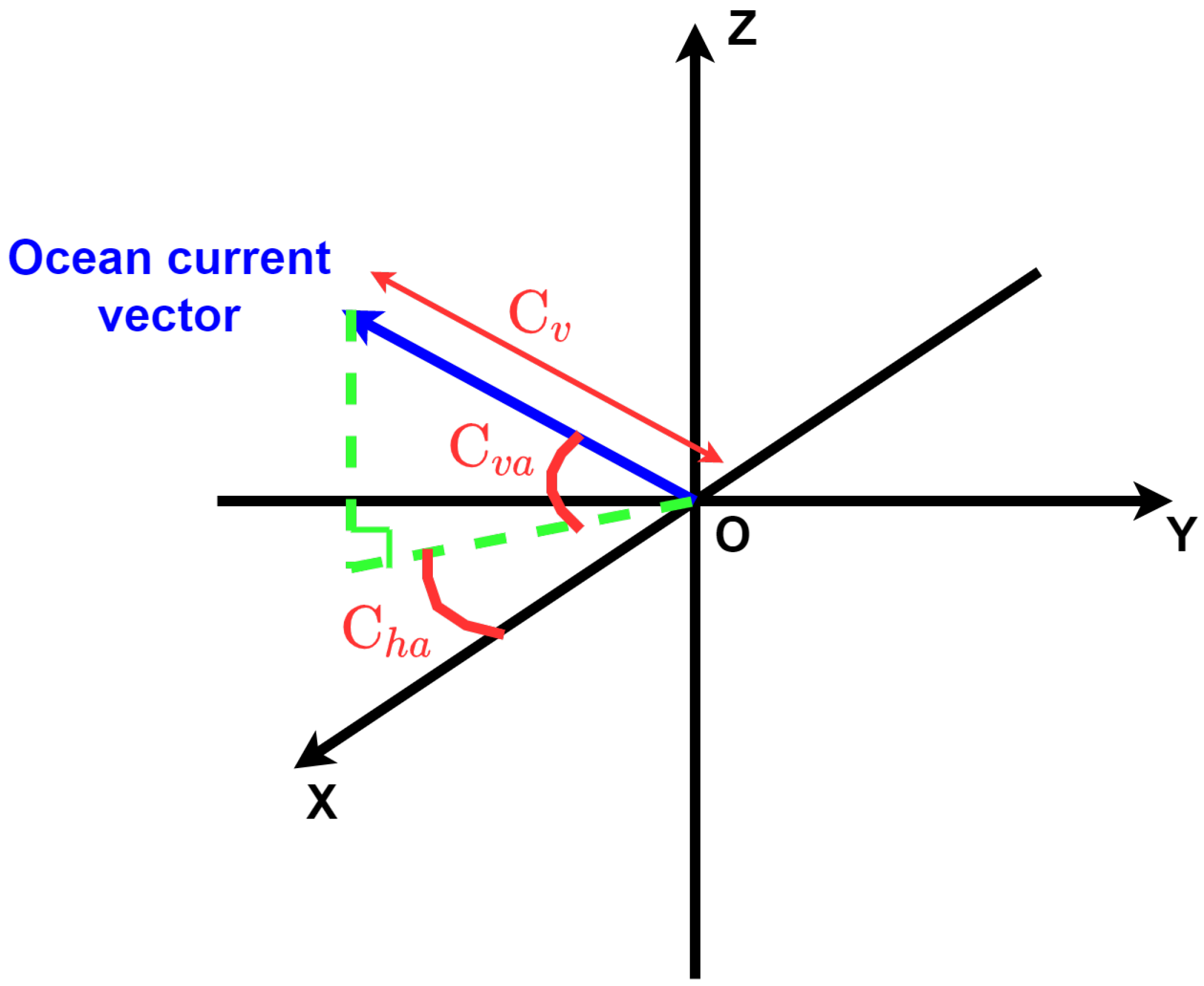
91] is to highly randomize the simulated environment to cover the real distribution of the real-world data despite the bias between the model world and the real world, instead of having to find the most realistic simulation possible (which can be a hard (and time-consuming) task). In our work, we already randomized the ocean currents and the location of the target waypoints, but we could go further by randomizing the starting point of the AUV and iteratively adding new random elements, such as rocks or other vehicles. We could also successively simulate different types of probability distributions, not only continuous uniform distributions.
Domain adaptation is another interesting subfield belonging to the transfer learning approaches [
92]. The idea is to transfer the knowledge between a source domain where many data are available to a target domain where data are lacking. Of course, the source and target domains have to be closely related. The features used in both tasks are extracted from their respective feature spaces and are then used inside a unified feature space to facilitate the transfer. In our example, the source domain would be the simulated environment and the target domain would be the real-world environment. This would allow transferring our controller from the simulation to the real world with a few real-world training episodes, thanks to the domain application.
The fact that sim-to-real techniques have already been successfully tested for the SAC algorithm, for example in [
93,
94,
95], is encouraging for the transfer of our SAC-based controller to a real AUV.
If we look at our work from a long-term perspective—our work falls within the project of facilitating the control of AUVs thanks to the use of ML. The proposals made here represent the first step towards this goal and allow identifying the most important aspects to handle during the implementation of RL algorithms for the end-to-end control of AUVs. We believe that this goal can be achieved thanks to the progressive integration of elements taken from the control theory or robotics inside the ML methods. We prefer to have the best of both worlds—the adaptability and the innovative control approaches achieved by the ML, as well as the guarantees and the knowledge provided by the control theory and robotics. Some works found in the literature developed RL methods based on elements taken from the control theory and show that this unification is possible. The integration of expert knowledge in ML could result in the creation of hybrid methods. Specifically, we prefer to test methods from a safe RL [
96,
97], to combine safety approaches with the SAC algorithm. These methods could add safety and stability guarantees to the learning process.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}