1. Introduction
Multi-sensor fusion is performed in many fields, such as autonomous driving and robotics. A single sensor does not guarantee reliable recognition in complex and varied scenarios [
1]. Therefore, it is difficult to cope with various autonomous driving situations using only one sensor. Conversely, fusing two or more sensors supports reliable environmental perception around the vehicle. In multi-sensor fusion, one sensor compensates for the shortcomings of the other sensor [
2]. In addition, multi-sensor fusion expands the detection range and improves the measurement density compared with using a single sensor [
3]. Studies based on multi-sensor fusion include 3D object detection, road detection, semantic segmentation, object tracking, visual odometry, and mapping [
4,
5,
6,
7,
8,
9]. Moreover, most large datasets that are built for autonomous driving research [
10,
11,
12,
13] provide data measured by at least two different sensors. Importantly, multi-sensor fusion is greatly affected by the calibration accuracy of the sensors used. While the vehicle is driving, the pose or position of the sensors mounted on the vehicle may change for various reasons. Therefore, for multi-sensor fusion, it is essential to perform the online calibration of sensors to accurately recognize changes in sensor pose or changes in the positions of the sensors.
Extensive academic research on multi-sensor calibration has been performed [
2,
3]. Many traditional calibration methods [
14,
15,
16,
17] use artificial markers, including checkerboards, as calibration targets. The target-based calibration algorithms are not suitable for autonomous driving because they involve processes that require manual intervention. Some of the calibration methods currently used focus on fully automatic and targetless online self-calibration [
3,
18,
19,
20,
21,
22,
23,
24]. However, most online calibration methods perform calibration only when certain conditions are met, and their calibration accuracy is not as high as the target-based offline methods [
1]. The latest online calibration methods [
1,
2,
25,
26,
27] based on deep learning use optimization through gradient descent, large-scale datasets, and CNNs to overcome the limitations of the previous online methods. In particular, the latest research based on CNNs has shown suitable results. Compared with previous methods, CNN-based online self-calibration methods do not require strict conditions and provide excellent calibration accuracy when they are run online.
Many CNN-based LiDAR-camera calibration methods use an image for calibration. In this case, the point cloud of the LiDAR is projected onto the image. Then, 2D convolution kernels are used to extract the features of the inputs.
In this study, we propose a CNN-based multi-sensor online self-calibration method. This method estimates the values of six parameters that describe rotation and translation between sensors that are capable of measuring 3D space. The combinations of sensors that are subject to calibration in our proposed method are: a LiDAR and stereo camera and a LiDAR and LiDAR. One of the two sensors is set as the reference sensor and the other as the target sensor. In the combination of LiDAR and stereo camera, the stereo camera is set as the reference sensor.
The CNN we propose is a network that uses voxels instead of using image features. Therefore, we convert the stereo image into 3D points called pseudo-LiDAR points to feed the stereo image into this network. Pseudo-LiDAR points and actual LiDAR points are expressed in voxel spaces through voxelization. Then, 3D convolution kernels are applied to the voxels to generate features that can be used for calibration parameter regression. In particular, the attention mechanism [
28] included in our proposed network confirms the correlation between the input information of the two sensors. The research fields that use voxels are diverse, including shape completion, semantic segmentation, multi-view stereoscopic vision, object detection, etc. [
29,
30,
31,
32].
The amount of data in public datasets is insufficient to perform online self-calibration. Therefore, existing studies have assigned random deviations to the values of known parameters and have evaluated the performance of online self-calibration based on how accurately the algorithm proposed in the respective study predicts this deviation. This approach is commonly referred to as miscalibration [
1,
2,
25]. To sample the random deviation, we choose the rotation range and translation range as ±20° and ±1.5 m, respectively, as in [
1]. In this study, we train five networks on a wide range of miscalibrations and apply iterative refinement to the outputs of the five networks and temporal filtering over time to increase the calibration accuracy. The KITTI dataset [
10] and Oxford dataset [
12] are used to conduct the research of the proposed method. The KITTI dataset is used for online LiDAR-stereo camera calibration, and the Oxford dataset is used for online LiDAR-LiDAR calibration.
The rest of this paper is organized as follows.
Section 2 provides an overview of existing calibration studies.
Section 3 describes the proposed method.
Section 4 presents the experimental results for the proposed method, and
Section 5 draws conclusions.
3. Methodology
This section describes the preprocessing of stereo images and LiDAR point clouds, the structure of our proposed network, the loss function for network training, and the postprocessing of the network output. These descriptions are commonly applied to the calibration of the LiDAR-stereo camera and LiDAR-LiDAR combinations. We chose a LiDAR as the target sensor in the LiDAR-stereo camera and LiDAR-LiDAR combinations, and the rest of the sensors as the reference sensor.
3.1. Preprocessing
In order to perform online self-calibration with the network we designed, several processes, including data preparation, were performed in advance. This section describes these processes. We assume that sensors targeted for online calibration are capable of 3D measurement. Therefore, we use point clouds that are generated by these sensors. In the LiDAR-LiDAR combination, this premise is satisfied, but in the case of the LiDAR-stereo camera combination, this premise is not satisfied, so we obtain a 3D point cloud from the stereo images. The conversion of the stereo depth map to 3D points and the removal of the 3D points, which are covered in the next two subsections, are not required for the LiDAR-LiDAR combination.
3.1.1. Conversion of Stereo Depth Map to 3D Points
A depth map is built from stereo images through stereo matching. In this paper, we obtain the depth map using the method in [
33] that implements semi-global matching [
34]. This depth map composed of disparities is converted to 3D points, which are called pseudo-LiDAR points, as follows:
where
,
, and
are the camera intrinsic parameters,
and
are pixel coordinates,
is the baseline distance between cameras, and
is the disparity obtained from the stereo matching.
3.1.2. Removal of Pseudo-LiDAR Points
The pseudo-LiDAR points are too many in number compared with the points measured by a LiDAR. Therefore, we, in this paper, reduce the quantity of pseudo-LiDAR points through a spherical projection, which is implemented using the method presented in [
35] as follows:
where (
X,
Y,
Z) are 3D coordinates of a pseudo-LiDAR point, (
,
) are the angular coordinates, (
,
) are the height and width of the desired projected 2D map,
is the range of each point, and
is the vertical field of view (FOV) of the sensor. We set
to 3° and
to −25°. Here, the range 3° to −25° is the vertical FOV of the LiDAR used to build the KITTI benchmarks [
10]. The pseudo-LiDAR points become a 2D image via this spherical projection. Multiple pseudo-LiDAR points can be projected onto a single pixel in the 2D map. In this case, only the last projected pseudo-LiDAR point is left, and the previously projected pseudo-LiDAR points are removed.
3.1.3. Setting of Region of Interest
Because the FOVs of the sensors used are usually different, we determine the region of interest (ROI) of each sensor and perform calibration only with data belonging to this ROI. However, the ROI cannot be determined theoretically but can only be determined experimentally. We determine the ROI of the sensors by looking at the distribution of data acquired with the sensors.
We provide an example of setting the ROI using data provided by the KITTI [
10] and Oxford [
12] datasets. For the KITTI dataset, which was built using a stereo camera and LiDAR, the ROI of the stereo camera is set to [Horizon: −10 m–10 m, Vertical: −2 m–1 m, Depth: 0 m–50 m], and the ROI of the LiDAR is set to the same values as the ROI of the stereo camera. For the Oxford dataset, which was built using two LiDARs, the ROI of the LiDAR is set to [Horizon: −30–30 m, Vertical: −2–1 m, Depth: −30–30 m].
3.1.4. Transformation of Point Cloud of Target Sensor
In this paper, the miscalibration method used in previous studies [
1,
2,
25] is used to perform the calibration of the stereo camera-LiDAR and LiDAR-LiDAR combination. In the KITTI [
10] and Oxford [
12] datasets we use, the values of six extrinsic parameters between two heterogeneous sensors and the 3D point clouds generated by them are given. Therefore, we can transform the 3D point cloud created by one sensor into a new 3D point cloud using the values of these six parameters. If we assign arbitrary deviations to these parameters, we can retransform the transformed point cloud in another space. At this time, if a calibration algorithm accurately finds the deviations that we randomly assign, we can move the retransformed point cloud to the position before the retransformation.
In order to apply the aforementioned approach to our proposed online self-calibration method, a 3D point
measured by the target sensor is transformed by Equation (3) as follows:
where
P′ is the transformed point of
P, and superscript
represents the transpose.
and
are expressed with homogeneous coordinates.
, described in Equation (4), is the transformation matrix we want to predict with our proposed method.
is used as the ground truth when the loss for training is calculated. In Equation (5), each of the parameters
,
, and
describes the angle rotated about the
x-,
y-, and
z-axes between the two sensors. In Equation (6),
,
, and
describe the relative displacement between two sensors along the
x-,
y-, and
z-axes. In this study, we assume that the values of the six parameters
,
,
,
,
, and
are given. In Equations (7) and (8), the parameters
,
,
,
,
, and
represent the random deviations for
,
,
,
,
, and
, respectively. Each of these six deviations is sampled randomly with equal probability within a predefined range of deviations described next. In Equations (5)–(8),
and
are rotation matrices and
and
are translation vectors. The transformation by Equation (3) is performed only on points belonging to a predetermined ROI of the target sensor.
We set the random sampling ranges for
,
,
,
,
, and
the same as in previous studies [
1,
25] as follows: (rotational deviation: −θ–θ, translation deviation: −τ–τ), Rg1 = {θ: ±20°, τ: ±1.5 m}, Rg2 = {θ: ±10°, τ: ±1.0 m}, Rg3 = {θ: ±5°, τ: ±0.5 m}, Rg4 = {θ: ±2°, τ: ±0.2 m}, and Rg5 = {θ: ±1°,τ: ±0.1 m}. Each of Rg1, Rg2, Rg3, Rg4, and Rg5 set in this way is used for training each of the five networks named Net1, Net2, Net3, Net4, and Net5. One deviation range is assigned to one network training. Training for calibration starts with Net1 assigned to Rg1, and it continues with networks assigned to progressively smaller deviation ranges. The network mentioned here is described in
Section 3.2.
3.1.5. Voxelization
We first perform a voxel partition by dividing the 3D points obtained by the sensors into equally spaced 3D voxels, as was performed in [
36]. This voxel partition requires a space that limits the 3D points acquired by a sensor to a certain range. We call this range a voxel space. We consider the length of a side of a voxel, which is a cube, as a hyper-parameter, and denote it as S. In this paper, the unit of S is expressed in cm. A voxel can contain multiple points, of which up to three are randomly chosen, and the rest are discarded. Here, it is an experimental decision that we leave only up to three points per voxel. Referring to the method in [
37], the average coordinates along the x-, y-, and z-axes of the points in each voxel are then calculated. We build three initial voxel maps,
Fx,
Fy, and
Fz, using the average coordinates for each axis. For each sensor, these initial voxel maps become the input to our proposed network.
Section 3.2 describes the network.
In this paper, we set the voxel space to be somewhat larger than the predetermined ROI of the sensor, considering the range of deviation. For example, in the case of the KITTI dataset, the voxel space of the stereo input is set as [horizontal: −15–15 m, vertical: −15–15 m, depth: 0–55 m], and the voxel space of the LiDAR input is set to the same size as the voxel space of the stereo input. In contrast, the voxel space of the 3D points generated by the two LiDARs in the Oxford dataset is set to [width: −40–40 m, height: −15–15 m, depth: −40–40 m]. The points outside of the voxel space are discarded.
3.2. Network Architecture
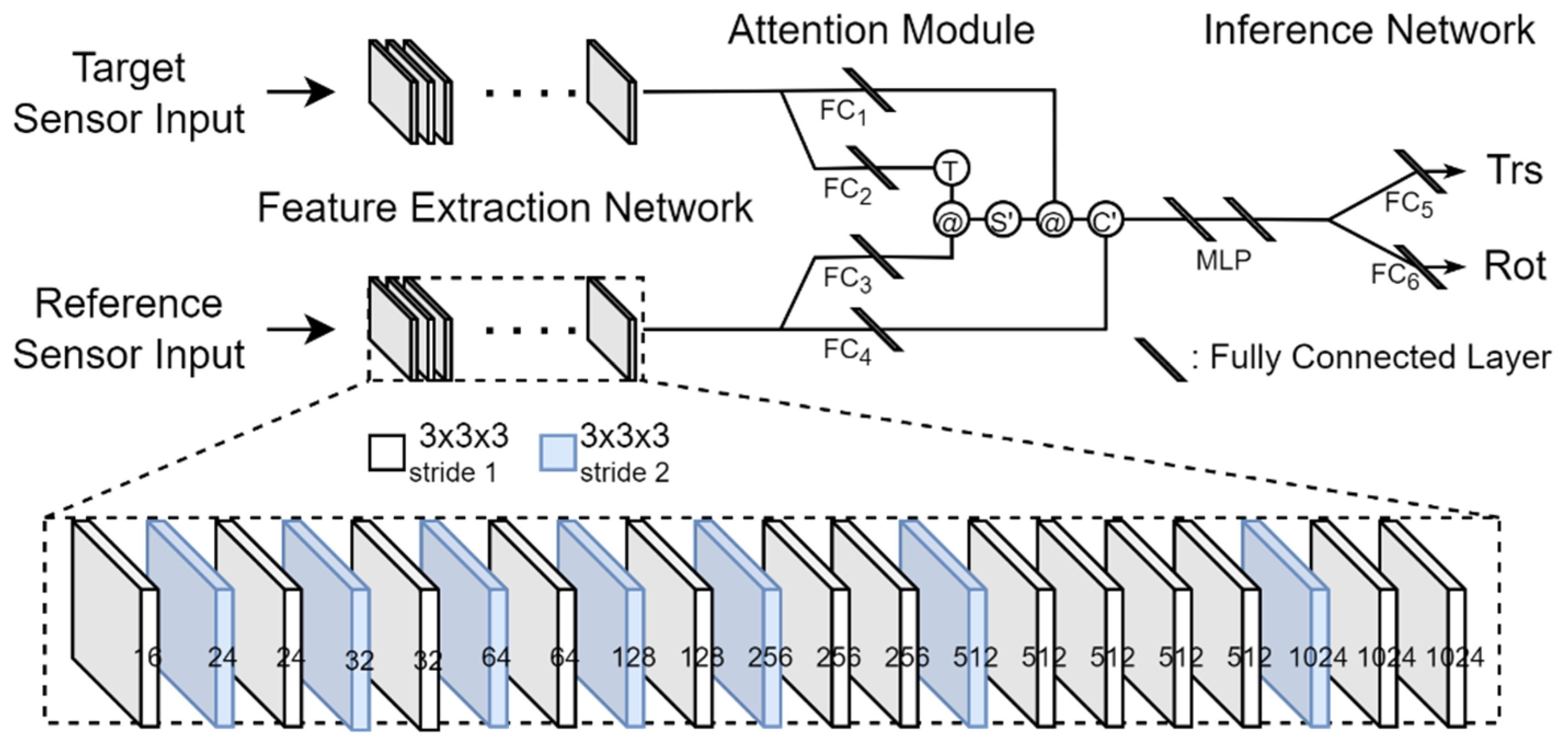
We propose a network of three parts, which are referred to as a feature extraction network (FEN), an attention module (AM), and an inference network (IN). The overall structure of the proposed network is shown in
Figure 1. The input of this network is the
Fx,
Fy, and
Fz for each sensor built from voxelization, and the output is seven numbers, three of which are translation-related parameter values, and the other four are rotation-related quaternion values. The network is capable of end-to-end training because every step is differentiable.
3.2.1. FEN
Starting from the initial input voxel maps
Fx,
Fy, and
Fz, FEN extracts features for use in predicting calibration parameters by performing 3D convolution on 20 layers. The number of layers, the size of the kernel used, the number of kernels used in each layer, and the stride applied in each layer are experimentally determined. The kernel size is 3 × 3 × 3. There are two types of stride, 1 and 2, which are used selectively for each layer. The number of kernels used in each layer is indicated at the bottom of
Figure 1. This number corresponds to the quantity of the feature volume created in the layer. In the deep learning terminologies, this quantity is called channels. Convolution is performed differently depending on the stride applied to each layer. When stride 1 is applied, submanifold convolution [
38] is performed, and when stride 2 is applied, general convolution is performed. General convolution is performed on all voxels with or without a value, but submanifold convolution is performed only when a voxel with a value corresponds to the central cell of the kernel. In addition, batch normalization (BN) [
39] and rectified linear unit (ReLU) activation functions are sequentially applied after convolution in the FEN.
We want the proposed network to perform robust calibration for large rotational and translational deviations between two sensors. To this end, a large receptive field is required. Therefore, we included seven layers with a stride of 2 in the FEN.
The final output of the FEN is 1024 feature volumes. The number of cells in the feature volume depends on the size of the voxel, but we let V be the number of cells in the feature volume. At this time, because each feature volume can be reconstructed as a V-dimensional column vector, we represent 1024 feature volumes as a matrix F of dimension V × 1024. The outputs of FENs for the reference and target sensors are denoted by Fr and Ft, respectively.
3.2.2. AM
It is not easy to match the features extracted from the FEN through convolutions because the point clouds from the LiDAR-stereo camera combination are generated differently. Even in the LiDAR-LiDAR combination, if the FOVs of the two LiDARs are significantly different, it is also not easy to match the features extracted from the FEN through convolutions. Moreover, because the deviation range of rotation and translation is set large to estimate calibration parameters, it becomes difficult to check the similarity between the point cloud of the target sensor and the point cloud of the reference sensor.
Inspired by the attention mechanism proposed by Vaswani et al. [
28], we solve these problems: we design an AM that implements the attention mechanism, as shown in
Figure 1. The AM calculates an attention value for each voxel of the reference sensor input using the following procedure.
The AM has four fully connected layers (FCs): FC
1, FC
2, FC
3, and FC
4. A feature is input into these FCs, and a transformed feature is output. We denote the outputs of FC
1, FC
2, FC
3, and FC
4 as matrices M
1, M
2, M
3, and M
4, respectively. Each FC has 1024 input nodes. Here, the number 1024 is the number of feature volumes extracted from the FEN. The FC
1 and FC
4 have G/2 output nodes, and the FC
2 and FC
3 have G output nodes. These FCs transform 1024 features to G or G/2 features. Here, G is a hyper-parameter. If the sum of the elements in a row of matrix F, which is the output of the FEN, is 0, the row vector is not input to FC. We apply layer normalization (LN) [
40] and the ReLU function to the output of these FCs so that the final output becomes nonlinear. The output M
2 of FC
2 is a matrix of dimension
Vt × G, and the output M
3 of FC
3 is a matrix of dimension
Vr × G. Here,
Vr and
Vt are the number of rows in which there is at least one element with a feature value among the elements in each row of
Fr and
Ft, respectively. Therefore,
Vr and
Vt can be different for each input. However, we fix the values of
Vr and
Vt because the number of input nodes of the multi-layer perceptron (MLP) of the IN following the AM cannot be changed every time. In order to fix the values of
Vr and
Vt, we input all the data to be used in the experiments into the network and set the values when they are the largest, but we make them a multiple of 8. This is because
Vr and
Vt are also hyper-parameters. If the actual
Vr and
Vt are less than the predetermined
Vr and
Vt, the elements of the output matrices of FCs will be filled with zeros. The output M
1 of FC
1 is a matrix of dimension
Vt × G/2, and the output M
4 of FC
4 is a matrix of dimension
Vr × G/2.
An attention score is obtained from the dot product of a row vector of M3 and a column vector of . This score is the same as the cosine similarity. The matrix AS is obtained through the dot products of all row vectors of M3 and all column vectors of are called an attention score matrix. The dimension of the matrix AS (AS = M3) is Vr × Vt.
We apply the softmax function to each row vector of AS and obtain the attention distribution. The softmax function calculates the probability of each element of the input vector. We call this probability an attention weight, and the matrix obtained by this process is the attention weight matrix AW of dimension Vr × Vt.
An attention value is obtained from the dot product of a row vector of AW and a column vector of the matrix M1. A matrix AV obtained through the dot products of all row vectors of AW and all column vectors of M1 is called an attention value matrix. The dimension of the matrix AV (AV = AWM1) is Vr × G/2.
Finally, we concatenate the attention value matrix AV and the matrix M4. The resulting matrix from this final process is denoted as AC (AC = [AV M4]) and has dimension Vr × G; this matrix becomes the input to the IN. The reason we set the output dimension of FC1 and FC4 to G/2 instead of G is to save memory and reduce processing time.
3.2.3. IN
The IN infers rotation and translation parameters. The IN consists of an MLP and two fully connected layers, FC5 and FC6. The MLP is composed of an input and an output layer, as well as a single hidden layer. The input layer has Vr × G nodes, and the hidden and output layers have 1024 nodes, respectively. Therefore, when we input AC, the output of the AM, into the MLP, we make AC a flat vector. In addition, this MLP has no bias input, and it uses ReLU as an activation function. Moreover, LN is performed on the weighted sums that are input to nodes in the hidden layer and output layer, and ReLU is applied to the normalization result to obtain the output of these nodes. The output of the MLP becomes the input to the FC5 and FC6. The MLP plays the role of dimension reduction in the input vector.
We do not apply a normalization or an activation function to the FC5 and FC6. FC5 produces three translation-related parameter values, which are , , and , and FC6 produces four rotation-related quaternion values, which are q0, q1, q3, and q4.
3.3. Loss Function
To train the proposed network, we use a loss function as follows:
where
is a regression loss related to rotation,
is a regression loss related to translation, and hyper-parameters
λ1 and
λ2, respectively, are their weights. We use the quaternion distance to regress the rotation. The quaternion distance is defined as:
where · represents the dot product, |·| indicates the norm, and
and
indicate a vector of the quaternion parameters predicted by the network and the ground-truth vector of quaternion parameters, respectively. From
of Equation (4), we obtain the four quaternion values. These four quaternion values are used for rotation regression as the ground truth.
For the regression of the translation vector, the smooth
L1 loss is applied. The loss
is defined as follows:
where the superscripts
p and
gt represent prediction and ground truth, respectively,
is a hyper-parameter and is usually taken to be 1, and |·| represents an absolute value. The parameters
,
and
are inferred by the network, and
,
, and
are obtained from
of Equation (4).
3.4. Postprocessing
3.4.1. Generation of a Calibration Matrix from a Network
Basically, postprocessing is performed to generate the calibration matrix
that is shown in Equation (12). The rotation matrix
and translation vector
in Equation (12) are generated by the quaternion parameters
,
,
, and
, and translation parameters
,
, and
inferred from the network we built, as shown in Equations (13) and (14).
Equation (15) shows how to calculate the rotation angle about each of the x-, y-, and z-axes from the rotation matrix . In Equation (15), (r,c) indicates the row index r and column index c of the matrix . The angle calculation described in Equation (15) is used to convert a given rotation matrix into Euler angles.
3.4.2. Calculation of Calibration Error
To evaluate the proposed calibration system, it is necessary to calculate the error of the predicted parameters. For this, we calculate the transformation matrix
, which contains the errors of the predicted parameters by Equation (16).
and
in Equation (16) are calculated by Equations (3) and (17), respectively. In Equation (17), each of
,
,
,
, and
is a calibration matrix predicted by each of the five networks, Net1, Net2, Net3, Net4, and Net5. The calculation of these five matrices is described in detail in 3.4.3. From
, we calculate the error of the rotation-related parameters using Equation (18) and the error of the translation-related parameters using Equation (19).
In Equations (18) and (19), (r,c) indicates the row index r and column index c of the matrix .
In the KITTI dataset, the rotation angle about the x-axis, the rotation angle about the y-axis, and the rotation angle about the z-axis correspond to pitch, yaw, and roll, respectively. In contrast, in the Oxford dataset, they correspond to roll, pitch, and yaw, respectively.
3.4.3. Iterative Refinement for Precise Calibration
The training uses all five deviation ranges, but the evaluation of the proposed method is performed with randomly sampled deviations only in Rg1, which is the largest deviation range. Using this sampled deviation, the transformation matrix
is formed as shown in Equations (3), (7), and (8). Then, a point cloud prepared for evaluation is initially transformed using Equation (3). By inputting this transformed point cloud into the trained Net1, the values of parameters that describe translation and rotation are inferred. With these inferred values, we obtain the
of Equation (12). This
becomes
. We multiply the initial transformed points by this
to obtain new transformed points, and we input these new transformed points into the trained Net2 to obtain
from Net2. This new
becomes
. In this way, the input points to the current network are multiplied by
, which is the output of the current network, to obtain new transformed points for use as the input to the next network; this process of obtaining new
by inputting them into the next network is repeated until Net5. For each point cloud prepared for evaluation as described above, a calibration matrix (
,
i = 1,···,5) is obtained from each of the five networks, and the final calibration matrix
is obtained by multiplying the calibration matrices as shown in Equation (17). The iterative transformation process of the point cloud for evaluation as described above is expressed as follows:
3.4.4. Temporal Filtering for Precise Calibration
Calibration performed with only a single frame can be vulnerable to various forms of noise. According to [
25], this problem can be improved by analyzing the results over time. For this purpose, N. Schneider et al. [
25] check the distribution of the results over all evaluation frames while maintaining the value of the sampled deviation used for the first frame. They take the median over the whole sequence, which enables the best performance on the test set. They sample the deviations from Rg1. They repeat 100 runs of this experiment, keeping the sampled deviations until all test frames are passed and resampling the deviations at the start of a new run.
It is good to analyze the results obtained over multiple frames. However, applying all the test frames to temporal filtering has a drawback in the context of autonomous driving. In the case of the KITTI dataset, the calibration parameter values are inferred from the results obtained from processing about 4500 frames, which takes a long time. It is also difficult to predict what will happen during this time. Therefore, we reduce the number of frames to use for temporal filtering and randomly determine the start frame for filtering among these frames. We set the bundle size of frames to 100 and performed quantitative analysis by taking the median from 100 results obtained by applying this bundle. The value of parameters from
for each frame is obtained using Equations (14) and (15). The basis for setting the bundle size is given in
Section 4.3.3.
4. Experiments
There are several tasks, such as data preparation in training and evaluation of the proposed calibration system. The KITTI dataset provides images captured with a stereo camera and point clouds acquired using a LiDAR. The dataset consists of 21 sequences (00 to 20) from different scenarios. The Oxford dataset provides point clouds acquired using two LiDARs. In addition, both datasets provide initial calibration parameters and visual odometry information.
We used the KITTI dataset for LiDAR-stereo camera calibration. We referred to the method proposed by Lv et al. [
1] in using the 00 sequence (4541 frames) for testing and using the rest (39,011 frames) of the sequences for training. We used the Oxford dataset for LiDAR-LiDAR calibration. Of the many sequences in the Oxford dataset, we used the 2019-01-10-12-32-52 sequence for training and the 2019-01-17-12-32-52 sequence for evaluation. The two LiDARs that were used to build the Oxford dataset were not synchronized. Therefore, we used visual odometry information to synchronize the frames. After the synchronization, the unsynchronized frames were deleted, and our Oxford dataset consisted of 43,130 frames for training and 35,989 frames for evaluation.
We did not apply the same hyper-parameter values to all five networks (Net1 to Net5) because of the large difference in the range of allowable deviations for rotation and translation in Rg1 and Rg5. Because Net5 is trained with Rg5, which has the smallest deviation range, and is applied last in determining the calibration matrix, we trained Net5 using different hyper-parameter values from other networks. Such hyper-parameters included S, Vr, Vt, G, λ1, λ2, and B, which are the length of a side of a voxel, the number of voxels with data among voxels in a voxel space of the reference sensor, the number of voxels with data among voxels in a voxel space of the target sensor, the number of output nodes of the FC2 and FC3 in the AM, the weight of the loss function , the weight of the loss function , and the batch size, respectively.
Through the experiments with the Oxford dataset, we observed that data screening is required to enhance the calibration accuracy. The dataset was built with two LiDARs mounted at the left and right corners in front of the roof of a platform vehicle.
Figure 2 shows a point cloud for one frame in the Oxford dataset. This point cloud contains points generated by scanning the surface of the platform vehicle by LiDARs. We confirmed that the calibrations performed on point clouds containing these points degrade the calibration accuracy. Therefore, to perform calibration after excluding these points, we set a point removal area to [Horizon: −5–5 m, Vertical: −2–1 m, Depth: −5–5 m] for the target sensor and [Horizon: −1.5–1.5 m, Vertical: −2–1 m, Depth: −2.5–1.5 m] for the reference sensor. Experimental results with respect to this region cropping are provided in
Section 4.3.1.
We trained the network for a total of 60 epochs. We initially set the learning rate to 0.0005 and halved it when the epochs reached 30, and we halved it again when the epochs reached 40. The batch size
B was determined to be within the limits allowed by the memory of the equipment used. We used one NVIDIA GeForce RTX 2080Ti graphic card for all our experiments. Adam [
41] was used for model optimization, and hyper-parameters
= 0.9 and
= 0.999 were used.
4.1. Evaluation Using the KITTI Dataset
Figure 3 shows a visual representation of the results for performing calibration on the KITTI dataset using the proposed five networks. In this experiment, we transform a point cloud using the calibration matrix inferred from the proposed network and using the ground-truth parameters given in the dataset. We want to show how consistent these two transformation results are.
Figure 3a,b show the transformation of a point cloud by randomly sampled deviations from Rg1 and the calibrated parameters given in the KITTI dataset, respectively. The left side of
Figure 3c shows the transformation of the point cloud by
predicted by the trained Net1. This result looks suitable, but as shown to the right of
Figure 3c, it can be seen that the points measured on a thin column were projected to positions that deviated from the column. The effect of iterative refinement appears here. Calibration does not end at Net1 but continues to Net5.
Figure 3d shows the transformation of the point cloud by
obtained after performing calibration up to Net5. By comparing the result of
Figure 3d with the result shown in
Figure 3c, we can see that the calibration accuracy is improved: suitable alignment even with the thin column.
Table 1 presents the average performance of calibrations performed without temporal filtering on 4541 frames for testing on the KITTI dataset. From the results shown in
Table 1, we can see the effect of iterative refinement. From Net1 to Net5, the improvements are progressive. Our method achieves an average rotation error of [Roll: 0.024°, Pitch: 0.018°, Yaw: 0.060°] and an average translation error of [X: 0.472 cm, Y: 0.272 cm, Z: 0.448 cm].
Figure 4 shows two examples of error distribution for individual components by means of boxplots. From these experiments, we confirmed that temporal filtering provides suitable calibration results regardless of the amount of arbitrary deviation. The dots shown in
Figure 4a,b are both obtained by transforming the same point cloud of the target sensor by randomly sampled deviations from Rg1, but the sampled deviations are different. As can be seen from the boxplots in
Figure 4e–h, the distribution of calibration errors was similar despite the large difference in sampled deviations.
Table 2 shows the calibration results for our method and for the existing CNN-based online calibration methods. From these results, it can be seen that our method achieves the best performance. In addition, when these results are compared with the results shown in
Table 1, it can be concluded that our method achieves significant performance improvement through temporal filtering. CalibNet [
2] did not specify a frame bundle.
Figure 5 graphically shows the changes in the losses calculated by Equations (10) and (11) for training the proposed networks on the KITTI dataset. In this figure, the green graph shows the results of training with randomly sampled deviations from Rg1, and the pink graph shows the results of training with randomly sampled deviations from Rg5. The horizontal and vertical axes of these graphs represent epochs and loss, respectively. From these graphs, we can observe that the loss reduction decreases from approximately the 30th epoch. This was consistently observed, no matter what deviation range the network was trained on or what hyper-parameters were used. There were similar trends in loss reduction for rotation and translation. Given this situation, we halved the initial learning rate after the 30th epoch of training. Training was performed at a reduced learning rate for 10 epochs after the 30th epoch. After the 40th epoch, we halved the learning rate again. Training continued until the 60th epoch, and the result that produced the smallest training error among the results obtained from the 45th to the 60th epoch was selected as the training result. When Net1 was trained, the hyper-parameters were set as S = 5, (
Vr,
Vt) = (96, 160), G = 1024, (
λ1,
λ2) = (1, 2), and
B = 8. When Net5 was trained, the hyper-parameters were set as S = 2.5, (
Vr,
Vt) = (384, 416), G = 128, (
λ1,
λ2) = (0.5, 5), and
B = 4. In
Figure 5, the training results before the 10th epoch are not shown because the loss was too large.
4.2. Evaluation Using the Oxford Dataset
Figure 6 and
Figure 7 show the results of performing calibration on the Oxford dataset using the proposed five networks. In these figures, the green dots represent the points obtained by the right LiDAR, which is considered to be the target sensor, and the red dots represent the points obtained by the left LiDAR.
Figure 6a,b show the results of the transformation of a point cloud from the target sensor by randomly sampled deviations from Rg1 and calibrated parameters given in the Oxford dataset, respectively.
Figure 6c shows the result of the transformation of the point cloud by
inferred from the trained Net1.
Figure 6d shows the result of the transformation of the point cloud by
obtained after performing calibration up to Net5. Similar to the results of the calibration performed using the KITTI dataset, the results of Net1 look suitable, but they are not suitable when compared with the results shown in
Figure 6d. The photo on the right side of
Figure 6c shows that the green and red dots indicated by an arrow are misaligned. In contrast, the photo on the right side of
Figure 6d shows that the green and red dots indicated by an arrow are well aligned. We show through this comparison that calibration accuracy can be improved by the iterative refinement of five networks even without temporal filtering.
Table 3 presents the average performance of calibrations performed without temporal filtering on 35,989 frames for testing in the Oxford dataset. Our method achieves an average rotation error of [Roll: 0.056°, Pitch: 0.029°, Yaw: 0.082°] and an average translation error of [X: 0.520 cm, Y: 0.628 cm, Z: 0.350 cm]. In this experiment, we applied the same hyper-parameters to all five networks. They are S = 5, (
Vr,
Vt) = (224, 288), G = 1024, (
λ1,
λ2) = (1, 2), and B = 8.
Figure 7 shows two examples of the error distribution of individual components by means of boxplots, as shown in
Figure 4. From these experiments, we can see that temporal filtering provides suitable calibration results regardless of the amount of arbitrary deviation, even for LiDAR-LiDAR calibration. The green dots shown in
Figure 7a,b are both obtained by transforming the same point cloud of the target sensor with randomly sampled deviations from Rg1, but the sampled deviations are different. As shown in
Figure 7e–g, the distribution of calibration errors is similar despite the large difference in sampled deviations. In these experiments, the size of the frame bundle used in the temporal filtering was 100.
Table 4 shows the calibration performance of the proposed method with temporal filtering. Our method achieves a rotation error of less than 0.1° and a translation error of less than 1 cm. By comparing
Table 3 and
Table 4, it can be seen that temporal filtering achieves a significant improvement in performance.
Figure 8 graphically shows the changes in the losses calculated by Equations (10) and (11) in training the proposed networks with the Oxford dataset. Compared with the results shown in
Figure 5, we observed that the results from this experiment were very similar to the experimental results achieved with the KITTI dataset. Therefore, we decided to apply the same training strategy to the KITTI and Oxford datasets. However, the settings of the hyper-parameter values that were applied to the network were different. When Net1 was trained, the hyper-parameters were set as S = 5, (
Vr,
Vt) = (224, 288), G = 1024, (
λ1,
λ2) = (1, 2), and
B = 8. When Net5 was trained, the hyper-parameters were set as S = 5, (
Vr,
Vt) = (224, 288), G = 1024, (
λ1,
λ2) = (0.5, 5), and
B = 4.
4.3. Ablation Studies
4.3.1. Performance According to the Cropped Area of the Oxford Dataset
At the beginning of
Section 4, we mentioned the need to eliminate some points in the Oxford dataset that degraded calibration performance. To support this observation, we presented in
Table 5 the results of experiments with and without the removal of those points. However, although there is a difference in the calibration performance according to the size of the removed area, it is difficult to theoretically determine the size of the area to be cropped.
Table 5 shows the results of the experiments by setting the area to be cut in two ways. Through these experiments, we found that the calibration performed after removing points that caused the performance degradation generally produced better results than the calibration performed without removing those points. These experiments were performed with the trained Net5, and the hyper-parameters were as follows. S = 5, V = (224, 288), G = 1024,
= (1, 2), and B = 8.
4.3.2. Performance According to the Length of a Voxel Side, S
We conducted experiments to check how the calibration performance changes according to S.
Table 6 and
Table 7 show the results of these experiments.
Table 6 shows the results for the KITTI dataset, and
Table 7 shows the results for the Oxford dataset. We performed an evaluation according to S with a combination of Rg1 and Net1 and a combination of Rg5 and Net5. These experiments showed that the calibration performance improved as S became smaller. However, as S became smaller, the computational cost increased, and in some cases, the performance deteriorated. We tried to experiment with fixed values of hyper-parameters other than S, but naturally, as S decreased, the hyper-parameters
Vr and
Vt increased rapidly. This was a burden on the memory, and thus it was difficult to keep the batch size B at the same value. Therefore, when S was 2.5, B was 4 in the experiment performed on the KITTI dataset, and B was 2 in the experiment performed on the Oxford dataset. However, for S greater than 2.5, B was fixed at 8. In addition, there were cases where the performance deteriorated when S was very small, such as 2.5, which was considered to be the result of a small receptive field in the FEN. Even in the experiments performed on the Oxford dataset, when S was 2.5 in Net1, the training loss diverged near the 5th epoch, so the experiment could no longer be performed. For training on the KITTI dataset, S was set to 2.5 in Net5, and S was set to 5 in Net1 to Net4. However, for training on the Oxford dataset, S was set to 5 for both Net1 and Net5.
4.3.3. Performance According to the Bundle Size of Frames
We conducted experiments to observe how the calibration performance changes according to the bundle size of the frame for temporal filtering.
Table 8 and
Table 9 show the results of these experiments.
Table 8 shows the results for the KITTI dataset, and
Table 9 shows the results for the Oxford dataset. We performed the experiments as presented in
Section 3.4.3. Because 100 runs had to be performed, the position of the starting frame for each run was predetermined. For each run, we took the median of the values of each of the six parameters associated with rotation and translation inferred from the frames in the bundle, and we calculated the absolute difference between this median and the deviation randomly sampled from Rg1. The error of each parameter shown in
Table 8 and
Table 9 was obtained by adding up the error of the corresponding parameters calculated for each run and dividing the sum by the number of runs. Through these experiments, we found that temporal filtering using many frames improves the overall calibration performance. However, if we look carefully at the results presented in the two tables, the effect is not shown for all parameters. Considering this observation and the processing time, the bundle size of the frame was set to 100.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}