
DRL-RNP: Deep Reinforcement Learning-Based Optimized RNP Flight Procedure Execution



Abstract
:1. Introduction
- (a)
- A flight controller based on multi-task deep reinforcement learning is proposed, which can solve the multi-channel coupling control problem existing in aircraft control and provide an effective solution for similar coupling control problems.
- (b)
- A DRL method named MHRL is proposed, which combines multi-task RL with hierarchical reinforcement learning (HRL) for integrated control and decision-making. MHRL can solve the problem of flight control in accordance with safety regulations and path planning considering fuel consumption.
- (c)
- The proposed work provides possible application prospects for the research that needs to consider both aircraft control and decision-making.
2. Background
2.1. Related Works
2.2. JSBSim
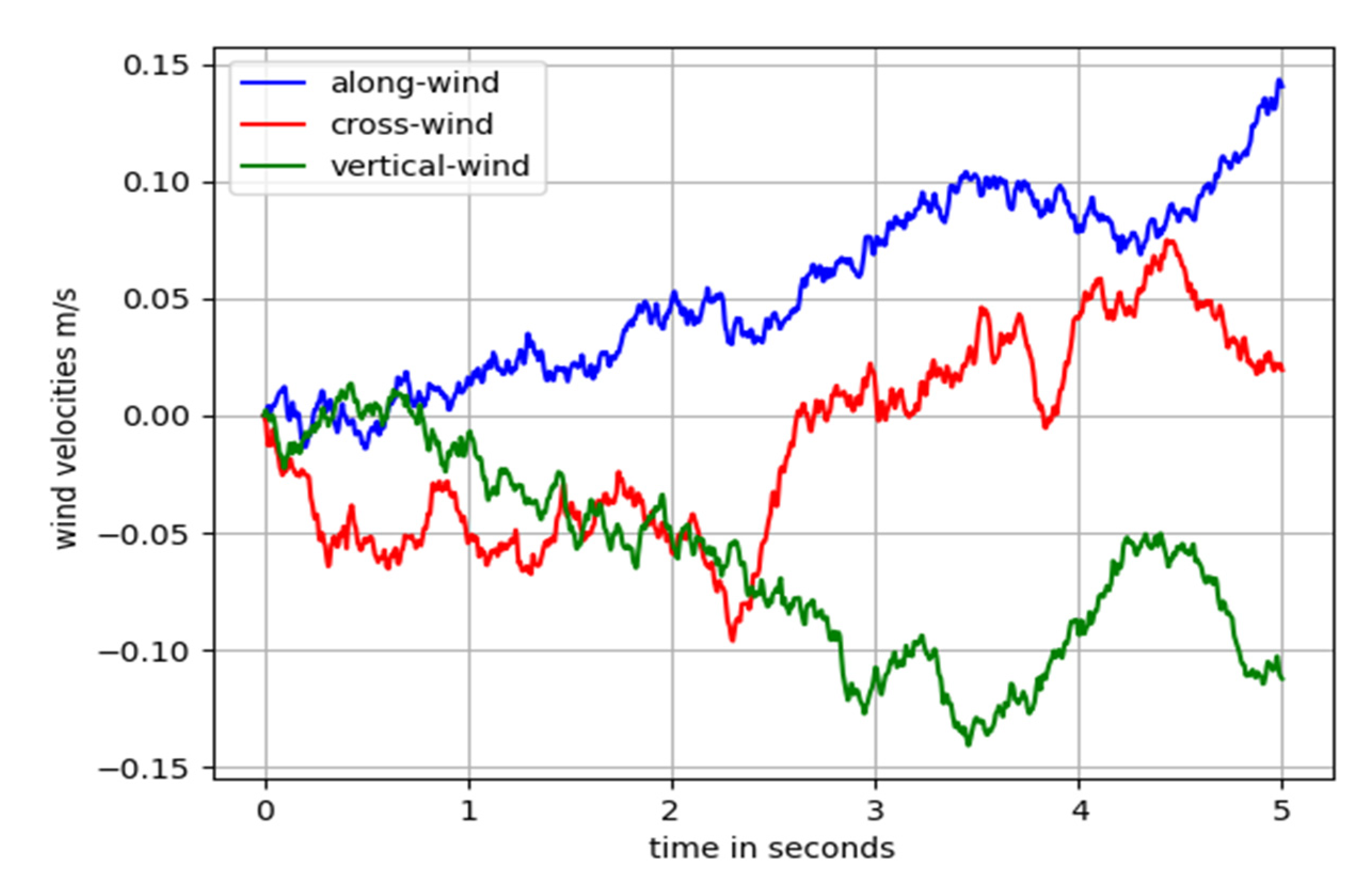
2.3. Dryden Wind Turbulence Model
2.4. RNP Approach Procedure
2.4.1. Basic Concepts
2.4.2. Safety Specifications
2.5. Deep Reinforcement Learning
2.5.1. Markov Decision Process
2.5.2. Model-Free RL
3. The Proposed DRL-RNP Approach
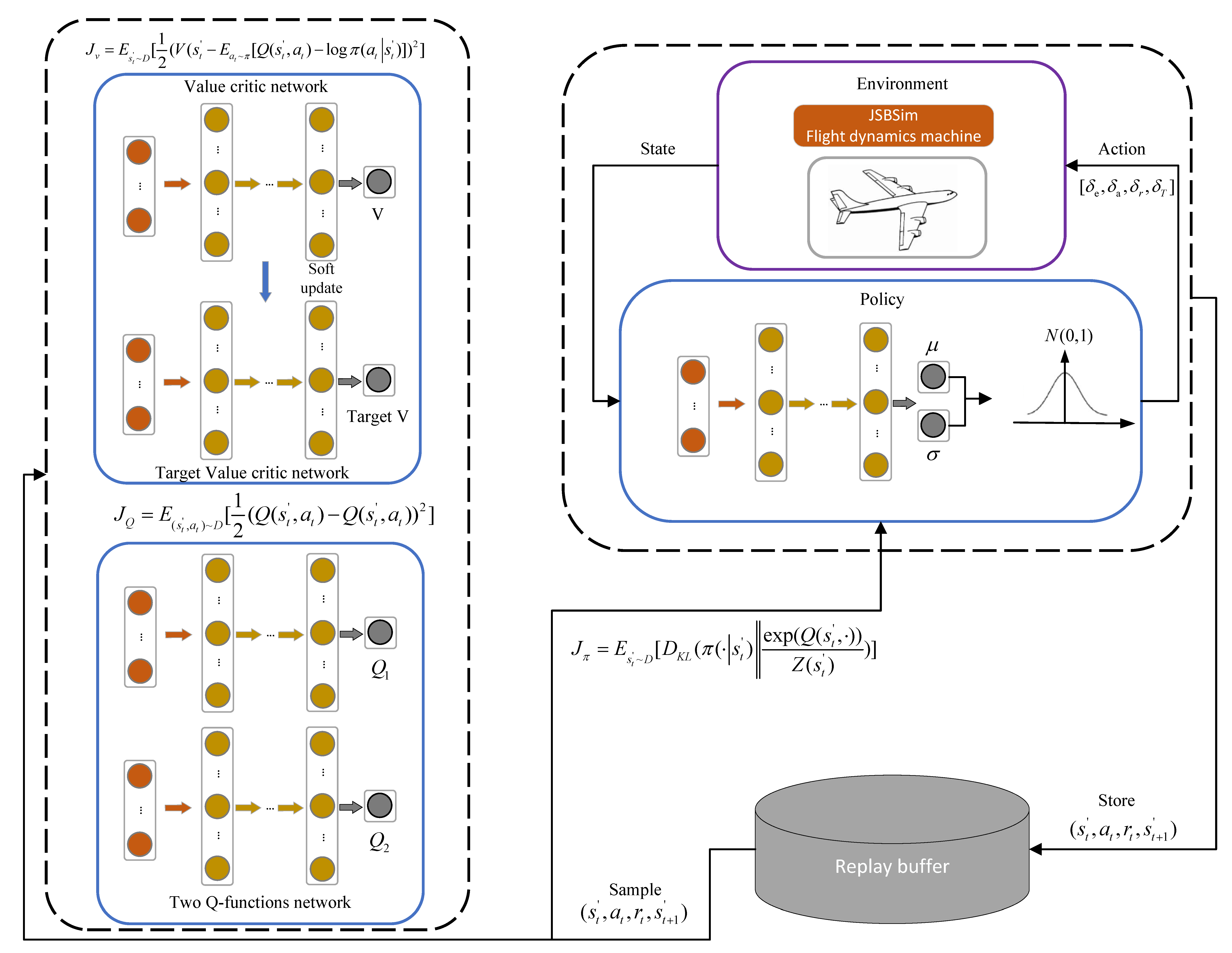
3.1. Aircraft Controller Based on Multi-Task DRL
| Algorithm 1 Multi-task SAC RL algorithm for aircraft control |
| Initialize the policy network parameter , value critic network parameter , target value critic network parameter , and two soft Q-function network parameters . |
| Initialize the replay buffer . |
| Initialize the task id tuple Initialize the environment. |
| for each episode do Randomly get an from . |
| for each environment step do Sample action from the policy , , obtain the next state and reward from the environment, and push the tuple to . end |
| for each gradient step do Sample a batch of memories from and update the value critic network (Equation (14)), the two soft Q-function networks (Equation (18)), the policy network (Equation (21)) and the target value network (soft-update). end |
| end |
3.2. Path Planning Based on MHRL
4. Simulation, Experiments, and Discussion
4.1. Aircraft Controller Based on Multi-Task DRL
4.1.1. Environment Settings
4.1.2. Model Settings
4.1.3. Simulation Results and Analysis
4.2. Path Planning Based on MHRL
4.2.1. Environmental Settings
4.2.2. Model Settings
4.2.3. Simulation Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviation/Symbol | Meaning |
| DRL | Deep Reinforcement Learning |
| RNP | Required Navigation Performance |
| PBN | Performance-based Navigation Procedure |
| ICAO | International Civil Aviation Organization |
| RNAV | Area Navigation |
| OPMA | Onboard Performance Monitoring and Alerting Navigation Satellite System |
| RNSS | Navigation Satellite System |
| UAV | Unmanned Aerial Vehicle |
| AGI | Artificial General Intelligence |
| MHRL | Multi-task and Hierarchical Reinforcement Learning |
| HRL | Hierarchical Reinforcement Learning |
| DDPG | Deep Deterministic Policy Gradient |
| DDQN | deep Q-network |
| MDP | Markov decision process |
| PPO | Proximal Policy Optimization |
| ATC | Air Traffic Control |
| DARPA | Defense Advanced Research Projects Agency |
| ADP | Adaptive Dynamic Programming |
| HJI | Hamilton–Jacobi–Issacs |
| HJB | Hamilton–Jacobi–Bellman |
| AUV | Autonomous Underwater Vehicle |
| IAF | Initial Approach Fix |
| IF | Intermediate Approach Fix |
| FAF | Final Approach Fix |
| MOC | Minimum Obstacle Clearance |
| Half Width of the Protection Area | |
| FDM | Flight Dynamics Machine |
| DOF | Degree Of Freedom |
| SAC | Soft Actor-critic |
| Transfer functions of the along wind | |
| Transfer functions of the cross wind | |
| Transfer functions of the vertical wind | |
| Wind velocity at a suggested altitude of 20 ft | |
| S | State space |
| A | Action space |
| State transition probability | |
| Reward function | |
| Discount factor | |
| Policy function | |
| Value function | |
| State-action value function | |
| Liner position | |
| Linear velocity | |
| Angular position | |
| Angular velocity | |
| Elevator control command | |
| Aileron control command | |
| Rudder control command | |
| Throttle control command | |
| Value objective function | |
| State-action value objective function | |
| Policy objective function |
References
- López-Lago, M.; Serna, J.; Casado, R.; Bermúdez, A. Present and Future of Air Navigation: PBN Operations and Supporting Technologies. Int. J. Aeronaut. Sp. Sci. 2020, 21, 451–468. [Google Scholar] [CrossRef]
- Israel, E.; Justin Barnes, W.; Smith, L. Automating the Design of Instrument Flight Procedures. In Proceedings of the 2020 Integrated Communications Navigation and Surveillance Conference (ICNS), Herndon, VA, USA, 8–10 September 2020; pp. 1–11. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. 2013. Available online: http://arxiv.org/abs/1312.5602 (accessed on 19 December 2013).
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Soleymani, F.; Paquet, E. Financial portfolio optimization with online deep reinforcement learning and restricted stacked autoencoder—DeepBreath. Expert Syst. Appl. 2020, 156, 113456. [Google Scholar] [CrossRef]
- Bayerlein, H.; Theile, M.; Caccamo, M.; Gesbert, D. UAV Path Planning for Wireless Data Harvesting: A Deep Reinforcement Learning Approach. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020. [Google Scholar]
- Hua, J.; Zeng, L.; Li, G.; Ju, Z. Learning for a robot: Deep reinforcement learning, imitation learning, transfer learning. Sensors 2021, 21, 1278. [Google Scholar] [CrossRef] [PubMed]
- Mousavi, S.; Schukat, M.; Howley, E. Deep Reinforcement Learning: An Overview. Lect. Notes Netw. Syst. 2018, 16, 426–440. [Google Scholar]
- Wang, H.; Liu, N.; Zhang, Y.; Feng, D.; Huang, F.; Li, D.; Zhang, Y. Deep reinforcement learning: A survey. Front. Inf. Technol. Electron. Eng. 2020, 21, 1726–1744. [Google Scholar] [CrossRef]
- Tang, C.; Lai, Y. Deep Reinforcement Learning Automatic Landing Control of Fixed-Wing Aircraft Using Deep Deterministic Policy Gradient. In Proceedings of the 2020 International Conference on Unmanned Aircraft Systems (ICUAS), Athens, Greece, 1–4 September 2020. [Google Scholar]
- Huang, X.; Luo, W.; Liu, J. Attitude Control of Fixed-wing UAV Based on DDQN. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; Volume 1, pp. 4722–4726. [Google Scholar]
- Bohn, E.; Coates, E.; Moe, S.; Johansen, T. Deep reinforcement learning attitude control of fixed-wing UAVs using proximal policy optimization. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 11–14 June 2019. [Google Scholar]
- Zu, W.; Yang, H.; Liu, R.; Ji, Y. A multi-dimensional goal aircraft guidance approach based on reinforcement learning with a reward shaping algorithm. Sensors 2021, 21, 5643. [Google Scholar] [CrossRef] [PubMed]
- Pope, A.P.; Ide, J.S.; Mićović, D.; Diaz, H.; Rosenbluth, D.; Ritholtz, L.; Twedt, J.C.; Walker, T.T.; Alcedo, K.; Javorsek, D. Hierarchical Reinforcement Learning for Air-to-Air Combat. In Proceedings of the 2021 International Conference on Unmanned Aircraft Systems (ICUAS), Athens, Greece, 15–18 June 2021. [Google Scholar]
- Long, Y.; He, H. Robot path planning based on deep reinforcement learning. In Proceedings of the 2020 IEEE Conference on Telecommunications, Optics and Computer Science (TOCS), Shenyang, China, 11–13 December 2020. [Google Scholar]
- Yan, C.; Xiang, X.; Wang, C. Towards Real-Time Path Planning through Deep Reinforcement Learning for a UAV in Dynamic Environments. J. Intell. Robot. Syst. Theory Appl. 2020, 98, 297–309. [Google Scholar] [CrossRef]
- Guo, S.; Zhang, X.; Zheng, Y.; Du, Y. An autonomous path planning model for unmanned ships based on deep reinforcement learning. Sensors 2020, 20, 426. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Wu, Y. Path Planning for UAV Ground Target Tracking via Deep Reinforcement Learning. IEEE Access 2020, 8, 29064–29074. [Google Scholar] [CrossRef]
- Lei, X.; Zhang, Z.; Dong, P. Dynamic Path Planning of Unknown Environment Based on Deep Reinforcement Learning. J. Robot. 2018, 2018, 5781591. [Google Scholar] [CrossRef]
- Sun, W.; Tsiotras, P.; Lolla, T.; Subramani, D.; Lermusiaux, P. Pursuit-evasion games in dynamic flow fields via reachability set analysis. In Proceedings of the 2017 American Control Conference (ACC), Seattle, WA, USA, 24–26 May 2017. [Google Scholar]
- Zhou, Z.; Ding, J.; Huang, H.; Takei, R.; Tomlin, C. Efficient path planning algorithms in reach-avoid problems. Automatica 2018, 89, 28–36. [Google Scholar] [CrossRef]
- Takei, R.; Huang, H.; Ding, J.; Tomlin, C. Time-optimal multi-stage motion planning with guaranteed collision avoidance via an open-loop game formulation. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, St. Paul, MN, USA, 14–18 May 2012. [Google Scholar]
- Ramana, M.V.; Kothari, M. A cooperative pursuit-evasion game of a high speed evader. In Proceedings of the 2015 54th IEEE Conference on Decision and Control (CDC), Osaka, Japan, 15–18 December 2015. [Google Scholar]
- Berndt, J. JSBSim: An open source flight dynamics model in C++. In Proceedings of the AIAA Modeling and Simulation Technologies Conference and Exhibit, Providence, RI, USA, 16–19 August 2004; Volume 1, pp. 261–287. [Google Scholar]
- Gage, S. Creating a unified graphical wind turbulence model from multiple specifications. In Proceedings of the AIAA Modeling and Simulation Technologies Conference and Exhibit, Austin, TX, USA, 11–14 August 2003. [Google Scholar]
- Abichandani, P.; Lobo, D.; Ford, G.; Bucci, D.; Kam, M. Wind Measurement and Simulation Techniques in Multi-Rotor Small Unmanned Aerial Vehicles. IEEE Access 2022, 8, 54910–54927. [Google Scholar] [CrossRef]
- Dautermann, T.; Mollwitz, V.; Többen, H.H.; Altenscheidt, M.; Bürgers, S.; Bleeker, O.; Bock-Janning, S. Design, implementation and flight testing of advanced RNP to SBAS LPV approaches in Germany. Aerosp. Sci. Technol. 2015, 47, 280–290. [Google Scholar] [CrossRef]
- International Civil Aviation Organization. Doc 8168 Aircraft Operations. Volume I—Flight Procedures, 5th ed.; Glory Master International Limited: Shanghai, China, 2006; pp. 1–279. [Google Scholar]
- Yarats, D.; Zhang, A.; Kostrikov, I.; Amos, B.; Pineau, J.; Fergus, R. Improving Sample Efficiency in Model-Free Reinforcement Learning from Images. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021. [Google Scholar]
- Nagabandi, A.; Kahn, G.; Fearing, R.; Levine, S. Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar]
- Algorithms, R.; Szepesvari, C. A Unified Analysis of Value-Function-Based Reinforcement- Learning Algorithms. Neural Comput. 1999, 11, 2017–2060. [Google Scholar]
- Yu, M.; Sun, S. Policy-based reinforcement learning for time series anomaly detection. Eng. Appl. Artif. Intell. 2020, 95, 103919. [Google Scholar] [CrossRef]
- Paczkowski, M. Policy Gradient Methods for Reinforcement Learning with Function Approximation. Pulp Pap. 1999, 70, 1057–1064. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. Int. Conf. Mach. Learn. 2013, 48, 1928–1937. [Google Scholar]
- Hull, D. Fundamentals of Airplane Flight Mechanics; Springer: Berlin, Germany, 2007; pp. 158–257. [Google Scholar]
- Clarke, S.; Hwang, I. Deep reinforcement learning control for aerobatic maneuvering of agile fixed-wing aircraft. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020. [Google Scholar]
- Varghese, N.; Mahmoud, Q. A survey of multi-task deep reinforcement learning. Electronics 2020, 9, 1363. [Google Scholar] [CrossRef]
- Ren, J.; Sun, H.; Zhao, H.; Gao, H.; Maclellan, C.; Zhao, S.; Luo, X. Effective extraction of ventricles and myocardium objects from cardiac magnetic resonance images with a multi-task learning U-Net. Pattern Recognit. Lett. 2022, 155, 165–170. [Google Scholar] [CrossRef]
- Hessel, M.; Soyer, H.; Espeholt, L.; Czarnecki, W.; Schmitt, S.; van Hasselt, H. Multi-task deep reinforcement learning with PopArt. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 11–13 July 2018. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Turbulence Level | |
|---|---|
| Light Moderate Severe | 15 knots 30 knots 45 knots |
| Leg Type | Main Area | Sub-Area |
|---|---|---|
| Initial approach leg Intermediate approach leg Final approach leg | 300 m 150 m 75 m | 0–300 m 0–150 m 0–75 m |
| Parameters | Value |
|---|---|
| Aircraft type Initial latitude Initial longitude Initial altitude Terrain altitude Initial velocity Initial heading Initial roll angle | A320 49.392057° N 7.057191° E 5000 ft 1022 ft 450 ft/s 100° 0° 0.8 0 0 0 |
| Parameters | Value |
|---|---|
| Learning rate Discount factor Soft update coefficient Replay buffer size Minibatch size Network frame Activation function | 1 × 10−4 0.98 0.05 20,000 1024 [256,256,256,256,256,256,256,512,512] Relu |
| The Types of PID Controller | P | I | D |
|---|---|---|---|
| Roll controller Pitch controller Velocity controller Heading controller Altitude controller | 1.3 2.9 2.1 2.7 2.7 | 0.19 0.13 0.15 0.17 0 | 1.9 0.3 5.0 1.1 3 |
| Point | Latitude | Longitude | Altitude | AW/2 | Velocity |
|---|---|---|---|---|---|
| Waypoint 1 Waypoint 2 Waypoint 3 Waypoint 4 | N 49.26417 N 49.205 N 49.20806 N 49.21167 | E 6.64556 E 6.66167 E 6.76889 E 6.89778 | ft ft ft ft | 4360 m 4360 m 4360 m 2685 m | t/s t/s t/s t/s |
| Parameters | Value |
|---|---|
| Aircraft type Initial position Initial altitude Initial velocity Initial heading Initial roll angle Initial fuel weight | A320 Waypoint1(2) 5000 ft 450 ft/s 90° (120°) 0° 15,000 lbs |
| Parameters | Value |
|---|---|
| Learning rate Discount factor Soft update coefficient Replay buffer size Minibatch size Network frame Activation function | 1 × 10−4 0.98 0.05 20,000 1024 [512,512,256,256,256,256,256] Relu |
| No Wind | Light Wind | Moderate Wind | Severe Wind | |
|---|---|---|---|---|
| Without fuel consumption reward | 252.16 lbs | 256.78 lbs | 258.19 lbs | 262.46 lbs |
| With fuel consumption reward | 237.76 lbs | 235.67 lbs | 244.24 lbs | 247.13 lbs |
| Difference | −5.71% | −8.22% | −5.40% | −5.84% |
| No Wind | Light Wind | Moderate Wind | Severe Wind | |
|---|---|---|---|---|
| Without fuel consumption reward | 298.30 lbs | 298.06 lbs | 296.61 lbs | 300.56 lbs |
| With fuel consumption reward | 256.78 lbs | 257.52 lbs | 260.32 lbs | 263.73 lbs |
| Differences | −13.91% | −13.06% | −12.23% | −12.25% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, L.; Wang, J.; Wang, Y.; Ji, Y.; Ren, J. DRL-RNP: Deep Reinforcement Learning-Based Optimized RNP Flight Procedure Execution. Sensors 2022, 22, 6475. https://doi.org/10.3390/s22176475
Zhu L, Wang J, Wang Y, Ji Y, Ren J. DRL-RNP: Deep Reinforcement Learning-Based Optimized RNP Flight Procedure Execution. Sensors. 2022; 22(17):6475. https://doi.org/10.3390/s22176475
Chicago/Turabian StyleZhu, Longtao, Jinlin Wang, Yi Wang, Yulong Ji, and Jinchang Ren. 2022. "DRL-RNP: Deep Reinforcement Learning-Based Optimized RNP Flight Procedure Execution" Sensors 22, no. 17: 6475. https://doi.org/10.3390/s22176475
APA StyleZhu, L., Wang, J., Wang, Y., Ji, Y., & Ren, J. (2022). DRL-RNP: Deep Reinforcement Learning-Based Optimized RNP Flight Procedure Execution. Sensors, 22(17), 6475. https://doi.org/10.3390/s22176475