
On the Design and Implementation of the External Data Integrity Tracking and Verification System for Stream Computing System in IoT †
Abstract
:1. Introduction
- Accuracy: Accuracy is a key consideration for stream real-time computing systems used in IoT. Only with a high level of accuracy and precision can the system be trusted by end users and be widely applied.
- Real-time: Data sharing in IoT requires high timeliness; so, data integrity verification needs real-time. Since the tracking and verification system is built outside the stream computing system, integrity verification does not affect the efficiency of the original system. Meanwhile, the verification time is synchronized with stream computing, making it possible to trace and recover error messages as soon as possible.
- Transparency: Different stream computing systems for IoT may have different topological frameworks, corresponding to different business and application interfaces; thus, the design of external tracking and verification systems should be transparent in order to achieve system versatility.
2. Related Work
- Schemes based on RSA
- 2.
- Schemes based on symmetric encryption
- 3.
- Schemes based on homomorphic verification tags
- 4.
- Schemes based on elliptic curve
- 5.
- Schemes based on bilinear mapping
- 6.
- Schemes based on the third party
- 7.
- Schemes based on the group
- 8.
- Schemes based on other technologies
- 9.
- Schemes based on the Frontier emerging technologies
3. Model Construction
3.1. Model Design
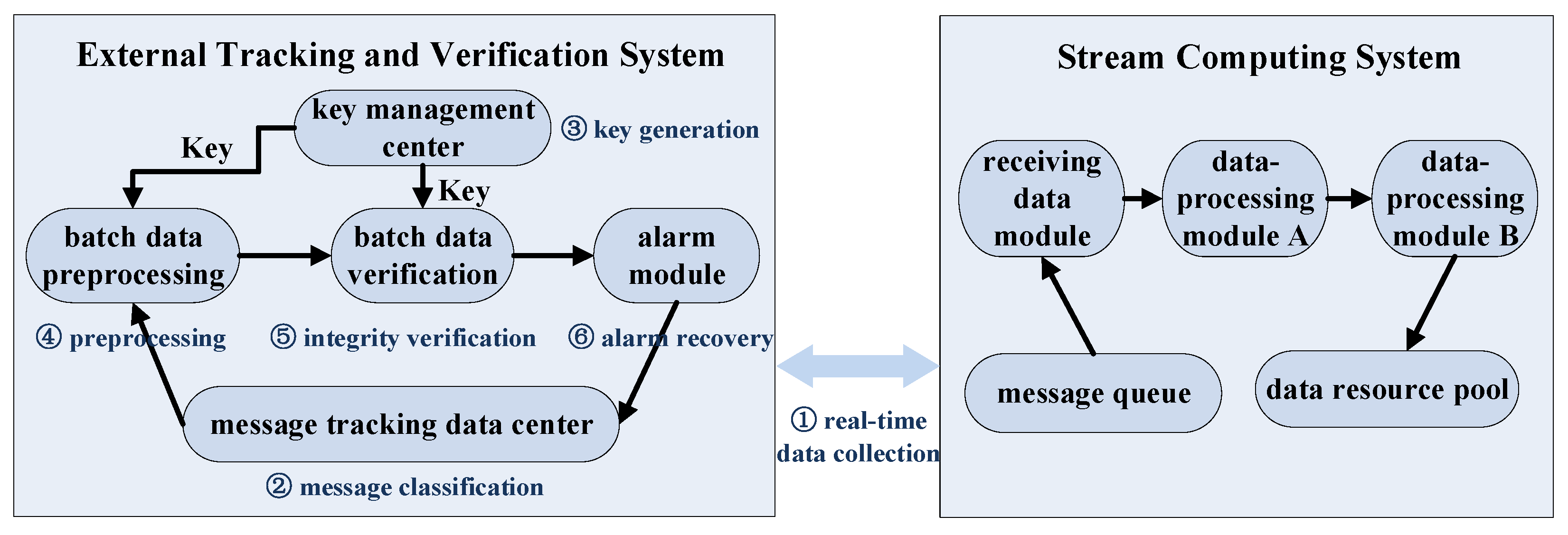
3.2. Overall Work Steps
- The phase of real-time data collection: The external tracking and verification system has a data collection interface on each data-processing module of the stream computing system, which is used to record and send message data to the message tracking data center. Each message defines a unique message ID, which remains unchanged during all phases. When a message enters a module or leaves this module, a message state is defined to record information such as the receiving module or the sending module, and the two states are submitted to the tracking data center.
- The phase of message classification: in the message tracking data center, each message is classified and preprocessed with the message ID as the unique identifier, and all the intermediate data of this message are merged to form a batch of message data.
- The phase of key generation: the key management center distributes the pregenerated key (symmetric key or public–private key pair) to the data preprocessing module and data verification module.
- The phase of batch data preprocessing: The system uses cryptographic algorithms to preprocess the batch data of each message—that is, it uses the key to generate verification tags. Specifically, the system computes the message data sent by each data-processing module in turn, and, respectively, generates verification tags to verify the integrity of the received message data of the next data-processing module.
- The phase of batch data integrity verification: Use the corresponding algorithm, verification tag, and key to verify the integrity of each message batch data. Specifically, each receiving module verifies the integrity of the received data according to the verification tag, key, and message status (i.e., sending module and receiving module information, message ID, etc.).
- The phase of alarm and recovery: If the verification passes, it means that the message has been completely and correctly processed; then, the related intermediate data are deleted. If the verification fails, it means that the data integrity is abnormal and the message is not processed correctly; then, alarm and recovery phase is executed, which checks the records of this error message- in the external tracking and verification system, resends the message to the message queue, and recalculates and reprocesses it in the stream system.
4. Preliminaries
4.1. Homomorphic Message Authentication Code
4.2. Pseudo-Random Function
4.3. Negligible Function
5. Implementation
5.1. Scheme Implementation
5.1.1. Formal Definition of Data Integrity Verification Scheme of Stream System
5.1.2. A Structure of Data Integrity Verification Scheme of Stream System
- The identifier Mid is randomly generated by a pseudo-random function when the message is generated. As the unique identifier of the message, it is used to distinguish messages with the same content but that are actually different. Mid remains unchanged throughout the life cycle of the message; thus, it can effectively resist collision in an actual system. After the stream system completes all calculations of a message and the integrity verification is correct in the entire cycle, the message data are deleted together with Mid.
- The identifier Sid is generated when the message is transmitted between modules. The Sid of each session (transmission from one module to another is called a session) is different. It is used to distinguish the message with the same content but that is actually different or the message in different processing phase but with same content. After the stream system completes all calculations of a message and the integrity verification is correct in the entire cycle, the message data are deleted together with Mid.
- The algorithm ProofGen can be regarded as an aggregation function, which is used to aggregate all the different messages of the same Mid collected by the receiving module and perform batch verification according to verification tags with corresponding Mid and Sid generated by the sending module. It improves computational efficiency.
5.2. System Detailed Design
5.2.1. Message Format Design
5.2.2. Detailed Design of External Data Integrity Tracking and Verification System
- The phase of real-time data collection: When a message is sent from module A to module B, data collection is performed at the data sending port (module A) and the data receiving port (module B), and the collected message data are sent to the message tracking data center.
- The phase of message classification: After the data center receives the collected message, it judges whether it is a sending message or a receiving message according to the Flag, the sending message (Flag = 00) will be put into the sending data storage module (i.e., sending module), and the receiving message (Flag = 01) will be put into the receiving data storage module (i.e., receiving module).
- The phase of key generation: The key management center sends the pregenerated key to the batch data preprocessing module and the batch data verification module, respectively.
- The phase of batch data preprocessing: The preprocessing module preprocesses the message data of sending module, calculates each message , and generates a verification tag ; then, it sends the tag to the batch data verification module.
- The phase of batch data integrity verification: The messages of receiving module are sent to batch data verification module. The batch data verification module verifies data integrity of the message one by one according to and . Specifically, aggregate and according to Mid: aggregate and verify a set of messages with the same Mid and the corresponding series of tags . If the verification passes, the information will be sent to the message tracking data center and the stream computing system, and the intermediate data in the two caches will be deleted; if the verification fails, the message alarm and recovery will be carried out.
- The phase of alarm and recovery: When the alarm module receives the error information, it calls out the error message from the batch data verification module and resends the error message to the message tracking data center according to the Mid and Sid. The data center finds out the original message and sends it to the stream computing system. Finally, the stream computing system replays and recalculates the message according to the original route.
6. Security
- The proof of correctness
- 2.
- The proof of reliability
- 3.
- The proof of data integrity
7. Experiment and Analysis
7.1. Comparison of Various Schemes
7.2. Computational Efficiency Comparison under Different Message Concurrency
7.3. Comparison of Preprocessing Efficiency between S-DIV and Traditional PDP
7.4. Comparison of Verification Efficiency between S-DIV and Traditional PDP
7.5. The Timing Analysis
7.6. Storage Cost and Communication Cost
7.6.1. Storage Cost
7.6.2. Communication Cost
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| Chapter | Notation | Description |
| Chapter 4 Preliminaries | Key | The secret key |
| The security parameter | ||
| id | The vector space identifier | |
| The vector value, whose index is i | ||
| The s-dimensional vector value space, whose order is q | ||
| Random constant parameters selected from space | ||
| The tag value of | ||
| T | The HomMac of | |
| The aggregated value of | ||
| The set of bit strings of length k | ||
| The set of all functions mapped from to | ||
| F | The pseudo-random function | |
| The set of all pseudo-random functions | ||
| k | The index value of pseudo-random function | |
| The pseudo-random function with input x | ||
| The function that maps from integers to real numbers | ||
| An integer value | ||
| A positive polynomial with input x | ||
| A negligible function with input x | ||
| Chapter 5 Implementation | Key | The secret key |
| The security parameter | ||
| Mid | The unique identifier of the message | |
| Sid | The session identifier of the message | |
| The message data with identifier Mid and Sid | ||
| The tag value of | ||
| The message data set identified by Mid | ||
| The tag set of | ||
| The data integrity proof | ||
| The finite field, whose order is q | ||
| The pseudo-random function mapped from to | ||
| The key space | ||
| The set of bit strings of arbitrary length | ||
| No solution or multiple solutions | ||
| The secret key selected from | ||
| The pseudo-random function with key b and input x | ||
| The splicing operation | ||
| The random parameter with index j | ||
| The message aggregate value | ||
| The tag aggregate value | ||
| The pseudo-random function aggregate value | ||
| Flag | The sending and receiving flag | |
| Chapter 6 Security | The secret key | |
| The aggregation of tags | ||
| The inverse of c | ||
| The aggregation of messages | ||
| The aggregation of pseudo-random function values | ||
| An illegal proof | ||
| An integrity proof | ||
| r, | The random number | |
| M | The message data | |
| The changed message data | ||
| T | The tag value | |
| The forged tag value |
References
- Tan, S.; Jia, Y.; Han, W.H. Research and Development of Provable Data Integrity in Cloud Storage. J. Comput. 2015, 38, 164–177. (In Chinese) [Google Scholar]
- Sun, D.W.; Zhang, G.Y.; Zheng, W.M. Big Data Stream Computing: Technologies and Instances. Ruan Jian Xue Bao J. Softw. 2014, 25, 839–862. (In Chinese) [Google Scholar]
- Storm Acker. Available online: https://www.cnblogs.com/DreamDrive/p/6671194.html (accessed on 28 August 2022).
- Ateniese, G.; Burns, R.; Curtmola, R. Provable Data Possession at Untrusted Stores. In Proceedings of the 14th ACM Conference on Computer and Communications Security, New York, NY, USA, 1 January 2007; pp. 598–609. [Google Scholar]
- Erway, C.; Küpçü, A.; Papamanthou, C.; Tamassia, R. Dynamic Provable Data Possession. ACM Trans. Inf. Syst. Secur. 2009, 17, 213–222. [Google Scholar]
- Wang, H.; Zhu, L.; Xu, C.; Lilong, Y. A Universal Method for Realizing Non-Repudiable Provable Data Possession in Cloud Storage. Secur. Commun. Netw. 2016, 9, 2291–2301. [Google Scholar] [CrossRef]
- Chinnasamy, P.; Deepalakshmi, P. Improved key generation scheme of RSA (IKGSR) algorithm based on offline storage for cloud. Adv. Big Data Cloud Comput. 2018, 645, 341–350. [Google Scholar]
- Ateniese, G.; Di, P.R.; Mancini, L.V.; Tsudik, G. Scalable and Efficient Provable Data Possession. In Proceedings of the 4th International Conference on Security and Privacy in Communication Networks, Istanbul, Turkey, 22–25 September 2008; ACM Press: New York, NY, USA, 2008. [Google Scholar]
- Juels, A.; Kaliski, B.S. Pors: Proofs of Retrievability for Large Files. In Proceedings of the 14th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 2 November–31 October 2007; ACM Press: New York, NY, USA, 2007; pp. 584–597. [Google Scholar]
- Chang, E.; Xu, J. Remote Integrity Check with Dishonest Storage Server. In Computer Security—ESORICS 2008; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5283, pp. 223–237. [Google Scholar]
- Shacham, H.; Waters, B. Compact Proofs of Retrievability. J. Cryptol. 2008, 26, 442–483. [Google Scholar] [CrossRef]
- Curtmola, R.; Khan, O.; Burns, R.; Ateniese, G. MR-PDP: Multiple-Replica Provable Data Possession. In Proceedings of the 2008 The 28th International Conference on Distributed Computing Systems, Beijing, China, 17–20 June 2008; pp. 411–420. [Google Scholar]
- Wang, C.; Wang, Q.; Ren, K.; Lou, W. Ensuring Data Storage Security in Cloud Computing. In Proceedings of the 2009 17th International Workshop on Quality of Service, Charleston, SC, USA, 13–15 July 2009; pp. 1–9. [Google Scholar]
- Hanser, C.; Slamanig, D. Efficient Simultaneous Privately and Publicly Verifiable Robust Provable Data Possession from Elliptic Curves. In Proceedings of the 2013 International Conference on Security and Cryptography (SECRYPT), Reykjavik, Iceland, 29–31 July 2013; pp. 1–12. [Google Scholar]
- Wang, H.; Zhu, L.; Wang, F.; Lilong, Y.; Chen, Y.; Liu, C. An Efficient Provable Data Possession based on Elliptic Curves in Cloud Storage. Int. J. Secur. Its Appl. 2014, 8, 97–108. [Google Scholar] [CrossRef]
- Zhu, Y.; Hu, H.; Ahn, G.; Yu, M. Cooperative Provable Data Possession for Integrity Verification in Multicloud Storage. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 2231–2244. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Q.; Ren, K.; Lou, W.J. Privacy-Preserving public auditing for data storage security in cloud computing. In Proceedings of the 2010 IEEE INFOCOM, San Diego, CA, USA, 15–19 March 2010; pp. 1–9. [Google Scholar] [CrossRef]
- Wang, C.; Chow, S.M.; Wang, Q.; Ren, K.; Lou, W.J. Privacy-Preserving public auditing for secure cloud storage. IEEE Trans. Comput. 2013, 62, 362–375. [Google Scholar] [CrossRef]
- Armknecht, F.; Bohli, J.; Karame, G.; Liu, Z.; Reuter, C. Outsourced Proofs of Retrievability. IEEE Trans. Cloud Comput. 2014, 9, 286–301. [Google Scholar] [CrossRef]
- Tate, S.R.; Vishwanathan, R.; Everhart, L. Multi-user Dynamic Proofs of Data Possession Using Trusted Hardware. In Proceedings of the Third ACM Conference on Data and Application Security and Privacy, San Antonio, TX, USA, 18–20 February 2013; pp. 353–364. [Google Scholar]
- Wang, B.; Li, B.; Li, H. Oruta: Privacy-Preserving Public Auditing for Shared Data in The Cloud. IEEE Trans. Cloud Comput. 2014, 2, 43–56. [Google Scholar] [CrossRef]
- Wang, B.; Li, B.; Li, H. Panda: Public Auditing for Shared Data with Efficient User Revocation in The Cloud. IEEE Trans. Serv. Comput. 2015, 8, 92–106. [Google Scholar] [CrossRef]
- Wang, H.Y.; Zhu, L.H.; Lilong, Y.J. Group Provable Data Possession with Deduplication in Cloud Storage. Ruan Jian Xue Bao J. Softw. 2016, 27, 1417–1431. (In Chinese) [Google Scholar]
- Zhu, L.; Wang, H.; Xu, C.; Sharif, K.; Lu, R. Efficient Group Proof of Storage with Malicious-Member Distinction and Revocation. IEEE Access 2019, 7, 75476–75489. [Google Scholar] [CrossRef]
- Chen, B.; Curtmola, R.; Ateniese, G.; Burns, R. Remote Data Checking for Network Coding-based Distributed Stroage Systems. In Proceedings of the 2010 ACM Workshop on Cloud Computing Security Workshop, Chicago, IL, USA, 8 October 2010; pp. 31–42. [Google Scholar]
- Halevi, S.; Harnik, D.; Pinkas, B.; Shulman, A. Proofs of Ownership in Remote Storage Systems. In Proceedings of the 18th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 17–21 October 2011; pp. 491–500. [Google Scholar]
- Cao, N.; Yu, S.; Yang, Z.; Lou, W.; Hou, Y.T. LT Codes-based Secure and Reliable Cloud Storage Service. In Proceedings of the 2012 Proceedings IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 693–701. [Google Scholar]
- Zheng, Q.; Xu, S. Secure and Efficient Proof of Storage with Deduplication. In Proceedings of the Second ACM Conference on Data and Application Security and Privacy, San Antonio, TX, USA, 7–9 February 2012; pp. 1–12. [Google Scholar]
- Li, Y.; Yu, Y.; Min, G.; Susilo, W.; Ni, J.; Choo, K.R. Fuzzy Identity-Based Data Integrity Auditing for Reliable Cloud Storage Systems. IEEE Trans. Dependable Secur. Comput. 2017, 16, 72–83. [Google Scholar] [CrossRef]
- Guo, W.; Zhang, H.; Qin, S.; Gao, F.; Jin, Z.; Li, W.; Wen, Q. Outsourced Dynamic Provable Data Possession with Batch Update for Secure Cloud Storage. Future Gener. Comput. Syst. 2019, 95, 309–322. [Google Scholar] [CrossRef]
- Guo, W.; Qin, S.; Gao, F.; Zhang, H.; Li, W.; Jin, Z.; Wen, Q. Dynamic Proof of Data Possession and Replication with Tree Sharing and Batch Verification in the Cloud. IEEE Trans. Serv. Comput. 2020, 15, 1813–1824. [Google Scholar] [CrossRef]
- Yaling, Z.; Li, S. Dynamic Flexible Multiple-Replica Provable Data Possession in Cloud. In Proceedings of the 2020 17th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 18–20 December 2020; pp. 291–294. [Google Scholar]
- Xu, Y.; Ren, J.; Zhang, Y.; Zhang, C.; Shen, B.; Zhang, Y. Blockchain Empowered Arbitrable Data Auditing Scheme for Network Storage as A Service. IEEE Trans. Serv. Comput. 2019, 13, 289–300. [Google Scholar] [CrossRef]
- Li, T.; Ren, S.; Wang, G.; Meng, Q. Cloud-edge-device Collaborative Integrity Verification Scheme Based on Chameleon Authentication Tree for Streaming Data. Netinfo Secur. 2022, 1, 37–45. (In Chinese) [Google Scholar]
- Wang, H. An External Data Integrity Tracking and Verification System for Universal Stream Computing System Framework. In Proceedings of the 2019 21st International Conference on Advanced Communication Technology (ICACT), PyeongChang, Korea, 17–20 February 2019; pp. 32–37. [Google Scholar] [CrossRef]
- Agrawal, S.; Dan, B. Homomorphic MACs: MAC-Based Integrity for Network Coding. In ACNS 2009: Applied Cryptography and Network Security; Springer: Berlin/Heidelberg, Germany, 2009; Volume 157, pp. 292–305. [Google Scholar]
- Boyle, E.; Goldwasser, S.; Ivan, I. Functional Signatures and Pseudorandom Functions. In PKC 2014: Public-Key Cryptography; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8383, pp. 501–519. [Google Scholar]
- Bellare, M. A Note on Negligible Functions. J. Cryptol. 2002, 15, 271–284. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S-PDP Based on RSA [4] | POR Based on SE [9] | CPOR Based on HVT [11] | E-PDP Based on EC [15] | CPDP Based on BM [16] | OPOR Based on TP [19] | S-DIV | |
|---|---|---|---|---|---|---|---|
| Data integrity | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Sampling verification | Yes | Yes | Yes | Yes | Yes | Yes | No |
| Preprocessing | |||||||
| Proof generation | |||||||
| Proof verification | |||||||
| Communication | |||||||
| Storage | |||||||
| Real-time | No | No | No | No | No | No | Yes |
| Data stream | No | No | No | No | No | No | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Zu, B.; Zhu, W.; Li, Y.; Wu, J. On the Design and Implementation of the External Data Integrity Tracking and Verification System for Stream Computing System in IoT. Sensors 2022, 22, 6496. https://doi.org/10.3390/s22176496
Wang H, Zu B, Zhu W, Li Y, Wu J. On the Design and Implementation of the External Data Integrity Tracking and Verification System for Stream Computing System in IoT. Sensors. 2022; 22(17):6496. https://doi.org/10.3390/s22176496
Chicago/Turabian StyleWang, Hongyuan, Baokai Zu, Wanting Zhu, Yafang Li, and Jingbang Wu. 2022. "On the Design and Implementation of the External Data Integrity Tracking and Verification System for Stream Computing System in IoT" Sensors 22, no. 17: 6496. https://doi.org/10.3390/s22176496