

Automated Android Malware Detection Using User Feedback



Abstract
:1. Introduction
2. Related Work
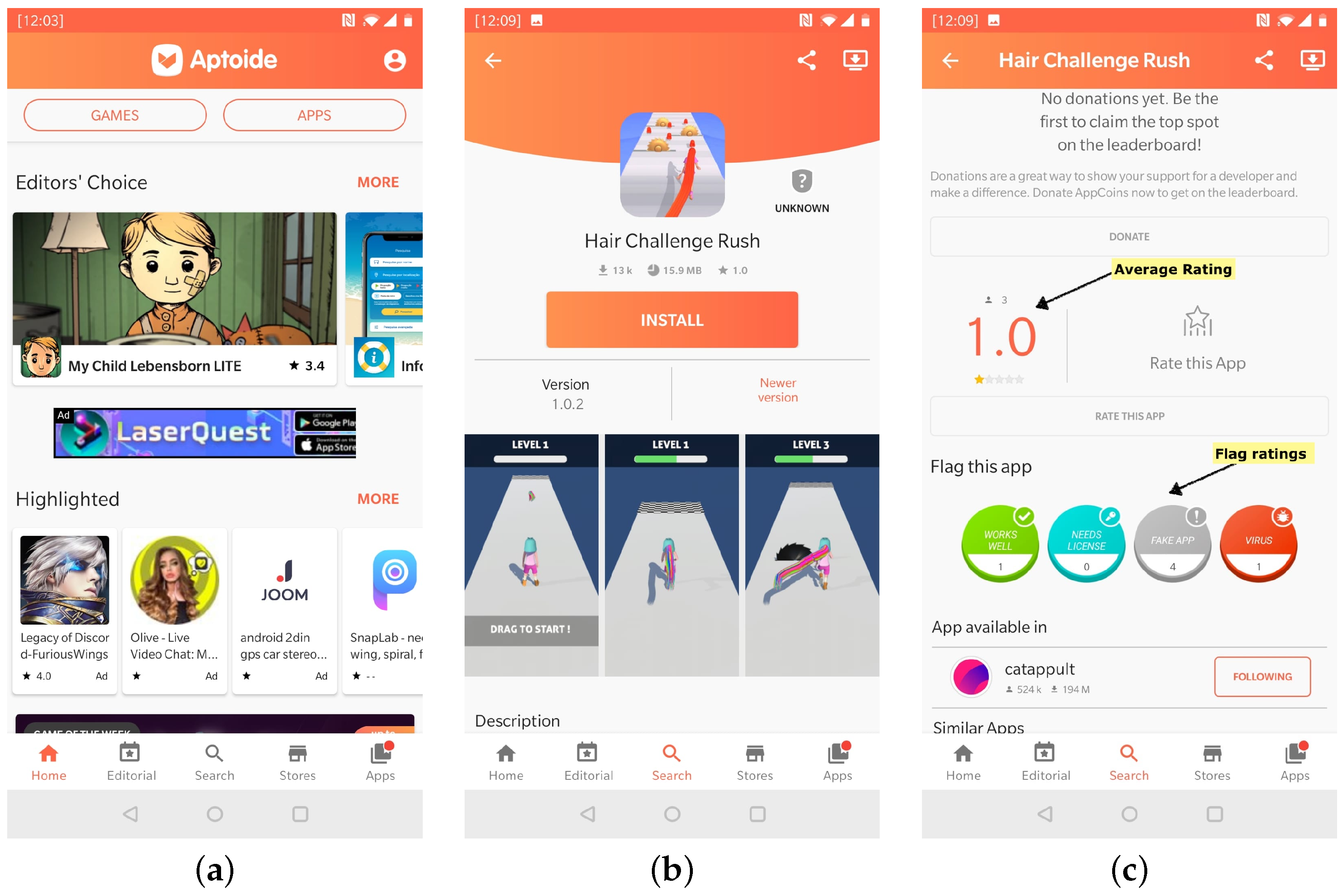
3. Data
Dimensionality Reduction
4. Model Implementation
4.1. Data Processing
4.2. Classification Algorithms
4.3. Experiments and Results
Experimental Setup
4.4. Results
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- McAfee. Mobile Threats Report. Available online: https://www.mcafee.com/enterprise/en-us/assets/reports/rp-mobile-threat-report-2019.pdf (accessed on 1 June 2022).
- StatCounter. Mobile Operating System Market Share Worldwide. Available online: https://gs.statcounter.com/os-market-share/mobile/worldwide (accessed on 1 June 2022).
- TheRegister. Earn 8000 a Month with Bogus Apps from Russian Malware Factories. Available online: http://www.theregister.co.uk/2013/08/05/mobile_malware_lookout/ (accessed on 1 June 2022).
- Nigam, R. A Timeline of Mobile Botnets, Virus Bulletin. Available online: https://www.virusbulletin.com/blog/2015/03/paper-timeline-mobile-botnets (accessed on 1 June 2022).
- InformationWeek. Cybercrime Black Markets Grow Up. Available online: http://www.informationweek.com/cybercrime-black-markets-grow-up/d/d-id/1127911 (accessed on 1 June 2022).
- Moser, A.; Kruegel, C.; Kirda, E. Limits of Static Analysis for Malware Detection. In Proceedings of the Twenty-Third Annual Computer Security Applications Conference (ACSAC 2007), Miami Beach, FL, USA, 10–14 December 2007; IEEE: Piscataway, NJ, USA, 2007. [Google Scholar]
- Xu, R.; Saïdi, H.; Anderson, R. Aurasium: Practical Policy Enforcement for Android Applications. In Proceedings of the 21st USENIX Security Symposium (USENIX Security 12), Bellevue, WA, USA, 8–10 August 2012; USENIX: Bellevue, WA, USA, 2012; pp. 539–552. [Google Scholar]
- Duque, J. Malware Detection Based on Dynamic Analysis Feature. Master’s Thesis, Iscte-Instituto Universitário de Liboa, Lisboa, Portugal, 2020. [Google Scholar]
- Tam, K.; Feizollah, A.; Anuar, N.B.; Salleh, R.; Cavallaro, L. The Evolution of Android Malware and Android Analysis Techniques. ACM Comput. Surv. 2017, 49, 1–41. [Google Scholar] [CrossRef]
- Hadad, T.; Puzis, R.; Sidik, B.; Ofek, N.; Rokach, L. Application Marketplace Malware Detection by User Feedback Analysis. In Information Systems Security and Privacy; Mori, P., Furnell, S., Camp, O., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 1–19. [Google Scholar]
- Tao, C.; Guo, H.; Huang, Z. Identifying security issues for mobile applications based on user review summarization. Inf. Softw. Technol. 2020, 122, 106290. [Google Scholar] [CrossRef]
- Pandita, R.; Xiao, X.; Yang, W.; Enck, W.; Xie, T. WHYPER: Towards Automating Risk Assessment of Mobile Applications. In Proceedings of the 22nd USENIX Security Symposium, Washington, DC, USA, 14–16 August 2013; pp. 527–542. [Google Scholar]
- Khalid, H.; Shihab, E.; Nagappan, M.; Hassan, A.E. What Do Mobile App Users Complain About? IEEE Softw. 2015, 32, 70–77. [Google Scholar] [CrossRef]
- McIlroy, S.; Ali, N.; Khalid, H.; Hassan, A. Analyzing and automatically labelling the types of user issues that are raised in mobile app review. Empir. Softw. Eng. 2016, 21, 1067–1106. [Google Scholar] [CrossRef]
- Ciurumelea, A.; Schaufelbühl, A.; Panichella, S.; Gall, H.C. Analyzing reviews and code of mobile apps for better release planning. In Proceedings of the 2017 IEEE 24th International Conference on Software Analysis, Evolution and Reengineering (SANER), Klagenfurt, Austria, 20–24 February 2017; pp. 91–102. [Google Scholar] [CrossRef]
- Scoccia, G.L.; Ruberto, S.; Malavolta, I.; Autili, M.; Inverardi, P. An Investigation into Android Run-Time Permissions from the End Users’ Perspective. In Proceedings of the 5th International Conference on Mobile Software Engineering and Systems, Gothenburg, Sweden, 27–28 May 2018; Association for Computing Machinery: New York, NY, USA, 2018. MOBILESoft ′18. pp. 45–55. [Google Scholar] [CrossRef]
- Ebrahimi, F.; Tushev, M.; Mahmoud, A. Mobile app privacy in software engineering research: A systematic mapping study. Inf. Softw. Technol. 2021, 133, 106466. [Google Scholar] [CrossRef]
- Antonio, N.; de Almeida, A.M.; Nunes, L.; Batista, F.; Ribeiro, R. Hotel online reviews: Creating a multi-source aggregated index. Int. J. Contemp. Hosp. Manag. 2018, 30, 3574–3591. [Google Scholar]
- Kiritchenko, S.; Zhu, X.; Cherry, C.; Mohammad, S. NRC-Canada-2014: Detecting Aspects and Sentiment in Customer Reviews. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014. [Google Scholar]
- Yeo, I.-K.; Johnson, R.A. A New Family of Power Transformations to Improve Normality or Symmetry. Biometrika 2000, 87, 954–959. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Mean | Standard-Deviation | Maximum | |
|---|---|---|---|
| Rating 1 | 543.22 | 4071.58 | 37,049 |
| Rating 2 | 146.46 | 1087.31 | 9859 |
| Rating 3 | 1085.56 | 8213.47 | 74,968 |
| Rating 4 | 555.01 | 3418.38 | 29,994 |
| Rating 5 | 5100.14 | 38,542.78 | 353,411 |
| Flag Good | 6.72 | 41.52 | 1021 |
| Flag Virus | 3.48 | 14.33 | 244 |
| Flag Fake | 3.62 | 18.67 | 367 |
| Flag License | 9.13 | 110.99 | 2417 |
| Ratings | Flags | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Rating 1 | Rating 2 | Rating 3 | Rating 4 | Rating 5 | Flag Good | Flag Virus | Flag Fake | Flag License | ||
| Ratings | Rating 1 | 1.00 | 0.95 | 0.85 | 0.81 | 0.882 | 0.17 | 0.09 | 0.02 | 0.11 |
| Rating 2 | 0.95 | 1.00 | 0.86 | 0.91 | 0.895 | 0.13 | 0.06 | −0.01 | 0.06 | |
| Rating 3 | 0.85 | 0.86 | 1.00 | 0.66 | 0.961 | 0.170 | 0.068 | 0.000 | 0.073 | |
| Rating 4 | 0.81 | 0.91 | 0.66 | 1.00 | 0.755 | 0.06 | 0.04 | −0.02 | 0.05 | |
| Rating 5 | 0.88 | 0.90 | 0.96 | 0.76 | 1.000 | 0.17 | 0.07 | −0.01 | 0.06 | |
| Flags | Flag Good | 0.165 | 0.13 | 0.17 | 0.06 | 0.17 | 1.00 | 0.62 | 0.59 | 0.54 |
| Flag Virus | 0.09 | 0.06 | 0.07 | 0.04 | 0.07 | 0.62 | 1.00 | 0.65 | 0.41 | |
| Flag Fake | 0.02 | −0.01 | 0.00 | −0.02 | −0.01 | 0.59 | 0.65 | 1.00 | 0.40 | |
| Flag License | 0.11 | 0.06 | 0.07 | 0.051 | 0.06 | 0.53 | 0.41 | 0.40 | 1.00 | |
| Mean | Standard-Deviation | Maximum | |
|---|---|---|---|
| Rating 1 | 72.34 | 246.73 | 2461 |
| Rating 2 | 21.79 | 82.69 | 697 |
| Rating 3 | 145.91 | 553.07 | 5761 |
| Rating 4 | 176.76 | 950.82 | 11,375 |
| Rating 5 | 718.54 | 2695.08 | 27,967 |
| Flag Good | 3.46 | 8.46 | 106 |
| Flag Virus | 2.29 | 4.16 | 38 |
| Flag Fake | 2.10 | 5.44 | 74 |
| Flag License | 0.98 | 3.59 | 48 |
| Model | Preprocess Method | F1 | Accuracy | FPR | FNR | ROC AUC | P-R AUC | Total Time Taken |
|---|---|---|---|---|---|---|---|---|
| XGBoost | NoPrep | 0.770 | 0.775 | 0.136 | 0.314 | 0.867 | 0.835 | 1 h 40 m 15 s |
| STD | 0.770 | 0.775 | 0.144 | 0.305 | 0.873 | 0.841 | 1 h 27 m 51 s | |
| NORM | 0.750 | 0.754 | 0.203 | 0.288 | 0.842 | 0.775 | 0 h 56 m 20 s | |
| PowerYJ | 0.790 | 0.788 | 0.144 | 0.28 | 0.863 | 0.808 | 0 h 36 m 36 s | |
| Quant | 0.770 | 0.771 | 0.136 | 0.322 | 0.869 | 0.839 | 0 h 23 m 17 s | |
| RF | NoPrep | 0.720 | 0.725 | 0.237 | 0.314 | 0.808 | 0.789 | 1 h 8 m 46 s |
| STD | 0.710 | 0.712 | 0.212 | 0.364 | 0.804 | 0.789 | 3 h 49 m 1 s | |
| NORM | 0.730 | 0.733 | 0.314 | 0.22 | 0.81 | 0.771 | 3 h 26 m 28 s | |
| PowerYJ | 0.710 | 0.712 | 0.229 | 0.347 | 0.806 | 0.79 | 3 h 11 m 43 s | |
| Quant | 0.720 | 0.72 | 0.237 | 0.322 | 0.806 | 0.789 | 3 h 5 m 55 s | |
| KNN | NoPrep | 0.710 | 0.716 | 0.212 | 0.356 | 0.774 | 0.767 | 0 h 1 m 1 s |
| STD | 0.700 | 0.699 | 0.254 | 0.347 | 0.771 | 0.744 | 0 h 1 m 9 s | |
| NORM | 0.700 | 0.703 | 0.246 | 0.347 | 0.796 | 0.777 | 0 h 1 m 11 s | |
| PowerYJ | 0.750 | 0.754 | 0.212 | 0.28 | 0.83 | 0.807 | 0 h 1 m 1 s | |
| Quant | 0.720 | 0.725 | 0.237 | 0.314 | 0.796 | 0.647 | 0 h 1 m 3 s | |
| SVM | NoPrep | 0.720 | 0.716 | 0.314 | 0.254 | 0.787 | 0.743 | 1 h 13 m 59 s |
| STD | 0.600 | 0.614 | 0.542 | 0.229 | 0.721 | 0.716 | 0 h 33 m 23 s | |
| NORM | 0.700 | 0.699 | 0.246 | 0.356 | 0.79 | 0.771 | 0 h 25 m 56 s | |
| PowerYJ | 0.750 | 0.75 | 0.186 | 0.314 | 0.818 | 0.794 | 0 h 29 m 25 s | |
| Quant | 0.710 | 0.712 | 0.186 | 0.39 | 0.769 | 0.714 | 0 h 32 m 6 s |
| Model | Preprocess Method | Statistic | F1 | Accuracy | FPR | FNR | ROC AUC | P-R AUC |
|---|---|---|---|---|---|---|---|---|
| XGBoost | PowerYJ | Mean | 0.790 | 0.788 | 0.144 | 0.28 | 0.863 | 0.808 |
| SD | 0.045 | 0.029 | 0.022 | 0.032 | 0.036 | 0.27 | ||
| RF | NORM | Mean | 0.730 | 0.733 | 0.314 | 0.22 | 0.81 | 0.771 |
| SD | 0.040 | 0.038 | 0.048 | 0.33 | 0.048 | 0.042 | ||
| KNN | PowerYJ | Mean | 0.750 | 0.754 | 0.212 | 0.28 | 0.83 | 0.807 |
| SD | 0.033 | 0.031 | 0.046 | 0.037 | 0.055 | 0.049 | ||
| SVM | PowerYJ | Mean | 0.750 | 0.75 | 0.186 | 0.314 | 0.818 | 0.794 |
| SD | 0.049 | 0.023 | 0.022 | 0.051 | 0.053 | 0.048 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duque, J.; Mendes, G.; Nunes, L.; de Almeida, A.; Serrão, C. Automated Android Malware Detection Using User Feedback. Sensors 2022, 22, 6561. https://doi.org/10.3390/s22176561
Duque J, Mendes G, Nunes L, de Almeida A, Serrão C. Automated Android Malware Detection Using User Feedback. Sensors. 2022; 22(17):6561. https://doi.org/10.3390/s22176561
Chicago/Turabian StyleDuque, João, Goncalo Mendes, Luís Nunes, Ana de Almeida, and Carlos Serrão. 2022. "Automated Android Malware Detection Using User Feedback" Sensors 22, no. 17: 6561. https://doi.org/10.3390/s22176561
APA StyleDuque, J., Mendes, G., Nunes, L., de Almeida, A., & Serrão, C. (2022). Automated Android Malware Detection Using User Feedback. Sensors, 22(17), 6561. https://doi.org/10.3390/s22176561