
Detection of Household Furniture Storage Space in Depth Images

Abstract
:1. Introduction
1.1. The Problem and the Contributions
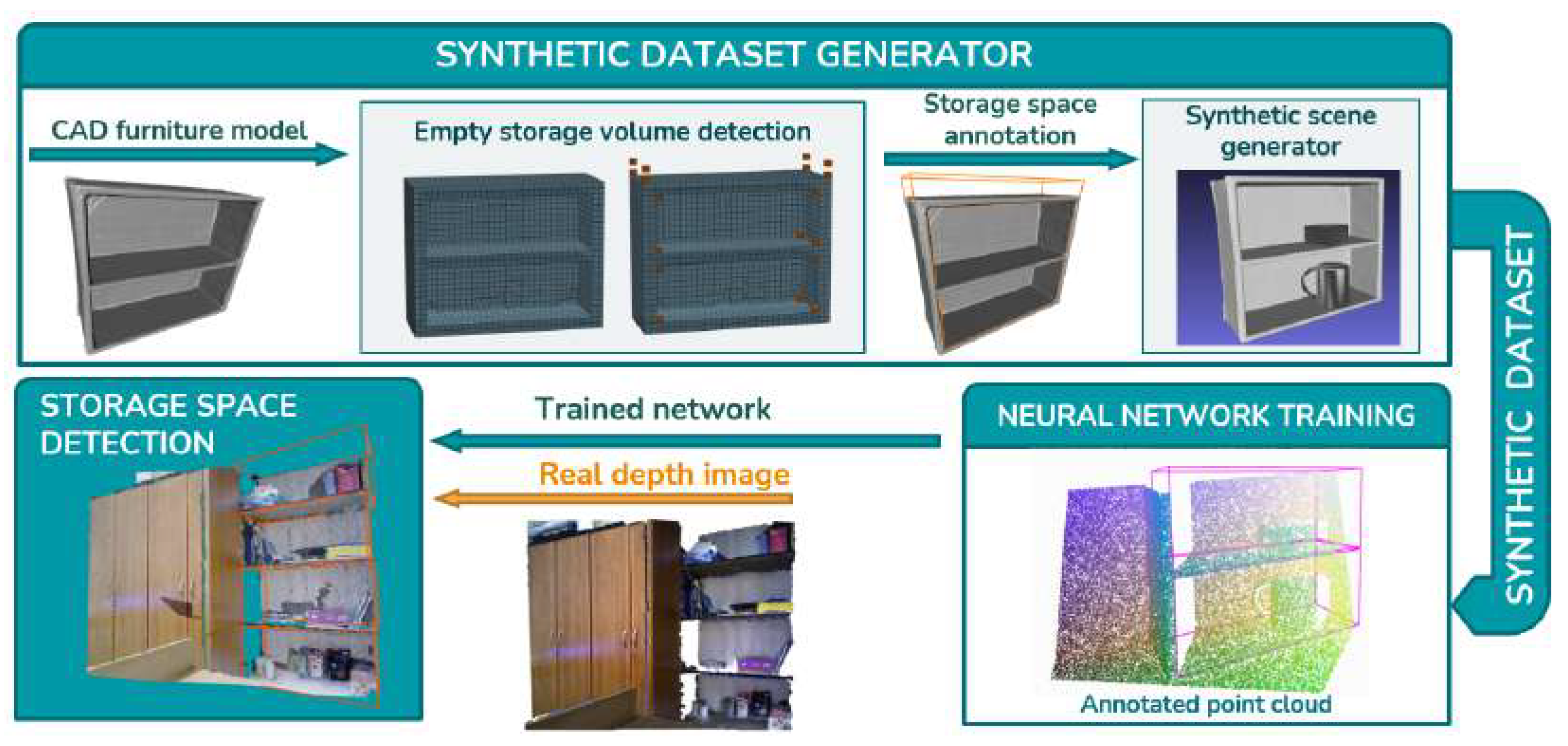
- An empty storage volume detection algorithm which provides automatic ground truth annotation of storage volumes in empty synthetic 3D furniture mesh models.
- A method for generating depth images of realistic synthetic scenes containing storage furniture with randomly cluttered storage space.
- Experimental evaluation of detection of storage volumes inside or on the top of furniture in depth images using the VoteNet and FCAF3D neural networks where the storage volumes could contain items.
- A dataset containing synthetic and real depth images with annotated ground truth storage volume bounding boxes.
1.2. Paper Overview
2. Related Research
2.1. Indoor Scenes and Furniture Synthesizing
2.2. Finding Empty Space within Furniture
2.3. On-Shelf Availability and Object Placement
3. Methods
| Algorithm 1: Synthetic dataset generator. | |
Input: CAD models of empty furniture and Output: furniture model depth image with set of annotated oriented bounding boxes of storage volumes | |
procedure Voxelization() | ▹ Process I |
| |
procedure Empty storage volume detection() | ▹ Process I |
| |
procedure Synthetic scene generator() | ▹ Process II |
| |
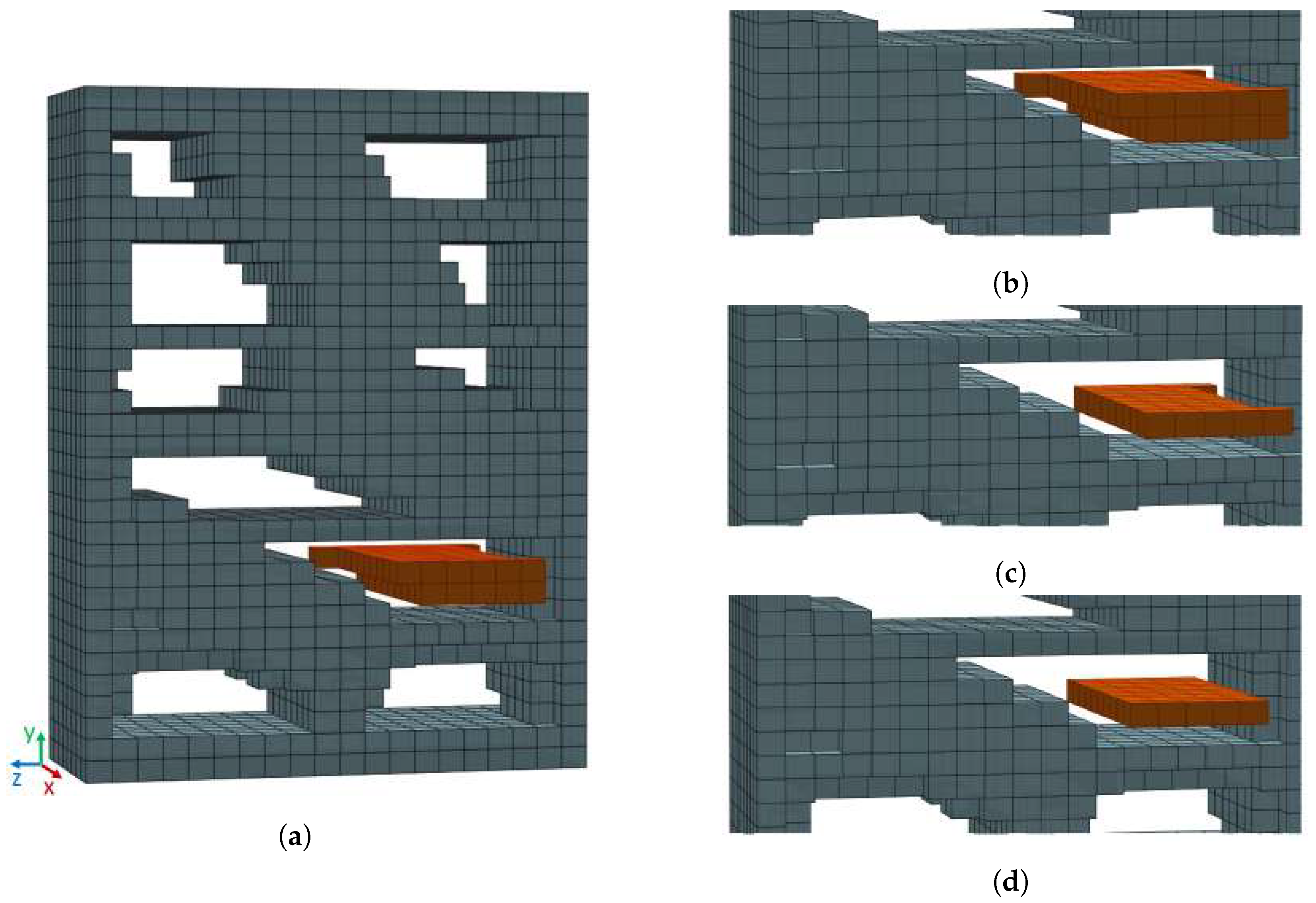
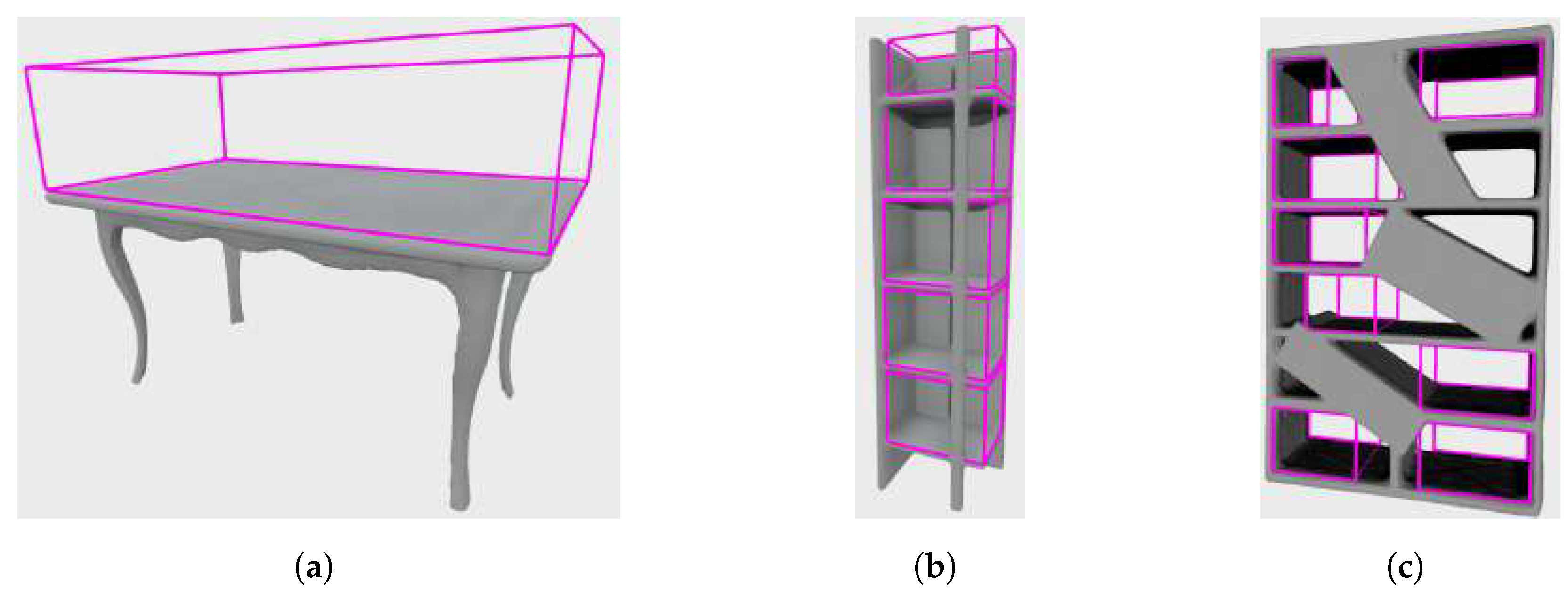
3.1. Empty Storage Volume Detection Algorithm
- Creating voxelized representation of the input mesh
- Detection of free space;
- Detection of empty storage volume candidates in the free space;
- Empty storage volume candidate pruning
- Bounding box fine-tunning.
3.1.1. Free Space Core Detection
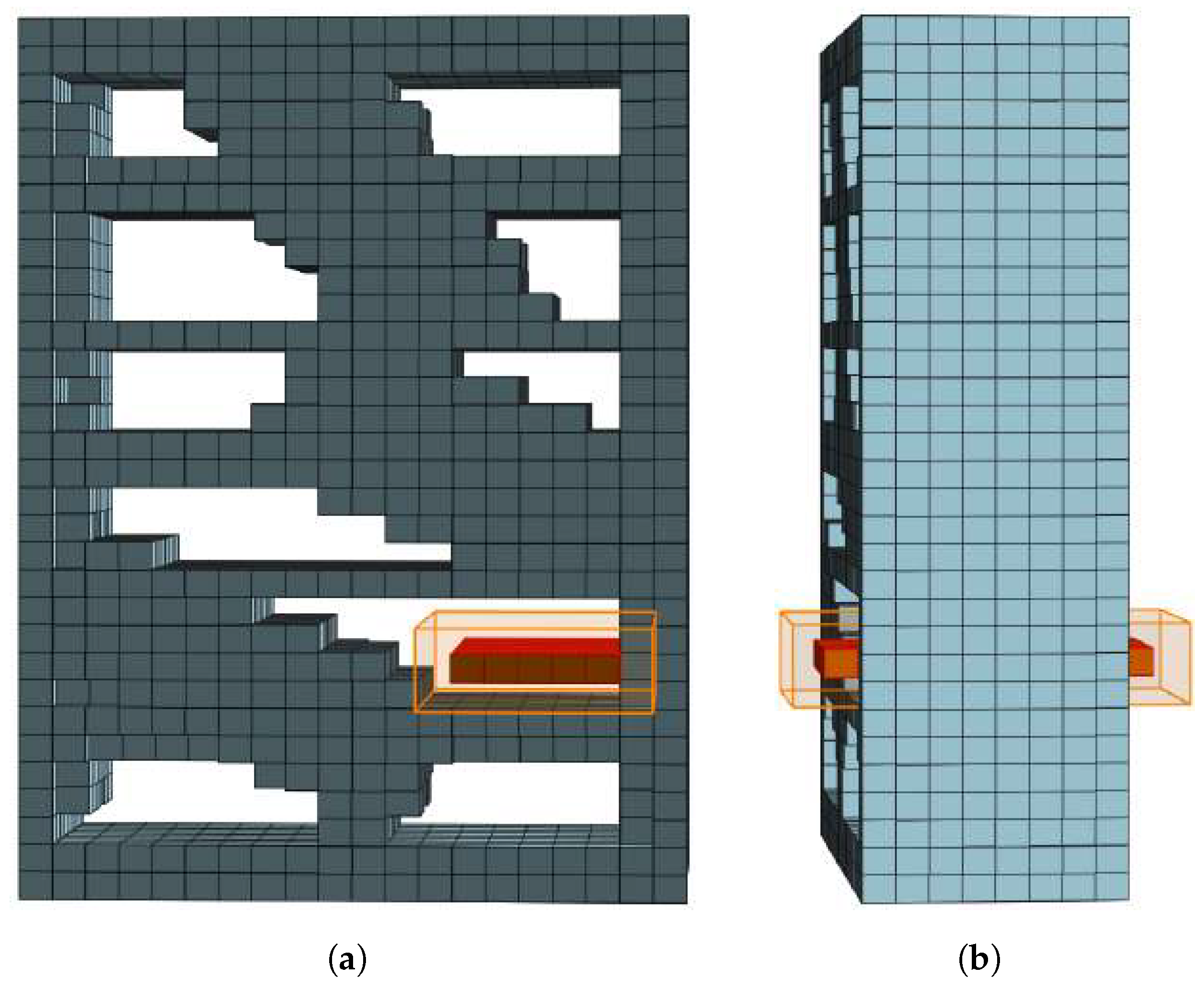
3.1.2. Detection of Empty Storage Volume Candidates
- (1)
- it has a sufficient size for storing the objects of interests, and
- (2)
- it has a hard flat horizontal surface underneath.

| Algorithm 2: An algorithm for detection of usable empty storage volumes in the occupancy grid. |
Input: free space core Output: set of storage volume candidates C
|
3.1.3. Empty Storage Volume Candidate Pruning
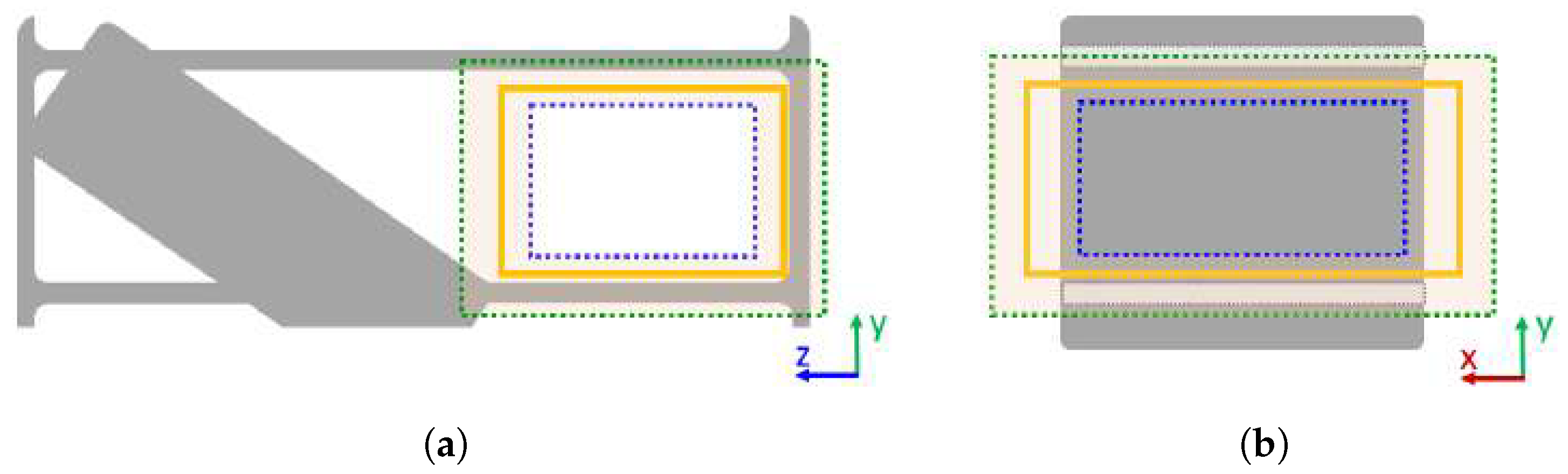
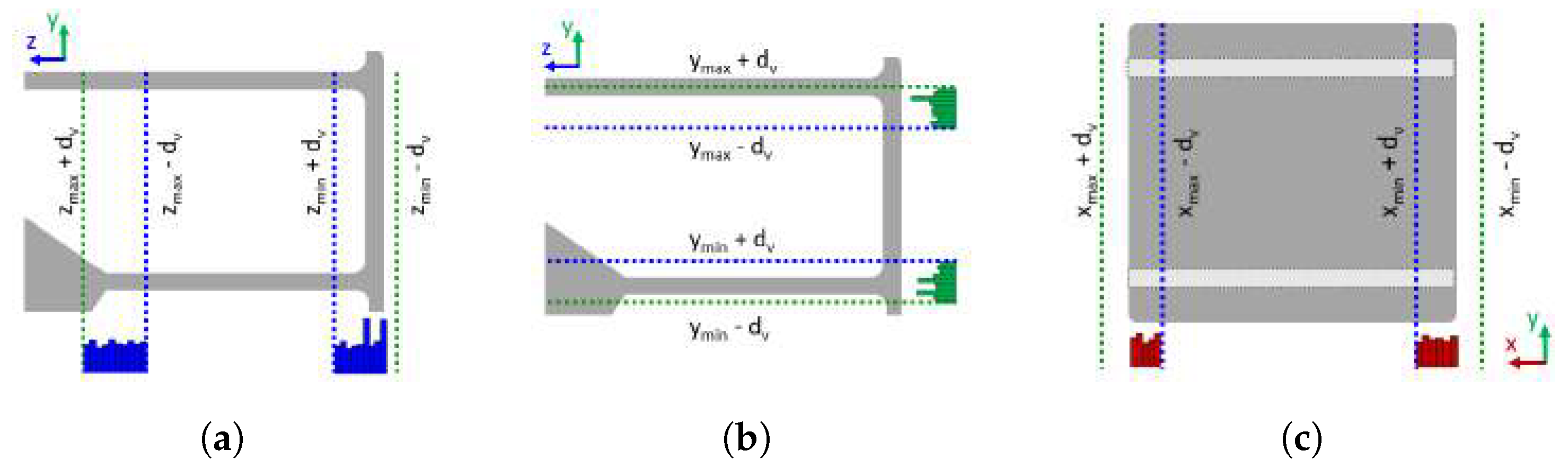
3.1.4. Bounding Box Fine-Tuning
- the histogram is empty;
- there are no distinguishable peaks in the histogram;
- there are several peaks in the histogram.
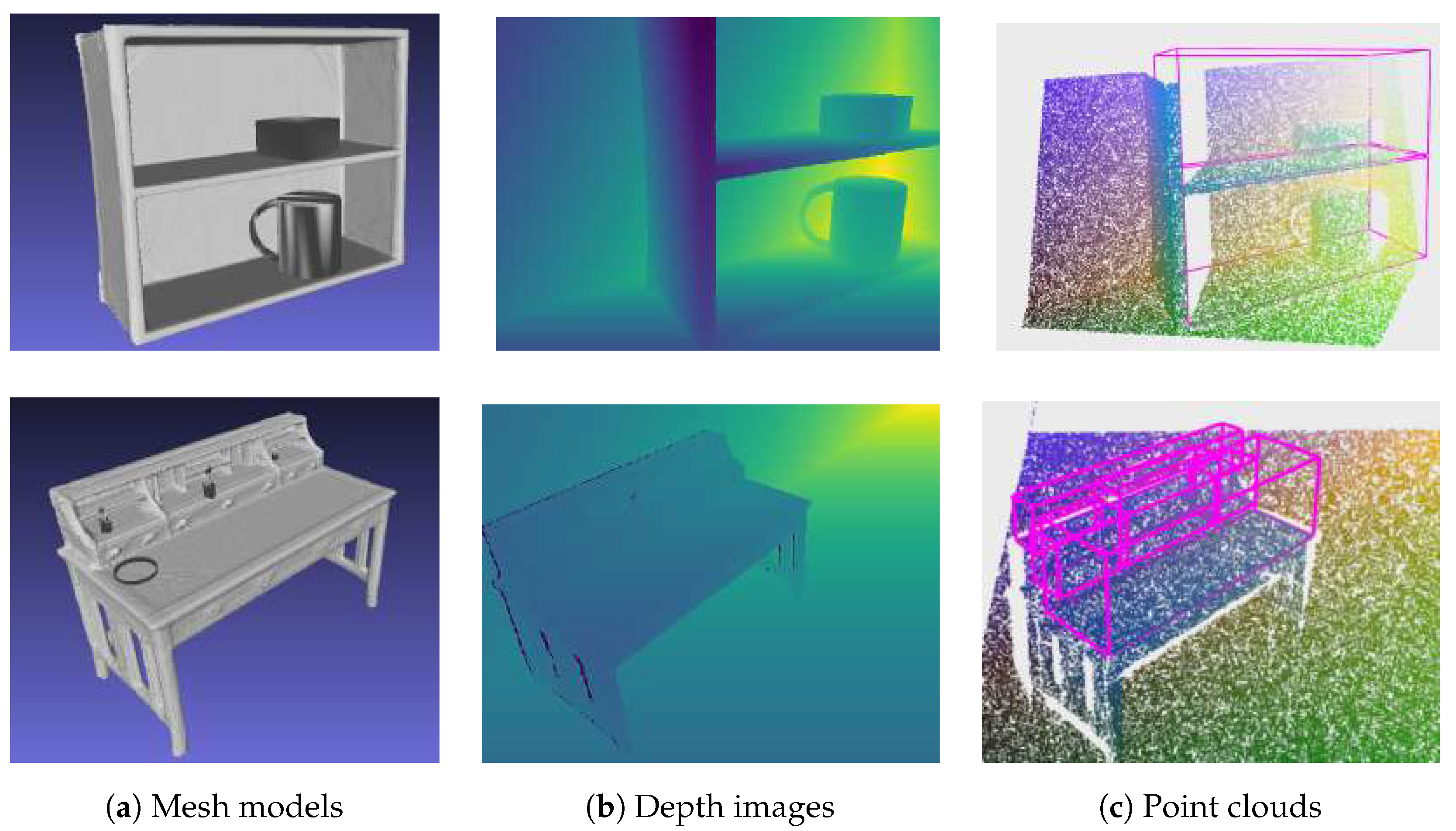
3.2. Synthetic Scenes Generation
4. Evaluation
4.1. Adaptation and Training of Neural Networks
4.2. Evaluation on the Synthetic Dataset
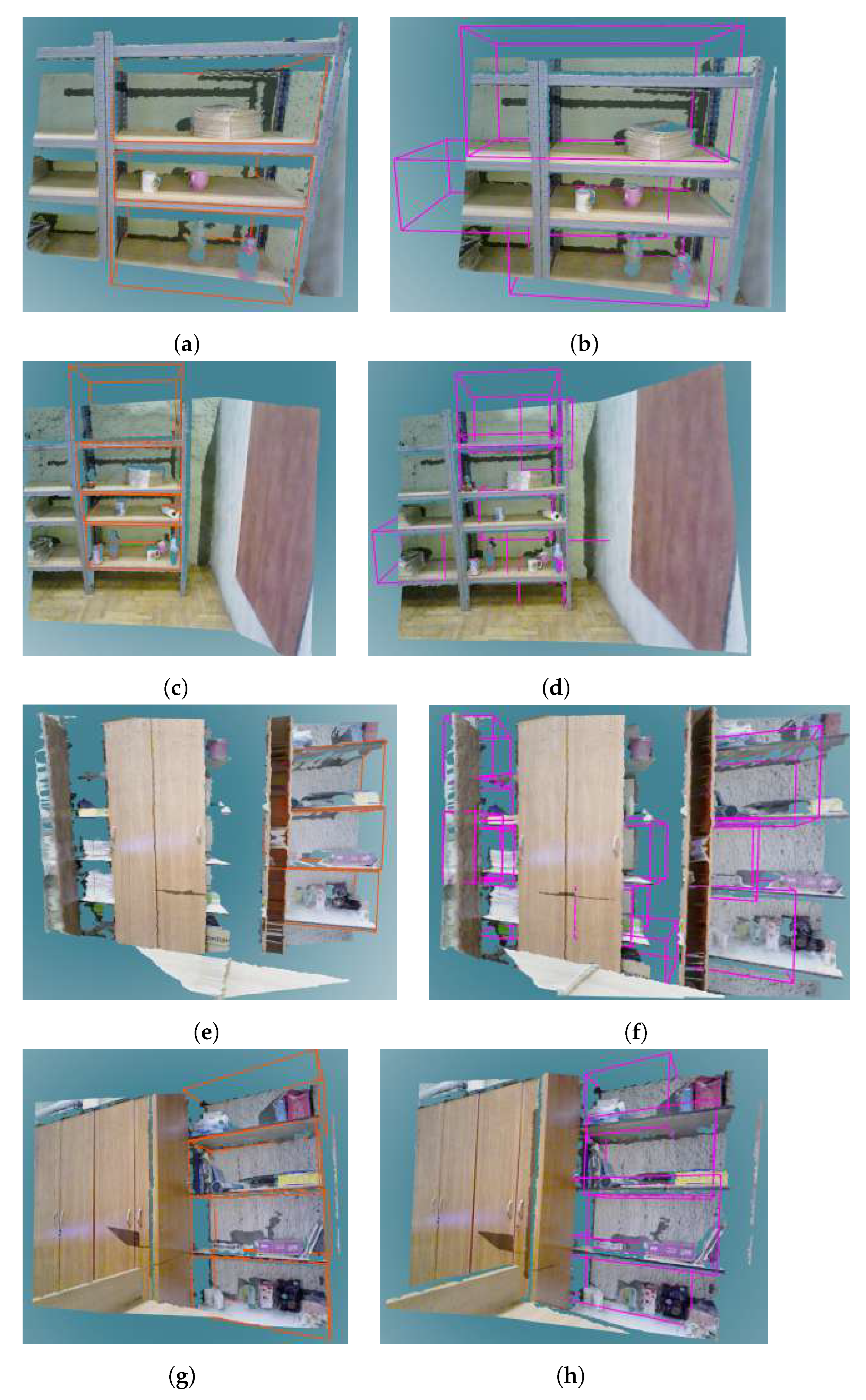
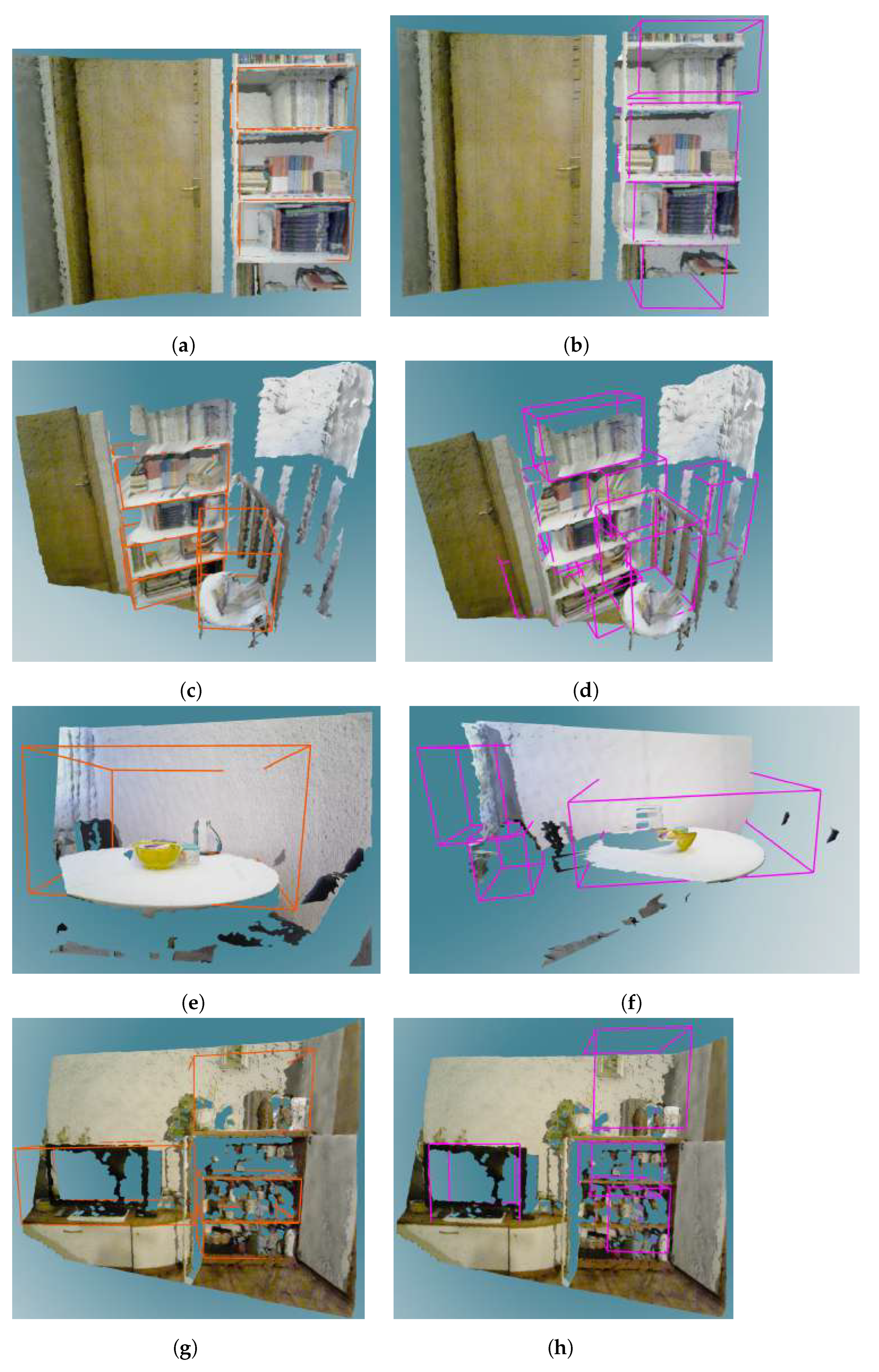
4.3. RGB-D Images of Real Scenes
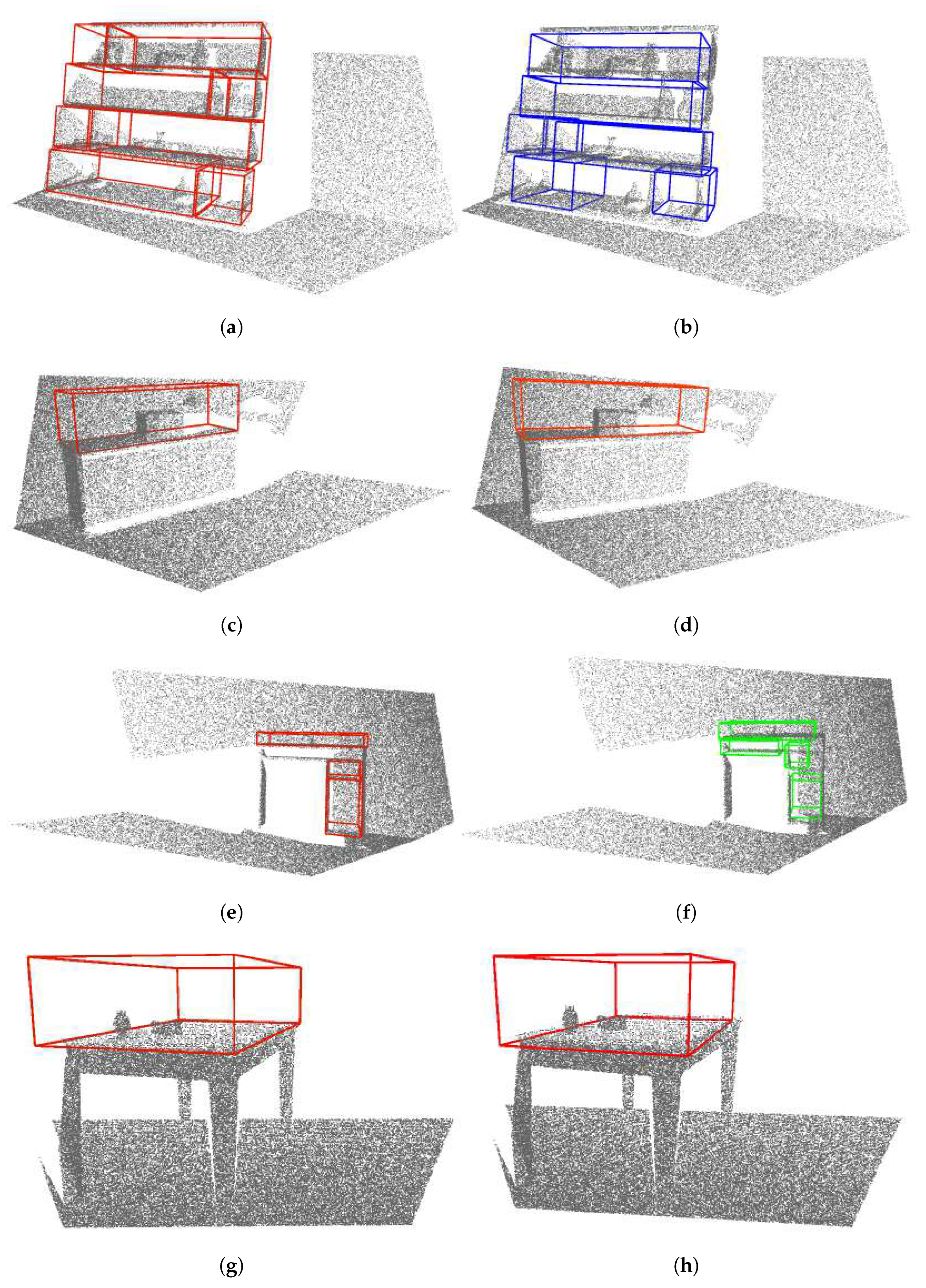
4.4. Ground Truth Annotation
5. Results
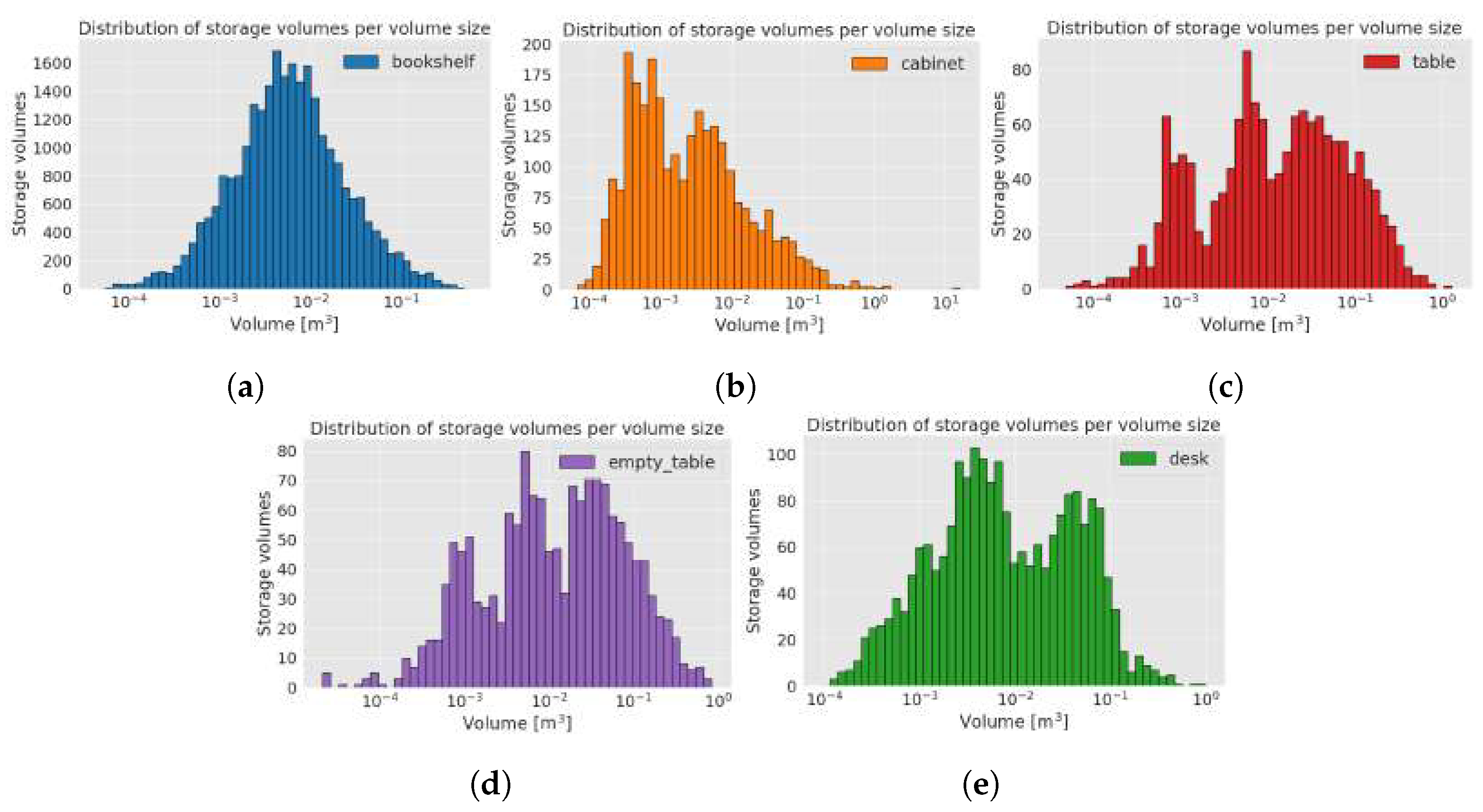
5.1. Synthetic Dataset
5.2. Real Dataset
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Sample Availability
References
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An information-rich 3D model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Qi, C.R.; Litany, O.; He, K.; Guibas, L.J. Deep hough voting for 3D object detection in point clouds. arXiv 2019, arXiv:1904.09664. [Google Scholar]
- Rukhovich, D.; Vorontsova, A.; Konushin, A. FCAF3D: Fully Convolutional Anchor-Free 3D Object Detection. arXiv 2021, arXiv:2112.00322. [Google Scholar]
- Lahoud, J.; Ghanem, B. 2D-Driven 3D Object Detection in RGB-D Images. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4632–4640. [Google Scholar] [CrossRef]
- Qi, C.R.; Chen, X.; Litany, O.; Guibas, L.J. ImVoteNet: Boosting 3D Object Detection in Point Clouds With Image Votes. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020; pp. 4403–4412. [Google Scholar] [CrossRef]
- Cosgun, A.; Hermans, T.; Emeli, V.; Stilman, M. Push planning for object placement on cluttered table surfaces. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; IEEE: Manhattan, NY, USA, 2011; pp. 4627–4632. [Google Scholar]
- Zhang, Z.; Sun, B.; Yang, H.; Huang, Q. H3DNet: 3D Object Detection Using Hybrid Geometric Primitives. arXiv 2020, arXiv:2006.05682. [Google Scholar]
- Chen, J.; Lei, B.; Song, Q.; Ying, H.; Chen, D.Z.; Wu, J. A Hierarchical Graph Network for 3D Object Detection on Point Clouds. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 389–398. [Google Scholar] [CrossRef]
- Cheng, B.; Sheng, L.; Shi, S.; Yang, M.; Xu, D. Back-tracing Representative Points for Voting-based 3D Object Detection in Point Clouds. arXiv 2021, arXiv:2104.06114. [Google Scholar]
- Liu, Z.; Zhang, Z.; Cao, Y.; Hu, H.; Tong, X. Group-Free 3D Object Detection via Transformers. arXiv 2021, arXiv:2104.00678. [Google Scholar]
- Xie, Q.; Lai, Y.K.; Wu, J.; Wang, Z.; Zhang, Y.; Xu, K.; Wang, J. MLCVNet: Multi-Level Context VoteNet for 3D Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020; pp. 10444–10453. [Google Scholar] [CrossRef]
- Xie, Q.; Lai, Y.K.; Wu, J.; Wang, Z.; Zhang, Y.; Xu, K.; Wang, J. Vote-based 3D Object detection with context modeling and SOB-3DNMS. Int. J. Comput. Vis. 2021, 129, 1857–1874. [Google Scholar] [CrossRef]
- Hu, H.; Immel, F.; Janosovits, J.; Lauer, M.; Stiller, C. A Cuboid Detection and Tracking System using A Multi RGBD Camera Setup for Intelligent Manipulation and Logistics. In Proceedings of the 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; pp. 1097–1103. [Google Scholar] [CrossRef]
- Zhou, B.; Wang, A.; Klein, J.F.; Kai, F. Object Detection and Mapping with Bounding Box Constraints. In Proceedings of the 2021 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Karlsruhe, German, 23–25 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Handa, A.; Patraucean, V.; Badrinarayanan, V.; Stent, S.; Cipolla, R. SceneNet: Understanding real world indoor scenes with synthetic data. arXiv 2015, arXiv:1511.07041. [Google Scholar]
- McCormac, J.; Handa, A.; Leutenegger, S.; Davison, A.J. SceneNet RGB-D: Can 5M synthetic images beat generic imagenet pre-training on indoor segmentation? In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Venice, Italy, 2017; pp. 2697–2706. [Google Scholar] [CrossRef]
- Song, S.; Yu, F.; Zeng, A.; Chang, A.X.; Savva, M.; Funkhouser, T. Semantic Scene Completion from a Single Depth Image. arXiv 2016, arXiv:1611.08974. [Google Scholar]
- Paschalidou, D.; Kar, A.; Shugrina, M.; Kreis, K.; Geiger, A.; Fidler, S. ATISS: Autoregressive Transformers for Indoor Scene Synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 12013–12026. [Google Scholar]
- Szot, A.; Clegg, A.; Undersander, E.; Wijmans, E.; Zhao, Y.; Turner, J.; Maestre, N.; Mukadam, M.; Chaplot, D.S.; Maksymets, O.; et al. Habitat 2.0: Training home assistants to rearrange their habitat. In Proceedings of the Advances in Neural Information Processing Systems; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 251–266. [Google Scholar]
- Pohlen, T.; Badami, I.; Mathias, M.; Leibe, B. Semantic segmentation of modular furniture. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–9 March 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Hržica, M.; Đurović, P.; Džijan, M.; Cupec, R. Finding empty volumes inside 3D models of storage furniture. In Proceedings of the 2021 Zooming Innovation in Consumer Technologies Conference (ZINC), Novi Sad, Serbia, 26–27 May 2021; pp. 242–245. [Google Scholar] [CrossRef]
- Seichter, D.; Langer, P.; Wengefeld, T.; Lewandowski, B.; Hochemer, D.; Gross, H.M. Efficient and robust semantic mapping for indoor environments. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Pennsylvania, PA, USA, 23–27 May 2022; pp. 9221–9227. [Google Scholar] [CrossRef]
- Varol, G.; Kuzu, R.S. Toward retail product recognition on grocery shelves. In Proceedings of the International Conference on Graphic and Image Processing, Singapore, 23–25 October 2015. [Google Scholar]
- Milella, A.; Marani, R.; Petitti, A.; Cicirelli, G.; D’Orazio, T. 3D Vision-Based Shelf Monitoring System for Intelligent Retail; Springer: Berlin/Heidelberg, Germany, 2021; pp. 447–459. [Google Scholar] [CrossRef]
- Milella, A.; Petitti, A.; Marani, R.; Cicirelli, G.; D’orazio, T. Towards Intelligent Retail: Automated on-Shelf Availability Estimation Using a Depth Camera. IEEE Access 2020, 8, 19353–19363. [Google Scholar] [CrossRef]
- Jha, D.; Mahjoubfar, A.; Joshi, A. Designing an efficient end-to-end machine learning pipeline for real-time empty-shelf detection. arXiv 2022, arXiv:2205.13060. [Google Scholar]
- Santra, B.; Ghosh, U.; Mukherjee, D.P. Graph-based modelling of superpixels for automatic identification of empty shelves in supermarkets. Pattern Recognit. 2022, 127, 108627. [Google Scholar] [CrossRef]
- Rosado, L.; Gonçalves, J.; Costa, J.; Ribeiro, D.; Soares, F. Supervised learning for Out-of-Stock detection in panoramas of retail shelves. In Proceedings of the 2016 IEEE International Conference on Imaging Systems and Techniques (IST), Crete Island, Greece, 4–6 October 2016; pp. 406–411. [Google Scholar] [CrossRef]
- Higa, K.; Iwamoto, K. Robust shelf monitoring using supervised learning for improving on-shelf availability in retail stores. Sensors 2019, 19, 2722. [Google Scholar] [CrossRef] [PubMed]
- Abdo, N.; Stachniss, C.; Spinello, L.; Burgard, W. Robot, organize my shelves! Tidying up objects by predicting user preferences. In Proceedings of the 2015 IEEE iNternational Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; IEEE: Manhattan, NY, USA, 2015; pp. 1557–1564. [Google Scholar]
- Majerowicz, L.; Shamir, A.; Sheffer, A.; Hoos, H.H. Filling your shelves: Synthesizing Diverse style-preserving artifact arrangements. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1507–1518. [Google Scholar] [CrossRef] [PubMed]
- Bailey, D.G. An efficient euclidean distance transform. In Combinatorial Image Analysis; Klette, R., Žunić, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 394–408. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. SUN RGB-D: A RGB-D scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and pattern Recognition, Boston, MA, USA, 7–12 June 2015; p. 10. [Google Scholar]
- Stutz, D.; Geiger, A. Learning 3D Shape Completion under Weak Supervision. arXiv 2018, arXiv:1805.07290. [Google Scholar] [CrossRef]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy Networks: Learning 3D Reconstruction in Function Space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Choy, C.B.; Xu, D.; Gwak, J.; Chen, K.; Savarese, S. 3D-R2N2: A Unified approach for single and multi-view 3D object Reconstruction. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Gwak, J.; Choy, C.B.; Savarese, S. Generative sparse detection networks for 3D Single-shot object detection. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020. [Google Scholar]
- Choy, C.; Gwak, J.; Savarese, S. 4D spatio-temporal ConvNets: Minkowski Convolutional neural networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3070–3079. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar] [CrossRef] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Count of Generated Scenes | ||||||
|---|---|---|---|---|---|---|
| Class Name | Count of Selected Shapenet Models | Training | Validation | Evaluation | Total | Count of Labeled Storage Volumes |
| bookshelf | 41 | 3600 | 901 | 501 | 5002 | 26,841 |
| cabinet | 10 | 725 | 182 | 501 | 1008 | 2702 |
| desk | 18 | 725 | 182 | 101 | 1008 | 2142 |
| table | 34 | 712 | 179 | 99 | 990 | 1512 |
| table empty | 34 | 712 | 179 | 99 | 990 | 1530 |
| negative | 4 | 720 | 180 | 100 | 1000 | 0 |
| TOTAL | 141 | 7194 | 1803 | 1001 | 9998 | 34,727 |
| Bounding Box | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class Name | Minimum | Maximum | Median All | Median per Axis | |||||||||||
| Size [m] | Volume | Size [m] | Volume | Size [m] | Volume | Size [m] | |||||||||
| x | y | z | [m] | x | y | z | [m] | x | y | z | [m] | x | y | z | |
| bookshelf | 0.072 | 0.072 | 0.070 | 45 × 10−6 | 1.36 | 3.39 | 1.03 | 0.60 | 0.273 | 0.518 | 0.322 | 0.006 | 0.31 | 0.41 | 0.32 |
| cabinet | 0.074 | 0.096 | 0.078 | 69 × 10−6 | 1.30 | 4.86 | 1.98 | 1.56 | 0.273 | 0.268 | 0.220 | 0.002 | 0.21 | 0.33 | 0.23 |
| desk | 0.084 | 0.081 | 0.112 | 95 × 10−6 | 1.79 | 3.27 | 1.36 | 1.00 | 0.250 | 0.225 | 0.949 | 0.007 | 0.36 | 0.64 | 0.32 |
| table | 0.088 | 0.058 | 0.062 | 40 × 10−6 | 2.44 | 2.96 | 1.44 | 1.29 | 0.487 | 0.541 | 0.384 | 0.013 | 0.50 | 0.88 | 0.27 |
| empty table | 0.073 | 0.041 | 0.056 | 21 × 10−6 | 2.11 | 2.56 | 1.24 | 0.84 | 0.481 | 0.535 | 0.379 | 0.012 | 0.49 | 0.90 | 0.27 |
| Environment | Home 1 | Home 2 | Office 1 | Office 2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Room/Furniture | Family Room | Living Room | Library | Bedroom | Gameroom | Kitchen | Pantry | Bookshelf Clutter | Bookshelf Empty | Desk | Cabinet | Total |
| Count of captured scenes | >4 | 5 | 12 | 23 | 8 | 5 | 22 | 16 | 11 | 36 | 9 | 151 |
| Count of annotated storage volumes | 17 | 11 | 43 | 54 | 20 | 5 | 88 | 51 | 55 | 102 | 34 | 480 |
| Real Dataset | Bounding Box | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Environment | Room | Minimum | Maximum | Median All | Median per Axis | |||||||||||
| Size [m] | Volume | Size [m] | Volume | Size [m] | Volume | Size [m] | ||||||||||
| x | y | z | [m] | x | y | z | [m] | x | y | z | [m] | x | y | z | ||
| Home 1 | Family room | 0.374 | 0.368 | 0.232 | 0.004 | 1.18 | 0.65 | 0.52 | 0.05 | 0.673 | 0.381 | 0.279 | 0.009 | 0.38 | 0.40 | 0.31 |
| Kitchen | 0.588 | 0.370 | 0.289 | 0.008 | 1.60 | 0.44 | 0.82 | 0.07 | 0.780 | 0.404 | 0.288 | 0.011 | 0.78 | 0.39 | 0.30 | |
| Library | 0.693 | 0.161 | 0.291 | 0.004 | 0.41 | 0.43 | 0.51 | 0.01 | 0.749 | 0.267 | 0.290 | 0.007 | 0.71 | 0.28 | 0.29 | |
| Home 2 | Bedroom | 0.550 | 0.051 | 0.277 | 0.001 | 1.506 | 0.471 | 0.553 | 0.049 | 0.516 | 0.390 | 0.271 | 0.007 | 0.534 | 0.394 | 0.280 |
| Gameroom | 0.470 | 0.222 | 0.189 | 0.002 | 1.135 | 1.083 | 0.504 | 0.077 | 0.513 | 0.274 | 0.208 | 0.004 | 0.488 | 0.318 | 0.197 | |
| Kitchen | 0.892 | 1.051 | 0.500 | 0.059 | 1.190 | 1.017 | 0.629 | 0.095 | 1.109 | 1.052 | 0.500 | 0.073 | 1.082 | 1.052 | 0.500 | |
| Pantry | 0.257 | 0.078 | 0.128 | 0.000 | 1.169 | 0.330 | 0.271 | 0.013 | 0.730 | 0.267 | 0.263 | 0.006 | 0.740 | 0.271 | 0.259 | |
| Office 1 | Bookshelf clutter | 0.758 | 0.574 | 0.202 | 0.011 | 1.145 | 0.573 | 0.500 | 0.041 | 0.756 | 0.591 | 0.322 | 0.018 | 0.761 | 0.573 | 0.322 |
| Bookshelf empty | 0.800 | 0.452 | 0.210 | 0.010 | 1.548 | 0.600 | 0.500 | 0.058 | 0.775 | 0.573 | 0.314 | 0.017 | 0.761 | 0.578 | 0.316 | |
| Desk | 0.240 | 0.666 | 0.087 | 0.002 | 1.328 | 0.670 | 0.535 | 0.060 | 0.218 | 0.764 | 0.644 | 0.013 | 0.614 | 0.637 | 0.502 | |
| Office 2 | Cabinet | 0.291 | 0.394 | 0.324 | 0.005 | 0.689 | 0.458 | 0.358 | 0.014 | 0.690 | 0.417 | 0.315 | 0.011 | 0.641 | 0.410 | 0.351 |
| IoU Threshold | Metric | NN | Synthetic Dataset | Real Dataset | ||
|---|---|---|---|---|---|---|
| DS1 | DS2 | DS | ||||
| 0.25 | Precision [%] | VoteNet | 44.09 | 39.63 | 43.66 | 42.22 |
| FCAF3D | 45.47 | 57.69 | 47.72 | 24.17 | ||
| Recall [%] | VoteNet | 62.91 | 57.46 | 62.29 | 66.67 | |
| FCAF3D | 70.83 | 73.31 | 71.41 | 75.42 | ||
| 0.50 | Precision [%] | VoteNet | 13.85 | 13.99 | 14.03 | 5.25 |
| FCAF3D | 29.17 | 43.27 | 32.23 | 9.9 | ||
| Recall [%] | VoteNet | 35.77 | 35.78 | 35.91 | 21.04 | |
| FCAF3D | 42.97 | 55.24 | 45.82 | 41.46 | ||
| Environment | Home 1 | Home 2 | Office 1 | Office 2 | Dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Room | NN | Family Room | Living Room | Library | Bedroom | Gameroom | Kitchen | Pantry | Bookshelf Clutter | Bookshelf Empty | Desk | Cabinet | ||
| 0.25 | Precision [%] | VoteNet | 37.73 | 56.44 | 43.22 | 33.64 | 40.72 | 73.10 | 43.38 | 64.50 | 53.21 | 42.85 | 55.35 | 42.22 |
| FCAF3D | 25.15 | 9.66 | 37.75 | 27.25 | 26.11 | 74.58 | 45.72 | 29.30 | 18.82 | 53.41 | 20.89 | 24.17 | ||
| Recall [%] | VoteNet | 64.71 | 81.82 | 74.42 | 64.81 | 60.00 | 100.00 | 62.50 | 84.31 | 61.82 | 63.73 | 91.18 | 66.67 | |
| FCAF3D | 82.35 | 72.73 | 76.74 | 85.19 | 65.00 | 100.00 | 78.41 | 72.55 | 65.45 | 72.55 | 67.65 | 75.42 | ||
| 0.50 | Precision [%] | VoteNet | 0.84 | 0.00 | 0.83 | 4.61 | 0.00 | 34.00 | 0.73 | 20.22 | 1.88 | 6.32 | 22.20 | 5.25 |
| FCAF3D | 7.72 | 0.25 | 21.53 | 16.09 | 2.25 | 27.50 | 19.38 | 17.66 | 2.31 | 27.88 | 8.27 | 9.90 | ||
| Recall [%] | VoteNet | 5.88 | 0.00 | 11.63 | 20.37 | 0.00 | 60.00 | 6.82 | 39.22 | 9.09 | 24.51 | 52.94 | 21.04 | |
| FCAF3D | 23.53 | 9.09 | 37.21 | 51.85 | 35.00 | 80.00 | 40.91 | 45.10 | 20.00 | 49.02 | 41.18 | 41.46 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hržica, M.; Pejić, P.; Hartmann Tolić, I.; Cupec, R. Detection of Household Furniture Storage Space in Depth Images. Sensors 2022, 22, 6774. https://doi.org/10.3390/s22186774
Hržica M, Pejić P, Hartmann Tolić I, Cupec R. Detection of Household Furniture Storage Space in Depth Images. Sensors. 2022; 22(18):6774. https://doi.org/10.3390/s22186774
Chicago/Turabian StyleHržica, Mateja, Petra Pejić, Ivana Hartmann Tolić, and Robert Cupec. 2022. "Detection of Household Furniture Storage Space in Depth Images" Sensors 22, no. 18: 6774. https://doi.org/10.3390/s22186774