5.1.1. Washing Machine
The disaggregation performances of the algorithms for the washing machine are displayed in
Table 2. For
Hz, the
S2P had a lower MAE than the
DAE and
S2S for 10 out of 11 houses, as well as a lower MAE median across the houses. By computing the TSKS tests for
Hz, the
p-values of the KS statistic were larger than any
p-value of significance (i.e.,
,
, and
are all greater than
). Since there was evidence for the pairwise distributions to be identical, it was adequate to use the MAE mean for comparison between the obtained performance samples.
S2P was also the algorithm with the lower MAE mean. Hence,
S2P was chosen for disaggregating the washing machine at
Hz.
Similarly, for Hz, S2P seemed to attain the best performance across the houses and a lower average MAE. From the TSKS tests for Hz, it was adequate to consider the MAE mean across the houses since there was evidence that the algorithms’ performance samples were identical (i.e., ). Therefore, S2P was the chosen algorithm.
The
S2P performance samples had small differences across the data scenarios, and the conclusions were similar (
Table 2), which indicates that the WM activations were captured for both scenarios. If the data were sampled with lower granularity (e.g., one sample for each 15 min), the disaggregation results could possibly show more differences between the data scenarios.
In order to inspect the overall effects of the characteristics, the S2P performance samples and (or a transformation of these samples) were fitted to a regression model as in Equation (1). From the Shapiro–Wilk test, there was evidence that the sample distributions were not normally distributed (i.e., , and ). The fitted for the BCT was close to zero in both cases (i.e., and ) and were thus approximated to zero (log-transformation) to facilitate further interpretation.
When the log-transform was considered for
and
, the
p-value of the Shapiro–Wilk test improved (i.e.,
and
). This is also indicated through the histogram visualization and KDE in
Figure 1, with the log-distributions of
and
closer to the normal distribution and, in particular, more symmetric.
The selected models are represented in Equation (2)
for
by carrying out BSS across the variables in
Table 1. Although the variable
DA could be relevant for explaining appliance consumption patterns, it was not considered because it comprised a large number of levels (seven in total), each of which was not sufficiently represented due to the small number of houses in the datasets. Furthermore, some DA levels were redundant (e.g.,
post 2002 and
2005), and there was a missing value for house 2. In contrast, for the variable
DT, the number of levels was smaller, each of which was represented more. The reference group for
DT was chosen to be
D (without loss of generality).
By inspecting Equation (2), it seems that the dwelling size, number of appliances, and dwelling type had no significant impact on the disaggregation performance for both data scenarios because these variables were not included in the selected models (estimated coefficients equal to zero). In contrast, the characteristic with a higher impact on disaggregation of the washing machine was the number of occupants for both data scenarios. The average effect of an integer variable on the disaggregation performance sample for a one-unit increase while the remaining variables were fixed was equal to , where a is the estimated variable coefficient. In a similar fashion, the average impact of the dummies was calculated in relation to the chosen reference group when using the same formula. In the context of the disaggregation problem, if the variable coefficient is negative, then the performance improves, and vice-versa.
Hence, if the number of occupants is increased by one unit, with the remaining variables being fixed, then the disaggregation performance decreases, on average, by a factor of for Hz ( for Hz). For the remaining characteristics, the effects are not relevant.
5.1.2. Dishwasher
The disaggregation results for the DW in
Table 3 demonstrate that
S2S achieved the best performance overall in both data scenarios. For
Hz, the MAE median and MAE mean for
S2S were improved in comparison with the other algorithms. Since the distributions of the performance samples appeared to be the same in the TSKS tests, using the mean for comparison was appropriate (i.e., the
p-values of the KS statistic
,
, and
were all greater than
).
Similarly, for Hz, S2S attained the best performance across the houses in general and a lower MAE median and MAE mean. Again, the TSKS tests show that it is adequate to use the mean for comparison of the performance samples (i.e., , , and were all greater than ).
In this case, the S2S performance samples exhibited some differences across the data scenarios, mainly for houses 2, 6, and 13. Hence, it is possible that a fraction of dishwasher activations at Hz were also not detected for Hz.
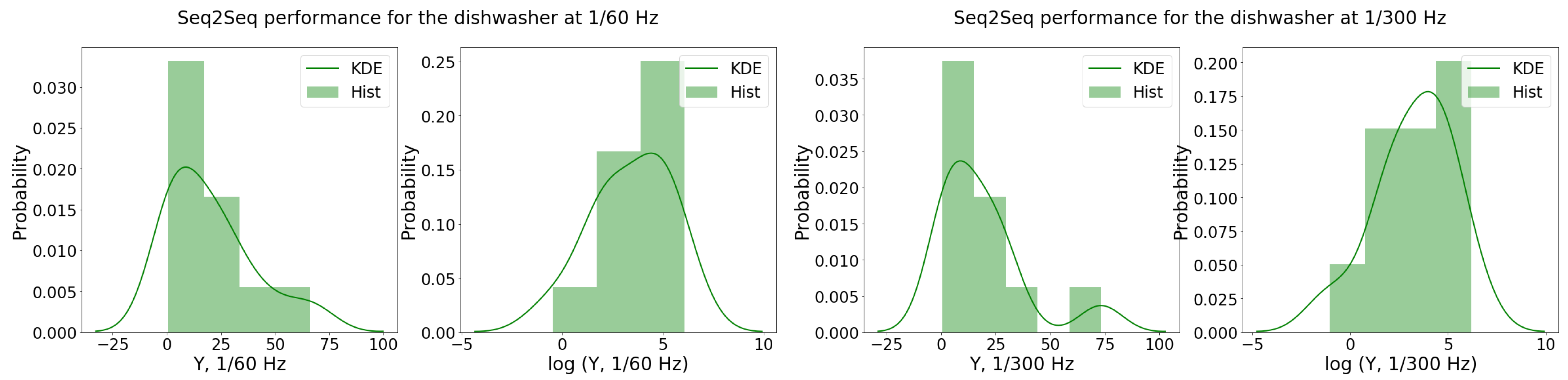
The
S2S performance samples across the houses, denoted as
and
, were fitted to a regression model. From the the Shapiro–Wilk test, the sample distributions did not seem to be normally distributed (i.e.,
and
). A BCT is suggested to be carried out with
and
. Since these values were close to zero, the log transformation was used to approximate the BCT. Indeed, the
p-value of the Shapiro–Wilk test improved when the log-transform was considered (i.e.,
and
). This can also be observed through the histogram visualization and KDE in
Figure 2, in which the log-distributions are closer to the normal distribution. The selected regression models are represented in Equation (3) using BSS:
According to Equation (3), the dwelling size had no relevant effect on the performance for both scenarios. For Hz, a one-unit increase in the number of occupants, with the remaining variables held constant, reduced the performance by a factor of (similar to Hz) on average. Furthermore, if the dwelling was semi-detached, this improved the performance by ( for Hz) when compared with a detached dwelling type. The number of appliances did not seem to be significant for explaining the performance because the effects of this variable varied depending on the data scenario considered. For Hz, a one-unit increase in the number of appliances improved the performance by on average, although this variable had no significance for Hz.
5.1.3. Microwave
The disaggregation results for the MW in
Table 4 show that
S2P performed the best overall for either the
-Hz or
-Hz granularities. For
Hz, the MAE median and MAE mean were lower for
S2P. The mean was adequate to be considered for comparison, as the TSKS tests indicated that the performance samples followed similar distributions (i.e., the
p-values of the KS statistic
were all greater than
).
For Hz, S2P attained the best performance for most houses and also had a lower MAE median and average MAE. Again, the TSKS tests indicated that the performance samples followed similar distributions (i.e., , and were all greater than 0.10). Similar to the washing machine, there were no significant differences in the S2P performance samples across the two data scenarios).
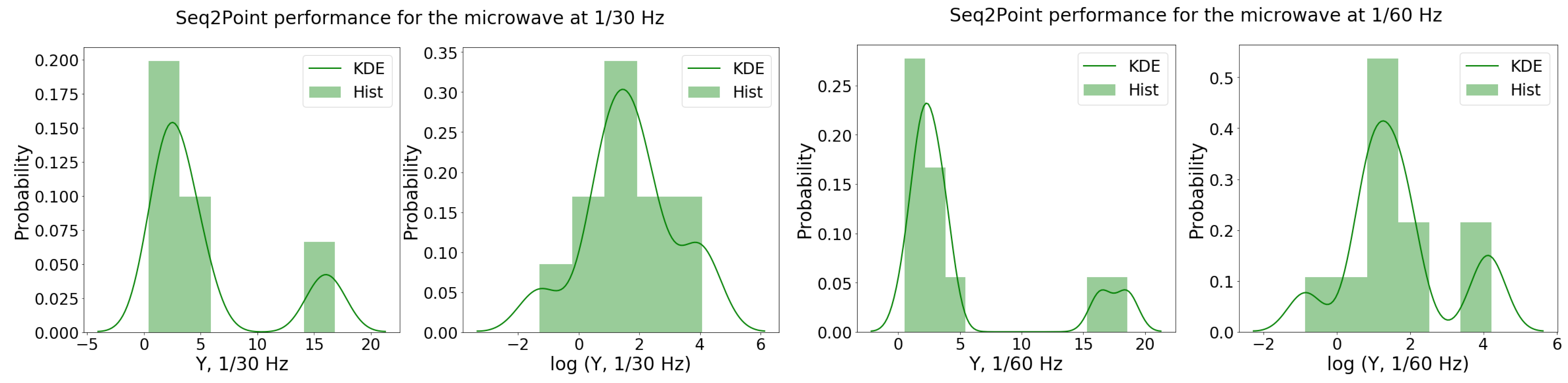
The
S2P performance samples
and
were then fitted to a regression model. From the Shapiro–Wilk tests, the sample distributions did not seem to come from a normal distribution (i.e.,
and
). A BCT was suggested with
and
. Since these values were relatively close to zero, the log transformation was considered. Indeed, the
p-value of the Shapiro–Wilk test for the log-distributions of
and
improved (i.e.,
and
). This is also indicated by inspection of the histograms and KDE, as shown in
Figure 3.
The selected models’ interpretations were similar for both data scenarios, as observed in Equation (4):
It seems that the number of occupants, the number of appliances, and the dwelling type had no significant effect on the disaggregation performance. In contrast, the dwelling size was the characteristic with a higher impact. By increasing the number of bedrooms in one unit, the disaggregation performance decreased on average by a factor of for 1/30 Hz ( for 1/60 Hz).








{kind=link}
{kind=link}
{kind=link}