
FASTNN: A Deep Learning Approach for Traffic Flow Prediction Considering Spatiotemporal Features

Abstract
:1. Introduction
- (1)
- This paper proposed a traffic flow prediction model based on a deep learning framework, the FASTNN, which can model ST aggregation and quantify intrinsic correlation and redundancy of ST features.
- (2)
- In this paper, filter spatial attention (FSA) was proposed to model the ST agglomeration of traffic data, and this module can implement dynamic adjustment of spatial weights.
- (3)
- This paper proposed a lightweight module, the matrix factorization based resample module (MFR), which can model the intrinsic correlation of the same ST feature and reduce the redundant information between different ST features.
2. Related Works
2.1. Traffic Flow Prediction
2.2. Attention for TFP
3. Problem and Definition
3.1. Problem
- (1)
- ST aggregation:
- (2)
- Intrinsic correlation of the same ST features and redundancy between different ST features:
3.2. Definition
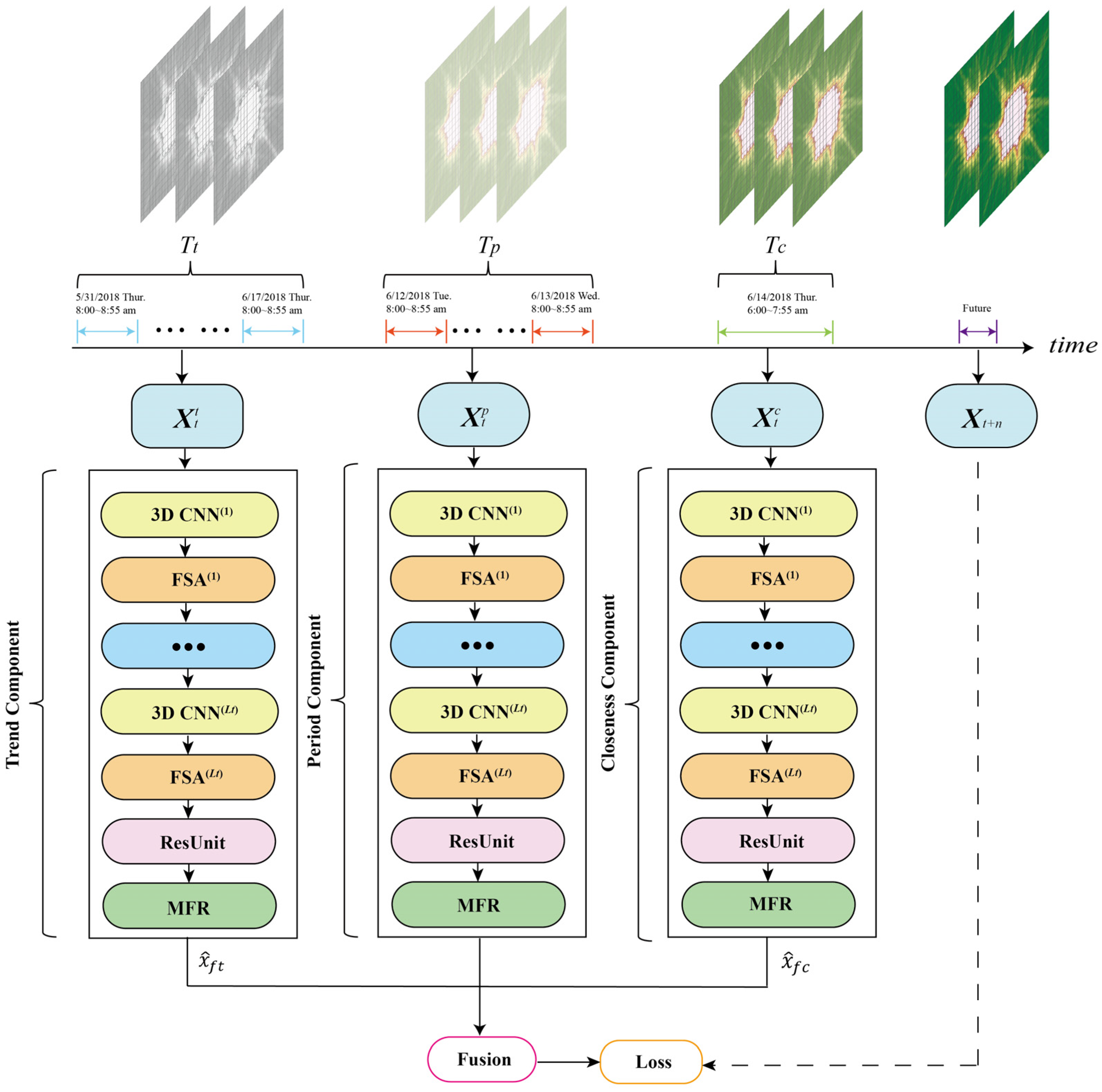
4. Methodology
- The closeness component;
- 2.
- The period component;
- 3.
- The trend component;
4.1. 3D Convolutional Neural Network
4.2. Filter Spatial Attention
4.3. Residual Unit
4.4. Matrix Factorization Based Resample Module
- Direct training using fully-connected layers introduces excessive training parameters that can lead to difficult optimization or overfitting of the model.
4.5. Fusion Component
4.6. Loss Function
5. Experiments
- How does the FASTNN proposed in this paper perform compared to the baselines?
- What is the performance of the FASTNN variants with different modules?
- How effective are the FSA module and the MFR module proposed in this paper?
- Why are FSA and MFR effective?
5.1. Dataset
- TaxiBJ dataset is crowd flow data obtained from GPS trajectory data of Beijing cabs, which contains four-time intervals: 1 July 2013, to 30 October 2013; 1 March 2014 to 30 June 2014; 1 March 2015, to 30 June 2015; and 1 November 2015, to 10 April 2016. This dataset firstly divides the main urban area of Beijing into 32 × 32 grid areas, and secondly counts the origin and destination points of each vehicle trajectory in the above four time periods according to the 0.5 h interval. Because the dataset has ST continuity, the dataset can detect all traffic conditions under a specific region;
- BikeNYC dataset is obtained from 1 April to 30 September 2014, New York City Bicycle System [39]. This dataset divides the main city of New York into a 16 × 8 grid, and counts the inflow and outflow of crowds within the area at one-hour time intervals, with a total number of time timestamps of 4392. This dataset is based on the 2014 NYC Bike system bike-sharing trip data and counts the traffic flow within the 16 × 8 grid according to the bike-sharing orders in each area, by latitude and longitude.
5.2. Baselines
- History Average Model (HA): The predicted flow of the model is the average of the recent historical traffic data at the corresponding time;
- Autoregressive Integrated Moving Average Model (ARIMA): ARIMA regards the data series of the prediction object over time as a random sequence, and uses a certain mathematical model to describe this sequence approximately;
- Support Vector Regression (SVR): SVR utilizes linear support vector machines for regression tasks, and the central idea of the model is to find a regression plane such that all the data in a set are closest to that plane;
- Long Short-Term Memory (LSTM): LSTM is a neural network with the ability to remember long and short-term information, consisting of a unit, input gates, output gates, and forgetting gates, for solving the problem of long-term dependencies;
- Gated Recurrent Unit (GRU): GRU [57] is a variant of LSTM. A gating mechanism is used to control the input, memory, and other information, while making predictions at the current time step;
- ConvLSTM: The convolution mechanism [58], which can extract spatial features, is added to the LSTM network, which can extract temporal features and can capture ST relationships;
- ST-ResNet: Spatiotemporal residual network [39], which utilizes three residual neural network components to model the temporal closeness, period, and trend properties of urban flows;
- ST3Dnet: An end-to-end deep learning model [18], ST3Dnet uses the 3D CNN and recalibration module to model the local and global dependencies.
5.3. Evaluation Metrics
5.4. Model Training
5.5. Performance Comparison with Baselines (Q1)
5.6. Evaluations on Variants of the Module (Q2)
- STNN: This model has removed all FSA modules and MFR modules from the FASTNN, remaining the components of 3D CNN and the residual unit;
- FASTNN-MA: This model has replaced the FSA module in the FASTNN with the MA;
- FASTNN-SA: This model has replaced the FSA module in the FASTNN with the SA;
- FASTNN-FNN: This model has replaced the MFR module in the FASTNN with the FNN;
- FASTNN-add: The FASTNN-add model has replaced the MFR module in the FASTNN with the adding layer, the adding layer can sum the ST features by filters.
5.7. Evaluations on Ablation Analysis (Q3)
5.8. Effective of the Module (Q4)
6. Conclusions
- (1)
- In the comparison of the baseline models, the deep learning-based baselines have better predictive performance than the traditional baselines, which indicates that deep learning-based baselines are capable of eliminating the subjective factors caused by the artificial design compared to traditional baselines and also have enhanced spatiotemporal dependent nonlinear fitting capability;
- (2)
- The performance of the FASTNN was evaluated using two large-scale real datasets, and the results indicate that the FASTNN achieves more accurate predictions than the existing baselines, and the performance of FASTNN improves by 22.94% and 9.86% (RMSE) on the BikeNYC and TaxiBJ datasets compared to the baseline with optimal performance. Simultaneously, the same predicted performance results also appear in the variant experiments;
- (3)
- In the ablation analysis, the FASTNN model with FSA predicted better performance than the model with MFR, indicating that modeling of spatiotemporal aggregation is more critical than the modeling of intrinsic correlation and redundancy of spatiotemporal features.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lv, Z.Q.; Li, J.B.; Dong, C.A.H.; Xu, Z.H. DeepSTF: A Deep Spatial-Temporal Forecast Model of Taxi Flow. Comput. J. 2021. [Google Scholar] [CrossRef]
- Zheng, Y.; Capra, L.; Wolfson, O.; Yang, H. Urban Computing: Concepts, Methodologies, and Applications. Acm Trans. Intell. Syst. Technol. 2014, 5, 1–55. [Google Scholar] [CrossRef]
- Kim, D.; Jeong, O. Cooperative Traffic Signal Control with Traffic Flow Prediction in Multi-Intersection. Sensors 2020, 20, 137. [Google Scholar] [CrossRef]
- Luis Zambrano-Martinez, J.; Calafate, C.T.; Soler, D.; Cano, J.-C.; Manzoni, P. Modeling and Characterization of Traffic Flows in Urban Environments. Sensors 2018, 18, 2020. [Google Scholar] [CrossRef]
- Ma, X.L.; Tao, Z.M.; Wang, Y.H.; Yu, H.Y.; Wang, Y.P. Long short-term memory neural network for traffic speed prediction using remote microwave sensor data. Transp. Res. Part C-Emerg. Technol. 2015, 54, 187–197. [Google Scholar] [CrossRef]
- Wei, W.Y.; Wu, H.H.; Ma, H. An AutoEncoder and LSTM-Based Traffic Flow Prediction Method. Sensors 2019, 19, 2946. [Google Scholar] [CrossRef]
- Kuang, L.; Yan, X.J.; Tan, X.H.; Li, S.Q.; Yang, X.X. Predicting Taxi Demand Based on 3D Convolutional Neural Network and Multi-task Learning. Remote Sens. 2019, 11, 1265. [Google Scholar] [CrossRef]
- Chu, K.-F.; Lam, A.Y.S.; Li, V.O.K. Deep Multi-Scale Convolutional LSTM Network for Travel Demand and Origin-Destination Predictions. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3219–3232. [Google Scholar] [CrossRef]
- Niu, K.; Cheng, C.; Chang, J.; Zhang, H.; Zhou, T. Real-Time Taxi-Passenger Prediction With L-CNN. IEEE Trans. Veh. Technol. 2019, 68, 4122–4129. [Google Scholar] [CrossRef]
- Lin, X.F.; Huang, Y.Z. Short-Term High-Speed Traffic Flow Prediction Based on ARIMA-GARCH-M Model. Wirel. Pers. Commun. 2021, 117, 3421–3430. [Google Scholar] [CrossRef]
- Evgeniou, T.; Pontil, M.; Poggio, T. Regularization networks and support vector machines. Adv. Comput. Math. 2000, 13, 1–50. [Google Scholar] [CrossRef]
- Smola, A.J.; Scholkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.B.; Zheng, Y.; Qi, D.K.; Li, R.Y.; Yi, X.W. DNN-Based Prediction Model for Spatio-Temporal Data. In Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM SIGSPATIAL GIS), San Francisco, CA, USA, 31 October–3 November 2016. [Google Scholar]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.Y.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef]
- Saxena, D.; Cao, J.N. Multimodal Spatio-Temporal Prediction with Stochastic Adversarial Networks. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–23. [Google Scholar] [CrossRef]
- Wang, X.Y.; Ma, Y.; Wang, Y.Q.; Jin, W.; Wang, X.; Tang, J.L.; Jia, C.Y.; Yu, J. Traffic Flow Prediction via Spatial Temporal Graph Neural Network. In Proceedings of the 29th World Wide Web Conference (WWW), Taipei, Taiwan, 20–24 April 2020; pp. 1082–1092. [Google Scholar]
- Guo, S.N.; Lin, Y.F.; Feng, N.; Song, C.; Wan, H.Y. Attention Based Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 922–929. [Google Scholar]
- Luis Zambrano-Martinez, J.; Calafate, C.T.; Soler, D.; Lemus-Zuniga, L.-G.; Cano, J.-C.; Manzoni, P.; Gayraud, T. A Centralized Route-Management Solution for Autonomous Vehicles in Urban Areas. Electronics 2019, 8, 722. [Google Scholar] [CrossRef]
- Williams, B.M.; Hoel, L.A. Modeling and forecasting vehicular traffic flow as a seasonal ARIMA process: Theoretical basis and empirical results. J. Transp. Eng. 2003, 129, 664–672. [Google Scholar] [CrossRef]
- Liu, Y.Y.; Tseng, F.M.; Tseng, Y.H. Big Data analytics for forecasting tourism destination arrivals with the applied Vector Autoregression model. Technol. Forecast. Soc. Change 2018, 130, 123–134. [Google Scholar] [CrossRef]
- Habtemichael, F.G.; Cetin, M. Short-term traffic flow rate forecasting based on identifying similar traffic patterns. Transp. Res. Part C-Emerg. Technol. 2016, 66, 61–78. [Google Scholar] [CrossRef]
- Jeong, Y.S.; Byon, Y.J.; Castro-Neto, M.M.; Easa, S.M. Supervised Weighting-Online Learning Algorithm for Short-Term Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1700–1707. [Google Scholar] [CrossRef]
- Chandra, S.R.; Al-Deek, H. Predictions of Freeway Traffic Speeds and Volumes Using Vector Autoregressive Models. J. Intell. Transp. Syst. 2009, 13, 53–72. [Google Scholar] [CrossRef]
- Zhang, F.; Zhu, X.; Hu, T.; Guo, W.; Chen, C.; Liu, L. Urban Link Travel Time Prediction Based on a Gradient Boosting Method Considering Spatiotemporal Correlations. Isprs Int. J. Geo-Inf. 2016, 5, 201. [Google Scholar] [CrossRef]
- Cheng, S.; Lu, F.; Peng, P.; Wu, S. A Spatiotemporal Multi-View-Based Learning Method for Short-Term Traffic Forecasting. Isprs Int. J. Geo-Inf. 2018, 7, 218. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Rice, J.A. Short-term travel time prediction. Transp. Res. Part C-Emerg. Technol. 2003, 11, 187–210. [Google Scholar] [CrossRef]
- Wu, Z.H.; Pan, S.R.; Long, G.D.; Jiang, J.; Zhang, C.Q. Graph WaveNet for Deep Spatial-Temporal Graph Modeling. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 1907–1913. [Google Scholar]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU Neural Network Methods for Traffic Flow Prediction. In Proceedings of the 31st Youth Academic Annual Conference of Chinese-Association-of-Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar]
- He, Y.X.; Li, L.S.; Zhu, X.T.; Tsui, K.L. Multi-Graph Convolutional-Recurrent Neural Network (MGC-RNN) for Short-Term Forecasting of Transit Passenger Flow. IEEE Trans. Intell. Transp. Syst. 2022. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Z.; Jia, R. DeepPF: A deep learning based architecture for metro passenger flow prediction. Transp. Res. Part C-Emerg. Technol. 2019, 101, 18–34. [Google Scholar] [CrossRef]
- Du, B.; Peng, H.; Wang, S.; Bhuiyan, M.Z.A.; Wang, L.; Gong, Q.; Liu, L.; Li, J. Deep Irregular Convolutional Residual LSTM for Urban Traffic Passenger Flows Prediction. IEEE Trans. Intell. Transp. Syst. 2020, 21, 972–985. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, Y.; Hu, J.; Zhao, Y.; Li, S.; Hu, J. Deep Autoencoder Neural Networks for Short-Term Traffic Congestion Prediction of Transportation Networks. Sensors 2019, 19, 2229. [Google Scholar] [CrossRef]
- Zhang, J.B.; Zheng, Y.; Qi, D.K. Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 1655–1661. [Google Scholar]
- Guo, S.N.; Lin, Y.F.; Li, S.J.; Chen, Z.M.; Wan, H.Y. Deep Spatial-Temporal 3D Convolutional Neural Networks for Traffic Data Forecasting. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3913–3926. [Google Scholar] [CrossRef]
- Yao, H.X.; Wu, F.; Ke, J.T.; Tang, X.F.; Jia, Y.T.; Lu, S.Y.; Gong, P.H.; Ye, J.P.; Li, Z.H. Deep Multi-View Spatial-Temporal Network for Taxi Demand Prediction. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 2588–2595. [Google Scholar]
- Sun, S.; Wu, H.; Xiang, L. City-Wide Traffic Flow Forecasting Using a Deep Convolutional Neural Network. Sensors 2020, 20, 421. [Google Scholar] [CrossRef] [Green Version]
- Ko, E.; Ahn, J.; Kim, E.Y. 3D Markov Process for Traffic Flow Prediction in Real-Time. Sensors 2016, 16, 147. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Zheng, Y.; Qi, D.; Li, R.; Yi, X.; Li, T. Predicting citywide crowd flows using deep spatio-temporal residual networks. Artif. Intell. 2018, 259, 147–166. [Google Scholar] [CrossRef]
- Chen, C.; Li, K.L.; Teo, S.G.; Chen, G.Z.; Zou, X.F.; Yang, X.L.; Vijay, R.C.; Feng, J.S.; Zeng, Z.; IEEE. Exploiting Spatio-Temporal Correlations with Multiple 3D Convolutional Neural Networks for Citywide Vehicle Flow Prediction. In Proceedings of the 18th IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 893–898. [Google Scholar]
- Zhang, J.B.; Zheng, Y.; Sun, J.K.; Qi, D.K. Flow Prediction in Spatio-Temporal Networks Based on Multitask Deep Learning. IEEE Trans. Knowl. Data Eng. 2020, 32, 468–478. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Z.; Lyu, C.; Ye, J. Attention-Based Deep Ensemble Net for Large-Scale Online Taxi-Hailing Demand Prediction. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4798–4807. [Google Scholar] [CrossRef]
- Yan, S.J.; Xiong, Y.J.; Lin, D.H. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7444–7452. [Google Scholar]
- Zheng, Z.B.; Yang, Y.T.; Liu, J.H.; Dai, H.N.; Zhang, Y. Deep and Embedded Learning Approach for Traffic Flow Prediction in Urban Informatics. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3927–3939. [Google Scholar] [CrossRef]
- Fang, S.; Zhang, Q.; Meng, G.; Xiang, S.; Pan, C. GSTNet: Global Spatial-Temporal Network for Traffic Flow Prediction. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 2286–2293. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Hao, S.; Lee, D.-H.; Zhao, D. Sequence to sequence learning with attention mechanism for short-term passenger flow prediction in large-scale metro system. Transp. Res. Part C-Emerg. Technol. 2019, 107, 287–300. [Google Scholar] [CrossRef]
- Wang, Z.; Su, X.; Ding, Z. Long-Term Traffic Prediction Based on LSTM Encoder-Decoder Architecture. IEEE Trans. Intell. Transp. Syst. 2021, 22, 6561–6571. [Google Scholar] [CrossRef]
- Zheng, C.; Fan, X.; Wang, C.; Qi, J. GMAN: A Graph Multi-Attention Network for Traffic Prediction. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 1234–1241. [Google Scholar]
- Do, L.N.N.; Vu, H.L.; Vo, B.Q.; Liu, Z.Y.; Phung, D. An effective spatial-temporal attention based neural network for traffic flow prediction. Transp. Res. Part C-Emerg. Technol. 2019, 108, 12–28. [Google Scholar] [CrossRef]
- Yu, K.; Qin, X.; Jia, Z.; Du, Y.; Lin, M. Cross-Attention Fusion Based Spatial-Temporal Multi-Graph Convolutional Network for Traffic Flow Prediction. Sensors 2021, 21, 8468. [Google Scholar] [CrossRef]
- Jia, H.; Luo, H.; Wang, H.; Zhao, F.; Ke, Q.; Wu, M.; Zhao, Y. ADST: Forecasting Metro Flow Using Attention-Based Deep Spatial-Temporal Networks with Multi-Task Learning. Sensors 2020, 20, 4574. [Google Scholar] [CrossRef]
- Liu, D.; Tang, L.; Shen, G.; Han, X. Traffic Speed Prediction: An Attention-Based Method. Sensors 2019, 19, 3836. [Google Scholar] [CrossRef] [PubMed]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pan, Z.Y.; Wang, Z.Y.; Wang, W.F.; Yu, Y.; Zhang, J.B.; Zheng, Y. Matrix Factorization for Spatio-Temporal Neural Networks with Applications to Urban Flow Prediction. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM), Beijing, China, 3–7 November 2019; pp. 2683–2691. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. In Proceedings of the NIPS 2014 Workshop on Deep Learning, Montreal, QC, Canada, 12–13 December 2014. [Google Scholar]
- Shi, X.J.; Chen, Z.R.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Description |
|---|---|
| The time length of the data | |
| Data channels | |
| The height of regions | |
| The width of regions | |
| The gird number of regions | |
| Input data of time intervals adjacent to time interval | |
| The adjacent data of -day for the same time intervals as . | |
| The adjacent data of -week for the same time intervals as . | |
| Final prediction at time t. | |
| Number of ST features of the layer network | |
| Data time length of layer network |
| Dataset | TaxiBJ | BikeNYC |
|---|---|---|
| City | Beijing | New York |
| Time-span | 7/1/2013–10/30/2013 3/1/2014–6/30/2014 3/1/2015–6/30/2015 11/1/2015–4/10/2016 | 4/1/2014–9/30/2014 |
| Time interval | 30 min | 1 h |
| Map size | 32 × 32 | 16 × 8 |
| Number of timestamps | 22,459 | 4392 |
| Baselines | BikeNYC | TaxiBJ | ||
|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | |
| HA | 12.56 ± 0.00 | 6.35 ± 0.00 | 53.21 ± 0.00 | 26.70 ± 0.00 |
| ARIMA | 11.56 ± 0.00 | 6.79 ± 0.00 | 28.65 ± 0.00 | 19.32 ± 0.00 |
| SVR | 11.02 ± 0.01 | 6.32 ± 0.07 | 26.75 ± 0.15 | 18.42 ± 0.09 |
| LSTM | 9.12 ± 0.69 | 5.31 ± 0.42 | 24.34 ± 0.50 | 16.76 ± 0.56 |
| CNN | 9.04 ± 0.57 | 4.98 ± 0.11 | 26.58 ± 0.23 | 14.02 ± 0.12 |
| ConvLSTM | 8.23 ± 2.49 | 4.36 ± 1.27 | 23.42 ± 1.36 | 13.24 ± 3.11 |
| ST-ResNet | 7.03 ± 0.72 | 3.94 ± 1.05 | 19.21 ± 0.56 | 12.97 ± 2.01 |
| ST3Dnet | 6.54 ± 1.03 | 3.62 ± 0.74 | 18.56 ± 0.59 | 11.06 ± 1.56 |
| FASTNN [ours] | 5.04 ± 0.68 | 2.46 ± 0.58 | 16.73 ± 0.36 | 10.49 ± 0.91 |
| Variant | TaxiBJ | BikeNYC | ||
|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | |
| FASTNN | 16.73 ± 0.36 | 10.49 ± 0.91 | 5.04 ± 0.68 | 2.46 ± 0.58 |
| STNN | 23.56 ± 0.69 | 13.36 ± 0.33 | 9.94 ± 0.50 | 5.02 ± 0.23 |
| FASTNN-SA | 21.18 ± 0.53 | 11.47 ± 0.47 | 8.14 ± 0.27 | 4.26 ± 0.16 |
| FASTNN-MA | 20.87 ± 0.69 | 10.13 ± 0.35 | 9.04 ± 0.48 | 4.88 ± 0.20 |
| FASTNN-FNN | 17.50 ± 0.35 | 10.93 ± 0.16 | 5.93 ± 0.25 | 3.56 ± 0.11 |
| FASTNN-add | 18.87 ± 0.15 | 11.51 ± 0.04 | 7.83 ± 0.23 | 3.98 ± 0.09 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Q.; Chen, N.; Lin, S. FASTNN: A Deep Learning Approach for Traffic Flow Prediction Considering Spatiotemporal Features. Sensors 2022, 22, 6921. https://doi.org/10.3390/s22186921
Zhou Q, Chen N, Lin S. FASTNN: A Deep Learning Approach for Traffic Flow Prediction Considering Spatiotemporal Features. Sensors. 2022; 22(18):6921. https://doi.org/10.3390/s22186921
Chicago/Turabian StyleZhou, Qianqian, Nan Chen, and Siwei Lin. 2022. "FASTNN: A Deep Learning Approach for Traffic Flow Prediction Considering Spatiotemporal Features" Sensors 22, no. 18: 6921. https://doi.org/10.3390/s22186921
APA StyleZhou, Q., Chen, N., & Lin, S. (2022). FASTNN: A Deep Learning Approach for Traffic Flow Prediction Considering Spatiotemporal Features. Sensors, 22(18), 6921. https://doi.org/10.3390/s22186921