Abstract
Traffic flow forecasting is a critical input to intelligent transportation systems. Accurate traffic flow forecasting can provide an effective reference for implementing traffic management strategies, developing travel route planning, and public transportation risk assessment. Recent deep learning approaches of spatiotemporal neural networks to predict traffic flow show promise, but could be difficult to separately model the spatiotemporal aggregation in traffic data and intrinsic correlation or redundancy of spatiotemporal features extracted by the filter of the convolutional network. This can introduce biases in the predictions that interfere with subsequent planning decisions in transportation. To solve the mentioned problem, the filter attention-based spatiotemporal neural network (FASTNN) was proposed in this paper. First, the model used 3-dimensional convolutional neural networks to extract universal spatiotemporal dependencies from three types of historical traffic flow, the residual units were employed to prevent network degradation. Then, the filter spatial attention module was constructed to quantify the spatiotemporal aggregation of the features, thus enabling dynamic adjustment of the spatial weights. To model the intrinsic correlation and redundancy of features, this paper also constructed a lightweight module, named matrix factorization based resample module, which automatically learned the intrinsic correlation of the same features to enhance the concentration of the model on information-rich features, and used matrix factorization to reduce the redundant information between different features. The FASTNN has experimented on two large-scale real datasets (TaxiBJ and BikeNYC), and the experimental results show that the FASTNN has better prediction performance than various baselines and variant models.
1. Introduction
Intelligent transportation system (ITS) is a critical input to the development of transportation systems. It can effectively integrate advanced information and communication technologies to form a real-time, accurate, and efficient traffic management system [1,2,3,4]. Traffic flow prediction (TFP) is an important part component of ITS [5,6,7], whose objective is to predict short-term or long-term traffic flow based on historical traffic data (e.g., traffic flow, vehicle speed, etc.). In terms of traffic flow forecasting applications, take for example the more passenger-centric transportation systems of recent years, namely mobility on demand (MoD), which allows passengers to proactively submit travel requests specifying their pick-up and drop-off locations. However, the negative side of this transportation system is that if there is an imbalance between vehicle supply and order requests in a region, the system may have to allocate a distant vehicle to meet passenger travel demand, and passenger waiting time increases [8,9]. If the above occurs during peak periods or in a congested area, it may increase the travel burden in that area. Therefore, TFP for the region can pre-allocate the required vehicles to areas with high travel demand, which not only reduces passenger waiting time and improves travel service quality, but also provide references for implementing traffic management strategies, developing travel route planning, and public transportation risk assessment.
The key issue to achieving accurate predictions is modeling the high-dimensional and nonlinear spatiotemporal (ST) dependencies of massive traffic ST big data. Initially, researchers applied traditional machine learning methods for predictions, such as the ARIMA model [10], SVM [11], and SVR [12] models, etc. However, these models cannot effectively extract the ST dependencies between multi-source traffic data given their invariable model structures and weights. Moreover, the label features of machine learning models are dependent on intensive manual analysis, which also increases the subjective error of prediction results. Deep learning methods overcome these disadvantages through stacking neural network infrastructure and training the network with gradient descent [13]. It can realize automatic extraction of diverse ST dependencies by designing various neural networks. Thus, how to design the corresponding neural network to capture its complex spatial dependence and temporal dynamics is a current research hotspot. Zhang [14] extracted the ST features of the data based on deep neural networks; Niu [15] modeled the spatial dependence of the traffic data using convolutional neural networks (CNN) and long short-term memory (LSTM); Saxena [16] employed generative adversarial networks to model the multimodality of the data; Wang [17] used attention mechanisms to model the local and global temporal dynamics. Guo [18] captures the ST correlation and heterogeneity through 3D convolutional neural networks. While these methods have shown promise in improving TFP accuracy, it appears less capable of modeling ST aggregation and quantifying intrinsic correlation and redundancy of ST features.
To solve the mentioned problems, this paper proposed a deep learning-based ST prediction network model for predicting traffic flow, named the filter attention-based spatiotemporal neural network (FASTNN), which can sufficiently model the ST agglomeration of data, automatically learn the intrinsic correlation of ST features, and reduce the redundancy among diverse ST features. Specifically, based on 3D CNN and the residual unit, this paper proposed a filter spatial attention module (FSA) to model the ST agglomeration and dynamically adjust the region weights of each ST feature. Second, the matrix factorization based resample module (MFR) was proposed to automatically learn the intrinsic correlation of the same ST feature, and this module also reduces the redundant information contained between different ST features. Finally, this paper experimented with the FASTNN on two large-scale real datasets, including Taxi trip data in Beijing and bike-sharing data in New York, and the performance results with the baseline show the effectiveness of the FASTNN. The contributions of this paper can be summarized as follows:
- (1)
- This paper proposed a traffic flow prediction model based on a deep learning framework, the FASTNN, which can model ST aggregation and quantify intrinsic correlation and redundancy of ST features.
- (2)
- In this paper, filter spatial attention (FSA) was proposed to model the ST agglomeration of traffic data, and this module can implement dynamic adjustment of spatial weights.
- (3)
- This paper proposed a lightweight module, the matrix factorization based resample module (MFR), which can model the intrinsic correlation of the same ST feature and reduce the redundant information between different ST features.
In the next section, the paper reviewed the existing literature on TFP and attention mechanisms in TFP research. Section 3 introduced the key concepts of the ST agglomeration and intrinsic correlation of the same ST feature, and also described the definitions related to TFP in this paper. In Section 4, the paper presented the framework of the proposed FASTNN model and the structure of the various components in the FASTNN. Experimental data and results were presented in Section 5. Finally, the conclusions were discussed in Section 6.
2. Related Works
Future traffic information is critical for MoD systems to improve their service quality and for policymakers to conduct effective transportation planning. Many researchers have investigated the related TFP problem [19]. TFP not only balances the supply and demand of future travel demand but also improves the operational efficiency of public transportation by formulating effective travel strategies based on the forecasted traffic information.
2.1. Traffic Flow Prediction
Traffic flow prediction (TFP) is a key problem in the field of data mining in urban computing [15,16]. Early TFP models were mainly based on statistical (e.g., autoregressive integrated moving average (ARIMA) [20], vector autoregression [21], etc.) or machine learning-based methods (including K-nearest neighbors [22], support vector machines [23], vector autoregressive moving average [24], etc.). For example, to address the sparsity and travel time uncertainty of real-time traffic data, Zhang [25] used the gradient-boosted regression tree method to extract the ST correlation of neighboring and target links of the road network to achieve temporal prediction of traffic flow; Cheng [26] proposed a multi-view learning algorithm for short-term traffic flow prediction, which can account for the temporal fluctuations and patterns of traffic in addition to the general spatial characteristics; Zhang [27] implemented a linear model with coefficients varying as a smoothing function of departure time to predict short-time travel times. However, it is difficult to extract the complex patterns hidden in the traffic flow because the above models have limited capacity to model complex traffic relationships nonlinearly. The scarcity of autonomous ability to learn combinational embeddings of ST features also represents a major challenge to these model-based approaches.
Given the complexity and variability of the actual traffic situation, the prediction accuracy of such models in the actual application requires to be improved to meet the requirements of ITS. To improve the model performance and achieve the depth extraction of ST dependencies, deep learning techniques with powerful feature extraction and non-linear fitting capabilities were widely accepted in TFP research. In time-dependent mining, Wu [28] used a Wave Net based on a one-dimensional temporal convolutional neural network to model the temporal correlation in traffic data; Fu [29] predicted traffic flow with LSTM and GRU networks; He [30] applied the sequence to sequence architecture to model the similarity of historical traffic flow between multiple time steps; To solve the subway traffic prediction problem, Liu [31] improved the LSTM network by using exogenous data, features of subway data, and temporal correlation; Du [32] proposed a deep irregular convolutional residual LSTM network model for urban traffic flow prediction to handle mixed traffic routes, mixed traffic, interchange stations, and some extreme weather; To predict the traffic congestion status of cities, Zhang [33] proposed a deep autoencoder neural networks to efficiently learn the temporal correlation of traffic networks.
The TFP deep learning method for mining time-dependent features has fewer training parameters and is highly efficient. However, the accuracy results of the prediction task for ST data still require to be improved because of its own inability to model the spatial correlation in the data. In spatial-dependent mining, TFP generally presents traffic data in a grid or pixel form in the spatial dimension [34,35]. Accordingly, the high dimensionality of traffic data can be analogized to the multi-channel of image data. Applying the 2-dimensional convolutional neural network (2D CNN) in computer vision to the TFP problem can model the spatial correlation. For instance, Zhang [34] employed a 2Dconv to predict the inflow and outflow of taxis, and Yao [36] also calculated the demand for cabs in urban areas using 2D CNN; Sun [37] performed mutual correlation calculations using a multilayer fully convolutional network to simulate the spatial correlation between current and neighboring sections, local and global scales.
All the above approaches showed comparatively better prediction performance for TFP than traditional model-based approaches. Nevertheless, the complex temporal and spatial characteristics of traffic data will not be limited to a single dimension in practical applications but will be synthesized in a 3-dimensional space [38]. Therefore, comprehensive mining of ST-dependent features is a crucial research component to improve the performance of TFP. Zhang [34,39] proposed a learning method called ST-ResNet to model the closeness, periodicity, and trend of spatiotemporal data using historical flows. Chen [40] and Guo [35] applied 3D convolutional neural networks (3D CNN) to extract the spatiotemporal correlation of data from multi-dimensions. Zhang [41] split the traffic prediction task into node and edge traffic prediction and proposed a multi-task deep learning framework that models the ST interaction from a graph-theoretic perspective. Liu [42] proposed a novel network to learn the dynamic similarity between regions, fully considering the complex spatial dependence and temporal dynamics. Yan [43] dynamically extracted ST features through multiple attention and masked multiple attention mechanisms and determined the significant influential parts of the road network by analyzing the attention weight matrix. Zheng et al. [44] developed a framework that combines CNN and LSTM networks to more effectively extract features of traffic data through an embedding module to fuse external information (e.g., weather, date). For the extraction and modeling of more complicated ST dependencies, Zambrano-Martinez [4] used logistic regression and cluster analysis to predict the geographic distribution of urban traffic behavior, creating a realistic traffic model for a specific target city; to extract the global ST features of traffic information, Fang [45] proposed a neural network method that includes multilayer ST blocks to obtain both global spatial correlation and dynamic temporal features.
In sum, that this may prove fruitful is motivated by the fact that deep learning can obtain more accurate results, not only by eliminating the subjective factors caused by the manual designing of model-driven methods but also by enhancing the nonlinear fitting ability of ST dependencies. A more effective and comprehensive representation of the ST dependencies embedded in traffic data is a crucial part of TFP research to obtain promising prediction results.
2.2. Attention for TFP
Attention is essentially an assignment mechanism [46]. The controlling idea is to determine the correlation between them based on the original data, then emphasize important features and realize the reallocation of weights.
Attentional mechanisms enable us to utilize limited attentional resources by filtering out distracting information from the large volume of data, thus significantly reducing information processing errors [42,47,48]. Essentially, the attention mechanism in deep learning is similar to the human visual system in that its purpose is to determine which part of the information may be more valuable for the task. Liu [29] demonstrated the effectiveness of the attention mechanism for TFP by merging three attention modules, channel attention, spatial attention, and location attention, via a deep integration network to achieve adaptive feature refinement. Hao [47] used the sequence-to-sequence model with the attention mechanism to model sequence data of different lengths, and the results have proven that the attention mechanism enhances the ability of the model to capture remote dependencies. Wang [48] proposed a hard attention module that strengthened neuronal memory by learning similar patterns, thus diminishing the accumulation of errors. To reduce error propagation between prediction time steps, Zheng [49] developed a transformed attention module to learn the direct correlation between historical and predicted flows. Do [50] proposed a temporal and spatial attention module for traffic flow prediction, which contributes to extracting the spatiotemporal dependencies between distinct time steps and road networks. Guo [35] designed a spatiotemporal attention module that adaptively adjusts the correlations of graph signal sequences in the temporal and spatial dimensions. Yu [51] used a cross-attention mechanism to fuse ST features to model global information. Jia [52] used a rectified block equipped with the attention mechanism to automatically reweight the measurements for different time intervals. Liu [53] proposed hierarchical attention to extracting features for each time step.
3. Problem and Definition
3.1. Problem
- (1)
- ST aggregation:
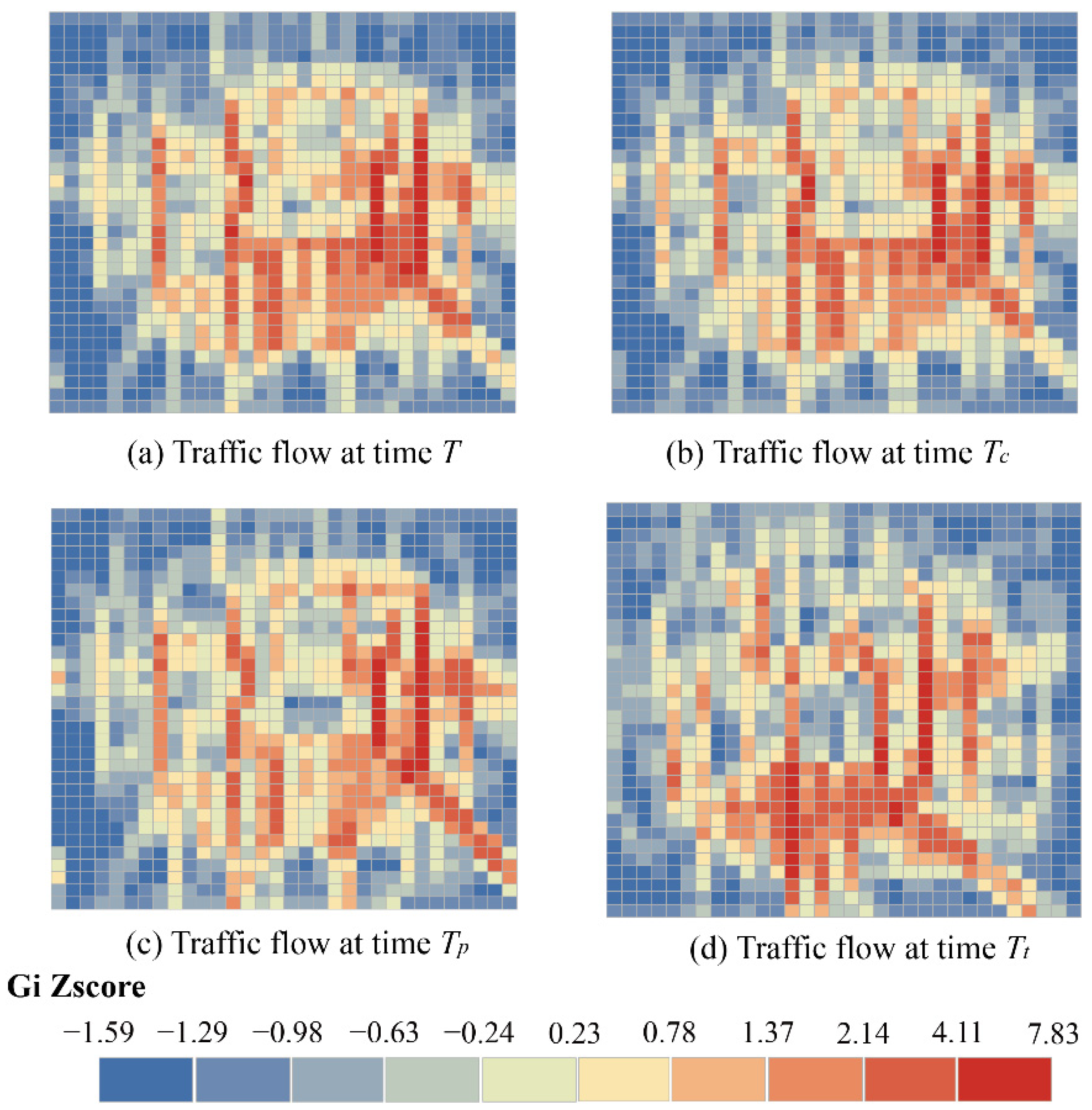
Figure 1 shows the hotspot aggregation characteristics of traffic flow at four moments, T represents the traffic flow at the current time and the time interval between and T is an hour, the time interval between and T is a complete day, the time interval between and T is a week. The higher z-score indicates a stronger degree of agglomeration. It can be observed from Figure 1 that the similarity of the flow distribution at T with , , and are decreasing in order from the time perspective. From the spatial perspective, the traffic flow at the four times is not evenly distributed, but concentrated in the city center with significant spatial agglomeration.
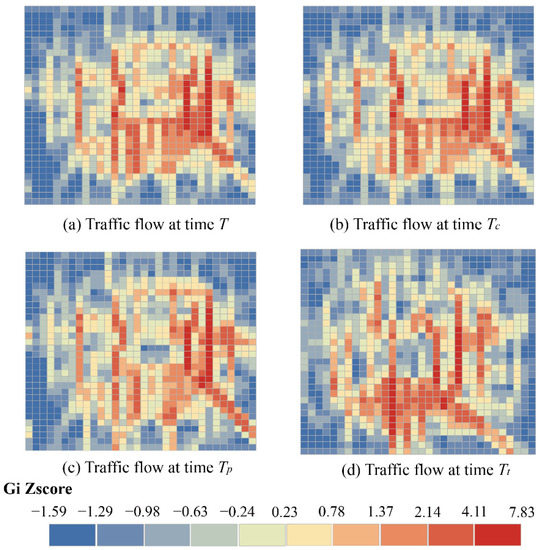
Figure 1.
Spatiotemporal aggregation of traffic data.
Therefore, the general deep learning method that shares parameter weights for all time steps or regions has limitations. Traffic data has agglomeration at different times, which also means that the weights of congested or sparse areas should be different. Given the dynamism of traffic conditions, dynamic adjustment of the weights is also necessary for the prediction task.
- (2)
- Intrinsic correlation of the same ST features and redundancy between different ST features:
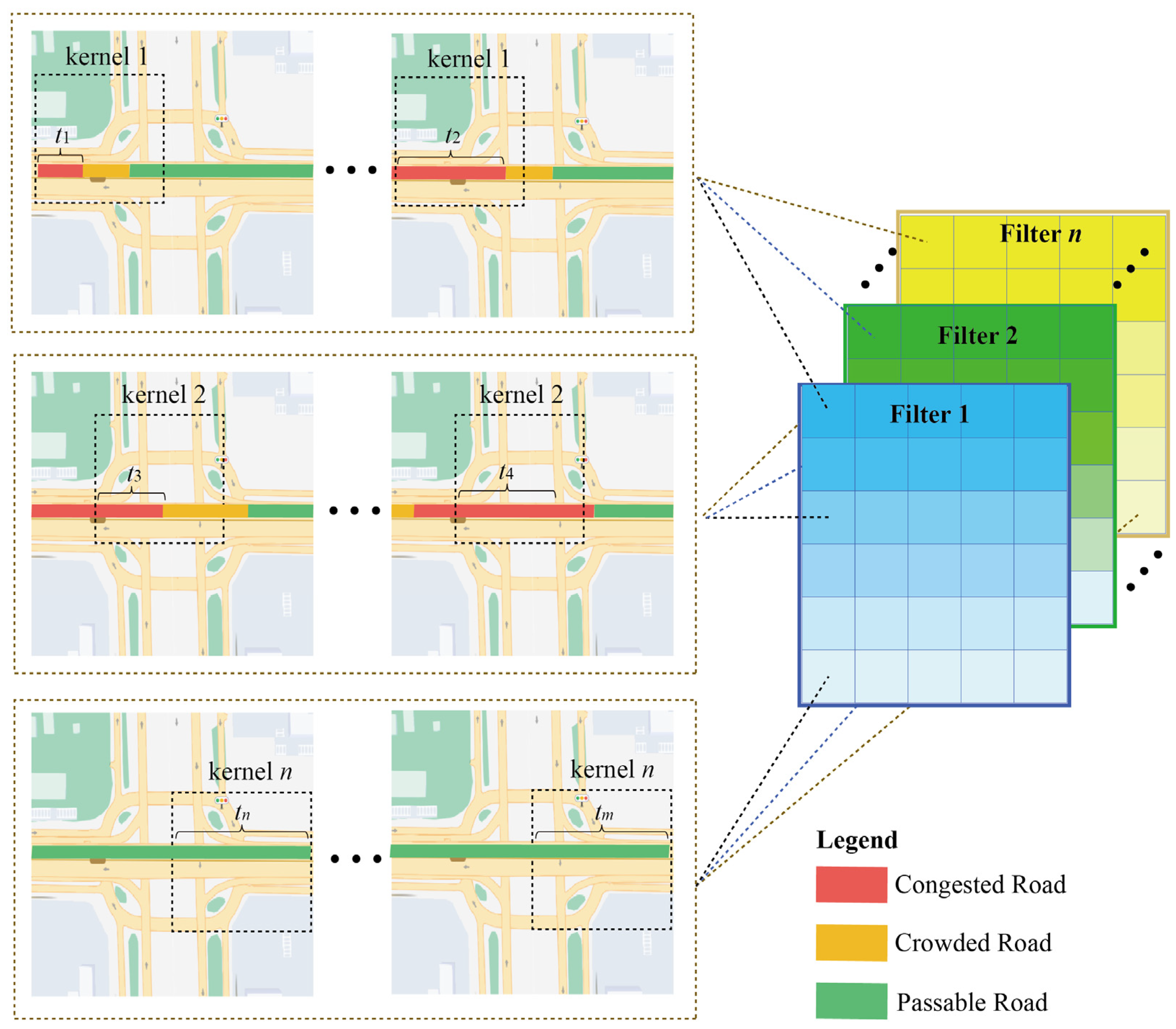
The ST data obtained at neighboring locations and adjacent time steps are not independent but are interrelated. Taking the traffic congestion situation as an example, traffic congestion does not occur in isolation and generally covers a continuous area and traffic congestion also moves along a 3-dimensional ST domain as time has passed. In this paper, 3D CNN was used to automatically extract the ST features of data, but the extracted ST features remain some problems: In CNN because the kernel is continuously moved to sense the data, the ST feature is extracted by a single filter (a single filter contains n kernel) extracted has intrinsic correlation. As shown in Figure 2, the time intervals to were consecutive. The road is congested at and the congestion state propagates eastward along the road network until , when the congestion state was extended, and all the above information can be sensed by kernel 1 in 3-dimensions. For the next consecutive time intervals, ~, 3D CNN perceives it with kernel 2. Although kernel 1 senses a different ST domain, the congestion at appears not abruptly but was closely related to the traffic state from to . Thus, there is an inherent correlation in the ST features captured by the convolution operation.
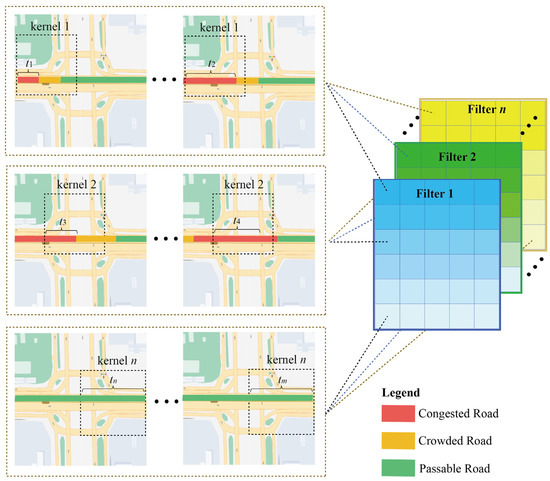
Figure 2.
Intrinsic correlation and redundancy of spatiotemporal features.
In addition, in kernel n, the same road was in a passable state in the long-term, and the ST features learned by the kernel of any size were consistent, so there also exists redundant information between multiple ST features. Therefore, it is not reasonable to share weights for all ST features. Learning the intrinsic correlation in ST features, adjusting the weights of the same ST feature to regions, concentrating on information-rich regions, and quantifying the contributions among different ST features to reduce the redundant information were critical issues to improve the prediction performance.
3.2. Definition
Data Definition: This paper defined urban traffic data as a 4-dimensional (4D) tensor . is the OD matrix that counts the outflows or inflows at time . First, the region was divided into a 2D non-overlapping raster of size according to latitude and longitude, where and were the height and width of the regional grid. Secondly, the flow data were stacked to 3D according to , the total number of types of flow data. Finally, the data were stacked to 4D according to the total number of timestamps of the flow data.
Problem Definition: The objective of this paper is to build a TFP model: the historical traffic with 3-time intervals of closeness, trend, and period at time was applied as input to predict multiple types of traffic flow at time . The summary of the notation can be found in Table 1.

Table 1.
Summary of Notation.
4. Methodology
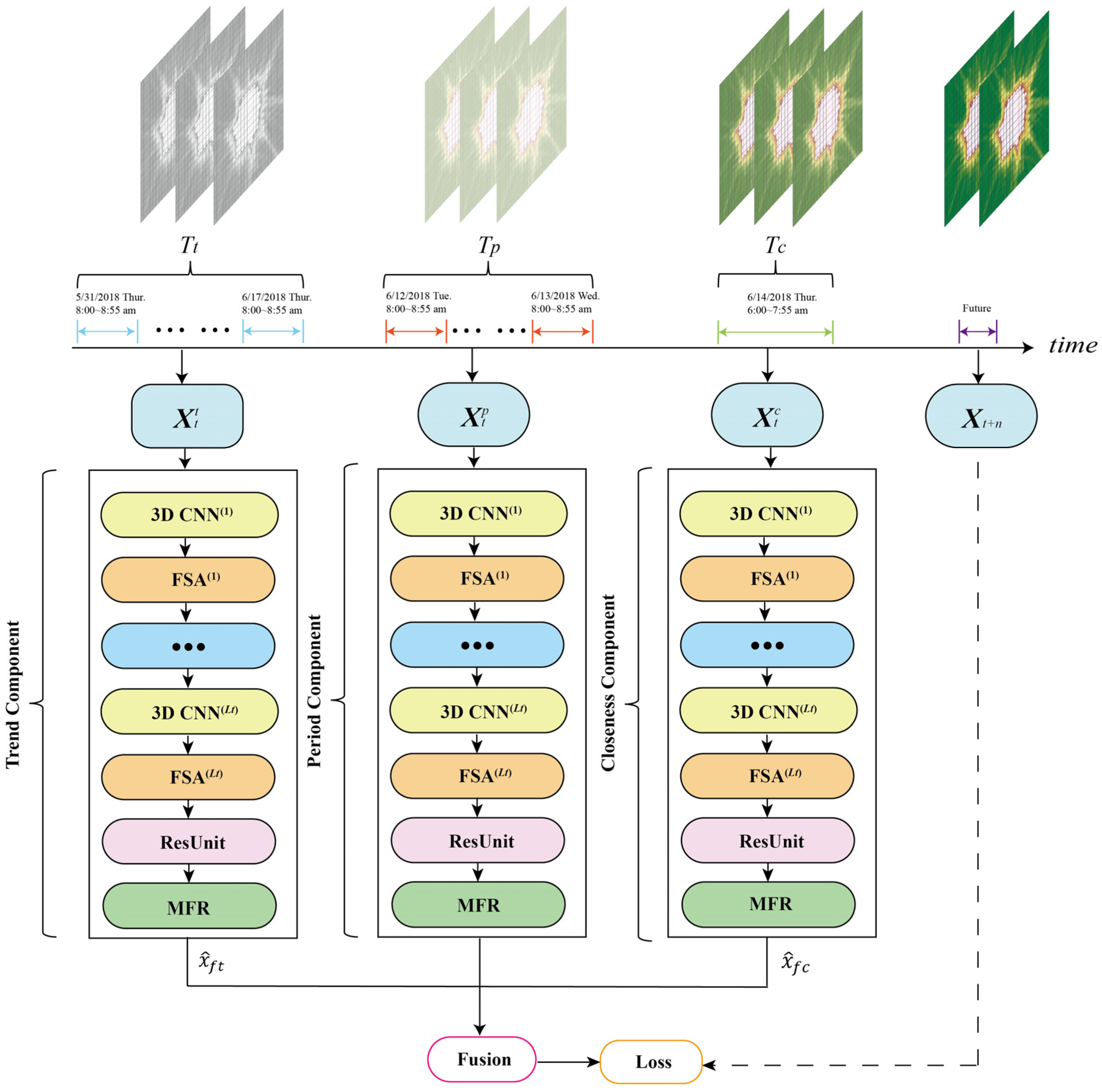
Figure 3 shows the framework of FASTNN, this model consists of three basic components of closeness, period, and trend, which intercept three time series of length , , and along the time as the three component inputs .
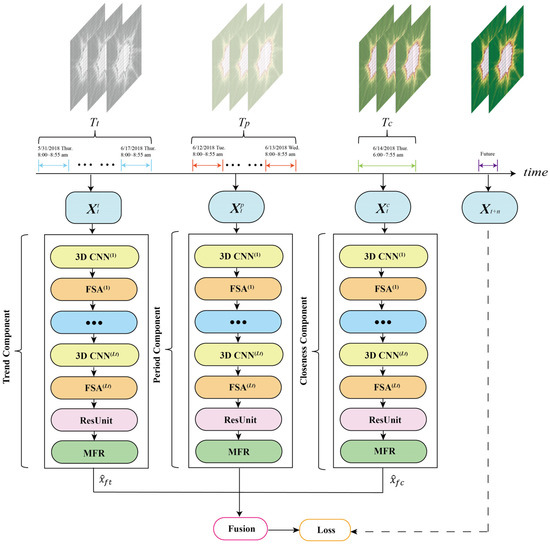
Figure 3.
The framework of FASTNN.
- The closeness component;
- 2.
- The period component;
- 3.
- The trend component;
The intrinsic structure of each component remains consistent, and these components can extract universal ST dependencies in the data. Taking the closeness component as an example, to extract deep-level spatiotemporal correlations, FASTNN input the historical traffic of closeness into the 3D CNN, and appended the FSA component after the 3D CNN to model the spatiotemporal agglomeration of each feature extracted, thus achieving the dynamic adjustment of the spatial weights. The ST dependencies of the traffic data have been comprehensively modeled after replications. To prevent network degradation, FASTNN added residual units after the FSA in the last layer. The ST features processed by residual units still have inherent correlation and redundancy, and these dependencies were modeled by the lightweight MFR proposed in this paper.
4.1. 3D Convolutional Neural Network
3D Convolutional neural network (3D CNN) contributes to the model to capture the dependence in the spatiotemporal dimension. Observations obtained at neighboring locations and adjacent time steps are not independent but interrelated and this spatiotemporal correlation can be effectively captured by 3D CNN.
The weights of 3D Convolutional can be expressed as 5-Dimension filters: , where is the number of filters, is the number of input filters or channels, is the number of input filters or channels, , and is the temporal length, height, and width of the 3D convolutional filter. Take the closeness component as an example, the input flow was denoted as .The calculation of each 3D Convolutional filter can be expressed as:
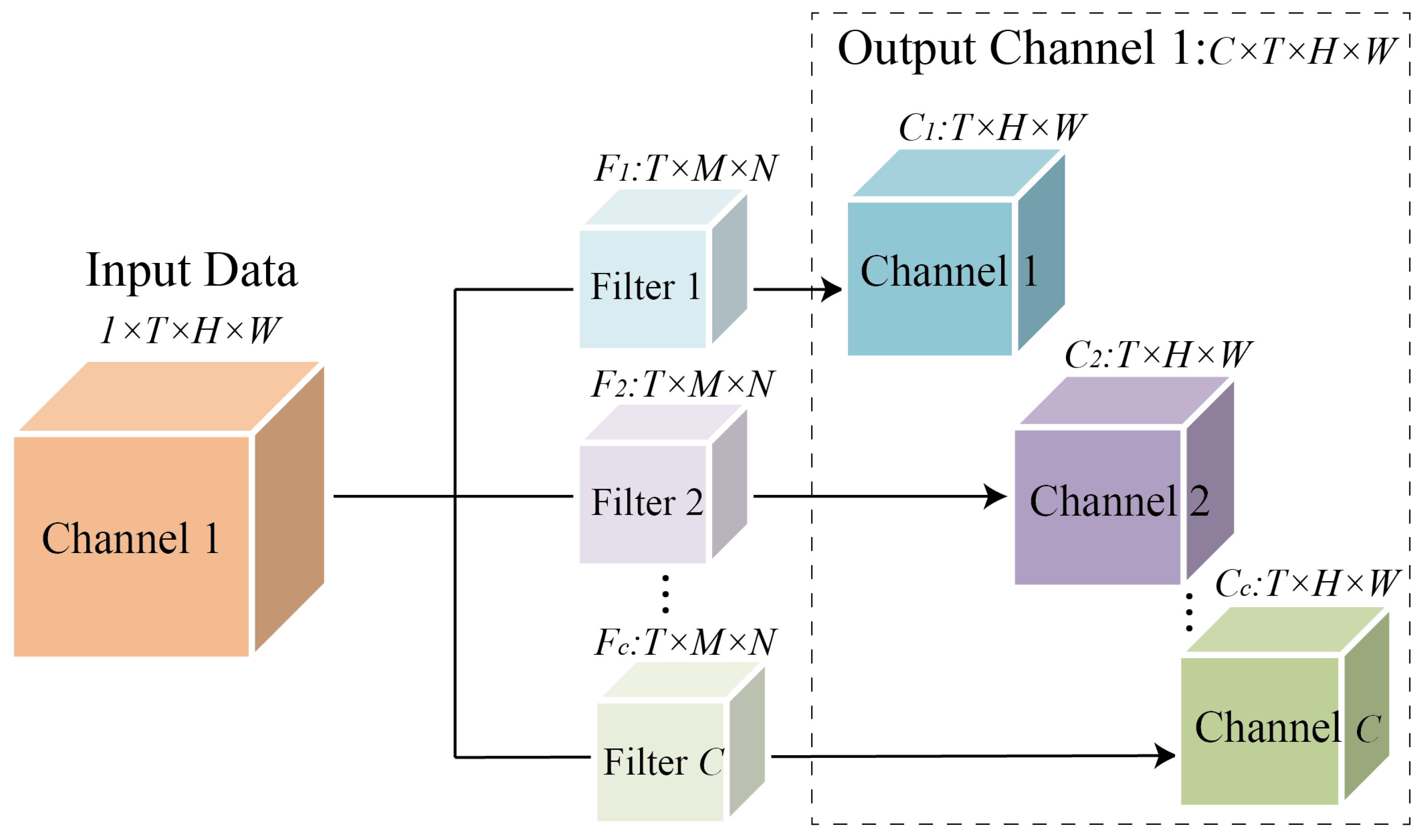
where , and . The output flow can be denoted as . The structure of 3D CNN is shown in Figure 4. Take the input data with the number of channels as 1 as an example, the input data can be expressed as , after the convolution of filters ,, the output channel data equal to the number of Filters was obtained. If the input data contains more than one channel, the number of dimensions of the output data channels increase accordingly. In the period and trend component, the 3D CNN layer was calculated similarly to the closeness component. After stacking multiple layers of 3D CNN, the critical information of traffic data in the time dimension has been effectively mined.
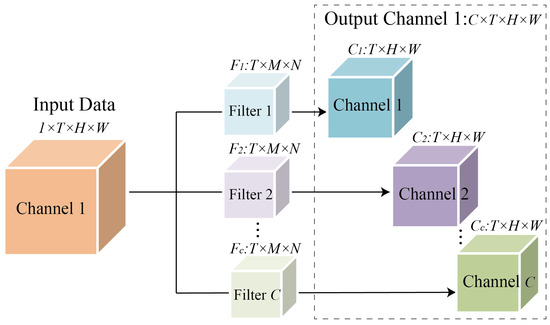
Figure 4.
The structure of 3D CNN.
4.2. Filter Spatial Attention
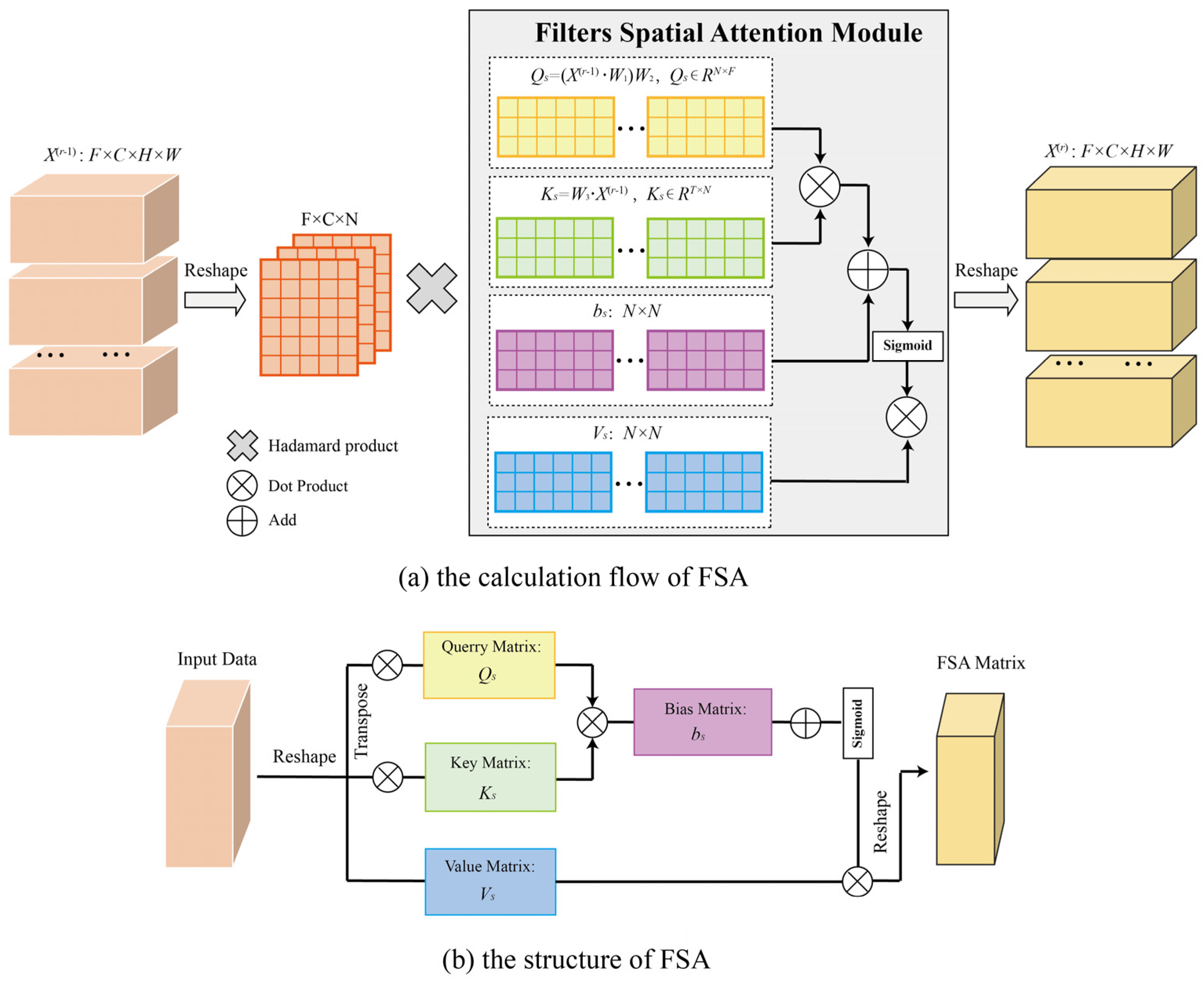
The 3D CNN shows promise in mining information along the ST dimensions but could be difficult to detect the ST agglomeration of traffic data and the agglomeration is dynamically changing, it is also difficult to adaptively adjust the region weight. Consequently, this paper used the filter spatial attention (FSA) module to dynamically adjust the intensity of ST agglomeration based on the input data. To compare the model performance of different attention mechanisms, this paper also compared the experimental performances of two different mechanisms, namely, multi-headed attention, self-attention, and the FSA proposed in this paper. The equation for calculating FSA was as follows:
In Equation (2), , , and were learn-able parameters, which is trained using gradient descent, , , and , is the sigmoid function and is the output of th 3D CNN. is the output time length of th 3D CNN and is the output filter length of th 3D CNN. is the total number of regional grids.
The calculation flow and structure of FSA were presented in Figure 5. In Figure 5a, take the closeness component as an example, the 3D CNN input of the th layer is and was used to model ST agglomeration, which denotes the Hadamard product and is the spatial weight matrix calculated by the FSA module. When , , is the input time length of the closeness component. When , to realize the fusion with the FSA module, the input was reshaped as , where was the filter number of the th 3D CNN layer. After multiplying the output with can obtained the input of th 3D CNN, the input was then reshaped back to . In the period and trend components, the calculation was completely consistent.
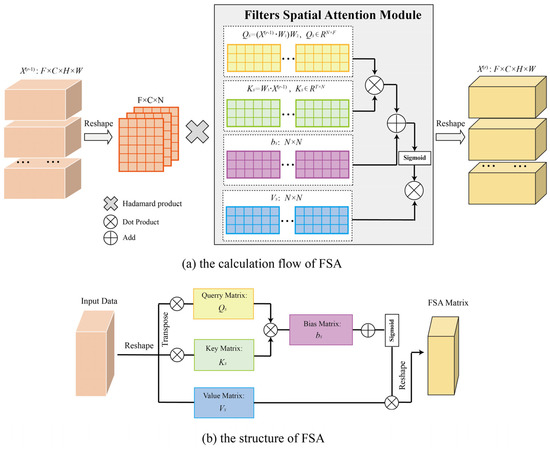
Figure 5.
The calculation flow and structure of FSA.
Figure 5b shows the structure of FSA. The structure of FSA is referenced to the general attention mechanism, in which the feature matrices are calculated by , , and . The difference with the general attention is the difference between the calculation method and data dimensionality: The attention uses the method of vector intersection to determine the similarity, while FSA uses multi-dimensional learning parameters and more dot product operations to determine the similarity more comprehensively.
4.3. Residual Unit
After stacking multiple layers of 3D CNN and modules of FSA, the dependencies of traffic data in ST dimensions have been comprehensively mined. As the number of neural network layers deepens, the training of the network becomes more difficult and even leads to performance degradation in the network.
As the depth of the neural network layers deepens, the training of the network could become more difficult and result in even degradation of the network performance. To alleviate the degradation phenomenon caused by the deepening of neural network layers, the residual unit proposed by He [54] was employed in this paper to guarantee the training performance of the model. In this paper, residual units were stacked after the last layer of 3D CNN, which were calculated as follows:
In Equation (4), is the set of all learnable parameters in the th residual unit. is the output of residual unit and is the input. When , to make the residual unit fuse with the FSA module output, the input of th the residual unit was reconstructed as , and is the feature number of the FSA output of the last module.
4.4. Matrix Factorization Based Resample Module
Quantifying and adjusting the weights of regions for the same ST feature, enhancing the focus on information-rich regions, and reducing the redundant information in different ST features was a critical aspect to improve the performance of the TFP model. However, modeling spatiotemporal features using a single set of parameter weights cannot model the nonlinear relationships among multiple spatiotemporal features. It is necessary to enable each filter to correspond to a separate prediction network. However, independent training of each filter’s prediction network introduces new problems:
- Independent training cannot model the correlation between multiple ST features, nor can it eliminate redundant ST features [35,55,56];
- Direct training using fully-connected layers introduces excessive training parameters that can lead to difficult optimization or overfitting of the model.
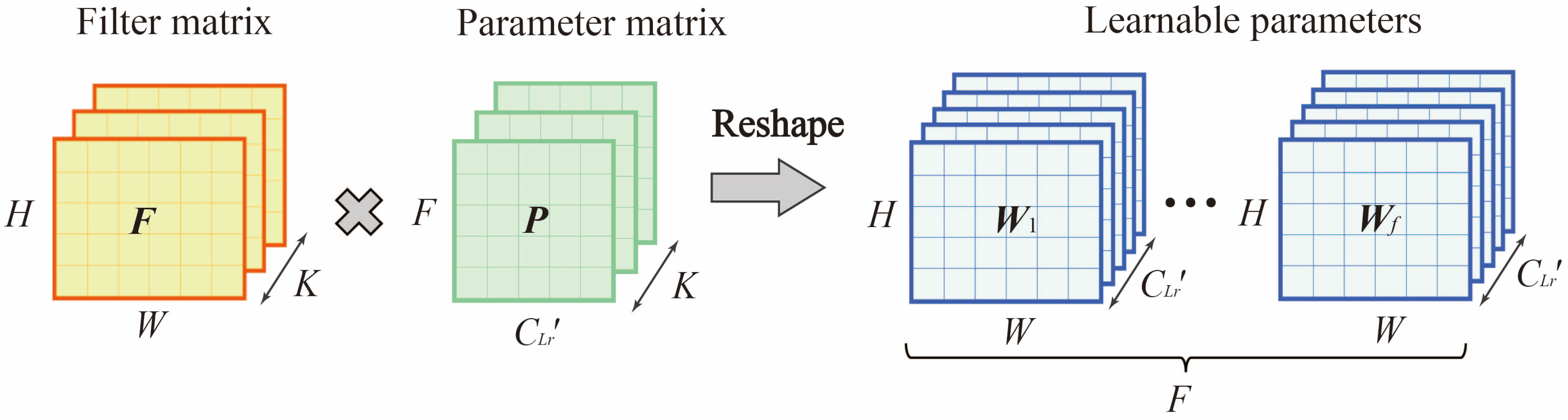
To address this problem, the matrix factorization-based resample module (MFR) was proposed in this paper. This module can automatically learn the contribution of each region in the same spatiotemporal features and the correlation between different spatiotemporal features, thus improving the model representation and prediction capability. The input to the MFR module was . The output after training was the . was the set of learnable parameters, , where was the number of ST features (i.e filters). As Figure 6 shown, this paper used a Filter Matrix and a Parameter Matrix to approximate , where is a constant less than .
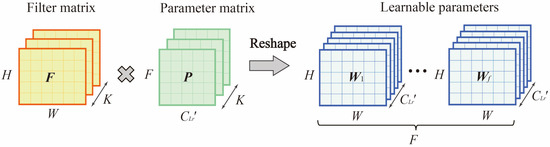
Figure 6.
Matrix decomposition of learnable parameters in MFR.
In Equation (6), represents the bias term of the th ST features, , also calculated by the matrix factorization.
4.5. Fusion Component
When fusing the outputs of components closeness, period, and trend, the fully-connected neural network (FNN) was used to automatically learn the importance of the three types of outputs. The output of the closeness component, the period component, and the trend component can be expressed as []. The fusion component can be expressed as follows:
where is the learnable parameter, representing the Hadamard product.
4.6. Loss Function
The model was trained by minimizing the loss function, which is defined as the mean root error (MSE) between the true traffic raster values and the predicted values. MSE was used for the reason that it is continuously derivable, which facilitates the use of gradient descent algorithms and also facilitates the convergence of the function. The formula for MSE is as follows:
where is the learnable parameters, is the predicted traffic flow at time and is the true traffic flow at time .
5. Experiments
The main objective of the urban traffic flow predicting task was to build an accurate model to predict multiple flows for a specific demand in each time and region of the city. This paper demonstrated the application of the FASTNN to an urban traffic flow forecasting task on two large-scale datasets (TaxiBJ and BikeNYC). The results of the paper were intended to answer the following questions:
- How does the FASTNN proposed in this paper perform compared to the baselines?
- What is the performance of the FASTNN variants with different modules?
- How effective are the FSA module and the MFR module proposed in this paper?
- Why are FSA and MFR effective?
5.1. Dataset
In this paper, two traffic flow datasets, TaxiBJ and BikeNYC, were used to verify the performance of the FASTNN, and the details of the two datasets were shown in Table 2. The common feature of both datasets is that the area was transformed into an grid, and the traffic flow data was transformed into raster data with 2 channels. The two channels were traffic inflow and outflow.
Table 2.
Details of the dataset.
- TaxiBJ dataset is crowd flow data obtained from GPS trajectory data of Beijing cabs, which contains four-time intervals: 1 July 2013, to 30 October 2013; 1 March 2014 to 30 June 2014; 1 March 2015, to 30 June 2015; and 1 November 2015, to 10 April 2016. This dataset firstly divides the main urban area of Beijing into 32 × 32 grid areas, and secondly counts the origin and destination points of each vehicle trajectory in the above four time periods according to the 0.5 h interval. Because the dataset has ST continuity, the dataset can detect all traffic conditions under a specific region;
- BikeNYC dataset is obtained from 1 April to 30 September 2014, New York City Bicycle System [39]. This dataset divides the main city of New York into a 16 × 8 grid, and counts the inflow and outflow of crowds within the area at one-hour time intervals, with a total number of time timestamps of 4392. This dataset is based on the 2014 NYC Bike system bike-sharing trip data and counts the traffic flow within the 16 × 8 grid according to the bike-sharing orders in each area, by latitude and longitude.
5.2. Baselines
In this paper, the FASTNN was compared with the following baselines:
- History Average Model (HA): The predicted flow of the model is the average of the recent historical traffic data at the corresponding time;
- Autoregressive Integrated Moving Average Model (ARIMA): ARIMA regards the data series of the prediction object over time as a random sequence, and uses a certain mathematical model to describe this sequence approximately;
- Support Vector Regression (SVR): SVR utilizes linear support vector machines for regression tasks, and the central idea of the model is to find a regression plane such that all the data in a set are closest to that plane;
- Long Short-Term Memory (LSTM): LSTM is a neural network with the ability to remember long and short-term information, consisting of a unit, input gates, output gates, and forgetting gates, for solving the problem of long-term dependencies;
- Gated Recurrent Unit (GRU): GRU [57] is a variant of LSTM. A gating mechanism is used to control the input, memory, and other information, while making predictions at the current time step;
- ConvLSTM: The convolution mechanism [58], which can extract spatial features, is added to the LSTM network, which can extract temporal features and can capture ST relationships;
- ST-ResNet: Spatiotemporal residual network [39], which utilizes three residual neural network components to model the temporal closeness, period, and trend properties of urban flows;
- ST3Dnet: An end-to-end deep learning model [18], ST3Dnet uses the 3D CNN and recalibration module to model the local and global dependencies.
5.3. Evaluation Metrics
To better evaluate the performance improvement of the FASTNN, this paper used the following two metrics for evaluation.
Root Mean Squared Error (RMSE):
Mean Absolute Error (MAE):
In Equations (9) and (10), where is the predicted traffic flow, is the real traffic flow in the region, and is the total number of time intervals, which also is the total number of samples.
5.4. Model Training
The FASTNN was constructed based on the TensorFlow framework and was trained and tested on an Ubuntu 16.04 server with a single graphics card (NVIDIA GTX 3060Ti). In the model training, the batch size was set to 16, the learning rate was set to 0.002, and the early stopping strategy was used to prevent overfitting. The two datasets were divided into respective training dataset, validation dataset, and test dataset in time order. These two datasets did not overlap with each other and were divided in a proportion of 8:1:1 on the time series.
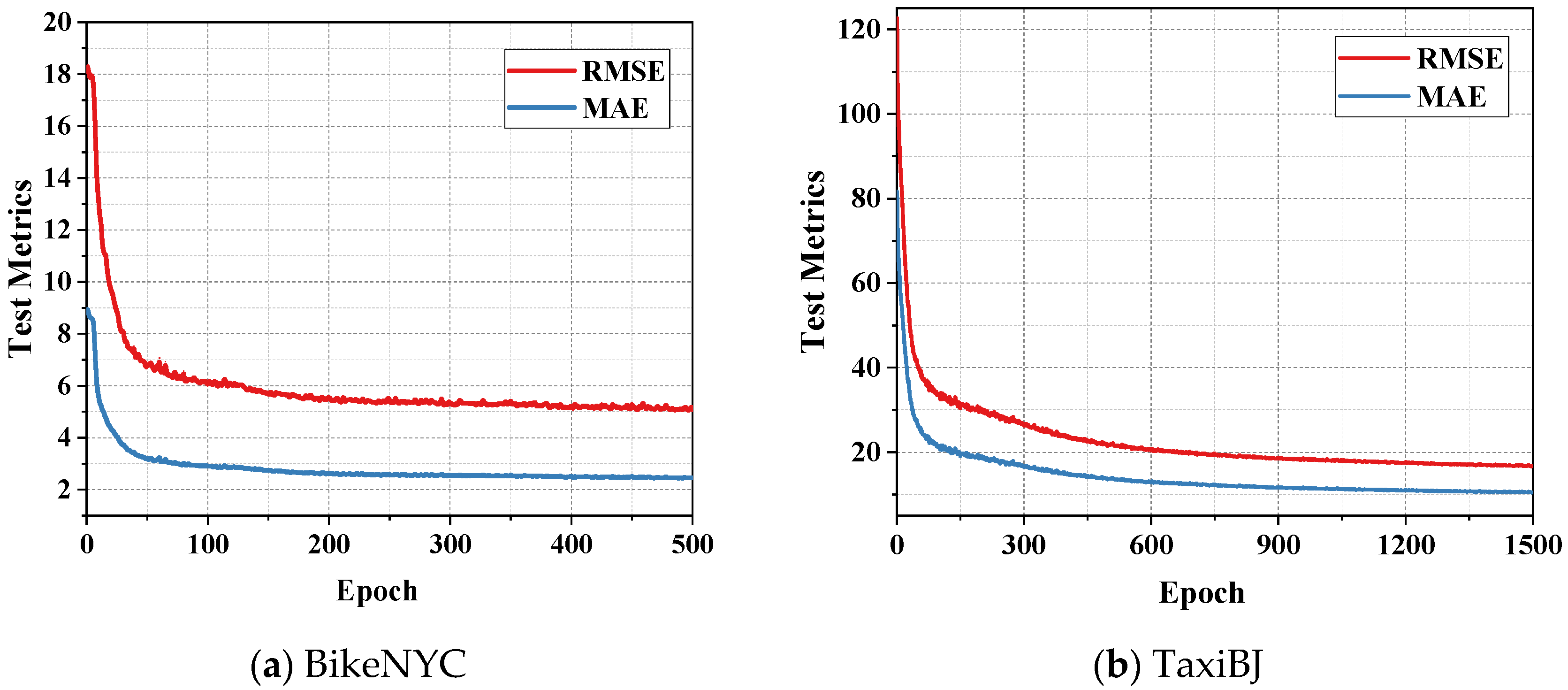
The adaptive moment estimation (Adam) optimization algorithm was used in the model for end-to-end gradient descent training. The RMSE and MAE curves during model training were shown in Figure 7. It can be observed that the FASTNN was properly trained and not overfitted on the two large-scale traffic datasets.
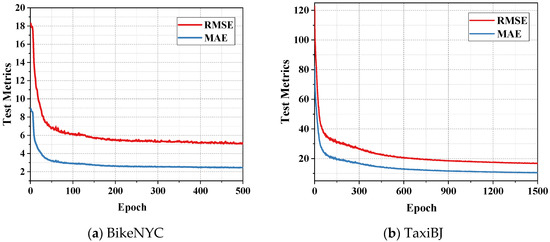
Figure 7.
The testing metrics on two datasets.
5.5. Performance Comparison with Baselines (Q1)
Table 3 presents the variation in the performance of the FASTNN and other baselines on the two datasets. For the FASTNN and all baselines, this paper used different random seeds for training, tested three times, and record the experimental results and error margin in the format of “mean ± error margin”. From Table 3, the following conclusions can be derived.
Table 3.
Comparison of performance under different baselines. (Note: Bold represents the best performance).
Compared to traditional time series analysis methods and machine learning methods (e.g., HA, ARIMA, and SVR), deep learning-based baselines have better predictive performance for all evaluation metrics. These findings are understandable because machine learning methods have limited capability to model nonlinear ST features. Moreover, for LSTM and CNN, which can only model temporal or spatial features from a single dimension, models, such as ConvLSTM and ST-ResNet, which can model ST dependencies from multiple dimensions, evidently achieve better performance.
In the TFP, the FASTNN achieves better prediction performance than existing baseline approaches. Compared to the best performance in traditional baselines (i.e., HA, ARIMA, and SVR) for the BikeNYC and TaxiBJ datasets, the FASTNN achieved relative improvements of 54.26% and 37.45% (RMSE), while MAE achieved a relative improvement of 61.08% and 43.05%. Compared to the best performance in deep learning-based baselines, the FASTNN achieved relative improvements of 22.94% and 9.86% (RMSE) in BikeNYC and TaxiBJ datasets. Similar improvement results were presented in the comparison of MAE metrics, and the improvement of MAE was 32.04% and 5.15%.
The architectural modules of FASTNN contribute to these improvements. Other baseline methods disregard the spatial agglomeration of traffic flow at different time intervals and use a weight-sharing training strategy for all regions. The FASTNN, on the contrary, incorporated the FSA module, which can dynamically adjust the region weights in each training step, and effectively distinguishes the traffic agglomeration regions from the sparse regions. Moreover, based on the concept of intrinsic correlation of the same ST features and redundancy between different ST features proposed in this paper, the FASTNN used the MFR module to automatically learn the intrinsic correlations in the same ST features and calculate their spatial weights. This module also can enhance the importance of information-rich features and reduce the impact of redundant information features, thus improving the prediction performance of the model.
5.6. Evaluations on Variants of the Module (Q2)
To investigate what is the performance of FASTNN variants with different modules, the FSA and MFR modules were varied and replaced in the FASTNN. The FSA module was based on the attention mechanism; thus, this paper evaluated the performance of two general variants, the multi-headed attention mechanism (MA), and the self-attention mechanism (SA) [46]. For the MFR module, which is capable of automatic learning intrinsic correlation and disregarding redundant information, this paper has compared it using the forward neural network (FNN) and the adding layer. Detailed variant model descriptions were shown as follows:
- STNN: This model has removed all FSA modules and MFR modules from the FASTNN, remaining the components of 3D CNN and the residual unit;
- FASTNN-MA: This model has replaced the FSA module in the FASTNN with the MA;
- FASTNN-SA: This model has replaced the FSA module in the FASTNN with the SA;
- FASTNN-FNN: This model has replaced the MFR module in the FASTNN with the FNN;
- FASTNN-add: The FASTNN-add model has replaced the MFR module in the FASTNN with the adding layer, the adding layer can sum the ST features by filters.
Table 4 shows the performance of FASTNN compared with other variants of the model. It can be observed that FASTNN proposed in this paper achieves the best performance compared to all variants.
Table 4.
Comparison of performance under different variants. (Note: Bold represents the best performance).
In the attention variants, a possible explanation for this is that FASTNN-MA and FASTNN-SA not only required reconstructing the learnable parameters to sequence length but also relied on manually setting the sequence length, which resulted in the possibility of dropping critical information for a shorter length during the computation. Longer sequence length, on the other hand, will increase the number of parameters in the model and result in overfitting problems in the model. For example, the FASTNN-MA model outperforms FASTNN-SA in the TaxiBJ dataset, which has a larger volume of data, while the opposite prediction performance was observed in the BikeNYC dataset, which has a smaller volume. Meanwhile, the MAE metric of FASTN-MA is slightly better than that of FASTNN in the TaxiBJ dataset, a possible explanation for this is that FASTNN-MA produced outliers in the prediction task of the TaxiBJ dataset with a larger data volume, which was detected by RMSE but not by MAE due to the different metric calculation.
In the MFR variant, the performance of FNN was better than that of the adding layer, which indicates that each ST feature contains information of different importance to the model. However, the direct calculation of contribution using FNN will ignore the intrinsic correlation in the same ST feature and introduce redundant information between different ST features, which results in the reduction of model accuracy.
5.7. Evaluations on Ablation Analysis (Q3)
To quantify the effectiveness of the FSA module and MFR module proposed in this paper, the following ablation analysis was conducted. This paper evaluated the prediction performance of the original model, the model without the FSA module (FASTNN-without FSA), and the model without the MFR module (FASTNN-without MFR), on the datasets using two metrics.
As shown in Figure 8, the accuracy of FASTNN-without FSA was consistently lower than that of the FASTNN given the lack of display modeling of the ST aggregation. Simultaneously, the accuracy of FASTNN-without FSA was additionally lower than that of FASTNN-without MFR, indicating a greater degree of importance for ST agglomerative deep mining in the TFP, and the quantification of the intrinsic correlation and redundancy brought the performance improvement less than its obvious effect.
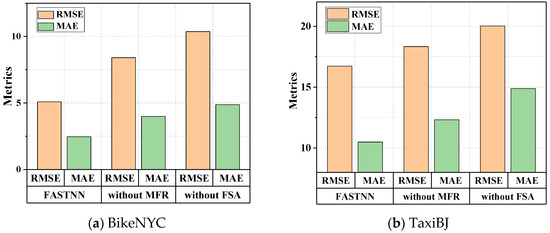
Figure 8.
Comparison of ablation experiments on two datasets.
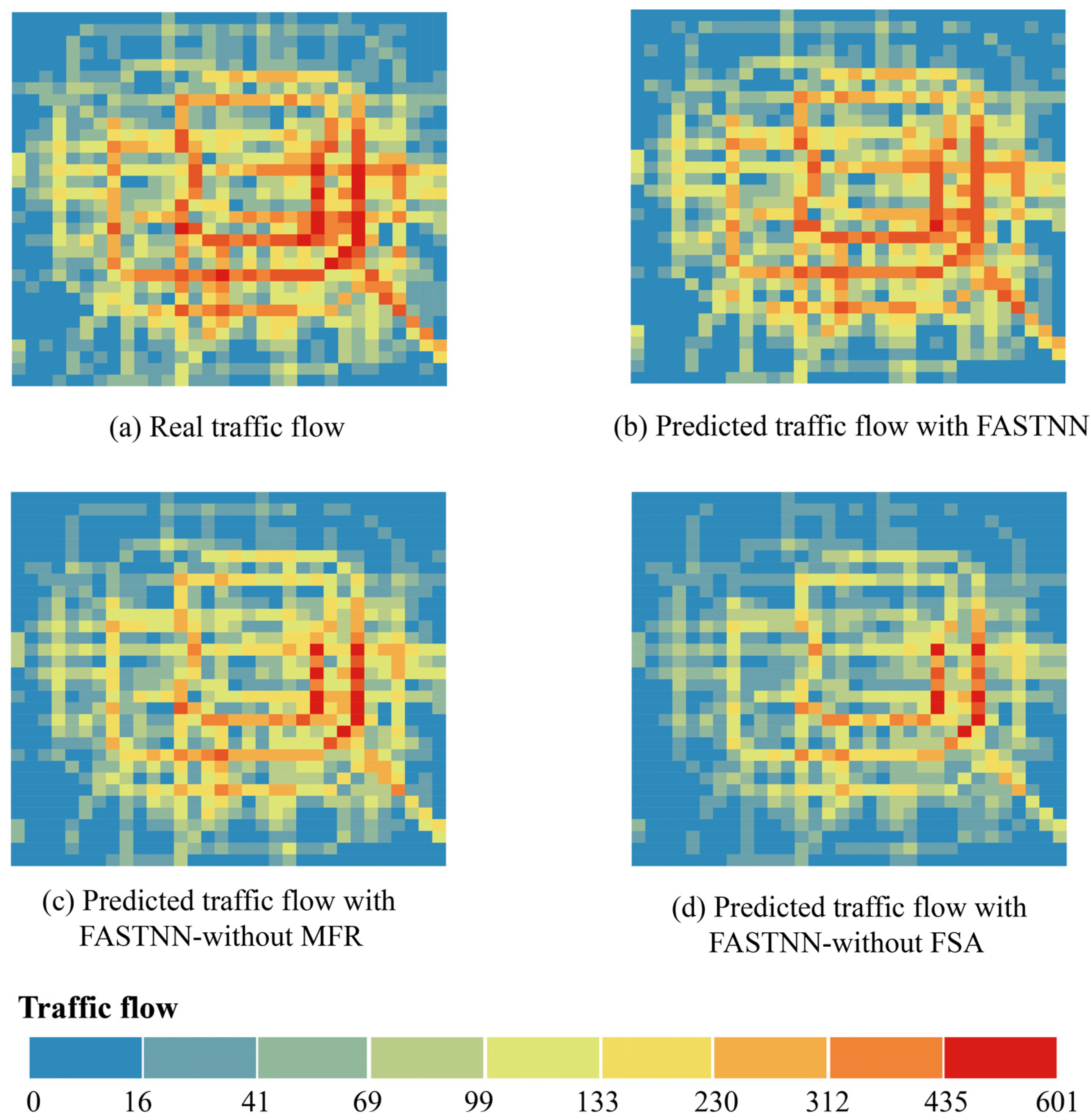
Figure 9 visualized the real traffic flow and the prediction results of each model. Among them, Figure 9a showed the visualization results of the original real traffic flow at moment , and Figure 9b–d show the traffic flow prediction results of FASTNN, FASTNN-without MFR, and FASTNN-without FSA at moment . The prediction result of FASTNN was the closest to the real traffic flow, which restores the real state of traffic flow to the greatest extent, and the prediction result of FASTNN-without MFR is secondary. The prediction of FASTNN-without FSA is underperforming, and the congestion characteristics in the center and the traffic flow in the edge part are not detectable efficiently.
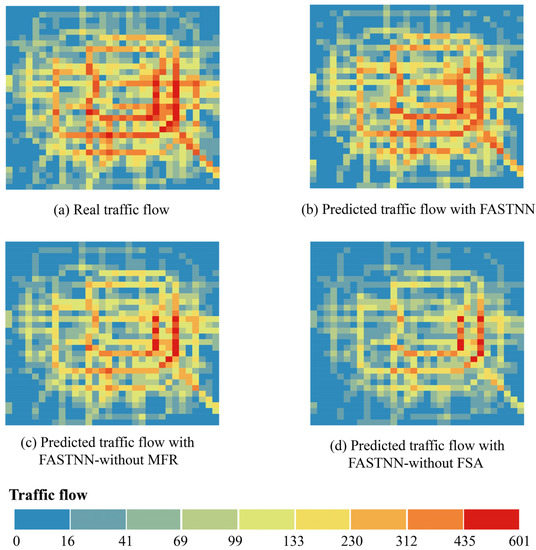
Figure 9.
Real traffic flow and model prediction results.
5.8. Effective of the Module (Q4)
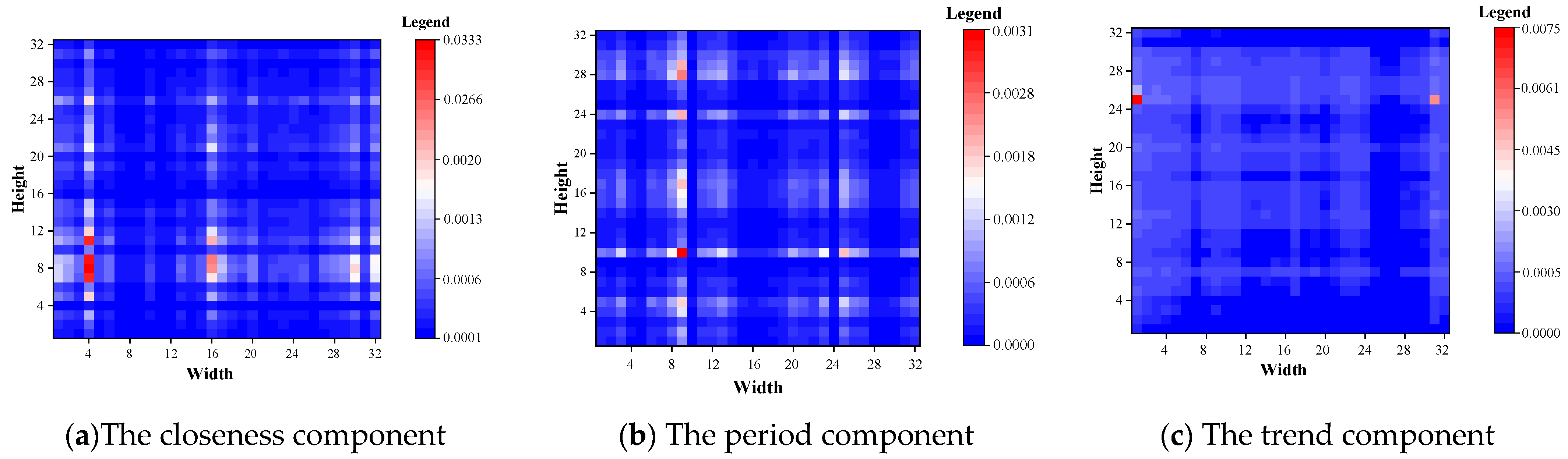
This paper visualized the FSA weight matrix of the output of the FSA module of the last layer of the three components of closeness period and trend using the TaxiBJ dataset as an example. As shown in Figure 10, the weights of all regions were greater than 0, indicating that all regions have a positive effect on the TFP. The closeness component has the maximum weight with a mean value of 0.000455 and the period component has the minimum weight with a mean value of 0.000301. In addition, the distribution pattern of the hotspot of the closeness component was similar to that of the period component, which indicated that the closer the input historical time is to the predicted time, the greater the contribution to the prediction.
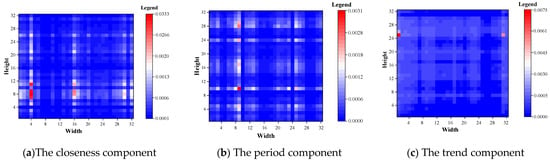
Figure 10.
Visualization of FSA module for TaxiBJ dataset.
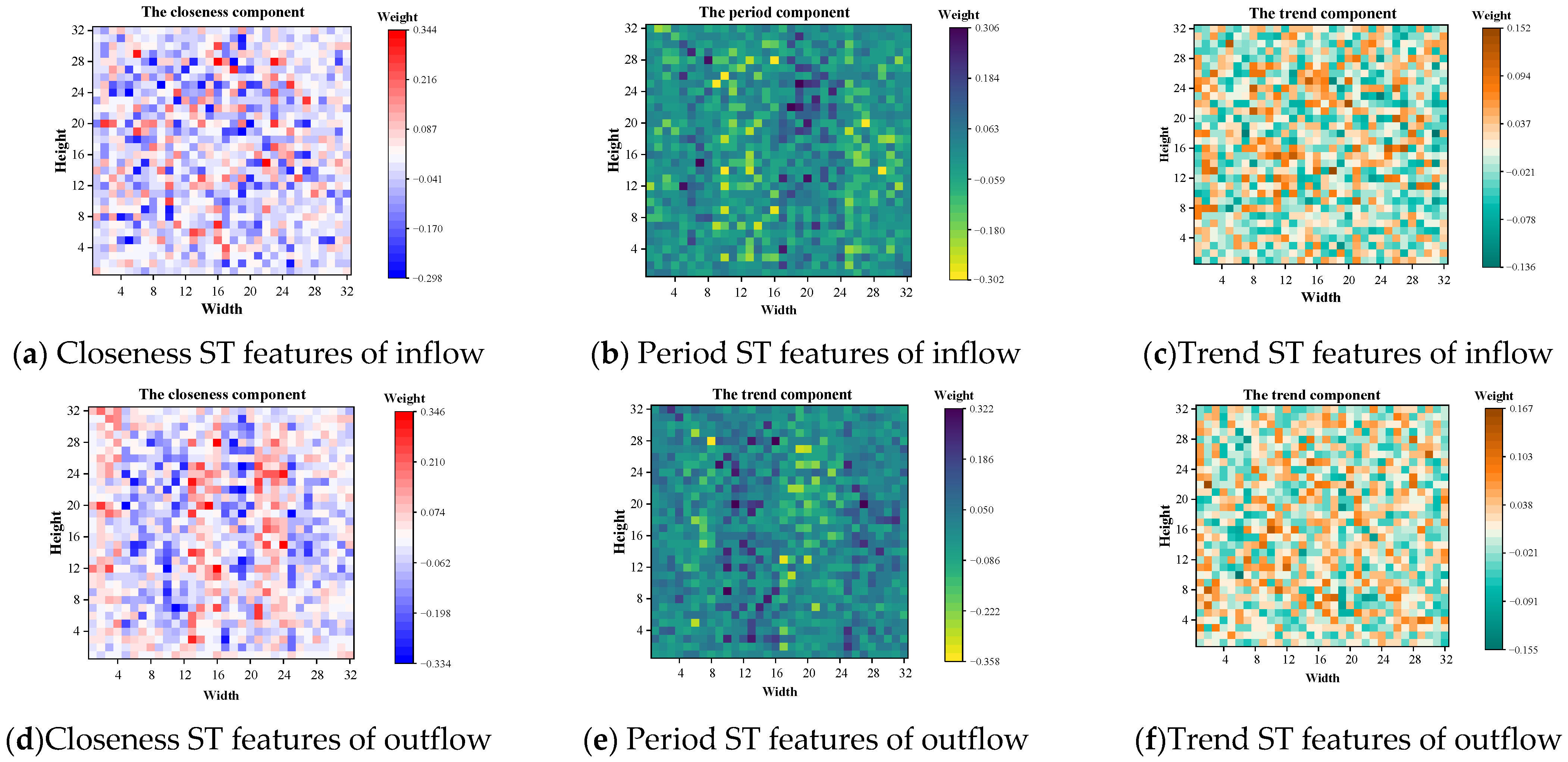
To visualize the effectiveness of the MFR module, the weight matrices of the outflows and inflows of the three components closeness, period, and trend in the MFR layer were visualized on its 32 × 32 grid using the TaxiBJ dataset as an example.
The results were shown in Figure 11. In each weight matrix, the value of grid indicated the MFR module weight of the corresponding ST feature to the region, which has modeled the intrinsic correlation of each ST feature and the redundancy between all ST features. It can be observed that the same ST features have different contributions to each region, as in Figure 11a, each region has different weight values, which also represents the successful modeling of the intrinsic correlation. Simultaneously, different ST features also have different contributions to the same region, as in Figure 11a–c, the weight values of the same region were different in different components, which represents the successful modeling of redundancy for different ST features.
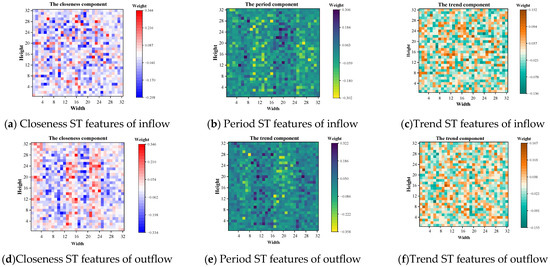
Figure 11.
Visualization of MFR module for TaxiBJ dataset.
6. Conclusions
Traffic flow prediction is a key input to intelligent transportation systems, intending to predict short-term or long-term traffic flow based on historical traffic data. Accurate TFP for the region can pre-allocate the required vehicles to areas with high travel demand, which not only reduces passenger waiting time and improves travel service quality but also provide references for implementing traffic management strategies, developing travel route planning, and public transportation risk assessment.
The starting point of this paper is to build an accurate deep learning model for traffic flow prediction. The motivation of this paper is to model the two key problems of spatial-temporal aggregation in traffic data and intrinsic correlation or redundancy of the spatialtemporal features and thus implement the deep mining of the spatiotemporal dependence of traffic data to improve the prediction accuracy. To solve mentioned problem, this paper proposed a novel deep learning model, named filter attention-based spatiotemporal neural network. This model used the filter spatial attention module, which can implement the dynamic adjustment of spatial weights of ST features under different times and regions. This model also constructed a lightweight matrix factorization-based resample module that models the intrinsic correlation in the ST feature, which also enhances the concentration of the model to information-rich ST features and reduces redundancy among different ST features. Meanwhile, this paper employed three types of historical traffic data-closeness, period, and trend- and 3D-convolutional neural networks to mine generic spatiotemporal dependencies. The specific experimental conclusions were as follows:
- (1)
- In the comparison of the baseline models, the deep learning-based baselines have better predictive performance than the traditional baselines, which indicates that deep learning-based baselines are capable of eliminating the subjective factors caused by the artificial design compared to traditional baselines and also have enhanced spatiotemporal dependent nonlinear fitting capability;
- (2)
- The performance of the FASTNN was evaluated using two large-scale real datasets, and the results indicate that the FASTNN achieves more accurate predictions than the existing baselines, and the performance of FASTNN improves by 22.94% and 9.86% (RMSE) on the BikeNYC and TaxiBJ datasets compared to the baseline with optimal performance. Simultaneously, the same predicted performance results also appear in the variant experiments;
- (3)
- In the ablation analysis, the FASTNN model with FSA predicted better performance than the model with MFR, indicating that modeling of spatiotemporal aggregation is more critical than the modeling of intrinsic correlation and redundancy of spatiotemporal features.
It is noteworthy that the FASTNN can run without extensive external features and achieve better results. This suggests that modeling the spatiotemporal aggregation of traffic data and quantifying the intrinsic correlation and redundancy between ST features can contribute positively to the extraction of nonlinear spatiotemporal dependencies. The FASTNN proposed in this paper can provide reliable traffic guidance information to intelligent transportation systems. In future work, we consider incorporating the extensive multi-source data (e.g., transit, bike) into the traffic flow prediction to mine and model the interactions and correlations between spatiotemporal data. Meanwhile, the incorporation of external traffic information, such as road networks and traffic lights, is also an important direction for TFP to consider. Limited by the availability of data, external features were not considered here in this paper.
Author Contributions
Conceptualization, Q.Z. and N.C.; methodology, Q.Z.; software, Q.Z.; validation, Q.Z.; formal analysis, Q.Z.; investigation, N.C.; resources, Q.Z., S.L. and N.C.; data curation, Q.Z. and S.L.; writing—original draft preparation, Q.Z. and N.C.; writing—review and editing, Q.Z. and N.C.; visualization, Q.Z.; supervision, N.C.; project administration, Q.Z. and N.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (grant number 41771423).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
We thank the editors and the anonymous reviewers for their valuable comments and suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lv, Z.Q.; Li, J.B.; Dong, C.A.H.; Xu, Z.H. DeepSTF: A Deep Spatial-Temporal Forecast Model of Taxi Flow. Comput. J. 2021. [Google Scholar] [CrossRef]
- Zheng, Y.; Capra, L.; Wolfson, O.; Yang, H. Urban Computing: Concepts, Methodologies, and Applications. Acm Trans. Intell. Syst. Technol. 2014, 5, 1–55. [Google Scholar] [CrossRef]
- Kim, D.; Jeong, O. Cooperative Traffic Signal Control with Traffic Flow Prediction in Multi-Intersection. Sensors 2020, 20, 137. [Google Scholar] [CrossRef]
- Luis Zambrano-Martinez, J.; Calafate, C.T.; Soler, D.; Cano, J.-C.; Manzoni, P. Modeling and Characterization of Traffic Flows in Urban Environments. Sensors 2018, 18, 2020. [Google Scholar] [CrossRef]
- Ma, X.L.; Tao, Z.M.; Wang, Y.H.; Yu, H.Y.; Wang, Y.P. Long short-term memory neural network for traffic speed prediction using remote microwave sensor data. Transp. Res. Part C-Emerg. Technol. 2015, 54, 187–197. [Google Scholar] [CrossRef]
- Wei, W.Y.; Wu, H.H.; Ma, H. An AutoEncoder and LSTM-Based Traffic Flow Prediction Method. Sensors 2019, 19, 2946. [Google Scholar] [CrossRef]
- Kuang, L.; Yan, X.J.; Tan, X.H.; Li, S.Q.; Yang, X.X. Predicting Taxi Demand Based on 3D Convolutional Neural Network and Multi-task Learning. Remote Sens. 2019, 11, 1265. [Google Scholar] [CrossRef]
- Chu, K.-F.; Lam, A.Y.S.; Li, V.O.K. Deep Multi-Scale Convolutional LSTM Network for Travel Demand and Origin-Destination Predictions. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3219–3232. [Google Scholar] [CrossRef]
- Niu, K.; Cheng, C.; Chang, J.; Zhang, H.; Zhou, T. Real-Time Taxi-Passenger Prediction With L-CNN. IEEE Trans. Veh. Technol. 2019, 68, 4122–4129. [Google Scholar] [CrossRef]
- Lin, X.F.; Huang, Y.Z. Short-Term High-Speed Traffic Flow Prediction Based on ARIMA-GARCH-M Model. Wirel. Pers. Commun. 2021, 117, 3421–3430. [Google Scholar] [CrossRef]
- Evgeniou, T.; Pontil, M.; Poggio, T. Regularization networks and support vector machines. Adv. Comput. Math. 2000, 13, 1–50. [Google Scholar] [CrossRef]
- Smola, A.J.; Scholkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.B.; Zheng, Y.; Qi, D.K.; Li, R.Y.; Yi, X.W. DNN-Based Prediction Model for Spatio-Temporal Data. In Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM SIGSPATIAL GIS), San Francisco, CA, USA, 31 October–3 November 2016. [Google Scholar]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.Y.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef]
- Saxena, D.; Cao, J.N. Multimodal Spatio-Temporal Prediction with Stochastic Adversarial Networks. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–23. [Google Scholar] [CrossRef]
- Wang, X.Y.; Ma, Y.; Wang, Y.Q.; Jin, W.; Wang, X.; Tang, J.L.; Jia, C.Y.; Yu, J. Traffic Flow Prediction via Spatial Temporal Graph Neural Network. In Proceedings of the 29th World Wide Web Conference (WWW), Taipei, Taiwan, 20–24 April 2020; pp. 1082–1092. [Google Scholar]
- Guo, S.N.; Lin, Y.F.; Feng, N.; Song, C.; Wan, H.Y. Attention Based Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 922–929. [Google Scholar]
- Luis Zambrano-Martinez, J.; Calafate, C.T.; Soler, D.; Lemus-Zuniga, L.-G.; Cano, J.-C.; Manzoni, P.; Gayraud, T. A Centralized Route-Management Solution for Autonomous Vehicles in Urban Areas. Electronics 2019, 8, 722. [Google Scholar] [CrossRef]
- Williams, B.M.; Hoel, L.A. Modeling and forecasting vehicular traffic flow as a seasonal ARIMA process: Theoretical basis and empirical results. J. Transp. Eng. 2003, 129, 664–672. [Google Scholar] [CrossRef]
- Liu, Y.Y.; Tseng, F.M.; Tseng, Y.H. Big Data analytics for forecasting tourism destination arrivals with the applied Vector Autoregression model. Technol. Forecast. Soc. Change 2018, 130, 123–134. [Google Scholar] [CrossRef]
- Habtemichael, F.G.; Cetin, M. Short-term traffic flow rate forecasting based on identifying similar traffic patterns. Transp. Res. Part C-Emerg. Technol. 2016, 66, 61–78. [Google Scholar] [CrossRef]
- Jeong, Y.S.; Byon, Y.J.; Castro-Neto, M.M.; Easa, S.M. Supervised Weighting-Online Learning Algorithm for Short-Term Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1700–1707. [Google Scholar] [CrossRef]
- Chandra, S.R.; Al-Deek, H. Predictions of Freeway Traffic Speeds and Volumes Using Vector Autoregressive Models. J. Intell. Transp. Syst. 2009, 13, 53–72. [Google Scholar] [CrossRef]
- Zhang, F.; Zhu, X.; Hu, T.; Guo, W.; Chen, C.; Liu, L. Urban Link Travel Time Prediction Based on a Gradient Boosting Method Considering Spatiotemporal Correlations. Isprs Int. J. Geo-Inf. 2016, 5, 201. [Google Scholar] [CrossRef]
- Cheng, S.; Lu, F.; Peng, P.; Wu, S. A Spatiotemporal Multi-View-Based Learning Method for Short-Term Traffic Forecasting. Isprs Int. J. Geo-Inf. 2018, 7, 218. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Rice, J.A. Short-term travel time prediction. Transp. Res. Part C-Emerg. Technol. 2003, 11, 187–210. [Google Scholar] [CrossRef]
- Wu, Z.H.; Pan, S.R.; Long, G.D.; Jiang, J.; Zhang, C.Q. Graph WaveNet for Deep Spatial-Temporal Graph Modeling. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 1907–1913. [Google Scholar]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU Neural Network Methods for Traffic Flow Prediction. In Proceedings of the 31st Youth Academic Annual Conference of Chinese-Association-of-Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar]
- He, Y.X.; Li, L.S.; Zhu, X.T.; Tsui, K.L. Multi-Graph Convolutional-Recurrent Neural Network (MGC-RNN) for Short-Term Forecasting of Transit Passenger Flow. IEEE Trans. Intell. Transp. Syst. 2022. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Z.; Jia, R. DeepPF: A deep learning based architecture for metro passenger flow prediction. Transp. Res. Part C-Emerg. Technol. 2019, 101, 18–34. [Google Scholar] [CrossRef]
- Du, B.; Peng, H.; Wang, S.; Bhuiyan, M.Z.A.; Wang, L.; Gong, Q.; Liu, L.; Li, J. Deep Irregular Convolutional Residual LSTM for Urban Traffic Passenger Flows Prediction. IEEE Trans. Intell. Transp. Syst. 2020, 21, 972–985. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, Y.; Hu, J.; Zhao, Y.; Li, S.; Hu, J. Deep Autoencoder Neural Networks for Short-Term Traffic Congestion Prediction of Transportation Networks. Sensors 2019, 19, 2229. [Google Scholar] [CrossRef]
- Zhang, J.B.; Zheng, Y.; Qi, D.K. Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 1655–1661. [Google Scholar]
- Guo, S.N.; Lin, Y.F.; Li, S.J.; Chen, Z.M.; Wan, H.Y. Deep Spatial-Temporal 3D Convolutional Neural Networks for Traffic Data Forecasting. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3913–3926. [Google Scholar] [CrossRef]
- Yao, H.X.; Wu, F.; Ke, J.T.; Tang, X.F.; Jia, Y.T.; Lu, S.Y.; Gong, P.H.; Ye, J.P.; Li, Z.H. Deep Multi-View Spatial-Temporal Network for Taxi Demand Prediction. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 2588–2595. [Google Scholar]
- Sun, S.; Wu, H.; Xiang, L. City-Wide Traffic Flow Forecasting Using a Deep Convolutional Neural Network. Sensors 2020, 20, 421. [Google Scholar] [CrossRef] [Green Version]
- Ko, E.; Ahn, J.; Kim, E.Y. 3D Markov Process for Traffic Flow Prediction in Real-Time. Sensors 2016, 16, 147. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Zheng, Y.; Qi, D.; Li, R.; Yi, X.; Li, T. Predicting citywide crowd flows using deep spatio-temporal residual networks. Artif. Intell. 2018, 259, 147–166. [Google Scholar] [CrossRef]
- Chen, C.; Li, K.L.; Teo, S.G.; Chen, G.Z.; Zou, X.F.; Yang, X.L.; Vijay, R.C.; Feng, J.S.; Zeng, Z.; IEEE. Exploiting Spatio-Temporal Correlations with Multiple 3D Convolutional Neural Networks for Citywide Vehicle Flow Prediction. In Proceedings of the 18th IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 893–898. [Google Scholar]
- Zhang, J.B.; Zheng, Y.; Sun, J.K.; Qi, D.K. Flow Prediction in Spatio-Temporal Networks Based on Multitask Deep Learning. IEEE Trans. Knowl. Data Eng. 2020, 32, 468–478. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Z.; Lyu, C.; Ye, J. Attention-Based Deep Ensemble Net for Large-Scale Online Taxi-Hailing Demand Prediction. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4798–4807. [Google Scholar] [CrossRef]
- Yan, S.J.; Xiong, Y.J.; Lin, D.H. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7444–7452. [Google Scholar]
- Zheng, Z.B.; Yang, Y.T.; Liu, J.H.; Dai, H.N.; Zhang, Y. Deep and Embedded Learning Approach for Traffic Flow Prediction in Urban Informatics. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3927–3939. [Google Scholar] [CrossRef]
- Fang, S.; Zhang, Q.; Meng, G.; Xiang, S.; Pan, C. GSTNet: Global Spatial-Temporal Network for Traffic Flow Prediction. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 2286–2293. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Hao, S.; Lee, D.-H.; Zhao, D. Sequence to sequence learning with attention mechanism for short-term passenger flow prediction in large-scale metro system. Transp. Res. Part C-Emerg. Technol. 2019, 107, 287–300. [Google Scholar] [CrossRef]
- Wang, Z.; Su, X.; Ding, Z. Long-Term Traffic Prediction Based on LSTM Encoder-Decoder Architecture. IEEE Trans. Intell. Transp. Syst. 2021, 22, 6561–6571. [Google Scholar] [CrossRef]
- Zheng, C.; Fan, X.; Wang, C.; Qi, J. GMAN: A Graph Multi-Attention Network for Traffic Prediction. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 1234–1241. [Google Scholar]
- Do, L.N.N.; Vu, H.L.; Vo, B.Q.; Liu, Z.Y.; Phung, D. An effective spatial-temporal attention based neural network for traffic flow prediction. Transp. Res. Part C-Emerg. Technol. 2019, 108, 12–28. [Google Scholar] [CrossRef]
- Yu, K.; Qin, X.; Jia, Z.; Du, Y.; Lin, M. Cross-Attention Fusion Based Spatial-Temporal Multi-Graph Convolutional Network for Traffic Flow Prediction. Sensors 2021, 21, 8468. [Google Scholar] [CrossRef]
- Jia, H.; Luo, H.; Wang, H.; Zhao, F.; Ke, Q.; Wu, M.; Zhao, Y. ADST: Forecasting Metro Flow Using Attention-Based Deep Spatial-Temporal Networks with Multi-Task Learning. Sensors 2020, 20, 4574. [Google Scholar] [CrossRef]
- Liu, D.; Tang, L.; Shen, G.; Han, X. Traffic Speed Prediction: An Attention-Based Method. Sensors 2019, 19, 3836. [Google Scholar] [CrossRef] [PubMed]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pan, Z.Y.; Wang, Z.Y.; Wang, W.F.; Yu, Y.; Zhang, J.B.; Zheng, Y. Matrix Factorization for Spatio-Temporal Neural Networks with Applications to Urban Flow Prediction. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM), Beijing, China, 3–7 November 2019; pp. 2683–2691. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. In Proceedings of the NIPS 2014 Workshop on Deep Learning, Montreal, QC, Canada, 12–13 December 2014. [Google Scholar]
- Shi, X.J.; Chen, Z.R.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
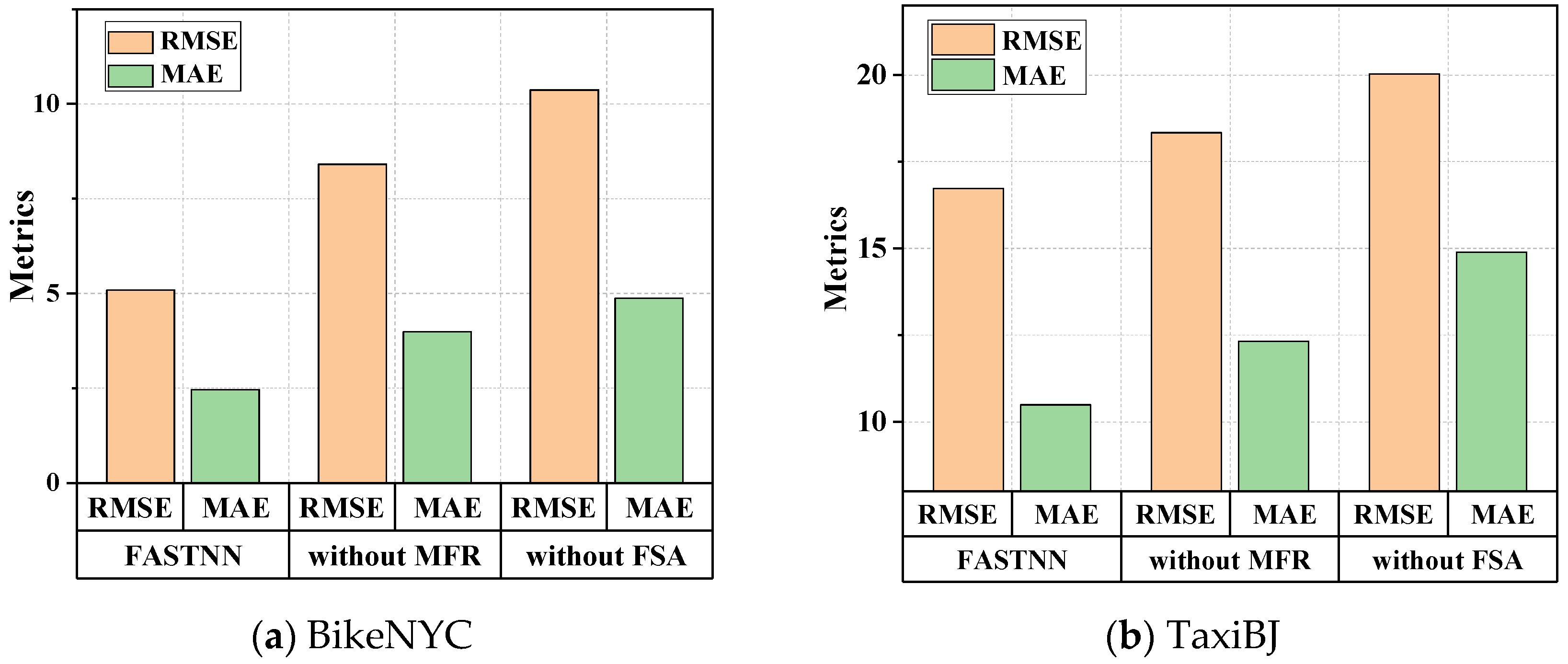
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).