


D2D-Assisted Multi-User Cooperative Partial Offloading in MEC Based on Deep Reinforcement Learning



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We construct a D2D-MEC framework that combines D2D communications and MEC technology. The user equipment with limited computational capability can offload part of its computation-intensive tasks to the MEC server located in the BS and the idle equipment nearby, and the allocation of computing resources is the responsibility of the BS. In order to maximize the computing power of the whole system under the condition of limited computing resources, we propose an MEC framework including partial offloading, resource allocation, and user association under the maximum delay constraint of the application.
- We propose an optimization problem with constraints on both delay and computational resources, which is NP hard. By analyzing the internal structure of the optimization problem, it is decomposed into two sub-problems. We prove that the optimal solutions of the two sub-problems constitute the optimal solution of the original problem. The convex optimization is employed to solve the optimal solution of the first subproblem. The second subproblem is described as a Markov decision process (MDP) used to maximize the amount of tasks calculated by the system, in which offload decisions, resource allocation, and user association are determined simultaneously. A DQN-based modeless reinforcement learning algorithm is proposed to maximize the objective function.
- Extensive simulations demonstrate that the proposed algorithm outperforms traditional MEC schemes, Q-learning, DQN, and other conventional algorithms under different system parameters.
2. System Model
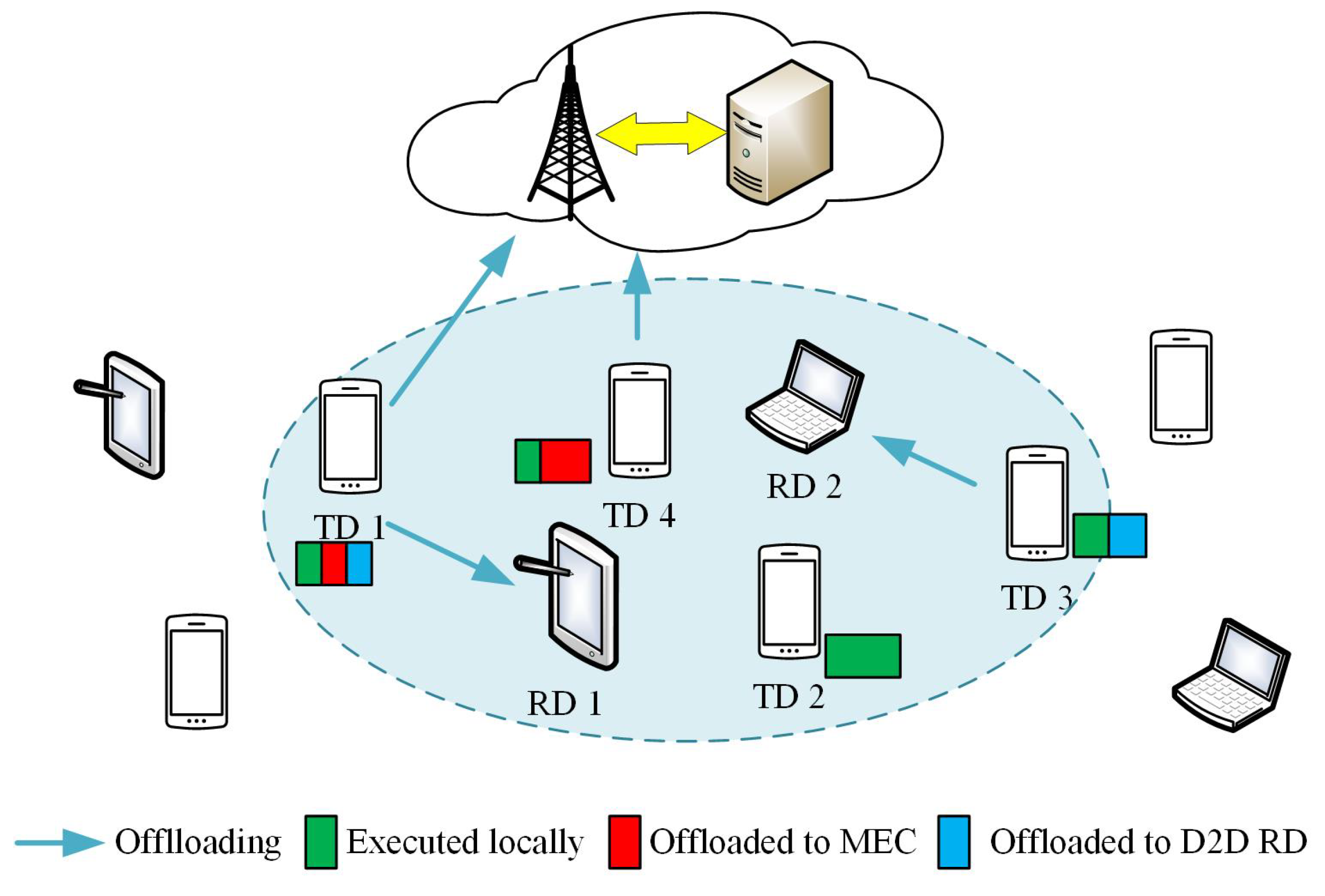
2.1. Network Model
2.2. Channel Model
2.3. Computation Model
- Local Computing: The local computation delay of the task on TD i can be computed as
- Edge Computing: The total latency of edge computing on TD i consists of three parts: (1) time for uploading computing tasks , (2) time for executing tasks on the MEC server , and (3) time for downloading computing results. Similar to [31,34], this study ignores the delay of sending results back to TDs from MEC server. This is because the size of the results is usually much smaller than the size of the transmitting data. Therefore, according to Equation (1), the delay of TD i to complete edge cloud computing can be computed as
- D2D RDs Computing: Similar to edge cloud computing, the delay of TD i to complete D2D RD computing can be obtained by (1) D2D transmission delay and (2) remote-execution delay
2.4. Problem Formulation
3. Problem Decomposition
4. DQN-Based Computation Offloading
4.1. Three Key Elements for MDP
- State Space:At each time slot, the agent observes and collects all device information within the range of the BS. At step t, the state of the system consists of two parts: . Among them, represents the computing resources of all resource devices in the system, and where represents the completion of the tasks on the task devices. We define as the system state observed by the BS at the beginning of the time slot; that is, .
- Action Space:The action space consists of two parts: , where , represents the offload association between the TDs and the D2D RDs. is the task offload ratio of the currently assigned TDs. According to constraint (26) and (27), it is stipulated that action at step t satisfies condition .
- Reward Function:The objective function of is the sum of the TD devices that complete the calculation. Considering that the size of the computing tasks of each device is different, to ensure the fairness of the evaluation, the reward function is defined as the sum of the size of the computing tasks completed in the current time slot:
4.2. Algorithm Design Based on DQN
- Initialize the action-value function and the target action-value function with parameters and , respectively. Initialize experiment replay buffer D to an empty set of size N.
- Initialize , and specify that the growth rate of is and grows to . This parameter determines the probability of random selection when the agent selects an action, and the probability of random selection decreases with the update of the network parameters.
- Initialize the optimal trajectory record and the maximum total return value .
- In each episode, the agent in the BS collects the . Initialize to calculate the total return value of this episode. is used to determine whether all actions in this episode are determined by the Q-Network or the optimal trajectory.
- If the training episode is less than or equal to 100, is used to decide whether the choice of action is randomly selected or selected according to the maximum Q value.
- When the training episode is greater than 100: , the selection of actions in this episode is the same as that in point number five; when , the actions are performed in accordance with the optimal trajectory in this episode. It should be noted that the reward settings in environment 1 and environment 2 are different. They are expressed as follows.
- When step t ends, store in the experience replay buffer; update the total reward value of the current cycle ; retrieve multiple records from the experience replay buffer to update Q-Network; increase the value of .
- At the end of each episode, compare the values of R and , and compare the number of training steps in this period with the length of to determine whether to update the action trajectory record.
- When adding a judgment item to the outer layer of the traditional DQN, the setting of the reward function becomes flexible.
- In addition to the traditional DQN replay memory D, a new cache space is added, which can be used to record the excellent action trajectory.
- Depending on the type of problem solved, the action space of the DQN-PTR can vary with the execution of each action.
| Algorithm 1: DQN-PTR to solve |
01: Initialize the Q-Network Q with random weights 02: Initialize the Target Q-Network with weights 03: Initialize replay memory D to capacity N 04: Initialize 05: Initialize optimal trajectory to empty and maximum total return 06: For do 07: Initialize sum reward 08: Initialize state , 09: For each step t do 10: If or then 11: If then 12: Select a random action 13: else 14: Set 15: end if 16: Execute action , observe next state and reward according to environment 1 17: else 18: Set according 19: Execute action , observe next state and reward according to environment 2 20: end if 21: 22: Store transition in D 23: If episode terminates at step then 24: If then 25: Replace the trajectory in with 26: 27: else if and then 28: Replace the trajectory in with 29: end if 30: break 31: end if 32: Sample random mini-batch of transitions from D 33: Set 34: Perform a gradient descent step on with respect to the network parameters 35: If then 36: 37: end if 38: Every C steps reset 39: end for 40: end for |
5. Analysis of Simulation Results
5.1. Simulation Setup
- Full Local: All TDs execute their tasks via local computing.
- Local-cloud: The computing tasks on TDs can be divided into two parts, which are computed on the local and edge cloud, respectively. In order to make full use of computing resources, all computing resources on TD i are allocated to task . If the local resources are insufficient, the computing resources will be supplemented by the edge cloud.
- RBA: The TD i randomly selects a D2D RD device for computing offload and utilizes all the computing resources of the D2D RD device. If the computing resources of the two places are insufficient, the edge cloud will supplement the computing resources.
- GBA: The TD i selects the D2D RD device with the largest remaining resources. Under the condition of making full use of local computing resources, the remaining computing tasks are evenly sent to the D2D RD device and edge cloud for computing.
- Q-learning: Q-learning is a basic reinforcement learning algorithm. Using Q-learning to solve , in simulation, the state space, action space, and reward function of Q-learning are all the same as those in DQN-PTR.
- DQN: DQN is an improved reinforcement learning algorithm based on Q-learning. In the simulation, the state space, action space, and reward function of DQN are all the same as those in DQN-PTR.
5.2. Simulation Result
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MEC | Mobile edge computin |
| D2D | Device-to-device |
| MDP | Markov decision process |
| DQN | Deep Q network |
| AR | Augmented reality |
| VR | Virtual reality |
| UE | User equipment |
| BS | Base station |
| SCA | Successive convex approximation |
| GP | Geometric programming |
| DCN | Distributed computing node |
| MIP | Mixed integer programming |
| RL | Reinforcement learning |
| VFC | Vehicular fog computing |
| TD | Task device |
| RD | Resource device |
| D2D RD | D2D Resource device |
| Notations | |
| The index of the TD i | |
| The index of the RD i, where represents the BS, and the others represent D2D RD | |
| The number of TDs | |
| The number of D2D RDs | |
| The set of all TDs | |
| The set of all RDs | |
| The index of the computing task on | |
| The data size of the task | |
| CPU cycles per bit required for task | |
| The maximum delay of the task | |
| The local computing capacity of the TD i | |
| The computing resource of the RD i | |
| The transmission rate between the TD i and the RD j | |
| The bandwidth allocated to the channel between TD i and RD j | |
| The cellular transmission power from TD i to BS | |
| The transmission power of D2D from TD i to a D2D RD | |
| The maximum uplink power of TD i | |
| User association between TD i and RD j | |
| The proportion of a computing task on TD i that is offloaded to the BS | |
| The proportion of a computing task on TD i that is offloaded to D2D RD | |
| The local computation delay of the task on TD i | |
| The delay of TD i to complete edge cloud computing | |
| Cellular transmission delay of TD i | |
| The computation delay of task at BS | |
| The delay of TD i to complete D2D RD computing | |
| D2D transmission delay of TD i | |
| The computation delay of task at D2D RD | |
| The total delay for completing the task on TD i | |
| The completion of the computing task on TD i |
Appendix A
Appendix B
- When , the computing task of TD i is only computed at the local and edge cloud, thus , and . In this case, constraint (21) is obviously satisfied. We then haveFrom (20), we can obtainTake the derivative of the right hand side of the above inequality, we have
- When , it means that TD i offloads the computing task to a certain D2D RD, we define the D2D RD as D2D RD j. According to (21), we have
- When , is substituted into (24) and the result is . Therefore, Theorem 1 is proved in both cases.
Appendix C
References
- Mangiante, S.; Klas, G.; Navon, A.; GuanHua, Z.; Ran, J.; Silva, M.D. Vr is on the edge: How to deliver 360 videos in mobile networks. In Proceedings of the Workshop on Virtual Reality and Augmented Reality Network, New York, NY, USA, 8–11 August 2017; pp. 30–35. [Google Scholar]
- Yang, Z.; Liu, Y.; Chen, Y.; Tyson, G. Deep reinforcement learning in cache-aided MEC networks. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Dinh, T.Q.; Tang, J.; La, Q.D.; Quek, T.Q.S. Offloading in Mobile Edge Computing: Task Allocation and Computational Frequency Scaling. IEEE Trans. Commun. 2017, 65, 3571–3584. [Google Scholar]
- Feng, C.; Han, P.; Zhang, X.; Yang, B.; Liu, Y.; Guo, L. Computation offloading in mobile edge computing networks: A survey. J. Netw. Comput. Appl. 2022, 202, 103366–103381. [Google Scholar] [CrossRef]
- Elgendy, I.A.; Zhang, W.Z.; Zeng, Y.; He, H.; Tian, Y.-C.; Yang, Y. Efficient and secure multi-user multi-task computation offloading for mobile-edge computing in mobile IoT networks. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2410–2422. [Google Scholar] [CrossRef]
- Khayyat, M.; Elgendy, I.A.; Muthanna, A.; Alshahrani, A.S.; Alharbi, S.; Koucheryavy, A. Advanced deep learning-based computational offloading for multilevel vehicular edge-cloud computing networks. IEEE Access 2020, 8, 137052–137062. [Google Scholar] [CrossRef]
- Zhang, W.Z.; Elgendy, I.A.; Hammad, M.; Iliyasu, A.M.; Du, X.; Guizani, M.; El-Latif, A.A.A. Secure and optimized load balancing for multitier IoT and edge-cloud computing systems. IEEE Internet Things J. 2020, 8, 8119–8132. [Google Scholar] [CrossRef]
- Taleb, T.; Samdanis, K.; Mada, B.; Flinck, H.; Dutta, S.; Sabella, D. On multi-access edge computing: A survey of the emerging 5G network edge cloud architecture and orchestration. IEEE Commun. Surv. Tutor. 2017, 19, 1657–1681. [Google Scholar] [CrossRef]
- Shakarami, A.; Shahidinejad, A.; Ghobaei-Arani, M. An autonomous computation offloading strategy in Mobile Edge Computing: A deep learning-based hybrid approach. J. Netw. Comput. Appl. 2021, 178, 102974–102992. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile edge computing: A survey on architecture and computation offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Hu, Z.; Niu, J.; Ren, T.; Dai, B.; Li, Q.; Xu, M.; Das, S.K. An efficient online computation offloading approach for large-scale mobile edge computing via deep reinforcement learning. IEEE Trans. Serv. Comput. 2021, 15, 669–683. [Google Scholar] [CrossRef]
- Kumari, P.; Mishra, R.; Gupta, H.P.; Dutta, T.; Das, S.K. An energy efficient smart metering system using edge computing in LoRa network. IEEE Trans. Sustain. Comput. 2021, 1–13. [Google Scholar] [CrossRef]
- Othman, M.; Madani, S.A.; Khan, S.U. A survey of mobile cloud computing application models. IEEE Commun. Surv. Tutor. 2013, 16, 393–413. [Google Scholar]
- Wu, H. Multi-objective decision-making for mobile cloud offloading: A survey. IEEE Access 2018, 6, 3962–3976. [Google Scholar] [CrossRef]
- Chalaemwongwan, N.; Kurutach, W. Mobile cloud computing: A survey and propose solution framework. In Proceedings of the 2016 13th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Chiang Mai, Thailand, 28 June–1 July 2016; pp. 1–4. [Google Scholar]
- Li, J.; Gao, H.; Lv, T.; Lu, Y. Deep reinforcement learning based computation offloading and resource allocation for MEC. In Proceedings of the 2018 IEEE Wireless communications and networking conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar]
- Elgendy, I.A.; Zhang, W.Z.; He, H.; Gupta, B.B.; El-Latif, A.A.A. Joint computation offloading and task caching for multi-user and multi-task MEC systems: Reinforcement learning-based algorithms. Wirel. Netw. 2021, 27, 2023–2038. [Google Scholar] [CrossRef]
- Sahni, Y.; Cao, J.; Yang, L.; Ji, Y. Multi-hop multi-task partial computation offloading in collaborative edge computing. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1133–1145. [Google Scholar] [CrossRef]
- Chouhan, S. Energy optimal partial computation offloading framework for mobile devices in multi-access edge computing. In Proceedings of the 2019 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 19–21 September 2019; pp. 1–6. [Google Scholar]
- Peng, J.; Qiu, H.; Cai, J.; Xu, W.; Wang, J. D2D-assisted multi-user cooperative partial offloading, transmission scheduling and computation allocating for MEC. IEEE Trans. Wirel. Commun. 2021, 20, 4858–4873. [Google Scholar] [CrossRef]
- Ti, N.T.; Le, L.B. Computation offloading leveraging computing resources from edge cloud and mobile peers. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- Wang, C.; Qin, J.; Yang, X.; Wen, W. Energy-efficient offloading policy in D2D underlay communication integrated with MEC service. In Proceedings of the 3rd International Conference on High Performance Compilation, Computing and Communications, Xi’an, China, 8–10 March 2019; pp. 159–164. [Google Scholar]
- Hu, G.; Jia, Y.; Chen, Z. Multi-user computation offloading with d2d for mobile edge computing. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Zhou, Z.; Dong, M.; Ota, K.; Wang, G.; Yang, L.T. Energy-efficient resource allocation for D2D communications underlaying cloud-RAN-based LTE-A networks. IEEE Internet Things J. 2015, 3, 428–438. [Google Scholar] [CrossRef]
- He, Y.; Ren, J.; Yu, G.; Cai, Y. D2D communications meet mobile edge computing for enhanced computation capacity in cellular networks. IEEE Trans. Wirel. Commun. 2019, 18, 1750–1763. [Google Scholar] [CrossRef]
- Chai, R.; Lin, J.; Chen, M.; Chen, Q. Task Execution Cost Minimization-Based Joint Computation Offloading and Resource Allocation for Cellular D2D MEC Systems. IEEE Syst. J. 2019, 13, 4110–4121. [Google Scholar] [CrossRef]
- Hamdi, M.; Hamed, A.B.; Yuan, D.; Zaied, M. Energy-Efficient Joint Task Assignment and Power Control in Energy-Harvesting D2D Offloading Communications. IEEE Internet Things J. 2022, 9, 6018–6031. [Google Scholar] [CrossRef]
- Fang, T.; Yuan, F.; Ao, L.; Chen, J. Joint Task Offloading, D2D Pairing, and Resource Allocation in Device-Enhanced MEC: A Potential Game Approach. IEEE Internet Things J. 2022, 9, 3226–3237. [Google Scholar] [CrossRef]
- Waqar, N.; Hassan, S.A.; Mahmood, A.; Dev, K.; Do, D.-T.; Gidlund, M. Computation Offloading and Resource Allocation in MEC-Enabled Integrated Aerial-Terrestrial Vehicular Networks: A Reinforcement Learning Approach. IEEE Trans. Intell. Transp. Syst. 2022, 14, 1–14. [Google Scholar] [CrossRef]
- Shakarami, A.; Ghobaei-Arani, M.; Shahidinejad, A. A survey on the computation offloading approaches in mobile edge computing: A machine learning-based perspective. Comput. Netw. 2020, 182, 107496–107519. [Google Scholar] [CrossRef]
- Qin, M.; Cheng, N.; Jing, Z.; Yang, T.; Xu, W.; Yang, Q.; Rao, R.R. Service-oriented energy-latency tradeoff for IoT task partial offloading in MEC-enhanced multi-RAT networks. IEEE Internet Things J. 2020, 8, 1896–1907. [Google Scholar] [CrossRef]
- Guo, M.; Wang, W.; Huang, X.; Chen, Y.; Zhang, L.; Chen, L. Lyapunov-based Partial Computation Offloading for Multiple Mobile Devices Enabled by Harvested Energy in MEC. IEEE Internet Things J. 2021, 9, 9025–9035. [Google Scholar] [CrossRef]
- Truong, T.P.; Nguyen, T.V.; Noh, W.; Cho, S. Partial computation offloading in NOMA-assisted mobile-edge computing systems using deep reinforcement learning. IEEE Internet Things J. 2021, 8, 13196–13208. [Google Scholar] [CrossRef]
- Shi, J.; Du, J.; Wang, J.; Yuan, J. Priority-aware task offloading in vehicular fog computing based on deep reinforcement learning. IEEE Trans. Veh. Technol. 2020, 69, 16067–16081. [Google Scholar] [CrossRef]
- Saleem, U.; Liu, Y.; Jangsher, S.; Tao, X.; Li, Y. Latency Minimization for D2D-Enabled Partial Computation Offloading in Mobile Edge Computing. IEEE Trans. Veh. Technol. 2020, 69, 4472–4486. [Google Scholar] [CrossRef]
- Ohnishi, S.; Uchibe, E.; Yamaguchi, Y.; Nakanishi, K.; Yasui, Y.; Ishii, S. Constrained deep q-learning gradually approaching ordinary q-learning. Front. Neurorobot. 2019, 13, 103–116. [Google Scholar] [CrossRef]
- Fooladivanda, D.; Rosenberg, C. Joint Resource Allocation and User Association for Heterogeneous Wireless Cellular Networks. IEEE Trans. Wirel. Commun. 2013, 12, 248–257. [Google Scholar] [CrossRef]
- Bu, T.; Li, L.; Ramjee, R. Generalized Proportional Fair Scheduling in Third Generation Wireless Data Networks. In Proceedings of the IEEE INFOCOM 2006—25th IEEE International Conference on Computer Communications, Barcelona, Spain, 10 April 2007; pp. 1–12. [Google Scholar]
- Garey, M.R.; Johnson, D.S. “Strong” np-completeness results: Motivation, examples, and implications. J. ACM 1978, 25, 499–508. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guan, X.; Lv, T.; Lin, Z.; Huang, P.; Zeng, J. D2D-Assisted Multi-User Cooperative Partial Offloading in MEC Based on Deep Reinforcement Learning. Sensors 2022, 22, 7004. https://doi.org/10.3390/s22187004
Guan X, Lv T, Lin Z, Huang P, Zeng J. D2D-Assisted Multi-User Cooperative Partial Offloading in MEC Based on Deep Reinforcement Learning. Sensors. 2022; 22(18):7004. https://doi.org/10.3390/s22187004
Chicago/Turabian StyleGuan, Xin, Tiejun Lv, Zhipeng Lin, Pingmu Huang, and Jie Zeng. 2022. "D2D-Assisted Multi-User Cooperative Partial Offloading in MEC Based on Deep Reinforcement Learning" Sensors 22, no. 18: 7004. https://doi.org/10.3390/s22187004
APA StyleGuan, X., Lv, T., Lin, Z., Huang, P., & Zeng, J. (2022). D2D-Assisted Multi-User Cooperative Partial Offloading in MEC Based on Deep Reinforcement Learning. Sensors, 22(18), 7004. https://doi.org/10.3390/s22187004