
PDC: Pearl Detection with a Counter Based on Deep Learning

Abstract
:1. Introduction
- (i)
- A model is developed to automatically recognize pearls based on CNN deep learning,
- (ii)
- The accuracy of pearl detection models is evaluated using images taken from nature and artificial light images,
- (iii)
- An efficient algorithm is presented based on CNN and a corresponding computer vision setup is developed for pearl counting in densely distributed cases.
2. Related Work
2.1. Object Detection
2.2. Object Count
3. Methods
3.1. Image Acquisition and Annotation
3.2. Detector and Counting Framework
- (i)
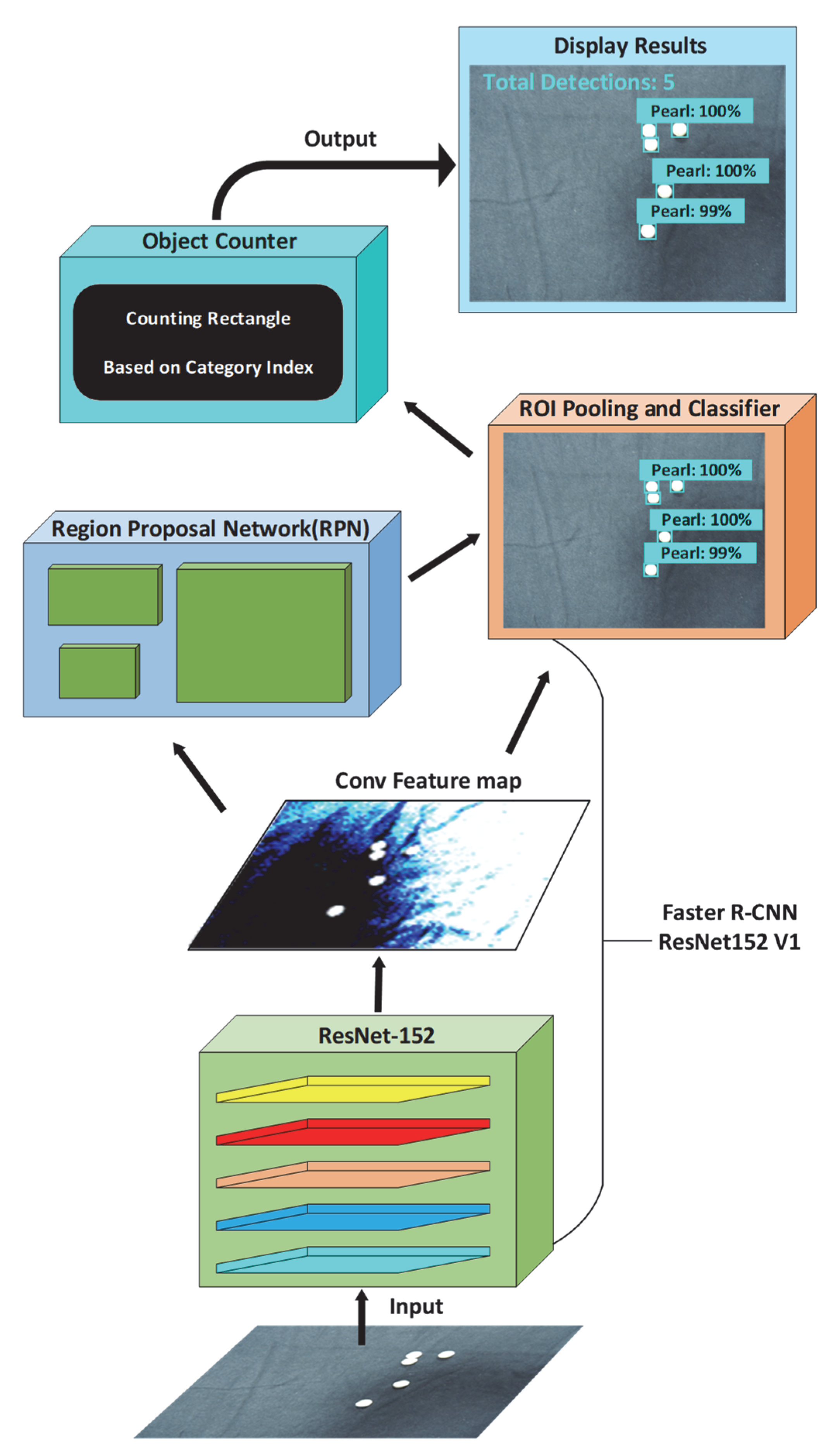
- Detector: Faster R-CNN ResNet152v1. A pearl image was first input to the convolutional backbone that can extract image features and output a feature map. ResNet152 was used as a substructure and greatly improves the effect of target detection. The region proposal network (RPN) was introduced to generate candidate regions, and the RoI pooling and classifier layer received both the optimized candidate boxes of RPN output and Conv feature map output. Finally, the classification and bounding box regression were predicted.
- (ii)
- Counter. As shown in Figure 5, the threshold was usually between 0.7 and 0.8. If the confidence value of detected people was below the threshold, the pearls were not counted. In this paper, the default threshold value of 0.8 was used for the sake of simplicity. Then, more bounding boxes of pearls were generated, and we found that pearl counting works better with more detected boxes and higher confidence values by a series of experiments.
3.3. Faster R-CNN ResNet152 as Detector
- Producing the fixed-size feature maps from non-uniform inputs,
- Finding a feature map obtained from a CNN after multiple convolutions and pooling layers
- Indicating the index and the proposal coordinates.
3.4. Counting Pearl
- (i)
- Obtain a binary pearl image. Load detected pearl image, greyscale, Gaussian blur, and Otsu’s threshold;
- (ii)
- Remove small noise. We find contours and then filter them by contour area filtering with cv2.contourArea and remove the noise by filling in the contour with cv2.drawContours;
- (iii)
- Find corners. The Shi-Tomasi Corner Detector that has already been implemented, as cv2.goodFeaturesToTrack is used for corner detection;
- (iv)
- Increase count until Max_Conf_Thresh = 1. The total number of these possible rectangles is obtained, and the interpreter can return the coordinates that are the edges of the image dimensions.
3.5. Evaluation Metrics
3.5.1. Intersection over Union, IoU
3.5.2. The Detection of Pearl Accuracy, Recall, Precision and mAP
3.5.3. Loss Function
3.5.4. Softmax
4. Experimental Results
4.1. Faster R-CNN with Object Counter Performance
4.2. The Visualization of Training
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ren, P.; Wang, L.; Fang, W.; Song, S.; Djahel, S. A novel squeeze YOLO-based real-time people counting approach. Int. J. Bio-Inspired Comput. 2020, 16, 94–101. [Google Scholar] [CrossRef]
- Sun, Y.; Li, Z.; He, H.; Guo, L.; Zhang, X.; Xin, Q. Counting trees in a subtropical mega city using the instance segmentation method. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102662. [Google Scholar] [CrossRef]
- Furuta, M.; Shimizu, K.; Maeta, T.; Miyashita, M.; Izunome, K.; Kubota, H. Noncontact evaluation for interface states by photocarrier counting. Jpn. J. Appl. Phys. 2018, 57, 031301. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhou, C.; Chang, F.; Kot, A.C. Multi-resolution attention convolutional neural network for crowd counting. Neurocomputing 2019, 329, 144–152. [Google Scholar] [CrossRef]
- Murthy, C.B.; Hashmi, M.F.; Keskar, A.G. Optimized MobileNet plus SSD: A real-time pedestrian detection on a low-end edge device. Int. J. Multimed. Inf. Retr. 2021, 10, 171–184. [Google Scholar] [CrossRef]
- Velumani, K. An automatic method based on daily in situ images and deep learning to date wheat heading stage. Field Crop. Res. 2020, 252, 107793. [Google Scholar] [CrossRef]
- Hu, X.; Li, H.; Li, X.; Wang, C. MobileNet-SSD MicroScope using adaptive error correction algorithm: Real-time detection of license plates on mobile devices. IET Intell. Transp. Syst. 2020, 14, 110–118. [Google Scholar] [CrossRef]
- Chen, L.; Lin, S.; Lu, X.; Cao, D.; Wu, H.; Guo, C.; Liu, C.; Wang, F.-Y. Deep Neural Network Based Vehicle and Pedestrian Detection for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3234–3246. [Google Scholar] [CrossRef]
- Han, A.; Zhang, Y.; Liu, Q.; Dong, Q.; Zhao, F.; Shen, X.; Liu, Y.; Yan, S.; Zhou, S. Application of refinements on faster-RCNN in automatic screening of diabetic foot wagner grades. Acta Med. Mediterr. 2020, 36, 661–665. [Google Scholar]
- Liu, S.; Ban, H.; Song, Y.; Zhang, M.; Yang, F. Method for Detecting Chinese Texts in Natural Scenes Based on Improved Faster R-CNN. Int. J. Pattern Recognit. Artif. Intell. 2020, 34, 2053002. [Google Scholar] [CrossRef]
- Gao, X.; Xu, J.; Luo, C.; Zhou, J.; Huang, P.; Deng, J. Detection of Lower Body for AGV Based on SSD Algorithm with ResNet. Sensors 2022, 22, 2008. [Google Scholar] [CrossRef]
- Chen, D.; Liang, M.; Jin, C.; Sun, Y.; Xu, D.; Lin, Y. Coronary Calcium Detection Based on Improved Deep Residual Network in Mimics. J. Med. Syst. 2019, 43, 119. [Google Scholar]
- Vy, N.; Duc, N.T. Single-image crowd counting: A comparative survey on deep learning-based approaches. Int. J. Multimed. Inf. Retr. 2020, 9, 63–80. [Google Scholar]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. UAV-YOLO Small Object Detection on Unmanned Aerial Vehicle Perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [PubMed]
- Abdullah, S.S.; Rajasekaran, M.P. Automatic detection and classification of knee osteoarthritis using deep learning approach. Radiol. Med. 2022, 127, 398–406. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Yang, G.; Sun, L.; Zhou, C.; Zhou, X.; Li, Q.; Bi, M.; Guo, J. Shrimp egg counting with fully convolutional regression network and generative adversarial network. Aquac. Eng. 2021, 94, 102175. [Google Scholar] [CrossRef]
- Rahmaniar, W.; Wang, W.J.; Chiu, C.-W.E.; Hakim, N.L.L. Real-time bi-directional people counting using an RGB-D camera. Sens. Rev. 2021, 41, 341–349. [Google Scholar] [CrossRef]
- Chen, B.; Miao, X. Distribution Line Pole Detection and Counting Based on YOLO Using UAV Inspection Line Video. J. Electr. Eng. Technol. 2019, 77, 125, reprinted in J. Electr. Eng. Technol. 2020, 15, 997–997. [Google Scholar]
- Anuar, M.M.; Halin, A.A.; Perumal, T.; Kalantar, B. Aerial Imagery Paddy Seedlings Inspection Using Deep Learning. Remote Sens. 2022, 14, 274. [Google Scholar] [CrossRef]
- Zheng, X.; Li, F.; Lin, B.; Xie, D.; Liu, Y.; Jiang, K.; Gong, X.; Jiang, H.; Peng, R.; Duan, X. A Two-Stage Method to Detect the Sex Ratio of Hemp Ducks Based on Object Detection and Classification Networks. Animals 2022, 12, 1177. [Google Scholar] [CrossRef] [PubMed]
- Yin, H.; Chen, C.; Hao, C.; Huang, B. A Vision-based inventory method for stacked goods in stereoscopic warehouse. Neural Comput. Appl. 2022, 7, 1–18. [Google Scholar] [CrossRef]
- Veeramani, B.; Raymond, J.W.; Chanda, P. DeepSort: Deep convolutional networks for sorting haploid maize seeds. BMC Bioinform. 2018, 19, 289. [Google Scholar] [CrossRef] [PubMed]
- Mu, L.; Zhao, H.; Li, Y.; Liu, X.; Qiu, J.; Sun, C. Traffic Flow Statistics Method Based on Deep Learning and Multi-Feature Fusion. Comput. Model. Eng. Sci. 2021, 129, 465–483. [Google Scholar] [CrossRef]
- Kirby, E.; Zenha, R.; Jamone, L. Comparing Single Touch to Dynamic Exploratory Procedures for Robotic Tactile Object Recognition. IEEE Robot. Autom. Lett. 2022, 7, 4252–4258. [Google Scholar] [CrossRef]
- Kosuge, A.; Suehiro, S.; Hamada, M.; Kuroda, T. mmWave-YOLO: A mmWave Imaging Radar-Based Real-Time Multiclass Object Recognition System for ADAS Applications. IEEE Trans. Instrum. Meas. 2022, 71, 1–10. [Google Scholar] [CrossRef]
- Huang, X.; He, P.; Rangarajan, A.; Ranka, S. Machine-Learning-Based Real-Time Multi-Camera Vehicle Tracking and Travel-Time Estimation. J. Imaging 2022, 8, 101. [Google Scholar] [CrossRef]
- Premachandra, C.; Tamaki, M. A Hybrid Camera System for High-Resolutionization of Target Objects in Omnidirectional Images. IEEE Sens. J. 2021, 21, 10752–10760. [Google Scholar] [CrossRef]
- Mittal, P.; Sharma, A.; Singh, R.; Sangaiah, A.K. On the performance evaluation of object classification models in low altitude aerial data. J. Supercomput. 2022, 78, 1305–1336. [Google Scholar] [CrossRef]
- Yang, Z.; Bai, Y.-M.; Sun, L.-D.; Huang, K.-X.; Liu, J.; Ruan, D.; Li, J.-L. SP-ILC: Concurrent Single-Pixel Imaging, Object Location, and Classification by Deep Learning. Photonics 2021, 8, 400. [Google Scholar] [CrossRef]
- Wang, H.; Li, D.; Song, Y.; Gao, Q.; Wang, Z.; Liu, C. Single-Shot Object Detection with Split and Combine Blocks. Appl. Sci. 2020, 10, 6382. [Google Scholar] [CrossRef]
- Moussa, M.M.; Shoitan, R.; Abdallah, M.S. Efficient common objects localization based on deep hybrid Siamese network. J. Intell. Fuzzy Syst. 2021, 41, 3499–3508. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, X.; Yan, J.; Qiu, X.; Yao, X.; Tian, Y.; Zhu, Y.; Cao, W. A wheat spike detection method in uav images based on improved yolov5. Remote Sens. 2021, 13, 3095. [Google Scholar] [CrossRef]
- Jia, W.; Xu, S.; Liang, Z.; Zhao, Y.; Min, H.; Li, S.; Yu, Y. Real-time automatic helmet detection of motorcyclists in urban traffic using improved YOLOv5 detector. IET Image Process. 2021, 2021, 3623–3637. [Google Scholar]
- Zhan, J.; Hu, Y.; Cai, W.; Zhou, G.; Li, L. PDAM-STPNNet: A Small Target Detection Approach for Wildland Fire Smoke through Remote Sensing Images. Symmetry 2021, 13, 2260. [Google Scholar] [CrossRef]
- Yang, D.; Bi, C.; Mao, L.; Zhang, R. Contour feature fusion SSD Algorithm. In Proceedings of the 38th Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 3423–3426. [Google Scholar]
- Zhou, S.; Qiu, J. Enhanced SSD with interactive multi-scale attention features for object detection. Multimed. Tools Appl. 2021, 80, 11539–11556. [Google Scholar] [CrossRef]
- Wu, B.; Iandola, F.; Jin, P.H.; Keutzer, K. SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2016; pp. 446–454. [Google Scholar]
- Hu, X. Football Player Posture Detection Method Combining Foreground Detection and Neural Networks. Sci. Program. 2021, 2021, 4102294. [Google Scholar] [CrossRef]
- Kuwada, C.; Ariji, Y.; Fukuda, M.; Kise, Y.; Fujita, H.; Katsumata, A.; Ariji, E. Deep learning systems for detecting and classifying the presence of impacted supernumerary teeth in the maxillary incisor region on panoramic radiographs. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 2020, 130, 464–469. [Google Scholar] [CrossRef]
- Liu, Z.; Lyu, Y.; Wang, L.; Han, Z. Detection Approach Based on an Improved Faster RCNN for Brace Sleeve Screws in High-Speed Railways. IEEE Trans. Instrum. Meas. 2020, 69, 4395–4403. [Google Scholar] [CrossRef]
- Xie, H.; Chen, Y.; Shin, H. Context-aware pedestrian detection especially for small-sized instances with Deconvolution Integrated Faster RCNN (DIF R-CNN). Appl. Intell. 2019, 49, 1200–1211. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Wu, M.; Yue, H.; Wang, J.; Huang, Y.; Liu, M.; Jiang, Y.; Ke, C.; Zeng, C. Object detection based on RGC mask R-CNN. IET Image Process. 2020, 14, 1502–1508. [Google Scholar] [CrossRef]
- Sun, C.-Y.; Hong, X.-J.; Shi, S.; Shen, Z.-Y.; Zhang, H.-D.; Zhou, L.-X. Cascade Faster R-CNN Detection for Vulnerable Plaques in OCT Images. IEEE Access 2021, 9, 24697–24704. [Google Scholar] [CrossRef]
- Zhong, L.; Li, J.; Zhou, F.; Bao, X.; Xing, W.; Han, Z.; Luo, J. Integration between Cascade Region-Based Convolutional Neural Network and Bi-Directional Feature Pyramid Network for Live Object Tracking and Detection. Traitement Signal 2021, 38, 1253–1257. [Google Scholar] [CrossRef]
- Ramalingam, B.; Tun, T.; Mohan, R.E.; Gomez, B.F.; Cheng, R.; Balakrishnan, S.; Rayaguru, M.M.; Hayat, A.A. AI Enabled IoRT Framework for Rodent Activity Monitoring in a False Ceiling Environment. Sensors 2021, 21, 5326. [Google Scholar] [CrossRef]
- Jiao, H. Intelligent Research Based on Deep Learning Recognition Method in Vehicle-Road Cooperative Information Interaction System. Comput. Intell. Neurosci. 2022, 2022, 4921211. [Google Scholar] [CrossRef]
- Huang, Z.; Hu, Q.; Mei, Q.; Yang, C.; Wu, Z. Identity recognition on waterways: A novel ship information tracking method based on multimodal data. J. Navig. 2021, 74, 1336–1352. [Google Scholar] [CrossRef]
- Xu, B. Livestock classification and counting in quadcopter aerial images using Mask R-CNN. Int. J. Remote Sens. 2020, 2020, 8121–8142. [Google Scholar] [CrossRef]
- Albuquerque, P.L.F.; Garcia, V.; Oliveira, A.D.S., Jr.; Lewandowski, T.; Detweiler, C.; Goncalves, A.B.; Costa, C.S.; Naka, M.H.; Pistori, H. Automatic live fingerlings counting using computer vision. Comput. Electron. Agric. 2019, 167, 105015. [Google Scholar] [CrossRef]
- Vasconez, J.P.; Delpiano, J.; Vougioukas, S.; Cheein, F.A. Comparison of convolutional neural networks in fruit detection and counting: A comprehensive evaluation. Comput. Electron. Agric. 2020, 173, 105348. [Google Scholar] [CrossRef]
- Chen, C.; Liu, B.; Wan, S.; Qiao, P.; Pei, Q. An Edge Traffic Flow Detection Scheme Based on Deep Learning in an Intelligent Transportation System. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1840–1852. [Google Scholar] [CrossRef]
- Jiang, Z.; Shi, B.; Du, F.; Xue, B.; Lei, M.; Yang, Z.; Sun, H. Intelligent Plant Cultivation Robot Based on Key Marker Algorithm Using Visual and Laser Sensors. IEEE Sens. J. 2022, 22, 879–889. [Google Scholar] [CrossRef]
- Yu, X.; Wang, Y.; An, D.; Wei, Y. Counting method for cultured fishes based on multi-modules and attention mechanism. Aquac. Eng. 2022, 96, 102215. [Google Scholar] [CrossRef]
- Syazwani, R.W.N.; Asraf, M.H.; Amin, M.A.M.S.; Dalil, K.A.N. Automated image identification, detection and fruit counting of top-view pineapple crown using machine learning. Alex. Eng. J. 2022, 61, 1265–1276. [Google Scholar] [CrossRef]
- Hansen, M.F.; Oparaeke, A.; Gallagher, R.; Karimi, A.; Tariq, F.; Smith, M.L. Towards Machine Vision for Insect Welfare Monitoring and Behavioural Insights. Front. Vet. Sci. 2022, 9, 835529. [Google Scholar] [CrossRef]
- Mahmud, M.S.; Zahid, A.; Das, A.K.; Muzammil, M.; Khan, M.U. A systematic literature review on deep learning applications for precision cattle farming. Comput. Electron. Agric. 2021, 187, 106313. [Google Scholar] [CrossRef]
- Mu, Y.; Chen, T.-S.; Ninomiya, S.; Guo, W. Intact Detection of Highly Occluded Immature Tomatoes on Plants Using Deep Learning Techniques. Sensors 2020, 20, 2984. [Google Scholar] [CrossRef]
- Kouyoumdjieva, S.T.; Danielis, P.; Karlsson, G. Survey of Non-Image-Based Approaches for Counting People. IEEE Commun. Surv. Tutor. 2020, 22, 1305–1336. [Google Scholar] [CrossRef]
- Durve, M.; Bonaccorso, F.; Montessori, A.; Lauricella, M.; Tiribocchi, A.; Succi, S. Tracking droplets in soft granular flows with deep learning techniques. Eur. Phys. J. Plus 2021, 136, 864. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, Y.-T.; Kuo, P.; Guo, J.-I. Automatic Industry PCB Board DIP Process Defect Detection System Based on Deep Ensemble Self-Adaption Method. IEEE Trans. Compon. Packag. Manuf. Technol. 2021, 11, 312–323. [Google Scholar] [CrossRef]
- Huang, K.; Li, S.; Deng, W.; Yu, Z.; Ma, L. Structure inference of networked system with the synergy of deep residual network and fully connected layer network. Neural Netw. 2022, 145, 288–299. [Google Scholar] [CrossRef] [PubMed]
- Urban, C.J.; Bauer, D.J. A Deep Learning Algorithm for High-Dimensional Exploratory Item Factor Analysis. Psychometrika 2021, 86, 1–29. [Google Scholar] [CrossRef] [PubMed]
- Chang, Y.-B.; Tsai, C.; Lin, C.-H.; Chen, P. Real-Time Semantic Segmentation with Dual Encoder and Self-Attention Mechanism for Autonomous Driving. Sensors 2021, 21, 8072. [Google Scholar] [CrossRef] [PubMed]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Num | Authors | Organization | Fundamentals | Technologies | Application | Year |
|---|---|---|---|---|---|---|
| 1 | Xiaoning Yu [55] | China Agricultural University | Deep learning | Multi-modules and attention mechanism | Aquaculture | 2022 |
| 2 | Wan Nurazwin R. [56] | Shah Alam Selangor | Image recognition | Machine learning classifiers | Pineapple crown | 2021 |
| 3 | Mark F. Hansen [57] | UWE Bristol | Machine vision | Black Soldier Fly (BSF) | insect farming | 2022 |
| 4 | Md Sultan Mahmud [58] | The Pennsylvania State University | Deep learning | LSTM + Mask RCNN | Cattle agriculture | 2021 |
| 5 | J.P. Vasconz [52] | Universidad Técnica Federico Santa María | CNN | Faster-RCNN with Inception V2 | Fruit counting | 2020 |
| 6 | Yue Mu [59] | Nanjing Agricultural University | Deep learning | R-CNN with ResNet101 | Tomato counting | 2020 |
| 7 | Sylvia T. Kouyoumdjieva [60] | KTH Royal Institute of Technology | No-image recognition | RSSI + CSI | People counting | 2020 |
| 8 | Mihir Durve [61] | Fondazione Istituto Italiano di Tecnologia | Deep learning | YOLO + DeepSORT | Track moving droplets | 2021 |
| Image Set | Amount of Images | Amount of Pearls | Image Conditions | |
|---|---|---|---|---|
| Train image set | 2700 | 13,850 | Natural light images | Artificial light images |
| 1350 | 1350 | |||
| Test image set | 300 | 1563 | Natural light images | Artificial light images |
| 150 | 150 | |||
| Model | mAP @0.5IoU | mAP @0.75IoU | Recall/AR @100(medium) | Recall/AR @100(small) | Model Loading Time | Speed Inference Time with Counter | Size |
|---|---|---|---|---|---|---|---|
| Faster R-CNN ResNet152 v1 (ours) | 1 | 0.9883 | 0.95 | 0.8643 | 5.478 s | 15.8 ms | 15 MB |
| Faster R-CNN ResNet101 v1 | 1 | 0.9642 | 0.9325 | 0.8571 | 5.625 s | 14.9 ms | 11.1 MB |
| Faster R-CNN ResNet50 v1 | 1 | 0.9542 | 0.9312 | 0.85 | 4.306 s | 15.8 ms | 7.2 MB |
| Faster R-CNN Inception ResNet v2 | 1 | 0.9118 | 0.925 | 0.7214 | 7.869 s | 16.0 ms | 18.1 MB |
| SSD MobileNet v1 | 0.9978 | 0.9838 | 0.94 | 0.8143 | 4.855 s | 14.5 ms | 7.4 MB |
| SSD MobileNet v2 | 1 | 0.9942 | 0.9375 | 0.8571 | 5.102 s | 15.1 ms | 9.6 MB |
| SSD ResNet50 v1 | 1 | 0.9830 | 0.925 | 0.85 | 4.361 s | 13.4 ms | 10.2 MB |
| SSD ResNet101 v1 | 0.9841 | 0.9841 | 0.9 | 0.8143 | 5.679 s | 15.2 ms | 15.8 MB |
| SSD ResNet 152 v1 | 0.9862 | 0.9862 | 0.8875 | 0.8286 | 6.471 s | 15.5 ms | 21.3 MB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, M.; Dong, X.; Li, J.; Yu, G.; Deng, R.; Pan, X. PDC: Pearl Detection with a Counter Based on Deep Learning. Sensors 2022, 22, 7026. https://doi.org/10.3390/s22187026
Hou M, Dong X, Li J, Yu G, Deng R, Pan X. PDC: Pearl Detection with a Counter Based on Deep Learning. Sensors. 2022; 22(18):7026. https://doi.org/10.3390/s22187026
Chicago/Turabian StyleHou, Mingxin, Xuehu Dong, Jun Li, Guoyan Yu, Ruoling Deng, and Xinxiang Pan. 2022. "PDC: Pearl Detection with a Counter Based on Deep Learning" Sensors 22, no. 18: 7026. https://doi.org/10.3390/s22187026