1. Introduction
Gamma ray or gamma radiation is an electromagnetic wave generated when an atomic nucleus in an excited energy state moves to a lower state or ground state or when a particle is annihilated [
1]. When a human body or living organism is irradiated with gamma rays for a long time, cells might be destroyed and DNA chains might be broken. Therefore, it is designated as a Group 1 carcinogen by the World Health Organization’s (WHO) International Agency for Research on Cancer (IARC) [
2].
High-pressure ion chambers (HPICs) are gas-filled detectors which respond to gamma energies and have been deployed for environmental and area monitoring. Gamma radiation causes a current to flow in an ion chamber detector. The magnitude of this electric current is proportional to the exposure rate [
3,
4].
In view of the threat of gamma rays to human health, various studies have been conducted in the literature [
5,
6]. Many previous efforts were focused on the health effects of gamma rays on artificial nuclides, but, more recently, researchers have started to investigate the health effects of radon, which is a representative natural gamma ray [
7]. As gamma rays are dangerous in both artificial and natural materials, spatial gamma dose rates are analyzed in various places [
8,
9]. For example, autonomous vehicles are equipped with devices that enable them to observe their environments and make decisions in real time [
10].
Previous studies have revealed that there exists a certain correlation between spatial gamma dose rate and rainfall data [
11,
12]. Specifically, preliminary results show that the correlation is highest with a time scale of one day and decreases as the time scale increases to one month or one year.
Considering such a correlation between the gamma exposure rate and the weather data, and if we can predict the change in the gamma exposure rate with the weather data, it could help us to understand and determine the actual cause of the increase in the gamma exposure rate.
In this study, we collected various weather and radiation data from the automatic weather system (AWS) and the environmental radiation monitoring system (ERMS) during a specific period and trained and tested two time-series learning algorithms—namely, long short-term memory (LSTM) and light gradient boosting machine (LightGBM)—with two preprocessing methods, namely, standardization and normalization. The experimental results illustrate that standardization is superior to normalization for data preprocessing with smaller deviations, and LightGBM outperforms LSTM in terms of prediction accuracy and running time. The prediction capability of LightGBM makes it possible to determine whether the increase in the gamma exposure rate is caused by a change in the weather or an actual gamma ray from radioactive materials.
2. Experimental Dataset
To support our research, we collected weather data from the automatic weather system (AWS) and radiation data from the high-pressure ion chamber (HPIC) of the environmental radiation monitoring system (ERMS) located in Uljin-gun, Korea. As the correlation between the weather observation data and gamma exposure rate decreases as the year progresses, we focused on the weather and radiation measurements during a period from 0:00 on 1 July 2020 to 0:00 on 1 November 2020, during which the weather had undergone severe changes. Specifically, during this period of four months, we acquired the 5-min average of gamma exposure rates, totaling 35,424 data points, and the 5-min average of weather measurements, including ground temperature, ground humidity, rainfall, atmospheric pressure, temperature at a 10 m tower, wind direction at a 10 m tower, wind speed at a 10 m tower, maximum wind speed at a 10 m tower, temperature at a 58 m tower, wind direction at a 58 m tower, wind speed at a 58 m tower, and maximum wind speed at a 58 m tower, as shown in
Table 1, totalling 425,052 data points (35,421 × 12).
3. Proposed Research Methods
3.1. Data Preprocessing
There were three missing 5-min averages of meteorological measurements. For the continuity of the dataset, these missing measurements were filled in with the same value as the preceding 5-min average. Furthermore, to unify various types of data in different engineering units, we employed two preprocessing methods, namely, normalization and standardization, and compared their effects on the performance.
Min–max Scaling was used for normalization, which adjusts the data so that all values are between 0 and 1. This can be obtained by the following formula:
where
is the maximum value of the data, and
is the minimum value of the data.
- 2.
Standardization
Standardization is the adjustment of data so that it has the properties of a normal distribution (
,
). This can be obtained by the following formula:
where
is the mean value of all data, and
is the standard deviation of all data.
- 3.
Data split
The dataset was divided into three parts: 80% of the total data was used for model training, 10% as a validation set for model optimization, and 10% as a test set to test the prediction results of the model.
3.2. Learning Algorithms
Considering the time-serial nature of the weather and radiation dataset, we chose long short-term memory (LSTM), a variant of a recurrent neural network (RNN), as a model for prediction. Since there exists a certain level of variation in such time-series data collected from real environments, we investigated the application of an ensemble learning framework, light gradient boosting machine (LightGBM). Both LSTM and LightGBM were trained with the data from the AWS and ERMS.
- 4.
LSTM
The long short-term memory (LSTM) network is an improved model of a recurrent neural network (RNN) that specifically addresses the long-term dependency problem of an RNN. The LSTM network is intended to classify time-series data or learn long-term dependencies between data. Generally, the LSTM network is divided into an input layer and an LSTM layer. The input layer receives time-series data, and the LSTM layer learns long-term dependencies between time-series data [
13,
14].
- 5.
LightGBM
Gradient boosting machine (GBM) combines weak learners to form strong learners, using gradient descent to assign weights. The decision tree used for GBM is expanded in a level-wise manner, and multiple decision trees are combined to predict the result [
15].
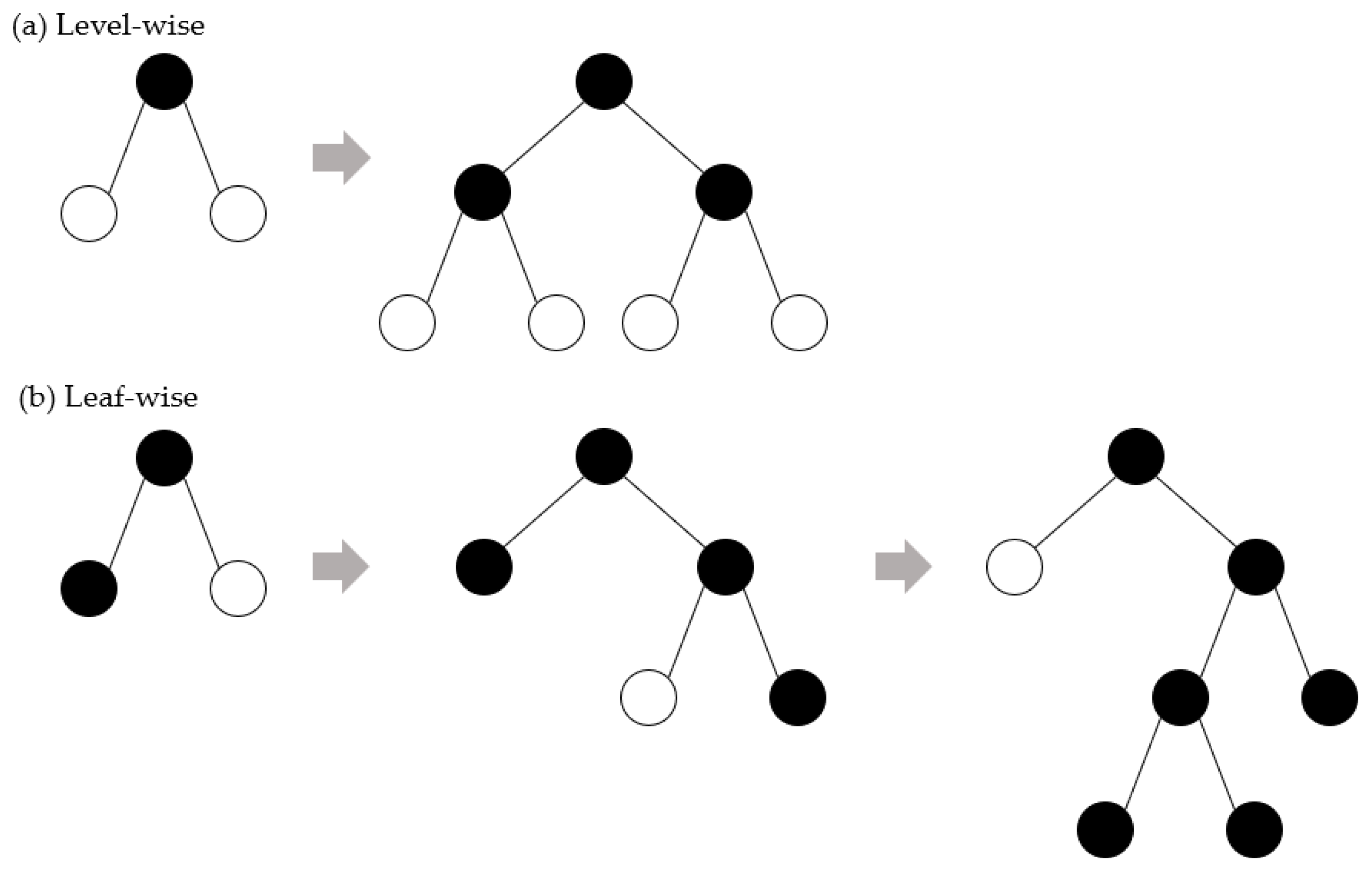
Although GBM has shown good learning results, it suffers from a problem of low efficiency in processing a large amount of data. Light gradient boosting machine (LightGBM) is a model belonging to a boosting series among ensemble learning models. Boosting is an algorithm that creates several weak models using gradient descent, trains them sequentially, and builds a model that is weighted according to the performance of the previous model. Unlike other models, LightGBM uses leaf-wise partitioning to perform learning in a way that reduces the loss in model training more than the level-wise partitioning method and has the advantage of taking less training time. The difference between leaf-wise and level-wise is illustrated in
Figure 1 [
16].
4. Implementation and Performance Evaluation
4.1. Data Analysis
We implemented the chosen learning methods using Python version 3.9.7, TensorFlow version 2.7.0, and LightGBM version 3.3.2. The technical solution integrates various components such as data preprocessing, analysis, and learning, and is executed on a Jupyter notebook with Anaconda 3 2021.11. The hardware specifications used in the experiments are provided in
Table 2.
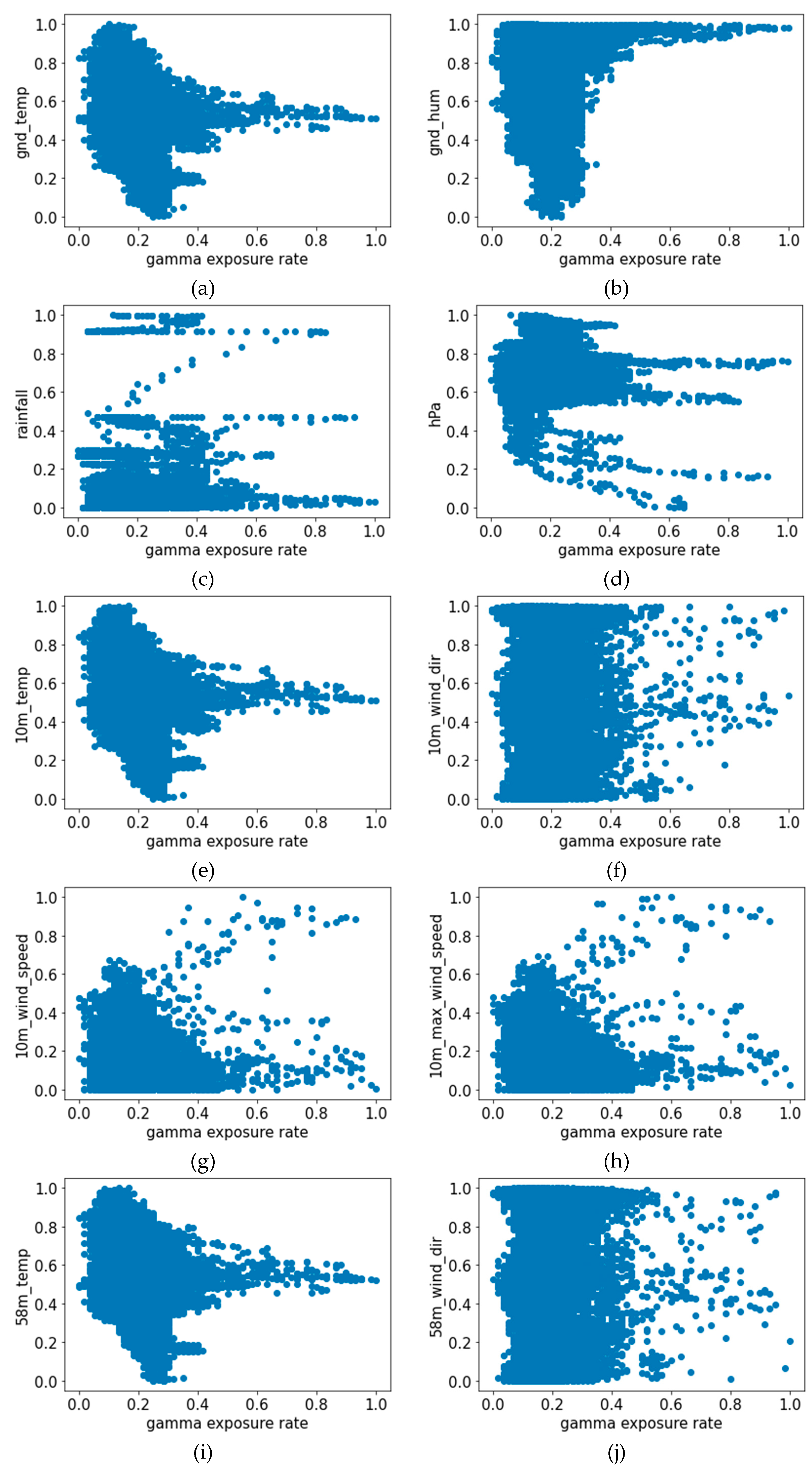
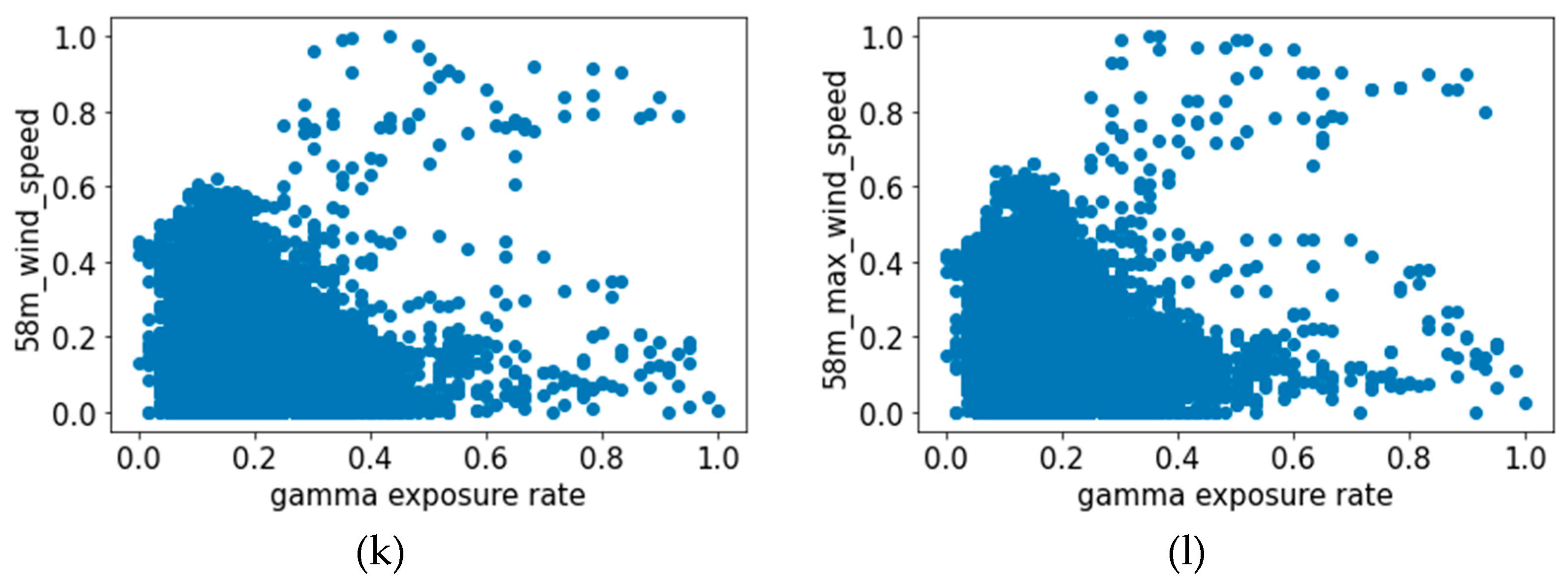
Since our goal was to predict the gamma exposure rate through the weather data, we needed to investigate the correlation between the weather data and the gamma exposure rate. Since the correlation between rainfall and gamma exposure is known, we conducted data analysis to find out if there existed significant correlations in other weather data. Towards this goal, we first performed a visual examination of the data by creating the scatter plot of the measurements in
Figure 2, which exhibits certain patterns between the variables. We further computed the correlation coefficient and the
p-value as shown in
Table 3. Note that for the correlation coefficient, the closer to 1, the higher the positive correlation, and the closer to −1, the higher the negative correlation. If it is 0, there is no correlation at all [
17]. If the
p-value is less than 0.05, it indicates that there is a significant relationship between the control and response variables [
18].
The correlation analysis results show that there does not exist a high correlatioin between the weather data and the gamma exposure rate, and some variables show a low correlation coefficient of less than 0.1. We further computed the p-value to check if the data were meaningful as the learning data, and it was confirmed that all were less than 0.05. Note that the data were preprocessed by two different methods, namely, standardization and normalization, before training the models.
4.2. Learning Results
4.2.1. LSTM-Based Learning Model
We designed an LSTM model with a hidden layer of 16 nodes. There was no significant change in the learning result even when the batch size was larger than 16. The number of trainings was 200 and the batch size was set to 16. We used mean square error (MSE) as the loss function, Adam as the optimizer, and sigmoid as the activation function. When ReLU is chosen as the activation function, GPU learning based on a CUDA deep neural network (cuDNN) is not available, and the learning result does not change significantly from that of sigmoid. EarlyStopping was set to prevent overfitting and learning was stopped when the loss function did not improve more than five times. For the comparison of the learning results, we considered mean square error (MSE) and root mean square error (RMSE) as the metrics, which can be computed as follows:
where
is the estimate value of the model, and
is the target value of the model.
As shown in
Table 4, the LSTM learning model preprocessed with standardization achieves a RMSE of 0.7729, and the LSTM learning model preprocessed with normalization achieves a RMSE of 0.0433. These results indicate that normalization preprocessing seems to be more advantageous in reducing the learning errors.
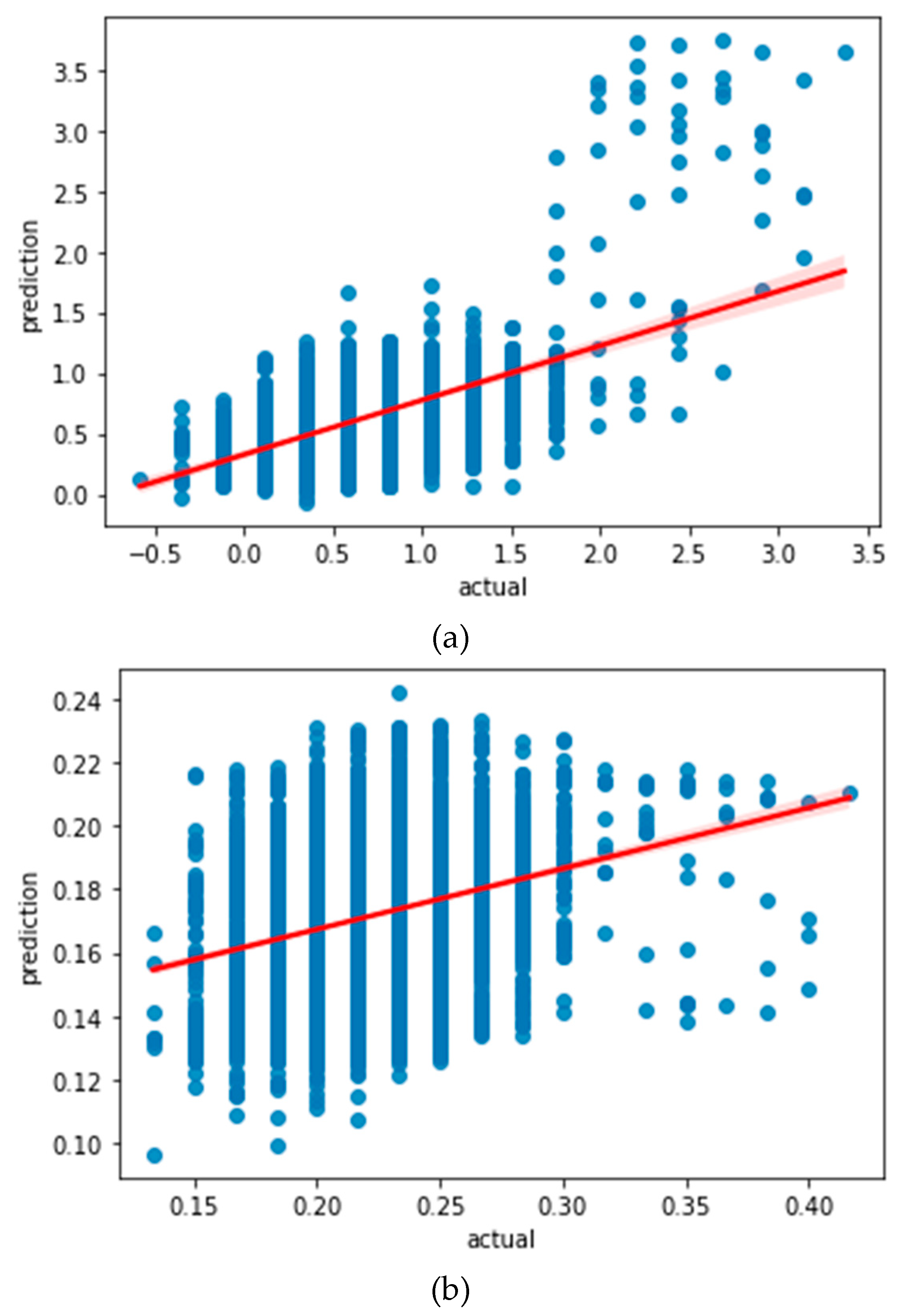
To understand how well the learned model would behave in prediction, we plotted the regression curve between the learned values and the actual values for each model, as shown in
Figure 3. These regression curves show that there is a notable discrepancy in both of the learning models. However, considering that LSTM with standardization preprocessing yields a larger slope of the regression curve, it is our conjecture that the standardization preprocessing method would help LSTM achieve a better prediction accuracy.
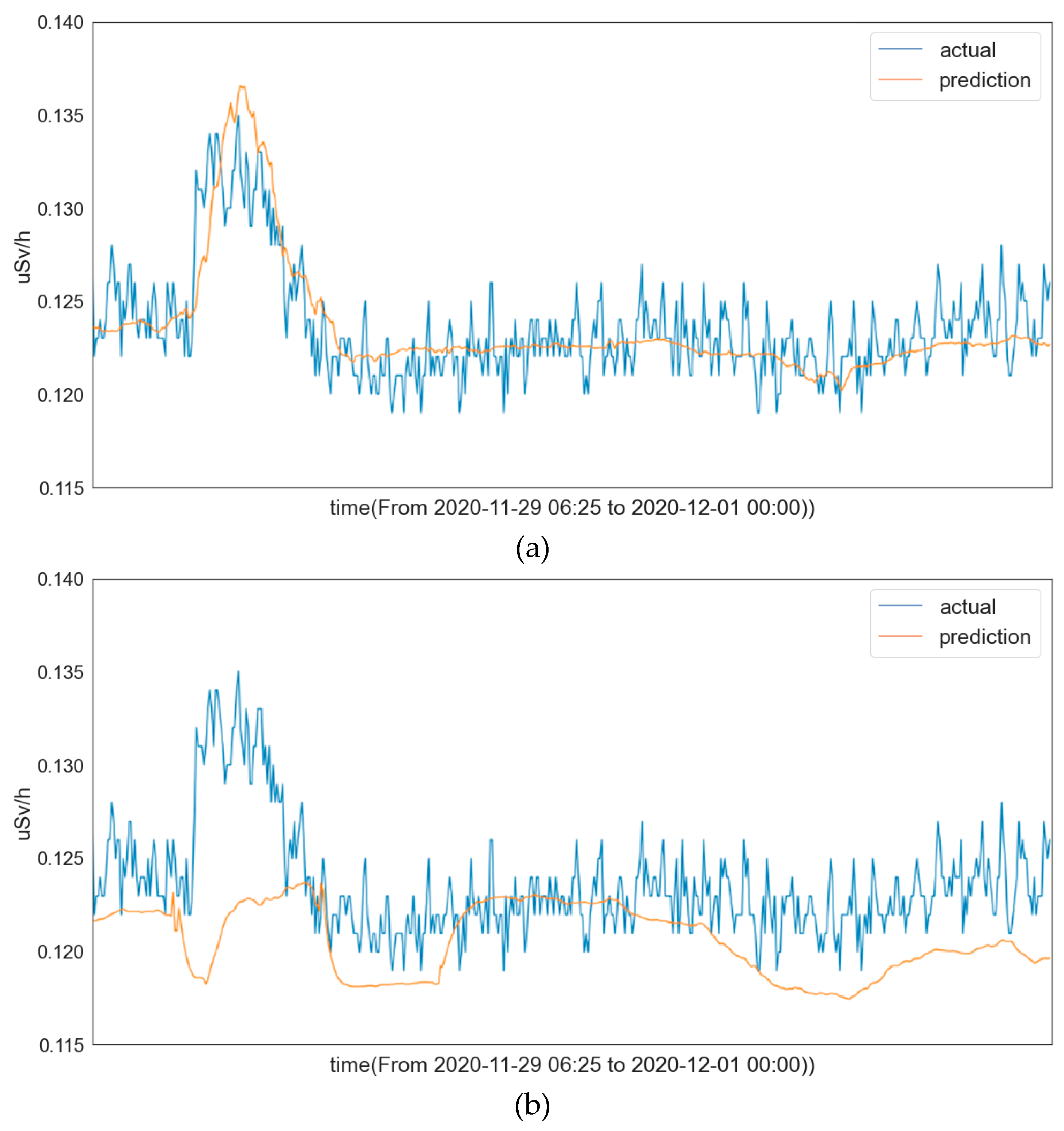
We tested the trained LSTM model with different preprocessing methods and plotted the corresponding prediction curves in
Figure 4. From these prediction curves, we observe that the LSTM model with standardization preprocessing achieves a satisfactory prediction performance, while the LSTM model with normalization preprocessing does not perform well. This is consistent with our conjecture. These results also indicate that the preprocessing method has a significant impact on the prediction performance.
4.2.2. LightGBM-Based Learning Model
We designed a LightGBM model in which the learning rate is set to 0.01, max depth is set to 16, boosting is based on GBDT, the number of leaves is set to 144, objective function uses regression, feature fraction is set to 0.9, bagging fraction is set to 0.7, bagging frequency is set to 5, seed is set to 2018, and the metric uses the area under the curve (AUC). To prevent overfitting, the training process was stopped early when the optimal AUC was calculated over 1000 rounds. However, if the learning process ends before reaching 1000 rounds, it does not yield an accurate learning result. We also observe that the changes in other parameters do not significantly affect the learning results. Similarly, to compare the learning results, we considered mean square error (MSE) and root mean square error (RMSE) as the metrics.
As shown in
Table 5, the LightGBM learning model preprocessed by standardization achieves a RMSE of 0.38441478, and the LightGBM learning model preprocessed by normalization achieves a RMSE of 0.0337. These results indicate that normalization preprocessing seems to be more advantageous in reducing the learning errors. Moreover, we plotted the regression curves of the LightGBM model with different preprocessing methods in
Figure 5. We observe that both of the curves align the learned and actual values well; hence, it is our conjecture that the LightGBM model with both of the preprocessing methods would perform well in prediction.
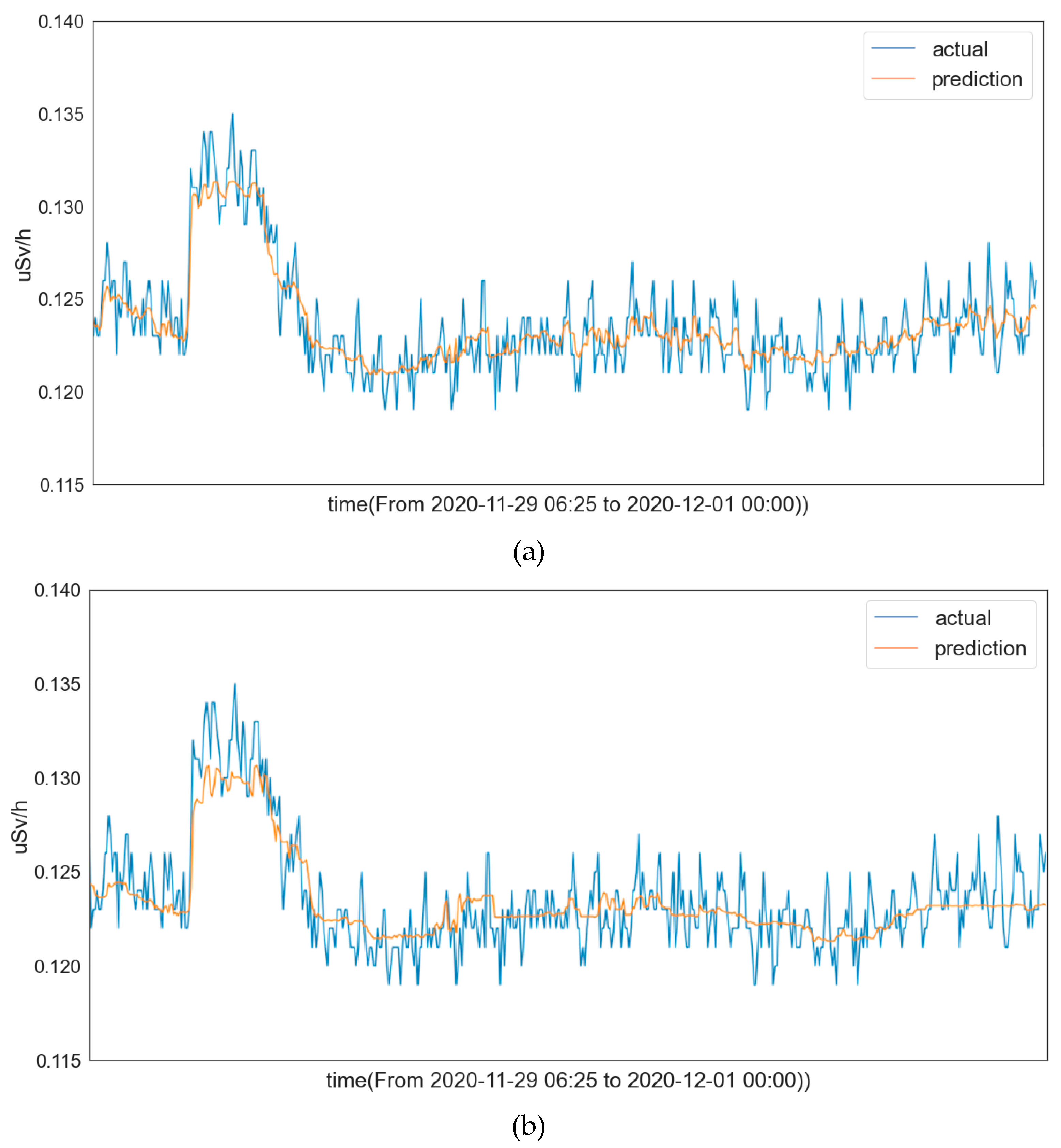
We tested the LightGBM model with different preprocessing methods and plotted their corresponding prediction curves in
Figure 6, which shows that the predicted values of the LightGBM model with both of the preprocessing methods follow the trend closely with high accuracy compared with the ground truths.
4.3. Comparison of Learning Time
We measured the learning time for each model as shown in
Table 6. We observe that the LightGBM learning algorithm learns significantly faster than the LSTM learning algorithm and consumes far fewer system resources.
4.4. Shapley Value of the LightGBM Learning Model
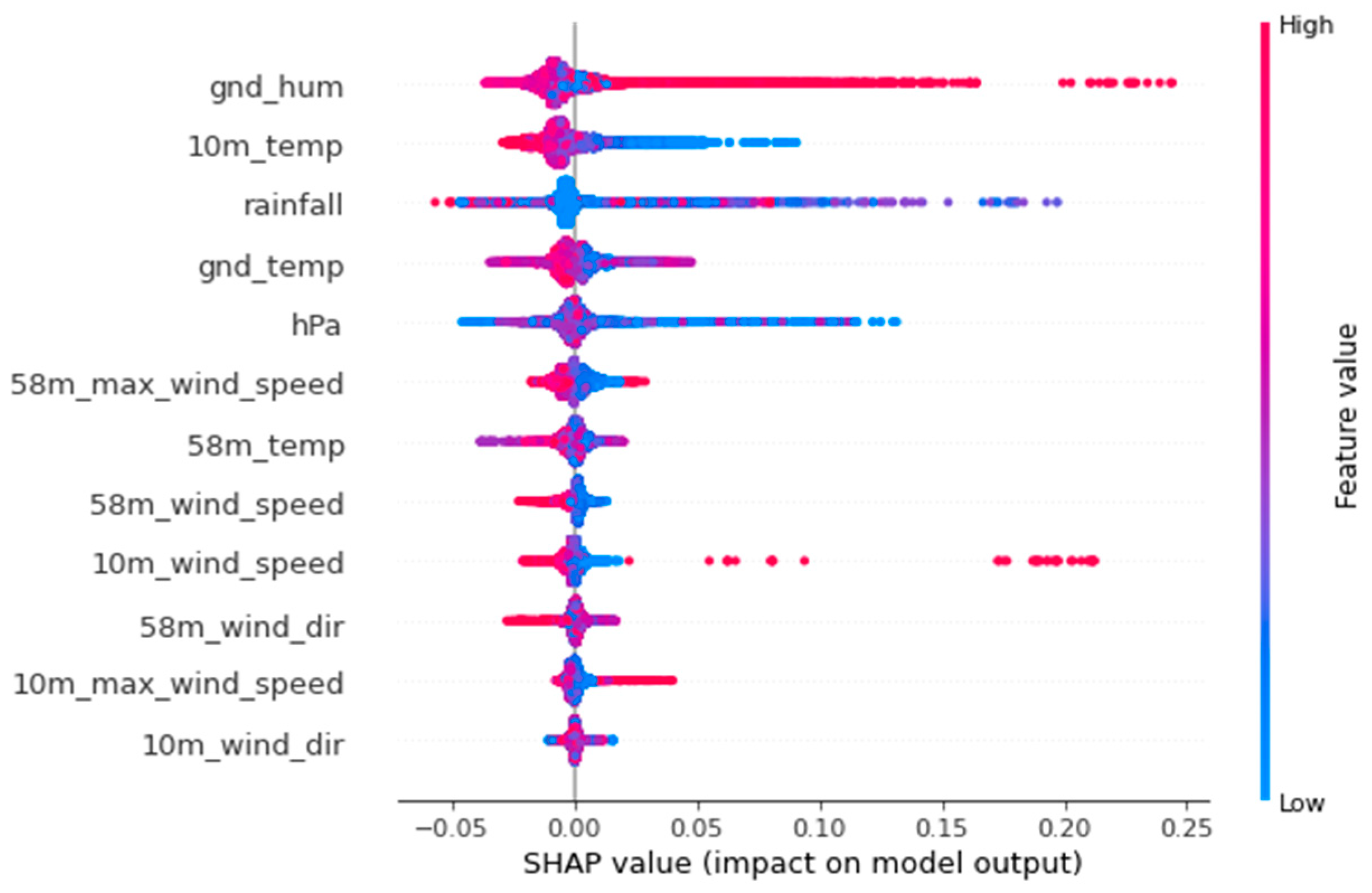
We conducted further analysis to understand what role these features play in the prediction process. Based on game theory, we computed the contribution of each feature to the score using SHAP (Shapley value) [
19], as shown in
Figure 7. These results show that ground humidity, 10 m temperature, and rainfall have the largest effects, and the other features also contribute to the prediction in some degree.
4.5. Gamma Exposure Rate Prediction
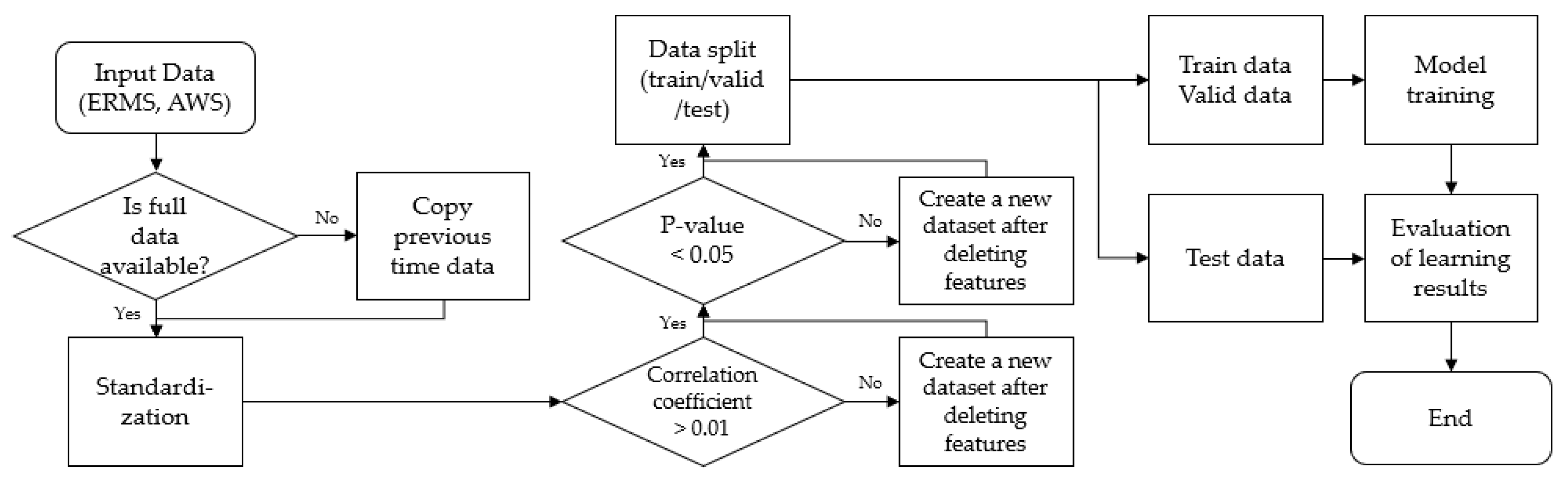
Combining our research, we can perform the gamma exposure rate prediction, given the gamma exposure rate and weather data. If there is a missing data item, we copy the data item from its preceding time step. The entire dataset is standardized. If there are weather data features whose absolute value of the correlation coefficient is less than 0.01, they are removed, and a new dataset is created. If there are weather data features with p-value greater than 0.05 in the new dataset, they are also removed to form a new dataset.
The resulting dataset is divided into training data, validation data, and test data. Then, the model is trained using the training data and the performance of the trained model is evaluated using the validation data. The above process is repeated when new data arrives. The flowchart of this prediction process is provided in
Figure 8.
5. Discussion and Conclusions
In this work, we hypothesized that there exists a certain relationship between the gamma exposure rate and weather data, analyzed the correlation between them, and proposed two machine learning models, LSTM and LightGBM, to predict the gamma exposure rate using various weather data.
In fact, previous studies have shown that there exists a high correlation between the gamma exposure rate and rainfall data. Our study confirms that other environmental parameters such as humidity and temperature also have a significant effect.
Data preprocessing is an important step to get the data ready for model training. We investigated two methods for data preprocessing, i.e., normalization and standardization. Our study shows that if normalization is used for preprocessing data with small deviations, it tends to converge to the average value. Standardization preprocessing leads to larger learning errors but yields better learning results. Standardization is considered more suitable for preprocessing data with small deviations.
The execution time measured in the experiments shows that LightGBM runs much faster in training and consumes far fewer system resources than LSTM. It seems that real-time analysis and prediction are possible with LightGBM running on a single-board computer (such as Jetson Nano, Coral Dev Board, Raspberry Pi, etc.) without the need to transmit data collected from the AWS and ERMS to a remote high-performance server.
The most significant finding of our research is that the gamma exposure rate can be predicted accurately by learning various weather data using the LightGBM learning algorithm. The trained LightGBM model has great potential to help us determine if the increase in the gamma exposure rate is due to a change in the weather or indeed an actual gamma ray. Our approach can also help autonomous vehicles to choose a safe route.
The runtime performance of LightGBM paves a way to realizing edge intelligence through edge computing using a single-board computer. It is in our interest to conduct real-time machine learning-based diagnosis to determine the root cause of a variation in the gamma exposure rate.
Author Contributions
Conceptualization, C.C., K.K. and C.W.; methodology, C.C., K.K. and C.W.; software, C.C.; validation, C.C., K.K. and C.W.; formal analysis, C.C., K.K. and C.W.; investigation, C.C. and K.K.; resources, C.C. and K.K.; data curation, C.C.; writing—original draft preparation, C.C. and K.K.; writing—review and editing, C.C., and C.W.; visualization, C.C.; supervision, K.K.; project administration, K.K.; All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Michael, F. Radioactivity Hall of Fame-Part I. In Radioactivity Introduction and History; Elsevier BV.: Amsterdam, The Netherlands, 2007; pp. 55–58. [Google Scholar]
- Weiderpass, E.; Meo, M.; Vanio, H. Risk Factors for Breast Cancer, Including Occupational Exposures. Saf. Health Work. 2011, 2, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Prasad, K.R.; Balagi, V.; Dighe, P.M.; Alex, M.; Karpagam, R. Pressurized ion chamber for low energy radiation monitoring. Radiat. Meas. 1997, 27, 593–598. [Google Scholar] [CrossRef]
- Steveninck, W.V. A pressurized ion chamber monitoring system for environmental radiation measurements utilizing a wide-range temperature-compensated electrometer. IEEE Trans. Nucl. Sci. 1994, 41, 1080–1085. [Google Scholar] [CrossRef]
- Tran, V.; Little, M.P. Dose and dose rate extrapolation factors for malignant and non-malignant health endpoints after exposure to gamma and neutron radiation. Radiat. Environ. Biophys. 2017, 56, 299–328. [Google Scholar] [CrossRef] [PubMed]
- Hazrati, S.; Sadegh, H.; Amani, M.; Alizadeh, B.; Fakhimi, H.; Rahimzadeh, S. Assessment of gamma dose rate in indoor environments in selected districts of Ardabil Province, Northwestern Iran. Int. J. Occup. Hyg. 2010, 2, 42–45. [Google Scholar]
- Seo, S.W.; Kang, J.K.; Lee, D.N.; Jin, Y.W. Health effects and consultations about radon exposure. J. Korean Med. Assoc. 2019, 62, 376–382. [Google Scholar] [CrossRef]
- Lowdon, M.; Martin, P.G.; Hubbard, M.W.; Taggart, M.P.; Connor, D.T.; Verbelen, Y.; Sellin, P.J.; Scott, T.B. Evaluation of Scintillator Detection Materials for Application within Airborne Environmental Radiation Monitoring. Sensors 2019, 19, 3828. [Google Scholar] [CrossRef]
- Lynch, R.A.; Smith, T.; Jacobs, M.C.; Frank, S.J.; Kearfott, K.J. A radiation weather station: Development of a continuous monitoring system for the collection, analysis, and display of environmental radiation data. Health Phys. 2018, 115, 590–599. [Google Scholar] [CrossRef]
- Wiseman, Y. Autonomous Vehicles, Encyclopedia of Information Science and Technology, 5th ed.; IGI Global: Hershey, PA, USA, 2020; Volume 1, Chapter 1; pp. 1–11. [Google Scholar]
- Cha, H.H.; Kim, J.H. Time Series Analysis of Gamma exposure rates in Gangneung Area. J. Korean Soc. Radiol. 2013, 7, 25–30. [Google Scholar] [CrossRef][Green Version]
- Cha, H.H.; Kim, J.H. Cross Correlation Analysis of Gamma Exposure Rates and Rainfall, Hours of Saylight, Average Wind Speed in Gangneung Area. J. Korean Soc. Radiol. 2013, 7, 347–352. [Google Scholar] [CrossRef][Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Fabregas, A.C.; Arellano, P.B.; Pinili, A.N. Long-Short Term Memory (LSTM) Networks with Time Series and Spatio-Temporal Approaches Applied in Forecasting Earthquakes in the Philippines. In Proceedings of the 4th International Conference on Natural Language Processing and Information Retrieval, Seoul, Korea, 18–20 November 2020. [Google Scholar]
- Friendman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Statics 2001, 29, 1189–1232. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y.L. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Taylor, R. Interpretation of the correlation coefficient: A basic review. J. Diagn. Med. Sonogr. 1990, 6, 35–39. [Google Scholar] [CrossRef]
- Lang, J.M.; Rothman, K.J.; Cann, C.I. That confounded P-value. Epidemiology (Cambridge Mass.) 1998, 9, 7–8. [Google Scholar]
- Winter, E. The shapley value. In Handbook of Game Theory with Economic Applications; Elsevier BV.: Amsterdam, The Netherlands, 2002; pp. 2025–2054. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}