



Deep Learning with LPC and Wavelet Algorithms for Driving Fault Diagnosis

 ,
, 
Abstract
:1. Introduction
2. Method Theory
2.1. Linear Predictive Coding Method
2.2. Wavelet Transform (WT)
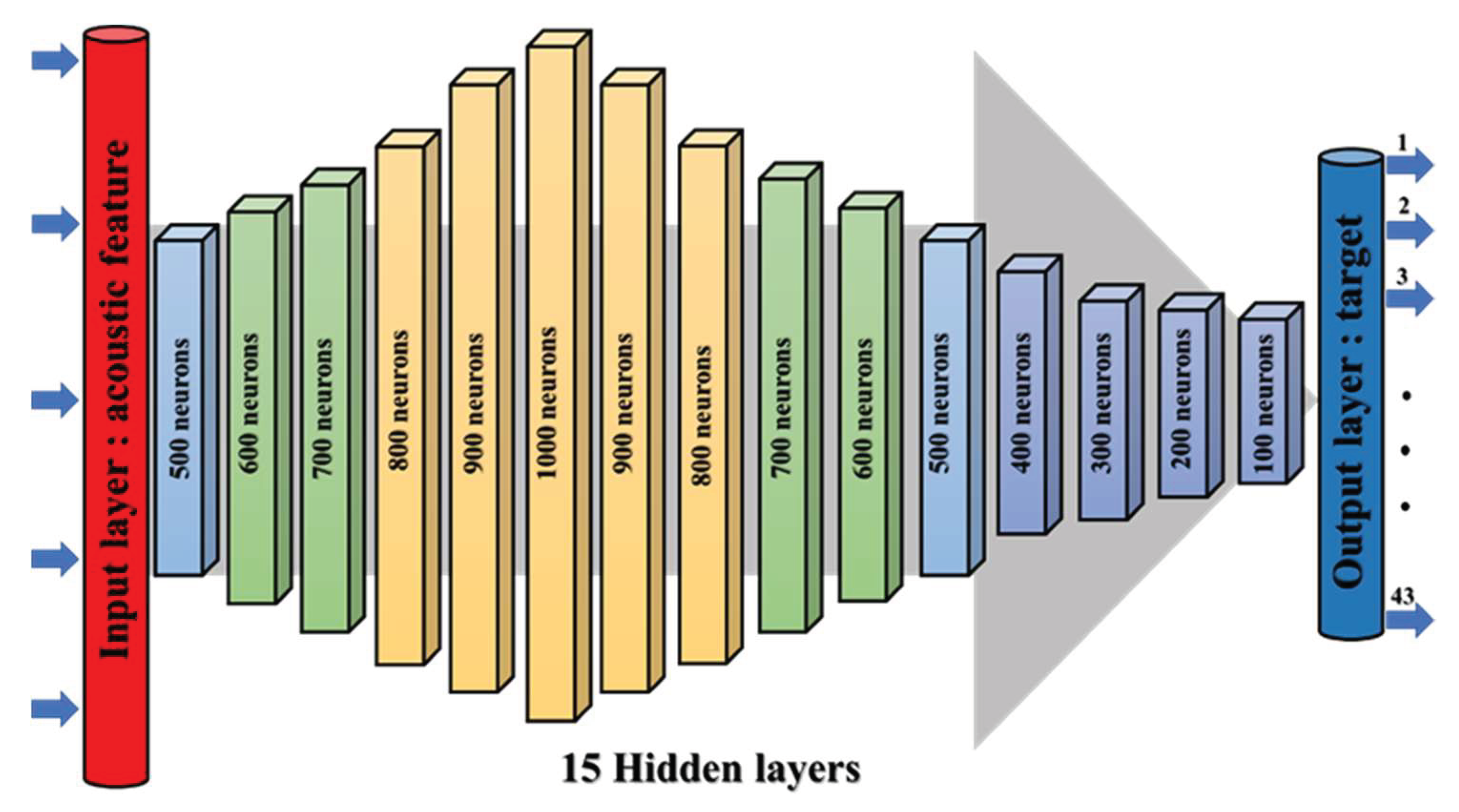
2.3. Deep Neural Network (DNN)
2.4. Convolutional Neural Network (CNN)
2.5. Long Short-Term Memory (LSTM)
3. Experimental Structure
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jaynes, C.; Seales, W.B.; Calvert, K.; Fei, Z.; Griffioen, J. The Metaverse: A networked collection of inexpensive, self-configuring, immersive environments. In Proceedings of the Workshop on Virtual Environments 2003 (EGVE’03), Zurich, Switzerland, 22–23 May 2003; Association for Computing Machinery: New York, NY, USA, 2003; pp. 115–124. [Google Scholar]
- Strutynska, I.; Dmytrotsa, L.; Kozbur, H.; Hlado, O.; Dudkin, P.; Dudkina, O. Development of Digital Platform to Identify and Monitor the Digital Business Transformation Index. In Proceedings of the 2020 IEEE 15th International Conference on Computer Sciences and Information Technologies (CSIT), Zbarazh, Ukraine, 23–26 September 2020; pp. 171–175. [Google Scholar]
- Jiang, Y. An Analysis of the Relationship between Mechanical and Electronic Engineering and Artificial Intelligence. In Proceedings of the 2019 International Conference on Virtual Reality and Intelligent Systems (ICVRIS), Jishou, China, 14–15 September 2019; pp. 191–194. [Google Scholar]
- Ghosh, A.; Chakraborty, D.; Law, A. Artificial intelligence in internet of things. CAAI Trans. Intell. Technol. 2018, 3, 208–218. [Google Scholar] [CrossRef]
- Buyya, R. Cloud computing: The next revolution in information technology. In Proceedings of the 2010 First International Conference on Parallel, Distributed and Grid Computing (PDGC 2010), Solan, India, 28–30 October 2010; pp. 2–3. [Google Scholar]
- Dai, X.; Gao, Z. From model signal to knowledge: A data-driven perspective of fault detection and diagnosis. IEEE Trans. Ind. Inform. 2013, 9, 2226–2238. [Google Scholar] [CrossRef]
- Purkait, P.; Chakravorti, S. Time and frequency domain analyses based expert system for impulse fault diagnosis in transformers. IEEE Trans. Dielectr. Electr. Insul. 2002, 9, 433–445. [Google Scholar] [CrossRef]
- Yang, F.; Wang, S.; Li, J.; Liu, Z.; Sun, Q. An overview of Internet of Vehicles. China Commun. 2014, 11, 1–15. [Google Scholar] [CrossRef]
- Cummings, M.L.; Bauchwitz, B. Safety Implications of Variability in Autonomous Driving Assist Alerting. IEEE Trans. Intell. Transp. Syst. 2022, 23, 12039–12049. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, Q.; Liu, J.; Guo, H. Fault detection and repairing for intelligent connected vehicles based on dynamic bayesian network model. IEEE Internet Things J. 2018, 5, 2431–2440. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Blockchain empowered asynchronous federated learning for secure data sharing in internet of vehicles. IEEE Trans. Veh. Technol. 2020, 69, 4298–4311. [Google Scholar] [CrossRef]
- Liu, H.; Ma, J.; Xu, T.; Yan, W.; Ma, L.; Zhang, X. Vehicle detection and classification using distributed fiber optic acoustic sensing. IEEE Trans. Veh. Technol. 2020, 69, 1363–1374. [Google Scholar] [CrossRef]
- Obeid, N.H.; Battiston, A.; Boileau, T.; Nahid-Mobarakeh, B. Early intermittent interturn fault detection and localization for a permanent magnet synchronous motor of electrical vehicles using wavelet transform. IEEE Trans. Transp. Electrif. 2017, 3, 694–702. [Google Scholar] [CrossRef]
- Kemalkar, A.K.; Bairagi, V.K. Engine fault diagnosis using sound analysis. In Proceedings of the International Conference on Automatic Control and Dynamic Optimization Techniques (ICACDOT), Pune, India, 9–10 September 2016; pp. 943–946. [Google Scholar]
- Chao, K.W.; Chen, Y.H.; Ho, Y.Y.; Guu, D.Y.; Luo, L.B.; Tseng, C.W.; Su, C.S.; Gong, C.A.; Huang, Q.Y.; Lee, I.E.; et al. Feature-Driven Fault Classification for Vehicle Driving Health based on Supervised Learning. In Proceedings of the 26th National Conference on Vehicle Engineering, Taichung, Taiwan, 25–26 January 2021. [Google Scholar]
- Gong, C.S.A.; Lee, H.C.; Chuang, Y.C.; Li, T.H.; Su, C.H.S.; Huang, L.H.; Hsu, C.W.; Hwang, Y.S.; Lee, J.D.; Chang, C.H. Design and Implementation of Acoustic Sensing System for Online Early Fault Detection in Industrial Fans. Hindawi J. Sens. 2018, 2018, 4105208. [Google Scholar] [CrossRef]
- Gong, C.S.A.; Su, C.H.S.; Tseng, K.H. Implementation of machine learning for fault classification on vehicle power transmission system. IEEE Sens. J. 2020, 20, 15163–15176. [Google Scholar] [CrossRef]
- Gong, C.S.A.; Su, C.-H.S.; Chao, K.-W.; Chao, Y.-C.; Su, C.-K.; Chiu, W.-H. Exploiting deep neural network and long short-term memory methodologies in bioacoustic classification of LPC-based features. PLoS ONE 2021, 16, e0259140. [Google Scholar] [CrossRef]
- Ameid, T.; Menacer, A.; Talhaoui, H.; Harzelli, I. Broken rotor bar fault diagnosis using fast Fourier transform applied to field-oriented control induction machine: Simulation and experimental study. Int. J. Adv. Manuf. Technol. 2017, 92, 917–928. [Google Scholar] [CrossRef]
- Ayhan, T.; Dehaene, W.; Verhelst, M. A 128:2048/1536 point FFT hardware implementation with output pruning. In Proceedings of the 2014 22nd European Signal Processing Conference (EUSIPCO), Lisbon, Portugal, 1–5 September 2014; pp. 266–270. [Google Scholar]
- Yan, R.; Gao, R.X.; Chen, X. Wavelets for fault diagnosis of rotary machines: A review with applications. Signal Process. 2014, 96, 1–15. [Google Scholar] [CrossRef]
- Swedia, E.R.; Mutiara, A.B.; Subali, M.; Ernastuti. Deep Learning Long-Short Term Memory (LSTM) for Indonesian Speech Digit Recognition using LPC and MFCC Feature. In Proceedings of the 2018 Third International Conference on Informatics and Computing (ICIC), Palembang, Indonesia, 17–18 October 2018; pp. 1–5. [CrossRef]
- Chong, U.P.; Lee, S.S.; Sohn, C.H. Fault diagnosis of the machines in power plant using LPC. In Proceedings of the 8th Russian-Korean International Symposium on Science and Technology (KORUS), Tomsk, Russia, 26 June–3 July 2004; pp. 170–174. [Google Scholar] [CrossRef]
- Chao, K.W.; Hu, N.-Z.; Chao, Y.-C.; Su, C.-K.; Chiu, W.-H. Implementation of artificial intelligence for classification of frogs in bioacoustics. Symmetry 2019, 11, 1454. [Google Scholar] [CrossRef]
- Yin, S.; Huang, Z. Performance monitoring for vehicle suspension system via fuzzy positivistic C-means clustering based on accelerometer measurements. IEEE/ASME Trans. Mechatron. 2014, 20, 2613–2620. [Google Scholar] [CrossRef]
- Tax, D.M.J.; Ypma, A.; Duin, R.P.W. Pump failure determination using support vector data description. In Advances in Intelligent Data Analysis. IDA; Hand, D.J., Kok, J.N., Berthold, M.R., Eds.; Lecture Notes in Computer Science; Springer: Berlin, Germany, 1999; Volume 1642, pp. 415–425. [Google Scholar] [CrossRef]
- Shifat, T.A.; Hur, J.-W. ANN Assisted Multi Sensor Information Fusion for BLDC Motor Fault Diagnosis. IEEE Access 2021, 9, 9429–9441. [Google Scholar] [CrossRef]
- Weatherspoon, M.H.; Langoni, D. Accurate and efficient modeling of FET cold noise sources using ANNs. IEEE Trans. Instrum. Meas. 2008, 57, 432–437. [Google Scholar] [CrossRef]
- Zhang, Y.; Fu, Y.; Jiang, W.; Li, C.; You, H.; Li, M.; Chandra, V.; Lin, Y. DIAN: Differentiable Accelerator-Network Co-Search Towards Maximal DNN Efficiency. In Proceedings of the 2021 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), Boston, MA, USA, 26–28 July 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Lei, X.; Pan, H.; Huang, X. A Dilated CNN Model for Image Classification. IEEE Access 2019, 7, 124087–124095. [Google Scholar] [CrossRef]
- Markel, J.D.; Gray, A.H., Jr. Linear Prediction of Speech; Springer: New York, NY, USA, 1976. [Google Scholar]
- Goswami, J.C.; Chan, A.K. Fundamentals of Wavelets: Theory, Algorithms, and Applications, 1st ed.; Wiley: Hoboken, NJ, USA, 2008. [Google Scholar]
- Choi, J.Y.; Choi, C.H. Sensitivity analysis of multilayer perceptron with differentiable activation functions. IEEE Trans. Neural Netw. 1992, 3, 101–107. [Google Scholar] [CrossRef]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef] [PubMed]
- Olshausen, B.A.; Field, D.J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607–609. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556v6. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A new convolutional neural network-based data-driven fault diagnosis method. IEEE Trans. Ind. Electron. 2018, 65, 5990–5998. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Neural Networks and Deep Learning; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Haykin, S.; Veen, B.V. Signals and Systems, 2nd ed.; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Hotho, G.; Villemoes, L.F.; Breebaart, J. A Backward-Compatible Multichannel Audio Codec. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 83–93. [Google Scholar] [CrossRef]
- Lin, C.H.; Lin, Y.C.; Tang, P.W. ADMM-ADAM: A New Inverse Imaging Framework Blending the Advantages of Convex Optimization and Deep Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5514616. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 11–13 April 2011; Volume 15, pp. 315–323. [Google Scholar]
- Nguyen, A.; Pham, K.; Ngo, D.; Ngo, T.; Pham, L. An Analysis of State-of-the-art Activation Functions For Supervised Deep Neural Network. In Proceedings of the 2021 International Conference on System Science and Engineering (ICSSE), Ho Chi Minh City, Vietnam, 26–28 August 2021; pp. 215–220. [Google Scholar]



































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Feature Signal Condition | Statement |
|---|---|---|
| 1 | Tire V30 32 psi | Normal pressure in 30 km/h. |
| 2 | Tire V30 50 psi | High pressure in 30 km/h. |
| 3 | Tire V30 20 psi | Low pressure in 30 km/h. |
| 4 | Tire V30 32 psi fail | Tire wear and normal pressure in 30 km/h. |
| 5 | Tire V30 50 psi fail | Tire wear and high pressure in 30 km/h. |
| 6 | Tire V30 20 psi fail | Tire wear and low pressure in 30 km/h. |
| 7 | Tire V20 32 psi | Normal pressure in 20 km/h. |
| 8 | Tire V20 50 psi | High pressure in 20 km/h. |
| 9 | Tire V20 20 psi | Low pressure in 20 km/h. |
| 10 | Tire V20 32 psi fail | Tire wear and normal pressure in 20 km/h. |
| 11 | Tire V20 50 psi fail | Tire wear and high pressure in 20 km/h. |
| 12 | Tire V20 20 psi fail | Tire wear and low pressure in 20 km/h. |
| 13 | Tap V30 32 psi | Tire studs and normal pressure in 30 km/h. |
| 14 | Tap V30 50 psi | Tire studs and high pressure in 30 km/h. |
| 15 | Tap V30 20 psi | Tire studs and low pressure in 30 km/h. |
| 16 | Tap V20 32 psi | Tire studs and normal pressure in 20 km/h. |
| 17 | Tap V20 50 psi | Tire studs and high pressure in 20 km/h. |
| 18 | Tap V20 20 psi | Tire studs and low pressure in 20 km/h. |
| 19 | Belt 1000 rpm normal | Belt normal at 1000 rpm. |
| 20 | Belt 1500 rpm normal | Belt normal at 1500 rpm. |
| 21 | Belt 2000 rpm normal | Belt normal at 2000 rpm. |
| 22 | Belt 1000 rpm idle speed | Belt idle speed at 1000 rpm. |
| 23 | Belt 1500 rpm idle speed | Belt idle speed at 1500 rpm. |
| 24 | Belt 2000 rpm idle speed | Belt idle speed at 2000 rpm. |
| 25 | Toe-in V30 32 psi | Chassis toe-in and normal pressure in 30 km/h. |
| 26 | Toe-in V30 50 psi | Chassis toe-in and high pressure in 30 km/h. |
| 27 | Toe-in V30 20 psi | Chassis toe-in and low pressure in 30 km/h. |
| 28 | Toe-in V20 32 psi | Chassis toe-in and normal pressure in 20 km/h. |
| 29 | Toe-in V20 50 psi | Chassis toe-in and high pressure in 20 km/h. |
| 30 | Toe-in V20 20 psi | Chassis toe-in and low pressure in 20 km/h. |
| 31 | Toe-out V30 32 psi | Chassis toe-out and normal pressure in 30 km/h. |
| 32 | Toe-out V30 50 psi | Chassis toe-out and high pressure in 30 km/h. |
| 33 | Toe-out V30 20 psi | Chassis toe-out and low pressure in 30 km/h. |
| 34 | Toe-out V20 32 psi | Chassis toe-out and normal pressure in 20 km/h. |
| 35 | Toe-out V20 50 psi | Chassis toe-out and high pressure in 20 km/h. |
| 36 | Toe-out V20 20 psi | Chassis toe-out and low pressure in 20 km/h. |
| 37 | Drive V10 32 psi | Broken drive shaft boot and normal pressure in 10 km/h. |
| 38 | Drive V10 50 psi | Broken drive shaft boot and high pressure in 10 km/h. |
| 39 | Drive V10 20 psi | Broken drive shaft boot and low pressure in 10 km/h. |
| 40 | Drive V20 50 psi | Broken drive shaft boot and high pressure in 20 km/h. |
| 41 | No.1 nozzle 1000 rpm | Engine single cylinder misfire, idle speed at 1000 rpm. |
| 42 | No.1 nozzle 1500 rpm | Engine single cylinder misfire, idle speed at 1500 rpm. |
| 43 | No.1 nozzle 2000 rpm | Engine single cylinder misfire, idle speed at 2000 rpm. |
| Results of 30-Feature Datasets | DNN | CNN | LSTM |
|---|---|---|---|
| Accuracy for LPC | 0.579 | 1.000 | 0.023 |
| Training time for LPC (s) | 97.515 | 115.200 | 70.031 |
| Accuracy for Wavelet | 1.000 | 0.858 | 0.879 |
| Training time for Wavelet (s) | 97.747 | 118.767 | 70.042 |
| Results of 40-Feature Datasets | DNN | CNN | LSTM |
|---|---|---|---|
| Accuracy for LPC | 0.828 | 1.000 | 0.023 |
| Training time for LPC (s) | 125.193 | 207.647 | 163.552 |
| Accuracy for Wavelet | 1.000 | 0.913 | 1.000 |
| Training time for Wavelet (s) | 124.090 | 207.727 | 162.962 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, C.-S.A.; Su, C.-H.S.; Liu, Y.-E.; Guu, D.-Y.; Chen, Y.-H. Deep Learning with LPC and Wavelet Algorithms for Driving Fault Diagnosis. Sensors 2022, 22, 7072. https://doi.org/10.3390/s22187072
Gong C-SA, Su C-HS, Liu Y-E, Guu D-Y, Chen Y-H. Deep Learning with LPC and Wavelet Algorithms for Driving Fault Diagnosis. Sensors. 2022; 22(18):7072. https://doi.org/10.3390/s22187072
Chicago/Turabian StyleGong, Cihun-Siyong Alex, Chih-Hui Simon Su, Yuan-En Liu, De-Yu Guu, and Yu-Hua Chen. 2022. "Deep Learning with LPC and Wavelet Algorithms for Driving Fault Diagnosis" Sensors 22, no. 18: 7072. https://doi.org/10.3390/s22187072