A Stacked Generalization Model to Enhance Prediction of Earthquake-Induced Soil Liquefaction

 ,
,  ,
,  , and
, and
Abstract
:1. Introduction
2. Data Modeling
2.1. Dataset Description
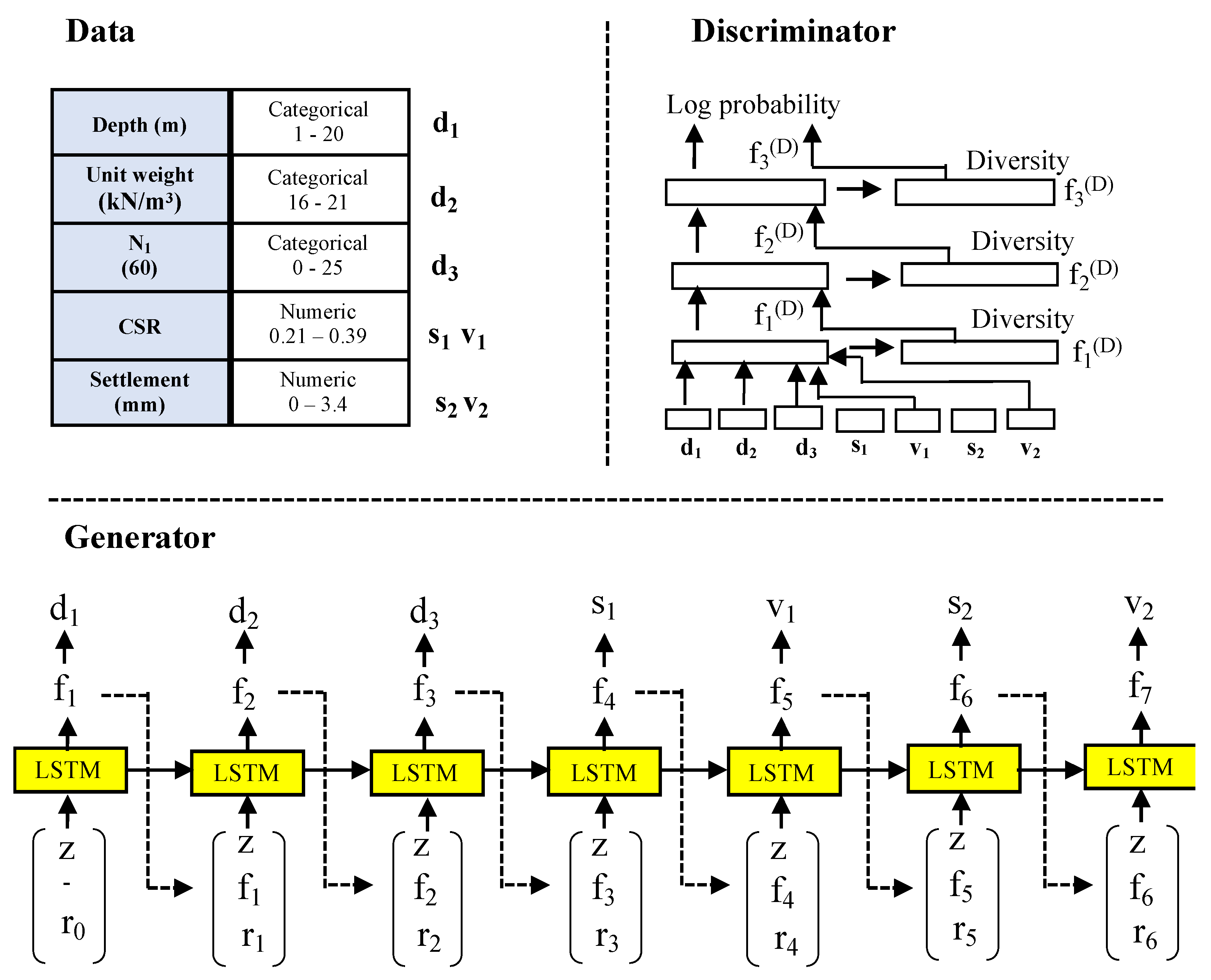
2.2. Data Augmentation
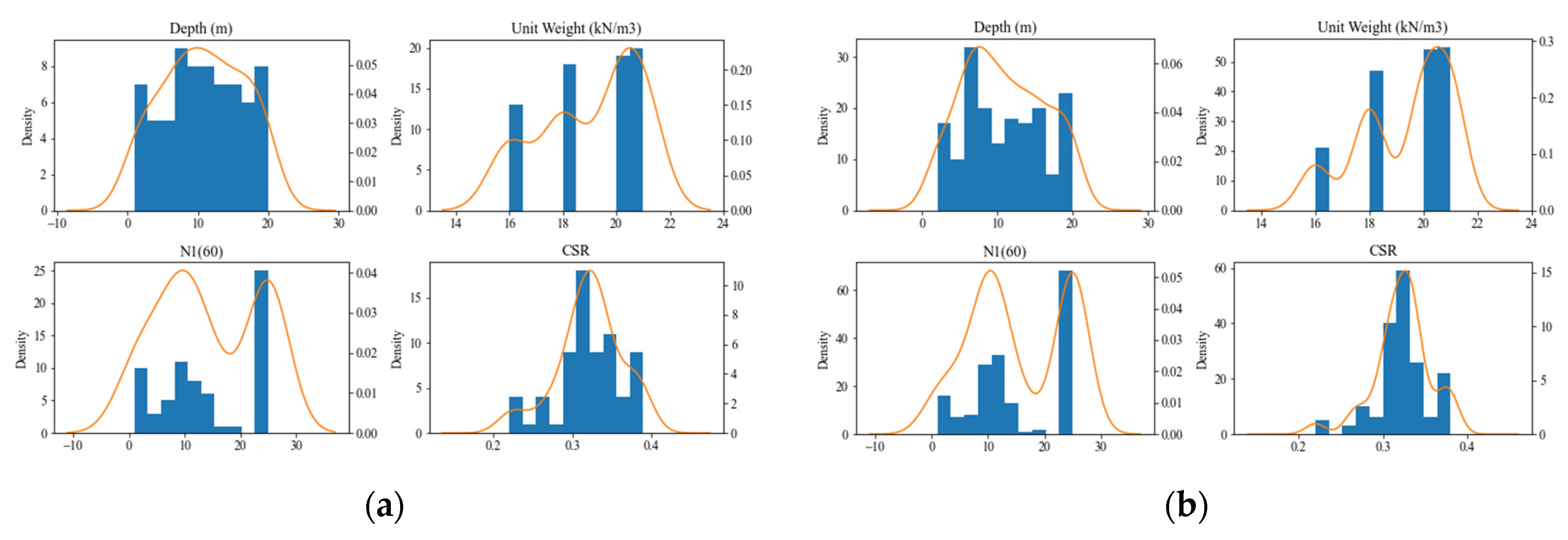
2.3. Analysis of Data Distribution
3. Materials and Methods
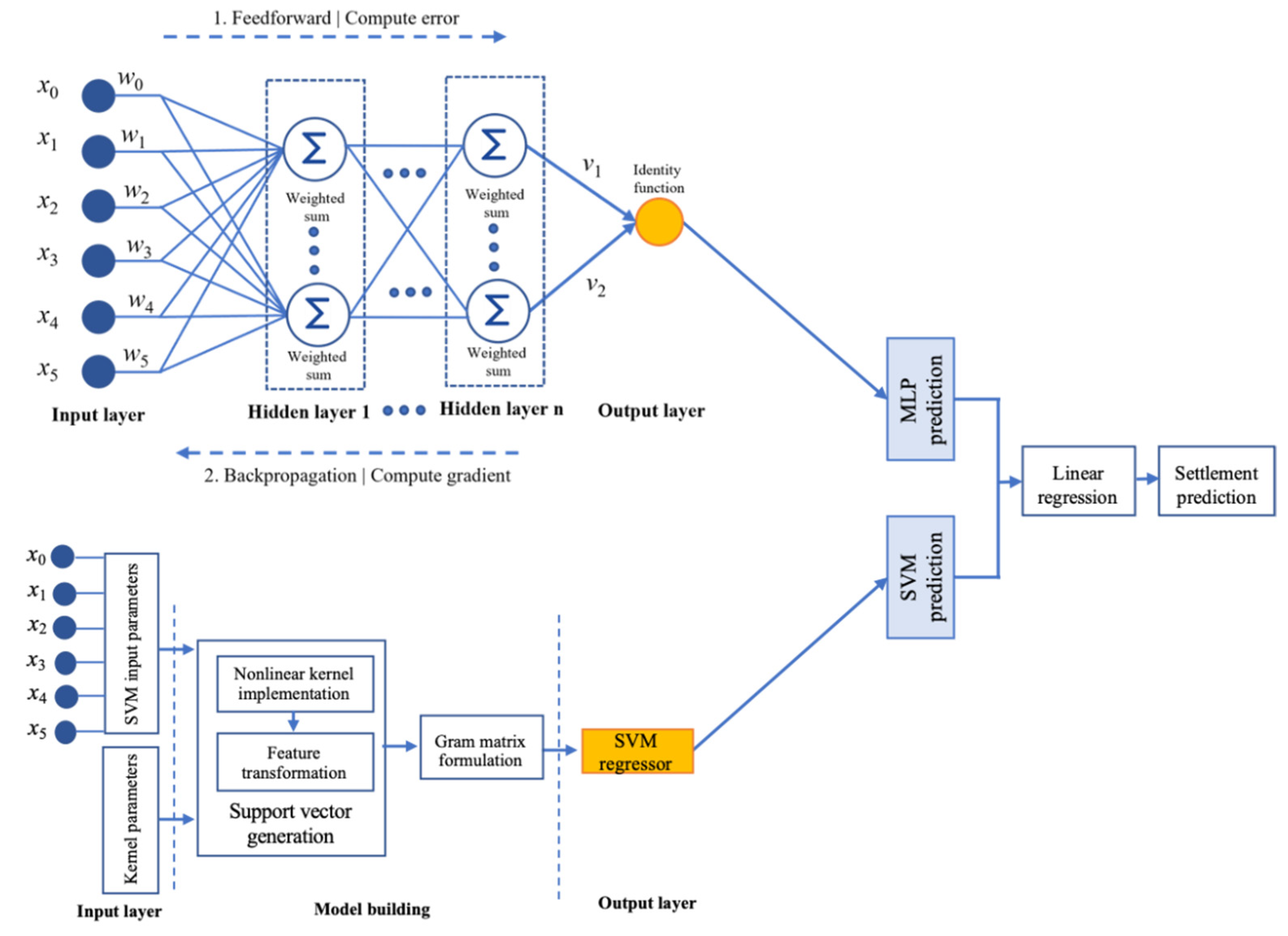
3.1. Stacking Generalization
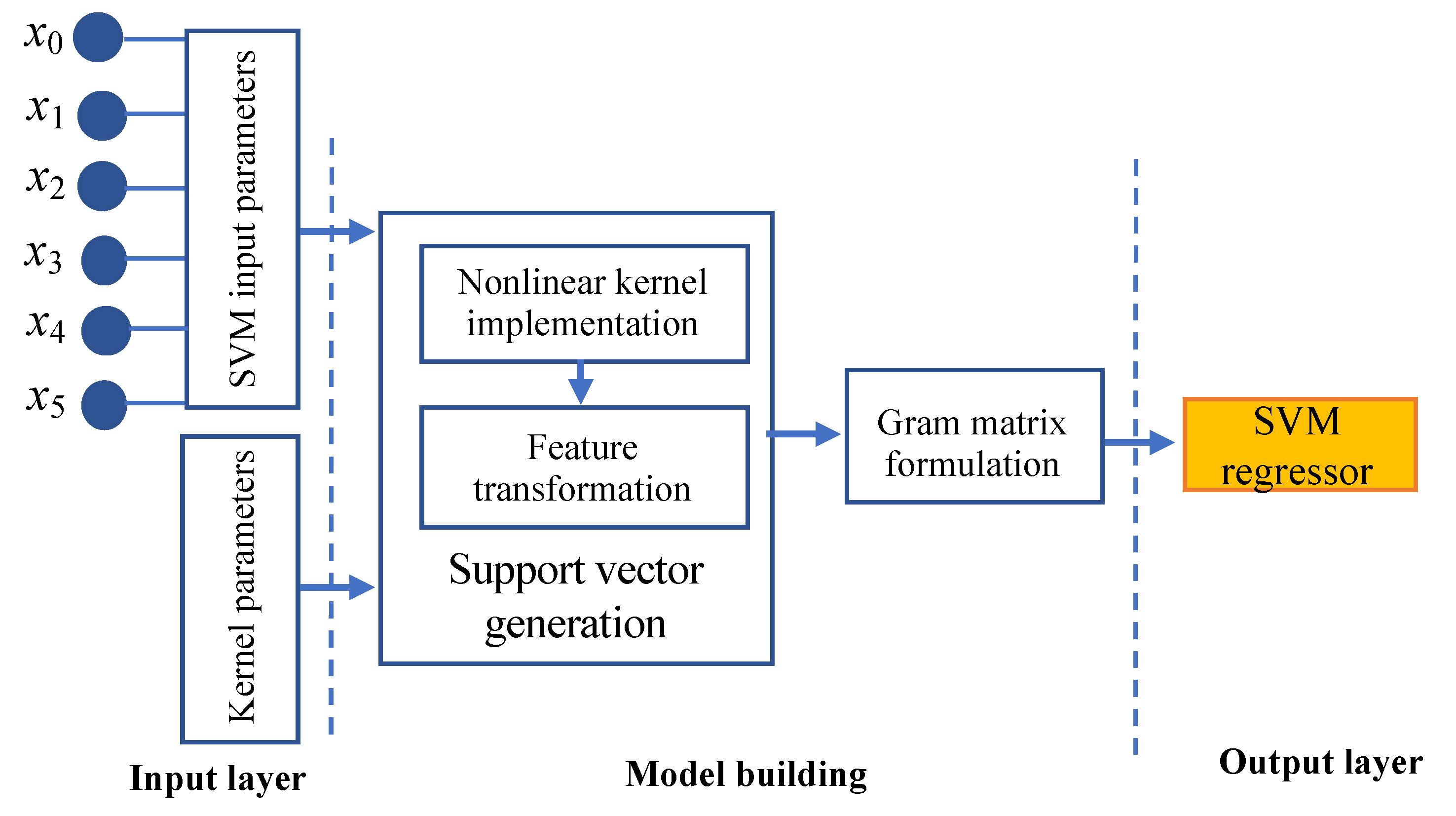
3.2. SVR Base Model Architecture
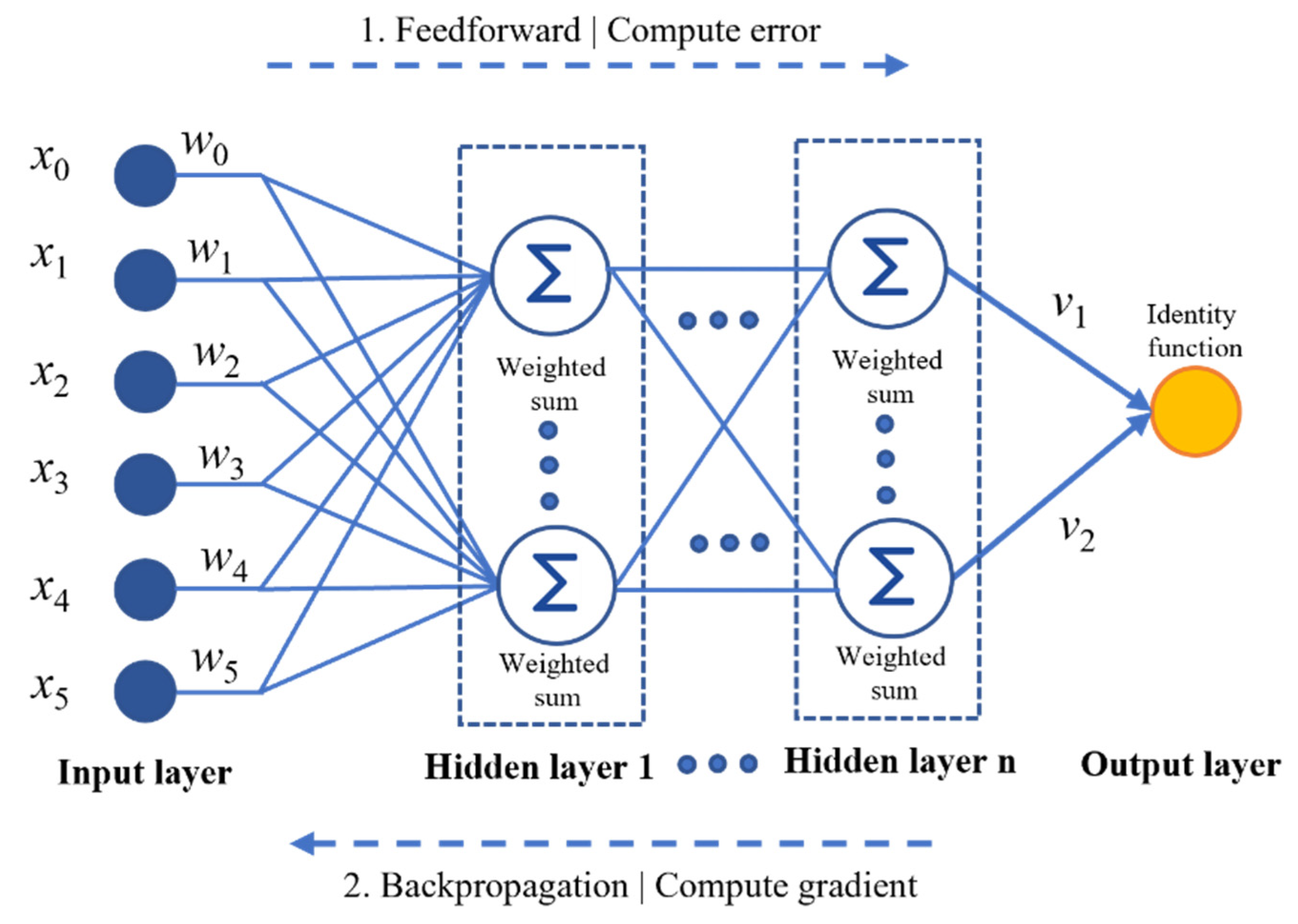
3.3. MLP Regressor
3.4. Stacking the Base Models
| Algorithm 1:Stacked generalization model (SGM) for liquefication prediction |
| 1. Let X be the input features in liquefication dataset D and y be the label for X in D Xn = {xn1, xn2, …xnn}, where ε Rn and . ε Rm D has n_d discrete features and n_c continuous features; 2. Perform data augmentation on the available data features using a tabular generative adversarial network (TGAN) a. Apply the GMM to the TGAN for preprocessing b. Configure generator (G) and discriminator (D) for the TGAN c. for r = 1 to n data points TGAN imputation repeated for r times Generator (G): Generate the scalar S, cluster vector V, and D vector by applying the TGAN Discriminator (D): Integrate MLP with LeakyReLU and Batch Norm Synthesize (S): Generate input values end for 3. Initialize SGM Base model: 02: SVR and MLPR Meta-model: 01: MLR 4. Build SVR base model a. Define objective function: , b. Apply kernel function: G() = <φ()> c. Transform gram matrix: ) d. Generate polynomial kernel function: G(Xi, Xj) = (1 + )q {2,…n} e. Finalize SVR predictive function: 5. Build MLPR base model a. Define linear weighted summation: b. Apply nonlinear activation function: , where i: input features, o: output features c. Activate identity function: d. Apply loss function: e. Deploy Gradient decent function: 6. Stacking meta-model a. Integrate predictions of SVR and MLP b. Combine prediction: Y = β0 + β1 X1 + β2 X2 + ε |
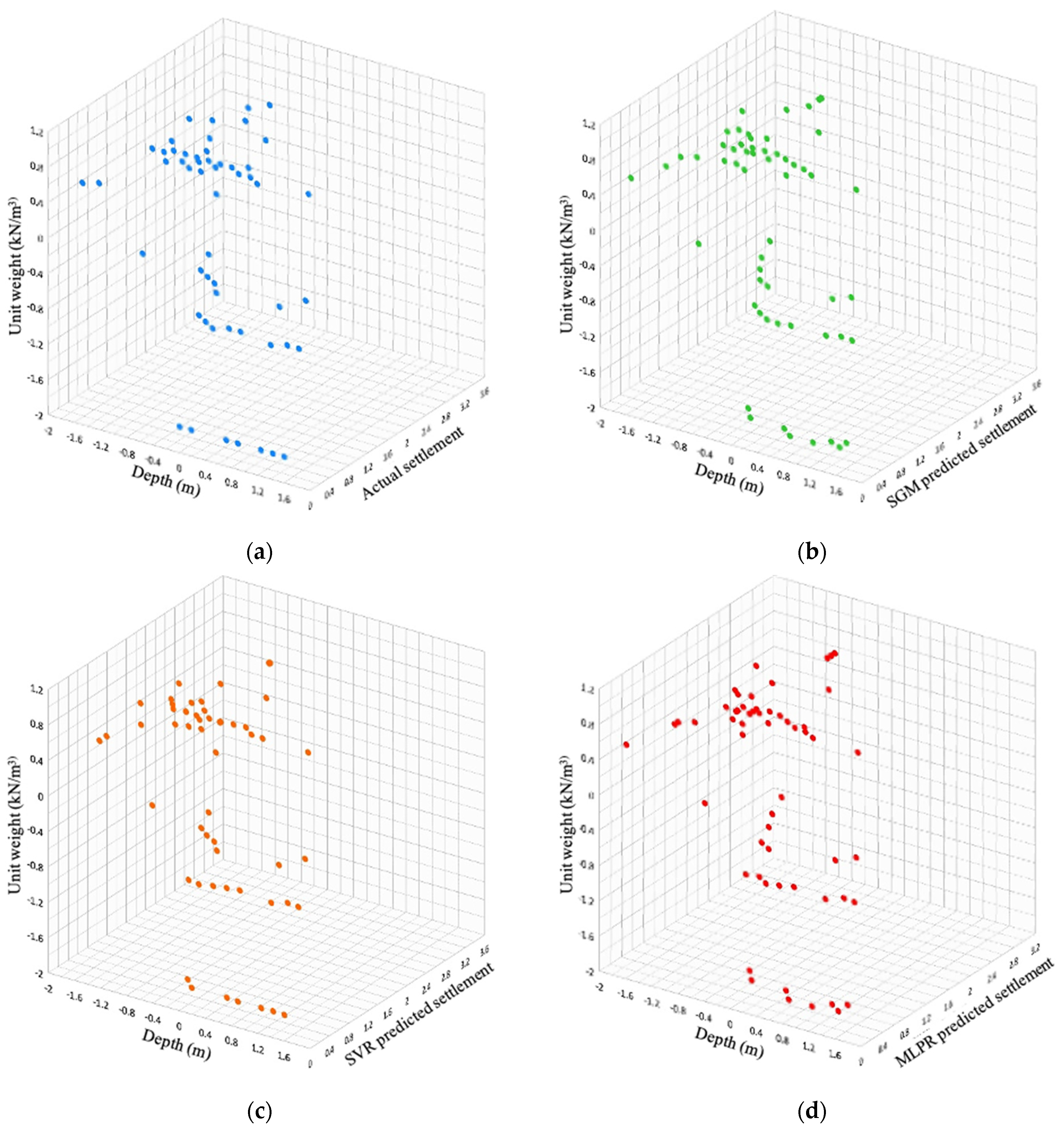
4. Results and Discussion
4.1. Performance Evaluation Metrics
4.2. Performance Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Choi, J.H.; Ko, K.; Gihm, Y.S.; Cho, C.S.; Lee, H.; Song, S.G.; Bang, E.S.; Lee, H.J.; Bae, H.K.; Kim, S.W.; et al. Surface deformations and rupture processes associated with the 2017 Mw 5.4 Pohang, Korea, earthquake. Bull. Seismol. Soc. Am. 2019, 109, 756–769. [Google Scholar] [CrossRef]
- Seed, B. Soil liquefaction and cyclic mobility evaluation for level ground during earthquakes. J. Geotech. Geoenv. Eng. 1979, 105, 14380. [Google Scholar] [CrossRef]
- Naik, S.P.; Kim, Y.-S.; Kim, T.; Su-Ho, J. Geological and structural control on localized ground effects within the Heunghae basin during the Pohang earthquake (Mw 5.4, 15th November 2017), South Korea. Geosciences 2019, 9, 173. [Google Scholar] [CrossRef]
- Leslie Youd, T.; Perkins David, M. Mapping liquefaction-induced ground failure potential. J. Geotech. Eng. Div. 1978, 104, 433–447. [Google Scholar] [CrossRef]
- Aminaton, M.; Tan, C.S. Short review on liquefaction susceptibility. Int. J. Eng. Res. Appl. (IJERA) 2012, 2, 2115–2119. [Google Scholar]
- National Academies of Sciences, Engineering, and Medicine. State of the Art and Practice in the Assessment of Earthquake-Induced Soil Liquefaction and Its Consequences; The National Academies Press: Washington, DC, USA, 2016. [Google Scholar]
- Sambit, P.N.; Gwon, O.; Park, P.; Kim, Y.-S. Land damage mapping and liquefaction potential analysis of soils from the epicentral region of 2017 Pohang Mw 5.4 earthquake, South Korea. Sustainability 2020, 12, 1234. [Google Scholar] [CrossRef]
- Park, S.-S.; Ogunjinmi, P.D.; Woo, S.-W.; Lee, D.-E. A simple and sustainable prediction method of liquefaction-induced settlement at Pohang using an artificial neural network. Sustainability 2020, 12, 4001. [Google Scholar] [CrossRef]
- Da Fonseca, A.V.; Millen, M.; Gómez-Martinez, F.; Romão, X.; Quintero, J. State of the Art Review of Numerical Modelling Strategies to Simulate Liquefaction-Induced Structural Damage and of Uncertain/Random Factors on the Behaviour of Liquefiable Soils. Deliverable D3.1 Article 2017. Available online: http://www.liquefact.eu/disseminations/deliverables/ (accessed on 27 June 2022).
- Popescu, R.; Prevost, J.H. Centrifuge validation of a numerical model for dynamic soil liquefaction. Soil Dyn. Earthq. Eng. 1993, 12, 73–90. [Google Scholar] [CrossRef]
- Ikuo, T.; Orense, R.P.; Toyota, H. Mathematical Principles in Prediction of Lateral Ground Displacement Induced by Seismic Liquefaction. Soils Found. 1999, 32, 1–19. [Google Scholar] [CrossRef]
- Subasi, O.; Koltuk, S.; Iyisan, R. A Numerical Study on the Estimation of Liquefaction-Induced Free-Field Settlements by Using PM4Sand Model. KSCE J. Civ. Eng. 2022, 26, 673–684. [Google Scholar] [CrossRef]
- Sadeghi, H.; Pak, A.; Pakzad, A.; Ayoubi, P. Numerical-probabilistic modeling of the liquefaction-induced free fields settlement. Soil Dyn. Earthq. Eng. 2021, 149, 106868. [Google Scholar] [CrossRef]
- Karimi, Z.; Dashti, S. Seismic performance of shallow founded structures on liquefiable ground: Validation of numerical simulations using centrifuge experiments. J. Geotechn. Geoenviron. Eng. 2016, 142, 13. [Google Scholar] [CrossRef]
- Tang, X.-W.; Hu, J.-L.; Qiu, J.-N. Identifying significant influence factors of seismic soil liquefaction and analyzing their structural relationship. KSCE J. Civ. Eng. 2016, 20, 2655–2663. [Google Scholar] [CrossRef]
- Hanna, A.M.; Ural, D.; Saygili, G. Neural network model for liquefaction potential in soil deposits using Turkey and Taiwan earthquake data. Soil Dyn. Earthq. Eng. 2007, 27, 521–540. [Google Scholar] [CrossRef]
- Chern, S.-G.; Lee, C.-Y.; Wang, C.-C. CPT-based liquefaction assessment by using fuzzy-neural network. J. Mar. Sci. Technol. 2008, 16, 139–148. [Google Scholar] [CrossRef]
- Kayadelen, C. Soil liquefaction modeling by genetic expression programming and neuro-fuzzy. Expert Syst. Appl. 2011, 38, 4080–4087. [Google Scholar] [CrossRef]
- Lee, C.Y.; Chern, S.G. Application of a support vector machine for liquefaction assessment. J. Mar. Sci. Technol. 2013, 21, 318–324. [Google Scholar]
- Kim, B.; Yuvaraj, N.; Sri Preethaa, K.R.; Arun Pandian, R. Surface crack detection using deep learning with shallow CNN architecture for enhanced computation. Neural Comput. Appl. 2021, 33, 9289–9305. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Y. An ensemble method to improve prediction of earthquake-induced, soil liquefaction: A multi-dataset study. Neural Comput. Appl. 2021, 33, 1533–1546. [Google Scholar] [CrossRef]
- Kim, B.; Lee, D.-E.; Hu, G.; Natarajan, Y.; Preethaa, S.; Rathinakumar, A.P. Ensemble machine learning-based approach for predicting of FRP–concrete interfacial bonding. Mathematics 2022, 10, 231. [Google Scholar] [CrossRef]
- Kim, B.; Yuvaraj, N.; Tse, K.T.; Lee, D.-E.; Hu, G. Pressure pattern recognition in buildings using an unsupervised machine-learning algorithm. J. Wind Eng. Ind. Aerodyn. 2021, 214, 104629. [Google Scholar] [CrossRef]
- Xue, X.; Yang, X. Seismic liquefaction potential assessed by support vector machines approaches. Bull Eng. Geol. Env. 2016, 75, 153–162. [Google Scholar] [CrossRef]
- Xue, X.; Liu, E. Seismic liquefaction potential assessed by neural networks. Environ. Earth Sci. 2017, 76, 192. [Google Scholar] [CrossRef]
- Gnanamanickam, J.; Natarajan, Y.; Sri, P.K.R. A hybrid speech enhancement algorithm for voice assistance application. Sensors 2021, 21, 7025. [Google Scholar] [CrossRef] [PubMed]
- Kim, B.; Yuvaraj, N.; Park, H.W.; Sri Preethaa, K.R.; Arun Pandian, R.; Lee, D.-E. Investigation of steel frame damage based on computer vision and deep learning. Autom. Constr. 2021, 132, 103941. [Google Scholar] [CrossRef]
- Integrated DB Center of National Geotechnical Information, SPT Database Available at 542. 2015. Available online: http://www.geoinfo.or.r (accessed on 15 May 2022).
- Park, S.S. Liquefaction evaluation of reclaimed sites using an effective stress analysis and an equivalent linear analysis. KSCE J. Civ. Eng. 2008, 28, 83–94. [Google Scholar]
- Hore, R.; Chakraborty, S.; Arefin, M.S.; Ansary, M. CPT & SPT tests in assessing liquefaction potential. Geotechn. Eng. J. SEAGS & AGSSEA 2020, 51, 61–68. [Google Scholar]
- Kim, B.; Yuvaraj, N.; Sri Preethaa, K.R.; Hu, G.; Lee, D.-E. Wind-induced pressure prediction on tall buildings using generative adversarial imputation network. Sensors 2021, 21, 2515. [Google Scholar] [CrossRef] [PubMed]
- Lei, X.; Kalyan, V. Synthesizing tabular data using generative adversarial networks. arXiv 2018, arXiv:1811.11264. [Google Scholar]
- Insaf, A. Tabular GANs for uneven distribution. arXiv 2020, arXiv:2010.00638. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mehdi, M.; Xu, B.; Warde-Farley, D.; Sherjil, O.; Courville, A.; Yoshua, B. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Ganaiea, M.A.; Minghui, H.; Malika, A.K.; Tanveera, M.; Suganthanb, P.N. Ensemble deep learning: A review. arXiv 2021, arXiv:2104.02395. [Google Scholar] [CrossRef]
- Park, J.; Lim, C. Predicting movie audience with stacked generalization by combining machine learning algorithms, Commun. Stat. Appl. Meth. 2021, 28, 217–232. [Google Scholar] [CrossRef]
- Sri Preethaa, K.R.; Sabari, A. Intelligent video analysis for enhanced pedestrian detection by hybrid metaheuristic approach. Soft Comput. 2020, 24, 12303–12311. [Google Scholar] [CrossRef]
- Liu, N.; Gao, H.; Zhao, Z.; Hu, Y.; Duan, L. A stacked generalization ensemble model for optimization and prediction of the gas well rate of penetration: A case study in Xinjiang. J. Pet. Explor. Prod. Technol. 2021, 12, 1595–1608. [Google Scholar] [CrossRef]
- Tan, Y.; Chen, H.; Zhang, J.; Tang, R.; Liu, P. Early Risk Prediction of Diabetes Based on GA-Stacking. Appl. Sci. 2022, 12, 632. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Distribution for 100 Actual Standard Penetration Test (SPT) Data Points | |||||||
|---|---|---|---|---|---|---|---|---|
| Mean | Standard Deviation (SD) | 25% | 50% | 75% | Minimum (Min) | Maximum (Max) | ||
| Input | Depth (m) | 10.50 | 5.795 | 5.75 | 10.5 | 15.25 | 1 | 20 |
| Unit weight (kN/m3) | 18.96 | 1.869 | 18 | 20 | 21 | 16 | 21 | |
| N1(60) | 13.62 | 8.722 | 7 | 11 | 25 | 0 | 25 | |
| CSR | 0.314 | 0.044 | 0.29 | 0.32 | 0.34 | 0.21 | 0.39 | |
| Output | Settlement (mm) | 0.898 | 0.873 | 0.3 | 0.6 | 1.4 | 0 | 3.4 |
| Parameters | Distribution for 177 Augmented SPT Data Points | |||||||
|---|---|---|---|---|---|---|---|---|
| Mean | Std | 25% | 50% | 75% | Min | Max | ||
| Input | Depth (m) | 10.80 | 5.321 | 7 | 10 | 15 | 2 | 20 |
| Unit weight (kN/m3) | 19.31 | 1.671 | 18 | 20 | 21 | 16 | 21 | |
| N1(60) | 15.25 | 8.410 | 10 | 12 | 25 | 1 | 25 | |
| CSR | 0.32 | 0.030 | 0.31 | 0.33 | 0.34 | 0.22 | 0.38 | |
| Output | Settlement (mm) | 0.98 | 0.831 | 0.5 | 0.6 | 1.4 | 0 | 3.4 |
| Models | Advantages | Limitations |
|---|---|---|
| Support vector regression (SVR) |
|
|
| Multilayer perceptron regressor (MLPR) |
|
|
| Linear regression (LR) |
|
|
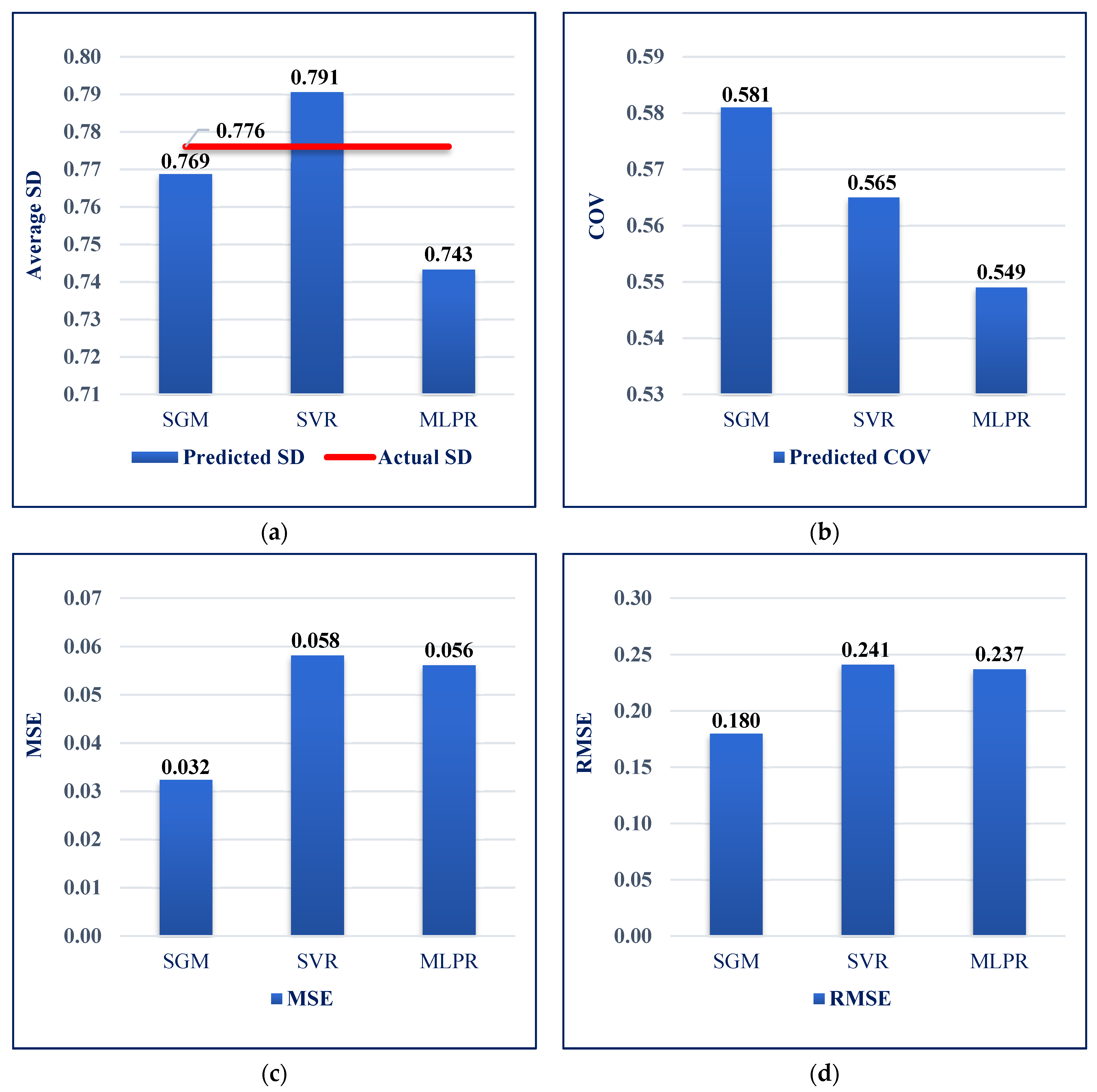
| Performance Metrics | SGM | SVR | MLPR |
|---|---|---|---|
| R2 score | 0.951 | 0.948 | 0.916 |
| SD | 0.769 | 0.791 | 0.743 |
| Covariance (COV) | 0.581 | 0.565 | 0.549 |
| Mean-square error (MSE) | 0.032 | 0.058 | 0.056 |
| Root-MSE (RMSE) | 0.180 | 0.247 | 0.237 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Preethaa, S.; Natarajan, Y.; Rathinakumar, A.P.; Lee, D.-E.; Choi, Y.; Park, Y.-J.; Yi, C.-Y. A Stacked Generalization Model to Enhance Prediction of Earthquake-Induced Soil Liquefaction. Sensors 2022, 22, 7292. https://doi.org/10.3390/s22197292
Preethaa S, Natarajan Y, Rathinakumar AP, Lee D-E, Choi Y, Park Y-J, Yi C-Y. A Stacked Generalization Model to Enhance Prediction of Earthquake-Induced Soil Liquefaction. Sensors. 2022; 22(19):7292. https://doi.org/10.3390/s22197292
Chicago/Turabian StylePreethaa, Sri, Yuvaraj Natarajan, Arun Pandian Rathinakumar, Dong-Eun Lee, Young Choi, Young-Jun Park, and Chang-Yong Yi. 2022. "A Stacked Generalization Model to Enhance Prediction of Earthquake-Induced Soil Liquefaction" Sensors 22, no. 19: 7292. https://doi.org/10.3390/s22197292