
Correction of Substrate Spectral Distortion in Hyper-Spectral Imaging by Neural Network for Blood Stain Characterization



Abstract
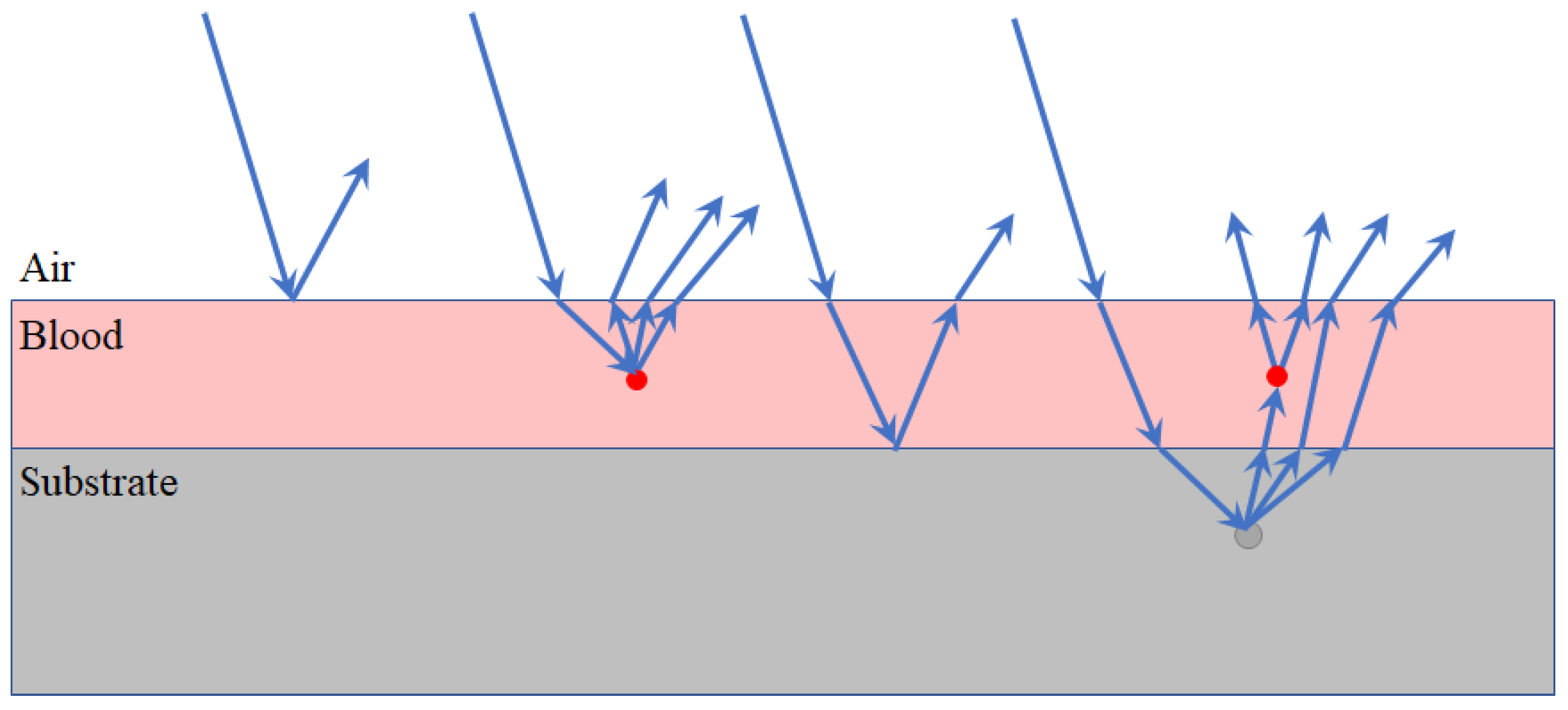
:1. Introduction
2. Material and Methods
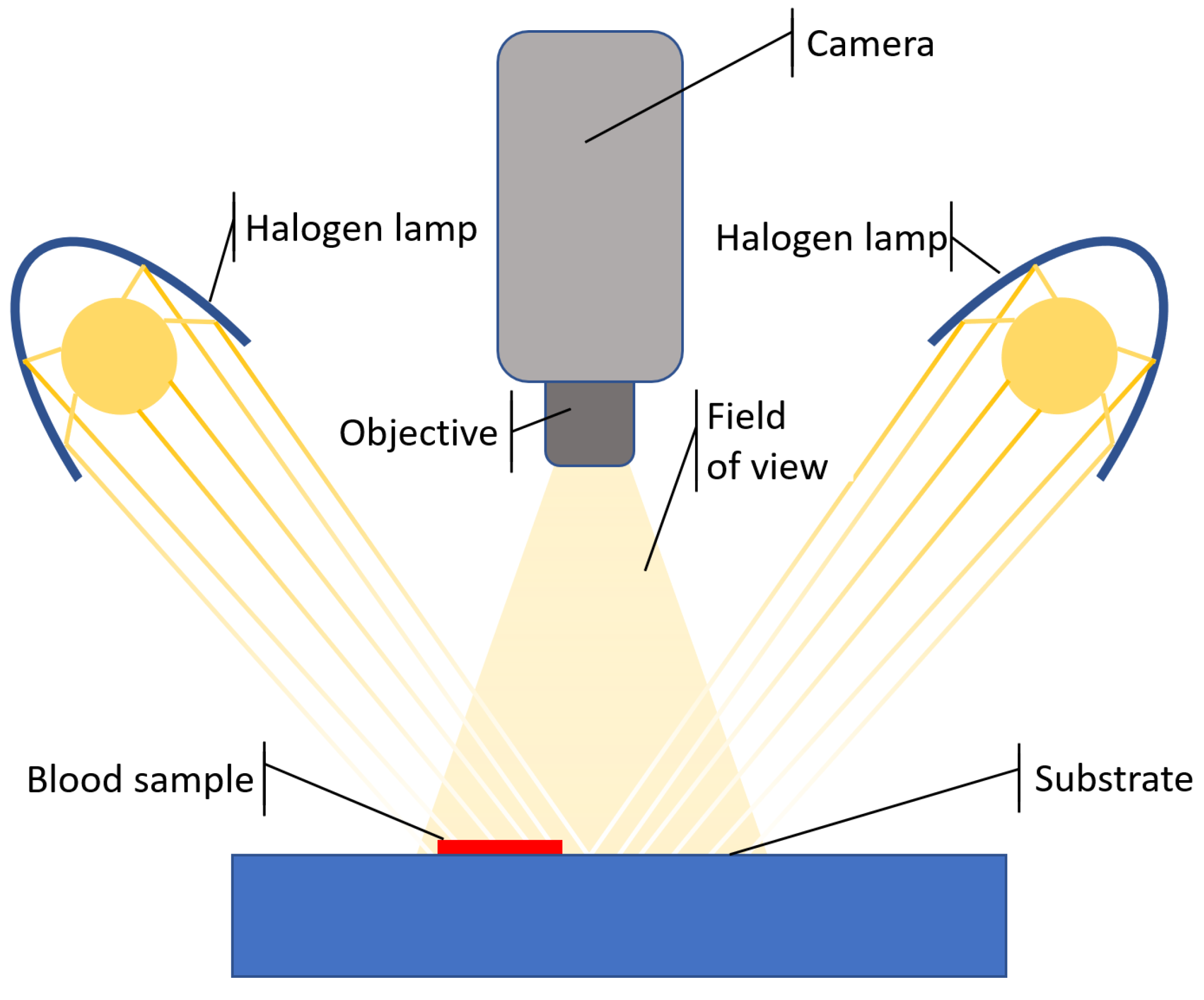
2.1. Test Bench
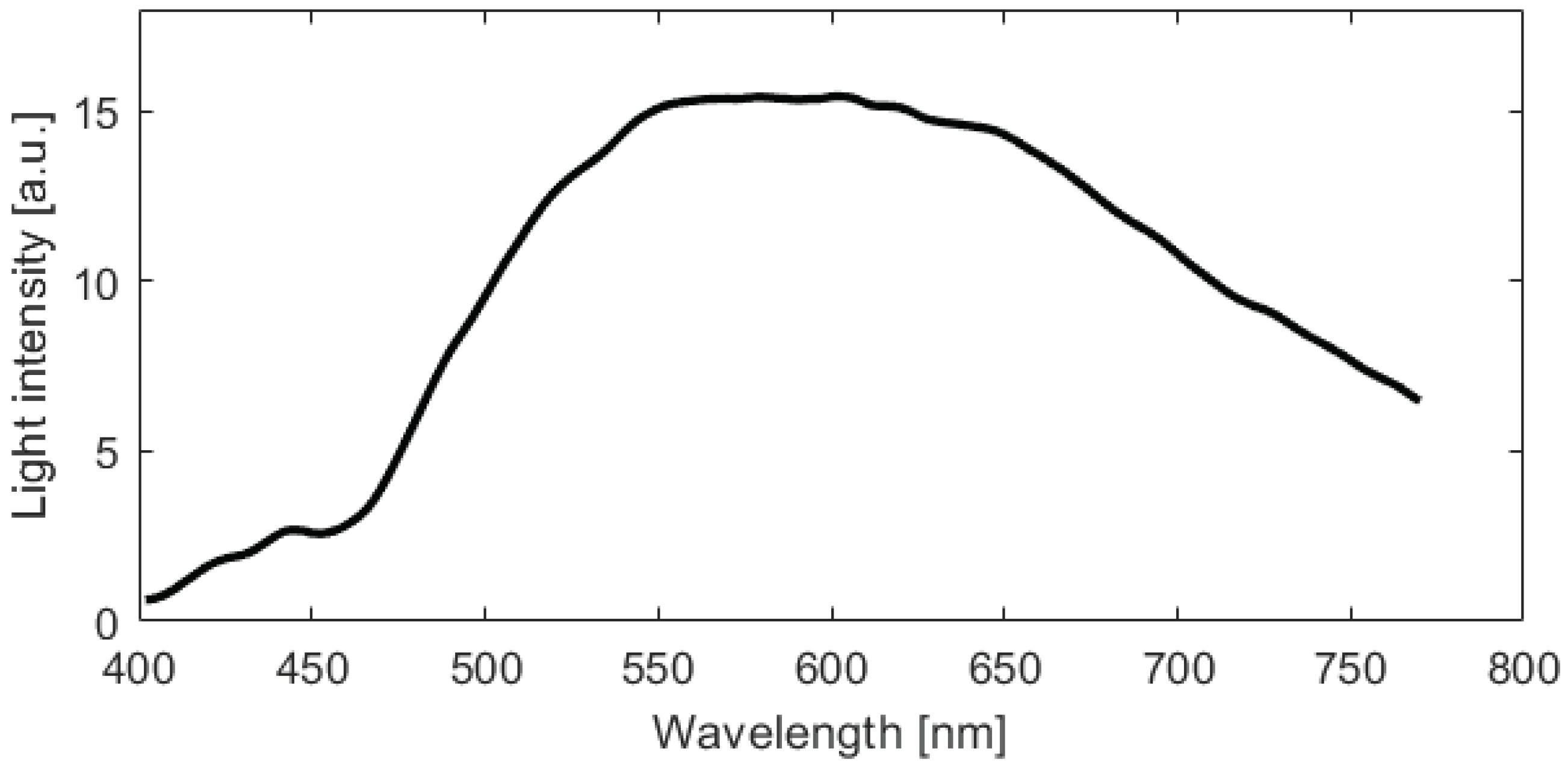
2.2. Image Acquisition
- The white light color provides proper visualization of the blood stain without interference from the substrate color.
- Its non-absorbent behavior makes it possible to have no distinction between the reaction that the blood may have on the substrate surface and on the substrate portion where it is absorbed [16].
3. Image Processing and Data Collection
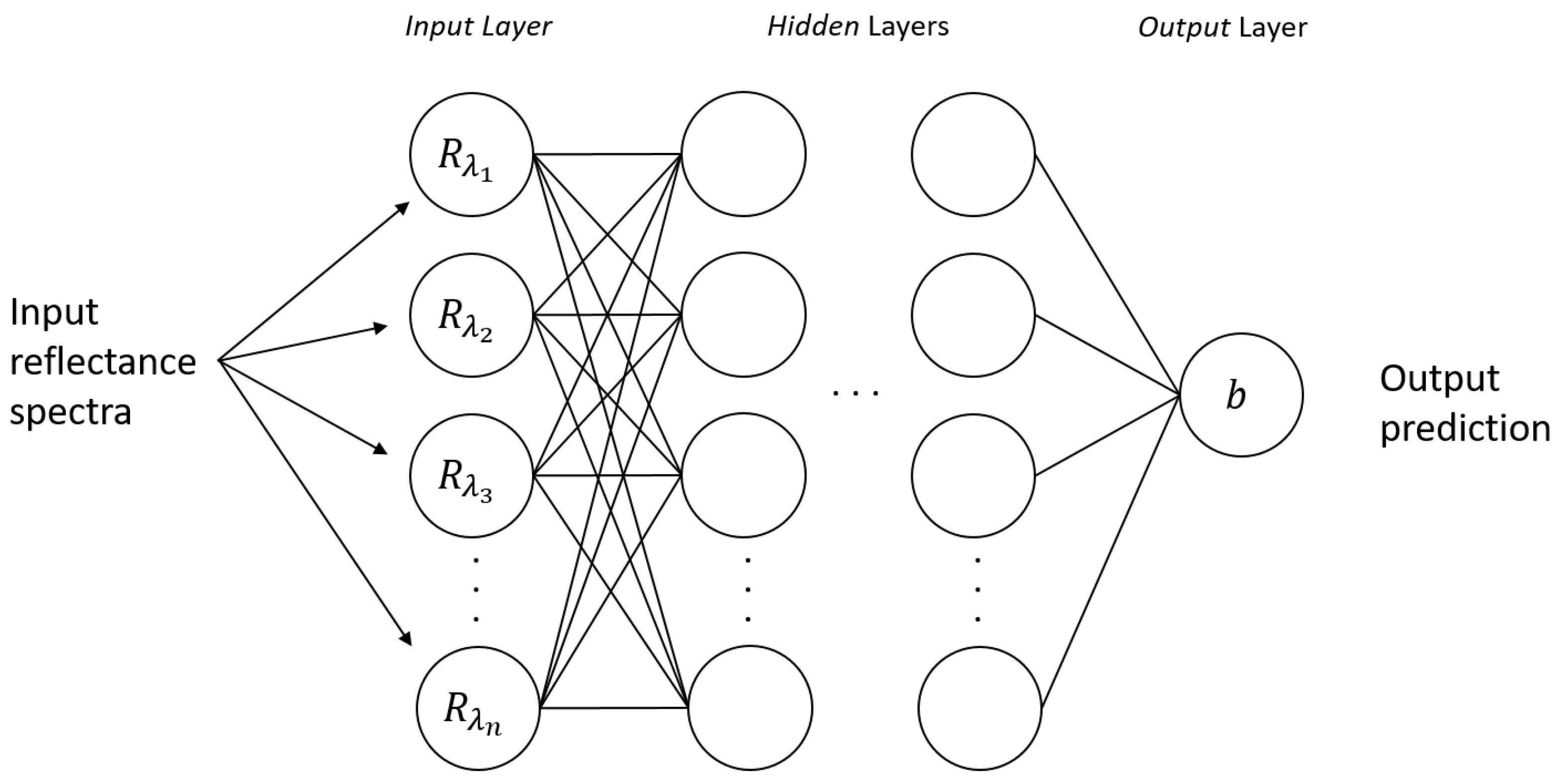
3.1. Blood Stain Spectra Binary Classification via Neural Networks
- Batch size , a hyper-parameter that defines the number of training data sub-samples that will be propagated through the network. The batch size was varied between 256 and 2048.
- Learning rate , a hyper-parameter that defines how much the model will change in response to the estimated loss each time the model weights are updated by the optimizer. The learning rate was varied between and .
- Number of epochs e, a hyper-parameter that defines the number of times a whole dataset is passed through the neural network model. The number of epochs was varied between 20 and 200.
- Activation function , a hyper-parameter that defines the relation between the weighted sum of the input and the output from an artificial neuron or from the set of artificial neurons included in a layer of the network. The activation function can be selected among linear, Sigmoid, ReLU, and Tanh [29].
- Optimizer o defines the algorithm exploited to reduce the loss function-modifying attributes of the neural network, such as weights and learning rate. The optimizer can be selected among SGD, Adam, RMSprop, Adadelta, and Adagrad [21].
- Number of layers ranging between 1 and 12.
- Number of neurons per layers ranging between 10 and 400.
3.2. Substrate Distortion Correction via Neural Networks
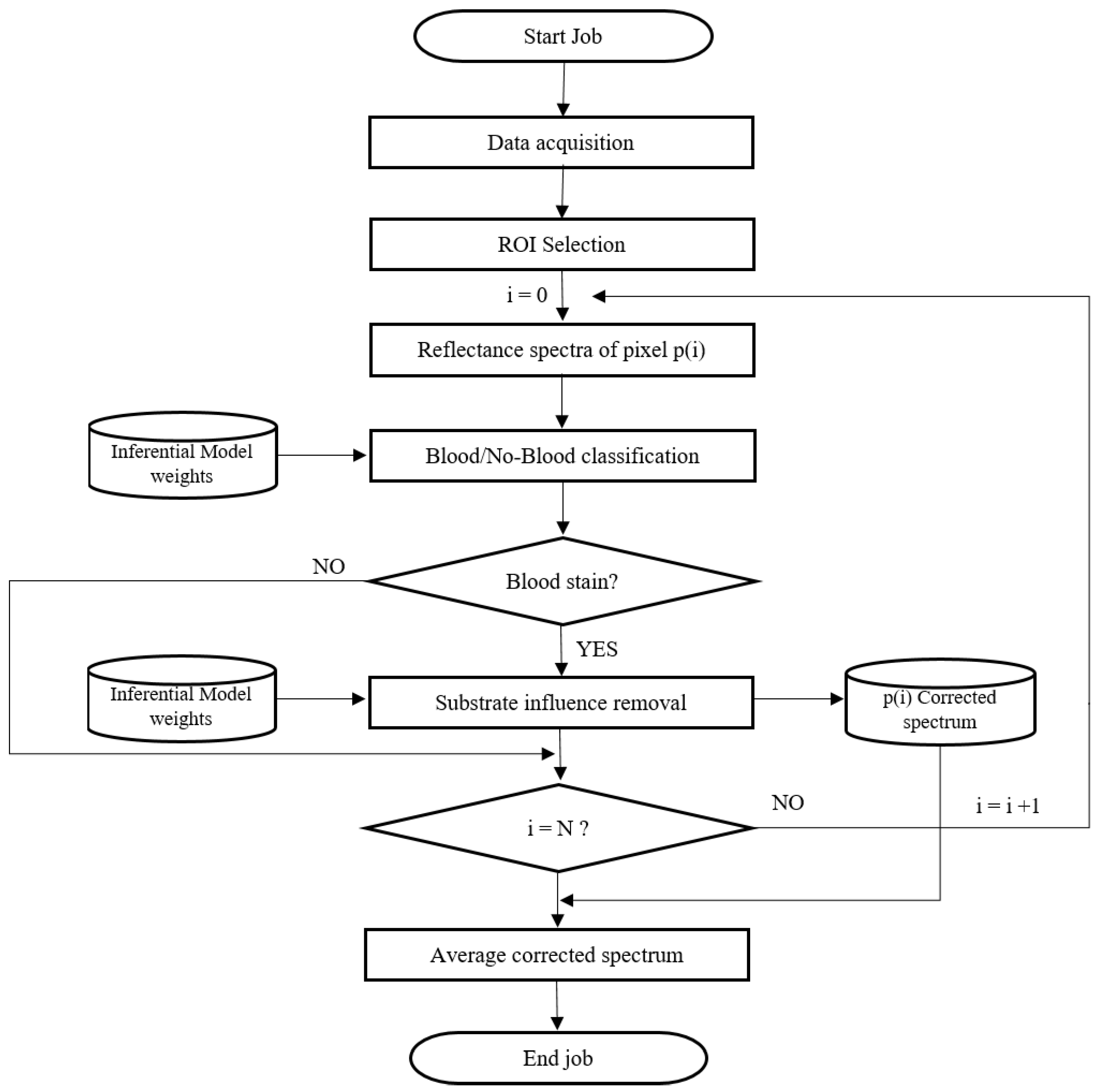
3.3. Procedure Workflow
- a
- The job starts by acquiring a hyper-spectral image containing the blood stain to be analyzed according to the procedure described in Section 2.1 and Section 2.2.
- b
- The Region Of Interest (ROI) containing the blood stain is selected, resulting in N reflectance spectra, where N is the total number of pixel in the ROI.
- c
- The first reflectance spectrum is used as input by the binary classification model of which the optimal weights were obtained during the training phase of the model, as described in Section 3.1.
- d
- The model verifies that the spectrum belongs to a blood stain. If the model considers the current spectrum as not belonging to a blood stain, it is discarded and the procedure is repeated from step “a” with the next spectrum. If, on the other hand, the spectrum is classified as blood spectrum, then this is used as input to the inferential model that deals with the removal of the background spectral distortion.
- e
- The optimal weights and model architecture are obtained according the procedure described in Section 3.2. The output spectrum is stored in the memory and the procedure is iterated from step 3 for each available reflectance spectrum.
- f
- Finally, the average corrected spectrum is returned as output and can be used for extraction of specific parameters, such as the blood age, for example.
4. Analysis of Results
4.1. Blood Stain Spectra Binary Classification Model
- Batch size .
- Learning rate .
- Number of epochs .
- Activation function .
- Optimizer .
- Number of layers .
- Number of neurons per layers .
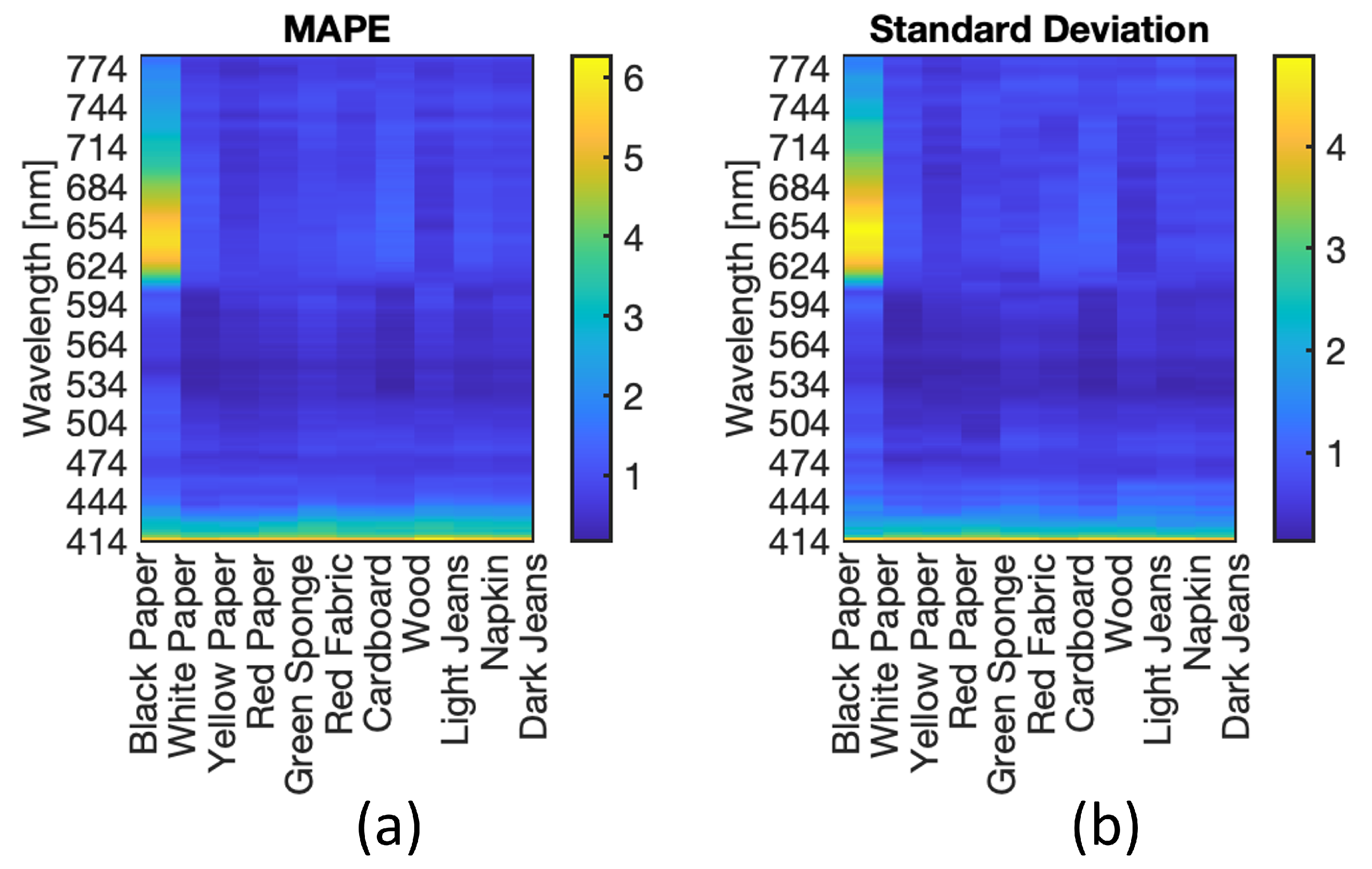
4.2. Substrate Influence Correction Model
- Batch size .
- Learning rate .
- Number of epochs .
- Optimizer .
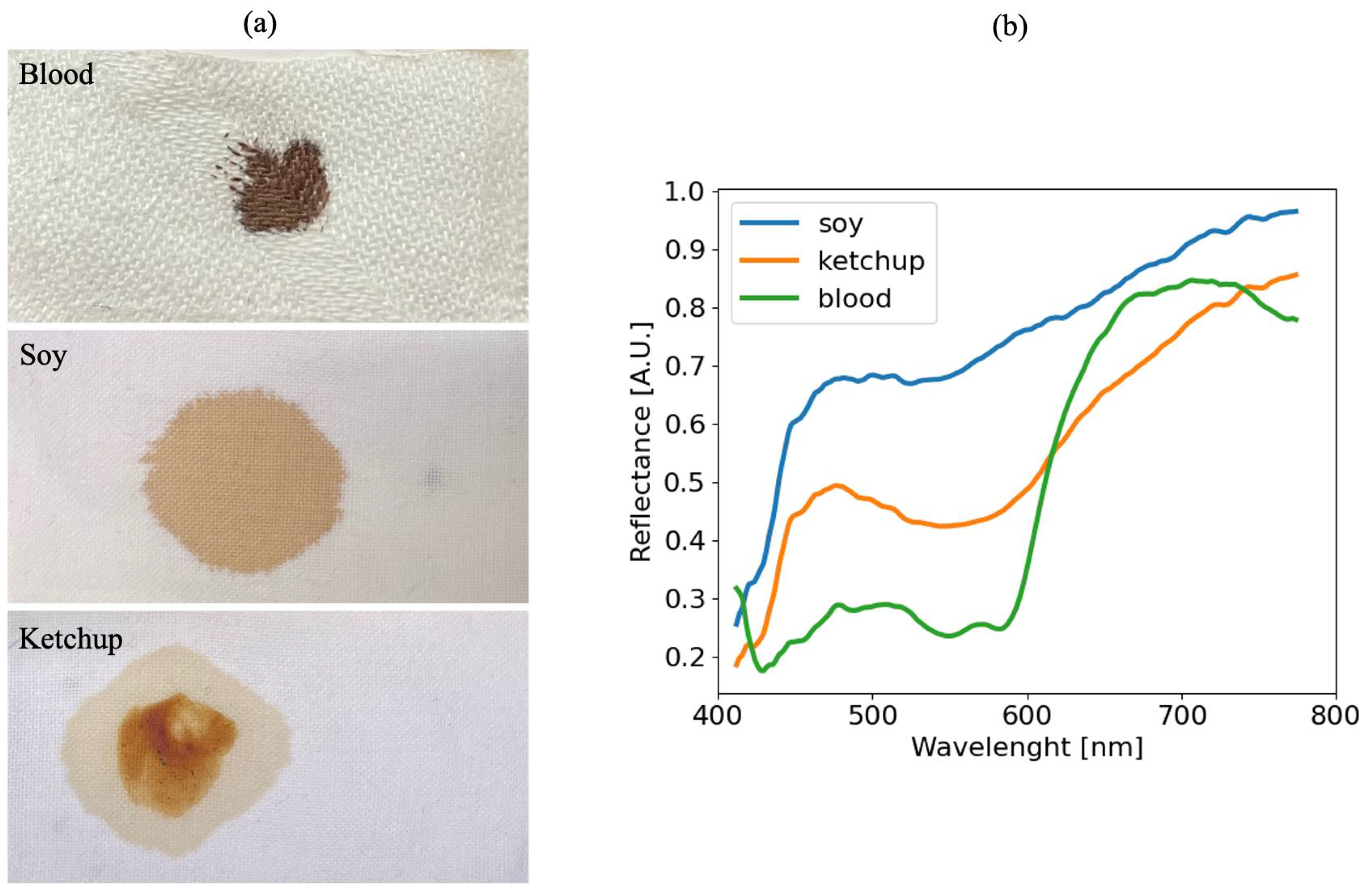
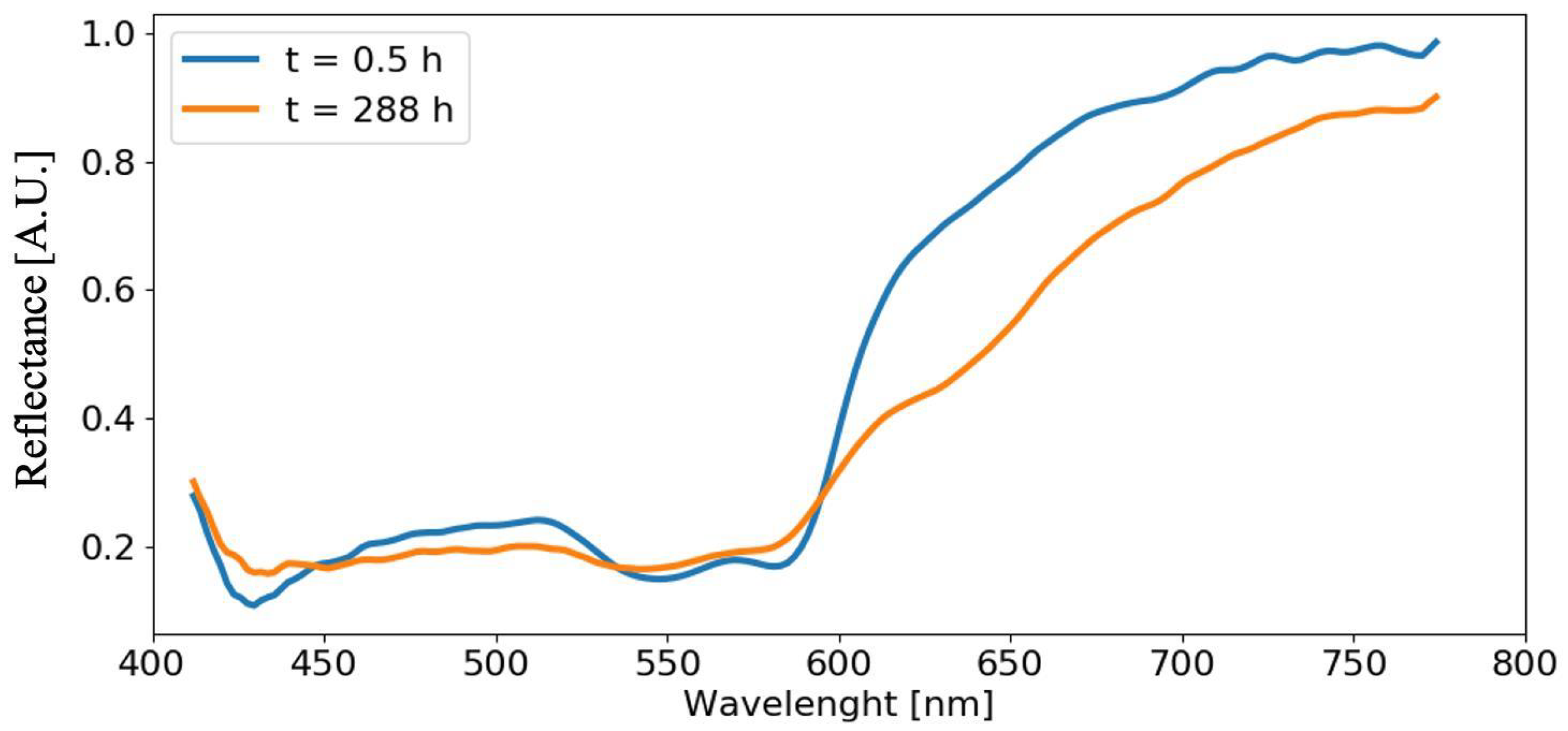
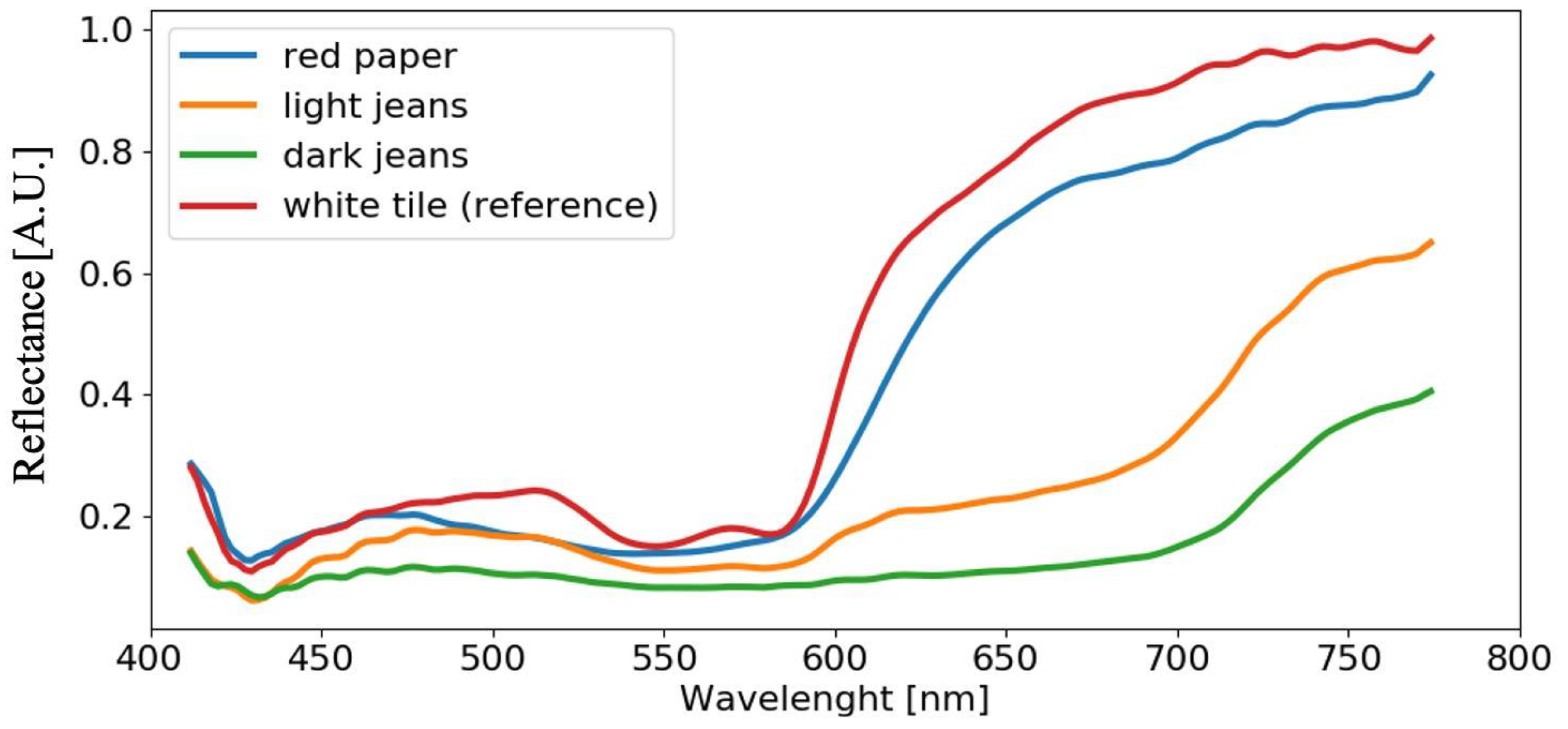
4.3. Analysis of Acquired Spectra
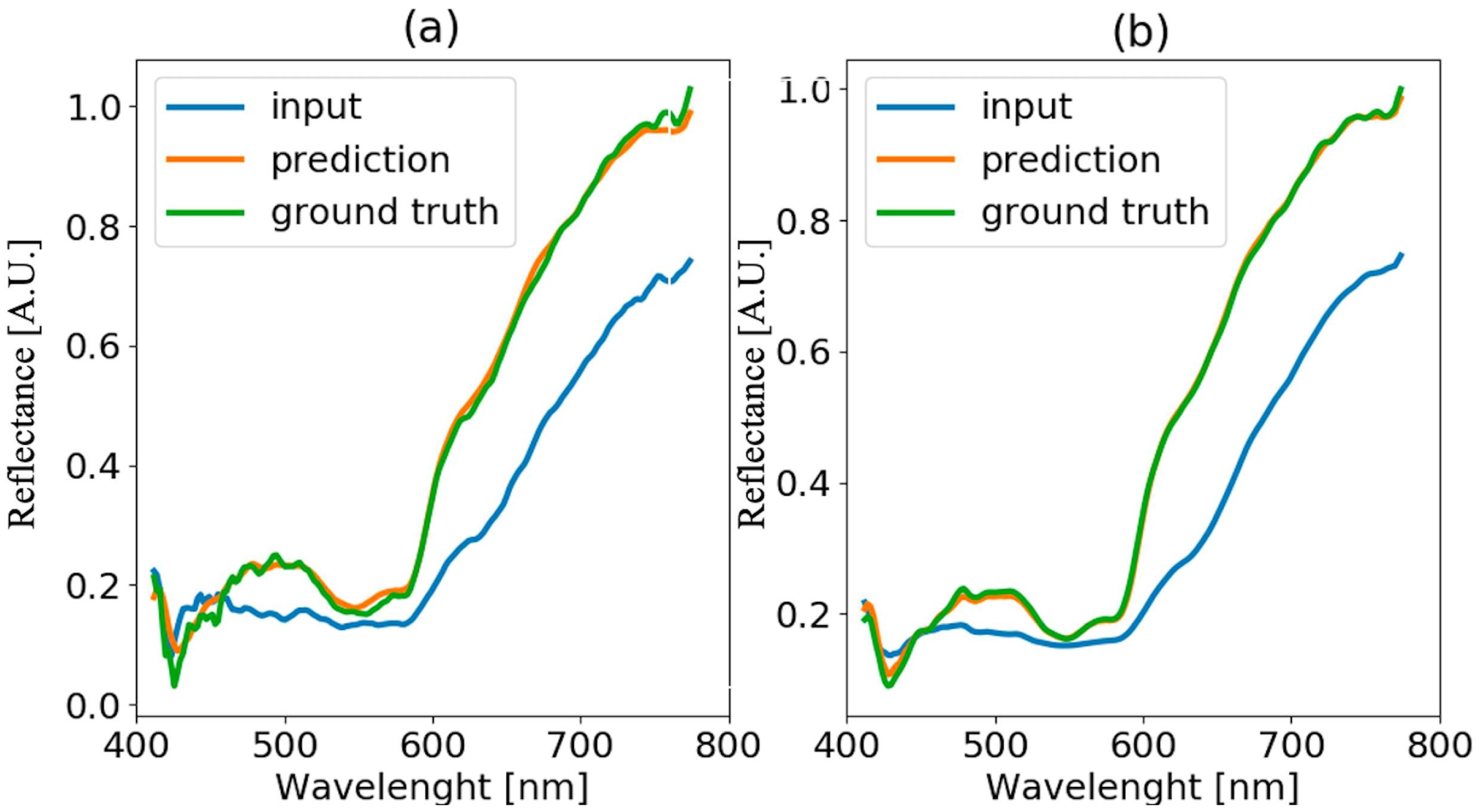
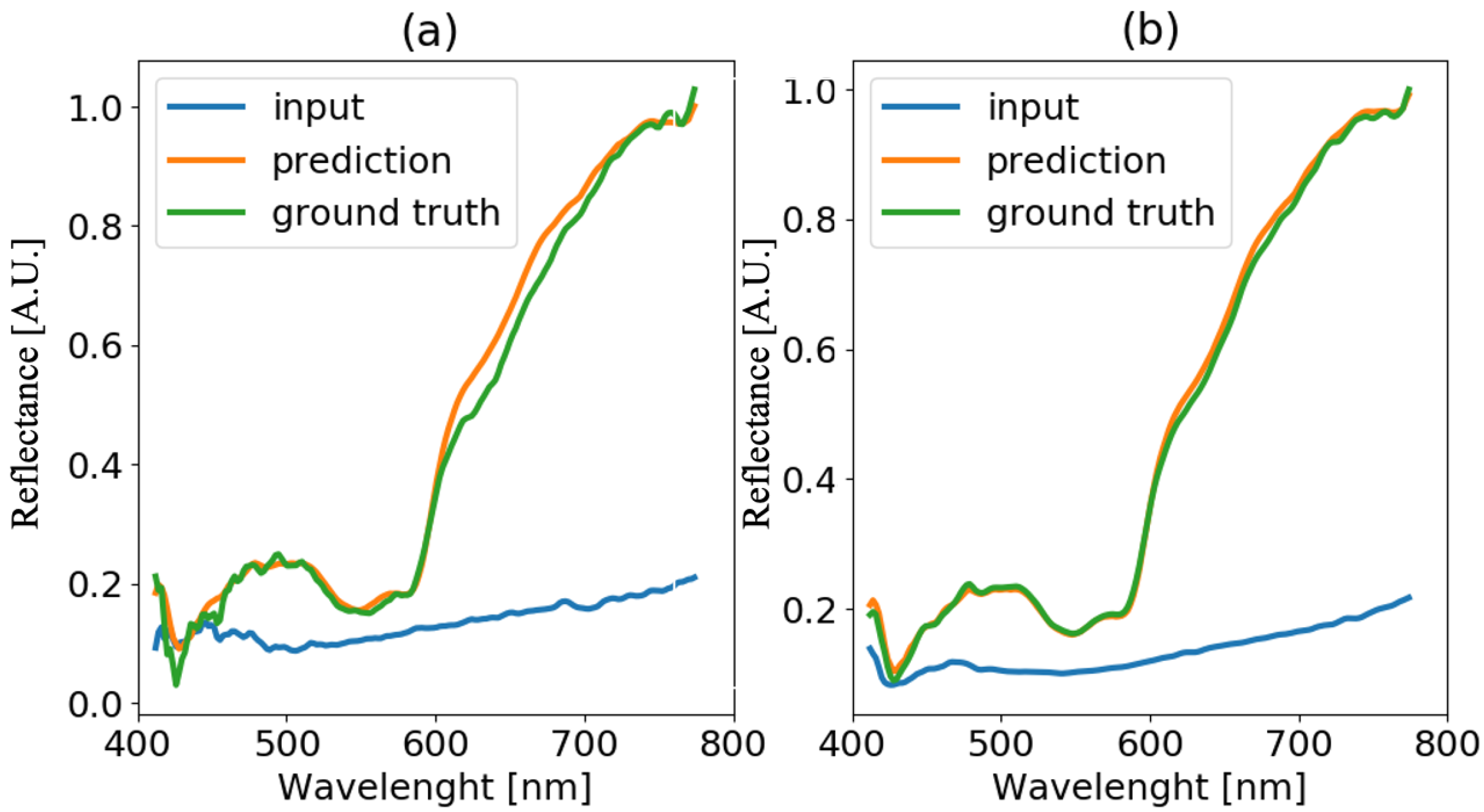
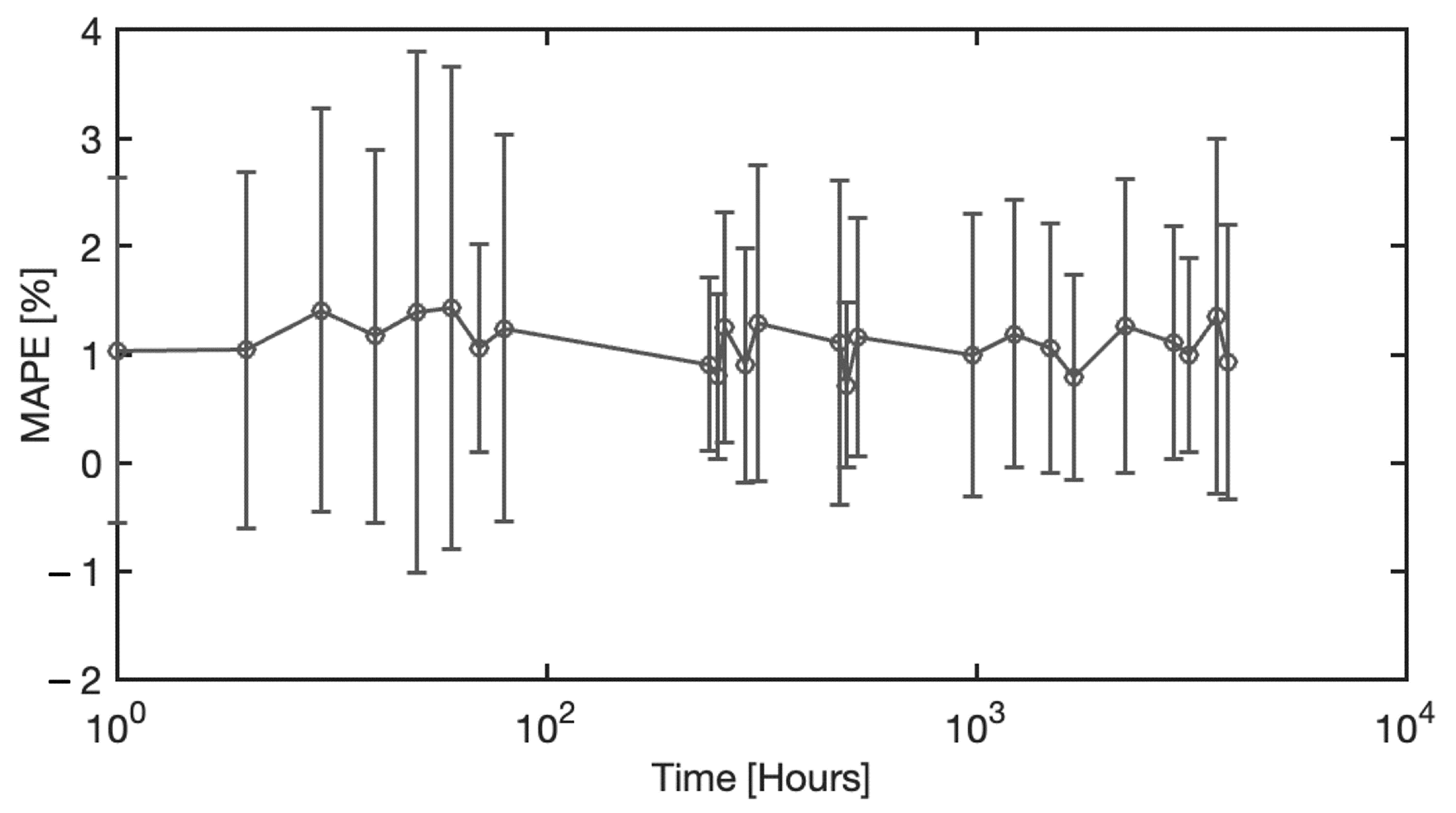
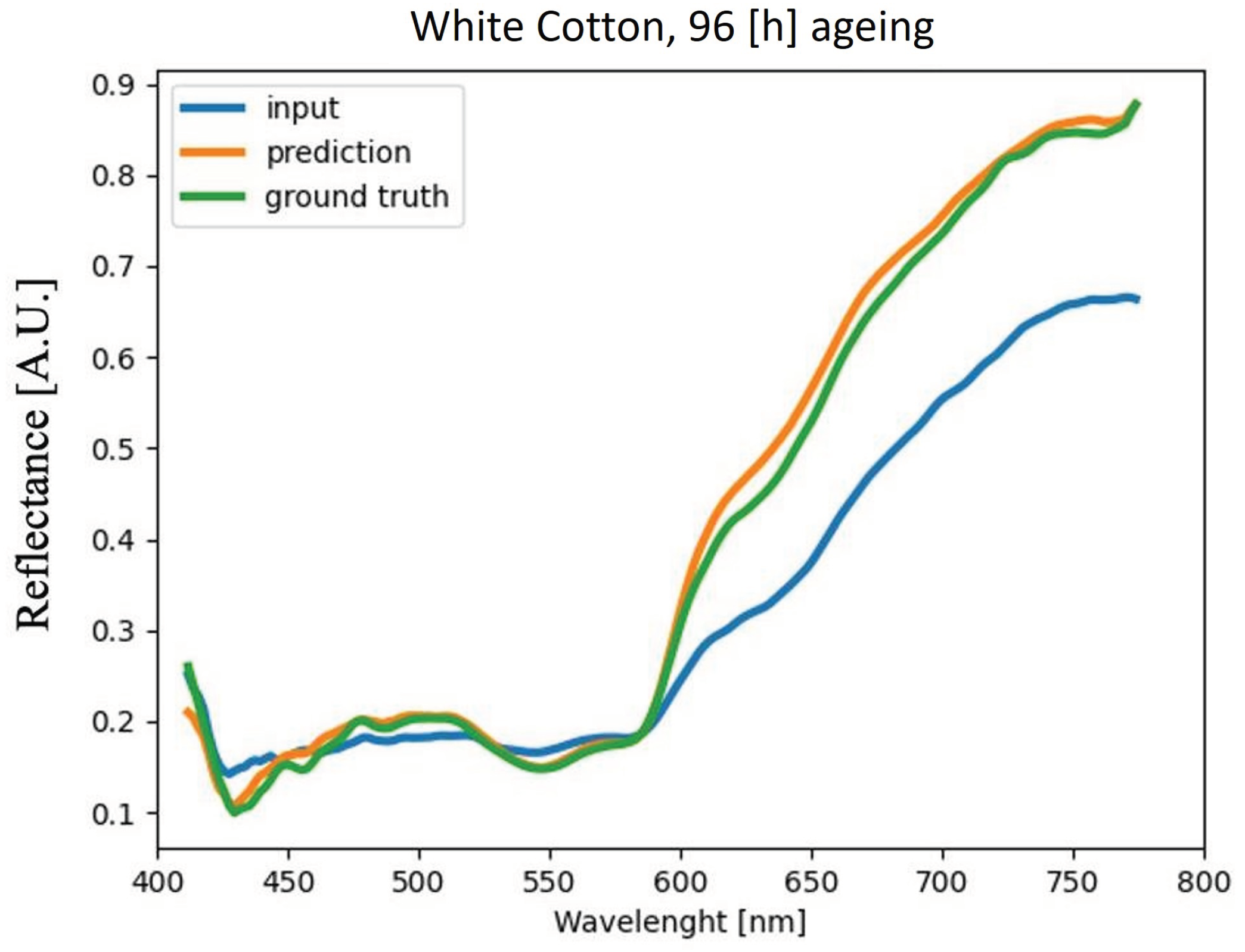
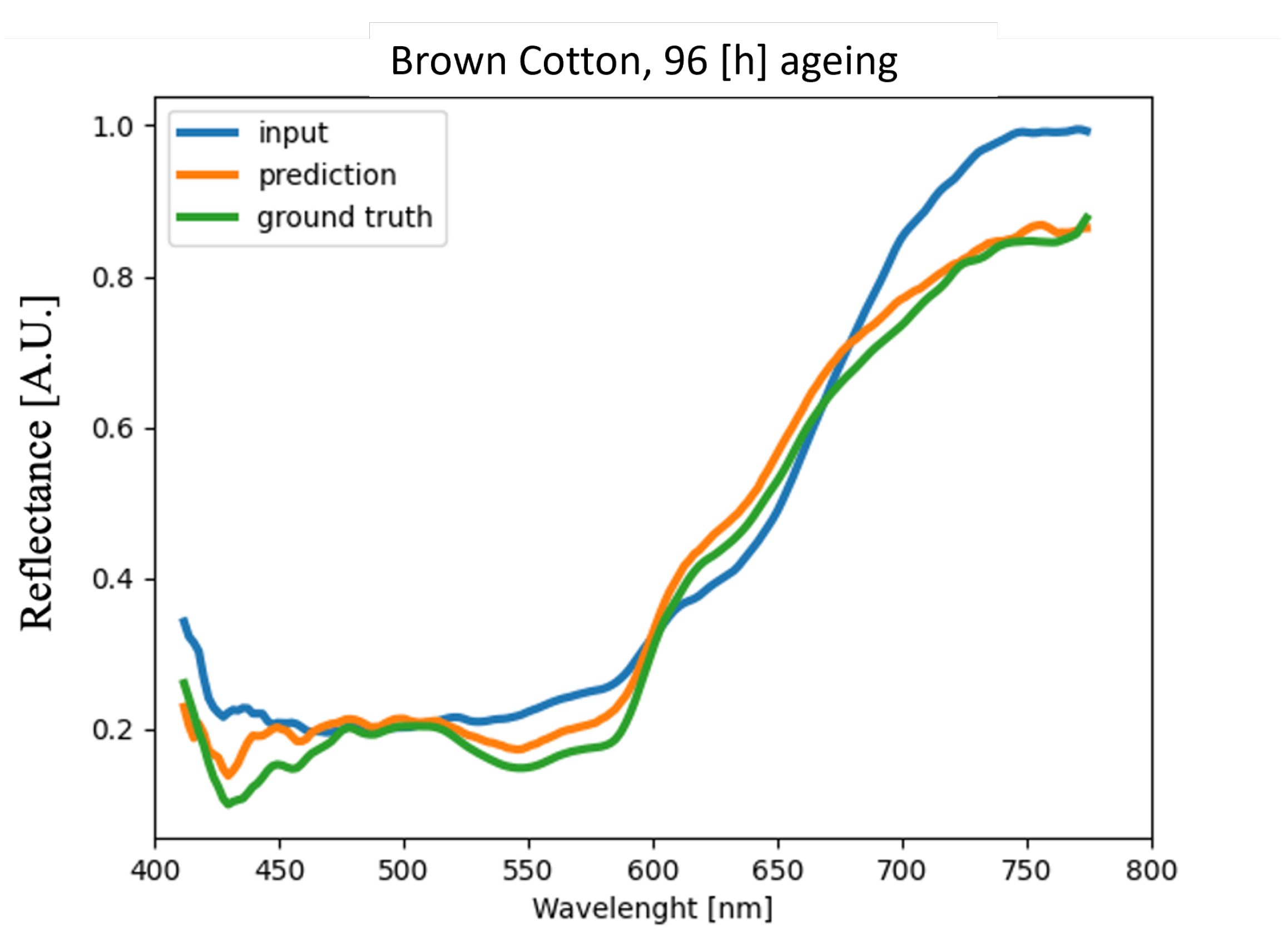
4.4. Analysis of Blood Spectra with Substrate Distortion Correction
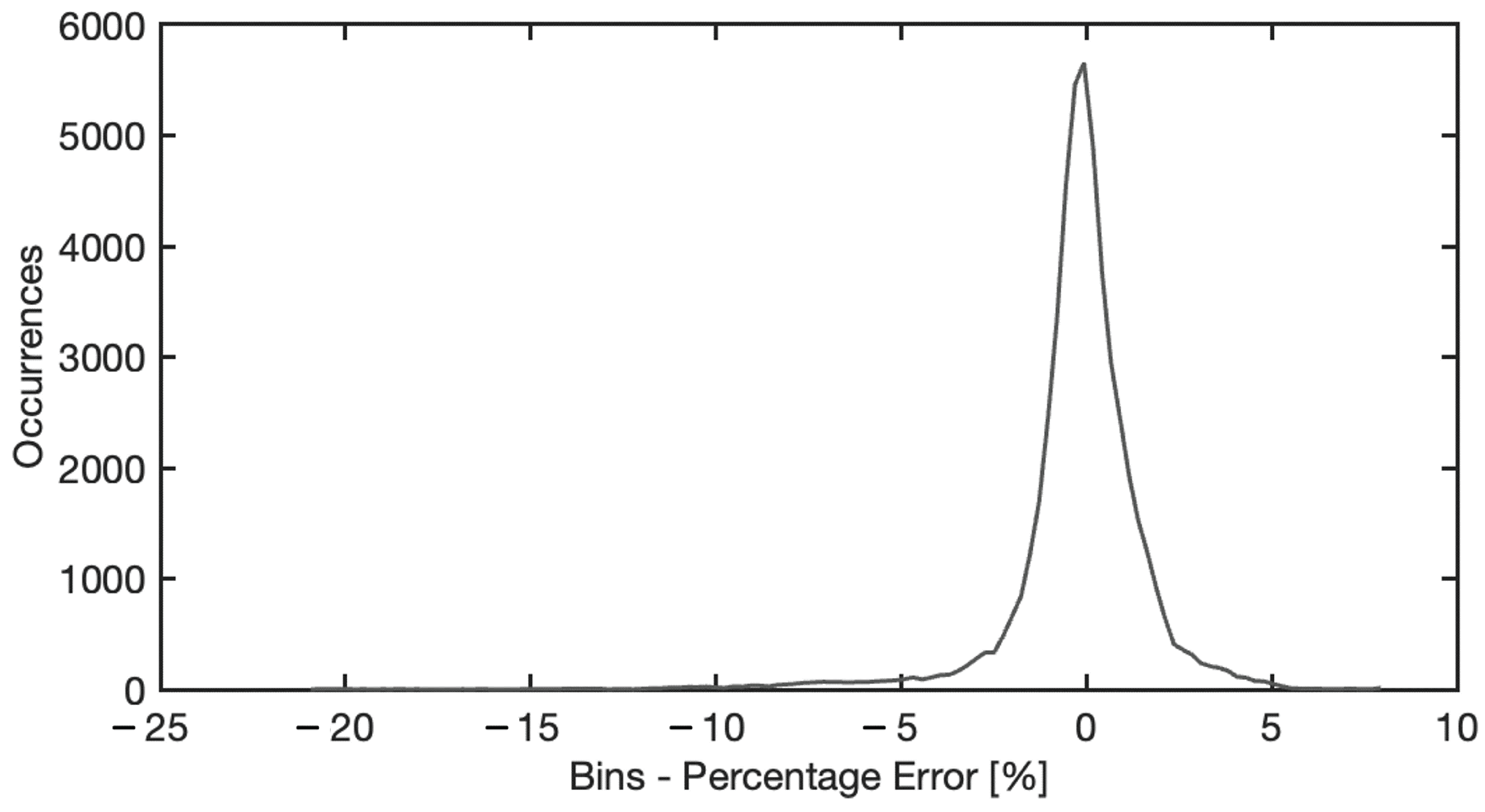
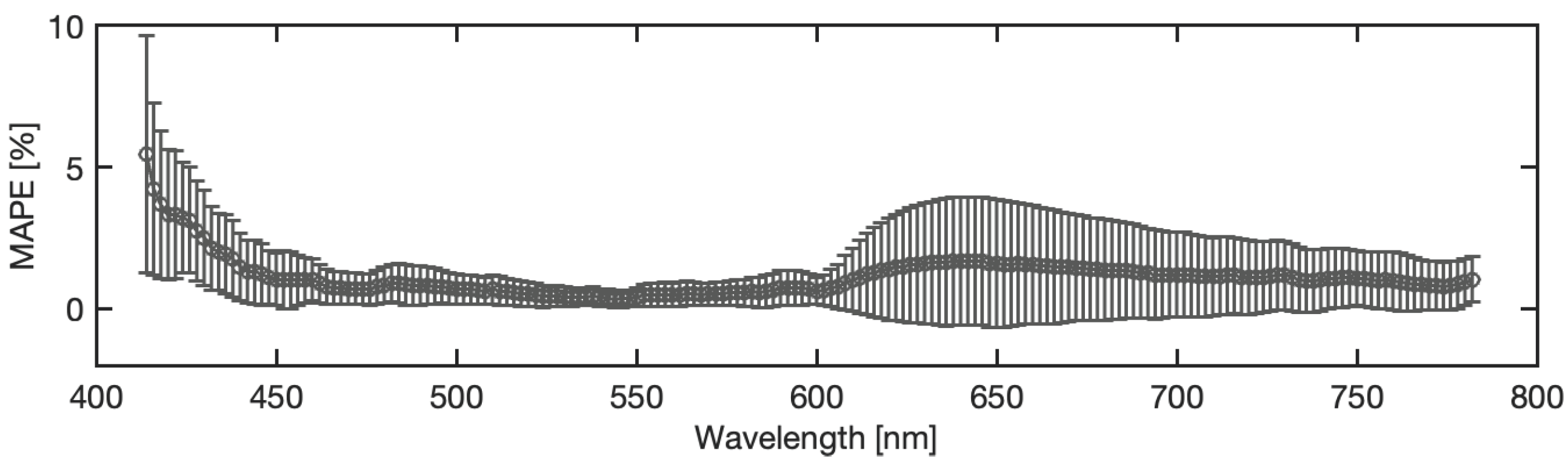
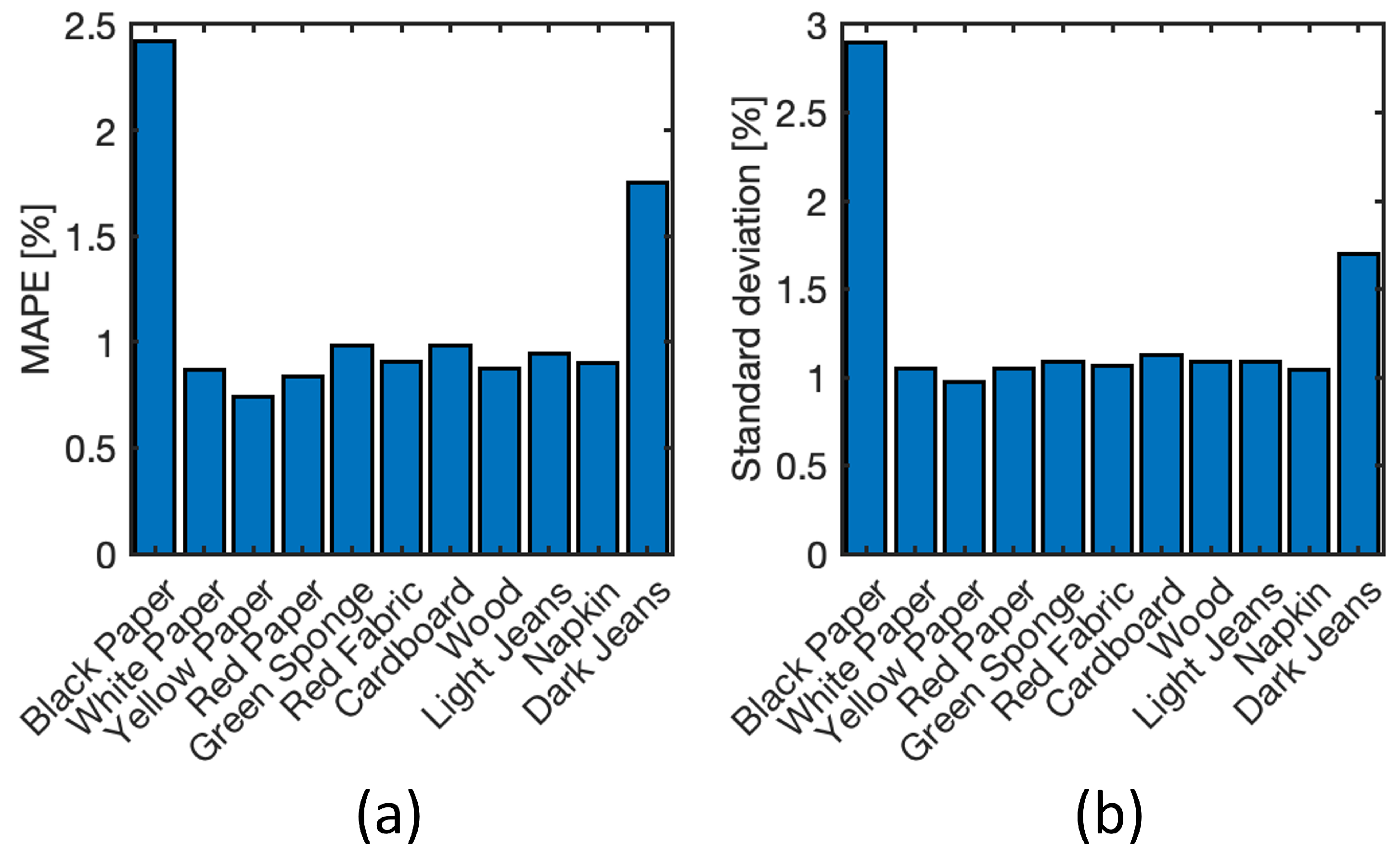
4.5. Neural Model Sensitivity Analysis
4.6. Test on New Materials
5. Discussion and Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| HSI | Hyper Spectral Imaging |
| DBS | Dry Blood Spot |
| NIR | Near Infra Red |
| IR | Infra Red |
| DL | Deep Learning |
| AI | Artificial Intelligence |
| SVM | Support Vector Machine |
| ANN | Artificial Neural Network |
| KNN | K-nearest neighbor Neural Network |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| MLP | Multi Layer Perceptron |
| GA | Genetic Algorithms |
| ROI | Region Of Interest |
| AU | Arbitrary Unit |
| MAPE | Mean Absolute Percentage Error |
| MAE | Mean Percentage Error |
References
- Lu, G.; Fei, B. Medical hyperspectral imaging: A review. J. Biomed. Opt. 2014, 19, 010901. [Google Scholar] [CrossRef] [PubMed]
- Indalecio-Céspedes, C.R.; Hernández-Romero, D.; Legaz, I.; Sánchez Rodríguez, M.F.; Osuna, E. Occult bloodstains detection in crime scene analysis. Forensic Chem. 2021, 26, 100368. [Google Scholar] [CrossRef]
- James, M.E. Degrees of contrast: Detection of latent bloodstains on fabric using an alternate light source (ALS) and the effects of washing. J. Forensic Sci. 2020, 66, 1024–1032. [Google Scholar] [CrossRef] [PubMed]
- Majda, A.; Wietecha-Posłuszny, R.; Mendys, A.; Wójtowicz, A.; Łydżba-Kopczyńska, B. Hyperspectral imaging and multivariate analysis in the dried blood spots investigations. Appl. Phys. A 2018, 124, 312. [Google Scholar] [CrossRef]
- Edelman, G.; Gaston, E.; van Leeuwen, T.; Cullen, P.; Aalders, M. Hyperspectral imaging for non-contact analysis of forensic traces. Forensic Sci. Int. 2012, 223, 28–39. [Google Scholar] [CrossRef]
- Edelman, G.; Manti, V.; van Ruth, S.M.; van Leeuwen, T.; Aalders, M. Identification and age estimation of blood stains on colored backgrounds by near infrared spectroscopy. Forensic Sci. Int. 2012, 220, 239–244. [Google Scholar] [CrossRef]
- Zulfiqar, M.; Ahmad, M.; Sohaib, A.; Mazzara, M.; Distefano, S. Hyperspectral Imaging for Bloodstain Identification. Sensors 2021, 21, 3045. [Google Scholar] [CrossRef]
- Książek, K.; Romaszewski, M.; Głomb, P.; Grabowski, B.; Cholewa, M. Blood Stain Classification with Hyperspectral Imaging and Deep Neural Networks. Sensors 2020, 20, 6666. [Google Scholar] [CrossRef]
- Pałka, F.; Książek, W.; Pławiak, P.; Romaszewski, M.; Książek, K. Hyperspectral Classification of Blood-Like Substances Using Machine Learning Methods Combined with Genetic Algorithms in Transductive and Inductive Scenarios. Sensors 2021, 21, 2293. [Google Scholar] [CrossRef]
- Yang, J.; Mathew, J.J.; Dube, R.R.; Messinger, D.W. Spectral feature characterization methods for blood stain detection in crime scene backgrounds. In Proceedings SPIE 9840, Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XXII; Velez-Reyes, M., Messinger, D.W., Eds.; SPIE: Baltimore, MD, USA, 2016. [Google Scholar] [CrossRef]
- Kerekes, J.; Baum, J. Hyperspectral Imaging System Modeling. Linc. Lab. J. 2003, 14, 117–130. [Google Scholar]
- Romaszewski, M.; Głomb, P.; Sochan, A.; Cholewa, M. A dataset for evaluating blood detection in hyperspectral images. Forensic Sci. Int. 2021, 320, 110701. [Google Scholar] [CrossRef]
- Bremmer, R.H.; Nadort, A.; van Leeuwen, T.G.; van Gemert, M.J.; Aalders, M.C. Age estimation of blood stains by hemoglobin derivative determination using reflectance spectroscopy. Forensic Sci. Int. 2011, 206, 166–171. [Google Scholar] [CrossRef]
- Bergmann, T.; Heinke, F.; Labudde, D. Towards substrate-independent age estimation of blood stains based on dimensionality reduction and k-nearest neighbor classification of absorbance spectroscopic data. Forensic Sci. Int. 2017, 278, 1–8. [Google Scholar] [CrossRef]
- Chen, R.; Zhang, L.; Zang, D.; Shen, W. Blood drop patterns: Formation and applications. Adv. Colloid Interface Sci. 2016, 231, 1–14. [Google Scholar] [CrossRef]
- McLaughlin, G.; Sikirzhytski, V.; Lednev, I.K. Circumventing substrate interference in the Raman spectroscopic identification of blood stains. Forensic Sci. Int. 2013, 231, 157–166. [Google Scholar] [CrossRef]
- Castellini, P.; Giulietti, N.; Falcionelli, N.; Dragoni, A.F.; Chiariotti, P. A neural network based microphone array approach to grid-less noise source localization. Appl. Acoust. 2021, 177, 107947. [Google Scholar] [CrossRef]
- Trevor, H.; Robert, T.; Jerome, F. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Rosenblatt, F. Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms. In Spartan Books; 1961. [Google Scholar]
- Rumelhart, D.E.; McClelland, J.L. Learning internal representations by error propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition: Foundations; MIT Press: Cambridge, MA, USA, 1986; Chapter 8; pp. 319–362. [Google Scholar]
- Sun, S.; Cao, Z.; Zhu, H.; Zhao, J. A survey of optimization methods from a machine learning perspective. IEEE Trans. Cybern. 2019, 50, 3668–3681. [Google Scholar] [CrossRef]
- Gaspar, P.; Carbonell, J.; Oliveira, J.L. On the parameter optimization of Support Vector Machines for binary classification. J. Integr. Bioinform. 2012, 9, 33–43. [Google Scholar] [CrossRef]
- Turner, R.; Eriksson, D.; McCourt, M.; Kiili, J.; Laaksonen, E.; Xu, Z.; Guyon, I. Bayesian Optimization is Superior to Random Search for Machine Learning Hyperparameter Tuning: Analysis of the Black-Box Optimization Challenge 2020. Proc. Mach. Learn. Res. 2021, 133, 3–26. [Google Scholar] [CrossRef]
- Joy, T.T.; Rana, S.; Gupta, S.; Venkatesh, S. Fast Hyperparameter Tuning using Bayesian Optimization with Directional Derivatives. Knowl.-Based Syst. 2020, 205, 106247. [Google Scholar] [CrossRef]
- Nguyen, V. Bayesian Optimization for Accelerating Hyper-Parameter Tuning. In Proceedings of the 2019 IEEE Second International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), Sardinia, Italy, 3–5 June 2019. [Google Scholar] [CrossRef]
- Joy, T.T.; Rana, S.; Gupta, S.; Venkatesh, S. Hyperparameter tuning for big data using Bayesian optimisation. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016. [Google Scholar] [CrossRef]
- Nogueira, F. Bayesian Optimization: Open Source Constrained Global Optimization Tool for Python. 2014. Available online: https://github.com/fmfn/BayesianOptimization (accessed on 6 June 2022).
- Agrawal, T. Bayesian Optimization. In Hyperparameter Optimization in Machine Learning; Apress: Berkeley, CA, USA, 2020; pp. 81–108. [Google Scholar] [CrossRef]
- Datta, L. A survey on activation functions and their relation with xavier and he normal initialization. arXiv 2020, arXiv:2004.06632. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Stock, J.H.; Watson, M.W. Introduzione all’econometria; Pearson Italia Spa: Milan, Italy, 2005. [Google Scholar]
- Raschka, S. Model evaluation, model selection, and algorithm selection in machine learning. arXiv 2018, arXiv:1811.12808. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Substrate | ID |
|---|---|
| Black paper | |
| White paper | |
| Yellow paper | |
| Red paper | |
| White ceramic tile | |
| Green sponge | |
| Red fabric | |
| Cardboard | |
| Wood | |
| Light Jeans | |
| Napkin | |
| Dark jeans |
| MAPE [%] | ||||
|---|---|---|---|---|
| 1 [h] | 24 [h] | 47 [h] | 96 [h] | |
| White Cotton | 2.85% | 4.07% | 4.35% | 4.12% |
| Brown Cotton | 4.88% | 3.64% | 3.72% | 4.91% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Giulietti, N.; Discepolo, S.; Castellini, P.; Martarelli, M. Correction of Substrate Spectral Distortion in Hyper-Spectral Imaging by Neural Network for Blood Stain Characterization. Sensors 2022, 22, 7311. https://doi.org/10.3390/s22197311
Giulietti N, Discepolo S, Castellini P, Martarelli M. Correction of Substrate Spectral Distortion in Hyper-Spectral Imaging by Neural Network for Blood Stain Characterization. Sensors. 2022; 22(19):7311. https://doi.org/10.3390/s22197311
Chicago/Turabian StyleGiulietti, Nicola, Silvia Discepolo, Paolo Castellini, and Milena Martarelli. 2022. "Correction of Substrate Spectral Distortion in Hyper-Spectral Imaging by Neural Network for Blood Stain Characterization" Sensors 22, no. 19: 7311. https://doi.org/10.3390/s22197311
APA StyleGiulietti, N., Discepolo, S., Castellini, P., & Martarelli, M. (2022). Correction of Substrate Spectral Distortion in Hyper-Spectral Imaging by Neural Network for Blood Stain Characterization. Sensors, 22(19), 7311. https://doi.org/10.3390/s22197311