
Gait-ViT: Gait Recognition with Vision Transformer

Abstract
:1. Introduction
- The gait images are represented as GEIs to capture the significant limb movements in gait while suppressing the effects of noise, shadow, and incomplete silhouettes.
- The Vision Transformer model encodes prominent gait features on the strength of multi-head attention mechanism, receptive fields, layer normalization, global operation, and residual connections, which elevates the performance of the proposed method.
- The performance of the proposed Gait-ViT method is evaluated on three datasets, namely CASIA B, OU-ISIR D, and OU-LP datasets.
2. Related Works
2.1. Handcrafted Approach
2.2. Deep Learning
2.3. Attention Models
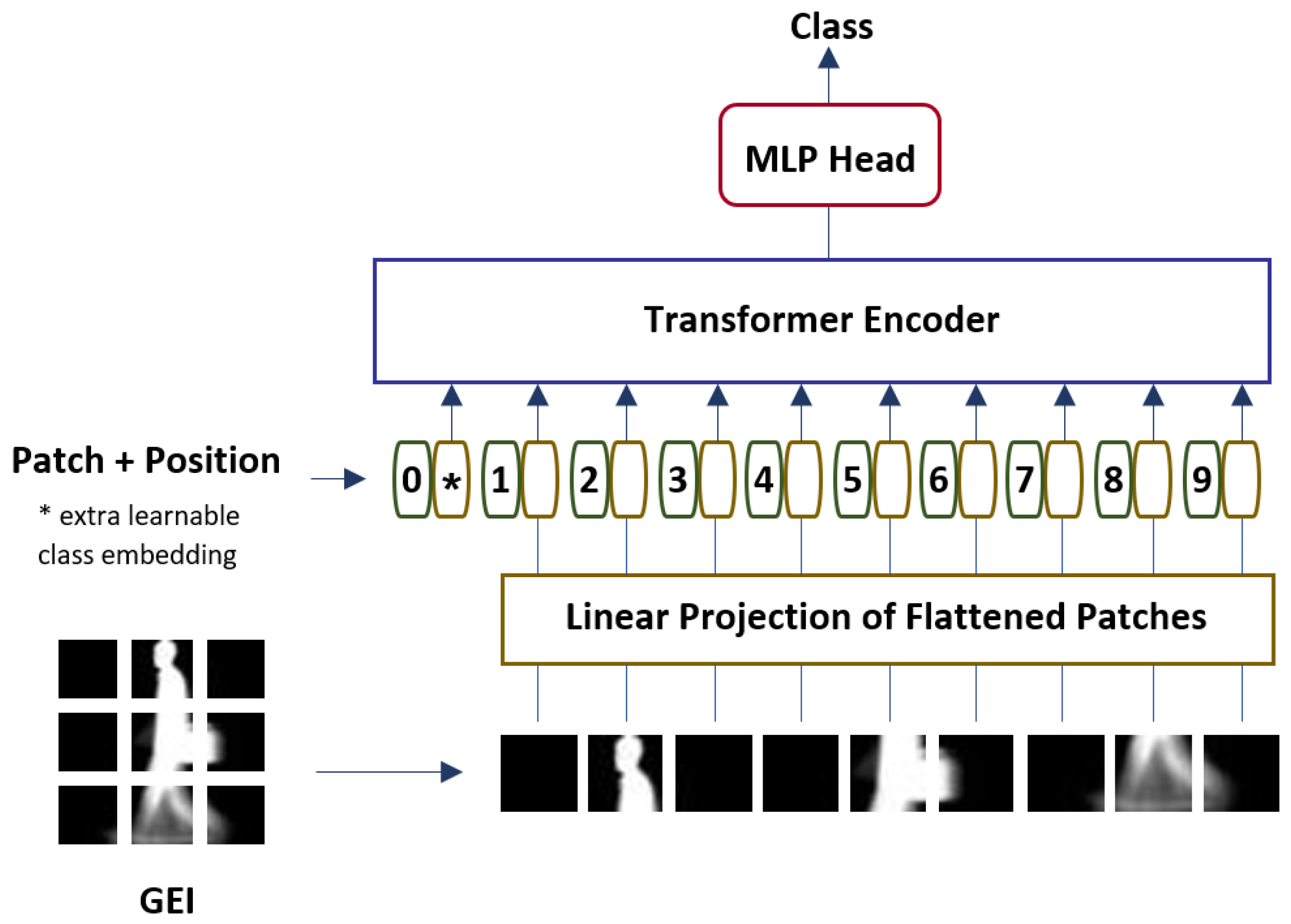
3. Gait Recognition with Vision Transformer
3.1. Gait Energy Image
3.2. Vision Transformer for Gait Recognition (Gait-ViT)
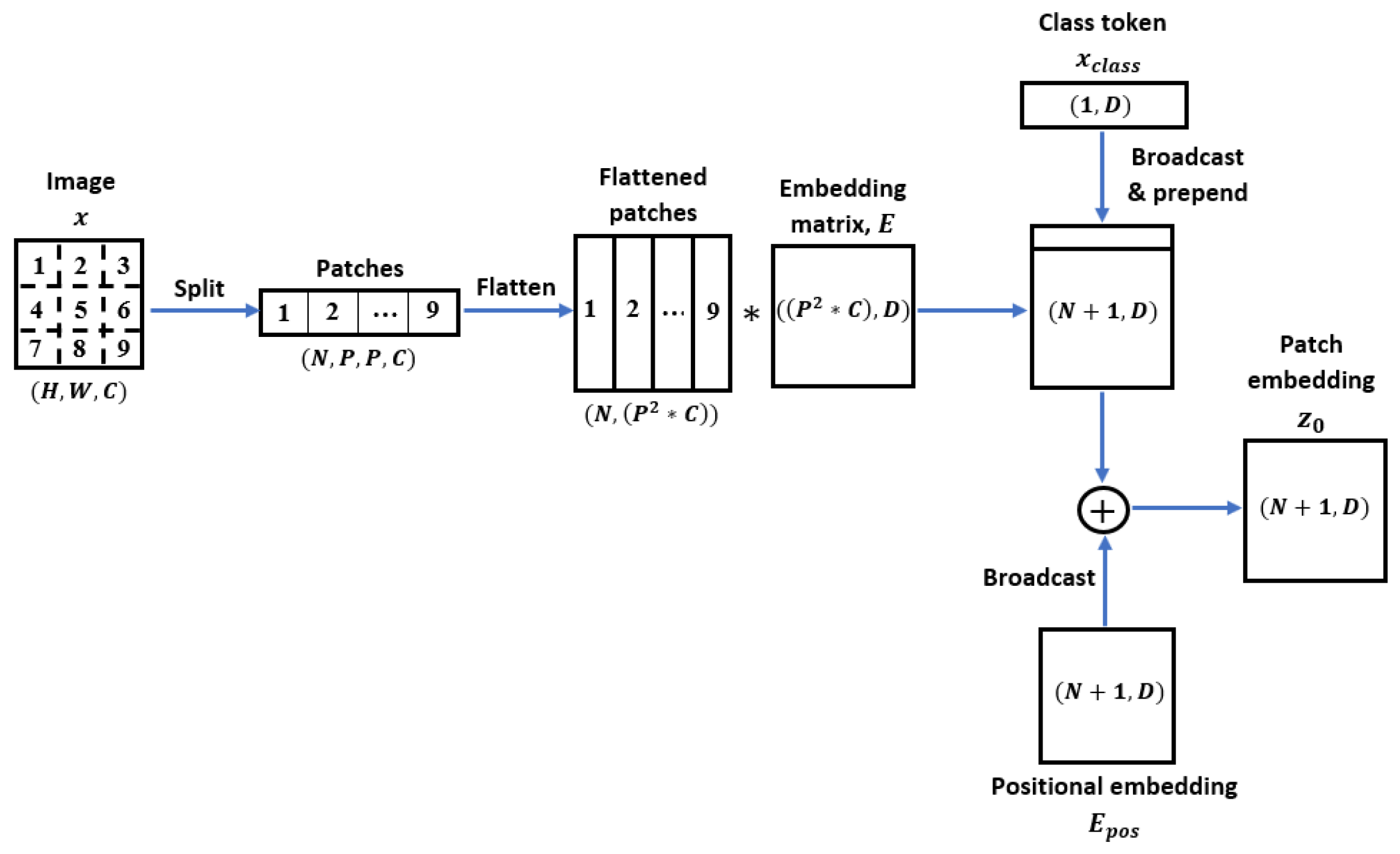
3.2.1. Linear Projection of Flattened Patches
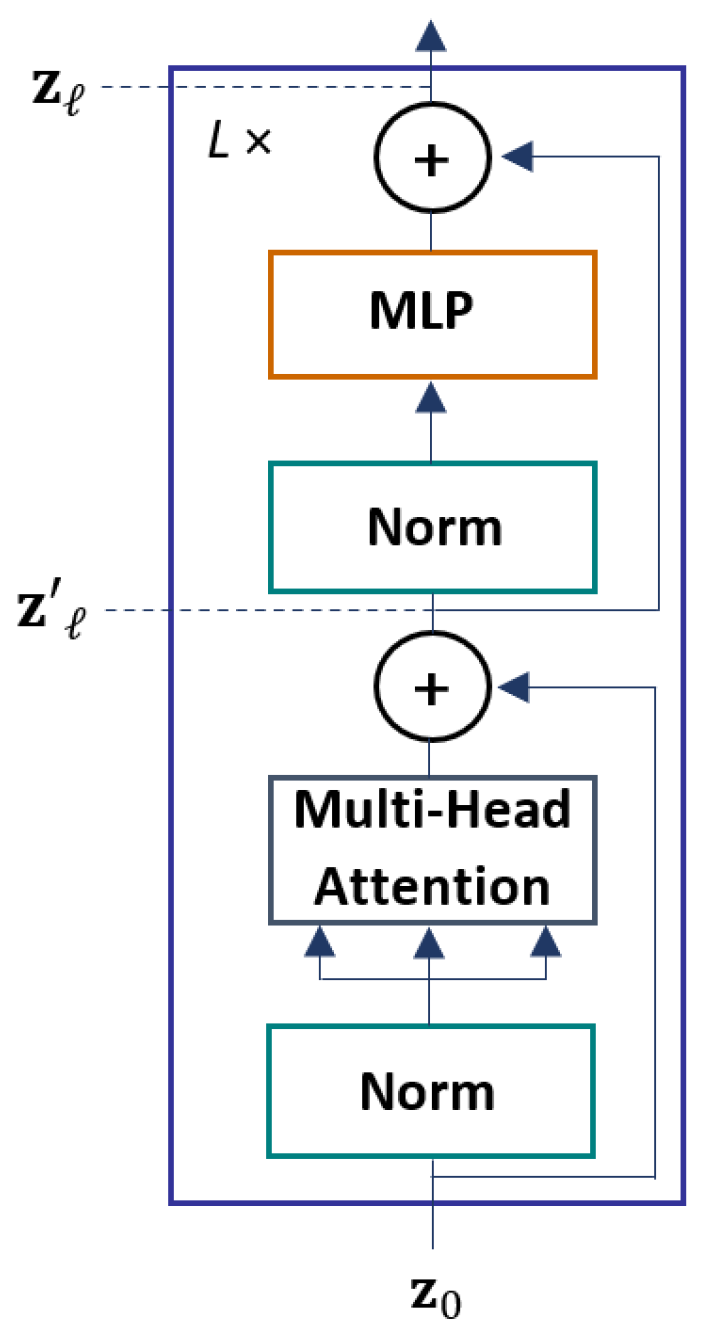
3.2.2. Transformer Encoder
- Processes in Multi-head Self-Attention (MSA)
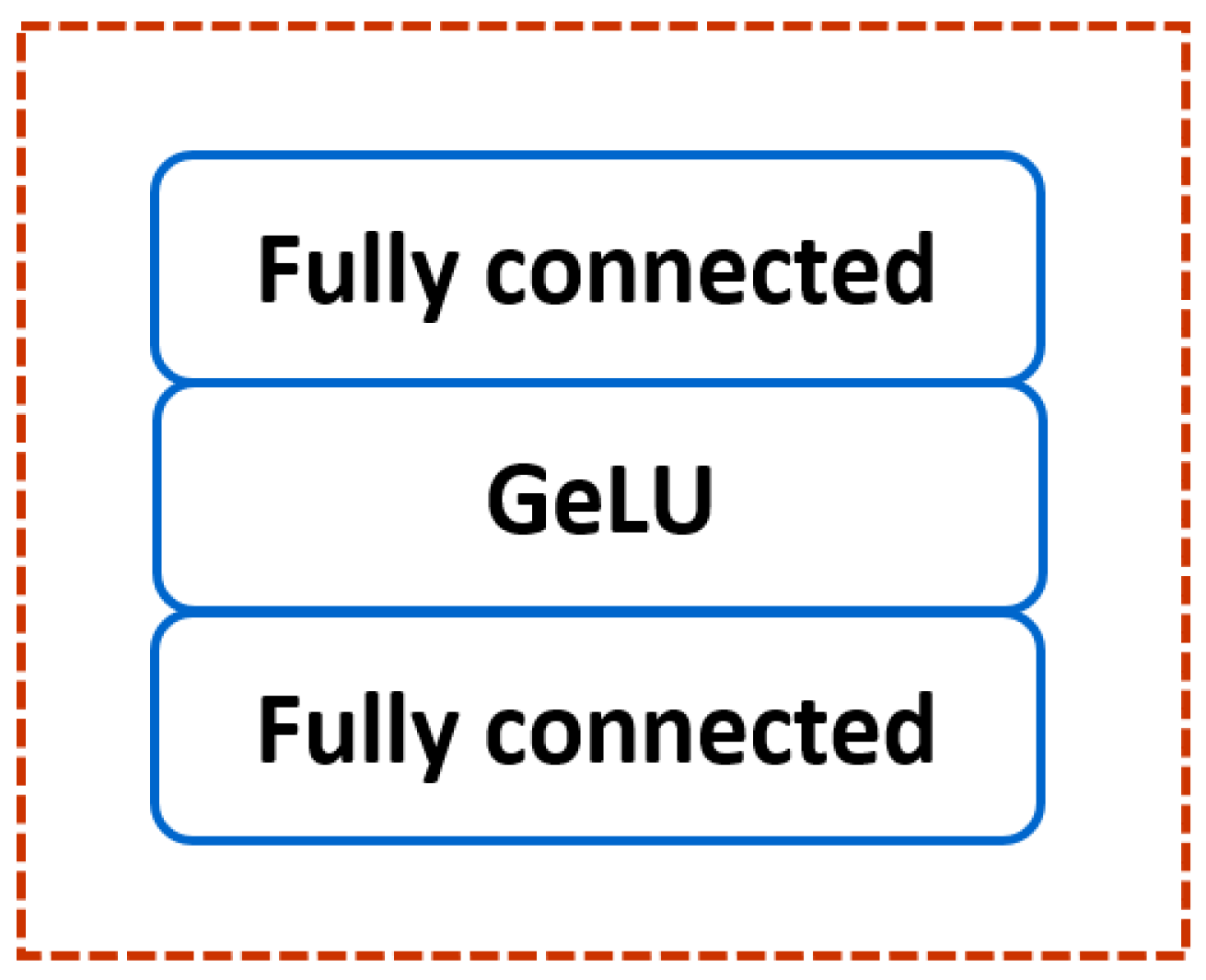
- Processes in Multi-layer Perceptron (MLP)
4. Experiments and Discussion
4.1. Datasets
4.2. Hyperparameter Tuning
4.3. Comparison with the Existing Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, X.; Zhang, J. Gait feature extraction and gait classification using two-branch CNN. Multimed. Tools Appl. 2020, 79, 2917–2930. [Google Scholar] [CrossRef]
- Sharif, M.; Attique, M.; Tahir, M.Z.; Yasmim, M.; Saba, T.; Tanik, U.J. A machine learning method with threshold based parallel feature fusion and feature selection for automated gait recognition. J. Organ. End User Comput. (JOEUC) 2020, 32, 67–92. [Google Scholar] [CrossRef]
- Ahmed, M.; Al-Jawad, N.; Sabir, A.T. Gait recognition based on Kinect sensor. In Proceedings of the Real-Time Image and Video Processing, Brussels, Belgium, 16–17 April 2014; Volume 9139, p. 91390B. [Google Scholar]
- Kovač, J.; Štruc, V.; Peer, P. Frame–based classification for cross-speed gait recognition. Multimed. Tools Appl. 2019, 78, 5621–5643. [Google Scholar] [CrossRef]
- Deng, M.; Wang, C. Human gait recognition based on deterministic learning and data stream of Microsoft Kinect. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3636–3645. [Google Scholar] [CrossRef]
- Sah, S.; Panday, S.P. Model based gait recognition using weighted KNN. In Proceedings of the 8th IOE Graduate Conference, Online, 15–17 June 2020. [Google Scholar]
- Lee, C.P.; Tan, A.W.; Tan, S.C. Gait probability image: An information-theoretic model of gait representation. J. Vis. Commun. Image Represent. 2014, 25, 1489–1492. [Google Scholar] [CrossRef]
- Lee, C.P.; Tan, A.W.; Tan, S.C. Time-sliced averaged motion history image for gait recognition. J. Vis. Commun. Image Represent. 2014, 25, 822–826. [Google Scholar] [CrossRef]
- Lee, C.P.; Tan, A.W.; Tan, S.C. Gait recognition with transient binary patterns. J. Vis. Commun. Image Represent. 2015, 33, 69–77. [Google Scholar] [CrossRef]
- Lee, C.P.; Tan, A.W.; Tan, S.C. Gait recognition via optimally interpolated deformable contours. Pattern Recognit. Lett. 2013, 34, 663–669. [Google Scholar] [CrossRef]
- Lee, C.P.; Tan, A.; Lim, K. Review on vision-based gait recognition: Representations, classification schemes and datasets. Am. J. Appl. Sci. 2017, 14, 252–266. [Google Scholar] [CrossRef]
- Mogan, J.N.; Lee, C.P.; Tan, A.W. Gait recognition using temporal gradient patterns. In Proceedings of the 2017 5th International Conference on Information and Communication Technology (ICoIC7), Melaka, Malaysia, 17–19 May 2017; pp. 1–4. [Google Scholar]
- Rida, I. Towards human body-part learning for model-free gait recognition. arXiv 2019, arXiv:1904.01620. [Google Scholar]
- Mogan, J.N.; Lee, C.P.; Lim, K.M. Gait recognition using histograms of temporal gradients. Proc. J. Phys. Conf. Ser. 2020, 1502, 012051. [Google Scholar] [CrossRef]
- Yeoh, T.; Aguirre, H.E.; Tanaka, K. Clothing-invariant gait recognition using convolutional neural network. In Proceedings of the 2016 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Phuket, Thailand, 24–27 October 2016; pp. 1–5. [Google Scholar]
- Takemura, N.; Makihara, Y.; Muramatsu, D.; Echigo, T.; Yagi, Y. On input/output architectures for convolutional neural network-based cross-view gait recognition. IEEE Trans. Circuits Syst. Video Technol. 2017, 29, 2708–2719. [Google Scholar] [CrossRef]
- Tong, S.; Fu, Y.; Yue, X.; Ling, H. Multi-view gait recognition based on a spatial-temporal deep neural network. IEEE Access 2018, 6, 57583–57596. [Google Scholar] [CrossRef]
- Chao, H.; Wang, K.; He, Y.; Zhang, J.; Feng, J. GaitSet: Cross-view gait recognition through utilizing gait as a deep set. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3467–3478. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Zeng, Y.; Pu, J.; Shan, H.; He, P.; Zhang, J. Selfgait: A Spatiotemporal Representation Learning Method for Self-Supervised Gait Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Online, 7–13 May 2021; pp. 2570–2574. [Google Scholar]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Bouridane, A. Gait recognition for person re-identification. J. Supercomput. 2021, 77, 3653–3672. [Google Scholar] [CrossRef]
- Chai, T.; Mei, X.; Li, A.; Wang, Y. Silhouette-Based View-Embeddings for Gait Recognition Under Multiple Views. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2319–2323. [Google Scholar]
- Mogan, J.N.; Lee, C.P.; Lim, K.M. Advances in Vision-Based Gait Recognition: From Handcrafted to Deep Learning. Sensors 2022, 22, 5682. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, J.; Li, J.; Zhao, D. Gait recognition based on 3D skeleton joints captured by kinect. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3151–3155. [Google Scholar]
- Zhen, H.; Deng, M.; Lin, P.; Wang, C. Human gait recognition based on deterministic learning and Kinect sensor. In Proceedings of the 2018 Chinese Control and Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 1842–1847. [Google Scholar]
- Choi, S.; Kim, J.; Kim, W.; Kim, C. Skeleton-based gait recognition via robust frame-level matching. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2577–2592. [Google Scholar] [CrossRef]
- Lima, V.C.; Melo, V.H.; Schwartz, W.R. Simple and efficient pose-based gait recognition method for challenging environments. Pattern Anal. Appl. 2021, 24, 497–507. [Google Scholar] [CrossRef]
- Rida, I.; Boubchir, L.; Al-Maadeed, N.; Al-Maadeed, S.; Bouridane, A. Robust model-free gait recognition by statistical dependency feature selection and globality-locality preserving projections. In Proceedings of the 2016 39th International Conference on Telecommunications and Signal Processing (TSP), Vienna, Austria, 27–29 June 2016; pp. 652–655. [Google Scholar]
- Mogan, J.N.; Lee, C.P.; Lim, K.M.; Tan, A.W. Gait recognition using binarized statistical image features and histograms of oriented gradients. In Proceedings of the 2017 International Conference on Robotics, Automation and Sciences (ICORAS), Melaka, Malaysia, 27–29 November 2017; pp. 1–6. [Google Scholar]
- Wang, X.; Wang, J.; Yan, K. Gait recognition based on Gabor wavelets and (2D) 2PCA. Multimed. Tools Appl. 2018, 77, 12545–12561. [Google Scholar] [CrossRef]
- Arshad, H.; Khan, M.A.; Sharif, M.; Yasmin, M.; Javed, M.Y. Multi-level features fusion and selection for human gait recognition: An optimized framework of Bayesian model and binomial distribution. Int. J. Mach. Learn. Cybern. 2019, 10, 3601–3618. [Google Scholar] [CrossRef]
- Wolf, T.; Babaee, M.; Rigoll, G. Multi-view gait recognition using 3D convolutional neural networks. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 4165–4169. [Google Scholar]
- Wang, X.; Zhang, J.; Yan, W.Q. Gait recognition using multichannel convolution neural networks. Neural Comput. Appl. 2020, 32, 14275–14285. [Google Scholar] [CrossRef]
- Su, J.; Zhao, Y.; Li, X. Deep metric learning based on center-ranked loss for gait recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4077–4081. [Google Scholar]
- Song, C.; Huang, Y.; Huang, Y.; Jia, N.; Wang, L. Gaitnet: An end-to-end network for gait based human identification. Pattern Recognit. 2019, 96, 106988. [Google Scholar] [CrossRef]
- Ding, X.; Wang, K.; Wang, C.; Lan, T.; Liu, L. Sequential convolutional network for behavioral pattern extraction in gait recognition. Neurocomputing 2021, 463, 411–421. [Google Scholar] [CrossRef]
- Mogan, J.N.; Lee, C.P.; Anbananthen, K.S.M.; Lim, K.M. Gait-DenseNet: A Hybrid Convolutional Neural Network for Gait Recognition. IAENG Int. J. Comput. Sci. 2022, 49, 393–400. [Google Scholar]
- Mogan, J.N.; Lee, C.P.; Lim, K.M.; Muthu, K.S. VGG16-MLP: Gait Recognition with Fine-Tuned VGG-16 and Multilayer Perceptron. Appl. Sci. 2022, 12, 7639. [Google Scholar] [CrossRef]
- Li, X.; Makihara, Y.; Xu, C.; Yagi, Y.; Ren, M. Joint intensity transformer network for gait recognition robust against clothing and carrying status. IEEE Trans. Inf. Forensics Secur. 2019, 14, 3102–3115. [Google Scholar] [CrossRef]
- Xu, C.; Makihara, Y.; Li, X.; Yagi, Y.; Lu, J. Cross-view gait recognition using pairwise spatial transformer networks. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 260–274. [Google Scholar] [CrossRef]
- Wang, X.; Yan, W.Q. Non-local gait feature extraction and human identification. Multimed. Tools Appl. 2021, 80, 6065–6078. [Google Scholar] [CrossRef]
- Lam, T.H.; Cheung, K.H.; Liu, J.N. Gait flow image: A silhouette-based gait representation for human identification. Pattern Recognit. 2011, 44, 973–987. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Yu, S.; Tan, D.; Tan, T. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 4, pp. 441–444. [Google Scholar]
- Makihara, Y.; Mannami, H.; Tsuji, A.; Hossain, M.A.; Sugiura, K.; Mori, A.; Yagi, Y. The OU-ISIR gait database comprising the treadmill dataset. IPSJ Trans. Comput. Vis. Appl. 2012, 4, 53–62. [Google Scholar] [CrossRef]
- Iwama, H.; Okumura, M.; Makihara, Y.; Yagi, Y. The OU-ISIR gait database comprising the large population dataset and performance evaluation of gait recognition. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1511–1521. [Google Scholar] [CrossRef]
- Shiraga, K.; Makihara, Y.; Muramatsu, D.; Echigo, T.; Yagi, Y. Geinet: View-invariant gait recognition using a convolutional neural network. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; pp. 1–8. [Google Scholar]
- Alotaibi, M.; Mahmood, A. Improved gait recognition based on specialized deep convolutional neural network. Comput. Vis. Image Underst. 2017, 164, 103–110. [Google Scholar] [CrossRef]
- Min, P.P.; Sayeed, S.; Ong, T.S. Gait recognition using deep convolutional features. In Proceedings of the 2019 7th International Conference on Information and Communication Technology (ICoICT), Kuala Lumpur, Malaysia, 24–26 July 2019; pp. 1–5. [Google Scholar]
- Aung, H.M.L.; Pluempitiwiriyawej, C. Gait Biometric-based Human Recognition System Using Deep Convolutional Neural Network in Surveillance System. In Proceedings of the 2020 Asia Conference on Computers and Communications (ACCC), Singapore, 18–20 September 2020; pp. 47–51. [Google Scholar]
- Balamurugan, S. Deep Features Based Multiview Gait Recognition. Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 472–478. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Number of Subjects | Sequences | Angle Views | Variations |
|---|---|---|---|---|
| CASIA-B | 124 | 10 | 11 | Normal walking, Carrying condition, Clothing |
| OU-ISIR DB | 100 | 370 | 1 | Steady walking |
| OU-ISIR DB | 100 | 370 | 1 | Fluctuated walking |
| OU-LP (Sequence A) | 3916 | 2 | 4 | 4 viewing angles |
| Batch Size | Accuracy (%) | Training Time (s) |
|---|---|---|
| 32 | 99.93 | 2555.7536 |
| 64 | 99.41 | 739.3975 |
| 128 | 99.34 | 621.2719 |
| Learning Rate | Accuracy (%) | Training Time (s) |
|---|---|---|
| 0.00001 | 99.34 | 2259.2996 |
| 0.0001 | 99.93 | 2555.7536 |
| 0.001 | 99.41 | 3025.1851 |
| 0.01 | 43.86 | 1881.2865 |
| Input Size | Accuracy (%) | Training Time (s) |
|---|---|---|
| 32 × 32 | 99.34 | 600.9491 |
| 64 × 64 | 99.93 | 2555.7536 |
| 128 × 128 | 98.60 | 2838.1245 |
| Optimizer | Accuracy (%) | Training Time (s) |
|---|---|---|
| SGD | 76.89 | 9449.4783 |
| Adam | 99.93 | 2555.7536 |
| Nadam | 99.63 | 3781.5499 |
| Hyperparameters | Tested Values | Optimal Value |
|---|---|---|
| Batch Size | 32, 64, 128 | 32 |
| Learning Rate | 0.00001, 0.0001, 0.001, 0.01 | 0.0001 |
| Input Size | 32 × 32, 64 × 64, 128 × 128 | 64 × 64 |
| Optimizer | SGD, Adam, Nadam | Adam |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mogan, J.N.; Lee, C.P.; Lim, K.M.; Muthu, K.S. Gait-ViT: Gait Recognition with Vision Transformer. Sensors 2022, 22, 7362. https://doi.org/10.3390/s22197362
Mogan JN, Lee CP, Lim KM, Muthu KS. Gait-ViT: Gait Recognition with Vision Transformer. Sensors. 2022; 22(19):7362. https://doi.org/10.3390/s22197362
Chicago/Turabian StyleMogan, Jashila Nair, Chin Poo Lee, Kian Ming Lim, and Kalaiarasi Sonai Muthu. 2022. "Gait-ViT: Gait Recognition with Vision Transformer" Sensors 22, no. 19: 7362. https://doi.org/10.3390/s22197362
APA StyleMogan, J. N., Lee, C. P., Lim, K. M., & Muthu, K. S. (2022). Gait-ViT: Gait Recognition with Vision Transformer. Sensors, 22(19), 7362. https://doi.org/10.3390/s22197362