1. Introduction
Monitoring computer networks in recent times has become more convenient and efficient through the use of intrusion detection systems (NIDS) that detect all abnormal actions on the network interface and report the same for proper actions. Concerning the growth in the size of communication networks, the application of NIDS and network intrusion prevention systems (NIPS) have undoubtedly become crucial in the 21st century network era. While the former (NIDS) detects intrusion and raises alarms to alert network experts to possible invasions in the network, the latter ensures that the alerting action does not harm the target system by preventing the attack. Both are implemented in synergy to ensure the holistic security of the network. Knowing when a system is under attack is paramount, as preventing the attack is essential. Hence, it accounts for researchers’ high interest in the intrusion detection system (IDS) domain. IDS monitors network traffic flow for possible cyberattacks and privacy violations at different layers of the network and prevents observed attacks from occurring.
The advance in technology has recently resulted in increased data collection sources in the IoT network ranging from smart devices, smart homes, and smart grids to network devices such as routers, hubs, and switches, among others. Data collected from these end devices or network nodes are based mainly on the modes involved in monitoring the traffic. In IDS, there are three modes of monitoring network traffic flow: host-based [
1,
2], network-based, and hybrid [
3] methods. When the IDS is implemented on the network nodes (host devices) to capture packets in transmission, filter the packets, and define whether they are real or malicious, the situation is known as host-based IDS (host-IDS). In some scenarios, the network administrator may decide to monitor the traffic at the network layers without including the end nodes of the network. Hence, the IDS is installed on the devices in the network layer or along the network transmission lines, and it is called a network-based IDS (network-IDS). In contrast to the above scenarios, the IDS is implemented by integrating the host-based and network-based methods to obtain a hybrid-IDS. Ideally, a network-IDS achieves a more comprehensive security advantage over other forms of IDS implementation modes because of a network-IDS interface with host systems and intermediate devices that allows it to prevent attacks on the lower interface at a quicker instance. Regarding network architecture, requirements, and specifications, multiple IDS systems or even hybrid can be used in a single network to track traffic in different end devices. IDs can also be categorized into misuse-based IDS, anomaly-based IDS, and hybrid, according to the nature of the network profile monitored by design. While the former works on the principle of known attacks, the latter is based on traffic flow patterns.
Internet of Things (IoT) systems are increasingly proliferating in every aspect of human existence, including finance, government, military, agriculture, and other industrial establishments. This increase has resulted due to the recent use of technologies such as Internet of Multimedia Things (IoMT), Industrial Internet of Things (IIoT), smart grids, smart and precision agriculture, Industry 4.0, and others [
4]. Following this expansion in IoT application domains, a large volume of data is generated and transmitted over the Internet, resulting in more cybersecurity concerns to avert constant threats to IoT systems from individuals with malicious intentions. Many threat attempts, including DDoS, denial of service (DoS), web attacks, infiltration, and man-in-the-middle attacks, are some of the prevailing intrusive cyberattacks on IoT systems. In [
5], the authors presented a comprehensive review of the different proposed models for IoT intrusion detection with ML classifiers, suggesting the high demand for highly efficient, effective, and accurate models developed with a machine and deep learning algorithms for IDS in IoT networks. An IDS deployed for an IoT system should be able to analyze data packets and produce real-time responses, obtain and critically evaluate data packets transmitted between multiple layers of the IoT network, and adapt to a variety of technologies in the IoT environment. This ideology serves as a principle for the development of IoT-based IDS models [
6,
7]. Operating in a constrained environment of low processing capabilities, dealing with fast response, and high-volume data processing should always be considered when designing IDS for IoT systems.
In the flow of events during IDS implementation, the IDS generates alerts when any suspicious activity is observed in the network. These alerts generated by the IDS at every entry point in the network are transmitted to the network monitoring expert (NME), which can either be a human or intelligent system, for analysis and consequently take possible actions. One of the current challenges with this scenario is the rate of false alarms generated by the IDS that may result in alert fatigue and failure in the system. In a case where there is a prevalence of alert fatigue, the network experts may spend unnecessary time investigating many false alarms and less time responding to realistic attacks. Hence, the need to reduce false-alarm rates has been studied in the literature [
8,
9]. In the case of a botnet attack that floods the entire IoT network with streams of bots causing resource depletion and network service interception, artificial intelligence (AI) devices are necessary to detect such floods.
The traditional method in monitoring network flows is the use of human experts who can easily become overwhelmed with false-alarm fatigue. Intelligent machine experts can overcome this problem. ML approaches to monitor both misuse and anomaly-based network traffic have been investigated with different performances in terms of accuracy, precision, recall, and F1-score. In [
10], an expanded survey on the various implementation of ML in NIDS relating to IoT environment was presented.
According to [
11], authors proposed an IDS based on ensemble ML. The system achieved an accuracy of 99.3% during testing. Other authors also achieved high degrees of accuracy in their proposals [
12,
13,
14]. One major problem in the domain of IDS models using ML has been the rate of false alarms which continues to reduce the practicality rate of implementation of IDS. When systems are designed for the purpose of recommendation activities or for filtering emails into spam or not, the impact of false negatives (FNs) and false positives (FPs) may be neglected [
15]. However, when it concerns intrusion whose effect can be more disastrous, reducing the FPs and FNs to their most feasible minimum is extremely important.
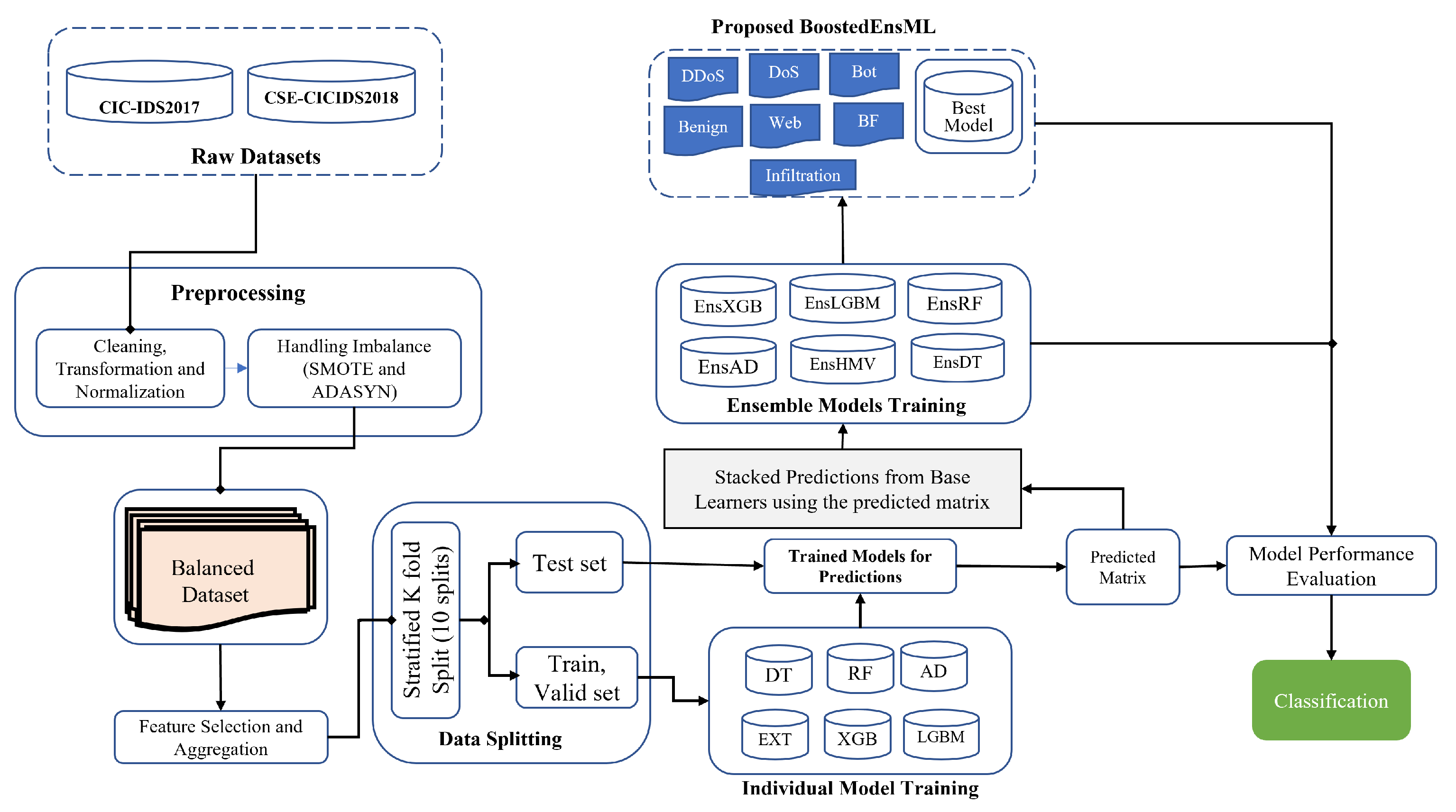
In this paper, we propose an IDS that uses boosted ensemble ML classifiers (BoostedEnML) aimed at enhancing the performance of IDS models in attack detection and classification with reduced false-alarm rates. Network packets are processed using ML algorithms to detect, analyze, and classify the traffic into their respective categories so that triggered alerts can be more reliable, reducing the computational overhead cost of managing false signals in the system. We implement our proposed model based on boosting algorithms as they showed better performance over other algorithms tested in this paper in model complexity, accuracy, and time function. Furthermore, the use of BoostedEnML in this work demonstrates that boosting classifiers such as LGBM and XGB can be combined to significantly improve the detection rate of ML IDS models in classifying attacks in an IoT environment as opposed to existing ML IDS models, which did not implement the combination of these two algorithms.
In the proposed IDS, we train, validate, and test different models based on random forest (RF) [
16], AdaBoost [
17], XGBoost [
18], LightGBM [
19], extra tree (ET), and decision tree (DT) [
20] classifiers. Except for the DT, other algorithms already exist as ensemble classifiers based on the aggregation of various DT algorithms. A combination of these using a new method usually results in improved performance, in our case, for research. We develop the proposed model on the CSE-CIC-IDS2018 and CIC-IDS2017 datasets, which are the most comprehensive datasets for IDS development [
21] currently available. IDS models and, generally, ML algorithms generalize better on balanced data by learning the same features from each class in the dataset. The two datasets used for this work contain imbalance; therefore, we handle the imbalance in our dataset using two main oversampling techniques, which are synthetic minority oversampling technique (SMOTE) [
22] and adaptive synthetic sampling (ADASYN) [
23,
24]. In the NIDS domain, several ensemble ML approaches have been discussed [
25,
26,
27,
28,
29,
30,
31], but none have used these classifier combinations to the best of our knowledge. Our proposed approach detects intrusion more accurately and precisely compared to existing systems [
25,
26,
27,
29].
The key contribution of this research are outlined as follows:
A search algorithm based on GridSearchCV was implemented to select the most fundamental parameters necessary to obtain a high-performing IDS model. This ensures that the model learns holistically on the dataset.
We performed feature selection to obtain the most predominant features of the datasets and used an ensemble technique to combine the features to obtain a comprehensive array of best performing features.
We implemented oversampling techniques, such as SMOTE and ADASYN, to handle data imbalance in our two datasets, thereby obtaining a highly accurate classification model. These datasets are widely used in similar and recent research.
We implemented several ensemble models and selected the best models depending on time-cost function and overall accuracy. Models based on boosting algorithm showed better performance; hence, they were used to develop the BoostedEnML as proposed. In each step, the resulting model was validated for a multiclass classification task.
We evaluated the model performance on two robust datasets having various intrusion attempts and used the AUC to validate the performance accuracy.
On evaluation, experimental results show that the proposed BoostedEnML IDS model accurately classified the network traffic flows in the used datasets with reduced FN, FP, and FAR, and maintained a high detection rate for packets of data on the IoT network. Our IDS model for IoT systems showed improved performance over existing models discussed in the literature. In addition, the proposed approach helps to reduce the model complexity by using lightweight algorithms to develop the ensemble model. With the grid search cross-validation applied, we ensured that the proposed model learns from the most relevant network traffic features and uses the algorithm’s best parameters to save training time.
The rest of the paper is organized in the following pattern.
Section 2 presents the background of ML in IDs, selected algorithms, and related propose works. Our approach to achieving the proposed model is presented in
Section 3. In
Section 4, we present, analyze, and interpret our research findings, and then we conclude our paper in
Section 5.
2. Background and Related Work
Currently, many research breakthroughs exist in the IDS for network security applied to IoT systems. Notwithstanding, there still exist significant challenges, some of which include a lack of a consistent understanding of normality introduced by network unpredictability, heterogeneous nature of network traffic, unavailability of appropriate public IDS datasets, and vulnerable environments and loopholes that grant access to attackers who actively search for and exploit security flaws. Some security researchers have opined that these challenges are uniquely inherent in IDS in networks and may not be observed in other domains [
32]. IoT system security challenges are evolving with the expansion of the application domain of the technology. The IoT layers comprising the perception, the network, and application layers continuously face different threats. The application layer sitting at the topmost part of the network transmits information between the network and other services and tends to face most of the threats due to the connection interface established between other devices [
5]. In [
33], authors proposed an ensemble IDS model for the IoT environment using gradient boosting algorithm for a binary class classification task. The proposed model reached an accuracy of 98.27% and a precision of 96.40% using XGBoost for feature selection.
Data generation in IoT systems has witnessed a great expansion in the last decades, and transmitting such a volume of data over a regular network has been challenged with high computational resource requirements, low bandwidth, and advanced network attacks. One approach to overcoming the resource constraint and increased cyberattacks is using a cloud computing environment with massive storage capacity, high computational power, and configurable resources integrated with virtualization capabilities for data storage [
34]. Flooding the IoT network at all layers with DDoS attacks such as UDP flood, ICMP/Ping flood, SYN flood, ping of death, and zero-day DDoS attacks have resulted in high data loss. Nie et al. in [
35] proposed a novel intrusion detection system in the IoT domain to deal with such intrusive attacks as distributed denial of service (DDoS), packet-sniffing, and man-in-the-middle attacks. The authors used the GAN method to train an IDS model using the CSE-CICIDS2018 and CICDDoS2019 datasets, the most recent and complete datasets for training and testing IDSs. The research showed that the models achieved about 97% accuracy in both datasets in the training and evaluation phases. Mitigating DDoS, DoS, botnet, and infiltration attacks on the IoT networks has recently been a challenging task [
36].
In [
37], authors proposed many IDS models based on machine learning to mitigate attacks on IoT devices in the smart city setting. Different ML algorithms and ensemble methods, such as the stacking, bagging, and boosting methods, were used to develop the ensemble model. On evaluation, the proposed ensemble models reached an accuracy and recall of 0.999. Several Ml algorithms were used by [
38] to propose the IDS model for IoT networks. In the work, the authors used K-nearest neighbor (KNN), support vector machine (SVM), artificial neural network (ANN), and other ML algorithms in their work. The models were trained using the train–test split method at an 80:20 ratio; the resulting models were evaluated on the BoT-IoT dataset and achieved an accuracy of 99% with the KNN. Furthermore, Ref. [
39] proposed an IDS model for cyberattack monitoring based on the bagging ensemble method with an accuracy of 99.67% on the NSL-KDD dataset.
Currently, several open-source network monitoring solutions are leveraged to provide network security by capturing the TCP/IP packets in the networks. Suricata [
40] and Snort [
41] are the most commonly used open-source traffic monitoring software. Both have shown some limitations in recording attacks during operation. Suricata and Snort work based on predefined rules to detect malicious attacks [
42,
43]. One of the major drawbacks of these systems is that any deviation from the predetermined rules would result in a false alarm. Again, it requires that a security expert study both existing attacks and novel network deviations under defined conditions that define the database’s signatures. Attackers exploit the vulnerabilities regularly discovered in IoT networks and use the same to tamper with the events protocol. Since this process is dynamic, using a manual approach to define attack features can be ineffective and burdensome to handle.
In addition, considering the extensive data generated by the IoT systems, manually searching for attacks in the dataset can be a hassle. An attempt to proffer a solution is the application of machine learning, which today has gained exceptional popularity in industries and the scientific community in IoT cybersecurity [
44,
45,
46,
47,
48]. The machine learning technique primarily used in IDS systems is supervised learning, where the database is provided with features and labels to classify the network traffic. Ensemble learning defines an approach where several base learners, referred to as weak learners, are aggregated based on specific rules to form a stronger classifier algorithm [
49]. With ensemble methods, models achieve better performance in predicting the nature of the traffic flow, as overfitting and class imbalance are handled with a better approach [
50]. In a nutshell, many of the existing ensemble models implement DT architecture in a bagged or boosted manner, leading to improved results.
The bagging method uses different samples of the train data on the algorithms at different times and rates, resulting in different submodels whose average is the desired output of the training. The voting ensemble uses majority voting (soft or hard) for classification tasks, as used in [
51] with an accuracy of 99%, and averaging for regression tasks to combine the outputs of the base learners. Bagged DT and RF models are the most widely used bagging ensemble models [
50]. On the contrary, the boosting algorithm forces each weak classifier to concentrate on a specific component of the data in the training distribution, thereby transforming groups of weak classifiers into strong ones with improved accuracy. Through this approach, later learners are pressed to concentrate on the mistakes made by earlier learners. Hence, the later classifiers are trained to overcome the mistakes of the earlier classifiers. As a result, each baseline learner in the boosting ensemble can concentrate more on the data points that the other learners misunderstood. When the data are pooled, boosting produces a more precise prediction [
17].
2.1. Machine Learning Models
In this section, an overview of the selected ML algorithms used in this work is presented. For simplicity, we discuss the decision tree, AdaBoost, extra tree, random forest, LightGBM and XGBoost.
Decision Tree (DT): Decision trees (DTs) are data structures composed of elements called nodes. Following a hierarchical model, the tree has a root node, where the tree begins; sequentially, the tree is composed of child nodes, where each node can have other children or subtrees. A leaf or terminal node is a node that has no offspring. The initial data enters the tree’s root and passes through the decision nodes until reaching the leaf node, which presents the result of the processing. Usually, three main variations of DT are prominent in use for IDS designs: ID3 [
52], C4.5 [
53], and CART [
54].
Adaptive Gradient Boosting (AdaBoost): Freund et al. [
17] proposed the AdaBoost as a boosting learner that creates a chain of classifiers in succession on the same dataset in such a manner that subsequent classification improves on the errors of the earlier classification. The algorithm achieves this by assigning higher weights to the incorrectly classified classes and lower weights to the correctly classified classes, thereby ensuring that the incorrectly classified instances gain priority during the next phase. The exact process repeats until the best possible result is achieved and the algorithm has used all the instances in the data. As implemented in [
55], authors proposed an IDS based on AdaBoost using the CIC-IDS2017 dataset as a training dataset. Applying SMOTE, an accuracy of 81.31% and an F-score of 81.31% were achieved during testing. Although achieving good accuracy, this resulted in a lot of false predictions that need to be improved.
Extra Tree (ET) Classifier: This algorithm improves the performance of DT and RF by incorporating a more significant number of trees into its network. As a result, compared with other ML algorithms, it has the highest number of trees and computational resource requirements. This algorithm works on the principle of meta-estimator and applies an averaging rule to increase predicted accuracy and reduce overfitting. First, the meta-estimator fits several randomized decision trees on different subsamples of the same dataset. Then, it aggregates the results of multiple decorrelated decision trees collected in a forest to output a classification result. The package is available in the
sklearn.ensemble.ExtraTreesClassifier library for use in any ML tasks [
56].
Random Forest: This algorithm, proposed by Breiman [
16], has shown great results in both classification and regression problems, making it the most used ensemble algorithm. By constructing component trees, the algorithm reduces the connection of different decision trees. It extends the attributes of bagged decision trees by inculcating randomized attributes. More importantly, the performance gains observed in RF are achieved through the randomness in the attribute selection process, not from the splits in the decision trees which are created based on a subset of the data attributes [
15]. As a popular ensemble algorithm, several authors have used it in IDS [
57,
58,
59]. In [
58], authors proposed an IDS model which used principal component analysis (PCA) for dimensionality reduction and random forest classifier for classification. The result was compared with support vector machines (SVM), naive Bayes, and classical decision trees. On testing, authors claimed that the model achieved an accuracy of 96.78%, making it preferable over the others, which achieved less accuracy.
Extreme Gradient Boosting (XGBoost): Extreme gradient boosting (XGBoost) [
60] is an extension of the implementation of gradient boosting tree proposed by Friedman et al. [
61]. Because it offers parallel computation, cache awareness, a built-in regularization strategy to avoid overfitting, and tree optimization by a split-finding algorithm, XGBoost generally outperforms gradient boosting in terms of performance as it has a quick training and inference time. In [
62], an efficient IDS model based on XGBoost was proposed for computer networks. The model was trained and evaluated on the network socket layer–knowledge discovery in databases (NSL-KDD) dataset with an accuracy of 98.70%.
Light Gradient Boosting Machine (LightGBM): Observing the high training time requirement for gradient boosting decision trees (GBDT), Ke et al. [
19] proposed two novel techniques to overcome the challenge based on Gradient-based One-Side Sampling (GOSS) and Exclusive Feature Bundling (EFB). This new implementation was named LightGBM, and it improved training and inference time of GBDT by 20%. Since its development, it has shown highly impressive results even in IDS systems, as shown in [
63,
64].
2.2. SMOTE and ADASYN for Imbalanced Dataset
One of the many challenges affecting the efficiency of ML models is the inadequacy of data points in the dataset used to train the models. Hence, the model cannot learn comprehensively from the available data, creating room for incomplete knowledge in some instances. In the case of our dataset, there are over 13 million benign traffic in the CSE-CIC-IDS2018, with some attacks such as SQL injection having only 87 data instances. In addition, in the CIC-IDS2017, the heartbleed attack has only 11 instances compared with the benign instances with 2 million data points. Some techniques have been proposed to solve this problem, usually based on either oversampling or undersampling methods. In undersampling, the majority class is reduced to be suitable to the minority classes, which leads to the loss of vital information, while in oversampling, the minority classes are increased to be equal or approximate to the majority classes. SMOTE [
22] and ADASYN [
23] are two of the many oversampling techniques used in handling data imbalance. SMOTE first selects a minority class instance
r randomly and finds its K-nearest minority class neighbors. The synthetic instance is then created by choosing one of the K-nearest neighbors
p at random and connecting
r and
p to form a line segment in the feature space. Finally, the synthetic instances are generated as a convex combination of the two chosen instances,
r and
p. ADASYN is based on the idea of adaptively generating minority data samples according to their distributions: more synthetic data are generated for minority class samples that are harder to learn compared to those minority samples that are easier to learn. Other derivatives of the SMOTE method include borderline-SMOTE [
65], borderline-SMOTE SVM, SMOTEN, SMOTENC, and KmeansSMOTE, which are all available in the Imblearn-learn library [
66].
2.3. Ensemble Machine Learning
Ensemble learning in ML aggregates the results of different ML classifications aimed at achieving better performances in accuracy and attack classification detection rate. In ensemble learning (EL), homogeneous and sometimes heterogeneous algorithmic classifiers can be combined to build an improved predictive model with better inference time [
67]. The applicability of ML techniques differs between use cases and the characteristics of the dataset on which it is built. This implies that the technique used for one project dataset might not be applicable to another of the same or similar domain [
68]. Hence, EL tries to achieve a model that can be used in the application domain with better results. Different EL models perform differently from each other in the IDS domain based on the dataset used to develop the model. Usually, three main classes/methods of EL exist, including bagging, stacking, and boosting.
Bagging entails averaging the predictions from many decision trees that have been fitted to various samples of the same dataset. It usually incorporates three main approaches, including bootstrapping samples of the train dataset, fitting unpruned DTs on each sample, and use of simple voting or averaging of predictions to obtain the final results. Some known examples of this include bagged decision tree (BDT), random forest (RF), and extra tree (ET) [
69]. Given a training set
with responses
, the bagging algorithm repeatedly (P times) selects a random sample accompanied by replacement of the training set, then fits trees of different sizes to these samples. This can be achieved using the procedure shown in Algorithm 1.
| Algorithm 1 The algorithm for bagging classifier |
- 1:
for
do - 2:
Sample, with replacement, n training examples from T, L; call these Tb, Lb. - 3:
Train a classification tree, fb on Tb, Lb. - 4:
After training, predictions for unseen samples x - 5:
obtain the final predictions from all the individual fb on x by taking the average of all predictions for regression or taking the majority vote for a classification problem using Equation ( 1). - 6:
end for
|
This approach leads to a better model with reduced variance of the IDS model without increasing the bias. This shows that in a case where the predictions of a single tree are extremely noise-sensitive on the training set, as long as the trees are not correlated, the average of the trees is insensitive to noise. Hence, bagging yields reliable IDS models for IoT environment. When we train many trees on a single dataset (training data), the trees would produce strongly correlated trees (even with the same tree many times not considering whether the training algorithm is deterministic or nondeterministic), which tends to cause overfitting and bias; bagging or bootstrapping the samples in the datasets is a measure to ensuring decorrelation in the trees by showing them different samples of data during the training process in the training sample [
70]. More specifically, we calculate an estimate of the uncertainty of the prediction as the standard deviation,
of the predictions from all the individual regression or classification trees on x
according to Equation (
2):
Stacking, also known as stacked generalization, is an ensemble modeling technique that includes using data from many models’ predictions as features to construct a new model and make predictions. In other words, during stacking, we fit different models on the same train data, obtain the results of the predictions, and use another algorithm to combine the predictions for improved results. This approach ensures that the learned features from the first model are maintained by the second model, thereby showing improved results compared to the single model. By using heterogeneous weak models trained on the same data sample, more robust IDS models are obtained [
71,
72]. Popular EL algorithms based on stacking are blending and super ensemble.
When boosting is implemented, there is sequential addition of the members of the ensemble algorithms which corrects the predictions of the previous classifier and generates a weighted average of the predictions as the output. This feature of boosting algorithm accounts for their better performances over stacked and bagged ensemble classifier. Common examples include AdaBoost, XGB, LGBM, and GBDT [
50,
73]. Assuming that the boosting ensemble is defined in terms of weighted sum of
L weak learners, we obtain the function shown in Equation (
3) where
are coefficients and
are weak learners.
One drawback of this approach is the difficulty to achieve faster optimization convergence. To arrest this challenge, instead of solving for the coefficients and the weak learners in one try, we implement an iterative optimization approach that is more cost-efficient and tractable. In this scenario, each weak learner is added one by one, checking the iteration for the best possible pair that it gives (coefficient and weak learner) to update the current ensemble model. Hence, we define recurrently the value of
in a way such that
In which case the values of
and
are selected such that
is the model which has the best fit on the train data, therefore it presents the best possible improvement over
according to Equation (
4). If we define E(.) as fitting error of the given model and e(.,.) to be the loss/error function, we denote the following:
As a result, rather than optimizing “globally” over all of the
L models in the total, we approach the optimum by optimizing “locally” creating and gradually adding the learning algorithm to the strong model. Hence, Equation (
5) presents a comprehensive approach to the design of highly optimized ensemble classifier based on booting technique. A typical algorithmic representation of the procedure for implementing the boosting algorithm is shown in Algorithm 2 with primary focus on the AdaBoost classifier upon which other boosting classifiers are built. A summary of related literature reviewed in this section is presented in
Table 1.
| Algorithm 2 The algorithm for boosting classifier |
- 1:
Form a large set of sample features - 2:
Initialize the weights of training samples - 3:
for T rounds do: - 4:
Normalize the weights of the samples - 5:
For available features from the set, train a classifier using a single feature and evaluate the training error - 6:
Choose the classifier with the lowest error - 7:
Update the weights of the training samples: increase if classified wrongly by this classifier, decrease if correctly - 8:
end for - 9:
Form the final strong classifier as the linear combination of the T classifiers.
|
4. Results and Discussion
In this section, we present and discuss the results obtained from the experiment. As earlier stated, we performed the experiment using two well-known datasets: CIC-IDS2017 and CSE-CICIDS2018, which are publicly available for research purposes [
76]. First, we oversampled the data points such that there were almost the same values for each of the samples. For instance, bot, which has 286,191 samples against the benign traffic, with 12,484,708 instances, in
Table 2 needed to be increased, otherwise the model would only learn the features of the benign traffic since it would see more of the packets injected as benign. The datasets obtained for the training, validation, and testing after handling imbalances with SMOTE and ADASYN, and splitting using
StratifiedKfold cross-validation, are presented in
Table 5. For each of the nine class labels in CICIDS2017, there are 606,812 instances for training and 67,242 instances for testing. The same applied to the CSE-CIC-IDS2018 dataset.
After oversampling the datasets, the resulting data points were very high for the ML task; so we performed undersampling and selected a total of 5,189,072 (6%) data instances of the CSE-CICIDS2018, and 30% of the CIC-IDS2017 dataset with a total of 6,671,664 samples. The two datasets both had a total of 80 features each after preprocessing. A total of 64 features were selected, as shown in
Table 4 with the Timestamp, Destination port, Fwd Seg Size, Min, and Init Fwd Win Bytes being the top four features in the CSE-CICIDS2018 dataset. The features are listed in ascending order with their importance according to weights attached to each. This helps us to understand the extent to which each feature is important to the model performance. Features such as ‘Tot Fwd Pkts’, ‘Subflow Fwd Pkts’, ‘PSH Flag Cnt’, ‘Idle Std’, ‘Idle Mean’, ‘Active Std’, ‘Active Mean’, ‘Active Max’, and ‘ACK Flag Cnt’ are observed to contribute almost one-thousandth (1/1000) to the model training and testing. This can imply that if these features are removed, the model can still perform very accurately. With the exception of the Timestamp and Destination Port (Dst Port), the most important features which contribute almost tens of percentages are the first four features: Fwd Seg Size, Min, Init Fwd Win Bytes, and TotLen Fwd Pkts.
Figure 2 shows the first 10 important features in the CICIDS2017 dataset as generated with the random forest feature importance. First, we show the results obtained after training the models on the CSE-CICIDS2018 dataset. The performance of each model in terms of the accuracy, precision, recall, F-score, model size, and test time are presented in
Table 6. The results show that the task classifies the labels into their respective seven classes as contained in the dataset; identifying, at each time, one of the categories of the network traffic. During the test, the accuracy for each of the ML algorithms, DT, RF, ET, AD, LGBM, and XGB, are 98.7%, 98.4%, 98.3%, 97.8%, 98.8%, and 98.9%, respectively. It can also be observed that XGB has the highest accuracy, precision, recall, F-score, and AUC, compared with other ML algorithms. Hence, it achieves the best performance in correctly identifying each network traffic according to its category. This is expected as it has shown very high accuracy in previous works, outperforming some deep learning models in some datasets [
81].
Furthermore, the LGBM model follows the XGB having obtained accuracy, precision, recall, F-score and AUC of 98.8%, 98.83%, 98.83%, 98.83%, and 99.96%, respectively. LGBM is a lightweight version of the XGB algorithm specifically designed for timing optimization with high accuracy, as seen in this current task. In general, a close look at the evaluation metrics shows close, and almost the same, values obtained for each of the models for each metric used. For instance, DT achieved almost 99% for all the metrics, and RF achieved approximately 98% for all the metrics as well as ET classifier. This is achieved as a result of the balanced dataset and cross-validation approach used. In all cases, each algorithm generalizes very well on the traffic, and thereby gains knowledge to identify to which class the packet belongs. Since all the models trained on the algorithms have almost similar performances, we measured the train and test time for each model to enable us to select the most suitable model for further tasks of ensemble design.
As shown in
Table 6, ET required the highest amount of time to predict the different attack classes, using about 15.1 s. This is attributed to the large number of trees in its architecture, so ET was excluded from being used as a base learner in ensemble models. DT, RF, LGBM, and XGB had total test times of 0.25 s, 9.98 s, 3.4 s, and 4.25 s, respectively. Therefore, we chose them as base learners for ensemble models.
The results obtained for the CIC-IDS2017 dataset using the various metrics are shown in
Table 7. On this dataset, the DT, RF, ET, AD, LGBM, and XGB classifiers detected each class with an accuracy of 99.59%, 99.45%, 99.68%, 69.67%, 99.16%, and 99.51%, respectively. In terms of the AUC score for each of the classifiers, the DT, RF, ET, AD, LGBM, and XGB reached 99.76%, 99.98%, 99.97%, 67.9%, 96.81%, and 99.97%, respectively, with ET and XGB having the same AUC score of 99.97%. Considering the precision and recall performances of the six models, we observe that each model has high values, which demonstrates the capacity of each of them to give reliable predictions while detecting network traffic. In precision, the DT, RF, AD, LGBM, and LGBM classifiers reached precisely 99.59%, 99.48%, 99.68%, 66.76%, 96.96%, and 99.52%. These performances show that ET and XGB can classify the flow packets with higher precision. In general, ET achieved the best performance in all metrics, although it had the highest detection or prediction time and memory requirement. Due to the large memory capacity and training and testing time requirement for the ET classifier, we selected XGB and LGBM which had similar performance ratings. On the other hand, DT had a prediction time of 0.18 s. LGBM, being a lightweight model, had the lowest memory requirement of about 3.1 MB with an accuracy of 99.16%. Therefore, the models on both datasets detected and classified each traffic with high performances in comparison with other existing methods [
4,
12].
We used a stacking method (StackingClassifier) to combine all the algorithms to develop ensembles for each classifier. Hence, we obtained Ens_DT (with DT as meta-learner), Ens_RF (with RF as meta-learner), Ens_LGBM (with LGBM as meta-learner), and Ens_XGB (XGB as meta-learner). To obtain the classifier based on majority vote, (EnsHMV), we used the four base classifiers as estimator and hard voting as the argument for the voting function. BoostedEnML was then developed using LGBM and XGB only.
The results obtained for the ensemble approach are shown in
Figure 3 and
Figure 4, respectively, for the CIC-IDS2017 and CSE-CIC-IDS2018 datasets.
From
Figure 3 and
Figure 4, we can observe that the ensemble ML classifiers outperformed the single ML classifiers, implying that using the ensemble approach can increase the performance of ML algorithms in detecting cyberattacks in IoT systems. For instance, on the CIC-IDS2017 dataset, Ens_DT, Ens_RF, Ens_LGBM, Ens_XGB, EnsHMV, and BoostedEnsML achieved an accuracy and F1-score of 97.8% and 98%, 98.9% and 99%, 99.7% and 99.9%, 99% and 99%, 99.99% and 99.99%, and 100% and 100%, respectively. The recall and precision in each case lies within the same range. In addition, on the CSE-CIC-IDS2018 dataset, the performance accuracy and recall for each of the ensemble models were, respectively, 98.9% and 98.9%, 99.1% and 99.1%, 99.5% and 99.52%, 99.6% and 99.6%, 99.56% and 99.66%, and 100% and 100% for Ens_DT, Ens_RF, Ens_LGBM, Ens_XGB, EnsHMV, and BoostedEnsML.
Since our task is based on multiclass classification, we show the confusion matrix for Ens_RF and Ens_LGBM classifiers in
Figure 5. Almost all the various network traffic types were correctly classified. From the confusion matrix, we can see that during the test for brute force, DDoS, and DOS with the Ens_RF model, all the 67,424 data points in the dataset were correctly identified as either brute force, DDoS, or DoS with 100% accuracy. On the other hand, 64,071 instances were identified as benign, 1 instance was misclassified as DDoS, 3344 were misclassified as infiltration attacks, and 7 were misclassified as web attacks while detecting benign traffic on the CSE-CICIDS2018 dataset. Similarly, on the CICIDS2017 dataset, the Ens_LGBM had only 1, 1, 3342, and 8 misclassifications of bot, DDoS, infiltration, and web attacks, respectively, while detecting benign flows, showing an FNR of 0.05%.
However, our proposed BoostedEnsML model outperformed all other ensemble models achieving 100% accuracy, precision, recall, F-score, and AUC for all the different attacks in both datasets, as can be seen in the confusion matrix in
Figure 6 and
Figure 7. Although other IDS models for IoT scenarios have achieved almost the same accuracy [
75], our work demonstrates that using only algorithms based on boosting techniques with balanced datasets can present an improvement on existing works. The model based on the HMV technique, called Ens_HMV, also outperformed other models, reaching high accuracy in both models. Notably, Ens_HMV on the two datasets achieved almost the same performance with the BoostedEnsML model but with regards to memory capacity, the BoostedEnsML (200 MB) is preferred as it has lower computational power than the Ens_HMV (500 MB).
The ROC curve shows the relationship between the true positive rate (TPR) and false positive rate (FPR) for the model performance in detection and classification of each attack. The ROC curve obtained on the CSE-CICIDS2018 dataset for LGBM, RF, DT, and ET is presented in
Figure 8. In each case, the AUC score is nearly 1.0, which indicates that the model has high accuracy in correctly classifying the various attacks and benign labels. In addition, the FPR is nearly zero for each of the models, showing a high rate of reduction in false alarms which have been a serious issue in ML used for IDS. Hence, our model outperforms most of the state-of-the-art models [
25,
26,
27] through the methodology adopted for the research. With high detection rate, the proposed model correctly classifies the various network traffic passing through the IoT environment, thereby helping to reduce exposure to cyberattacks.
We applied the ensemble model developed using voting technique (EnsHMV) that is based on bagging classifier for a classification task and the IDS model based on stacked boosting algorithms (BoostedEnML) on each of the datasets to identify how each of them performs in detecting and classifying the network packets into their respective classes. We considered each class as a separate entity to evaluate the classifier’s ability to differentiate it from the normal traffic (benign). The result for this experiment is shown in
Table 8. The results illustrate that for the various attack in the two datasets, both IDS models showed high precision, recall, and F-score, reaching 100% in correctly classifying the classes. More specifically, while EnsHMV and BoostedEnML performed similarly on the 2018 dataset, BoostedEnML outperformed EnsHMV on both datasets. In detecting infiltration attacks on the CSE-CICIDS2018 dataset, the two models report that the attack is infiltration with 100% recall, while on CICIDS2017, the EnsHMV detected an infiltration attack with a recall of 99.67% against BoostedEnML that reached 100%. The results generally show a low possibility of false alarms in both scenarios.
In terms of the F-score, which is the weighted mean of the recall and precision of the model behavior,
Table 8 demonstrates that the EnsHMV reached 0.9636%, 0.9984%, 0.9999%, 0.9989%, 0.9890%, 0.9969%, 1.00%, 0.995%, 0.9992%, and 0.9988% in classifying the benign, botnet, brute force, DDoS, DoS, heartbleed, infiltration, portscan, and web attack traffics in the CICIDS2017 dataset, respectively; while on the CSE-CICIDS2018 dataset, the EnsHMV attained an F-score performance of 0.9978%, 1.000%, 1.000%, 1.000%, 0.9999%, 0.9999%, and 1.000% in classifying the benign, botnet, brute force, DDoS, DoS, infiltration, and web attack flows, respectively. Similarly, the BoostedEnML showed higher performance than the EnsHMV in relation to the F-score measure on both datasets. Specifically, on the CICIDS2017, the BoostedEnML showed an F-score of 1.000%, 0.9999%, 0.9999%, 0.9980%, 1.000%, 1.000%, 1.000%, 0.9999%, and 1.000%, respectively, in the classification of the benign, botnet, brute Force, DDoS, Dos, heartbleed, infiltration, portscan, and web attack flows. It also achieved 0.9998%, 1.000%, 0.9999%, 1.000%, 0.9999%, 1.000%, and 1.0000% in detecting the benign, botnet, brute force, DDoS, DoS, infiltration, and web attack packets in the CSE-CICIDS2018 dataset.
We compared the performance of our models with those of existing models in the literature, as presented in
Table 9. In the work of Das et al. [
11], the proposed model achieved an accuracy of 92% for the ensemble decision tree, and our En_DT achieved 97.8%, which is about a 5.8% improvement. In addition, while the ensemble based on the neural network (NN), a deep learning model, achieved 99.5%, our BoostedEnsML achieved 100% in all evaluation metrics, showing that the proposed approach is better. On the same dataset as used in our work, the ensemble model based on stacking RF and KNN with DT used as meta-learner in Kim et al. [
75] detected the attacks and benign traffic with the accuracy of 99.9%, while our work detected each traffic with 100%, showing 0.1% improvement after handling data imbalance which was not stated in the work of Kim et al. [
75]. This indicates that with a balanced dataset integrated with feature selection, the performance of IDS models can be enhanced. There is also a need to evaluate the effect of different feature selection techniques and data imbalance methods on the general behavior of IDS models in detecting and classifying network flows in IoT systems. Our work will try to investigate this idea in future studies.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}