

A Novel Segmentation Scheme with Multi-Probability Threshold for Human Activity Recognition Using Wearable Sensors

 ,
, 
Abstract
:1. Introduction
- The TS algorithm is proposed according to the stationary of the static signal. A new indicator, , is estimated to identify the optimal threshold and segment from the static interval of the unknown time series.
- The SA algorithm is proposed according to the peak and trough of the periodic-like signal. Two new notions, slope and area, are employed to eliminate the abnormal points which support to identify the suspected periodic-like interval of the unknown time series.
- Combined with the pre-segmentation results, a multi-probability threshold recognition model is proposed, which not only substantially improves the accuracy of HAR, but also effectively distinguishes the useless segments in the complex continuous time series.
2. Related Work
2.1. Human Activity Recognition
2.2. Signal Segmentation
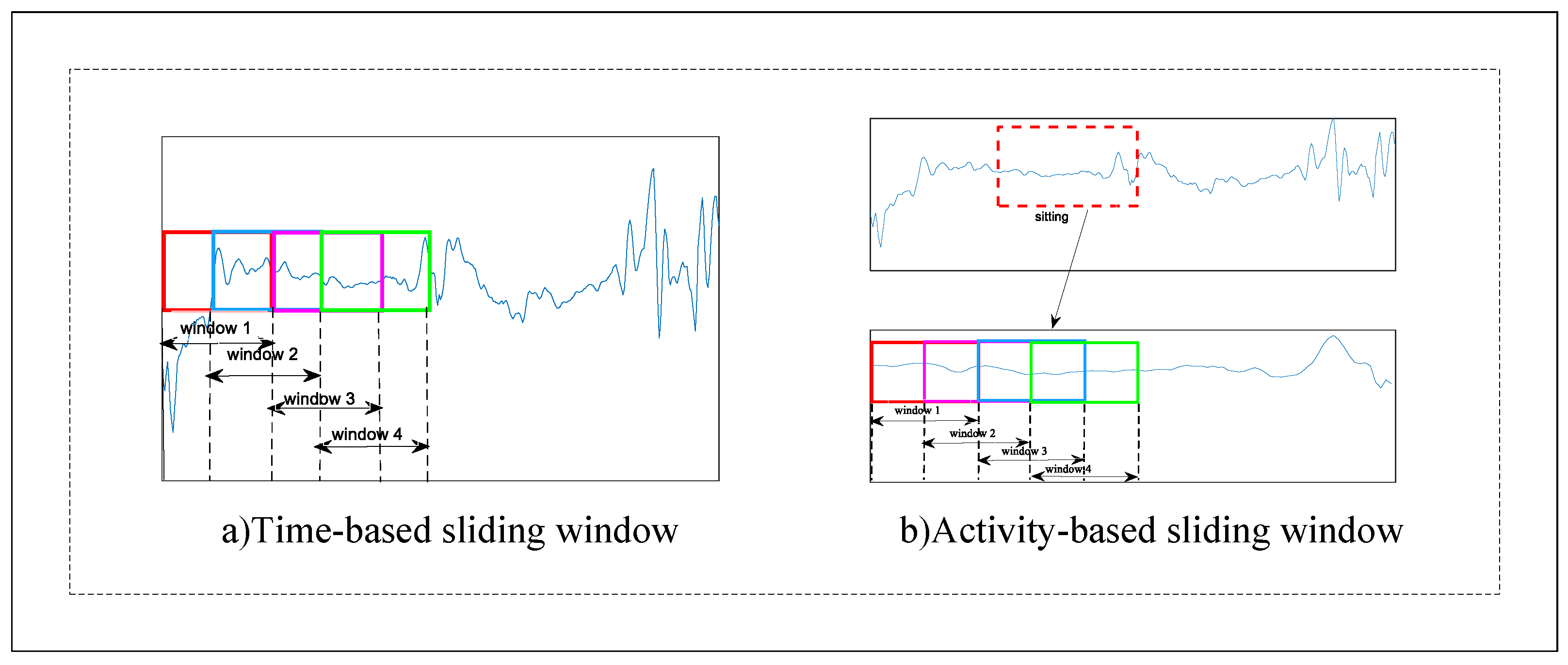
3. The Proposed Scheme
3.1. Problem Formalization
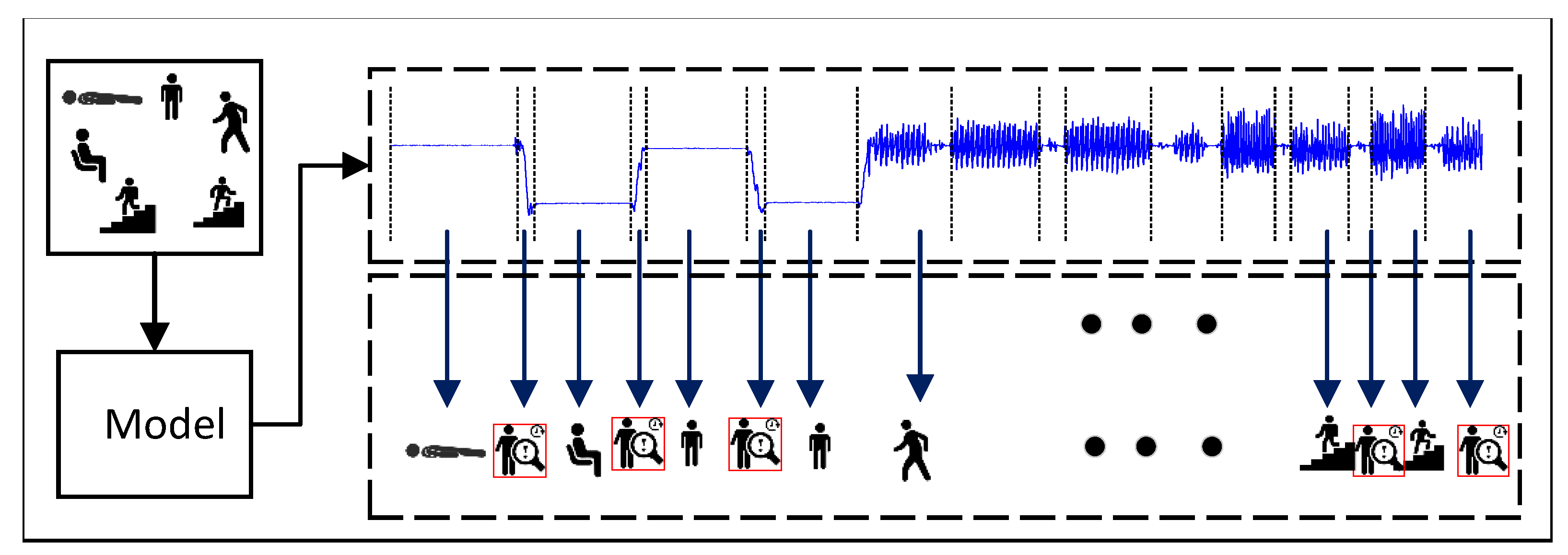
3.2. The Proposed Framework
- The training set is segmented by sliding window based on activity, and the corresponding time–frequency domain features are extracted manually. The recognition model is trained by traditional classifiers (SVM, DT, NB, etc.).
- For the training set, TS and its optimization algorithms are used to find the optimal threshold parameters, cbest and dbest, and apply them to the testing set to identify the suspected static segmentations in the time series.
- For the training set, the peak–trough method is applied to estimate the related slope, Kmin, and area, Smax. The SA algorithm is used to detect and eliminate the outliers, and the suspected periodic-like segmentations in the testing set can be determined.
- The testing set is segmented according to the method of overlapping sliding window and feature extraction, and multi-class labels are generated by training the model. Combined with the basic activity segmentations identified before, the probability vector of each window can be obtained by the MLWP algorithm. Correct activity category and unknown ones of the window can be distinguished by .
3.3. Filtering and Feature Extraction
3.4. Static Segmentation
| Algorithm 1 The proposed TS algorithm. |
Input:C, , , , . Output:, initialization:, , = 0
|
3.5. Periodic-like Interval Segmentation
| Algorithm 2 The proposed SA algorithm. |
Input:, , , , , Output:D
|
3.6. Multi-Label Weighted Probability Model (MLWP)
| Algorithm 3 The proposed MLWP algorithm. |
Input:E, L, M, N, k Output:Lforcast
|
4. Performance Evaluation
4.1. Experimental Environment and Data Sets
4.2. Evaluation Indicators
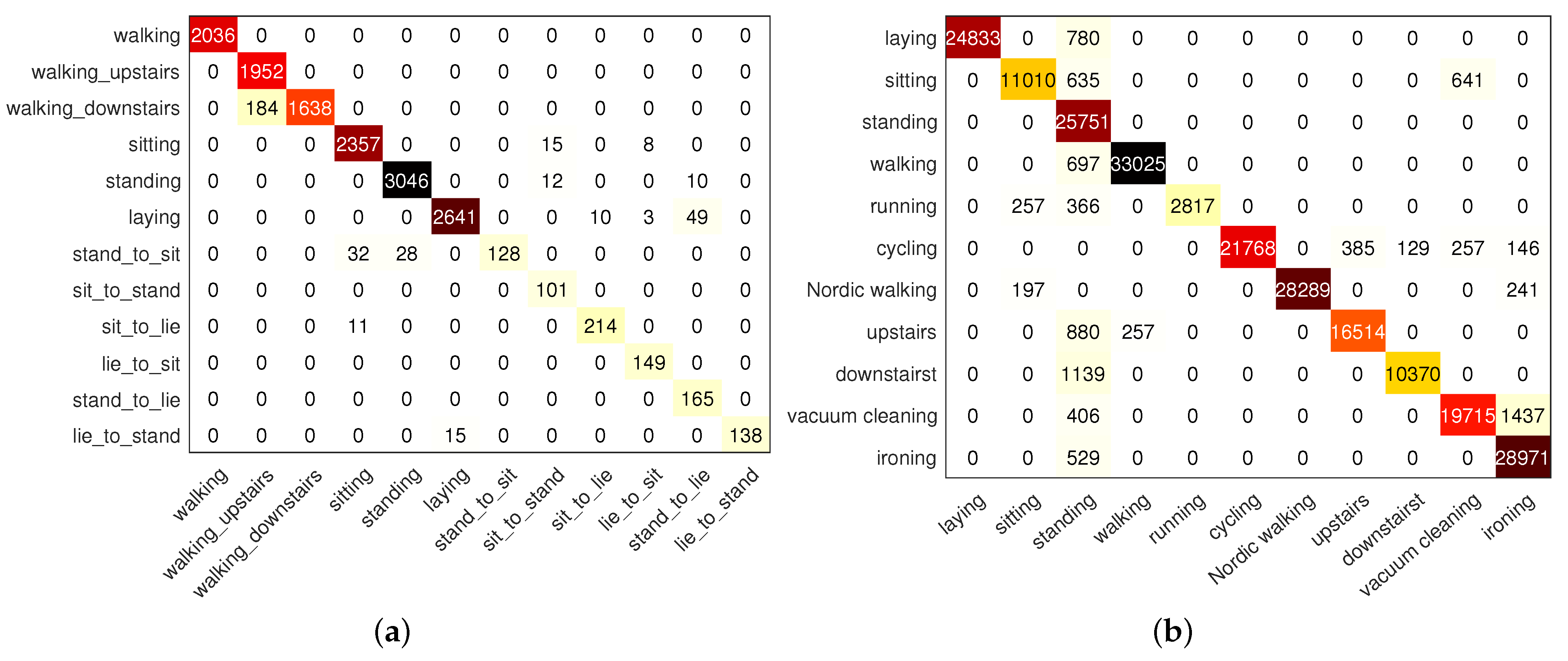
4.3. Experimental Results
4.3.1. Static and Period-like Interval Segmentation
4.3.2. Model Classification Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. 2014, 46, 33. [Google Scholar] [CrossRef]
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Qin, Z.; Zhang, Y.; Meng, S.; Qin, Z.; Choo, K.K.R. Imaging and fusing time series for wearable sensor-based human activity recognition. Inf. Fusion 2020, 53, 80–87. [Google Scholar] [CrossRef]
- Ahmed, N.; Rafiq, J.I.; Islam, M.R. Enhanced Human Activity Recognition Based on Smartphone Sensor Data Using Hybrid Feature Selection Model. Sensors 2020, 20, 317. [Google Scholar] [CrossRef]
- Al-Janabi, S.; Salman, A.H. Sensitive integration of multilevel optimization model in human activity recognition for smartphone and smartwatch applications. Big Data Min. Anal. 2021, 4, 124–138. [Google Scholar] [CrossRef]
- Ferrari, A.; Micucci, D.; Mobilio, M.; Napoletano, P. On the Personalization of Classification Models for Human Activity Recognition. IEEE Access 2020, 8, 32066–32079. [Google Scholar] [CrossRef]
- Esfahani, P.; Malazi, H.T. PAMS: A new position-aware multi-sensor dataset for human activity recognition using smartphones. In Proceedings of the 2017 19th International Symposium on Computer Architecture and Digital Systems (CADS), Kish Island, Iran, 21–22 December 2017; pp. 1–7. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra Perez, X.; Reyes Ortiz, J.L. A Public Domain Dataset for Human Activity Recognition using Smartphones. In Proceedings of the 21th International European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- Fida, B.; Bernabucci, I.; Bibbo, D.; Conforto, S.; Schmid, M. Varying behavior of different window sizes on the classification of static and dynamic physical activities from a single accelerometer. Med. Eng. Phys. 2015, 37, 705–711. [Google Scholar] [CrossRef]
- Wan, S.; Qi, L.; Xu, X.; Tong, C.; Gu, Z. Deep Learning Models for Real-time Human Activity Recognition with Smartphones. Mob. Netw. Appl. 2020, 25, 743–755. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Bianco, S.; Cadene, R.; Celona, L.; Napoletano, P. Benchmark Analysis of Representative Deep Neural Network Architectures. IEEE Access 2018, 6, 64270–64277. [Google Scholar] [CrossRef]
- Ferrari, A.; Micucci, D.; Mobilio, M.; Napoletano, P. Hand-crafted Features vs Residual Networks for Human Activities Recognition using Accelerometer. In Proceedings of the 2019 IEEE 23rd International Symposium on Consumer Technologies (ISCT), Ancona, Italy, 19–21 June 2019; pp. 153–156. [Google Scholar]
- Gupta, P.; Dallas, T. Feature selection and activity recognition system using a single triaxial accelerometer. IEEE Trans. Biomed. Eng. 2014, 61, 1780–1786. [Google Scholar] [CrossRef] [PubMed]
- Sun, F.; Mao, C.; Fan, X.; Li, Y. Accelerometer-Based Speed-Adaptive Gait Authentication Method for Wearable IoT Devices. IEEE Internet Things J. 2019, 6, 820–830. [Google Scholar] [CrossRef]
- Reyes-Ortiz, J.L.; Oneto, L.; Sama, A.; Parra, X.; Anguita, D. Transition-Aware Human Activity Recognition Using Smartphones. Neurocomputing 2016, 171, 754–767. [Google Scholar] [CrossRef]
- Santos, L.; Khoshhal, K.; Dias, J. Trajectory-based human action segmentation. Pattern Recognit. 2015, 48, 568–579. [Google Scholar] [CrossRef]
- Sheng, Z.; Hailong, C.; Chuan, J.; Shaojun, Z. An adaptive time window method for human activity recognition. In Proceedings of the 2015 IEEE 28th Canadian Conference on Electrical and Computer Engineering (CCECE), Halifax, NS, Canada, 3–6 May 2015; pp. 1188–1192. [Google Scholar]
- Noor, M.H.M.; Salcic, Z.; Kevin, I.; Wang, K. Adaptive sliding window segmentation for physical activity recognition using a single tri-axial accelerometer. Pervasive Mob. Comput. 2016, 38, 41–59. [Google Scholar] [CrossRef]
- Gyllensten, I.C.; Bonomi, A.G. Identifying Types of Physical Activity With a Single Accelerometer: Evaluating Laboratory-trained Algorithms in Daily Life. IEEE Trans. Biomed. Eng. 2011, 58, 2656–2663. [Google Scholar] [CrossRef]
- Masum, A.K.M.; Bahadur, E.H.; Shan-A-Alahi, A.; Chowdhury, M.A.U.Z.; Uddin, M.R.; Al Noman, A. Human Activity Recognition Using Accelerometer, Gyroscope and Magnetometer Sensors: Deep Neural Network Approaches. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019; pp. 1–6. [Google Scholar]
- Ramos-Garcia, R.I.; Hoover, A.W. A Study of Temporal Action Sequencing During Consumption of a Meal. In Proceedings of the International Conference on Bioinformatics, Computational Biology and Biomedical Informatics, Washington, DC, USA, 22–25 September 2013. [Google Scholar]
- Tang, Y.; Teng, Q.; Zhang, L.; Min, F.; He, J. Layer-Wise Training Convolutional Neural Networks with Smaller Filters for Human Activity Recognition Using Wearable Sensors. IEEE Sens. J. 2021, 21, 581–592. [Google Scholar] [CrossRef]
- Gao, W.; Zhang, L.; Teng, Q.; He, J.; Wu, H. DanHAR: Dual Attention Network For Multimodal Human Activity Recognition Using Wearable Sensors. Appl. Soft Comput. 2021, 111, 107728. [Google Scholar] [CrossRef]
- Cheng, X.; Zhang, L.; Tang, Y.; Liu, Y.; Wu, H.; He, J. Real-Time Human Activity Recognition Using Conditionally Parametrized Convolutions on Mobile and Wearable Devices. IEEE Sens. J. 2022, 22, 5889–5901. [Google Scholar] [CrossRef]
- Yang, Z.; Raymond, O.I.; Zhang, C.; Wan, Y.; Long, J. DFTerNet: Towards 2-bit Dynamic Fusion Networks for Accurate Human Activity Recognition. IEEE Access 2018, 6, 56750–56764. [Google Scholar] [CrossRef]
- Bifet, A.; Gavalda, R. Learning from Time-Changing Data with Adaptive Windowing. In Proceedings of the 2007 SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007. [Google Scholar]
- Wächter, A.; Biegler, L.T. On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming. Math. Program. 2006, 106, 25–57. [Google Scholar] [CrossRef]
- Sant’Anna, A.; Wickstrom, N. A Symbol-Based Approach to Gait Analysis From Acceleration Signals: Identification and Detection of Gait Events and a New Measure of Gait Symmetry. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 1180–1187. [Google Scholar] [CrossRef] [PubMed]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Ye, J.; Qi, G.J.; Zhuang, N.; Hu, H.; Hua, K.A. Learning Compact Features for Human Activity Recognition Via Probabilistic First-Take-All. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 126–139. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.; Hammerla, N.; Mellor, S.; Plotz, T. Optimising sampling rates for accelerometer-based human activity recognition. Pattern Recognit. Lett. 2016, 73, 33–40. [Google Scholar] [CrossRef]
- Hassan, M.M.; Uddin, M.Z.; Mohamed, A.; Almogren, A. A robust human activity recognition system using smartphone sensors and deep learning. Future Gener. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Y.; Zhang, Z.; Bao, J.; Song, Y. Human activity recognition based on time series analysis using U-Net. arXiv 2018, arXiv:1809.08113. [Google Scholar]
- Gusain, K.; Gupta, A.; Popli, B. Transition-aware human activity recognition using eXtreme gradient boosted decision trees. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2018; pp. 41–49. [Google Scholar] [CrossRef]
- Jansi, R.; Amutha, R. Hierarchical evolutionary classification framework for human action recognition using sparse dictionary optimization. Swarm Evol. Comput. 2021, 63, 100873. [Google Scholar] [CrossRef]
- Jin, L.; Wang, X.; Chu, J.; He, M. Human Activity Recognition Machine with an Anchor-Based Loss Function. IEEE Sens. J. 2022, 22, 741–756. [Google Scholar] [CrossRef]
- Teng, Q.; Wang, K.; Zhang, L.; He, J. The Layer-Wise Training Convolutional Neural Networks Using Local Loss for Sensor-Based Human Activity Recognition. IEEE Sens. J. 2020, 20, 7265–7274. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | Expression | Characteristics | Expression |
|---|---|---|---|
| Mean value | Standard deviation | ||
| Mode | M | Maximum | |
| Minimum | Skewness | ||
| Kurtosis | K | Gravity Frequency | |
| Frequency Variance | Mean Square Frequency |
| Signal | Description | Signal | Description |
|---|---|---|---|
| Acceleration of x-axis | Acceleration of y-axis | ||
| Acceleration of z-axis | Angular velocity of x-axis | ||
| Angular velocity of y-axis | Angular velocity of z-axis | ||
| Data difference of | Data difference of | ||
| Data difference of | Data difference of | ||
| Data difference of | Data difference of | ||
| Resultant acceleration | Resultant angular velocity |
| Window length (s) | 1.28 | 2.56 | 3.84 | 5.12 | 6.4 |
| Accuracy (%) | 94.8 | 94.5 | 95.2 | 96 | 95.9 |
| Accuracy (%) | Precision (%) | Recall (%) | F1 (%) | |
|---|---|---|---|---|
| 97.48 | 94.41 | 94.94 | 93.93 | |
| 97.73 | 95.33 | 90.84 | 92.72 | |
| 97.39 | 91.52 | 96.75 | 93.47 | |
| 97.68 | 91.67 | 91.30 | 90.51 | |
| 98.28 | 92.75 | 96.04 | 94.08 |
| Accuracy (%) | Precision (%) | Recall (%) | F1 (%) | |
|---|---|---|---|---|
| SVM | 95.93 | 93.94 | 96.71 | 95.12 |
| DT | 81.20 | 78.23 | 75.96 | 74.19 |
| LDA | 93.77 | 91.53 | 94.21 | 92.64 |
| NB | 85.52 | 80.85 | 80.72 | 88.23 |
| KNN | 91.66 | 89.62 | 92.25 | 90.69 |
| BT | 95.21 | 93.30 | 96.04 | 94.44 |
| Method | ANN [35] | FCN [36] | UNET [36] | SVM [35] | EGBM [37] | DBN [35] | SRH [38] | The Proposed Scheme |
|---|---|---|---|---|---|---|---|---|
| A1 | 83.27 | 95.77 | 95.56 | 88.78 | 97.78 | 94.69 | 98.59 | 100 |
| A2 | 95.48 | 93.84 | 95.54 | 97.30 | 96.82 | 97.12 | 98.30 | 100 |
| A3 | 96.88 | 93.10 | 91.19 | 97.61 | 93.57 | 97.61 | 97.86 | 100 |
| A4 | 91.93 | 90.43 | 91.65 | 95.97 | 93.89 | 95.97 | 97.96 | 98.37 |
| A5 | 93.99 | 93.80 | 94.17 | 97.58 | 95.86 | 97.78 | 97.93 | 96.88 |
| A6 | 85.71 | 95.53 | 97.20 | 97.14 | 98.70 | 96.67 | 99.07 | 97.16 |
| A7 | 34.78 | 71.43 | 77.14 | 73.91 | 62.86 | 82.61 | 82.86 | 94.67 |
| A8 | 00.00 | 66.67 | 75.00 | 80.00 | 83.33 | 80.00 | 83.33 | 80.6 |
| A9 | 56.25 | 83.33 | 77.08 | 50.00 | 91.67 | 81.25 | 93.75 | 100 |
| A10 | 76.00 | 84.85 | 75.76 | 64.00 | 81.82 | 72.00 | 87.88 | 100 |
| A11 | 51.02 | 85.71 | 83.67 | 69.39 | 75.51 | 85.71 | 87.75 | 100 |
| A12 | 18.52 | 81.58 | 71.05 | 62.96 | 73.68 | 81.48 | 84.21 | 84.43 |
| Method | SVM [11] | CNN [11] | Local Loss CNN [40] | Lego CNN [24] | Condconv CNN [26] | MLP-D [39] | CNN-D [39] | LSTM-D [39] | Hybrid-D [39] | The Proposed Scheme |
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | 84.07 | 91 | 92.97 | 93.5 | 94.01 | 87.9 | 94.72 | 87.4 | 94.38 | 95.93 |
| Recall | 84.71 | 91.66 | - | 88.17 | - | - | - | - | - | 93.94 |
| Precision | 84.23 | 91.54 | - | 91.07 | - | - | - | - | - | 96.71 |
| F1-Score | 83.76 | 91.16 | 93.03 | 91.4 | - | 86.66 | 94.23 | 86.53 | 93.88 | 95.12 |
| Method | CNN [40] | Local Loss CNN [40] | Lego CNN [24] | DanHAR [25] | The Proposed Scheme |
|---|---|---|---|---|---|
| B1 | 90.3 | 90.3 | 90.3 | 90.3 | 97 |
| B2 | 98.4 | 97.8 | 98.4 | 95.1 | 90 |
| B3 | 86.3 | 92.3 | 92.6 | 93.7 | 100 |
| B4 | 35.9 | 50.3 | 58.0 | 47.3 | 98.0 |
| B5 | 96.5 | 97.8 | 98.2 | 96.9 | 81.9 |
| B6 | 94.6 | 94.1 | 73.5 | 94.1 | 96 |
| B7 | 86.4 | 93.8 | 94.3 | 95.5 | 98.5 |
| B8 | 98.1 | 98.1 | 99.0 | 97.1 | 93.6 |
| B9 | 91.6 | 94.4 | 88.8 | 96.2 | 90.1 |
| B10 | 83.2 | 87.4 | 84.2 | 79.8 | 91.5 |
| B11 | 88.3 | 91.6 | 94.7 | 95.5 | 98.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, B.; Wang, C.; Huan, Z.; Li, Z.; Chen, Y.; Gao, G.; Li, H.; Dong, C.; Liang, J. A Novel Segmentation Scheme with Multi-Probability Threshold for Human Activity Recognition Using Wearable Sensors. Sensors 2022, 22, 7446. https://doi.org/10.3390/s22197446
Zhou B, Wang C, Huan Z, Li Z, Chen Y, Gao G, Li H, Dong C, Liang J. A Novel Segmentation Scheme with Multi-Probability Threshold for Human Activity Recognition Using Wearable Sensors. Sensors. 2022; 22(19):7446. https://doi.org/10.3390/s22197446
Chicago/Turabian StyleZhou, Bangwen, Cheng Wang, Zhan Huan, Zhixin Li, Ying Chen, Ge Gao, Huahao Li, Chenhui Dong, and Jiuzhen Liang. 2022. "A Novel Segmentation Scheme with Multi-Probability Threshold for Human Activity Recognition Using Wearable Sensors" Sensors 22, no. 19: 7446. https://doi.org/10.3390/s22197446
APA StyleZhou, B., Wang, C., Huan, Z., Li, Z., Chen, Y., Gao, G., Li, H., Dong, C., & Liang, J. (2022). A Novel Segmentation Scheme with Multi-Probability Threshold for Human Activity Recognition Using Wearable Sensors. Sensors, 22(19), 7446. https://doi.org/10.3390/s22197446