
Pedestrian Trajectory Prediction for Real-Time Autonomous Systems via Context-Augmented Transformer Networks

Abstract
:1. Introduction
- A novel framework based on transformer networks that address the problem of pedestrians’ trajectory prediction in urban traffic shared spaces.
- An efficient representations of contextual information that account for the preference of pedestrians in urban traffic shared spaces.
- A scalable framework that can provide multi-pedestrians’ trajectory predictions (more than 40 per second) in real-time without compromise on accuracy.
- A robust data-driven approach that can generalise to unseen scenarios across different urban traffic shared spaces.
2. Related Work
3. Proposed Method
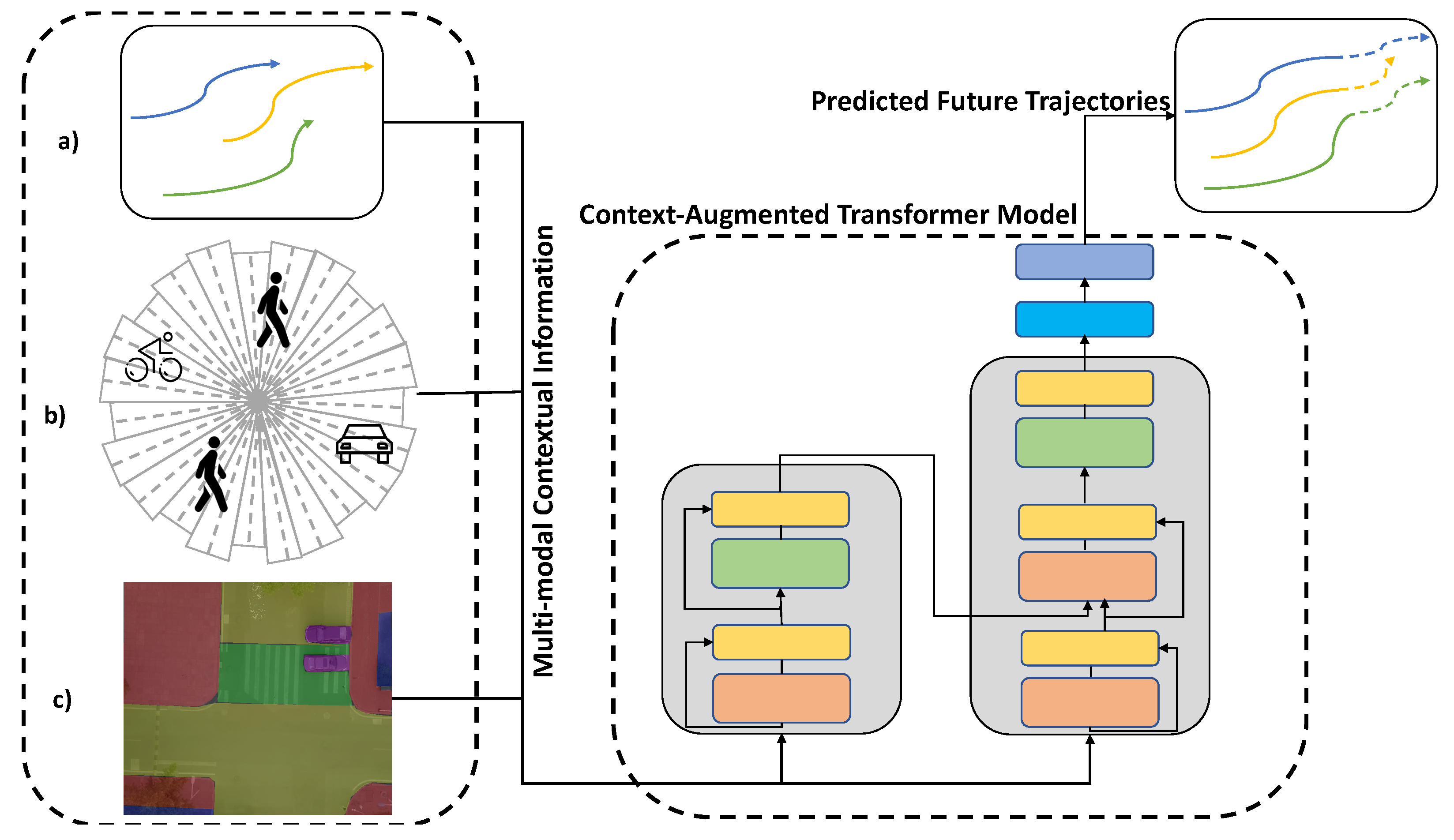
3.1. Problem Formulation
3.1.1. Positional Information
3.1.2. Agent Interactions Information
3.1.3. Scene Semantics Information
- (1)
- road;
- (2)
- side-walk;
- (3)
- zebra-crossing;
- (4)
- vegetation/grass;
- (5)
- parked vehicle.
3.2. Context-Augmented Transformer Model
3.3. Datasets
4. Experiments and Results
4.1. Implementation Details
4.2. Performance Evaluation
- (1)
- Transformer-based approaches are more resilient than LSTM-based ones when it comes to long pedestrians’ trajectory prediction;
- (2)
- The added contextual information to our proposed context-augmented transformer network will provide more accurate predictions about pedestrians’ trajectories when compared to the vanilla transformer network and other baseline approaches that utilise only positional information.
4.2.1. DUT and inD Results
4.2.2. Run-Time Performance
4.2.3. nuScenes Results
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Saleh, K.; Hossny, M.; Nahavandi, S. Towards trusted autonomous vehicles from vulnerable road users perspective. In Proceedings of the 2017 Annual IEEE International Systems Conference (SysCon), Montreal, QC, Canada, 24–27 April 2017; pp. 1–7. [Google Scholar]
- Lui, A.K.F.; Chan, Y.H.; Leung, M.F. Modelling of Destinations for Data-driven Pedestrian Trajectory Prediction in Public Buildings. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Online, 15–18 December 2021; pp. 1709–1717. [Google Scholar]
- Lui, A.K.F.; Chan, Y.H.; Leung, M.F. Modelling of Pedestrian Movements near an Amenity in Walkways of Public Buildings. In Proceedings of the 2022 8th International Conference on Control, Automation and Robotics (ICCAR), Xiamen, China, 8–10 April 2022; pp. 394–400. [Google Scholar]
- Helbing, D.; Molnar, P. Social force model for pedestrian dynamics. Phys. Rev. E 1995, 51, 4282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social LSTM: Human Trajectory Prediction in Crowded Spaces. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 961–971. [Google Scholar]
- Gupta, A.; Johnson, J.; Fei-Fei, L.; Savarese, S.; Alahi, A. Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 188–23 June 2018; pp. 2255–2264. [Google Scholar]
- Amirian, J.; Hayet, J.B.; Pettré, J. Social Ways: Learning Multi-Modal Distributions of Pedestrian Trajectories With GANs. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 2964–2972. [Google Scholar]
- Li, X.; Liu, Y.; Wang, K.; Wang, F.Y. A recurrent attention and interaction model for pedestrian trajectory prediction. IEEE/CAA J. Autom. Sin. 2020, 7, 1361–1370. [Google Scholar] [CrossRef]
- Xue, H.; Salim, F.; Ren, Y.; Oliver, N. MobTCast: Leveraging Auxiliary Trajectory Forecasting for Human Mobility Prediction. Adv. Neural Inf. Process. Syst. 2021, 34, 30380–30391. [Google Scholar]
- Yao, H.Y.; Wan, W.G.; Li, X. End-to-End Pedestrian Trajectory Forecasting with Transformer Network. ISPRS Int. J. Geo-Inf. 2022, 11, 44. [Google Scholar] [CrossRef]
- Saleh, K.; Hossny, M.; Nahavandi, S. Contextual Recurrent Predictive Model for Long-Term Intent Prediction of Vulnerable Road Users. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3398–3408. [Google Scholar] [CrossRef]
- Lee, N.; Choi, W.; Vernaza, P.; Choy, C.B.; Torr, P.H.S.; Chandraker, M. DESIRE: Distant future prediction in dynamic scenes with interacting agents. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2165–2174. [Google Scholar]
- Saleh, K.; Hossny, M.; Nahavandi, S. Long-term recurrent predictive model for intent prediction of pedestrians via inverse reinforcement learning. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 10–13 December 2018; pp. 1–8. [Google Scholar]
- Kooij, J.F.P.; Schneider, N.; Flohr, F.; Gavrila, D.M. Context-based pedestrian path prediction. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 618–633. [Google Scholar]
- Saleh, K.; Hossny, M.; Nahavandi, S. Cyclist trajectory prediction using bidirectional recurrent neural networks. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Canberra, Australia, 29–30 November 2018; pp. 284–295. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Giuliari, F.; Hasan, I.; Cristani, M.; Galasso, F. Transformer networks for trajectory forecasting. In Proceedings of the 2020 25th international conference on pattern recognition (ICPR), Milan, Italy, 10–15 January 2020; pp. 10335–10342. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Becker, S.; Hug, R.; Hübner, W.; Arens, M. An evaluation of trajectory prediction approaches and notes on the trajnet benchmark. arXiv 2018, arXiv:1805.07663. [Google Scholar]
- Tutsoy, O. Design and comparison base analysis of adaptive estimator for completely unknown linear systems in the presence of OE noise and constant input time delay. Asian J. Control 2016, 18, 1020–1029. [Google Scholar] [CrossRef]
- Keller, C.G.; Gavrila, D.M. Will the pedestrian cross? a study on pedestrian path prediction. IEEE Trans. Intell. Transp. Syst. 2013, 15, 494–506. [Google Scholar] [CrossRef] [Green Version]
- Karasev, V.; Ayvaci, A.; Heisele, B.; Soatto, S. Intent-aware long-term prediction of pedestrian motion. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 2543–2549. [Google Scholar]
- Anderson, C.; Vasudevan, R.; Johnson-Roberson, M. Off the beaten sidewalk: Pedestrian prediction in shared spaces for autonomous vehicles. IEEE Robot. Autom. Lett. 2020, 5, 6892–6899. [Google Scholar] [CrossRef]
- Saleh, K.; Hossny, M.; Nahavandi, S. Intent prediction of vulnerable road users from motion trajectories using stacked LSTM network. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 327–332. [Google Scholar]
- Mohamed, A.; Qian, K.; Elhoseiny, M.; Claudel, C. Social-STGCNN: A Social Spatio-Temporal Graph Convolutional Neural Network for Human Trajectory Prediction. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 14412–14420. [Google Scholar]
- Salzmann, T.; Ivanovic, B.; Chakravarty, P.; Pavone, M. Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 683–700. [Google Scholar]
- Pfeiffer, M.; Paolo, G.; Sommer, H.; Nieto, J.; Siegwart, R.; Cadena, C. A data-driven model for interaction-aware pedestrian motion prediction in object cluttered environments. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]
- Yang, D.; Li, L.; Redmill, K.; Özgüner, Ü. Top-view trajectories: A pedestrian dataset of vehicle-crowd interaction from controlled experiments and crowded campus. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 899–904. [Google Scholar]
- Bock, J.; Krajewski, R.; Moers, T.; Runde, S.; Vater, L.; Eckstein, L. The ind dataset: A drone dataset of naturalistic road user trajectories at german intersections. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 13–19 October 2020; pp. 1929–1934. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar]
- Kothari, P.; Kreiss, S.; Alahi, A. Human Trajectory Forecasting in Crowds: A Deep Learning Perspective. IEEE Trans. Intell. Transp. Syst. 2022, 23, 7386–7400. [Google Scholar] [CrossRef]
- Ivanovic, B.; Pavone, M. The Trajectron: Probabilistic Multi-Agent Trajectory Modeling With Dynamic Spatiotemporal Graphs. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 2375–2384. [Google Scholar]
- Chandra, R.; Bhattacharya, U.; Bera, A.; Manocha, D. TraPHic: Trajectory Prediction in Dense and Heterogeneous Traffic Using Weighted Interactions. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8475–8484. [Google Scholar]
- Zhao, T.; Xu, Y.; Monfort, M.; Choi, W.; Baker, C.; Zhao, Y.; Wang, Y.; Wu, Y.N. Multi-Agent Tensor Fusion for Contextual Trajectory Prediction. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12118–12126. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | DUT | inD | ||
|---|---|---|---|---|
| Model | ADE | RMSE | ADE | RMSE |
| Vanilla-LSTM | 1.52 | 1.06 | 1.38 | 1.07 |
| Vanilla-TF [17] | 1.21 | 0.95 | 1.07 | 0.96 |
| Context-LSTM | 1.16 | 0.95 | 1.03 | 0.96 |
| Context-TF (ours) | 0.97 | 0.88 | 0.80 | 0.88 |
| Dataset | DUT | inD | ||
|---|---|---|---|---|
| Model | ADE | RMSE | ADE | RMSE |
| Context-TF | 1.34 | 1.07 | 1.05 | 0.99 |
| Context-TF | 1.33 | 1.07 | 1.01 | 0.97 |
| Context-TF | 1.41 | 1.08 | 0.99 | 0.94 |
| Dataset | DUT | inD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| t (Second) | Linear-CV | Social-GAN [6] | MATF [35] | OSP [24] | Context-TF (Ours) | Linear-CV | Social-GAN [6] | MATF [35] | OSP [24] | Context-TF (Ours) |
| 1 | 0.39/0.38 | 0.62/0.66 | 0.63/0.72 | 0.22/0.30 | 0.41/0.54 | 0.50/0.50 | 0.98/1.09 | 0.42/0.50 | 0.12/0.37 | 0.11/0.34 |
| 2 | 0.84/0.82 | 0.86/0.96 | 1.22/1.40 | 0.49/0.64 | 0.65/0.69 | 1.10/1.13 | 1.58/1.79 | 0.86/1.03 | 0.37/0.83 | 0.26/0.50 |
| 3 | 1.31/1.28 | 1.21/1.43 | 1.87/2.15 | 0.78/1.01 | 0.77/0.76 | 1.79/1.85 | 2.24/2.56 | 1.40/1.68 | 0.67/1.35 | 0.42/0.64 |
| 4 | 1.81/1.75 | 1.67/2.02 | 2.58/2.97 | 1.09/1.37 | 0.88/0.82 | 2.57/2.64 | 2.96/3.39 | 2.00/2.40 | 1.02/1.92 | 0.60/0.77 |
| 5 | 2.31/2.22 | 2.20/2.73 | 3.37/3.85 | 1.41/1.74 | 0.97/0.88 | 3.42/3.50 | 3.74/4.28 | 2.65/3.20 | 1.42/2.53 | 0.80/0.88 |
| Dataset | nuScenes | |||
|---|---|---|---|---|
| Model | @1 s | @2 s | @3 s | @4 s |
| Linear-CV | 14.08/18.78 | 24.56/43.86 | 35.93/61.61 | 48.17/89.88 |
| Context-LSTM | 15.44/26.23 | 24.32/39.30 | 33.36/61.18 | 47.39/85.66 |
| Trajectron++ [27] | 12.06/16.27 | 21.51/36.20 | 32.10/59.32 | 43.88/85.85 |
| Context-TF (ours) | 11.09/14.99 | 19.91/33.62 | 30.02/55.80 | 41.39/82.36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saleh, K. Pedestrian Trajectory Prediction for Real-Time Autonomous Systems via Context-Augmented Transformer Networks. Sensors 2022, 22, 7495. https://doi.org/10.3390/s22197495
Saleh K. Pedestrian Trajectory Prediction for Real-Time Autonomous Systems via Context-Augmented Transformer Networks. Sensors. 2022; 22(19):7495. https://doi.org/10.3390/s22197495
Chicago/Turabian StyleSaleh, Khaled. 2022. "Pedestrian Trajectory Prediction for Real-Time Autonomous Systems via Context-Augmented Transformer Networks" Sensors 22, no. 19: 7495. https://doi.org/10.3390/s22197495