
A Novel Background Modeling Algorithm for Hyperspectral Ground-Based Surveillance and Through-Foliage Detection


Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
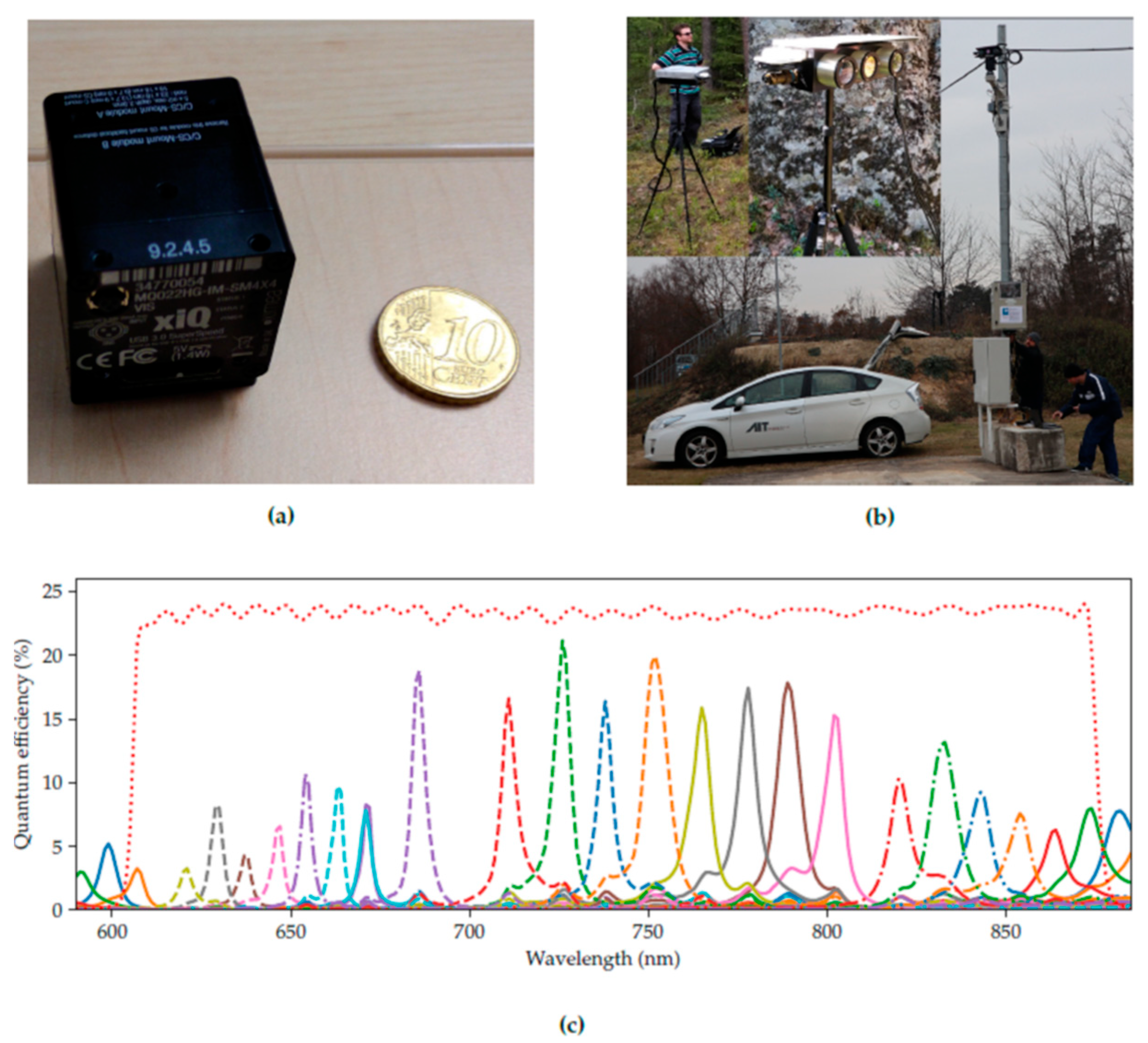
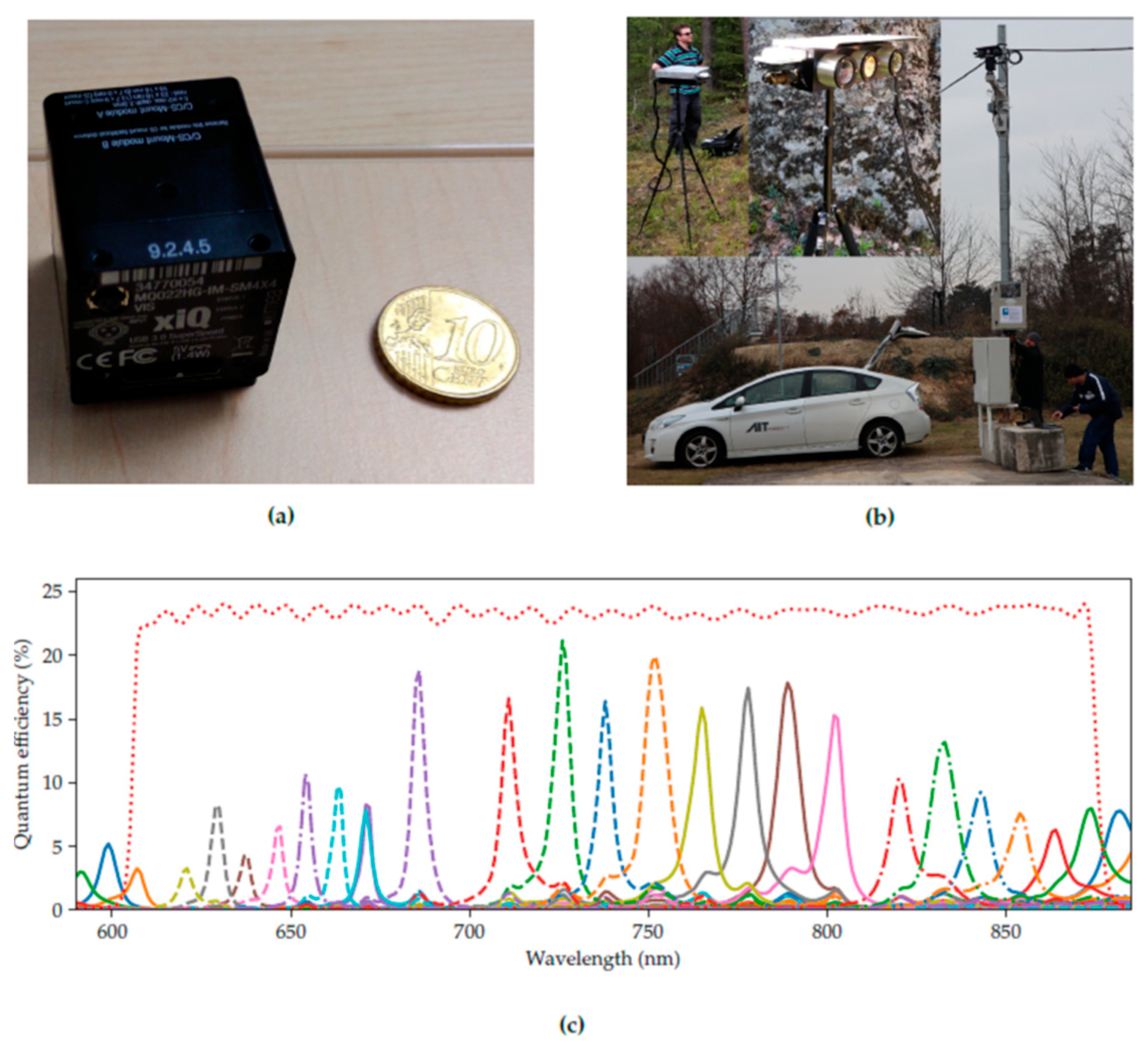
3.1. The Hyperspectral Sensor
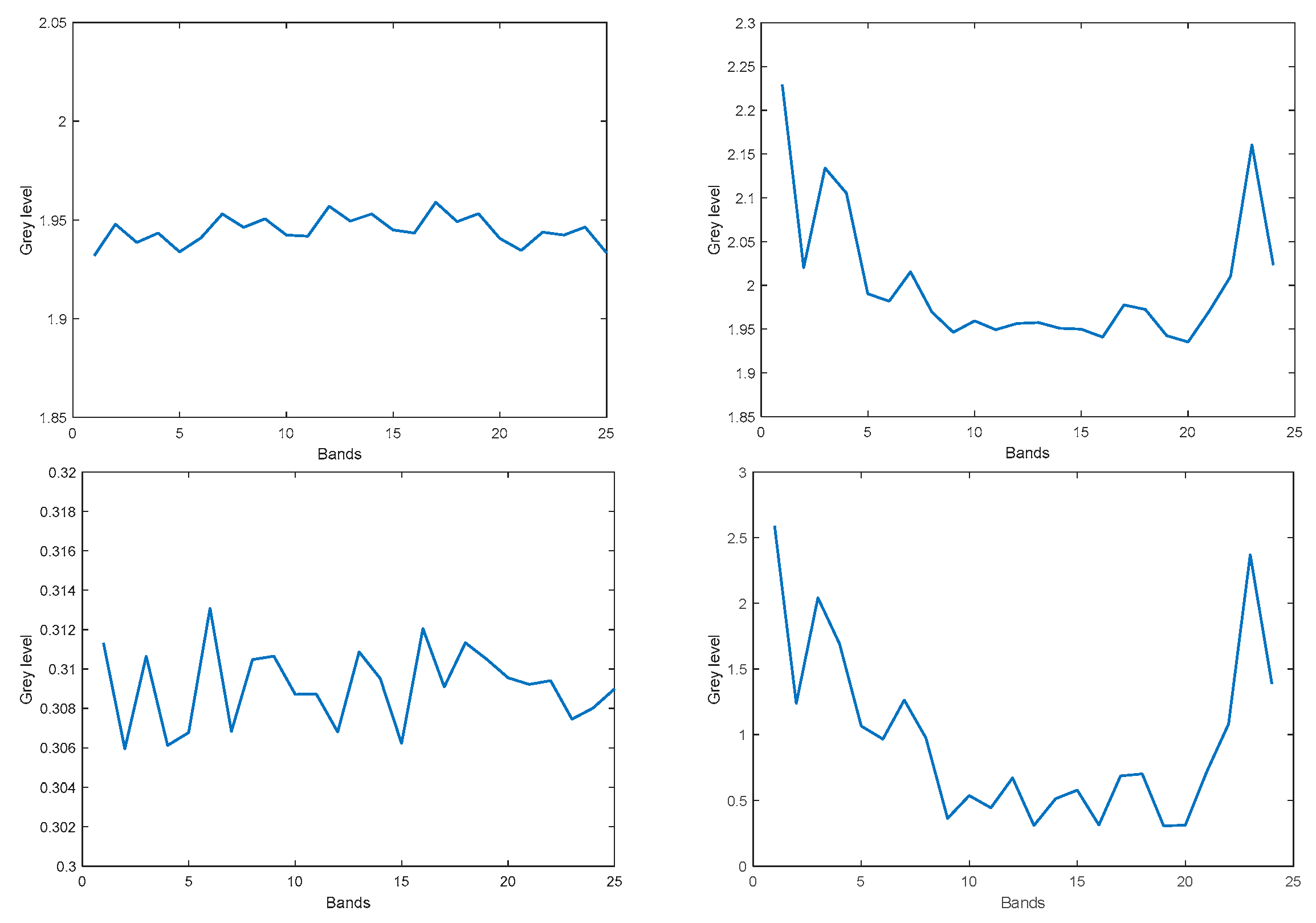
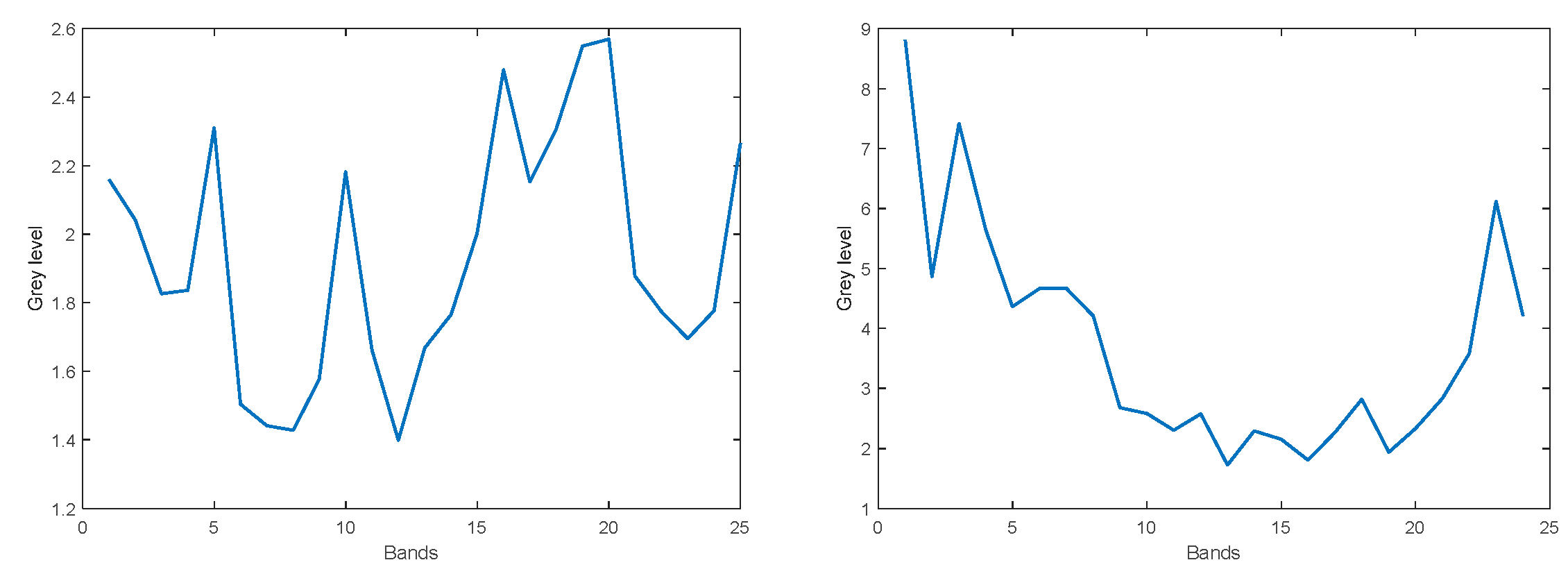
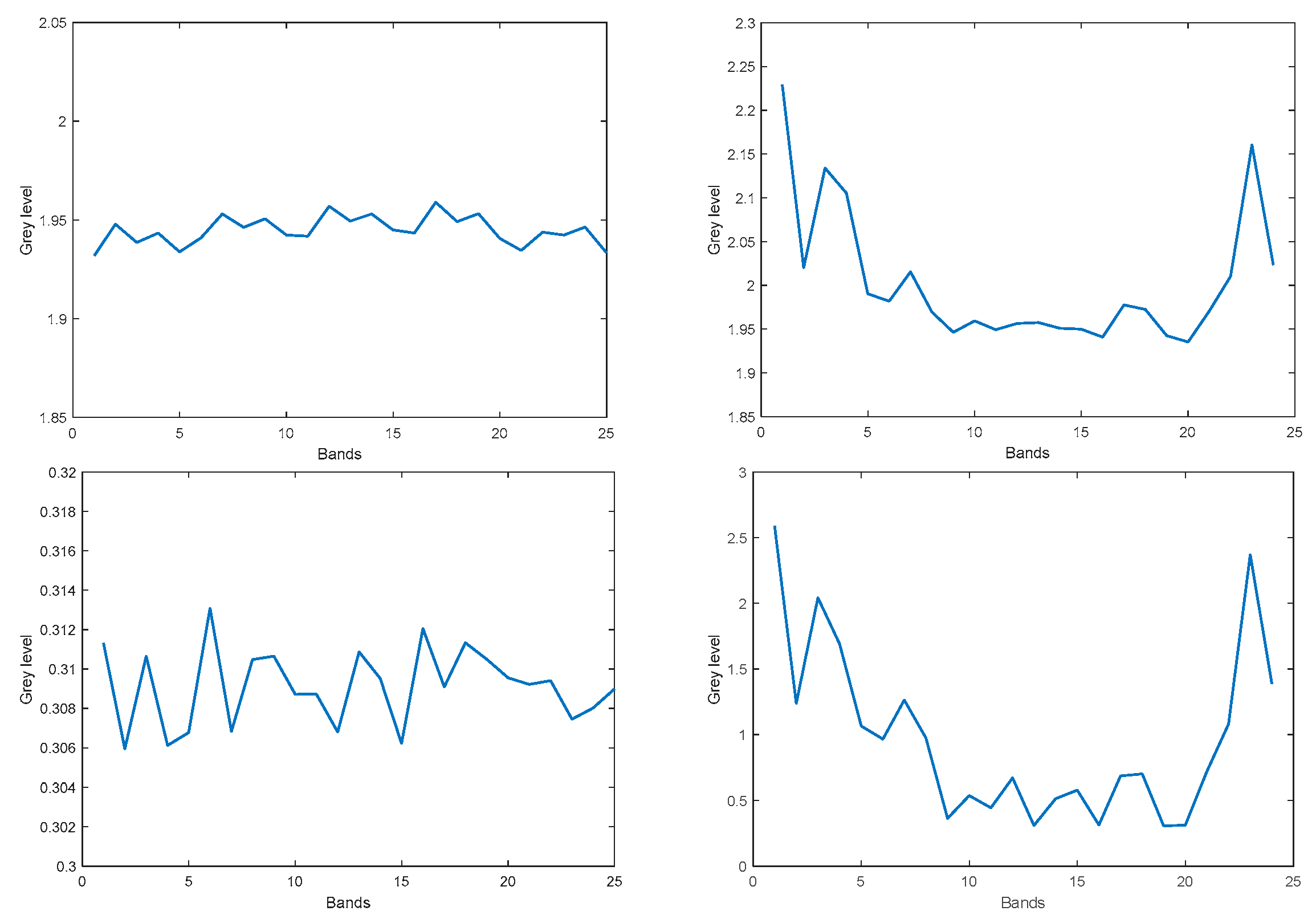
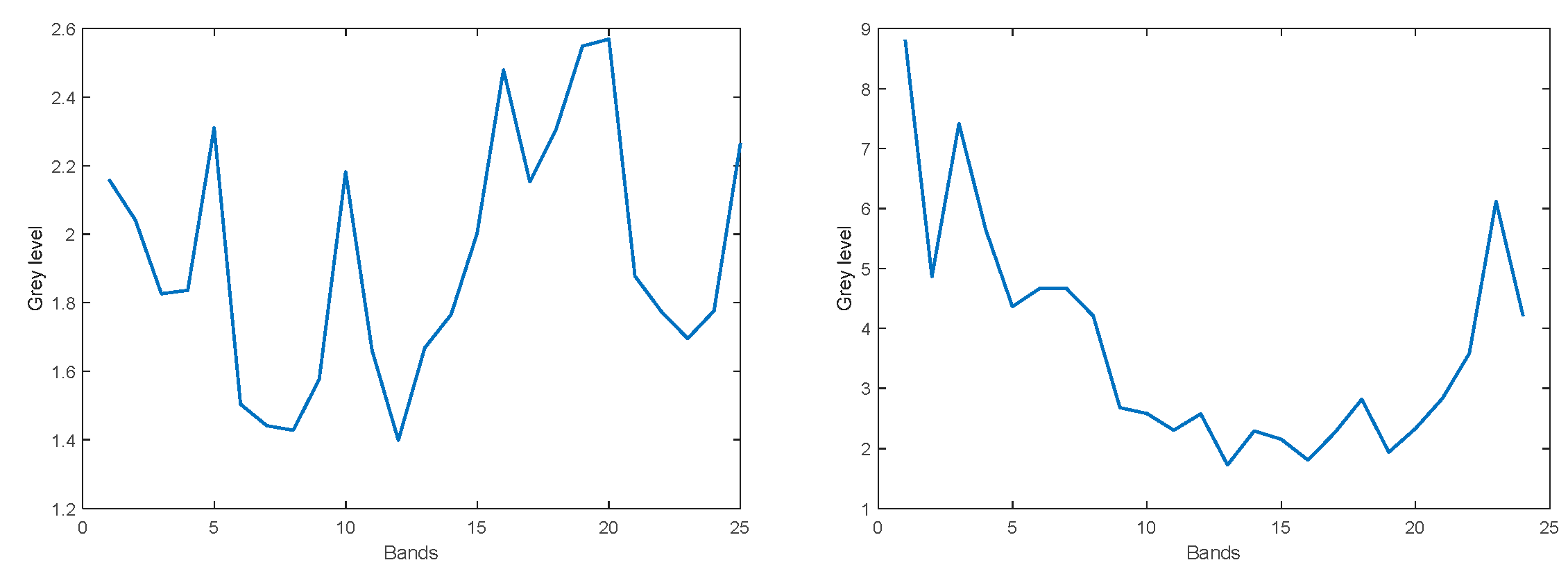
3.2. Noise Measurements
3.3. Dimensional Reduction of the Hyperspectral Data
3.3.1. Batch-Wise Dimensional Reduction Algorithms
3.3.2. Incremental Dimensional Reduction Algorithms
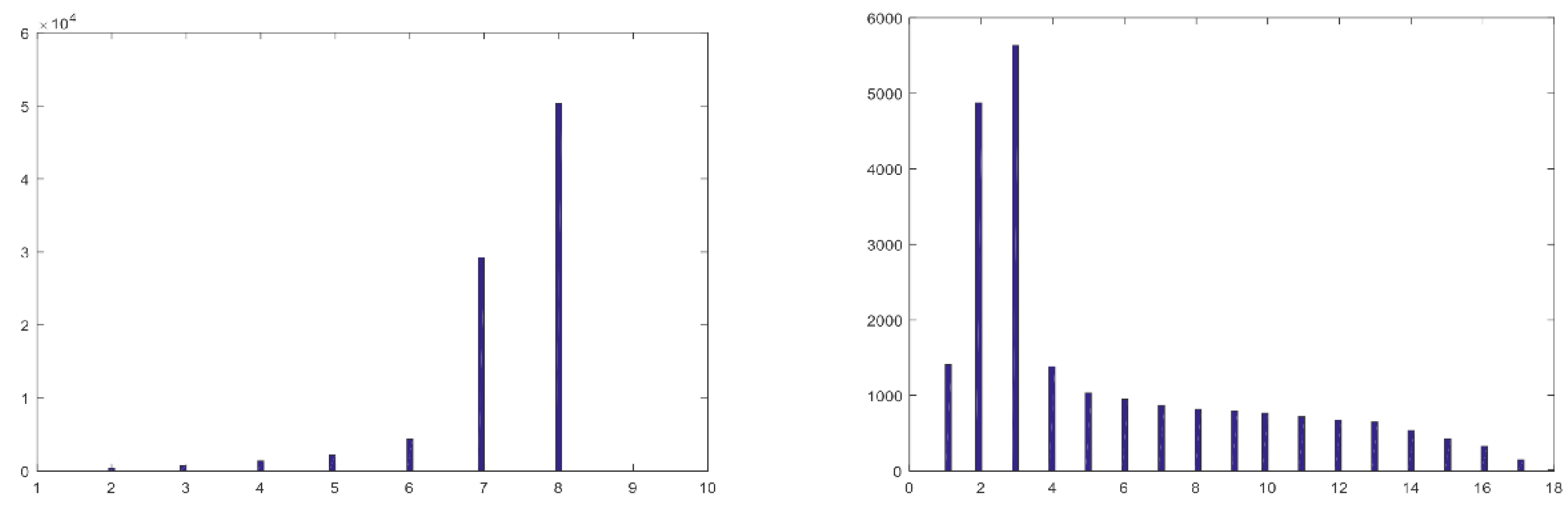
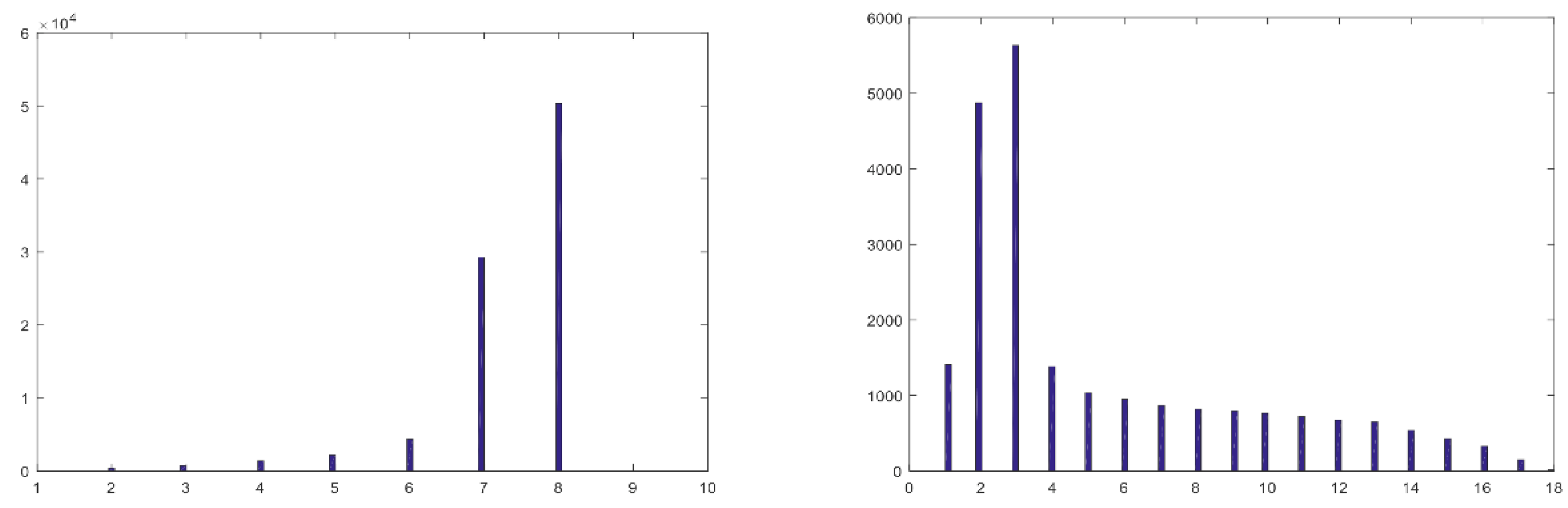
3.4. What Is the Subspace Dimensionality of the Hyperspectral Pixels
3.5. Hyperspectral Background Modeling Based on Local Dimensional Reduction
3.5.1. Motivation
3.5.2. The Background Modeling Algorithm
| Algorithm 1: Hyperspectral Background Modeling |
| Initialization: • Perform pixel-based batch-PCA on first frames to obtain the principal subspace for each pixel, • Compute moving window median and standard deviation , based on frames. for each 25-dimensional pixel in the new coming frame • Project the pixel to its current principal subspace • Label the pixel as background/foreground according to the residual vector perpendicular to the subspace • Update and • Post-process the resulting foreground mask: ○ Remove pixels with inconsistent (slow) motion ○ Filter isolated pixels ○ Smooth the foreground mask temporally ○ Accumulate evidence on the foreground mask ○ Raise detection alarm if moving objects detected • Update principal subspace and its dimensionality |
| End |
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- The Horizon 2020 Programme FOLDOUT Project. Available online: https://foldout.eu/ (accessed on 27 June 2022).
- Picus, C.; Bauer, D.; Hubner, M.; Kriechbaum-Zabini, A.; Opitz, A.; Pegoraro, J.; Schreiber, D.; Veigl, S. Novel Smart Sensor Technology Platform for Border Crossing Surveillance within FOLDOUT. J. Def. Secur. Technol. 2022, 5, 44–57. [Google Scholar] [CrossRef]
- Black, M.; Anandan, P. The Robust Estimation of Multiple Motions: Parametric and Piece-wise-Smooth Flow Fields. Comput. Vis. Image Underst. 1996, 63, 75–104. [Google Scholar] [CrossRef]
- Pegoraro, J.; Pflugfelder, R. The Problem of Fragmented Occlusion in Object Detection. In Proceedings of the Joint Austrian Computer Vision and Robotics Workshop, Graz, Austria, 16–17 April 2020. [Google Scholar]
- Papp, A.; Pegoraro, J.; Bauer, D.; Taupe, P.; Wiesmeyr, C.; Kriechbaum-Zabini, A. Automatic Annotation of Hyperspectral Images and Spectral Signal Classification of People and Vehicles in Areas of Dense Vegetation with Deep Learning. Remote Sens. 2020, 12, 2111. [Google Scholar] [CrossRef]
- Kandylakis, Z.; Vasili, K.; Karantzalos, K. Fusing Multimodal Video Data for Detecting Moving Objects/Targets in Challenging Indoor and Outdoor Scenes. Remote Sens. 2019, 11, 446. [Google Scholar] [CrossRef] [Green Version]
- Shah, M.; Cave, V.; dos Reis, M. Automatically localising ROIs in hyperspectral images using background subtraction techniques. In Proceedings of the 35th International Conference on Image and Vision Computing (IVCNZ), Wellington, New Zealand, 25–27 November 2020. [Google Scholar]
- Kandylakis, Z.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Multiple object tracking with background estimation in hyperspectral video sequences. In Proceedings of the 7th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Tokyo, Japan, 2–5 June 2015. [Google Scholar]
- Bouwmans, T.; Porikli, F.; Höferlin, B. Background Modeling and Foreground Detection for Video Surveillance; Chapman and Hall/CRC: New York, NY, USA, 2014. [Google Scholar]
- Stauffer, C.; Grimson, W. Adaptive Background Mixture Models for Real-Time Tracking. In Proceedings of the CVPR, Fort Collins, CO, USA, 23–25 June 1999. [Google Scholar]
- Elgammal, A.; Harwood, D.; Davis, L. Non-parametric model for background subtraction. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2000; pp. 751–767. [Google Scholar]
- Kim, K.; Chalidabhongse, T.; Harwood, D.; Davis, D. Real-time foreground–background segmentation using codebook model. J. Real-Time Imaging 2005, 11, 172–185. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Suter, D. A consensus-based method for tracking: Modelling background scenario and foreground appearance. Pattern Recognit. 2007, 40, 1091–1105. [Google Scholar] [CrossRef] [Green Version]
- Panda, D.K.; Meher, S. Dynamic background subtraction using Local Binary Pattern and Histogram of oriented Gradients. In Proceedings of the Third International Conference on Image Information Processing (ICIIP), Waknaghat, India, 21–24 December 2015. [Google Scholar]
- St-Charles, P.; Bilodeau, G.; Bergevin, R. SuBSENSE: A Universal Change Detection Method With Local Adaptive Sensitivity. IEEE Trans. Image Process. 2015, 24, 359–373. [Google Scholar] [CrossRef] [PubMed]
- Giraldo, J.; Le, T.; Bouwmans, T. Deep Learning based Background Subtraction: A Systematic Survey. In Handbook of Pattern Recognition and Computer Vision; World Scientific: Singapore, 2020; pp. 51–73. [Google Scholar]
- Braham, M.; van Droogenbroeck, M. Deep background subtraction with scene-specific convolutional neural networks. In Proceedings of the 2016 International Conference on Systems, Signals and Image Processing (IWSSIP), Bratislava, Slovakia, 23–25 May 2016. [Google Scholar]
- Benezeth, Y.; Sidibé, D.; Thomas, J.B. Background subtraction with multispectral video sequences. In Proceedings of the IEEE International Conference on Robotics and Automation workshop on Non-Classical Cameras, Camera Networks and Omnidirectional Vision (OMNIVIS), Hong Kong, China, 4–7 June 2014. [Google Scholar]
- Chen, C.; Wolf, W. Background modeling and object tracking using multi-spectral sensors. In Proceedings of the 4th ACM International Workshop on Video Surveillance and Sensor Networks (VSSN), Santa Barbara, CA, USA, 27 October 2006. [Google Scholar]
- Liu, R.; Ruichek, Y.; el Bagdouri, M. Background subtraction with multispectral images using codebook algorithm. In International Conference on Advanced Concepts for Intelligent Vision Systems; Springer: Cham, Switzerland, 2017; pp. 581–590. [Google Scholar]
- Healey, G.E.; Kondepudy, R. Radiometric CCD camera calibration and noise estimation. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 267–276. [Google Scholar] [CrossRef] [Green Version]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Green, A.A.; Berman, M.; Switzer, P.; Craig, M.D. A transformation for ordering multispectral data in terms of image quality with implications for noise removal. IEEE Trans. Geosci. Remote Sens. 1988, 26, 65–74. [Google Scholar] [CrossRef] [Green Version]
- De La Torre, F.; Black, M. A framework for robust subspace learning. Int. J. Comput. Vis. 2003, 54, 117–142. [Google Scholar] [CrossRef]
- Li, Y. On incremental and robust subspace learning. Pattern Recognit. 2004, 37, 1509–1518. [Google Scholar] [CrossRef]
- Huber, J.; Ronchetti, E.M.E. Robust Statistics; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2009. [Google Scholar]
- Hofmann, M.; Tiefenbacher, P.; Rigoll, G. Background segmentation with feedback: The Pixel-Based Adaptive Segmenter. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence (IJCAI), Vancouver, BC, Canada, 24–28 August 1981. [Google Scholar]
- Schreiber, D.; Rauter, M. GPU-based non-parametric background subtraction for a practical surveillance system. In Proceedings of the IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Background Modeling (Hyperspectral) | YOLOv5 (Thermal) | YOLOv5 (RGB) | |
|---|---|---|---|
| True Positive Rate = TP/(TP + FN) | 93% | 3% | 12% |
| False Positive rates = FP/(TN + FP) | 7% | 0% | 0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schreiber, D.; Opitz, A. A Novel Background Modeling Algorithm for Hyperspectral Ground-Based Surveillance and Through-Foliage Detection. Sensors 2022, 22, 7720. https://doi.org/10.3390/s22207720
Schreiber D, Opitz A. A Novel Background Modeling Algorithm for Hyperspectral Ground-Based Surveillance and Through-Foliage Detection. Sensors. 2022; 22(20):7720. https://doi.org/10.3390/s22207720
Chicago/Turabian StyleSchreiber, David, and Andreas Opitz. 2022. "A Novel Background Modeling Algorithm for Hyperspectral Ground-Based Surveillance and Through-Foliage Detection" Sensors 22, no. 20: 7720. https://doi.org/10.3390/s22207720
APA StyleSchreiber, D., & Opitz, A. (2022). A Novel Background Modeling Algorithm for Hyperspectral Ground-Based Surveillance and Through-Foliage Detection. Sensors, 22(20), 7720. https://doi.org/10.3390/s22207720