


Daily Estimation of Global Solar Irradiation and Temperatures Using Artificial Neural Networks through the Virtual Weather Station Concept in Castilla and León, Spain

 ,
,  ,
,  ,
, 
Abstract
1. Introduction
2. Materials and Methods
2.1. Daily Data on Global Solar Irradiation and Ambient Temperature (Maximum, Average and Minimum)
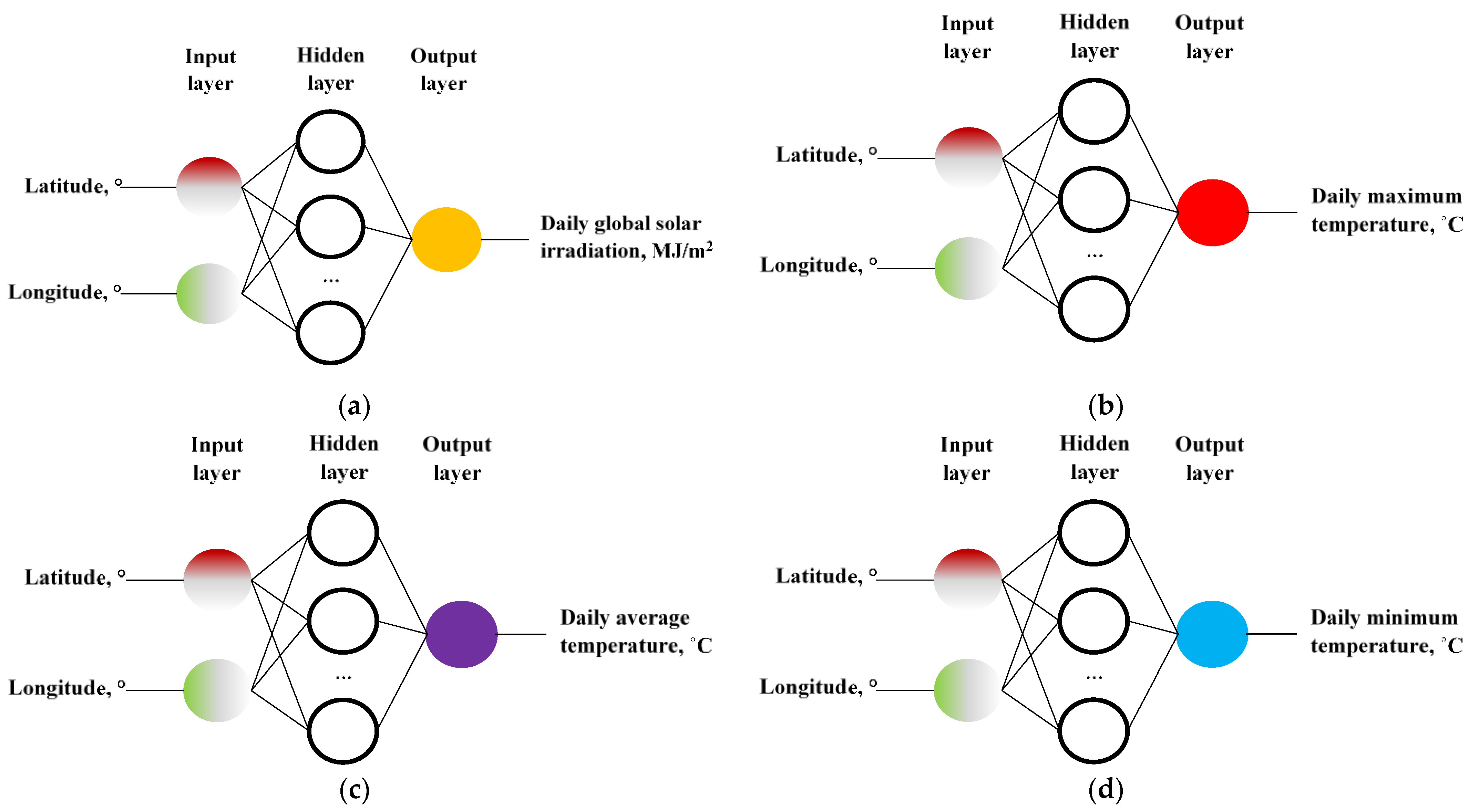
2.2. Estimation of Solar Irradiation and Ambient Temperature Using Artificial Neural Networks
2.3. Statistics for the Validation of the ANN Models
3. Results
3.1. ANN Models for Estimating Daily Global Solar Irradiation at the Reference Station
3.2. ANN Models for the Estimation of the Maximum Daily Temperature in the Reference Station
3.3. ANN Models for the Estimation of the Average Daily Temperature in the Reference Station
3.4. ANN Models for the Estimation of the Minimum Daily Temperature in the Reference Station
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Nomenclature
| ANN | Artificial Neural Network |
| ARRMSE | Average Relative Root Mean Square |
| BP-LM | Back-Propagation Levenberg–Marquardt algorithm |
| CGAN | Conditional Generative Adversarial Networks |
| DIDW | Dual Inverse Distance Weighting |
| ETo | Evapotranspiration |
| GAM | Generalized Additive Regression |
| GCM | General Circulation Models |
| GIS | Geographic Information System |
| IDW | Inverse Distance Weighting |
| IoT | Internet of Things |
| ITACyL | Agricultural Technological Institute in Castilla and León (Instituto Tecnológico Agrario de Castilla y León, in Spanish) |
| LR | Linear Regression |
| LSDV | Least Squares Dummy Variable |
| mamsl | meters above mean sea level |
| MARS | Monitoring Agriculture with Remote Sensing |
| MCYFS | MARS Crop Yield Forecasting System |
| MLP | Multilayer Feed-forward Perceptron |
| MLR | Multivariate Linear Regression |
| OCK | Ordinary Co-Kriging |
| OK | Ordinary Kriging |
| OLI | Operational land imager |
| RF | Random Forest |
| RMSE | Root Mean Square Error |
| R2 | Coefficient of determination |
| SIAR | Agro-climatic Information System for Irrigation (Sistema de Información para el Asesoramiento al Riego, in Spanish) |
| SIDW | Semantics Inverse Distance Weighting |
| TIRS | Thermal infrared sensor |
| SIM | Spatial Interpolation Methods |
| VWS | Virtual Weather Station. |
Appendix A

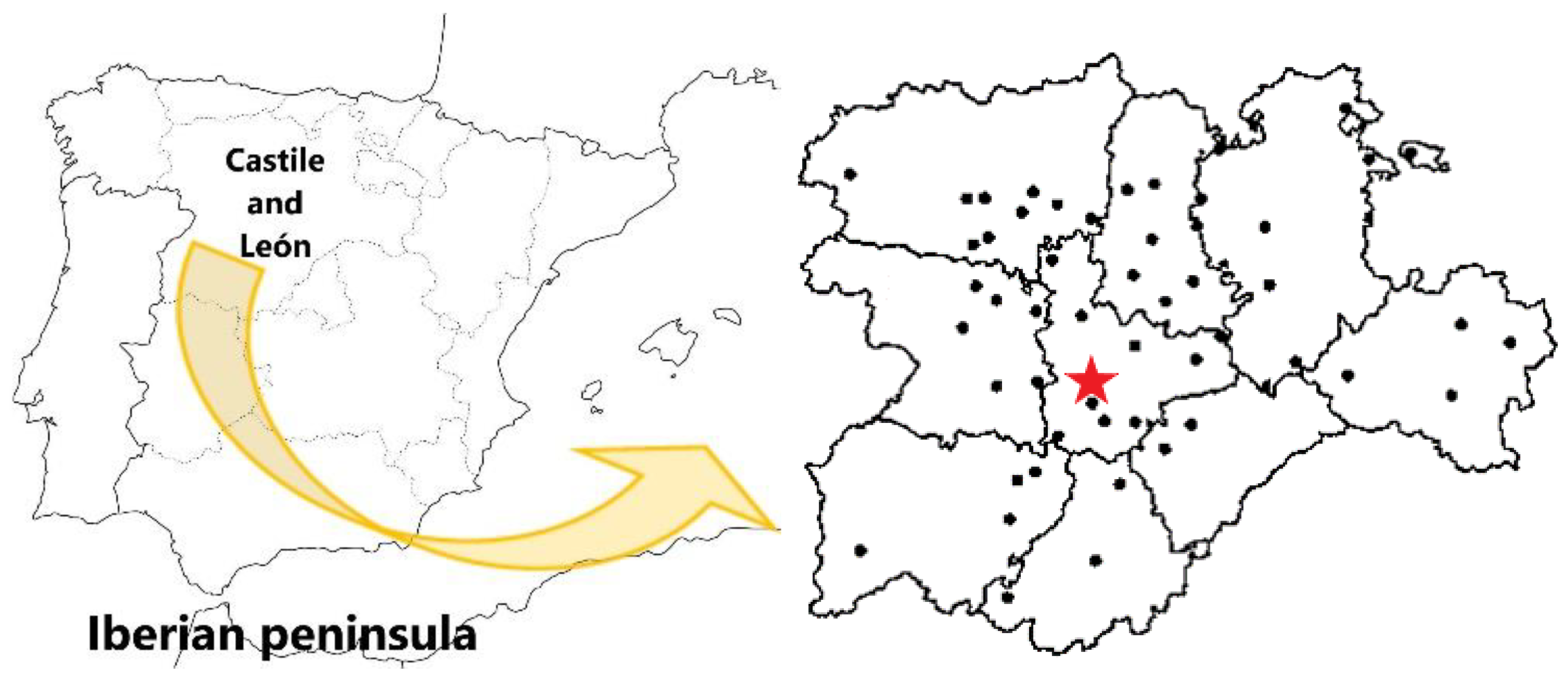{kind=link}
{kind=link}
| Province | Location | Altitude (mamsl) | Latitude (°) | Longitude (°) |
|---|---|---|---|---|
| Ávila | Nava de Arévalo | 921 | 40.997 | −4.765 |
| Ávila | Muñogalindo | 1128 | 40.597 | −4.905 |
| Ávila | Losar del Barco | 1027 | 40.397 | −5.535 |
| Burgos | Valle de Losa | 635 | 42.988 | −3.220 |
| Burgos | Condado de Treviño | 551 | 42.719 | −2.690 |
| Burgos | Valle de Valdelucio | 975 | 42.724 | −4.081 |
| Burgos | Lerma | 840 | 41.987 | −3.763 |
| Burgos | Tardajos | 770 | 42.353 | −3.814 |
| Burgos | Vadocondes | 870 | 41.628 | −3.573 |
| Burgos | Santa Gadea del Cid | 520 | 42.684 | −3.108 |
| León | Carracedelo | 467 | 42.550 | −6.733 |
| León | Mansilla Mayor | 791 | 42.512 | −5.446 |
| León | Cubillas de los Oteros | 777 | 42.378 | −5.511 |
| León | Zotes del Páramo | 779 | 42.265 | −5.731 |
| León | Quintana del Marco | 750 | 42.201 | −5.862 |
| León | Hospital de Órbigo | 835 | 42.463 | −5.883 |
| León | Bustillo del Páramo | 874 | 42.439 | −5.800 |
| León | Sahagún | 856 | 42.369 | −5.006 |
| León | Santas Martas | 885 | 42.453 | −5.362 |
| Palencia | Torquemada | 868 | 42.039 | −4.300 |
| Palencia | Villaeles de Valdavia | 881 | 42.576 | −4.558 |
| Palencia | Villamuriel del Cerrato | 750 | 41.952 | −4.508 |
| Palencia | Fuentes de Nava | 744 | 42.090 | −4.767 |
| Palencia | Villoldo | 817 | 42.256 | −4.598 |
| Palencia | Herrera de Pisuerga | 821 | 42.549 | −4.311 |
| Palencia | Villaluenga de la Vega | 927 | 42.525 | −4.776 |
| Palencia | Lantadilla | 798 | 42.336 | −4.300 |
| Salamanca | Ciudad Rodrigo | 635 | 40.618 | −6.492 |
| Salamanca | Arabayona | 850 | 41.047 | −5.393 |
| Salamanca | Ejeme | 812 | 40.769 | −5.525 |
| Salamanca | Aldearrubia | 815 | 41.004 | −5.493 |
| Segovia | Gomezserracín | 870 | 41.287 | −4.299 |
| Segovia | Navas de la Asunción | 822 | 41.141 | −4.486 |
| Soria | Almazán | 943 | 41.483 | −2.556 |
| Soria | Hinojosa del Campo | 1043 | 41.743 | −2.081 |
| Soria | San Esteban de Gormaz | 855 | 41.535 | −3.220 |
| Soria | Fuentecantos | 1063 | 41.843 | −2.434 |
| Valladolid | Mayorga | 748 | 42.172 | −5.300 |
| Valladolid | Finca Zamadueñas | 714 | 41.626 | −4.740 |
| Valladolid | Medina del Campo | 724 | 41.320 | −4.904 |
| Valladolid | Rueda | 700 | 41.385 | −4.968 |
| Valladolid | Villalón de Campos | 788 | 42.100 | −5.034 |
| Valladolid | Torrecilla de la Orden | 793 | 41.219 | −5.267 |
| Valladolid | Olmedo | 750 | 41.292 | −4.717 |
| Valladolid | Encinas de Esguevas | 816 | 41.754 | −4.091 |
| Valladolid | Tordesillas | 658 | 41.509 | −4.989 |
| Valladolid | Valbuena de Duero | 756 | 41.662 | −4.284 |
| Valladolid | Medina de Rioseco | 739 | 41.889 | −5.030 |
| Zamora | Colinas de Trasmonte | 709 | 42.014 | −5.821 |
| Zamora | Villaralbo | 659 | 41.497 | −5.670 |
| Zamora | Villalpando | 701 | 41.825 | −5.406 |
| Zamora | Pozuelo de Tábara | 714 | 41.780 | −5.907 |
| Zamora | Barcial del Barco | 738 | 41.935 | −5.644 |
| Zamora | Toro | 623 | 41.489 | −5.470 |
References
- Lee, C.-L.; Strong, R.; Dooley, K.E. Analyzing precision agriculture adoption across the globe: A systematic review of scholarship from 1999–2020. Sustainability 2021, 13, 10295. [Google Scholar] [CrossRef]
- Nguyen, L.L.H.; Halibas, A.; Nguyen, T.Q. Determinants of precision agriculture technology adoption in developing countries: A review. J. Crop Improv. 2022, 1–24. [Google Scholar] [CrossRef]
- Pasquel, D.; Roux, S.; Richetti, J.; Cammarano, D.; Tisseyre, B.; Taylor, J.A. A review of methods to evaluate crop model performance at multiple and changing spatial scales. Precis. Agric. 2022, 23, 1489–1513. [Google Scholar] [CrossRef]
- Jayaraman, P.P.; Yavari, A.; Georgakopoulos, D.; Morshed, A.; Zaslavsky, A. Internet of things platform for smart farming: Experiences and lessons learnt. Sensors 2016, 16, 1884. [Google Scholar] [CrossRef]
- Leirvik, T.; Yuan, M. A machine learning technique for spatial interpolation of solar radiation observations. Earth Space Sci. 2021, 8, e2020EA001527. [Google Scholar] [CrossRef]
- Aaheim, A.; Romstad, B.; Wei, T.; Kristjánsson, J.E.; Muri, H.; Niemeier, U.; Schmidt, H. An economic evaluation of solar radiation management. Sci. Total Environ. 2015, 532, 61–69. [Google Scholar] [CrossRef]
- Calcabrini, A.; Ziar, H.; Isabella, O.; Zeman, M. A simplified skyline-based method for estimating the annual solar energy potential in urban environments. Nat. Energy 2019, 4, 206–215. [Google Scholar] [CrossRef]
- Thornton, P.K.; van de Steeg, J.; Notenbaert, A.; Herrero, M. The impacts of climate change on livestock and livestock systems in developing countries: A review of what we know and what we need to know. Agric. Syst. 2009, 101, 113–127. [Google Scholar] [CrossRef]
- Tollenaar, M.; Fridgen, J.; Tyagi, P.; Stackhouse, P.W., Jr.; Kumudini, S. The contribution of solar brightening to the US maize yield trend. Nat.Clim. Change 2017, 7, 275–278. [Google Scholar] [CrossRef]
- Yang, Y.; Xu, W.; Hou, P.; Liu, G.; Liu, W.; Wang, Y.; Zhao, R.; Ming, B.; Xie, R.; Wang, K.; et al. Improving maize grain yield by matching maize growth and solar radiation. Sci. Rep. 2019, 9, 3635. [Google Scholar] [CrossRef] [PubMed]
- Franco, B.M.; Hernández-Callejo, L.; Navas-Gracia, L.M. Virtual weather stations for meteorological data estimations. Neural Comput. Appl. 2020, 32, 12801–12812. [Google Scholar] [CrossRef]
- Fu, P.; Rich, P.M. A geometric solar radiation model with applications in agriculture and forestry. Comput. Electron. Agric. 2002, 37, 25–35. [Google Scholar] [CrossRef]
- Mavromatis, T.; Jagtap, S.S. Estimating solar radiation for crop modeling using temperature data from urban and rural stations. Clim. Res. 2005, 29, 233–243. [Google Scholar] [CrossRef]
- Donatelli, M.; Bellocchi, G. New methods to estimate global solar radiation. In Proceedings of the Thrid International Crop Science Conference, Hamburg, Germany, 17–22 August 2000. [Google Scholar]
- Belocchi, G.; Acutis, M.; Filla, G.; Donatelli, M. An indicator of solar radiation model performance based on fuzzy expert system. Agron. J. 2002, 94, 1222–1233. [Google Scholar] [CrossRef]
- Zhu, D.; Cheng, X.; Zhang, F.; Yao, X.; Gao, Y.; Liu, Y. Spatial interpolation using conditional generative adversarial neural networks. Int. J. Geogr. Inf. Sci. 2020, 34, 735–758. [Google Scholar] [CrossRef]
- Zou, L.; Wang, L.; Lin, A.; Zhu, H.; Peng, Y.; Zhao, Z. Estimation of global solar radiation using an artificial neural network based on an interpolation technique in southeast China. J. Atmos. Sol. Terr. Phys. 2016, 146, 110–122. [Google Scholar] [CrossRef]
- Li, J.; Heap, A.D. Spatial interpolation methods applied in the environmental sciences: A review. Environ. Model. Softw. 2014, 53, 173–189. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, X.; Zhu, R.; Zhang, Z.; Weng, Z. Integrating data-to-data correlation into inverse distance weighting. Comput. Geosci. 2020, 24, 203–216. [Google Scholar] [CrossRef]
- Wu, W.; Gan, R.; Li, J.; Cao, X.; Ye, X.; Zhang, J.; Qu, H. A spatial interpolation of meteorological parameters considering geographic semantics. Adv. Meteorol. 2020, 2020, 9185283. [Google Scholar] [CrossRef]
- Loghmari, I.; Timoumi, Y.; Messadi, A. Performance comparison of two global solar radiation models for spatial interpolation purposes. Renew. Sust. Energ. Rev. 2018, 82, 837–844. [Google Scholar] [CrossRef]
- Gunawardena, N.; Durand, P.; Hedde, T.; Dupuy, F.; Pardyjak, E. Data filling of micrometeorological variables in complex terrain for high-resolution nowcasting. Atmosphere 2022, 13, 408. [Google Scholar] [CrossRef]
- MARS Crop Yield Forecasting System (MCYFS) Wiki of the European Commission. Interpolation of Observed Weather. Available online: https://marswiki.jrc.ec.europa.eu/agri4castwiki/index.php/Interpolation_of_observed_weather (accessed on 1 June 2022).
- Martín, A.M.; Dominguez, J. Solar radiation interpolation. In Solar Resources Mapping. Fundamentals and Applications; Polo, J., Martín-Pomares, L., Sanfilippo, A., Eds.; Springer: Cham, Switzerland, 2019; pp. 221–242. [Google Scholar]
- Keskin, M.; Dogru, A.O.; Balcik, F.B.; Goksel, C.; Ulugtekin, N.; Sozen, S. Comparing spatial interpolation methods for mapping meteorological data in Turkey. In Energy Systems and Management; Bilge, A., Toy, A., Günay, M., Eds.; Springer: Cham, Switzerland, 2015; pp. 33–42. [Google Scholar]
- Yazar, M.F.; Ozelkan, E.; Üstündağ, B.B. Multi-parameter spatial interpolation of solar radiation in heterogeneous structured agricultural areas. In Proceedings of the Third International Conference on Agro-Geoinformatics, Beijing, China, 11–14 August 2014. [Google Scholar]
- Antonić, O.; Križan, J.; Marki, A.; Bukovec, D. Spatio-temporal interpolation of climatic variables over large Region of complex terrain using neural networks. Ecol. Model. 2001, 138, 255–263. [Google Scholar] [CrossRef]
- Siqueira, A.N.; Tiba, C.; Fraidenraich, N. Spatial interpolation of daily solar irradiation, through artificial neural networks. In Proceedings of the ISES World Congress 2007 (Vol. I–Vol. V) Solar Energy and Human Settlement, Beijing, China, 18–21 September 2007; Tsinghua University Press: Beijing, China; Springer: Berlin, Germany, 2008; pp. 2573–2577. [Google Scholar]
- Snell, S.; Gopal, S.; Kaufmann, R. Spatial interpolation of surface air temperatures using artificial neural networks: Evaluating their use for downscaling GCMs. J. Clim. 2000, 13, 886–895. [Google Scholar] [CrossRef]
- Rigol, J.P.; Jarvis, C.H.; Stuart, N. Artificial neural networks as a tool for spatial interpolation. Int. J. Geogr. Inf. Sci. 2001, 15, 323–343. [Google Scholar] [CrossRef]
- Zambon, I.; Cecchini, M.; Egidi, G.; Saporito, M.G.; Colantoni, A. Revolution 4.0: Industry vs. Agriculture in a future development for SMEs. Processes 2019, 7, 36. [Google Scholar] [CrossRef]
- InfoRiego. Información Meteorológica. Available online: http://www.inforiego.org (accessed on 1 June 2022).
- Chazarra, A.; Flórez, E.; Peraza, B.; Tohá, T.; Lorenzo, B.; Criado, E.; Moreno, J.V.; Romero, R.; Botey, R. Mapas Climáticos de España (1981–2010) y ETo (1996–2016), 1st ed.; Agencia Estatal de Meteorología (AEMET), Ministerio para la Transición Ecológica: Madrid, Spain, 2018; pp. 11–13. [Google Scholar]
- Diez, F.J.; Navas-Gracia, L.M.; Chico-Santamarta, L.; Correa-Guimaraes, A.; Martínez-Rodríguez, A. Prediction of horizontal daily global solar irradiation using artificial neural networks (ANNs) in the Castile and León Region, Spain. Agronomy 2020, 10, 96. [Google Scholar] [CrossRef]
- Diez, F.J.; Correa-Guimaraes, A.; Chico-Santamarta, L.; Martínez-Rodríguez, A.; Murcia-Velasco, D.A.; Andara, R.; Navas-Gracia, L.M. Prediction of daily ambient temperature and its hourly estimation using artificial neural networks in an agrometeorological station in Castile and León, Spain. Sensors 2022, 22, 4850. [Google Scholar] [CrossRef]
- Strong, R.; Wynn, J.T., II; Lindner, J.R.; Palmer, K. Evaluating brazilian agriculturalists’ IoT smart agriculture adoption barriers: Understanding stakeholder salience prior to launching an innovation. Sensors 2022, 22, 6833. [Google Scholar] [CrossRef]
- Kilelu, C.W.; Lee, J.v.d.; Koge, J.; Klerkx, L. Emerging advisory service agri-enterprises: A dual perspective on technical and business performance. J. Agric. Educ. Ext. 2022, 28, 45–65. [Google Scholar] [CrossRef]
- Mehdizadeh, S. Assessing the potential of data-driven models for estimation of long-term monthly temperatures. Comput. Electron. Agric. 2018, 144, 114–125. [Google Scholar] [CrossRef]
- da Silva Júnior, J.C.; Medeiros, V.; Garrozi, C.; Montenegro, A.; Gonçalves, G.E. Random forest techniques for spatial interpolation of evapotranspiration data from Brazilian’s Northeast. Comput. Electron. Agric. 2019, 166, 105017. [Google Scholar] [CrossRef]
- Aparecido, L.E.O.; Cabral de Moraes, J.R.S.; Cunha de Meneses, K.; Torsoni, G.B.; Silva e Costa, C.T.; Mesquita, D.Z. Climate efficiency for sugarcane production in Brazil and its application in agricultural zoning. Sugar Tech 2021, 23, 776–793. [Google Scholar] [CrossRef]


| Tordesillas | Data | ANN (2-4-1) | ANN (2-3-1) | ANN (2-2-1) | ANN (2-1-1) |
|---|---|---|---|---|---|
| 1 June 2020 | 27.58 | 26.85 | 27.27 | 27.62 | 26.83 |
| 2 June 2020 | 25.61 | 25.60 | 26.03 | 25.79 | 25.79 |
| 3 June 2020 | 24.38 | 23.16 | 22.23 | 21.90 | 22.77 |
| 4 June 2020 | 27.74 | 25.29 | 25.07 | 24.68 | 24.67 |
| 5 June 2020 | 31.09 | 30.41 | 30.79 | 29.92 | 30.00 |
| 6 June 2020 | 27.45 | 27.29 | 26.22 | 26.29 | 25.98 |
| 7 June 2020 | 17.94 | 17.58 | 16.14 | 16.92 | 17.10 |
| 8 June 2020 | 26.96 | 26.75 | 26.72 | 26.60 | 26.47 |
| 9 June 2020 | 24.94 | 26.89 | 27.32 | 27.06 | 26.07 |
| 10 June 2020 | 28.46 | 27.96 | 28.60 | 27.73 | 27.64 |
| 11 June 2020 | 21.55 | 20.72 | 22.33 | 21.74 | 21.07 |
| 12 June 2020 | 14.93 | 14.16 | 15.71 | 15.94 | 14.41 |
| 13 June 2020 | 21.29 | 20.51 | 21.10 | 20.21 | 20.36 |
| 14 June 2020 | 27.64 | 26.34 | 26.60 | 26.31 | 26.18 |
| 15 June 2020 | 22.21 | 22.30 | 23.11 | 22.43 | 22.69 |
| RMSE | 1.04 | 1.31 | 1.38 | 1.23 | |
| R2 | 0.94 | 0.90 | 0.89 | 0.91 |
| Tordesillas | Data | ANN (2-4-1) | ANN (2-3-1) | ANN (2-2-1) | ANN (2-1-1) |
|---|---|---|---|---|---|
| 1 June 2020 | 28.73 | 27.92 | 27.96 | 27.72 | 27.54 |
| 2 June 2020 | 29.73 | 29.01 | 29.34 | 29.05 | 28.57 |
| 3 June 2020 | 27.73 | 26.52 | 26.17 | 26.18 | 25.58 |
| 4 June 2020 | 21.26 | 20.98 | 20.78 | 21.09 | 20.82 |
| 5 June 2020 | 26.86 | 26.60 | 26.28 | 26.68 | 26.30 |
| 6 June 2020 | 27.13 | 26.12 | 26.48 | 25.92 | 25.59 |
| 7 June 2020 | 19.19 | 18.15 | 19.26 | 18.57 | 18.74 |
| 8 June 2020 | 20.06 | 20.05 | 19.86 | 19.91 | 19.89 |
| 9 June 2020 | 20.26 | 20.26 | 20.60 | 21.02 | 20.62 |
| 10 June 2020 | 24.8 | 24.33 | 24.14 | 24.11 | 24.12 |
| 11 June 2020 | 21.46 | 20.66 | 20.42 | 20.32 | 20.39 |
| 12 June 2020 | 18.2 | 17.45 | 16.71 | 16.84 | 16.42 |
| 13 June 2020 | 18.99 | 19.37 | 19.30 | 19.45 | 19.28 |
| 14 June 2020 | 21.79 | 21.98 | 21.18 | 21.29 | 21.17 |
| 15 June 2020 | 22.79 | 22.20 | 22.17 | 22.00 | 22.22 |
| RMSE | 0.68 | 0.77 | 0.86 | 1.04 | |
| R2 | 0.97 | 0.96 | 0.95 | 0.92 |
| Tordesillas | Data | ANN (2-4-1) | ANN (2-3-1) | ANN (2-2-1) | ANN (2-1-1) |
|---|---|---|---|---|---|
| 1 June 2020 | 20.39 | 19.71 | 19.40 | 19.47 | 19.26 |
| 2 June 2020 | 22.00 | 21.47 | 21.53 | 20.98 | 20.57 |
| 3 June 2020 | 19.04 | 18.51 | 18.20 | 18.40 | 17.98 |
| 4 June 2020 | 16.15 | 16.02 | 15.42 | 14.92 | 15.35 |
| 5 June 2020 | 16.83 | 16.13 | 16.50 | 16.80 | 16.57 |
| 6 June 2020 | 18.09 | 17.46 | 18.04 | 17.53 | 17.31 |
| 7 June 2020 | 14.65 | 13.61 | 13.61 | 13.62 | 13.96 |
| 8 June 2020 | 13.77 | 13.03 | 13.14 | 12.94 | 12.82 |
| 9 June 2020 | 13.83 | 13.06 | 13.83 | 13.09 | 13.05 |
| 10 June 2020 | 16.68 | 15.75 | 16.20 | 15.75 | 15.83 |
| 11 June 2020 | 15.11 | 14.69 | 14.50 | 14.80 | 14.02 |
| 12 June 2020 | 11.88 | 11.31 | 11.88 | 11.18 | 11.20 |
| 13 June 2020 | 13.45 | 13.37 | 13.15 | 12.84 | 12.72 |
| 14 June 2020 | 15.43 | 15.10 | 15.10 | 14.76 | 14.59 |
| 15 June 2020 | 15.99 | 15.84 | 15.57 | 15.41 | 15.40 |
| RMSE | 0.61 | 0.58 | 0.78 | 0.88 | |
| R2 | 0.95 | 0.95 | 0.91 | 0.89 |
| Tordesillas | Data | ANN (2-4-1) | ANN (2-3-1) | ANN (2-2-1) | ANN (2-1-1) |
|---|---|---|---|---|---|
| 1 June 2020 | 11.93 | 10.80 | 10.57 | 10.93 | 10.67 |
| 2 June 2020 | 13.67 | 13.38 | 13.54 | 13.27 | 12.85 |
| 3 June 2020 | 13.86 | 13.21 | 13.88 | 13.00 | 13.00 |
| 4 June 2020 | 11.33 | 9.32 | 9.37 | 9.20 | 9.16 |
| 5 June 2020 | 6.19 | 6.58 | 6.10 | 5.77 | 5.86 |
| 6 June 2020 | 9.59 | 9.84 | 9.75 | 9.70 | 9.00 |
| 7 June 2020 | 10.66 | 9.07 | 9.60 | 8.88 | 9.21 |
| 8 June 2020 | 7.8 | 7.31 | 7.41 | 6.38 | 6.54 |
| 9 June 2020 | 5.99 | 5.80 | 5.76 | 5.24 | 5.16 |
| 10 June 2020 | 7.67 | 6.72 | 5.84 | 5.66 | 5.98 |
| 11 June 2020 | 9.26 | 9.16 | 8.84 | 8.51 | 8.32 |
| 12 June 2020 | 8.66 | 8.13 | 8.21 | 8.45 | 7.72 |
| 13 June 2020 | 5.99 | 6.49 | 6.74 | 7.18 | 7.29 |
| 14 June 2020 | 7.19 | 7.19 | 6.94 | 7.07 | 7.07 |
| 15 June 2020 | 8.06 | 7.87 | 8.21 | 8.41 | 7.84 |
| RMSE | 0.83 | 0.88 | 1.11 | 1.12 | |
| R2 | 0.89 | 0.88 | 0.81 | 0.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diez, F.J.; Boukharta, O.F.; Navas-Gracia, L.M.; Chico-Santamarta, L.; Martínez-Rodríguez, A.; Correa-Guimaraes, A. Daily Estimation of Global Solar Irradiation and Temperatures Using Artificial Neural Networks through the Virtual Weather Station Concept in Castilla and León, Spain. Sensors 2022, 22, 7772. https://doi.org/10.3390/s22207772
Diez FJ, Boukharta OF, Navas-Gracia LM, Chico-Santamarta L, Martínez-Rodríguez A, Correa-Guimaraes A. Daily Estimation of Global Solar Irradiation and Temperatures Using Artificial Neural Networks through the Virtual Weather Station Concept in Castilla and León, Spain. Sensors. 2022; 22(20):7772. https://doi.org/10.3390/s22207772
Chicago/Turabian StyleDiez, Francisco J., Ouiam F. Boukharta, Luis M. Navas-Gracia, Leticia Chico-Santamarta, Andrés Martínez-Rodríguez, and Adriana Correa-Guimaraes. 2022. "Daily Estimation of Global Solar Irradiation and Temperatures Using Artificial Neural Networks through the Virtual Weather Station Concept in Castilla and León, Spain" Sensors 22, no. 20: 7772. https://doi.org/10.3390/s22207772
APA StyleDiez, F. J., Boukharta, O. F., Navas-Gracia, L. M., Chico-Santamarta, L., Martínez-Rodríguez, A., & Correa-Guimaraes, A. (2022). Daily Estimation of Global Solar Irradiation and Temperatures Using Artificial Neural Networks through the Virtual Weather Station Concept in Castilla and León, Spain. Sensors, 22(20), 7772. https://doi.org/10.3390/s22207772