

Multi-Object Detection in Security Screening Scene Based on Convolutional Neural Network

Abstract
:1. Introduction
- (1)
- (2)
- Based on the divide-and-conquer concept, we create a multi-scale extraction module to enrich the information inside the multi-stage prediction feature layer.
- (3)
- On the feature prediction layer, a multi-scale attention mechanism is combined to get rid of redundant feature interference and pull out useful context information.
2. Materials and Methods
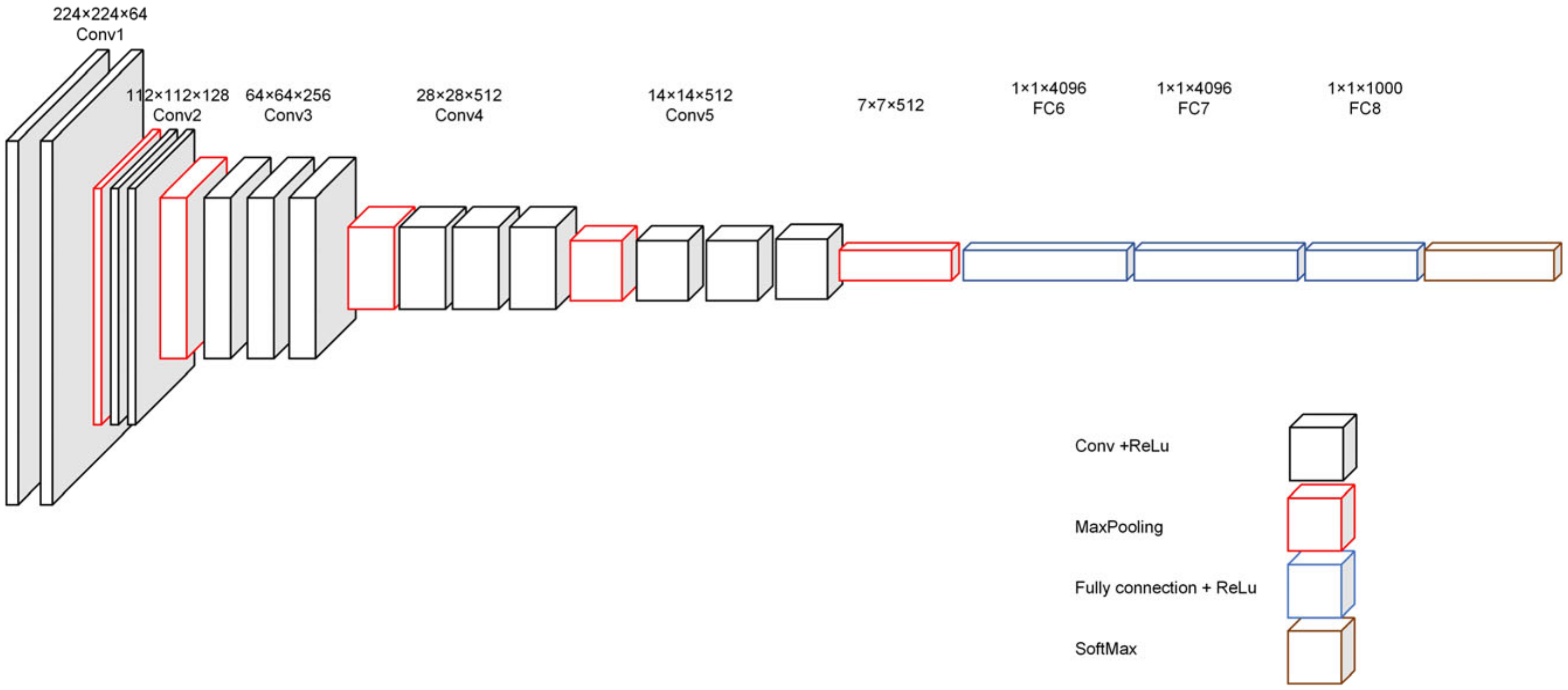
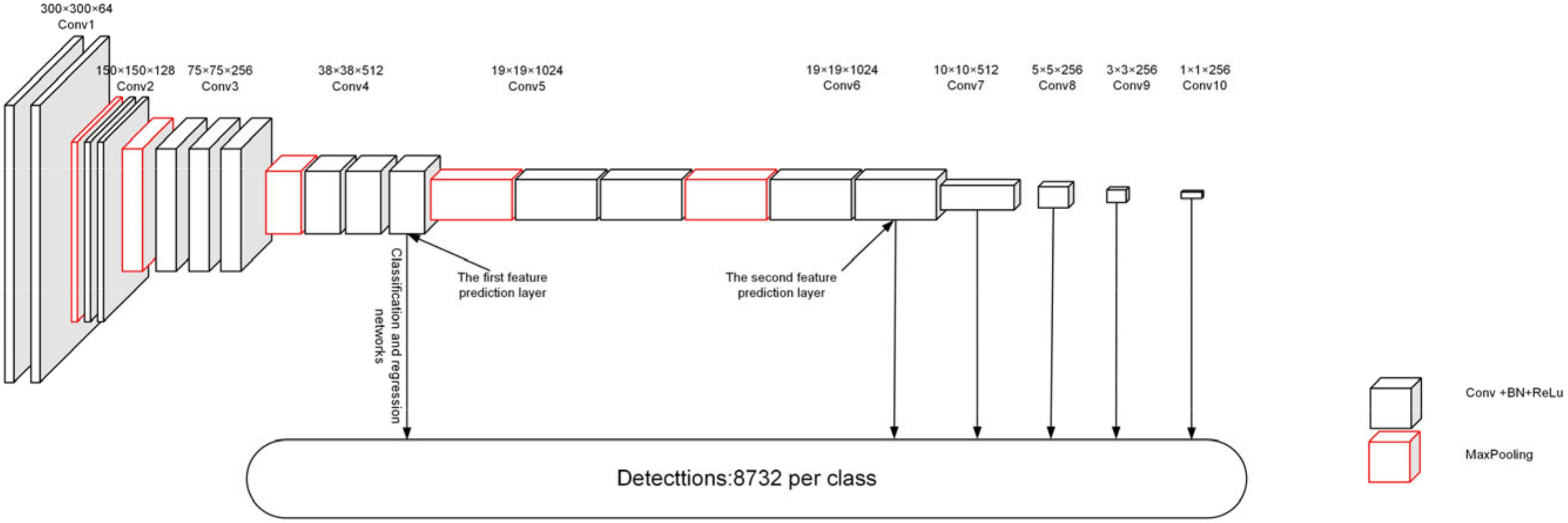
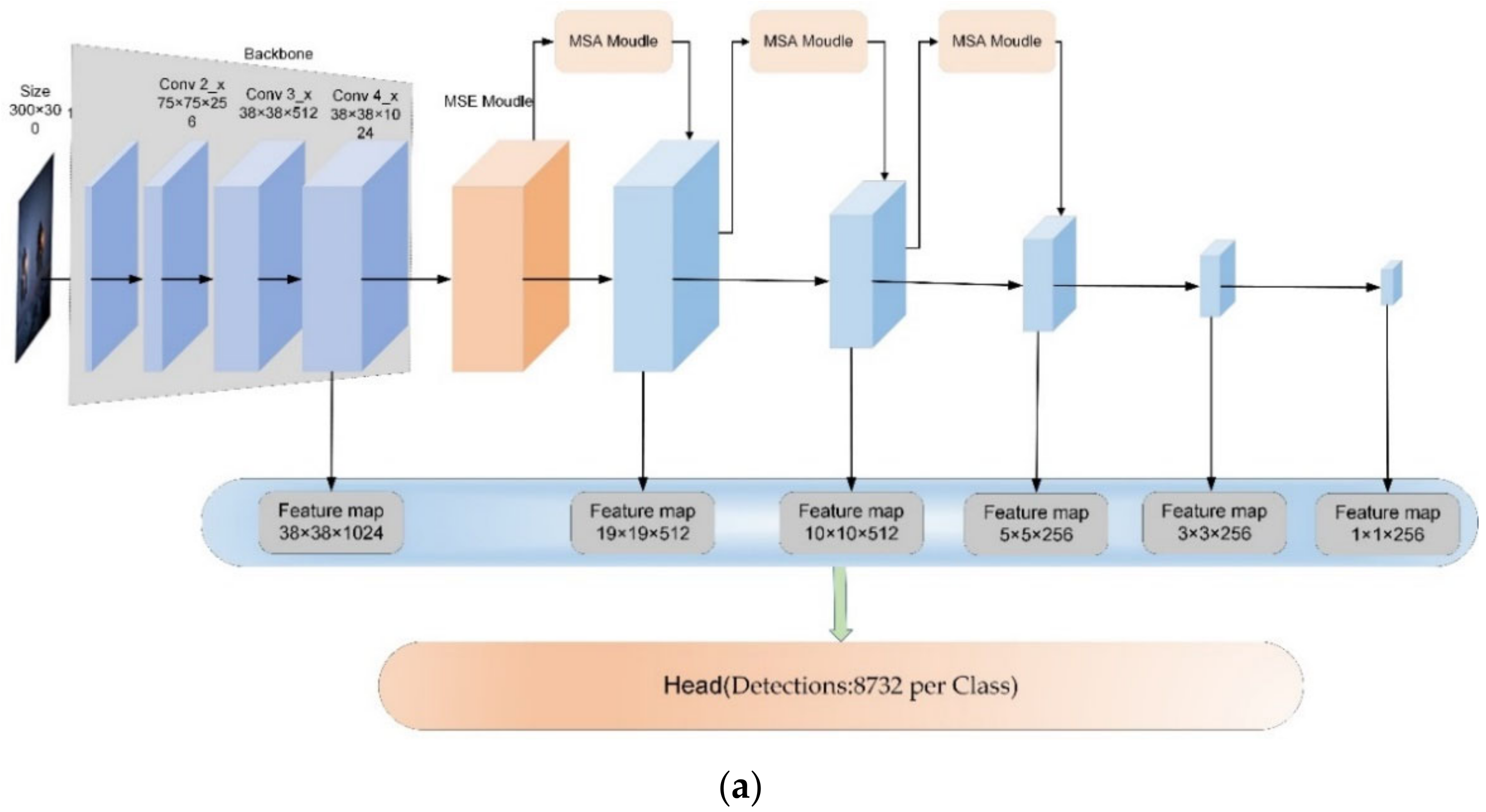
2.1. Original Network Architecture
2.1.1. Backbone Network
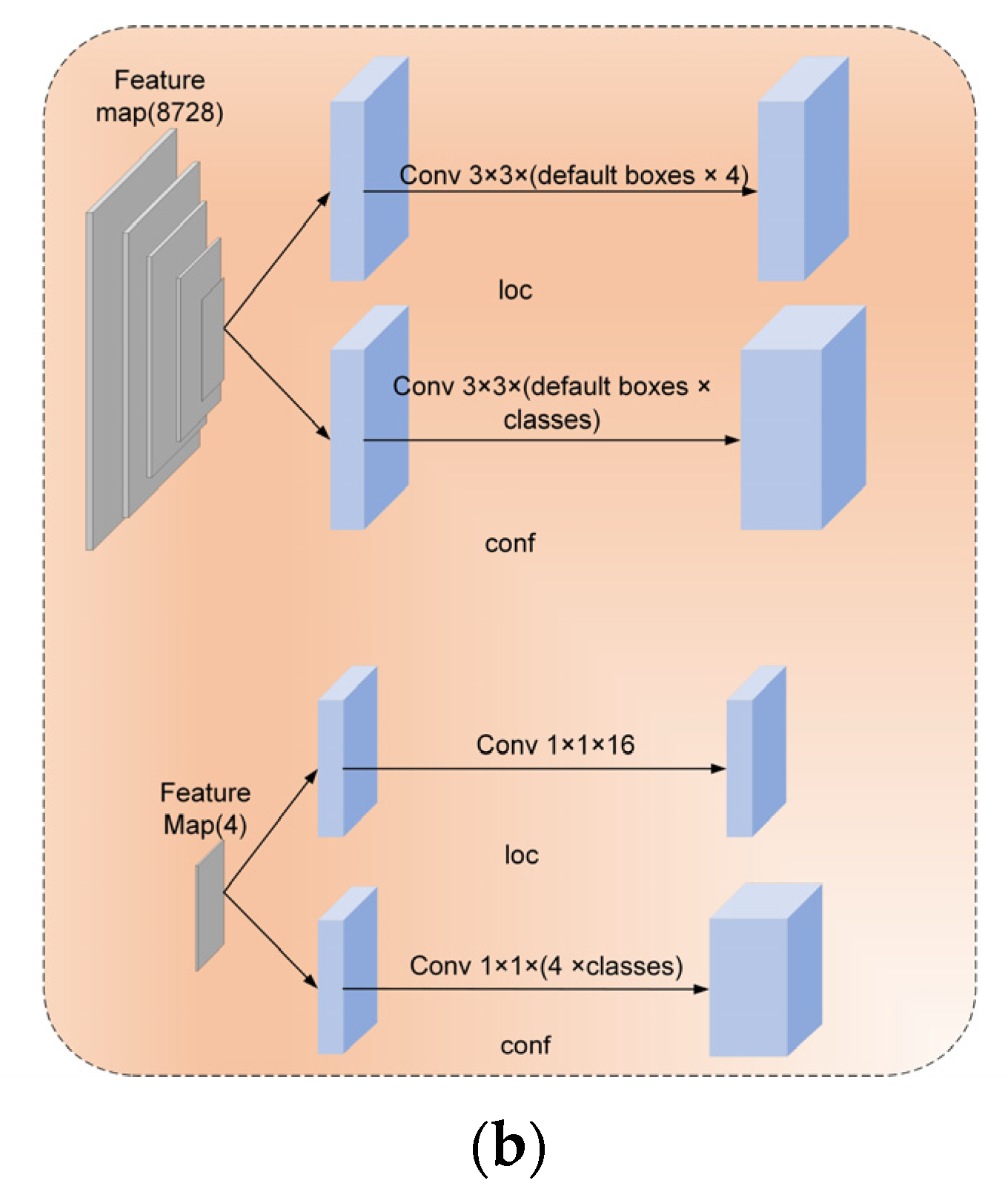
2.1.2. Predefined Anchors and Positive and Negative Sample Matching
- (1)
- Calculate the intersection over union between the ground truth boxes and the default anchor boxes. For each ground truth box, choose the intersection over union with the highest value as the positive sample.
- (2)
- Mark the remaining default anchors not marked as positive samples if their intersection over union is greater than 0.5 with any ground truth box.
| Algorithm1 Positive and negative sample matching |
| Input: g: Real sample box, mainly including the coordinate information of the upper left and lower right corners l: True sample label d: default anchor box, mainly including the upper left and lower right coordinates Iw: the width of the image, the image width and height are equal in size Output: Ol: the positive sample label matched by the default box Od: the default anchor box as the positive sample 1. Real sample frame normalization: g = g/Iw 2. Default anchor box normalization. For each feature map do: d = d/Iw 3. Calculate the intersection over union of any two anchor frames: iou = IOU (g, d) 4. Get the default box matched by the real sample box and its index (first dimension): best1_iou, index1 = max(iou(1)) 5. get the real box matched by the default anchor box and its index (second dimension): best2_iou, index2 = max(iou(2)) 6. set index1 index to the default box intersection over union to 1.0: best2_iou[index1] = 1.0 7. Modify index2 index to the real sample box index. idx = arange(0, index2.size) index2[index1[idx]] = idx 8. get the mask of the remaining default anchor boxes larger than the threshold: mask = best2_iou>0.5 9. index of all default box positive samples: index2 = index2[mask] 10. set the default anchor box label. Ol[8732] = 0 Ol[index2] = l[index2] 11. Positive sample anchors: Od = d[index2] Return Ol, Od |
2.1.3. Loss Function
3. Improved Approach
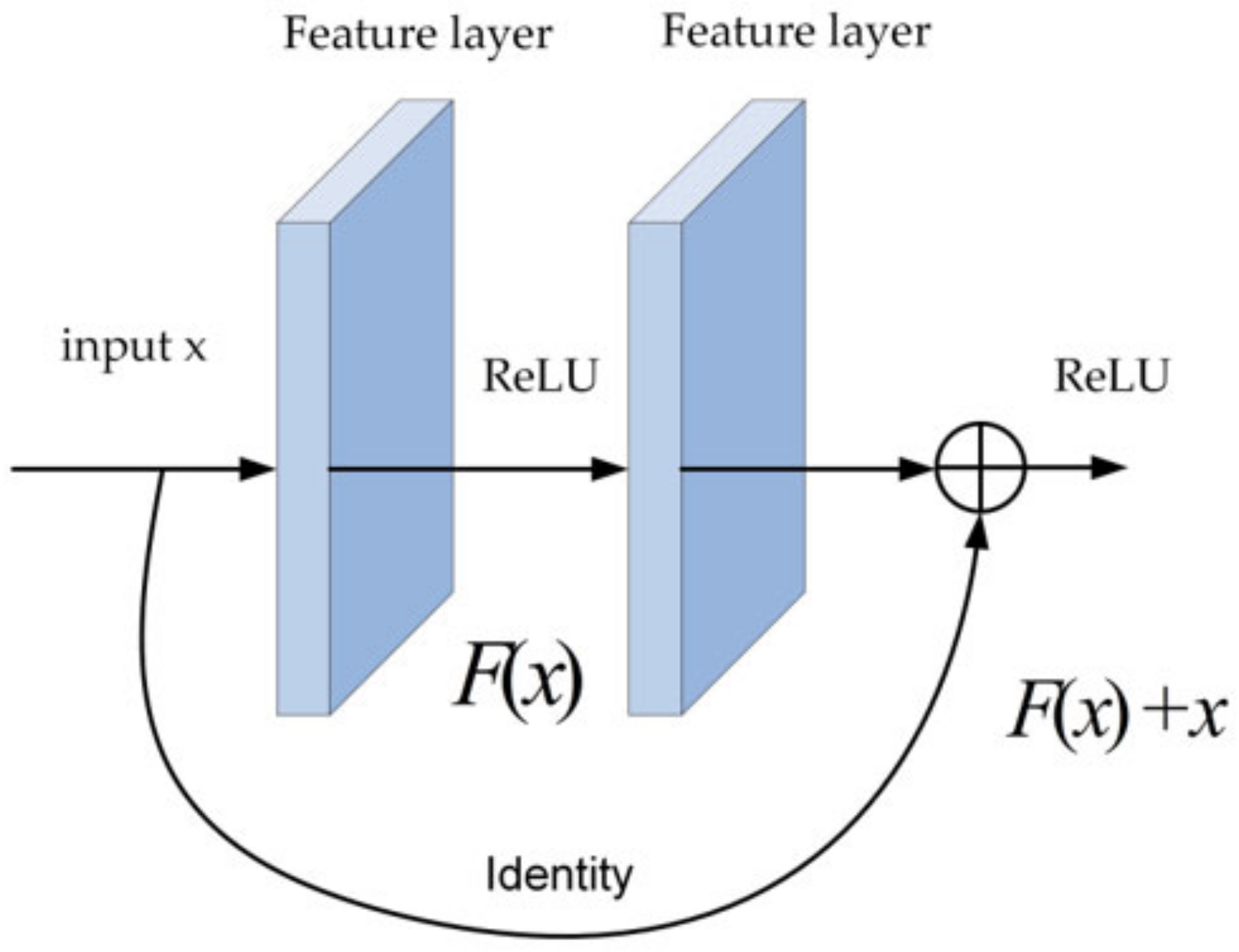
3.1. Improved Backbone
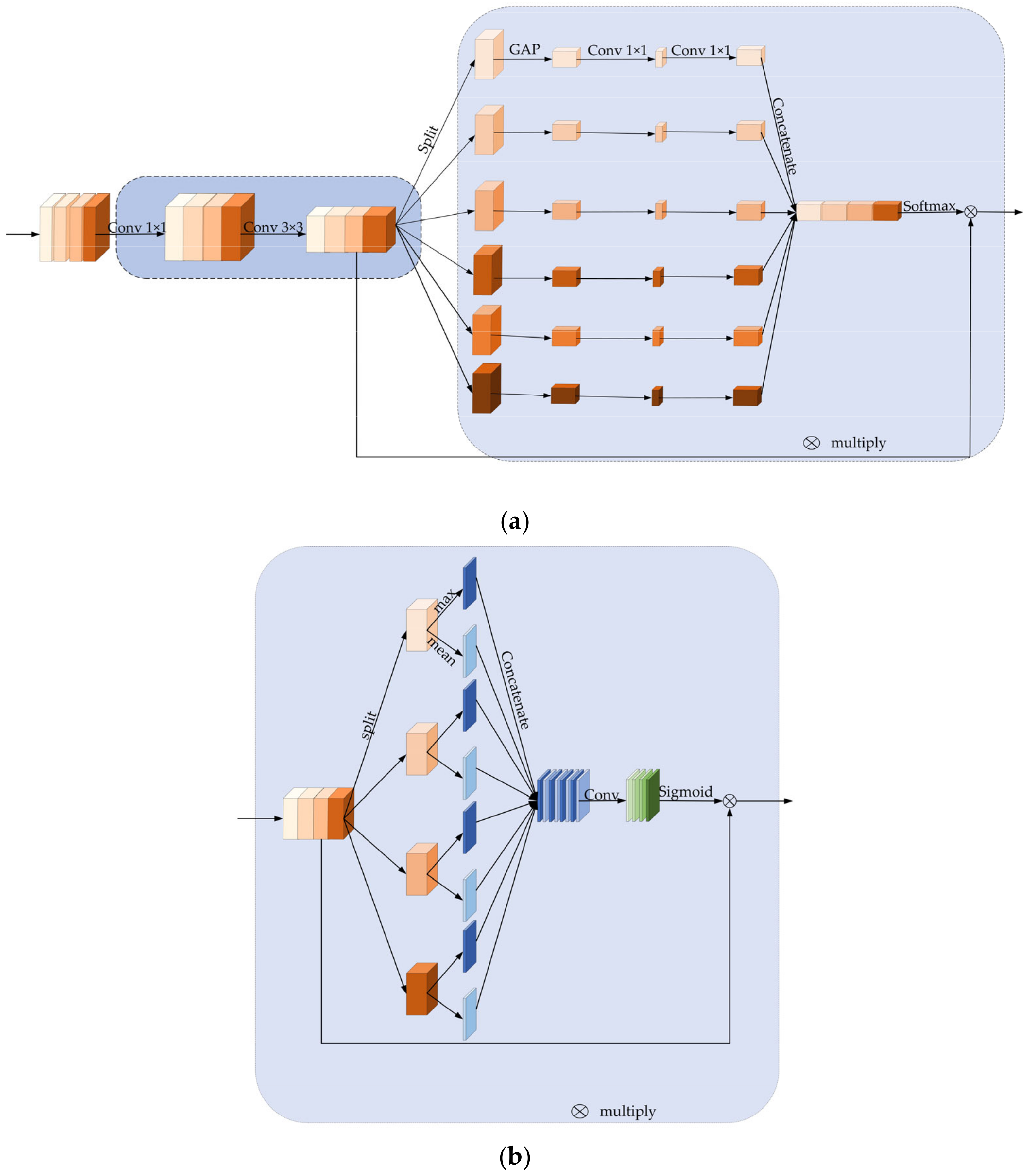
3.2. Multi-Scale Feature Extraction
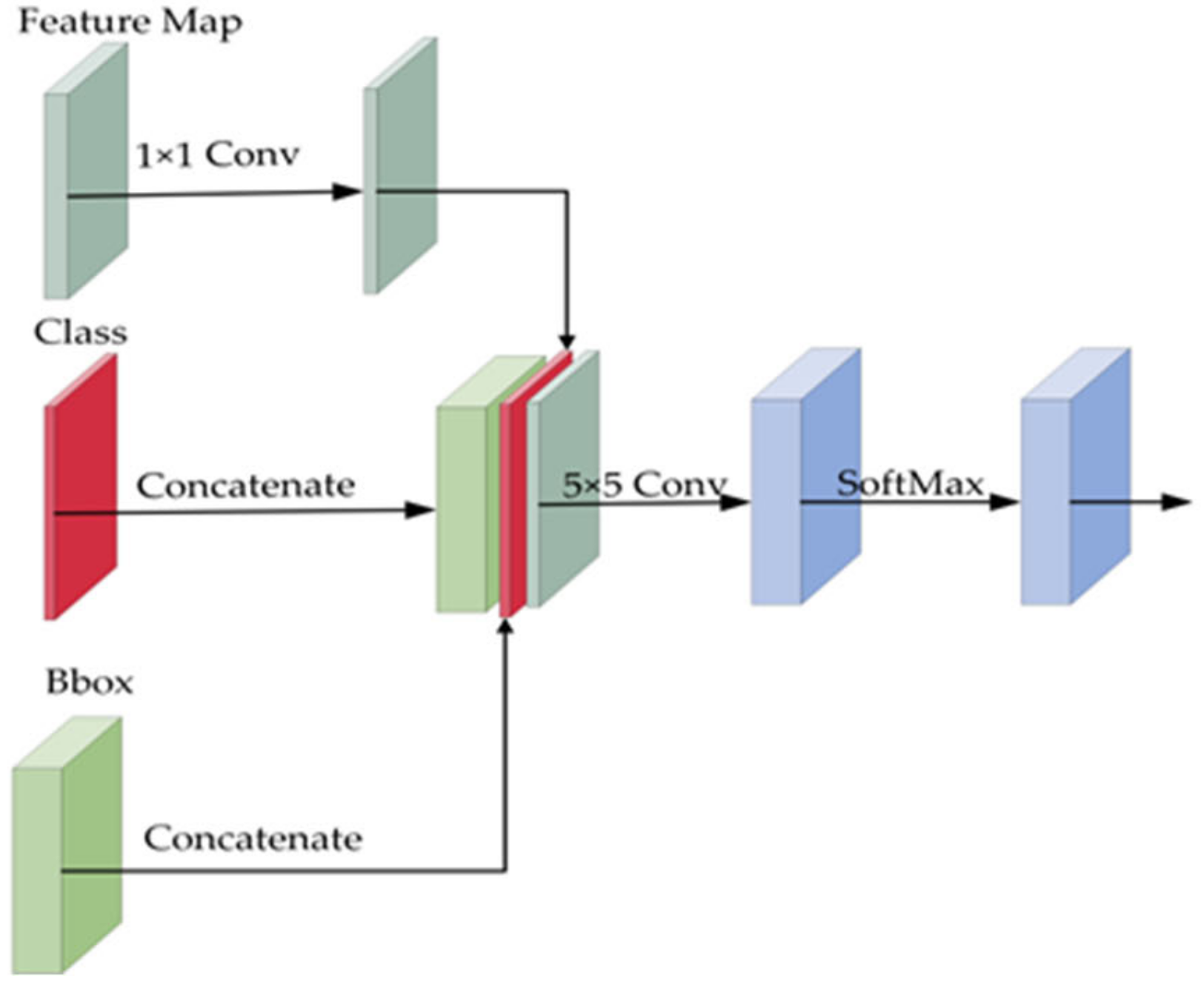
3.3. Multi-Scale Attention Mechanism
4. Experiment
4.1. Experimental Environment and Hyperparameter Setting
4.2. Introduction to the Dataset
4.3. Assessment Criteria
4.4. Analysis and Comparison of Experimental Results
5. Conclusions
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cao, Y.; Zhang, L.; Meng, J.; Song, Q.; Zhang, L. A multi-objective prohibited item identification algorithm in the X-ray security scene. Laser Optoelectron. 2021, 5, 1–14. (In Chinese) [Google Scholar]
- Alex, K.; Ilya, S.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Lin, T.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 99, 2999–3007. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Fu, M.; Deng, M.; Zhang, D. Survey on Deep Neural Network Image Target Detection Algorithms. Comput. Appl. Syst. 2022, 7, 35–45. [Google Scholar] [CrossRef]
- Qiao, J.; Zhang, L. X-Ray Object Detection Based on Pyramid Convolution and Strip Pooling. Prog. Laser Optoelectron. 2022, 4, 217–228. [Google Scholar]
- Zhang, Z.; Li, H.; Li, M. Research on YOLO Algorithm in Abnormal Security Images. Comput. Eng. Appl. 2020, 56, 187–193. [Google Scholar]
- Huang, G.; Liu, Z.; Van, D.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wu, H.; Wei, X.; Liu, M.; Wang, A.; Liu, H. Improved YOLOv4 for dangerous goods detection in X-ray inspection combined with atrous convolution and transfer learning. China Opt. 2021, 14, 1417–1425. [Google Scholar]
- Akcay, S.; Kundegorski, M.E.; Willcocks, C.G.; Breckon, T.P. Using deep convolutional neural network architectures for object classification and detection within x-ray baggage security imagery. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2203–2215. [Google Scholar] [CrossRef] [Green Version]
- Galvez, R.; Dadios, E.; Bandala, A.; Vicerra, R.R.P. Threat object classification in X-ray images using transfer learning. In Proceedings of the IEEE 10th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment and Management (HNICEM), Baguio City, Philippines, 29 November–2 December 2018; pp. 1–5. [Google Scholar]
- Gong, Y.; Luo, J.; Shao, H.; Li, Z. A transfer learning object detection model for defects detection in X-ray images of spacecraft composite structures. Compos. Struct. 2022, 284, 115136. [Google Scholar] [CrossRef]
- Hassan, T.; Bettayeb, M.; Akçay, S.; Khan, S.; Bennamoun, M.; Werghi, N. Detecting prohibited items in X-ray images: A contour proposal learning approach. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Online, 25–28 October 2020; pp. 2016–2020. [Google Scholar]
- Wei, Y.; Tao, R.; Wu, Z.; Ma, Y.; Zhang, L.; Liu, X. Occluded prohibited items detection: An x-ray security inspection benchmark and de-occlusion attention module. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 138–146. [Google Scholar]
- Tao, R.; Wei, Y.; Jiang, X.; Li, H.; Qin, H.; Wang, J.; Liu, X. Towards real-world X-ray security inspection: A high-quality benchmark and lateral inhibition module for prohibited items detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10923–10932. [Google Scholar]
- Sigman, J.B.; Spell, G.P.; Liang, K.J.; Carin, L. Background adaptive faster R-CNN for semi-supervised convolutional object detection of threats in x-ray images. In Proceedings of the Anomaly Detection and Imaging with X-Rays (ADIX), Online, 26 May 2020; Volume 11404, pp. 12–21. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You Only Look One-level Feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13039–13048. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap Between Anchor-Based and Anchor-Free Detection via Adaptive Training Sample Selection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Fleet, D.; Pajdla, T.; Schiele, B.; Tuytelaars, T. Chapter 53—Visualizing and understanding convolutional networks. In Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; Volume 8689, pp. 818–833. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Guo, J.; Ma, X.; Sansom, A.; Mcguire, M.; Fu, S. Spanet: Spatial Pyramid Attention Network for Enhanced Image Recognition. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), Online, 6–10 July 2020. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, H.; Zu, K.; Lu, J.; Zou, Y.; Meng, D. Epsanet: An efficient pyramid squeeze attention block on convolutional neural network. arXiv 2021, arXiv:2105.14447. [Google Scholar]
- Ioannou, Y.; Robertson, D.; Cipolla, R.; Criminisi, A. Deep roots: Improving cnn efficiency with hierarchical filter groups. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1231–1240. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Adaptive NMS: Refining Pedestrian Detection in a Crowd. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6452–6461. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Map Size | Anchor Boxes Size | Aspect Ratios |
|---|---|---|
| 38 × 38 | 21, 45 | 1, 2, 0.5 |
| 19 × 19 | 45, 99 | 1, 2, 0.5, 3, 1/3 |
| 10 × 10 | 99, 153 | 1, 2, 0.5, 3, 1/3 |
| 5 × 5 | 153, 207 | 1, 2, 0.5, 3, 1/3 |
| 3 × 3 | 207, 261 | 1, 2, 0.5, 3, 1/3 |
| 1 × 1 | 261, 315 | 1, 2, 0.5, 3, 1/3 |
| Layer Name | Output Size | VGG | ResNet |
|---|---|---|---|
| Conv1 | 150 × 150 | [Conv3] × 2 | [Conv7] × 1 |
| Conv2 | 75 × 75 | [Conv3] × 2 | [Conv1, Conv3, Conv1] × 3 |
| Conv3 | 38 × 38 | [Conv3] × 2 [Conv1] × 1 | [Conv1, Conv3, Conv1] × 4 |
| Conv4 | 38 × 38 | [Conv3] × 2 | [Conv1, Conv3, Conv1] × 6 |
| Additional layer1 | 19 × 19 | [Conv1, Conv3] × 1 | [Conv1, Conv3] × 1 |
| Additional layer2 | 10 × 10 | [Conv1, Conv3] × 1 | [Conv1, Conv3] × 1 |
| Additional layer3 | 5 × 5 | [Conv1, Conv3] × 1 | [Conv1, Conv3] × 1 |
| Additional layer4 | 3 × 3 | [Conv1, Conv3] × 1 | [Conv1, Conv3] × 1 |
| Additional layer5 | 1 × 1 | [Conv1, Conv3] × 1 | [Conv1, Conv3] × 1 |
| Approach | mAP0.5 | mAP0.75 | mAPs | mAPm | mAPl | Inference Speed (ms) |
|---|---|---|---|---|---|---|
| Fast-RCNN | 67.2 | 45.7 | 57.8 | 71.5 | 72.3 | 396 |
| Faster-RCNN | 69.9 | 46.3 | 58.3 | 74.9 | 76.5 | 142 |
| G-RCNN | 77.3 | 55.1 | 61.4 | 83.9 | 88.4 | 89 |
| YOLOv4 | 75.1 | 53.5 | 49.7 | 88.4 | 87.2 | 33 |
| YOLOv5 | 75.5 | 55.5 | 49.7 | 87.8 | 89.3 | 28 |
| YOLOv7 | 77.2 | 55.5 | 52.3 | 88.7 | 90.6 | 37 |
| SSD300 | 74.4 | 51.9 | 47.5 | 85.3 | 87.4 | 52 |
| DSSD321 | 75.9 | 53.3 | 55.1 | 85.1 | 87.5 | 67 |
| Improved SSD300 | 78.7 | 56.0 | 52.6 | 90.3 | 93.2 | 47 |
| Improved SSD300 (10k) | 80.6 | 56.3 | 52.6 | 94.1 | 95.1 | 47 |
| Approach | Backbone | mAP |
|---|---|---|
| SSD300 | VGG16 | 74.4 |
| SSD300 | ResNet50 | 75.2 |
| SSD + MSE | ResNet50 | 76.1 |
| SSD + MSA | ResNet50 | 77.5 |
| SSD + MSE + MSA | ResNet50 | 78.7 |
| NMS Approach | mAP0.5 | mAP0.75 | mAPs | mAPm | mAPl |
|---|---|---|---|---|---|
| greedy NMS | 80.6 | 56.3 | 52.6 | 94.1 | 95.2 |
| Adaptive-NMS | 81.1 | 55.9 | 52.6 | 95.1 | 95.6 |
| Adaptive-NMS + Soft-NMS | 81.8 | 58.0 | 52.9 | 95.8 | 96.7 |
| Baseline | Method | Dataset | mAP0.5 | FA | FP | CA | KN | CK | LA | Inference (ms) |
|---|---|---|---|---|---|---|---|---|---|---|
| Fast-RCNN | Transfer Learned | DBF6 | 85.1 | 91.6 | 90.1 | 84.4 | 67.7 | 88.9 | 87.9 | 150 |
| Fast-RCNN | MSA + MSE | DBF6 | 88.3 | 92.1 | 92.5 | 90.1 | 71.9 | 91.4 | 91.8 | 175 |
| R-FCN | Transfer Learned | DBF6 | 85.6 | 94.2 | 92.5 | 88.7 | 55.6 | 92.0 | 90.6 | 85 |
| R-FCN | MSA + MSE | DBF6 | 89.5 | 94.7 | 92.9 | 91.7 | 65.9 | 96.6 | 95.2 | 93 |
| Baseline | Method | Dataset | mAP0.5 | FO | ST | SC | UT | MU | Inference (ms) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv3 | DOAM | OPIXray | 79.3 | 90.2 | 41.7 | 97.0 | 72.1 | 95.5 | 23 |
| YOLOv3 | MSA + MSE | OPIXray | 80.2 | 91.3 | 41.7 | 97.8 | 74.3 | 95.9 | 30 |
| FCOS | DOAM | OPIXray | 82.4 | 86.7 | 68.6 | 90.2 | 78.8 | 87.7 | 26 |
| FCOS | MSA + MSE | OPIXray | 82.6 | 86.9 | 69.3 | 90.2 | 80.3 | 85.7 | 34 |
| SSD | DOAM | OPIXray | 74.1 | 81.4 | 41.5 | 95.1 | 68.2 | 84.3 | 55 |
| SSD | MSA + MSE | OPIXray | 82.9 | 92.1 | 59.7 | 97.5 | 73.3 | 91.9 | 41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, F.; Zhang, X.; Liu, Y.; Jiang, H. Multi-Object Detection in Security Screening Scene Based on Convolutional Neural Network. Sensors 2022, 22, 7836. https://doi.org/10.3390/s22207836
Sun F, Zhang X, Liu Y, Jiang H. Multi-Object Detection in Security Screening Scene Based on Convolutional Neural Network. Sensors. 2022; 22(20):7836. https://doi.org/10.3390/s22207836
Chicago/Turabian StyleSun, Fan, Xiangfeng Zhang, Yunzhong Liu, and Hong Jiang. 2022. "Multi-Object Detection in Security Screening Scene Based on Convolutional Neural Network" Sensors 22, no. 20: 7836. https://doi.org/10.3390/s22207836