1. Introduction
Surface ozone is one of six air pollutants that have a safety level set by National Ambient Air Quality Standards, since it can adversely impact human health and the environment. Short-term exposure to ozone is related to mortality in urban countries [
1]; for example, a 0.45% increase in mortality was attributed to a 10 ppb increase in ozone [
2]. To protect human beings from these harmful effects, the U.S. Environmental Protection Agency (EPA) set a target value of maximum ozone concentrations to an eight-hour average concentration of 70 ppb and 120 ppb within a day and a calendar year, respectively. U.S. environmental policies for ozone reduction are made and implemented based on these values. While these policies can help reduce overall surface ozone pollution, daily ozone levels are not always lower than the suggested values. As a complementary measure, future ozone information could be provided to the public to help with individual decision making and provide warnings to avoid events of high ozone concentrations. Hence, ozone forecasting is a critical task with high potential impact.
Ozone forecasts can be conducted using numerical methods and/or data-driven approaches. Numerical methods provide predictions of ozone concentrations by simulating emissions, chemistry, physics of the atmosphere, and chemical transformation and transportation processes. For numerical methods, there are two well-known forecasting models: the Community Multiscale Air Quality (CMAQ) model developed by the U.S. EPA [
3] and the Weather Research and Forecasting/Chemistry (WRF-chem) model [
4]. Both of these methods need substantial computational time and have limited accuracy due to use of simplified assumptions in the fields of physics and chemistry. In addition, ozone concentrations at local spots may be different from ozone forecasts by numerical methods because of limited spatial resolution.
Data-driven approaches forecast ozone concentrations based on data obtained from measurement stations. Compared to numerical methods, these approaches can predict ozone concentrations with less computational burden as well as at microscopic scales. Data-driven approaches can be categorized into statistical and machine learning methods. Statistical methods utilize statistics to predict ozone concentrations. Some examples of statistical methods are autoregressive integrated moving average and multiple linear regression. Su et al. [
5] evaluated several statistical methods for hourly ozone concentration prediction, including kernel extreme learning machine (KELM), support vector machine regression, back propagation neural network, and stepwise regression. As machine learning techniques have advanced, many studies have applied machine-learning algorithms, e.g., convolutional neural network (CNN) and long short-term memory (LSTM) networks to predict ozone concentrations [
6,
7,
8]. Freeman et al. [
9] presented a recurrent neural network with LSTM to forecast averages of 8-hour surface ozone concentrations. Jia et al. [
10] employed a sequence-to-sequence deep learning model, which has a gated recurrent unit (GRU)-based encoding forecasting structure, to forecast up to the next 6 h of ozone concentrations over the Yangtze River Delta region of eastern China. Eslami et al. [
6] used a deep convolutional neural network (CNN) to forecast hourly ozone concentrations for a lead time of 24 h based on chemical and meteorological measurement data obtained from Seoul, South Korea. An identified limitation of deep CNN models is that the models do not provide good performance during cold months or under the ambient environment with high ozone concentrations [
7]. Ma et al. [
11] proposed a stacked bidirectional LSTM with a transfer learning to predict three air pollutants, such as ozone, nitro-dioxide, and particulate matter with a diameter of less than 2.5 microns. Kleinert et al. [
8] applied multiple CNN layers to forecast the daily maximum 8-h average ozone concentrations for up to 4 days.
The selection of input features used in data-driven approaches is one of the most important tasks for improving forecast accuracy. Many studies have selected input features according to revealed mechanisms of ozone formation as well as atmosphere physics. Near-surface ozone is generated from the oxidation of volatile organic compounds (VOCs) and nitrogen oxides (NO
) under sunlight [
12]. Many studies have considered chemical (O
, NO, and NO
) and meteorological measurement data (temperature, relative humidity, wind direction, and wind speed) as input features.
The planetary boundary layer (PBL), which determines vertical transports of heat, water vapor, and aerosols between the underlying surface and atmosphere, has been shown to impact air pollutants [
13,
14], including ozone. Some studies have recently shown that the fate of air pollutants is impacted by the PBL [
14,
15]. The mixing of the PBL can result in diurnal cycles in air pollutant concentrations [
16], and it was shown that stable weather conditions can promote elevations in ozone concentrations. Another study showed that the ozone in the residual layer is downward transported to the PBL as PBL height increases [
17]. The difference in PBL height on days between high ozone and low ozone concentrations is not significant, but the PBL growth rate is related to ozone concentrations [
18]. Like these studies, PBL height could be an important factor in ozone concentration predictions in addition to meteorological parameters. Many studies on ozone forecasting have applied machine learning and deep learning algorithms to forecast ozone concentrations, but the use of the forecasted values of PBL height as an input feature in these algorithms has not been considered.
In this paper, we investigate the effectiveness of integrating PBL height into data-driven ozone forecasting models on forecast accuracy. Since PBL height, as well as meteorological parameters, have a nonlinear relationship with ozone concentrations, we employ machine learning algorithms that are capable of modeling nonlinearity between input and output, i.e., multilayer perception (MLP) and bidirectional long short-term memory (LSTM). We present two ozone forecasting models based on two machine learning algorithms where ozone, temperature, and relative humidity data, as well as the PBL height data, are used as input features. We consider the predicted PBL height for two forecasting models, instead of their real measurements, since it is difficult to gather actual PBL data. Two types of inputs, such as the measurement and predicted data, have a sequential relation in time and a different number of features, i.e., the number of features for measurement data and PBL height are 3 and 1, respectively. We apply different techniques for integrating two different types of inputs in two ozone forecasting models. In the case of bidirectional LSTMs, we present two separate bidirectional LSTMs where each LSTM is connected sequentially and each one is individually connected to each of two inputs. We evaluate the performance of the two ozone forecasting models and verify the effectiveness of using PBL height in the forecasting models.
The rest of the paper is organized as follows: we describe the background of MLP and bidirectional LSTM models in
Section 2. In
Section 3, the MLP and bidirectional LSTM models for ozone prediction are described. In
Section 4, we evaluate the performance of the models by comparing with conventional models. Finally, we draw conclusions in
Section 5.
3. Ozone Forecasting Models
Conventional data-driven ozone prediction models have used historical ozone data and other historical parameters, such as temperature, pressure, relative humidity, wind speed, wind direction, and NOx as input features. These models have extracted relationships between past measurement data and future ozone concentrations so that forecasting ozone concentrations can be fulfilled based on its measurement data.
In the area of air quality research, attention has recently been paid to the planetary boundary layer (PBL) as a meteorological parameter that determines the vertical transport of heat, water vapor, and aerosols between the underlying surface and atmosphere. The PBL characteristics have an impact on the fate of air pollutants [
14,
15]. For example, diurnal cycles of ozone concentration can result from the mixing of the PBL [
16], and stable weather conditions can be favorable for elevating ozone concentrations. As PBL height increases, the ozone in the residual layer is downward transported to the PBL [
17]. The difference in PBL height on days between high ozone and low ozone concentrations is not significant, but the PBL growth rate is related to ozone concentrations [
18]. PBL height can be an important factor in ozone concentration predictions in addition to meteorological parameters, such as temperature, relative humidity, wind speed, and wind direction. Thus, we consider PBL height in ozone forecasting models as a new input feature.
In the following sections, we present two different types of ozone forecasting models, each of which is based on MLP and bidirectional LSTM models, respectively. We use forecast data for PBL heights as a new input feature to two ozone forecasting models because it is difficult to gather actual measured PBL heights. The predicted PBL height data have different dimensions of time from the measurement data used for other input features, so they cannot be directly applied. We present different techniques for using two different types of inputs in two ozone forecasting models.
3.1. Mlp-Based Forecasting Model
We forecast ozone concentrations for hours ahead using the past data of ozone, temperature, and relative humidity with hours, as well as the predicted PBL heights for future hours. The predicted PBL heights can be obtained from WRF models. To use two different inputs in an MLP-based ozone prediction model, we need a structure, since the past measurement data and the predicted PBL heights have different dimensions, i.e., the past measurement input and the predicted PBL heights have and dimensions, respectively. These inputs cannot be directly concatenated to apply to MLP models. Therefore, we make the past measurement and predicted PBL height data flattened and concatenated, and then these combined data are used as an input to MLP models. For hidden layers, we consider one or two layers. An output layer generates -hour ozone forecasts. In this study, we set all activation functions of layers to hyper-tangents.
Ozone, temperature, and relative humidity, which are used as past measurement inputs in our ozone prediction models, can be measured at sensor stations, but the predicted PBL heights cannot be obtained from the stations. Alternatively, the forecasted value of the PBL heights is available with the help of many WRF models, which generate short-term and medium-term forecasts in different intervals. We focus on the WRF model that can generate forecasted values of the PBL heights every hour for more than the next 24 h, which will allow us to use the PBL height data in our proposed ozone prediction models. For example, the North America Mesoscale (NAM) model in the United States forecasts regional weather parameters, including PBL heights, every hour up to 36 h. The forecasts are issued every 6 h. We note that our ozone prediction models have a limit on prediction time horizon due to the data availability of predicted PBL heights.
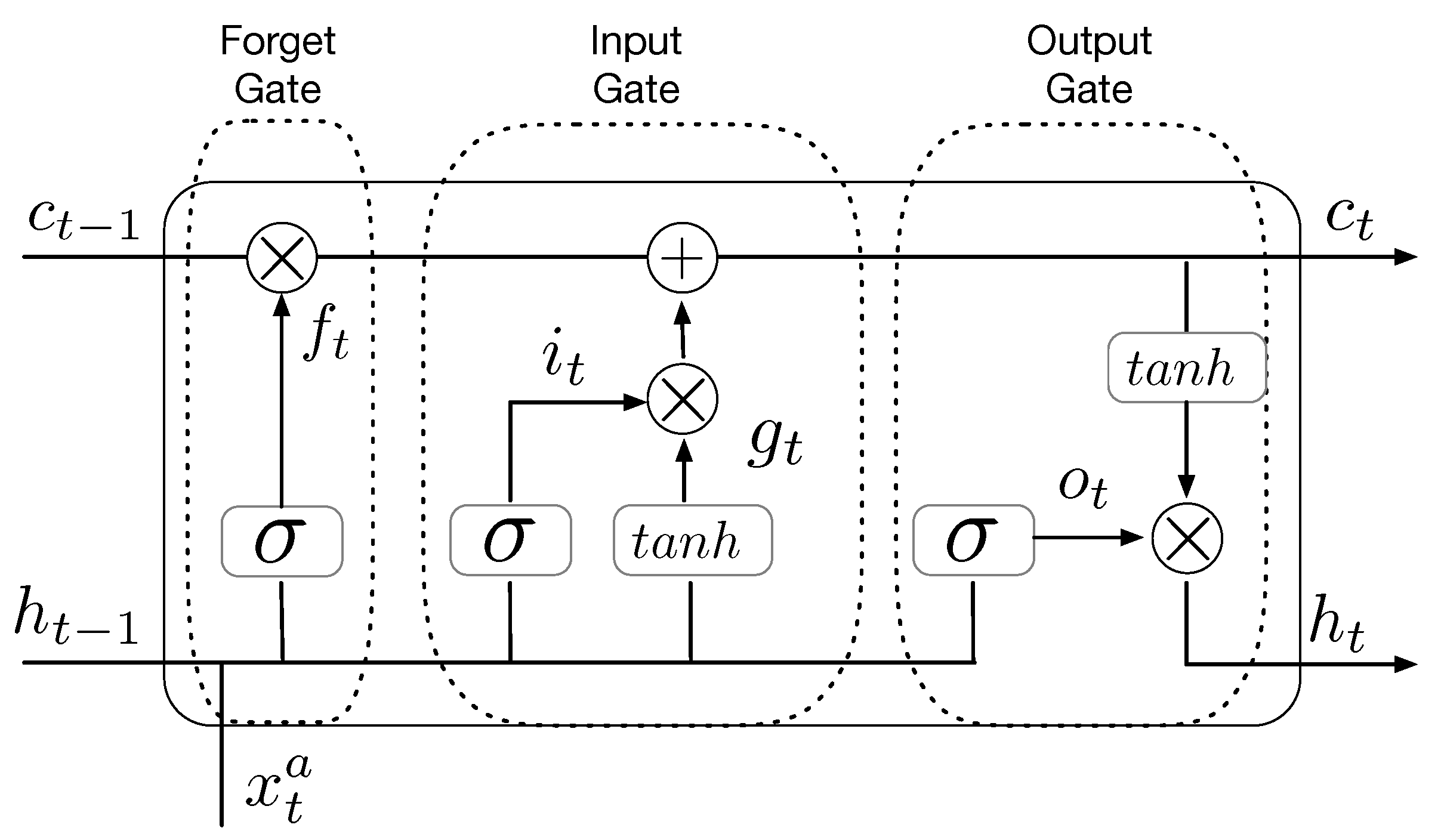
3.2. Bidirectional LSTM-Based Forecasting Model
Similar to the MLP-based ozone forecasting model, two different types of inputs are employed in our bidirectional LSTM-based ozone prediction model. One type is the measurement data of ozone, temperature, and relative humidity. The other one is the predicted PBL heights obtained from the WRF model. The two inputs have a sequential relation in time, but have different time dimensions, i.e., for the measurement data and for the predicted PBL height data. Concatenating two inputs over time cannot be applied to a single bidirectional LSTM network due to different dimensions because input to a single bidirectional LSTM network must have the same dimension over time. Thus, we need a sequential bidirectional LSTM model where two bidirectional LSTM models are connected to each other.
Figure 3 shows the bidirectional LSTM-based ozone prediction model. This model has a sequential structure in LSTM networks in forward and backward directions. LSTM networks in forward and backward directions are placed on the lower and upper layers in
Figure 3. In the proposed model, the left LSTM networks at the lower and upper layers use the measurement data, such as ozone, temperature, and relative humidity as inputs. The right ones use the predicted PBL heights as an input. The left LSTM networks learn an appropriate latent representation from the observed ozone, temperature, and relative humidity. The latent representation and PBL heights are used to reconstruct ozone concentrations through the right LSTM networks. The right LSTM networks on both of the layers generate outputs with the recurrent sequence set to be true. The two outputs provided from the two right-side LSTM networks are concatenated in a time-distributed manner, and then the
concatenated outputs are connected to
dense layers at the output layer. Each of the
dense layers generates predicted ozone concentrations at the corresponding time for the next
hours. We note that when we concatenate two LSTM networks, we set the dimensions of outputs in two LSTMs to being equal so that the memory cell state in the left LSTM can be transferred to the right one.
The four LSTM networks have the same activation function of hyper-tangent and the same recurrent activation function of the sigmoid in this paper. The output layer has an activation function of hyper-tangents.
4. Experiments
In this section, we compare the performance of the MLP-based and bidirectional LSTM-based ozone forecasting models and evaluate the effectiveness of the use of the predicted PBL heights on accuracy improvement. To this end, ozone data collected in California, USA are used in this paper.
4.1. Data Sets
4.1.1. Numerical Weather Data
Our ozone forecasting models need the predicted -hour PBL height data. The predicted PBL height data can be provided by WRF models. In this paper, we select the North American Mesoscale (NAM) model, which is one of the regional weather forecast models run by the National Centers for Environmental Prediction (NCEP), as a WRF model. The NAM model forecasts several weather parameters, such as temperature, relative humidity, wind direction, wind speed, and PBL heights over the North American continent four times daily at times 00z, 06z, 12z, and 18z over grid points with a 12 km horizontal resolution. The weather forecasts are generated with a one-hour interval up to the next 36 h and a three-hour interval until the next 84 h.
The NAM data set can be downloaded from the Archive Information Request (AIR) systems of the National Centers for Environmental Information. It is written in a grib2 format, which is a file format for gridded meteorological data. We collect NAM data from 1 January 2017 to 31 December 2019. We extract PBL height forecasts at specific grid points from the collected NAM data set to make training and test sets for our proposed ozone forecasting models. The grid points used to forecast PBL heights are related to the locations of ozone monitoring stations.
4.1.2. Measured Ozone, Temperature, and Relative Humidity Data
In the United States, the EPA operates air quality monitoring stations that measure six criteria pollutants, including ozone. We can download historical ozone data collected by these stations, including hourly ozone concentrations, using the EPA API. Meteorological parameters, such as temperature and relative humidity, are also measured by the stations and can be downloaded using the EAP API.
We collect the historical ozone, temperature, and relative humidity data from 1 January 2017 to 31 December 2019.
Table 1 lists the GPS information and location names of the EPA monitoring stations considered in this paper, and
Figure 4 shows the location of the considered air quality monitoring stations. Since our ozone forecasting models use predicted rather than actual PBL heights, we need to determine the appropriate grid points used to obtain the predicted PBL heights. We select one of the grid points close to each corresponding EPA monitoring station.
Table 2 shows the latitude and longitude of the selected grid point corresponding to each air quality monitoring station, as well as the distance in km to its corresponding air quality monitoring station.
4.2. Data Preprocessing
We perform max-min normalization to ozone, temperature, relative humidity, and PBL height to normalize their values having different scales. The normalized values are re-scaled in values from −1 to 1.
The data set measured at the monitoring stations and provided from the NAM model has missing values. For measurement data at air quality monitoring stations, linear imputation is applied to missing values when they are not continuous. In the case of the NAM data set, some data during 2017 to 2019 is missing, but no imputation is applied.
Each sample is considered for making the training and test sets for our proposed ozone forecasting models, whenever both data from the monitoring stations and the NAM model have no missing values for and hours, respectively. In other words, we remove samples, including missing values on the monitoring stations or NAM data. For the training set, each sample is generated by a 1-h sliding move during 2017. On the other hand, a 24-h sliding move is applied to evaluate the daily average performance on the test set from 2018 to 2019.
4.3. Evaluation Metrics
We employ mean absolute error (MAE), root mean square error (RMSE), and index of agreement (IOA) to evaluate the proposed ozone prediction models and verify the effectiveness of using PBL heights as an input on the ozone prediction performance. MAE and RMSE represent the amount of error between observed and predicted values, which are the most widely used performance metrics in many research areas, including ozone forecasting. The IOA, which was proposed by Willmott [
29], has been used to evaluate how well a predicted sequence fits to an observed sequence, and its value varies between 0 and 1. When two sequences are perfectly matched, IOA is equal to 1. IOA of 0 means that two sequences have no agreement with each other. The MAE, RMSE, and IOA are mathematically expressed as follows:
where
and
represent the observed and the forecasted values at
i-th time, respectively, and
denotes the mean value of
.
4.4. Simulation Results
We evaluate the impact of utilization of the forecasted PBL heights on ozone forecasting performance. We compare performances of MLP-based and bidirectional LSTM-based forecasting models in terms of IOA, MAE, and RMSE with the following two cases: (1) using only the historical meteorological measurement data and (2) both the historical meteorological measurement data and the forecasted PBL heights.
For MLP-based ozone forecast models, we consider a single and two hidden layers regardless of use of the predicted PBL heights. We set the activation function at all layers, such as input, hidden, and output layers, to a sigmoid function. There are several hyperparameters in MLP models, i.e., the number of nodes in input and hidden layers, to be determined. We perform a grid search to obtain the best forecasting performance. For the number of nodes in the input layer and hidden layers, search ranges are set to and , respectively. We considered a range of the number of nodes in the input layer as initially, but we reduced the search range since higher values showed worse performance. We also consider several epochs of .
For bidirectional LSTM-based models, we need to set up the dimension of outputs at all LSTM blocks. We note that all LSTM networks are set to have the same dimension. To obtain the best performance of ozone forecasts, a grid search is also applied for a set of and several epochs of .
Table 3 shows the best performance of the MLP- and LSTM-based surface ozone forecasting models with and without predicted PBL heights in terms of IOA, MAE, and RMSE. It is shown that MAE and RMSE for all stations decrease as the number of hidden layers in MLP models increases. Decreases in MAE for all stations are from 0.12% to 1.35%. Considering that it requires a lot of computation in hyperparameter optimization, increasing the number of hidden layers seems to be not necessarily a good thing.
Utilization of the forecasted PBL heights at the forecast horizon improves MAE and RMSE for both the MLP-based and bidirectional LSTM-based models. In the case of station 6-065-8001, the MAE of the MLP with a single hidden layer using the predicted PBL heights results in a smaller value compared to models not using the forecasted PBL heights, i.e., there is a decrease in MAE from 7.3918 ppb to 6.6540 ppb. Among all models, the range of decreases in MAE is from 1.63% (MLP with L = 1 at 6-085-0005) to 10.13% (MLP with L = 1 at 6-077-1002). For the RMSE metric, MLP with two hidden layers using the forecasted PBL heights yields 6.8828 ppb at station 6-19-4001, which is much smaller than that seen in models not using the predicted PBL heights, i.e., a decrease of 5.48%. The enhancement rates in terms of RMSE over all MLP-based models are from 1.70% (MLP with L = 1 at 6-085-0005) to 8.43% (MLP with L = 2 at 6-077-1002) by considering the forecasted PBL heights additionally. However, we observe that IOA has no significant change regardless of use of the forecasted PBL heights.
5. Conclusions
In this paper, we investigated the effectiveness of using forecasted planetary boundary layer (PBL) information obtained from WRF model outputs on the performance of our proposed measurement data-driven surface ozone prediction models. We used the meteorological data collected from air monitoring stations operated by the U.S. Environmental Protection Agent (EPA) as measurement data. We considered the North America Mesoscale (NAM) model, which is one of the regional weather forecast models run by the National Centers for Environmental Prediction (NCEP), to gather the predicted PBL data. We note that the NAM model forecasts hourly PBL heights up to 36 h every 6 h. We considered two machine learning algorithms for surface ozone forecasting models, the multilayer perceptron (MLP) and the bidirectional long short-term memory (LSTM) models. To apply the measurement data, as well as the predicted PBL height data, as inputs to these two forecasting models, we needed the following consideration: For the bidirectional LSTM-based model, a sequence-to-sequence structure was proposed because the measurement data and predicted PBL height data are in sequential relation, but they have a different number of features. That is, the measurement data considers three features, such as ozone, temperature, and relative humidity, while the predicted PBL height data have only one single feature with itself. To verify the effectiveness of using predicted PBL heights, we compared the performances of the MLP-based and bidirectional LSTM-based models where the historical measurement data and the forecasted PBL heights together were considered and compared with the models where only past measurement data were used, in terms of IOA, MAE, and RMSE. We showed that the MLP-based and bidirectional LSTM-based models that used the additional predicted PBL heights as an input yielded a performance enhancement, i.e., lower MAE and RMSE, compared to the models without the forecasted PBL heights. However, neither model showed a significant difference in IOA. Therefore, utilization of predicted PBL heights can improve the forecasting accuracy for surface ozone concentrations. In future work, we will study the effect of wind speed and NOx as well as predicted PBL heights on ozone forecasting, since wind speed and NOx are considered important features for ozone forecasting.









{kind=link}
{kind=link}
{kind=link}
{kind=link}