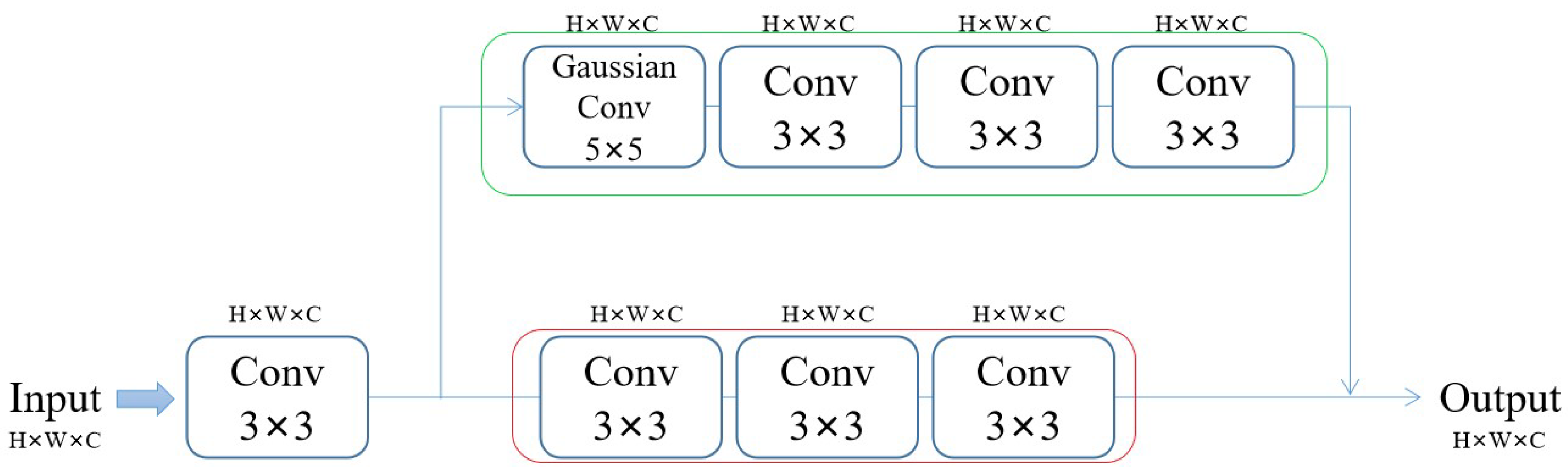
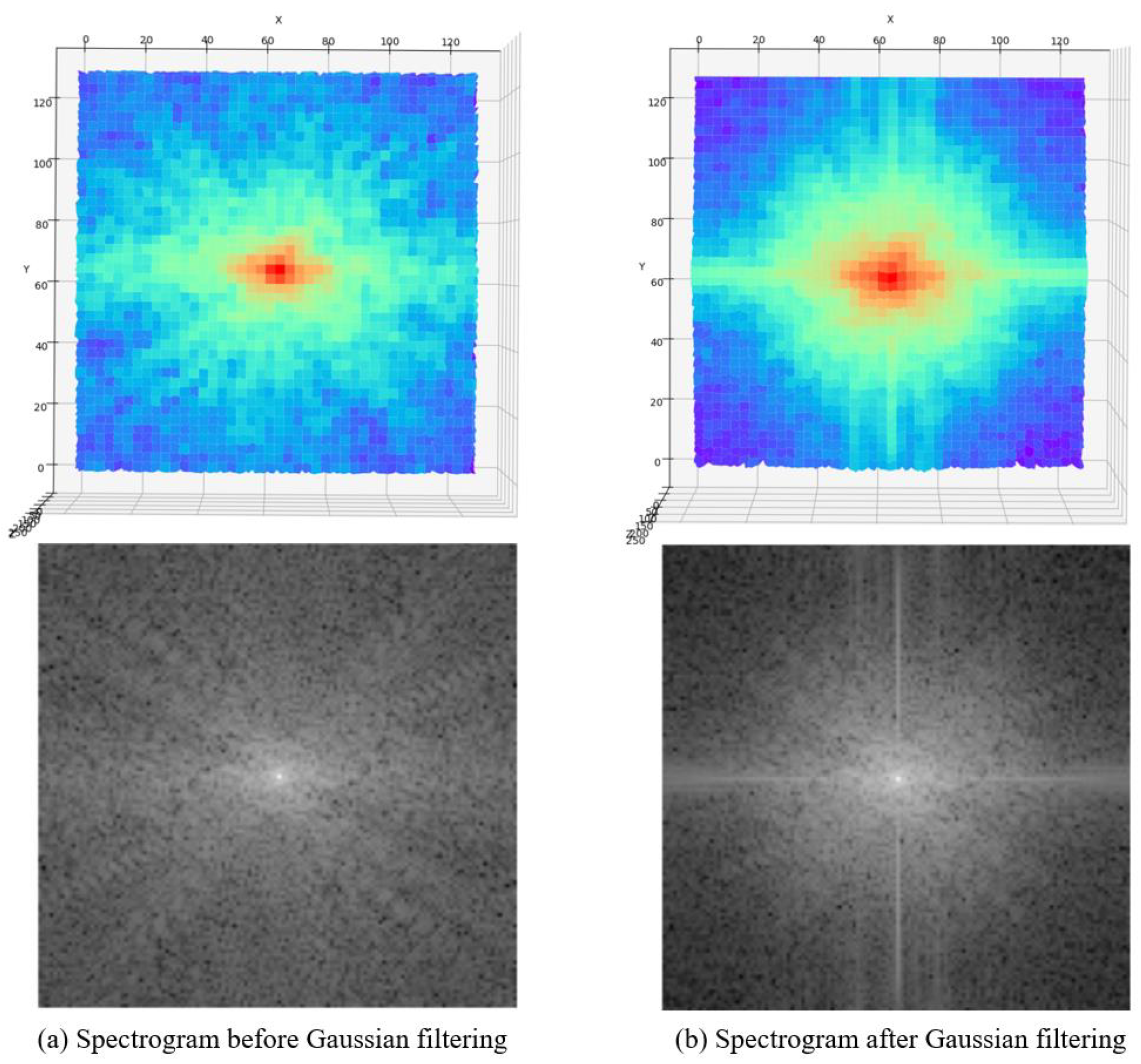
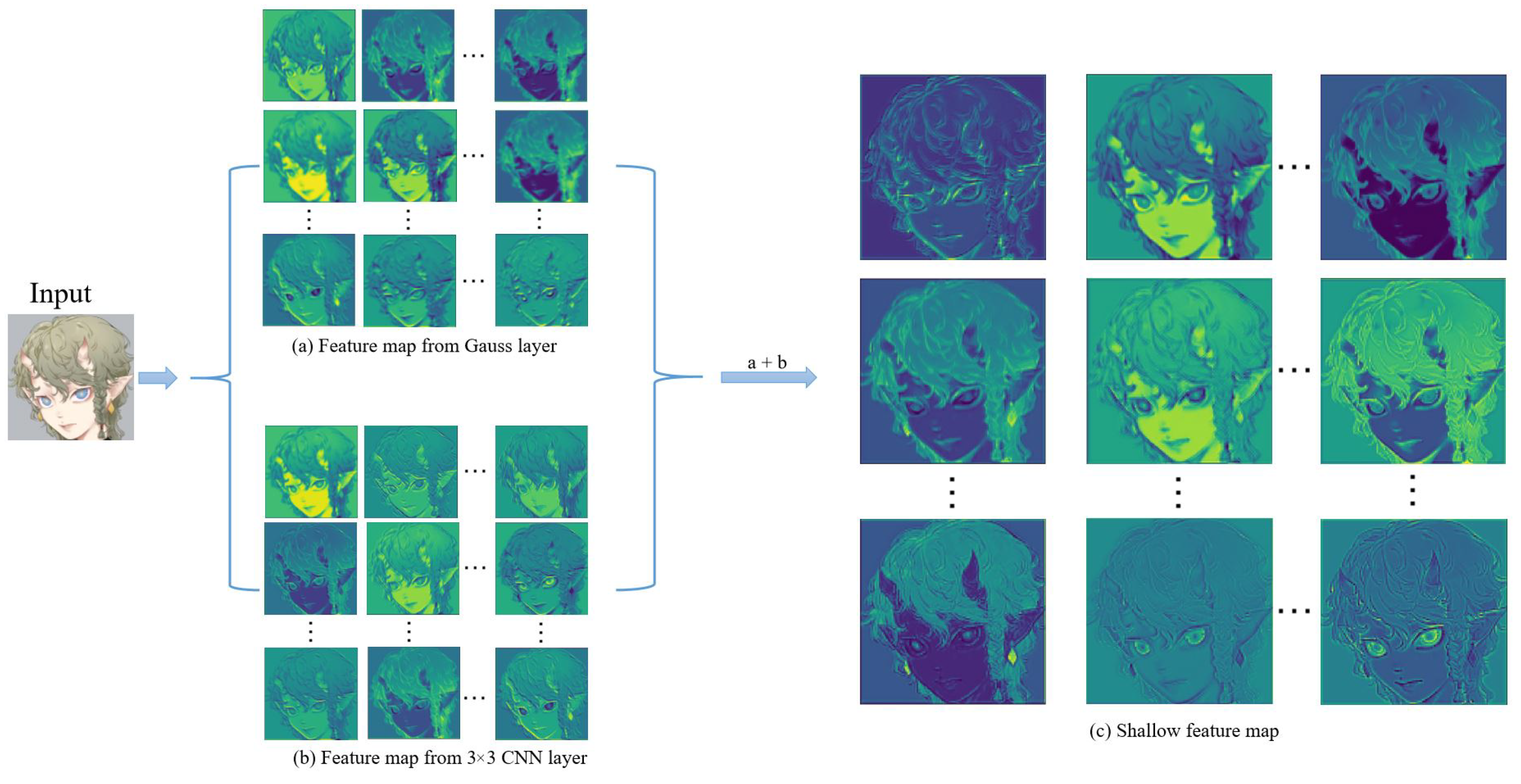
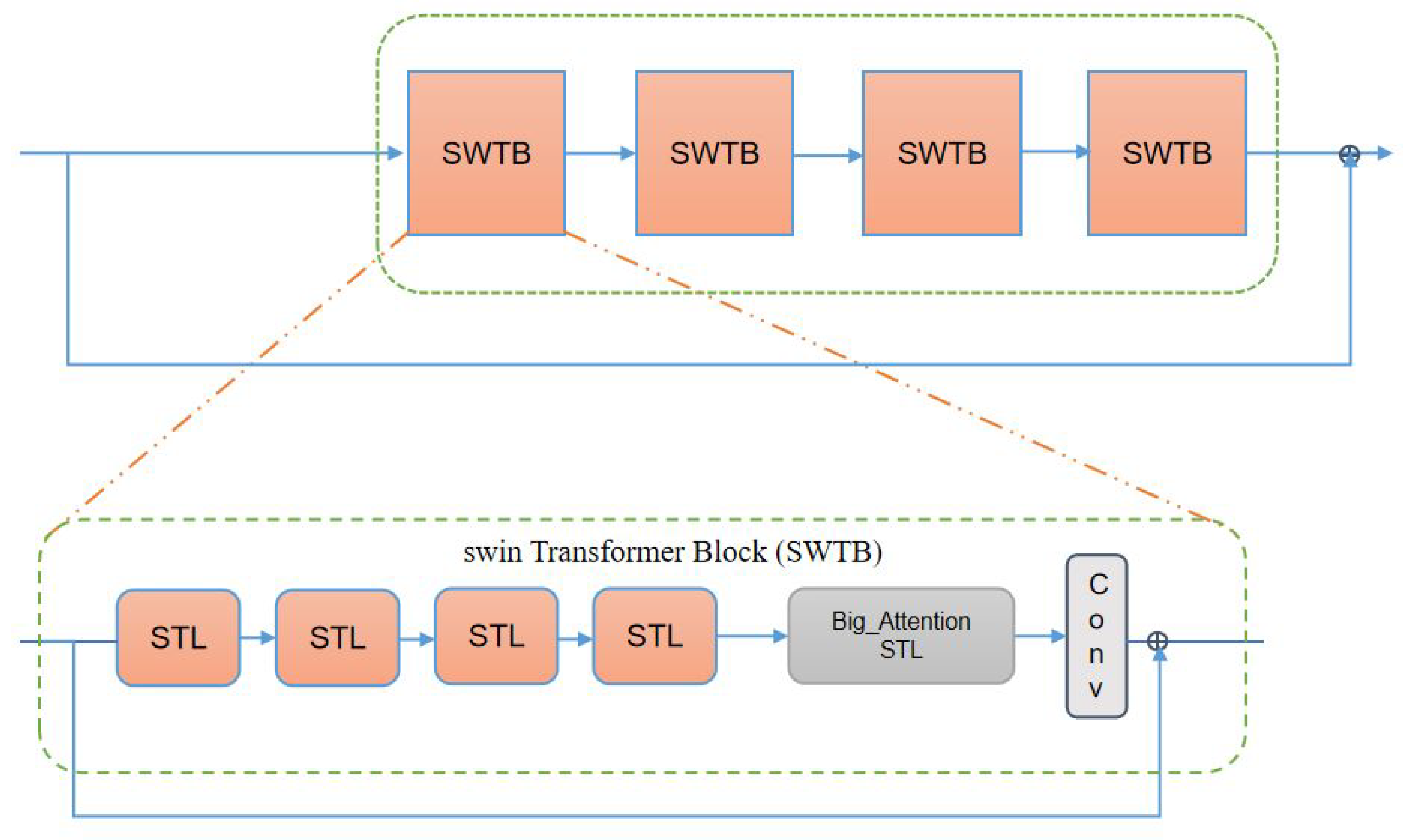
4.3.1. Results on Anime Face and Characters
In order to assess the effect of our model’s performance on the super-resolution of anime images, we selected 180 anime face images (AnimeFace180) and 83 anime character (Multi-level anime83) images from the test dataset for testing. The image features of AnimeCharacter12 are included in the image of Multi-level anime83, so they are not used in this test.
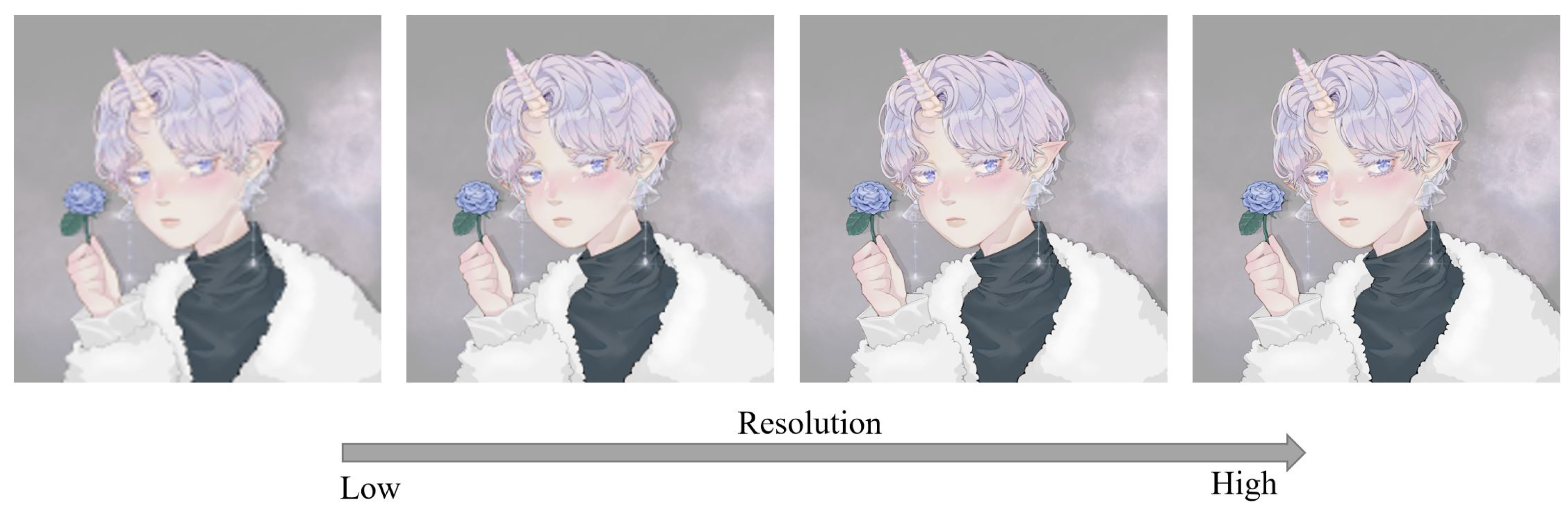
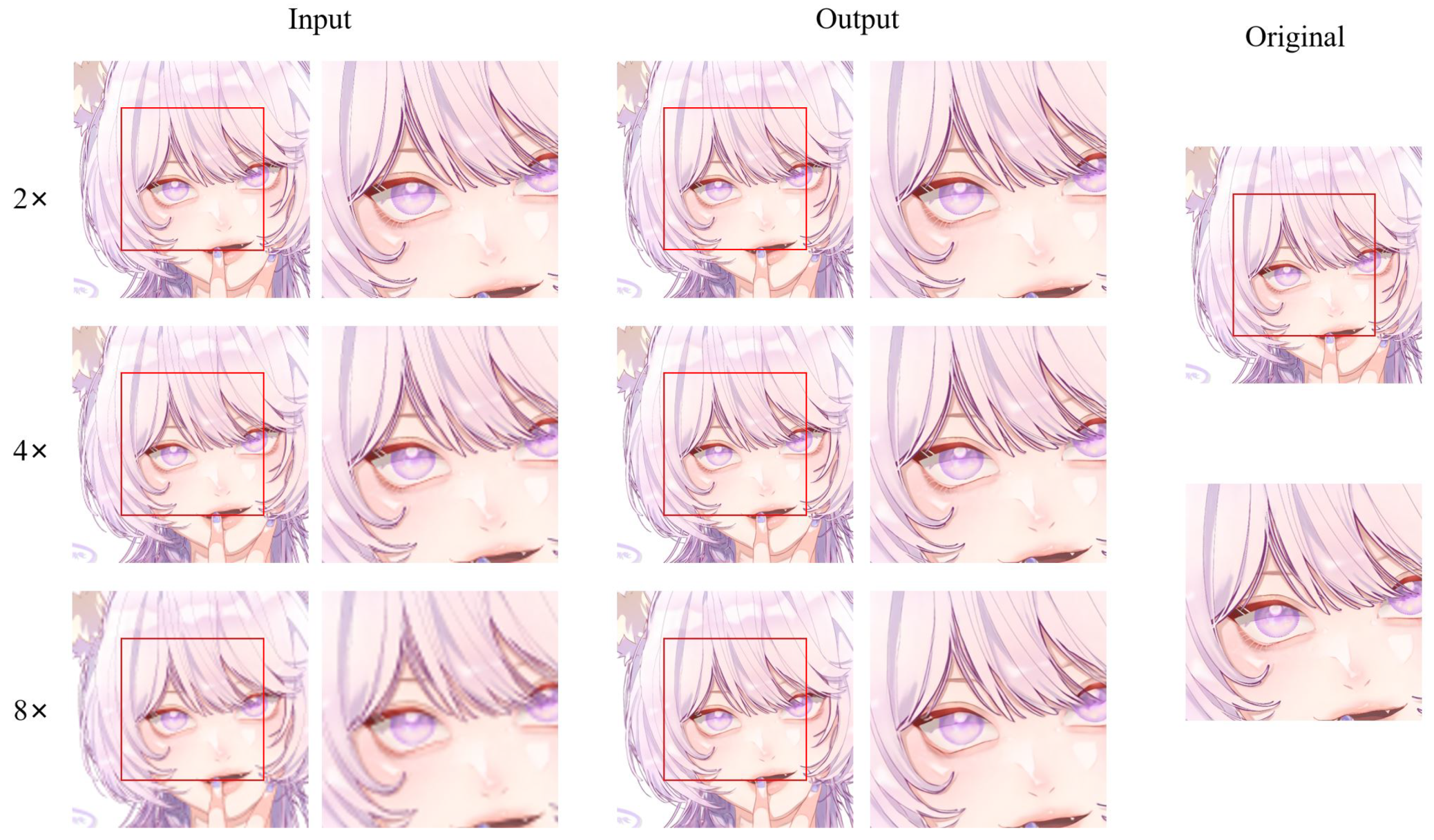
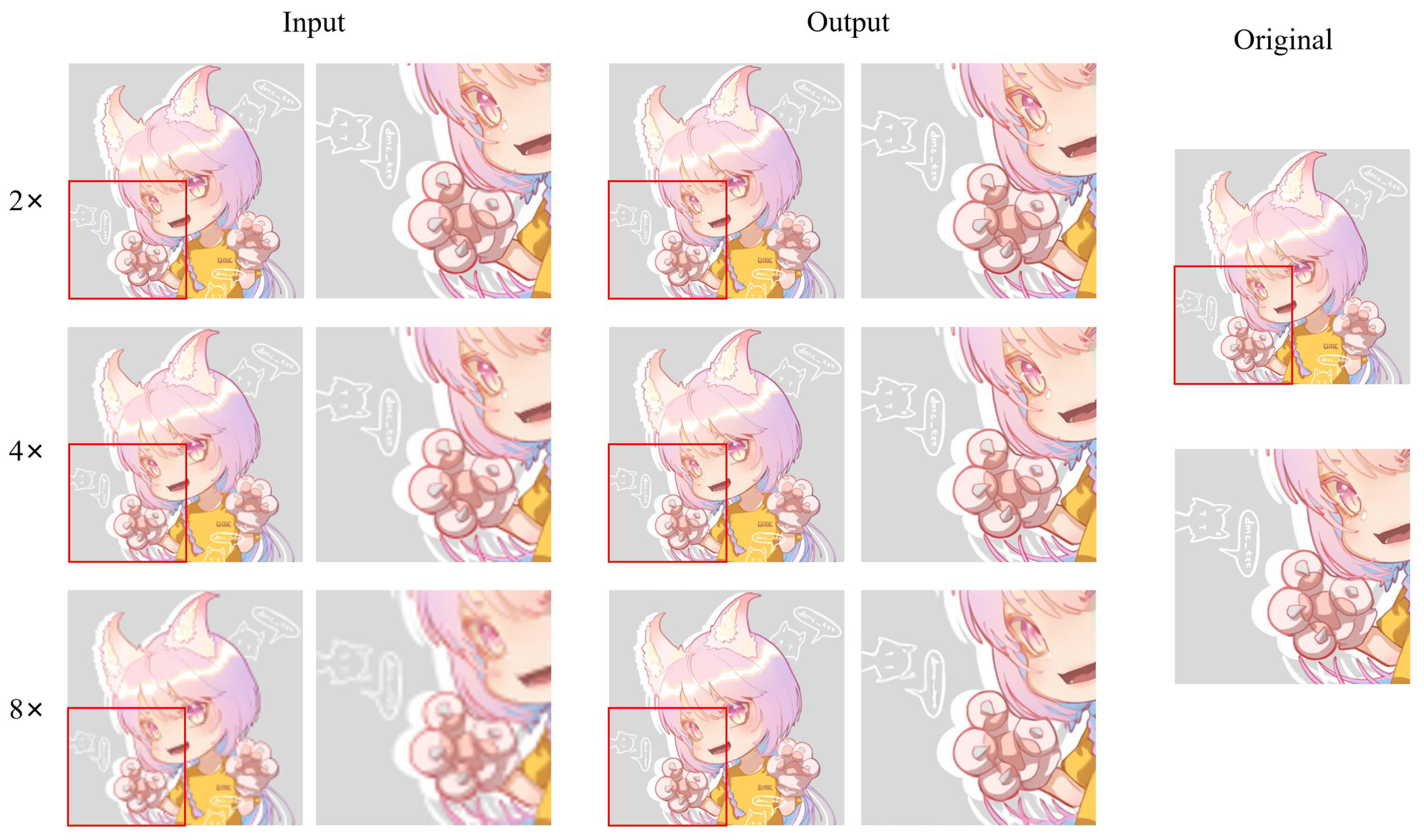
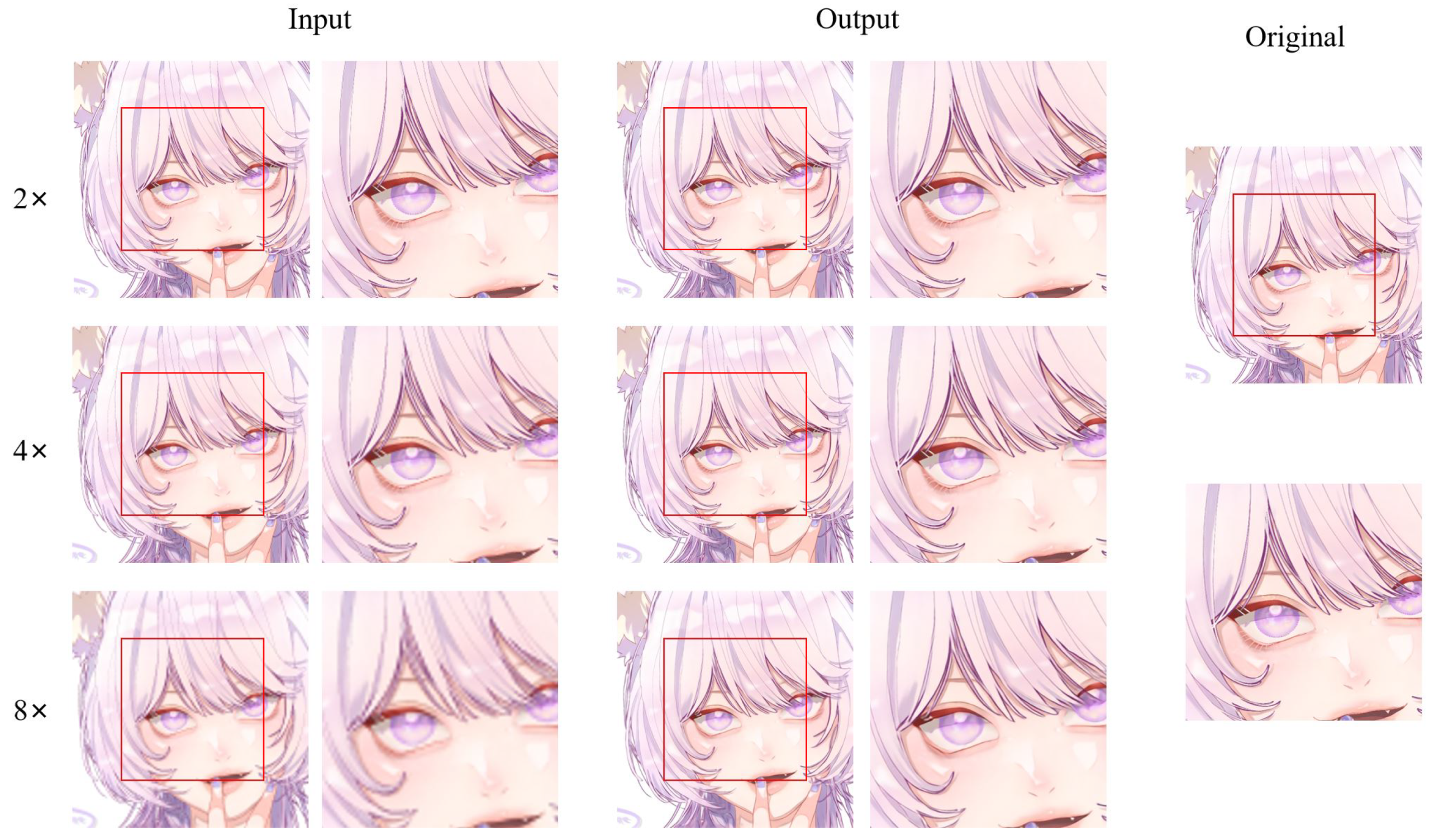
An example of different super-resolution tasks (2×, double super-resolution; 4×, quadruple super-resolution; 8×, octal super-resolution) is shown in
Figure 20. The example comes from the test dataset consisting of 180 anime face images. Following
Figure 20, we can conclude that in 2× and 4× tasks, the anime image’s sharpness significantly improves. The jagged lines in some of the original low-resolution images are smoothed out. The difference between the generated image and the original high-resolution image is minimal. In the 8× task, the jagged lines in the original low-resolution image were improved, and the overall quality of the image was also improved compared to before.
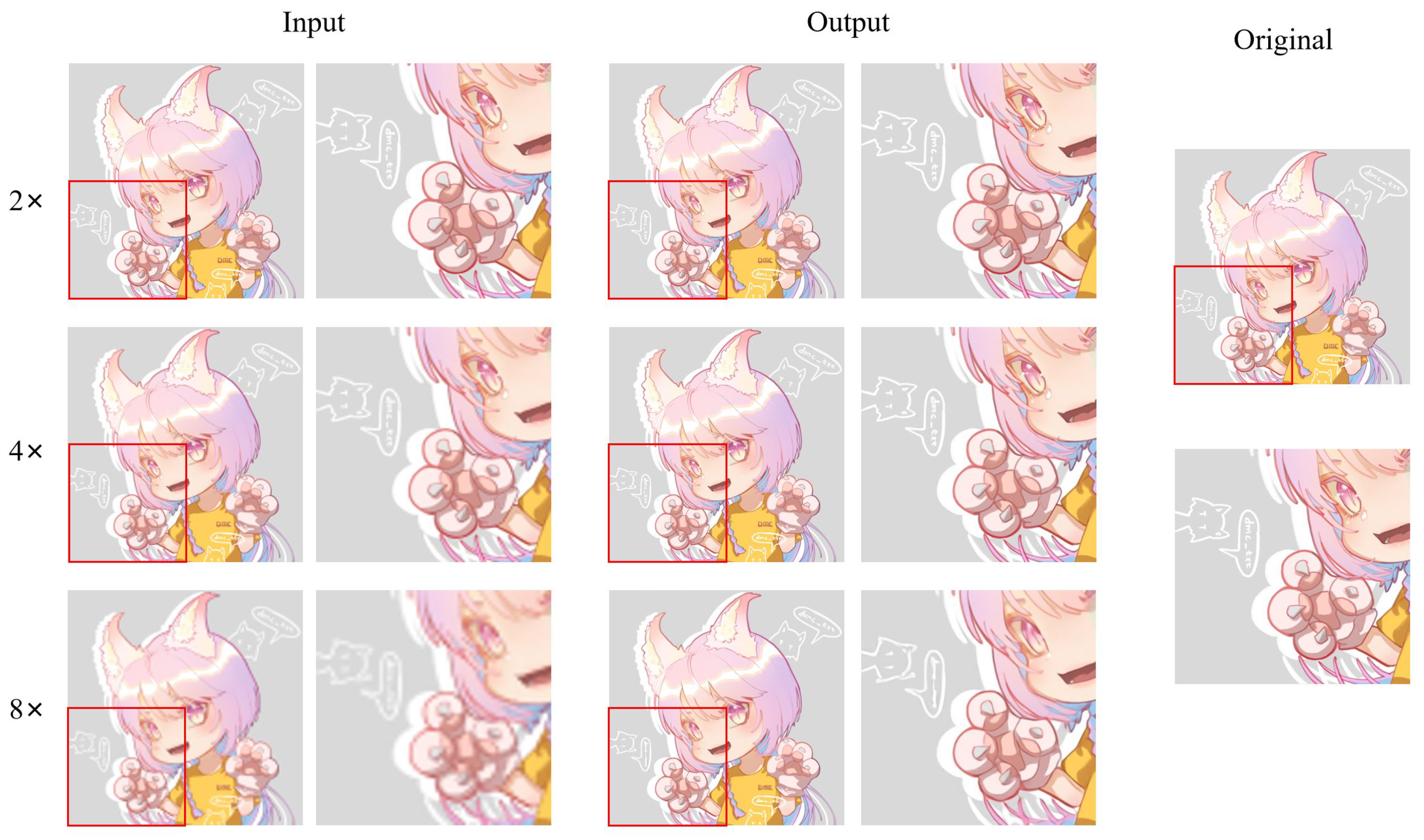
In addition to anime face images, there are also many half-body and full-body images in anime works. Therefore, we selected 83 anime character images, including half-body and full-body images, from the test dataset to assess the model’s performance.
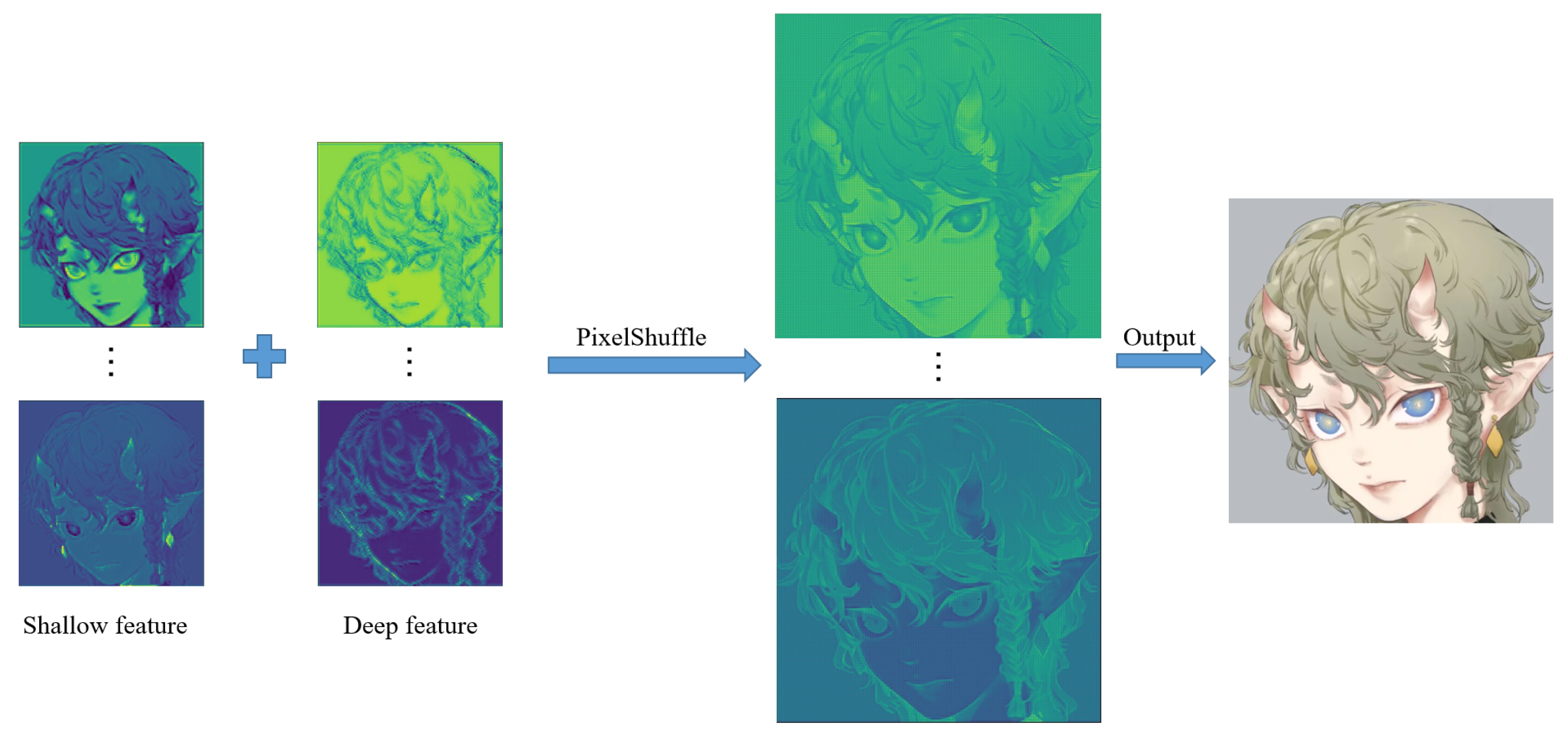
Figure 21 shows an example of different super-resolution tasks. We zoomed in on parts of the image to show details more clearly. In the 2× and 4× tasks, the details of hair end and hand nails in the anime images generated by our model are significantly improved. In addition, the lines across the character are smoother than in the original low-resolution image. In the 8× mission, the sharpness of the characters is also greatly improved. The test results of anime faces and characters show that our model has a good effect on improving the resolution of low-resolution anime images. Furthermore,
Table 1 demonstrates the maximum and average values of PSNR and SSIM for the super-resolution tasks (2×, 4×, 8×) on these two test datasets. The standard value of PSNR in lossy image and video compression is said to be 30–50 dB, but the average value is over 30 dB even at 8×. It is said that quality degradation is visibly noticeable when the SSIM is 0.90 or less, but the average value is above this value up to 4× task.
4.3.3. Comparison against the State-of-the-Art Methods
In order to reflect the different performances among different models, the model proposed in this paper is compared with the classic or state-of-the-art methods.
Bicubic: For the classic super-resolution, we choose the Bicubic method. Bicubic interpolation [
4] is a more complex interpolation method. The algorithm uses the gray value of 16 points around the point to be sampled for cubic interpolation, which takes into account the gray value of the four directly adjacent points and the effect of the gray value change rate between adjacent points. Three operations can approach the upscaling effect of high-resolution images; it was widely used in super-resolution tasks in the early days. The traditional interpolation stretching and enlarging methods can hardly avoid problems such as aliasing, blurred images, and missing data. We use cubic interpolation in OpenCV to upscale the anime image by 2×, 4×, 8×.
Waifu2x: Waifu2x [
32] uses a trained deep convolutional neural network for image enlargement, which solves the shortcomings of other enlargement methods, such as reduced line sharpness and poor color block purity which often occur when enlarging animation-style pictures. It outperforms other magnification methods. We use Vgg7 to extract features and then use upconv7 to upsample to obtain the final 2× result. The result of 4× is performing two 2× operations. The result of 8× is four 2× operations.
Real-ESRGAN: In addition, we also choose a GAN-based anime image super-resolution method. Usually, an actual image may go through various processes, such as camera blur, sensor noise, and image compression, that make the image blurred and degraded. Therefore, Real-ESRGAN [
23] extends the first-order degradation model to a higher-order degradation model. A filter is then set up to simulate ringing and overshoot artifacts. The result is that this model is able to restore images more. Moreover, Real-ESRGAN was trained separately for anime images and achieved good visual effects. The generator we used is a deep network with several residual-in-residual dense blocks. The discriminator we used is a U-Net with spectral normalization.
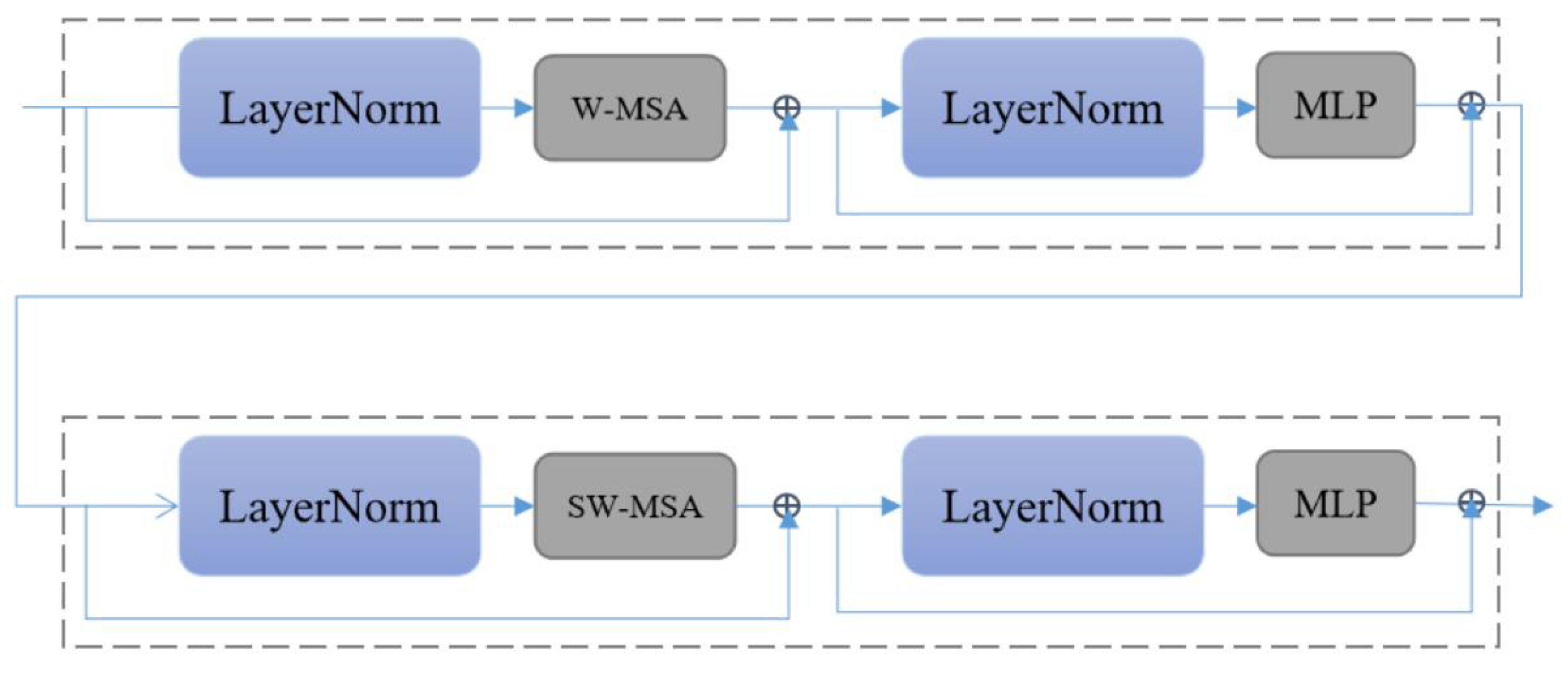
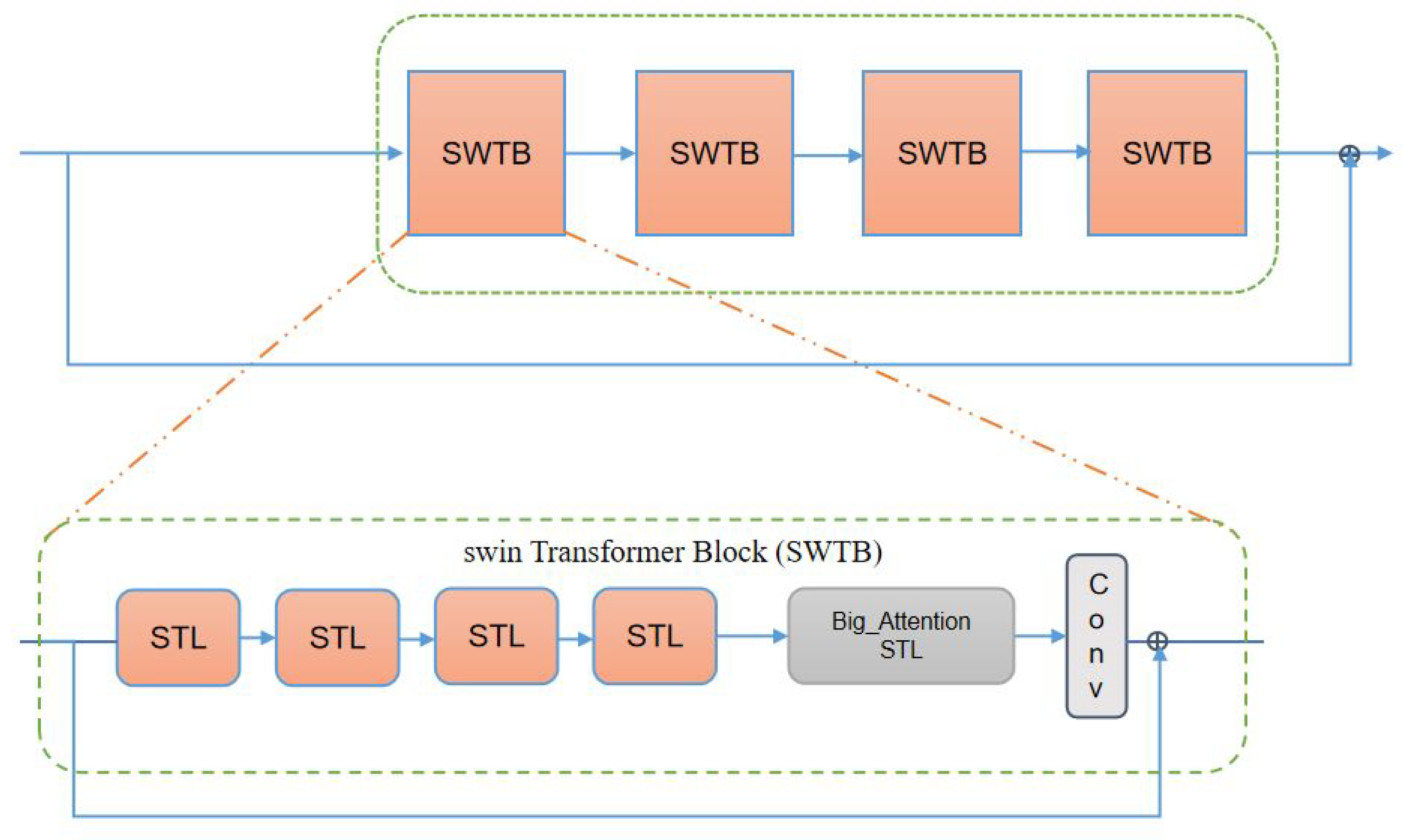
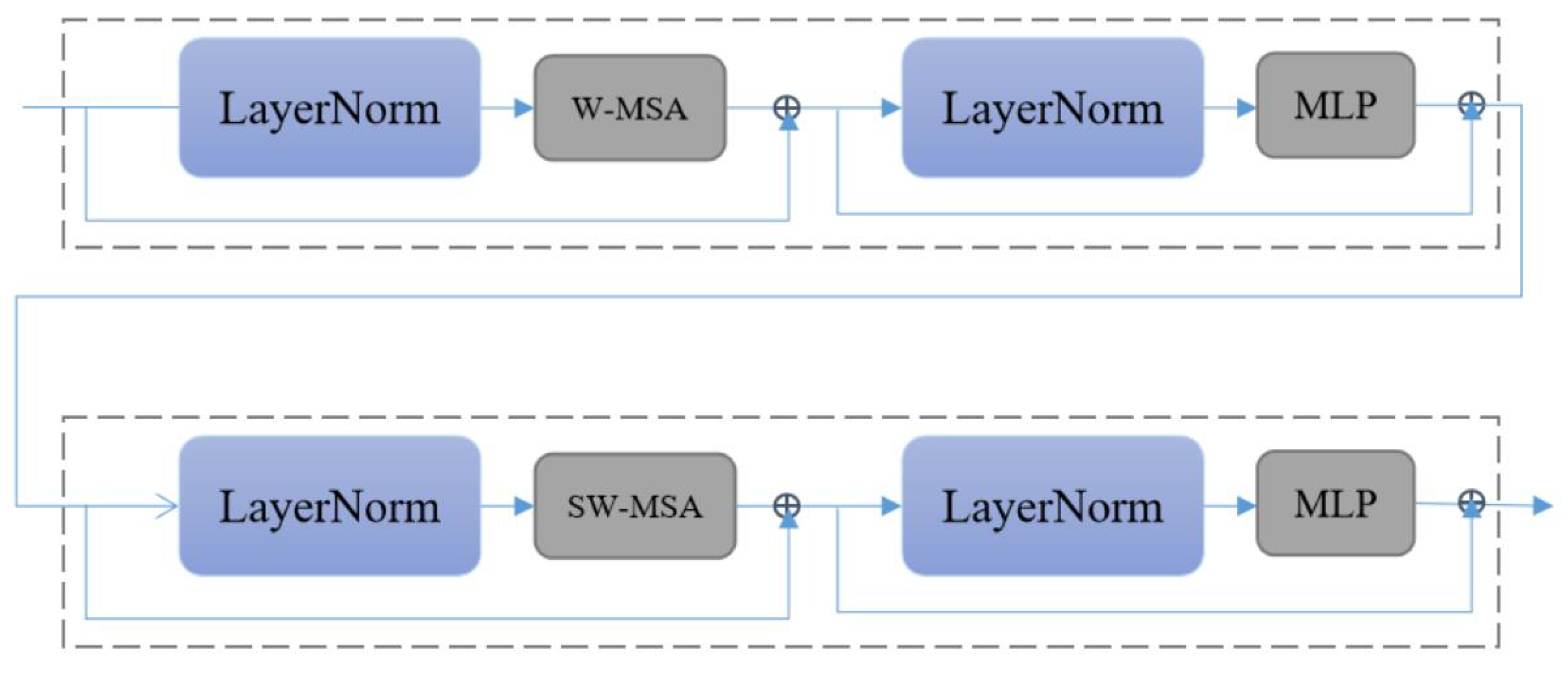
SwinIR: Since the transformer-based method is not currently applied to anime image super-resolution, we choose the current state-of-the-art method for comparison. SwinIR [
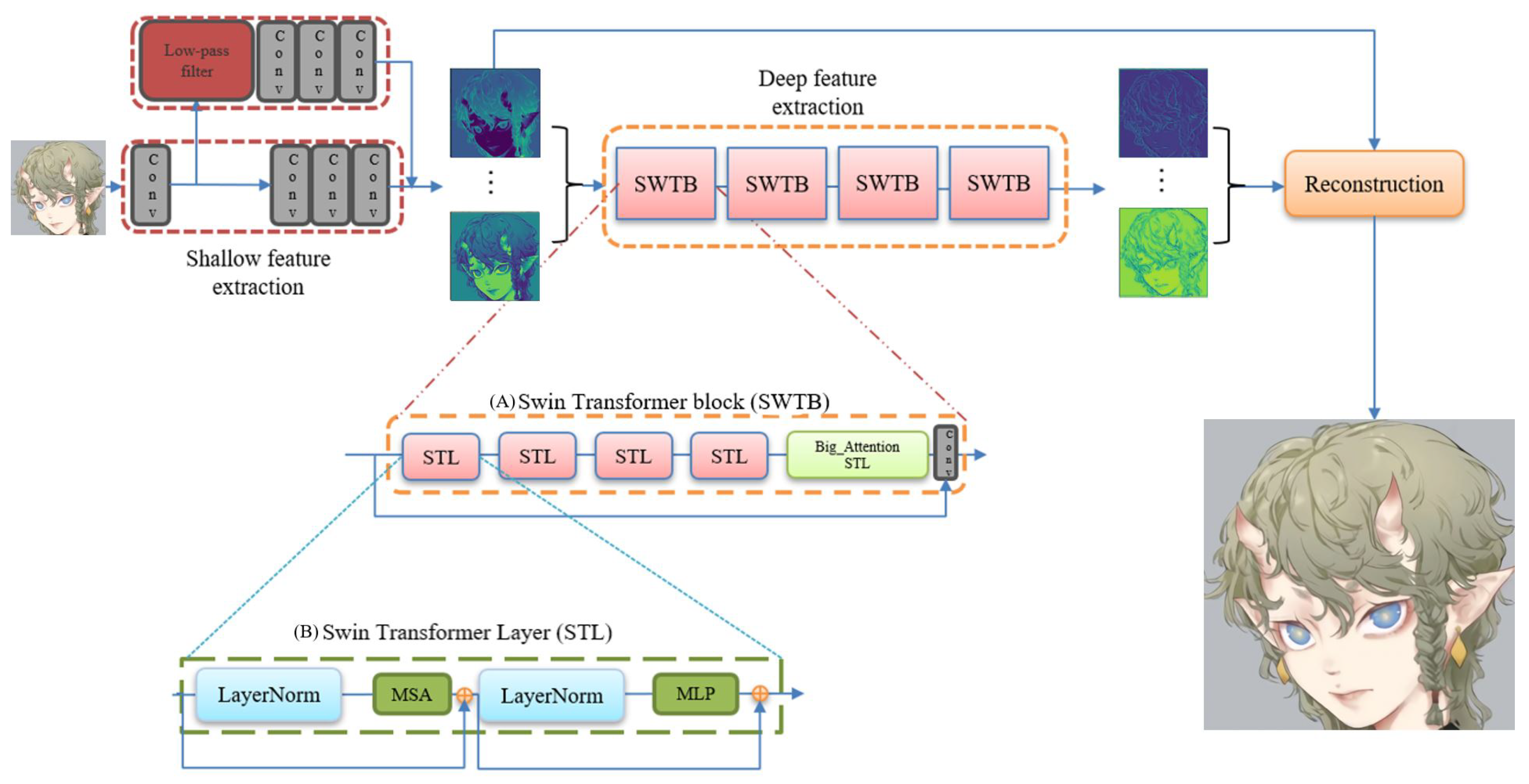
28] is based on Swin Transformer. SwinIR has a strong global perception ability to improve the overall quality of the image. For SwinIR, RSTB numbers and STL numbers are 6 and 6.
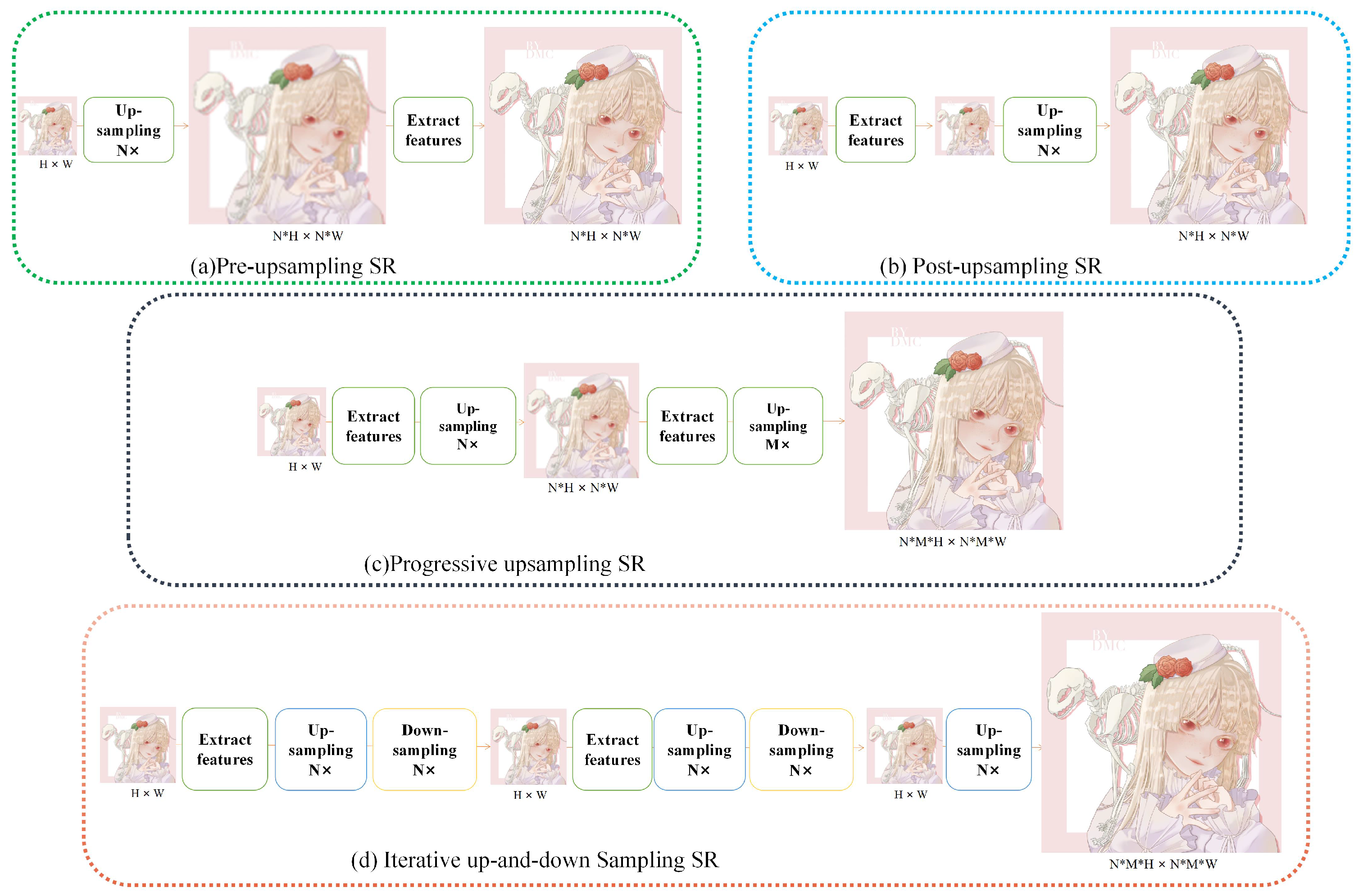
Comparative experiments were performed based on previously designed datasets. Additionally, quantitative comparisons were made on the result values (PSNR, SSIM). A visual comparison was also performed for graphic illustration.
- (1)
Comparison on AnimeFace180
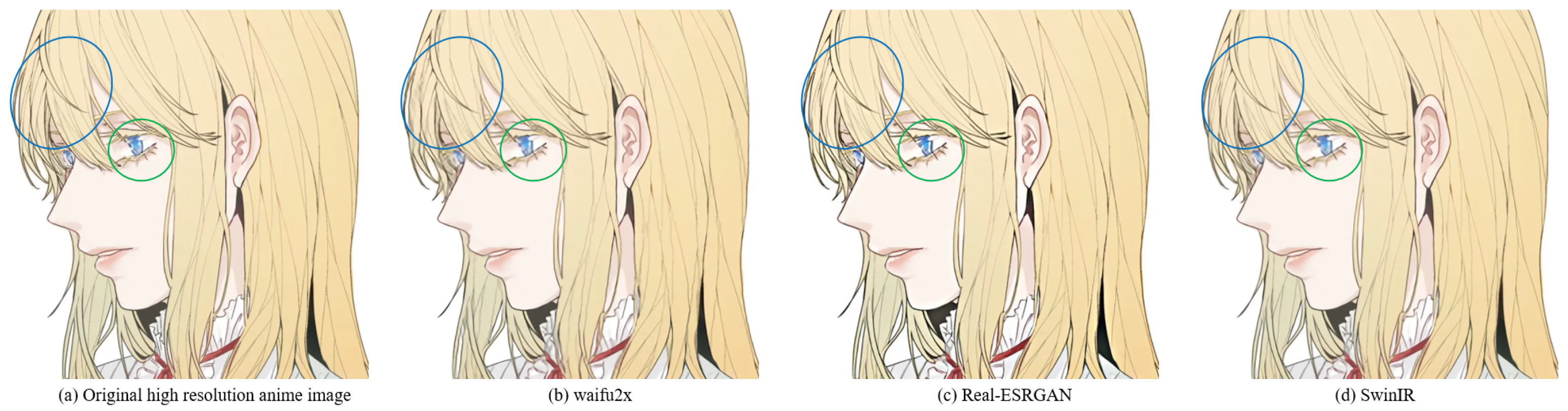
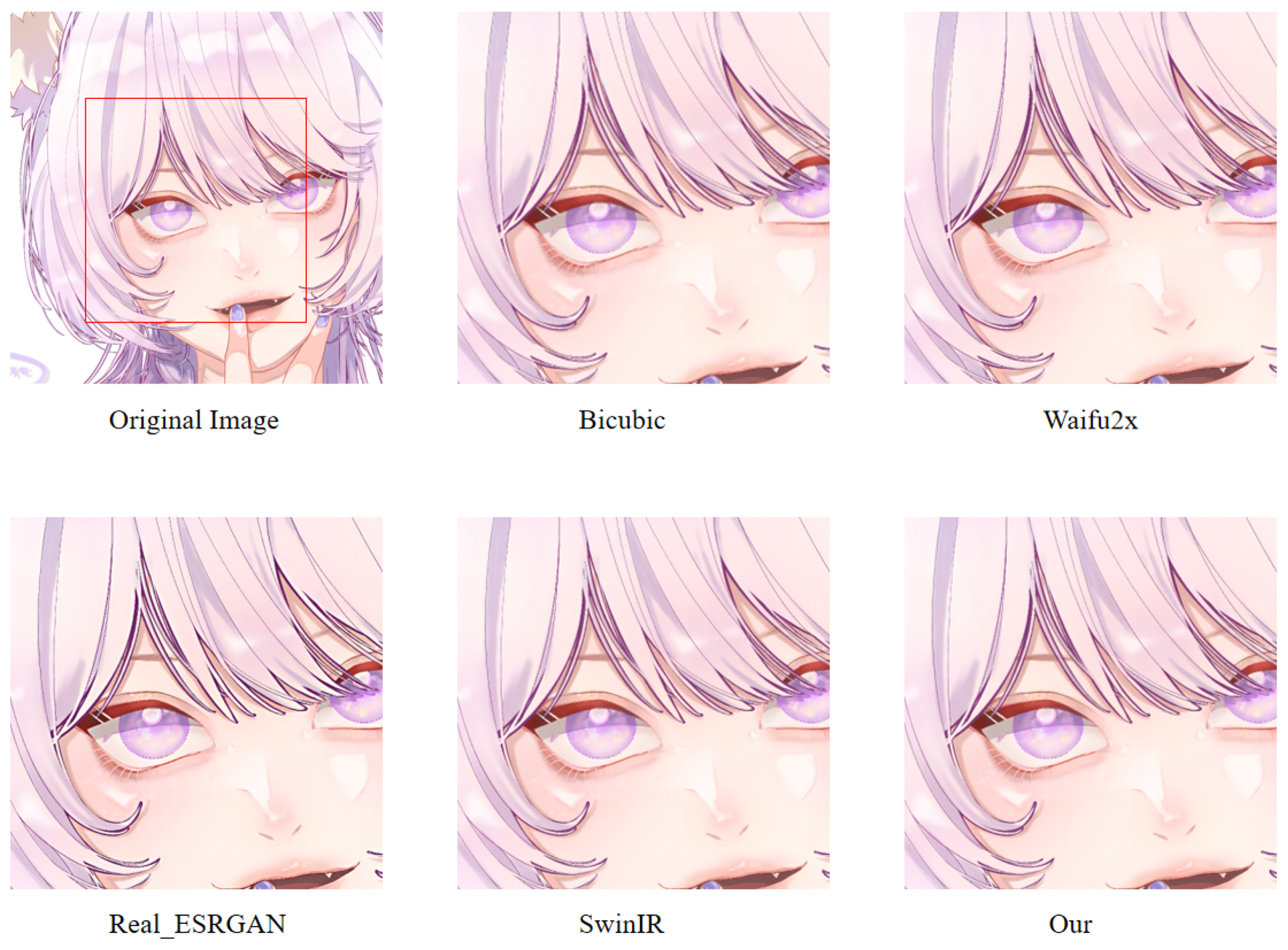
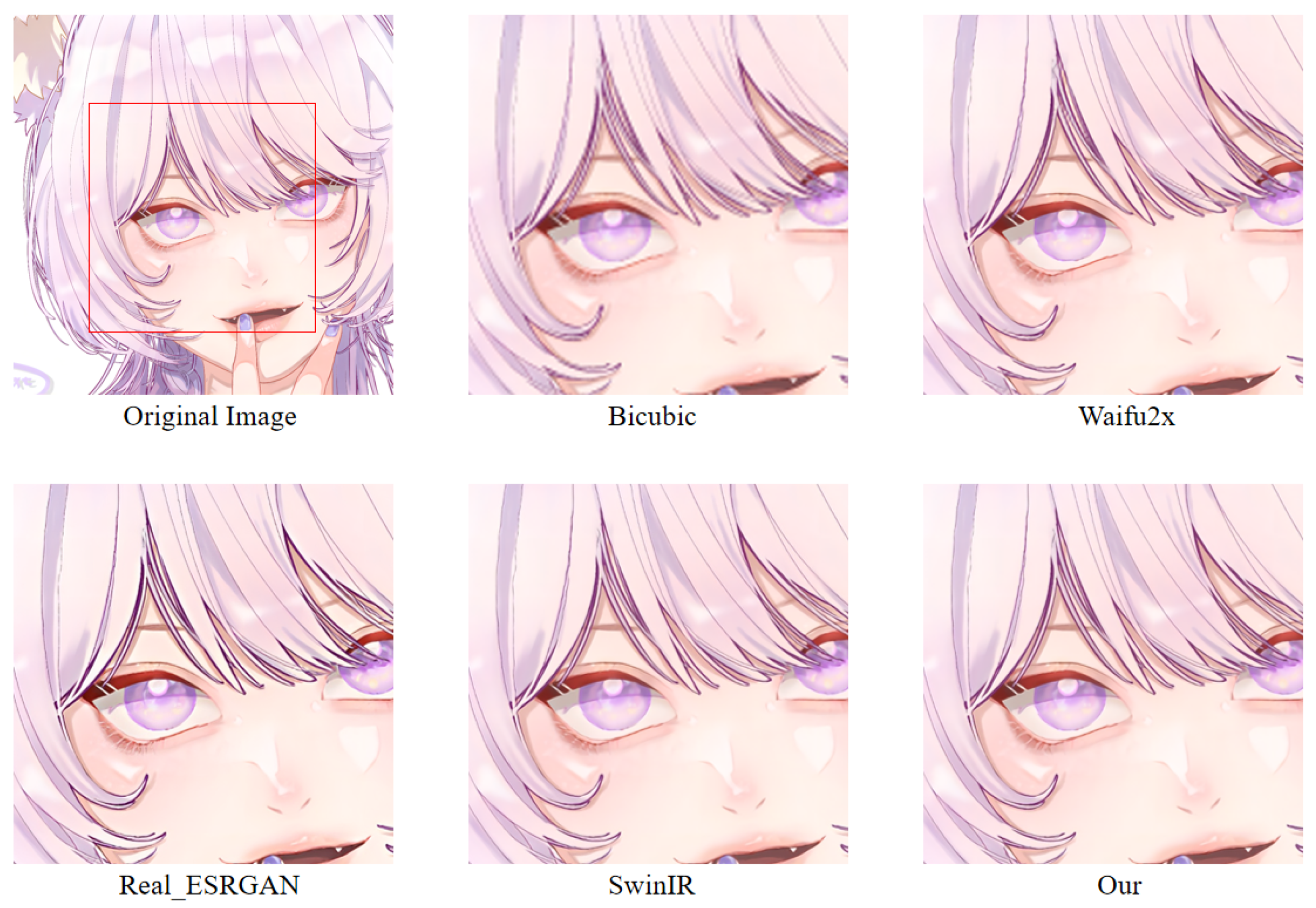
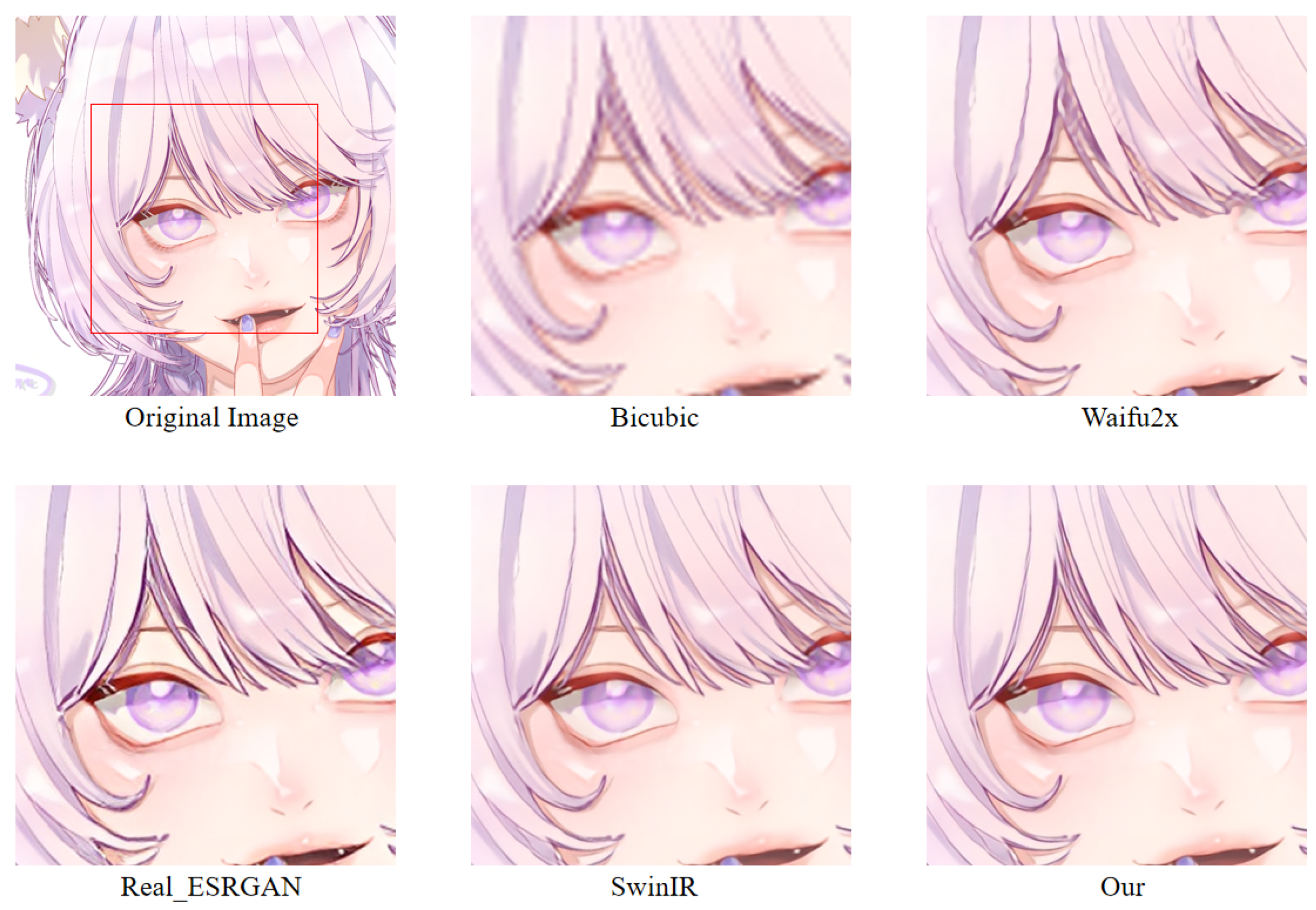
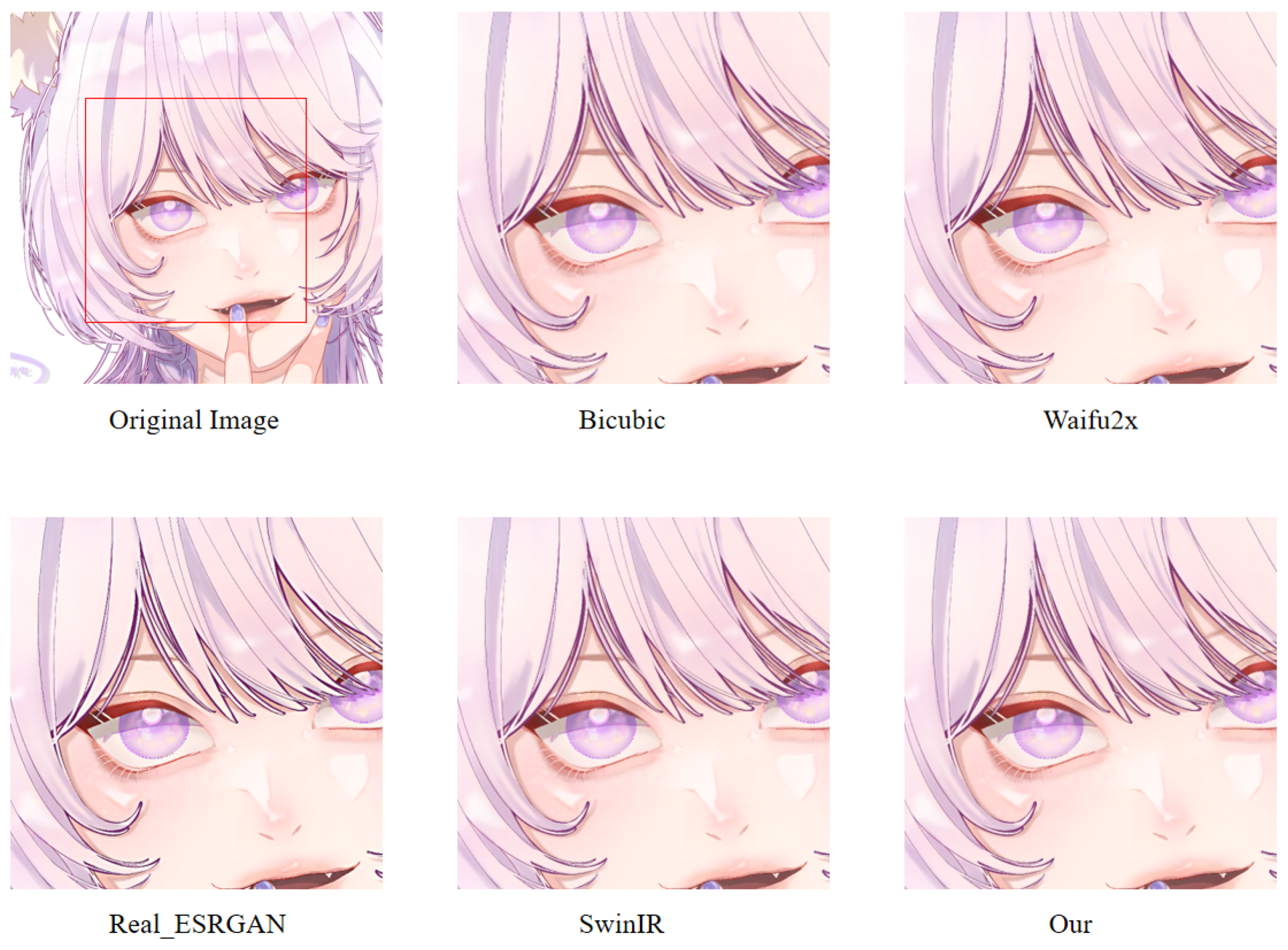
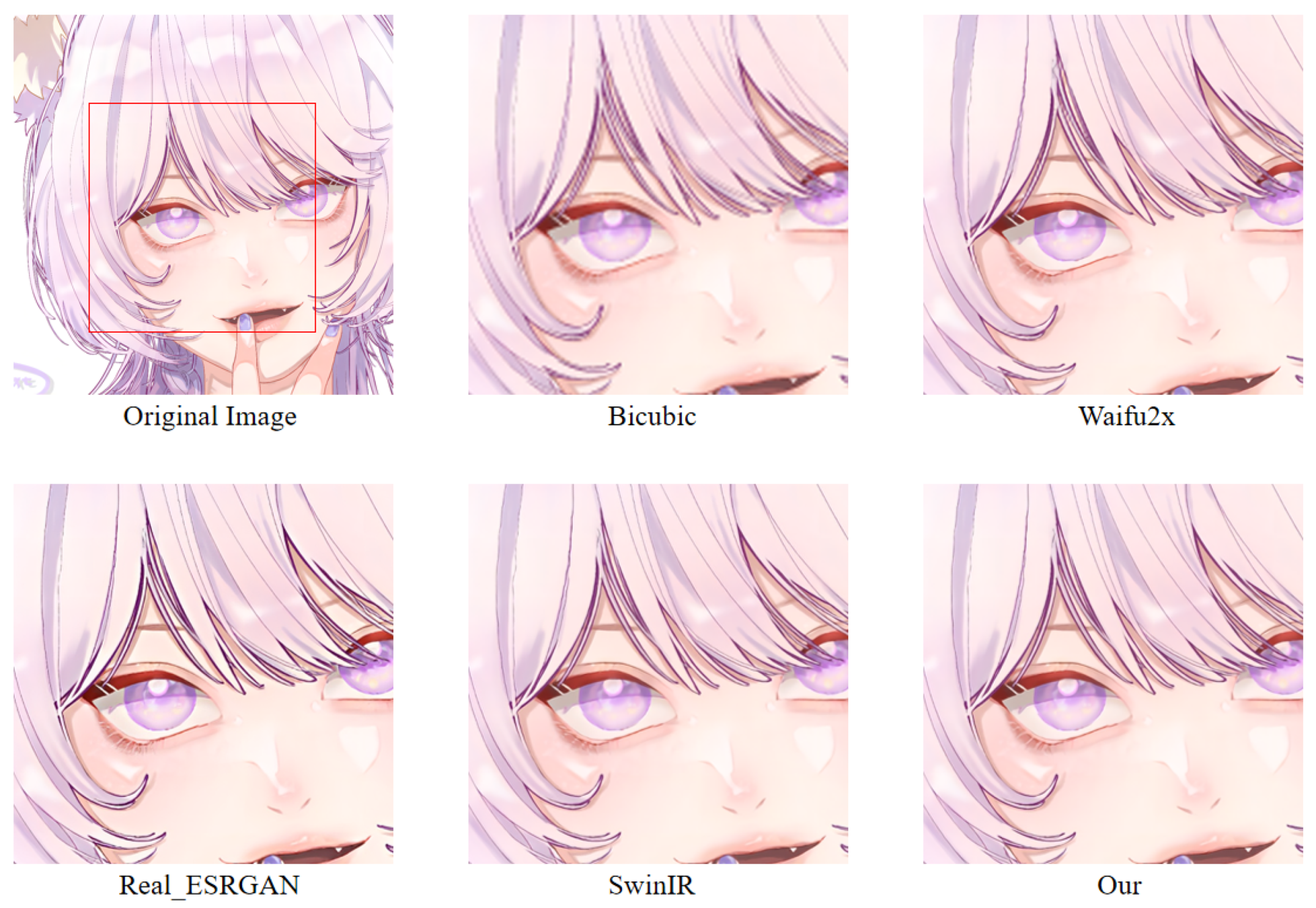
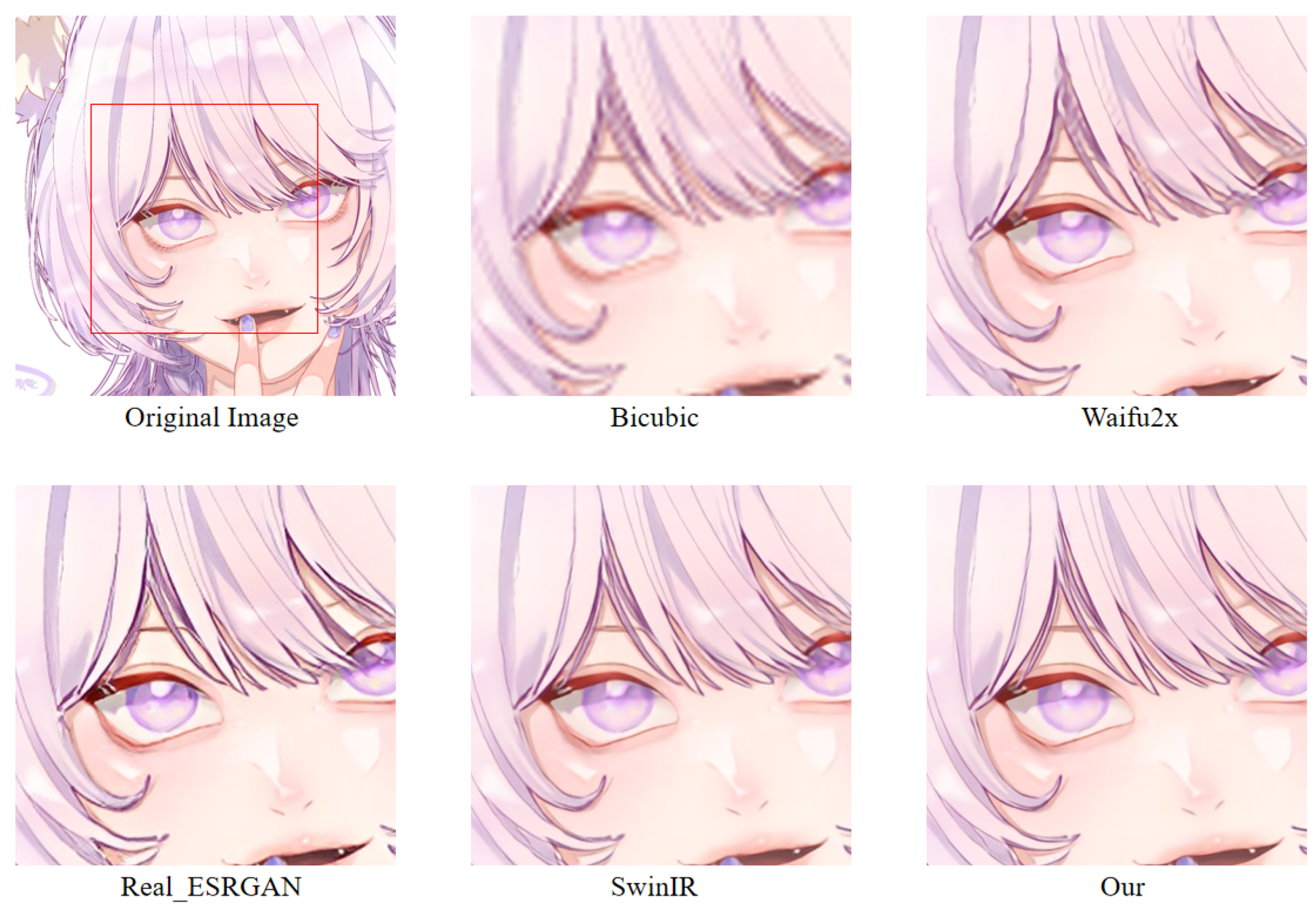
In order to more intuitively observe the anime image reconstruction capabilities of different models, we visually compare the reconstructed images as shown in
Figure 22,
Figure 23 and
Figure 24.
We can see the details of different models’ performances in the reconstructed images (see
Figure 22,
Figure 23 and
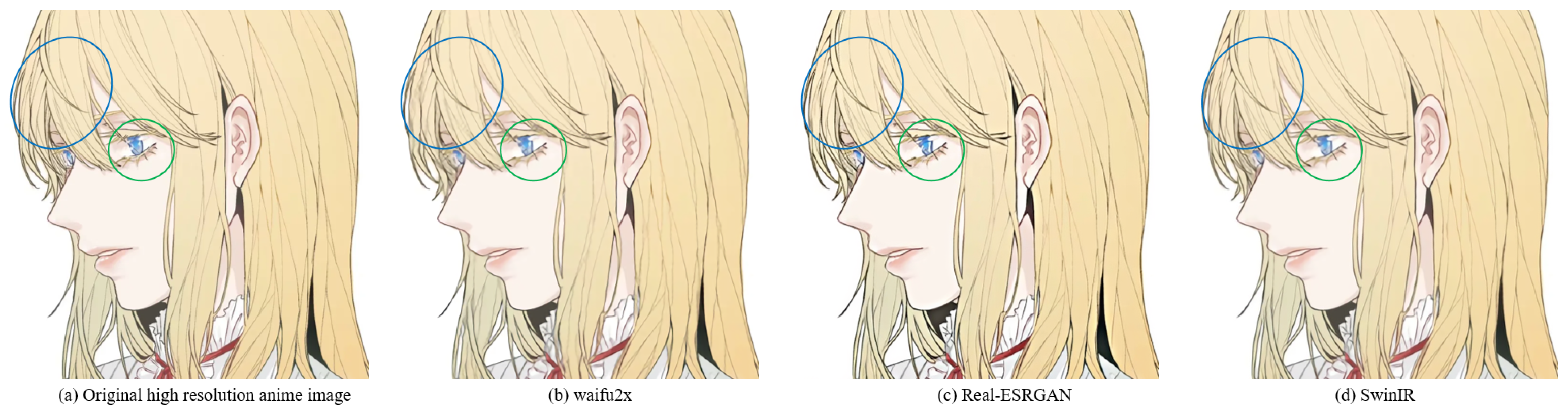
Figure 24). Bicubic-based methods achieve the worst results. We stated this point before because the interpolation-based method relies too much on the information of the image itself, so the reconstruction effect is often not good. Some ghosting and checkerboard effects appear in images reconstructed by Waifu2x. However, the images generated by Real-ESRGAN reconstruction avoid the occurrence of such ghosting and checkerboard effects. Moreover, if we only measure from a visual point of view, we see that Real-ESRGAN generates images of decent quality.
Nevertheless, since Real-ESRGAN is based on GAN, some hallucinations will appear during anime image reconstruction. It will add some extra information, such as the thick lines at the corners of the eyes. For SwinIR, the overall effect of anime images generated by SwinIR is greatly improved. However, because it removes the patch merging operation, the global perception ability is reduced, and some image details are missing. Finally, the model based on our method reconstructs images with fewer artifacts and avoids the checkerboard effect.
Table 3 discloses the assessment of our proposed method against the state-of-the-art methods. The presented experimental results demonstrate that the proposed method achieved the best results, followed by SwinIR. However, as mentioned above, the Bicubic-based method performed the worst. The assessment was performed using the standard PSNR and SSIM metrics on resolution tasks at different magnifications (2×, 4×, 8×).
- (2)
Comparison on AnimeCharacter12
In Animeface180, we only tested the super-resolution effect of anime face images. However, there are not only a large number of anime face images in anime works, but also many full-body images of anime characters. Therefore, to assess our model’s performance in the overall anime character, we conduct comparisons between different methods on the AnimeCharacter12 test dataset.
First, we use an example to visually compare the differences between different methods (see
Figure 25).
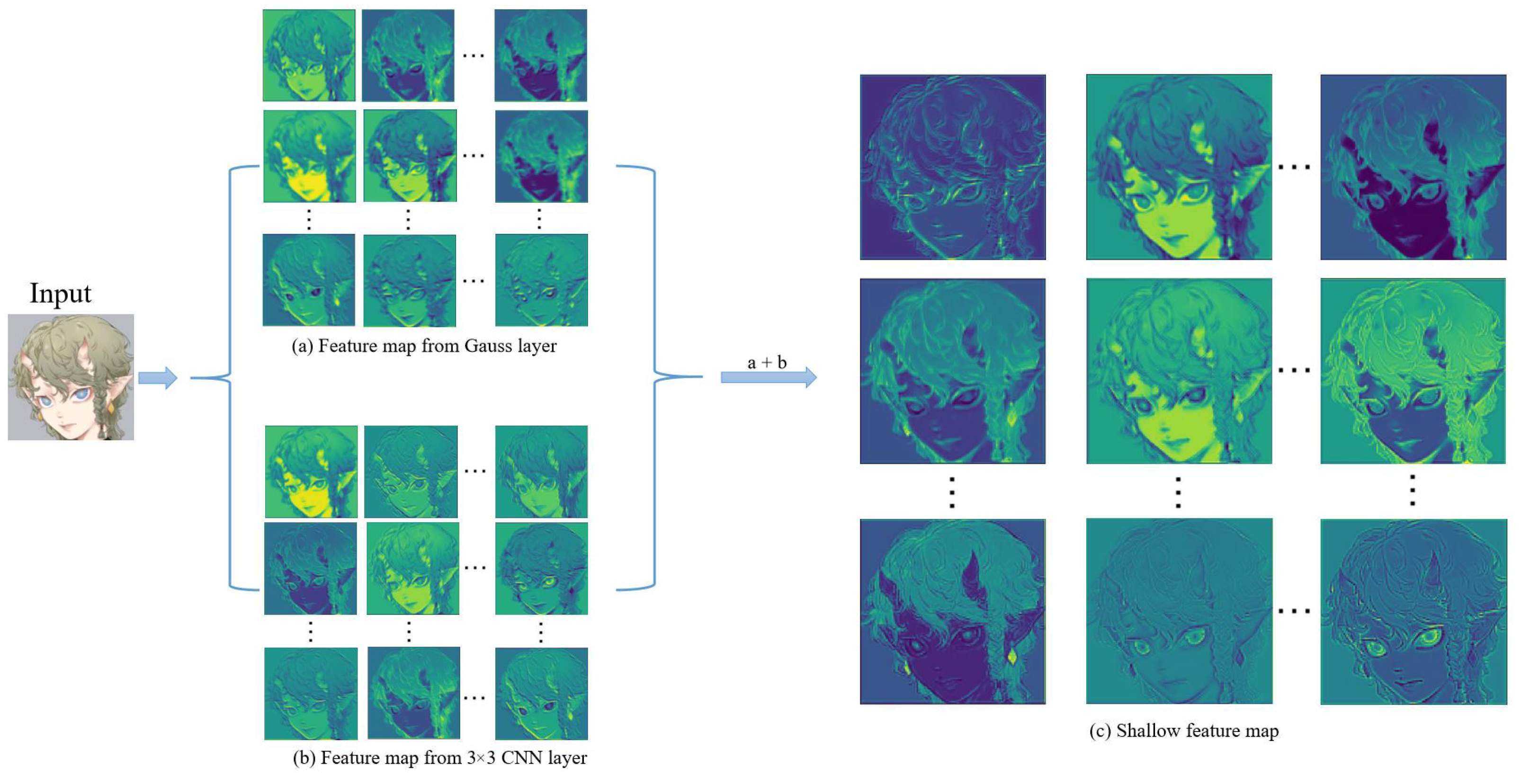
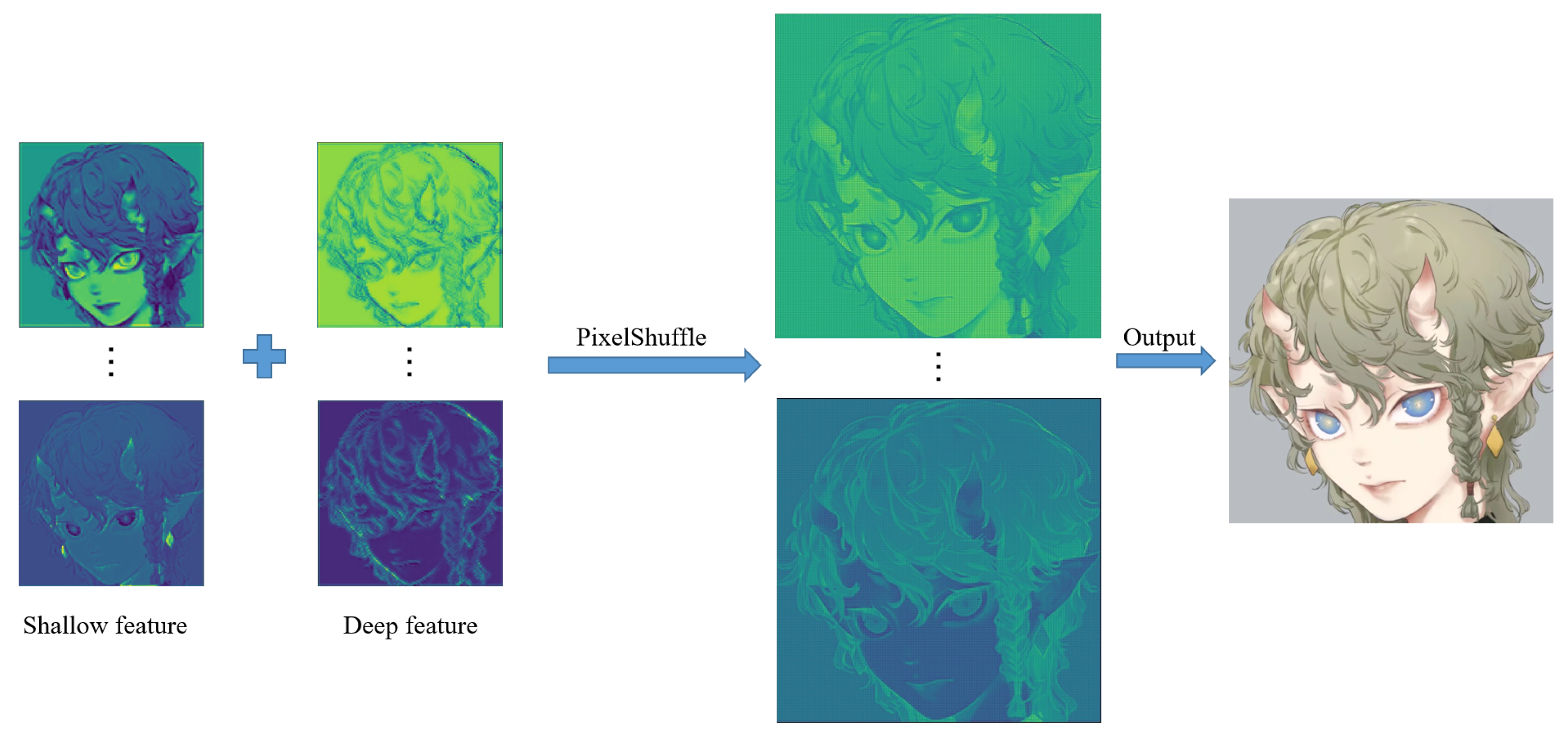
The super-resolution image obtained by the interpolation method, i.e., Bicubic, which relies on the image’s information, is still very blurry and does not have the effect of improving the image resolution. The results achieved by Waifu2x on 2× missions are still good, with no obvious error messages. However, on 4× and 8× tasks, Waifu2x has some glaringly wrong textures. For example, the color of some areas overflows, and some lines are jagged. This is because Real-ESRGAN mainly focuses on visual perception, resulting in the images generated by it not having high values in evaluation indicators. While visually pleasing to the human viewing experience, there are some color deviations from high-resolution images, and some lines are overly thickened. SwinIR and our method are based on the Swin Transformer, and the images generated by SwinIR and ours are closer to the original high-resolution image. Nevertheless, because we make good use of the rich low-frequency information of the anime image, the color in the enclosed area is closer to the original image. In addition, the increased global awareness also makes our method smoother than SwinIR on some fine lines.
By comparison, our model is better than Waifu2x in detail rendering. Moreover, compared to Real-ESRGAN, we did not have some hallucinations problems. Compared to SwinIR, we are better at the restoration of details. This is thanks to the last large attention window in each layer of our network. Larger attention windows can incorporate more information. Moreover,
Table 4 also confirms the performance assessment of our model, which achieved the best results in terms of standard PSNR and SSIM evaluation metrics.
- (3)
Comparison on Multi-level anime83
Multi-level anime83 contains anime images in different scenes. Therefore, it can well reflect the generalization ability of the model. We verify the generalization ability of different models through Multi-level anime83 (see
Table 5).
The results of three example images from the Multi-level anime83 test dataset for different super-resolution methods at 4× super-resolution task are shown in
Figure 26. Compared with the crane patterns on the clothes of anime characters, the super-resolution images generated by the Bicubic method are still very blurry. The super-resolution image lines generated by Waifu2x are not smooth. The super-resolution images generated by Real-ESRGAN, SwinIR, and ours are not very different from a visual point of view. The same situation occurs in the second super-resolution task on animal characters. However, we can find that the lines generated by Real-ESRGAN are always slightly thicker. The gap between the three can be observed in the third anime picture with Chinese characters. Real-ESRGAN has obvious errors in some strokes. Compared with our generated Chinese characters, the Chinese characters generated by SwinIR have poor regularity and insufficient color uniformity.
Following
Figure 26 and
Table 5, we can confirm that the proposed model achieves the best results under the 2×, 4×, and 8× tasks, followed by SwinIR. Our model can perform super-resolution tasks well in different application scenarios (anime faces, anime characters, anime buildings, anime animals, etc.).
- (4)
The runtime comparison with different methods
We conducted runtime tests on three test datasets to verify the computational speed of different methods. AnimeFace180 contains three sizes of anime images: 64 × 64, 128 × 128, and 256 × 256. These sizes correspond to 8×, 4×, and 2× anime image super-resolution tasks. Both AnimeCharacter12 and Multi-level anime83 also contain three sizes of anime images: 128 × 128, 256 × 256, and 512 × 512. These sizes correspond to 8×, 4×, and 2× image super-resolution tasks. The tests were performed on the computer, with CPU-i7-11800H and GPU-3080Ti, respectively.
As shown in
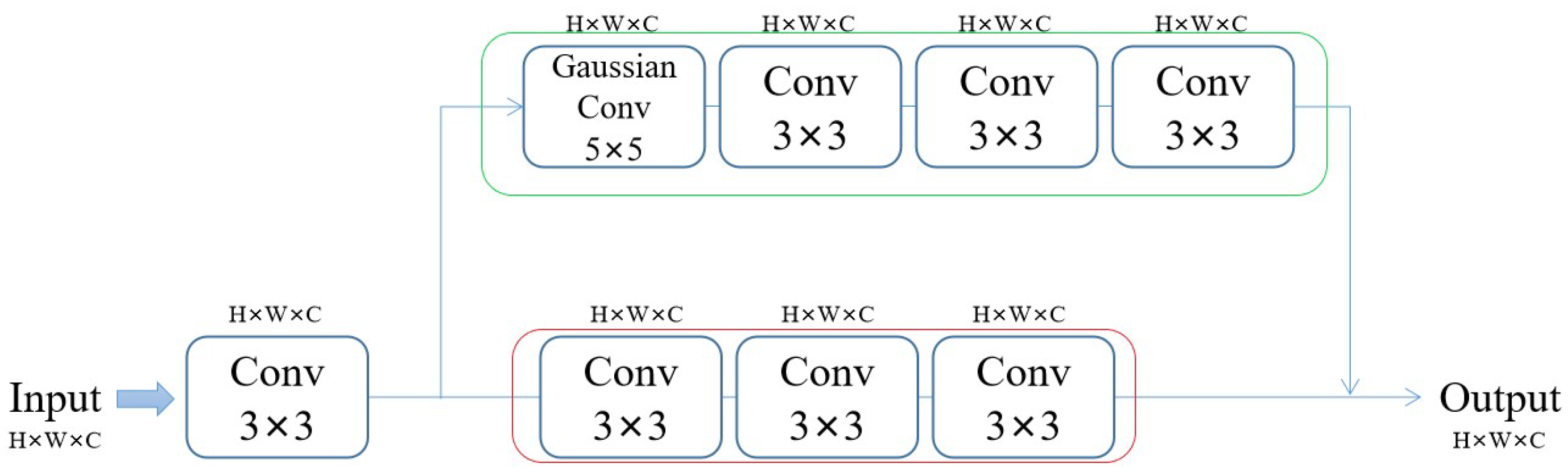
Table 6, our model does not have an advantage in runtime testing. As the core of the transformer model, the self-attention mechanism not only endows the transformer with powerful modeling capabilities but also brings a series of computing and memory problems to the transformer model. In computer vision, the self-attention mechanism is based on each pixel as a token, resulting in a longer computing time for the transformer-based model. Our priority in designing the model is the quality of the super-resolution images. Therefore, we disregard memory and computational overhead to obtain better super-resolution results.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}