1. Introduction
Computer vision is a research field in computer science that studies the components associated with digital images or videos. Recently, deep learning-based 3D object detection methods, using 3D sensors, have been actively proposed in various fields, such as autonomous driving and robotics [
1]. For effective end-to-end systems for deploying 3D object detection methods, state-of-the-art studies are being conducted on CNN, Recurrent Neural Networks (RNNs), and cloud computing processing for the integration of long-term short-term memory, and distributed systems, as well as parallelization within and between networks [
2,
3]. With the development of 3D information acquisition hardware-assisted technologies, there are various types of 3D scanners, LiDARs, and RGB-D image sensors for obtaining scaled information [
4]. The 3D sensor uses infrared rays to determine the depth information between the object and the sensor by measuring the change in the waveform of the wavelength reflected by the object or the time difference. The depth and color information of objects in 3D can be obtained and converted spatially to construct a point cloud, which is a 3D data structure [
5]. The characteristics of 3D data contain more information than those of 2D. This enables the networks to easily distinguish occluded objects. Therefore, 3D data acquired from small IT devices, have been applied to 3D shape classification, such as object detection and tracking, point cloud segmentation, and point cloud processing [
6].
Point clouds are used in many fields, such as in the military, education, medical care, and architecture [
7], and deep learning is being applied to efficiently process them. There are two methods for processing a point cloud by deep learning: a method that implies spatial information and a method that directly uses point information [
8]. A 3D CNN is a typical example of a method for processing implied spatial information [
9]. CNN is a deep learning model that is widely used in the image field and can efficiently collect and process image features. However, in the case of 3D models, a large amount of computation occurs, owing to the application of CNN filters when projected spatial features are implied [
10]. Additionally, the loss of 3D coordinate information of a point occurs during the implication process. Defining the best point cloud representation for deep learning is not straightforward and remains an open problem [
11,
12,
13]. To address this problem, several studies have used GNN for the classification and semantic segmentation of point clouds [
6,
14,
15,
16]. A Point-GNN, which expresses the point cloud as a graph, has a wide receptive field while directly processing point information [
17]. The recent development of GCN, which is a representative method of GNN, suggests that graph representation can provide improved functions for irregular point cloud processing [
18].
Our previous study [
19] addressed the novel VPS (Visual Positioning System) to determine the user’s position in an indoor space without GPS by matching the point cloud pose database, which is addressed by pre-defined voxel indexes and object pose estimation. The network in this system improved Point-GNN [
17], and used MLP (Multi-Layer Perceptron) to estimate the pose of 3D objects, and proposed 3D IoU (Intersection Over Union) using Euler rotation. The Euler method has been used in algorithms related to several 3D spaces. The conventional method was to calculate two 3D bounding boxes, IoU in seven DOF (Degrees of Freedom) in one rotation (centered on the
z-axis) using a bird’s eye view. However, we designed the nine DOF estimation of an object pose, which improved the limits of the seven DOF pose estimation. We adjusted the new network structure to improve performance, such as accuracy and real-time operation.
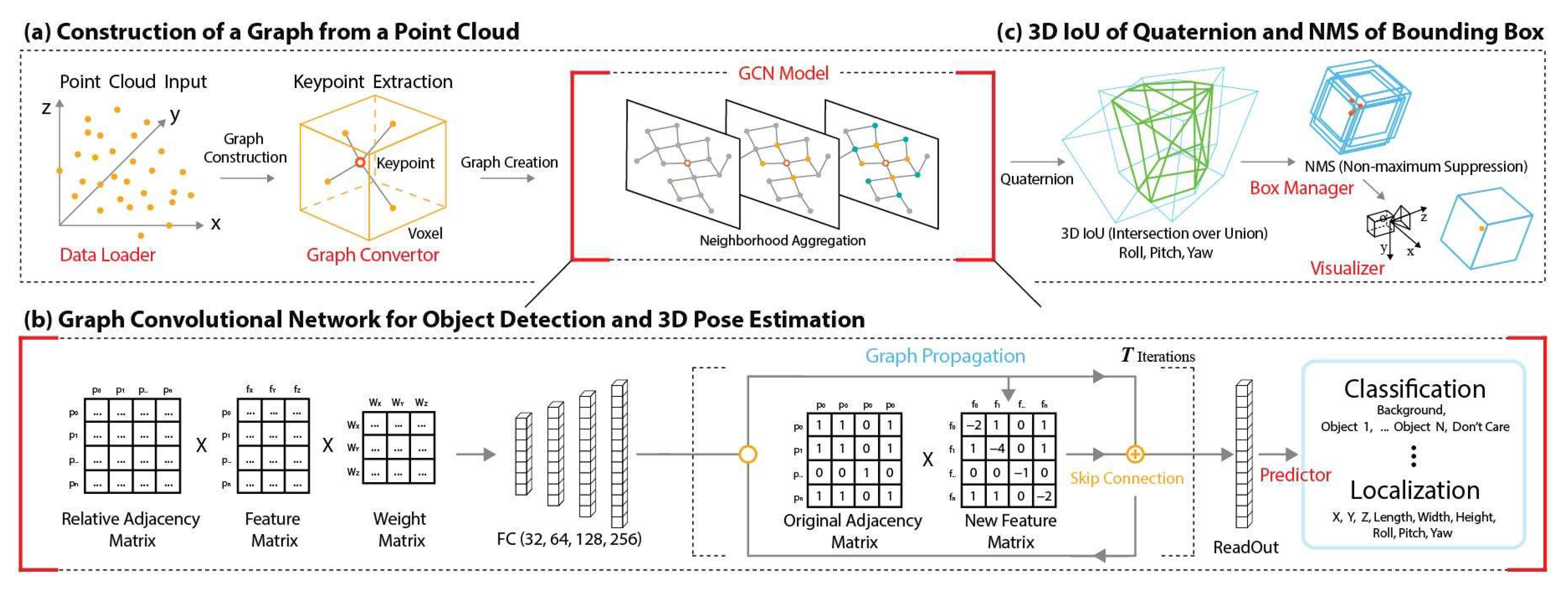
In this paper, we propose a 3D point cloud object detection and pose estimation method based on a graph convolution network and the keypoint attention mechanism to aggregate the features of neighboring points. The partial concept of our method is inspired by Point-GNN [
17]. The proposed method represents the point cloud as its graph, processes the structured adjacency matrix and feature matrix as inputs, and outputs the class, the bounding box, the size of the object, and the pose of the object. Their outputs are estimated, based on the vertices. All processes are dealt with in one-stage, while detecting multiple objects. Our method computes a rotated 3D IoU around all axes with nine DOF (three coordinates, three translations, and three rotations) for pose estimation in a 3D space. Additionally, to overcome the gimbal lock caused by Euler rotation in 3D space, we use the quaternion rotation. Our proposed method is evaluated on the RGB-D Dataset 7-Scene and demonstrates its potential in a 3D spatial processing domain using GCN.
The contributions of this study can be summarized as follows:
We propose a one-stage object detection and pose estimation approach using a graph convolutional network based on point cloud.
We design a point cloud-based graph convolutional network with a keypoint attention mechanism.
In the RGB-D Dataset 7-Scene, 3D objects are estimated with nine DOF, and rotation error is overcome to achieve comparable performance with state-of-the-art systems.
The remainder of this paper is organized as follows.
Section 2 provides a brief overview of the work, and
Section 3 details the system architecture and the proposed methodology.
Section 4 presents the experiments and performance evaluations.
Section 5 proceeds with an analysis of the obtained results, and
Section 6 summarizes the conclusions. The code is available at
github.com/onomcanbot/Pointcloud-GCN (accessed on 16 August 2022).
6. Conclusions
In this work, we proposed the GCN for object detection and pose estimation in irregular point clouds represented by graphs.
Our method consisted of an end-to-end approach to class prediction and a box prediction and pose estimation by spatially structuring the graph. By aggregating the point features of the point cloud and its neighbors, the graph structure was reused in every process to increase the efficiency of memory usage. By designing a GCN model for efficient feature encapsulation, we improved the speed by simplifying the learning and prediction layers compared with GNN-based systems. Accuracy was also improved by introducing a relative adjacency matrix to reflect the relative characteristics of relative coordinates between neighboring points. In addition, owing to the low memory usage, learning and prediction was possible, not only on the GPU, but also on the CPU. Accuracy similar to that of the latest competitive methods was achieved through various preprocessing algorithms and skip-connection techniques.
In a future study, to better reflect the original information when extracting keypoints through voxels, we will design a feature-impregnation layer for each voxel around the keypoints to achieve higher accuracy and represent regular inputs as graphs.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}