We proposed a bimodal extended Kalman filter-based pedestrian trajectory prediction model. This model adopts the bimodal extended Kalman filter, which is a special implementation of the Bayes filter. This filter is applied to encode the observed trajectories of the pedestrians and their surrounding obstacles into the state representation. After the state representation is encoded via the filter, the representation is then passed to the decoder to predict the future trajectories of the pedestrians.
2.2.2. State Representation
In our work, we choose the setting for the state so that it is able to represent the state information of that pedestrian in the specific frame. The state is a tuple that consists of two variables.
The first variable , named mode, is the discrete random variable describing the pedestrian’s moving mode. We consider the pedestrians has two moving modes, hence this variable is a binary variable. We define being the static mode, any pedestrian in this mode prefers to stay in the same location. On the other hand, we defined the mode as the moving mode, any pedestrian in such mode would prefer moving but not staying in the same location.
The second variable , named base state, is a 4-dimensional vector which contains the 2-dimensional position and 2-dimensional velocity of the pedestrian.
With such a setting, we are able to estimate the state and predict the trajectories in a mode-aware manner.
2.2.4. The Proposed Model
For the proposed prediction model, we first encode the trajectories into the belief state distribution, which is the state distribution built on top of the observed data. To calculate the state distributions for the pedestrians in the scene. We introduce the bimodal extended Kalman filter to help encode the observed trajectories into the state distributions. The algorithm is performed as follows.
Just like the extended Kalman filter [
22] is an implementation of the Bayes filter, the proposed bimodal extended Kalman filter is an implementation of the bimodal Bayes filter. We will first show the algorithm of the bimodal Bayes filter, as it provides the overview of the workflow for the bimodal extended Kalman filter. Then we will illustrate the algorithm of the bimodal extended Kalman filter.
The bimodal Bayes filter is a specialization of the Bayes filter in which the state consists of a binary mode variable and a continuous multi-dimensional variable. The estimated state is processed in two phases. For the first phase, the current state distribution is predicted based on the previous state distribution with the help of the state prediction model. In the case of the bimodal extended Kalman filter, there are three minor steps in the prediction phase. Firstly, the mode is being predicted with the mode transition model . Secondly, the base state for each mode is predicted via the mode-specific motion model . Finally, the predicted base states would be merged into the predicted mode-conditioned base state distribution. After the first phase is completed, the second phase is followed. The second phase is the correction phase, the predicted distribution would be corrected based on the observed data in this. In the correction phase, there are also three minor steps. Firstly, the likelihood function of the state is being computed based on the observed pedestrian position and the observation model . Then, the mode is corrected with the likelihood function via the Bayes rule. Finally, the predicted base state is corrected.
To estimate the state with the bimodal Bayes filter, one should provide the previous belief state distribution and the state observation, with a properly configured state transition model and observation model. The state-transition model takes the previous state as input and computes the current state. The state transition model contains two parts: one is the mode transition model and the other one is the base state transition model. The mode transition model represent the mode transition probability and is parameterized as . The base state transition model is a function that takes the previous base state and a standard normal noise vector as input and produces the current base state , and shows the base state transition from the previous mode m to the current . The transition process could be denoted as . The observation model models the observation process of the state. It takes the state s and the observation noise vector as input, and produces the observation vector as output. The observation process could be denoted as . The pseudo-code for this algorithm is shown in Algorithm 1.
As the bimodal extended Kalman filter is the implementation of the bimodal Bayes filter, the bimodal extended Kalman filter further assumes the base state is normally distributed and linearizes the base state transition model as well as the observation model to approximate posterior distribution, which is similar to how the extended Kalman filter [
22] extends the Kalman filter [
23]. The prediction phase and the correction phase are performed sequentially in the filtering algorithm. The pseudo-code for this algorithm is shown in Algorithm 2.
| Algorithm 1: Bimodal Bayes Filter. |
| Input: belief distribution of the previous state s |
| Output: belief distribution of the current state |
| // Prediction step |
| where |
| // Mode Prediction |
| |
| // Base State Prediction |
| |
| |
| |
| // Correction step |
| where |
| // Mode Correction |
| |
| |
| |
| // Base State Correction |
| |
| |
| return
|
To estimate the current state distribution of the algorithm, the belief distribution of the previous state is passed into the filter as the input, and it is followed by the prediction phase (Algorithm 2 line 1) and the correction phase (Algorithm 2 line 10), and finally the belief distribution of the current state is produced as the output.
In the prediction phase, the mode is predicted using the Bayes rule with the mode transition model
(Algorithm 2 lines 2 and 3). Then, the base state distribution
is predicted with the linearized base state transition model (Algorithm 2 lines 4–6). The Jacobian matrices
G and
E of the base state transition model
with respect to the base state
and the standard multivariate normal noise
are computed. These Jacobian matrices are used for computing the first-order approximation of the predicted state distribution. The predicted modal mean
is approximated by the application of the base state transition model
at the mean of previous base state
and the zero mean of the standard multivariate-normal noise. The predicted modal covariance
is computed as the sum of the transformed previous base state covariance
and the transformed noise covariance
. Finally, the predicted modal base state distributions are merged into the predicted base state distribution. As the mixture of two normal distributions may not distribute normally, the mixture normal distribution is merged approximately by preserving the mean and covariance of the mixture distribution. After the prediction phase is completed, the correction phase is followed (Algorithm 2 lines 8 and 9).
| Algorithm 2: Bimodal Extended Kalman Filter. |
| Input: belief distribution of the previous state s |
| Output: belief distribution of the current state |
| // Prediction step |
| where |
| // Mode Prediction |
| |
| |
| // Predict the base state for each mode |
| |
| |
| |
| |
| // Merge the base state |
| |
| |
| // Correction step |
| where |
| // Compute observation distribution |
| |
| |
| |
| |
| // Mode correction |
| |
| |
| // Base state correction |
| |
| |
| |
| return |
In the correction phase, the predicted distribution would be corrected based on the observed data . There are also three steps in this phase. First, the observation distribution of the state is computed based on the observed data and the linearized observation model (Algorithm 2 lines 11–14). The Jacobin matrices D and H of the observation with respect to the base state and the standard multivariate normal noise are computed. The mean is approximated by the application of the observation model at the mean of the predicted base state and the zero mean of the standard multivariate-normal noise. The covariance is computed as the sum of the transformed predicted base state covariance and the transformed noise covariance . Then, the mode is corrected via the Bayes rule (Algorithm 2 lines 15–16). Finally, the Kalman gain K is computed and the predicted base state distribution is corrected with the Kalman gain (Algorithm 2 lines 17–19).
In our setting, the base state represents the pedestrian’s position and velocity , the mode m to represent the static and the moving mode pedestrian, and the observation represents the position of the pedestrian. The required models for the bimodal extended Kalman filter are specified as follows:
- 1.
For the observation model, it is parameterized with the standard deviation
of the observation noise.
- 2.
For the mode transition model, it is defined as:
- 3.
For the base state transition model, we apply different motion-model according to the mode. When current mode
is in static mode, we model the motion as constant position model. On the other hand, when current mode
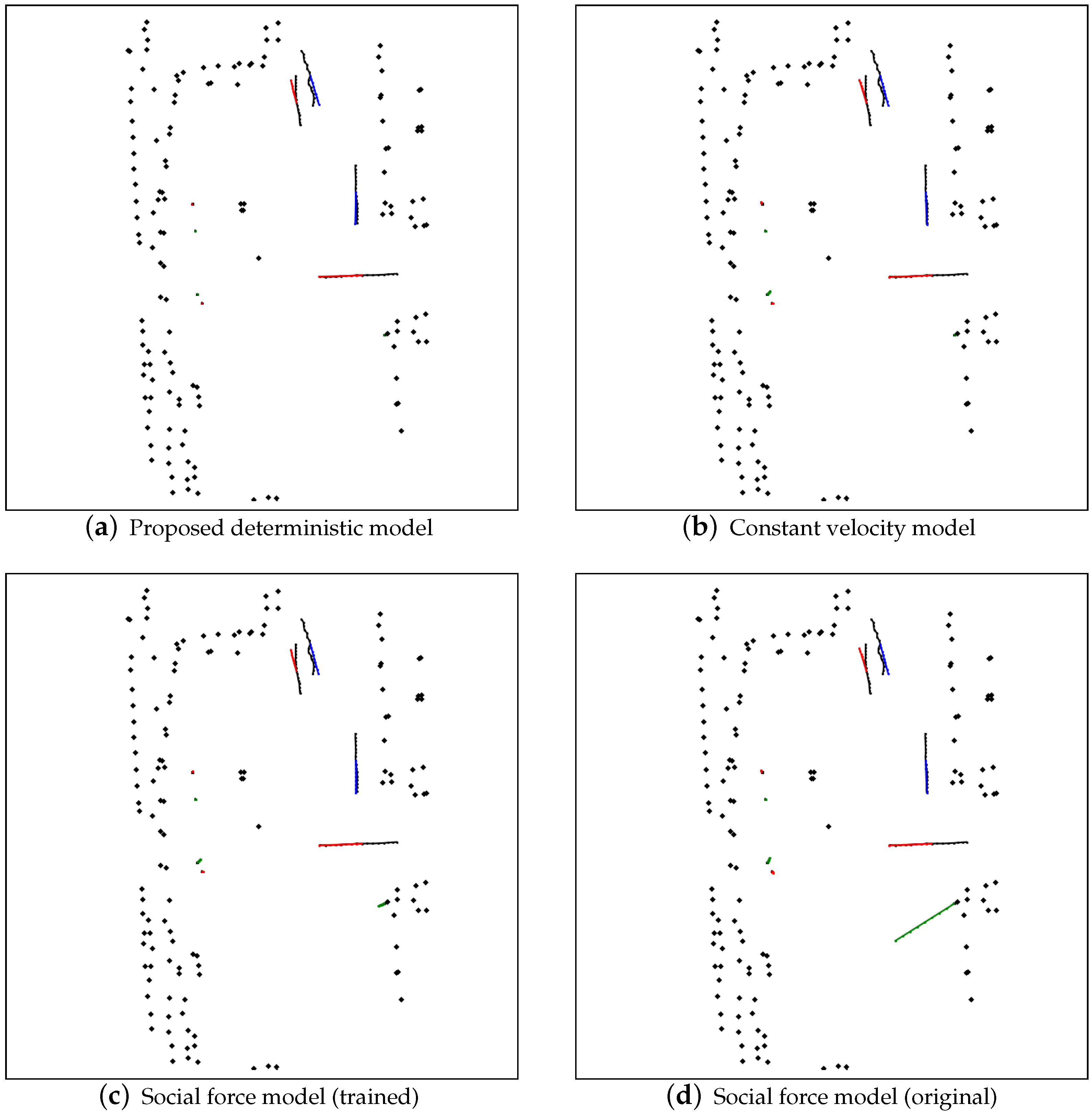
is in moving mode, we apply the social force model [
11] as the motion model. For both scenario, an extra noise is added to the velocity term to model the uncertainty of the pedestrian’s plan. The model is defined as follows.
In the encoding step, we adopt the bimodal extended Kalman filter to estimate the current state distribution of every pedestrian. We take the observed pedestrian position sequence as the input data, and estimate the state distribution frame by frame recursively. For each frame, the filter takes the observed position and the previous state distribution, and estimates the current state distribution accordingly. Through the steps, the current state distribution is computed, which contains the parameterized variables representing the mode distribution and the base state distribution.
After the current state distribution is estimated, the decoding phase is then applied to the distribution to generate the predicted pedestrian future trajectories. To decode and predict the future trajectory of the pedestrians. First, states are sampled from the computed state distributions. The sampled state is taken as the initial input. The input then goes into the state transition models and predicts the state. Then, the state is generated recursively via the state transition model by taking the previous state as the input, until the required prediction sequence length is reached. To reduce the prediction variance, the velocity noise is applied to the only states for the output predicted trajectories.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}