1. Introduction
Many of the countries in the world are experiencing growth in terms of the proportion of older adults in the population. In 2020, there were 727 million people aged 65 years or over, and it is projected that the number of older adults will double to 1.5 billion in 2050 [
1], representing the fastest growing segment of the world’s population. Enabling people to age independently in their own homes is clearly necessary both for their wellbeing and to avoid a caregiver crisis.
Advances in pervasive computing and wireless sensor networks have resulted in the development of monitoring systems such as smart homes. A variety of unobtrusive sensors such as binary and motion sensors are installed in a smart home to collect information about the inhabitant. These sensors, which record the inhabitant’s interactions within the home (e.g., turning on the light, opening the bathroom door) are used to infer the inhabitant’s daily activities (e.g., showering and cooking). Significant deviations from normality are then detected as potentially risky behaviours, and a query issued.
Many activity recognition systems based on supervised learning have been proposed [
2,
3,
4,
5,
6]. These systems learn from a set of training data where the activities are labelled a priori, and assume that the inhabitant’s activities remained constant over time. However, human behaviours are rarely so consistent; for example, changes in season may affect sleeping patterns and mealtimes. Systems that do cater for such variability will misclassify the changed patterns, which hinders their utilisation in real homes.
For a smart home to support its inhabitant, the recognition system should not only recognise their activities, but continuously learn and adapt to the inhabitant’s ongoing changing behaviours. The application of novelty detection in learning systems is one of the commonly used methods where the system uses the trained model to learn about inputs that it has never seen before. Some works have attempted to extend novelty detection to learn incrementally by retraining when a previously unseen activity is detected [
7,
8,
9]. However, this is a significant computational overhead, and may allow the catastrophic forgetting of old behaviours, where the performance of the previously learned activities significantly decreases as new activities are learned.
The central problem that this paper aims to address is how to identify unseen new activities that were not present in the training data and then learn about recurring new activities without forgetting previously learned ones. Our approach to this problem is to first train a base model using an adaptive lossless compression scheme based on the prediction by partial matching (PPM) method by exploiting the repetition in the sensor stream, which represents the inhabitant’s activities. This base model is then used to guide the learning of new activities.
The remainder of this paper is organised as follows:
Section 2 discusses the related work.
Section 3 provides a description of the method used.
Section 4 presents our proposed method.
Section 5 describes the benchmark datasets used in this study.
Section 6 details the experiments and evaluation method. The results and findings are discussed in
Section 7.
Section 8 provides a summary of our work.
2. Related Work
Novelty detection often requires a machine learning system to act as a ‘detector’, which identifies whether an input is part of the data that a machine learning system was trained on. This will result in some form of novelty score, which is then compared with a decision threshold, where new unseen inputs are classified as novel if the threshold is exceeded. Novelty detection has gained much research attention, especially in diagnostic and monitoring systems [
10,
11,
12]. An overview of the existing approaches is provided in [
13].
There are works that use the one-class classification approach for novelty detection. In this approach, the classifier is trained with only the normal data, which are then used to predict new data as either normal or outliers [
14]. In the work of [
15], they extracted nonlinear features from vibration signals and used these features to detect novelty. This method, however, requires an extensive preprocessing step for feature extraction. Rather than applying one-class classification on preprocessed data, Perera and Patel [
16] used an external multi-class dataset for feature learning based on a one-class convolutional neural network. Although this method bypasses the data preprocessing step, the performance of such a system is highly dependent on the hyperparameter selection and a large quantity of training data.
Another approach to novelty detection is to use an ensemble [
17]. A normality score is computed from the consensus votes obtained from the ensemble models, and a threshold value is dynamically determined based on the distribution of the normality score from each ensemble model in order to identify novelty. This approach, however, does not learn incrementally, nor does it adapt to new activities. In the work of [
7], they extended the ensemble approach to allow activities to be learned incrementally. When a new activity is detected, a new base model is trained and is added to a set of previously trained base models. One of the problems with this approach is the increase in the ensemble size when more activities are learned, which can significantly affect the performance of previously learned activities.
To avoid overwriting previously learned activities, Ye and Callus [
18] proposed using a neural network to iteratively learn new activities by reusing the information from a previous trained network to train a new network. A gradient-based memory approach is applied to control the update of the model parameters. Although this method is able to maintain the knowledge of previous activities, it is memory-intensive.
A recent method was proposed by [
19] for novelty detection. In this method, they first compressed the sensor stream to identify repeated patterns that represent activities. A new activity was identified by monitoring the changes in the frequency distribution. Since patterns have to be repeated frequently in order to generate significant changes in the frequency distributions, this method takes more time to learn a new pattern. A similar work was seen in [
20], where they combined the Markov model and prediction by partial matching for route prediction. New routes were detected by measuring the similarity between the original route and predicted route that the user is likely to traverse. The similarity is measured in terms of the rate of compression, which is computed from the partial matching trees and Markov transition probabilities. Although this method is able to predict new routes, it needs prior knowledge of user destinations.
3. Prediction by Partial Matching (PPM)
Prediction by partial matching (PPM) is an adaptive statistical data compression technique that uses the last few symbols to predict the next symbol in the input sequence [
21]. PPM adaptively builds several
k context models, where
k refers to the number of preceding symbols used.
Following the approach taken in [
22], the PPM is built based on each activity sequence,
S, which is represented as a triplet of ASCII characters identifying the time when the activity is performed, the location, and the type of activity:
. Given the input string ‘
activeactionick’, let
,
,
,
, and
. The PPM is trained on each sequence of
rather than on the entire input string.
Table 1 shows the results of three context models with
, and 0 after the input string ‘
activeactionick’ has been processed.
With this, the highest context model () predicts the user’s activity given the time and location (i.e., )), while the model predicts: (1) the user’s location given the time of the day () and (2) their activity given the location ().
When the PPM model is queried, the model starts with the largest k (here, 2). When the string ‘io’ is seen, the likely next symbol is n, with a probability of 0.5. If a new symbol is observed in this context, then an escape (‘esc’) event is triggered, which indicates a switch to a lower-order model. This process is repeated until the context is matched or the lowest model () is reached. The lowest model predicts all symbols equally with , where A is the set of distinct symbols used.
4. Proposed Method
The first aim of this paper is to detect novel activities, i.e., activities that were not present during the training of the PPM model. We achieve this by calculating a novelty score that measures how similar the new input is to the learned activities. This novelty score can be computed in terms of compression factor (
CF), defined as in [
23]:
The higher the factor, the better the compression, i.e., the more similar the novel input is to the learned activities. To calculate the size of the compressed dataset, our method leverages the esc event in the PPM model. The rationale behind this approach is that if an input string contains context similar to the PPM model, the compression process will rarely activate the esc event, resulting in a higher CF. However, if the input string differs greatly from the PPM model, the esc event will be triggered more frequently, resulting in a lower CF.
If the input string ‘act’ has been seen frequently in the past, then it is likely to recur identically in the future. However, if there are variations in the input string (suggesting variations in the activities), the next occurrence will be followed by different symbols, e.g., ‘ack’ or ‘ict’. This will trigger the PPM model to switch to a lower model. To determine the size of the compressed and uncompressed data, we calculate the entropy, in units of bits, from the probabilities obtained from the PPM model.
Section 4.1 provides further examples of how
CF is calculated to detect novel activities.
One of the challenges in detecting novel activities is that the input pattern could be an entirely new activity that has not been seen before, or it could be just noise in the data. For this, a threshold is applied to quantify the novelty. Novelty is detected when the
CF value is above the threshold.
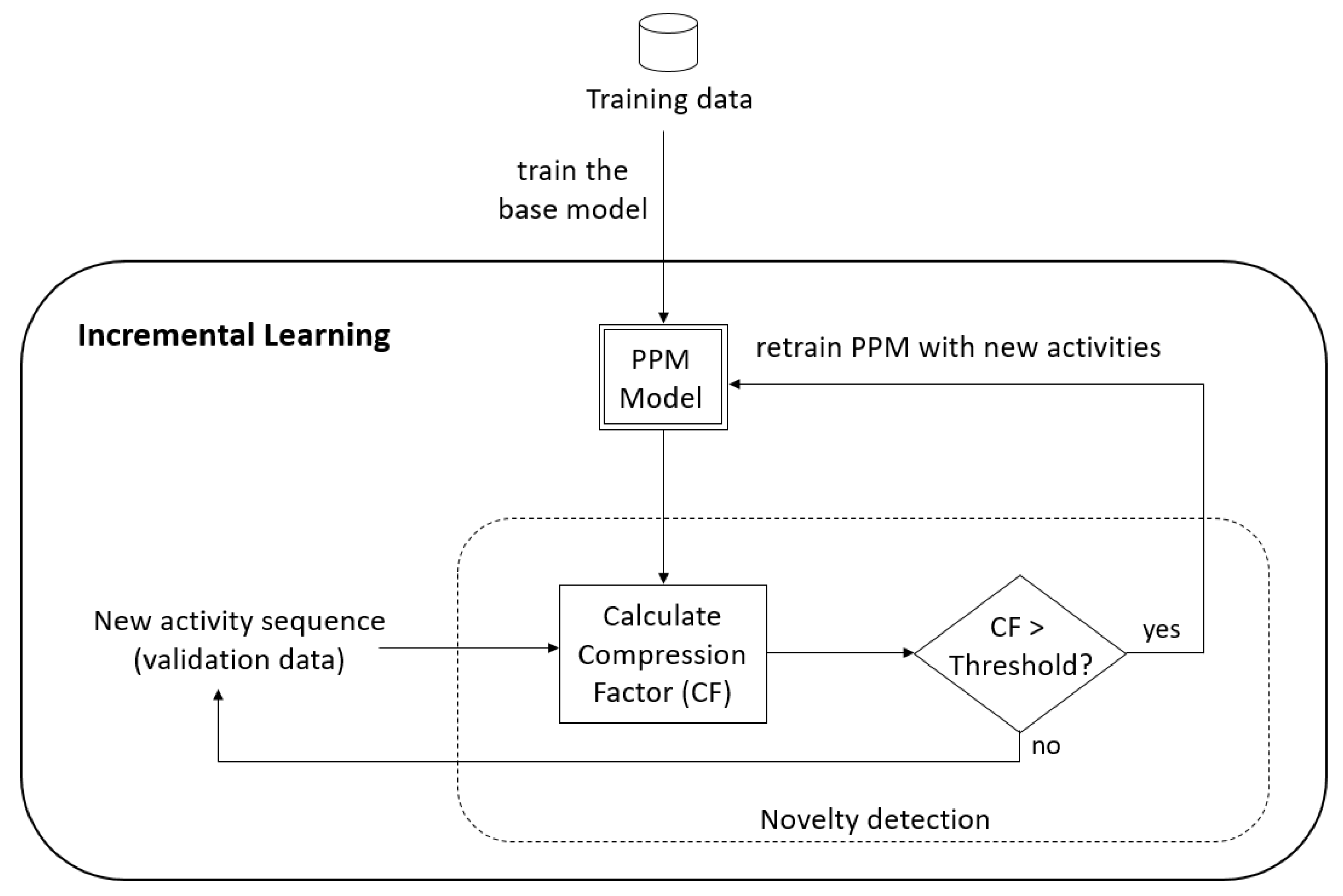
Figure 1 summarises the overall procedure of the proposed method. Algorithm 1 shows the steps of detecting new activities.
| Algorithm 1 Novelty Detection based on Prediction by Partial Matching (PPM) |
Input: base PPM model trained on training set
Input: activity sequence on validation set
Initialise:
Initialise: threshold value
for
do
Using Equation (1), calculate compression factor
if then
end if
end for
Retrain P with N |
4.1. Detecting Unseen New Activities
Suppose that the PPM model shown in
Table 1 is trained from the following input data:
(8 a.m., Kitchen, Preparing Meal)
(9.30 a.m., Bathroom, Bathing)
(9.30 a.m., Bedroom, Dressing)
(9.30 a.m., Kitchen, Washing Dishes)
Once the PPM is trained from the input string ‘
’, this base PPM model is used for novelty detection. Given that there are nine distinct characters, the entropy of the uncompressed data is
bits.
Figure 2 illustrates how
CF is computed based on four different scenarios. The size of the compressed data is computed based on the PPM model shown in
Table 1. If the novelty threshold is 2.0, novelty is detected for the scenarios shown in
Figure 2a–c since the
CF value is above the threshold in those instances.
In the figure, (a) shows an example where a different activity was seen at a similar time and location in the past (i.e., ‘washing dishes’ instead of ‘preparing meal’). When the input string
is detected, the
model is first queried for
. Since the string ‘
ac’ is seen in the
model, meaning that the prediction of
will be in the
model, the
esc event is triggered to switch to the
model. Both strings ‘
ac’ and ‘
ck’ are queried and the size of the compressed data is computed as
bits. Using Equation (
1), the
CF for the input string
is
. Since the
CF is above the threshold, novelty is detected.
(b) shows an example where a similar location and activity were seen in the past but at a different time. Since the input string is not seen in the model, the esc event is triggered to switch to the model. The string ‘ve’ is seen ()), but not ‘av’. An esc event is triggered to switch to by taking . The size of the compressed data for the input string is , with CF . Novelty is detected for this input string since the CF is above the threshold.
For the input string in (c), the string ‘on’ is seen ()) in , but not ‘so’. This will trigger the esc event to switch to . Since the string ‘s’ is a new time and has not been seen before, we take to calculate the size of the compressed data (). The CF for this input string is approximately 3.94 and novelty is detected.
(d) shows an example where a similar activity at a similar time was seen in the past, but the activity was performed in a different location. For the input string , the string ‘ic’ is seen in (). Since the string ‘cn’ is not seen, an esc event is triggered by taking . The CF for this input is approximately 1.33, which is below the threshold and therefore no novelty is detected.
5. Data Source
We tested our approach on three publicly available smart home datasets, which we summarise in
Table 2. In each of these datasets, the home inhabitant noted their activities, providing ground truth annotations.
6. Experiments and Evaluation Method
We evaluated the recognition performance and time required to train the PPM in comparison with other approaches, and also tested the effect of the size of the training dataset on recognition performance. We partitioned the data into training, validation, and testing sets according to the splits shown in
Table 3, using 6-fold cross-validation.
Our approach (labelled Model 2) uses the validation set to perform novelty detection. As a comparison, we included a model that does not use the validation data at all (Model 1) and another that is trained on both the training and validation sets following the approach taken in [
22]. Both Model 1 and Model 3 are learned from a predefined set of activities and are used as the baseline models.
Figure 3 shows the implementation of the three models based on the respective training–validation sets.
To evaluate the effectiveness of our method, three evaluations were carried out. The first evaluates the recognition performance in terms of predicting the user’s location given the time of the day ( ). The second evaluates the recognition performance in terms of predicting the user’s activity given the location (). The first two evaluations use the context model for prediction. The third evaluates the recognition performance in terms of predicting the user’s activity given location and time (). This evaluation used the context model for prediction.
We also determined the effect of the training dataset size on the base PPM model and the model’s capability for incremental learning by reducing the training and validation sets to 5 days each for the Aruba and van Kasteren datasets, and 3 days each for the MIT PlaceLab dataset. All of the remaining data (48 days for Aruba, 10 for MIT PlaceLab, and 14 for van Kasteren) were used for testing. For this evaluation, 8-fold cross-validation was used.
Finally, we measured the time required to train the PPM using Matlab on a desktop computer with an Intel(R) Core(TM) CPU i7-7700K @ 4.2 GHz and 64 GB memory.
7. Results and Discussion
Table 4 shows the recognition performance of
and
predictions. The recognition performance of
prediction is shown in
Table 5. In comparison with baseline Model 1, our method (Model 2) achieved a higher performance for
(Aruba: 91.41%, MIT PlaceLab: 87.57%, van Kasteren: 80.82%),
(Aruba: 98.73%, MIT: 98.69%, van Kasteren: 99.87%), and
(Aruba: 88.02%, MIT: 73.87%, van Kasteren: 79.21%) across all of the datasets. The results show that our method is able to incrementally learn new activities and can improve the recognition performance of the baseline model when trained on the same amount of data.
However, when compared with Model 3, we can see that the amount of data matters: our model has a lower, but comparable, performance. However, using Model 3 requires twice as much waiting for activities to appear and be learnt from the data (a time frame of 30 days vs. 15 days). By using our method, we can deploy a baseline model for activity recognition (Model 1), and improve the recognition performance by allowing it to learn new activities when new data are available. This result suggests that a general PPM model can be used as a base model in various smart homes and the recognition performance of this base model can be improved by using our method.
Figure 4 shows the results of the three models trained on different training–validation–test splits. In terms of the size of the training dataset, when trained on a smaller training set, Model 1 suffers across all three datasets for
and
, with a performance as low as 44.41%. Model 2 shows an increment of more than 10% across all of the datasets for
and
when compared with Model 1. In terms of the
prediction, Model 1 has a slightly lower performance compared with when it is trained with a larger dataset. However, we can still see that Model 2 shows improvement in the recognition performance. A lower recognition performance was observed for
compared with
across all three datasets. This was due to the variations in the time at which the user performed the activities. These variations were not repeated frequently enough for the base PPM to learn the representations. Compression tends to be more effective when patterns are repeated frequently. When trained on a smaller training set, the performances of Models 2 and 3 are comparable across all three datasets. These results show that the ability of our method to carry out incremental learning is not affected by the training size. Our method allows the algorithm to continuously learn in order to improve the recognition performance of the base model, even if the base model is trained with a very small training set.
Table 6 shows the amount of time (in minutes) it took to train the PPM for each model. The values in parentheses show the number of activity instances in each training set. As can be seen from
Table 6, the training time grows with the number of activity instances. When comparing all three models, Model 3 has the longest training time since it trains on a larger number of activity instances. Model 2, even though it includes the time to retrain the PPM when new activities are detected, has a slightly shorter training time than Model 3. Although the time difference is not significant, Model 2 allows new activities to be incrementally learned when new data are available.
In this study, the threshold used to quantify the novelty was chosen to be 2.0 based on preliminary experiments. However, the threshold could be determined dynamically from the probability distribution of the data. Methods that could potentially be applied include internal and external voting consensus schemes [
17].
We also plan to extend our work to monitor potential abnormality. The challenge lies not in the activity itself, but rather when and where the activity actually takes place. We can further extend the use of
CF score to determine the abnormal activity (as shown in
Figure 2d). Our work is currently applied in a batch manner, but can be extended for online learning. Once new activity is detected, the probabilities in the PPM model can be updated directly instead of retraining the entire PPM model.
8. Conclusions
The majority of previous studies on activity recognition consider learning in a fixed environment, where the living environment and activities performed remain constant. However, variability is normal; both human activities and the environment can change over time. In this paper, we proposed a method based on prediction by partial matching that has the ability to continuously learn and adapt to changes in a user’s activity patterns. The main advantage of our approach is that new activities can be incrementally learned in an unsupervised manner. Experiments were performed on three distinct smart home datasets. The results demonstrate that our method works effectively to identify new activities, while retaining previously learned activities.
Author Contributions
Conceptualization and methodology, S.-L.C., L.K.F., H.W.G. and S.M.; literature review, S.-L.C.; experiments and data analysis, S.-L.C. and L.K.F.; writing—original draft preparation, S.-L.C. and L.K.F.; writing—review and editing, H.W.G., S.M. and S.-L.C.; funding acquisition, S.-L.C. and L.K.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Education (MOE), Malaysia, under the Fundamental Research Grant Scheme (No. FRGS/1/2021/ICT02/MMU/02/2).
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- United Nations. World Population Ageing 2019; Department of Economic and Social Affairs, Population Division: New York, NY, USA, 2020. [Google Scholar]
- Hamad, R.A.; Hidalgo, A.S.; Bouguelia, M.-R.; Estevez, M.E.; Quero, J.M. Efficient activity recognition in smart homes Using delayed fuzzy temporal windows on binary sensors. IEEE J. Biomed. Health Inform. 2020, 24, 387–395. [Google Scholar] [CrossRef] [PubMed]
- Viard, K.; Fanti, M.P.; Faraut, G.; Lesage, J.-J. Human activity discovery and recognition using probabilistic finite-state automata. IEEE Trans. Autom. Sci. Eng. 2020, 17, 2085–2096. [Google Scholar] [CrossRef]
- Chua, S.-L.; Marsland, S.; Guesgen, H.W. A supervised learning approach for behaviour recognition in smart homes. J. Ambient Intell. Smart Environ. 2016, 8, 259–271. [Google Scholar] [CrossRef]
- Du, Y.; Lim, Y.; Tan, Y. A novel human activity recognition and prediction in smart home based on interaction. Sensors 2019, 19, 4474. [Google Scholar] [CrossRef] [Green Version]
- Thapa, K.; Abdullah Al, Z.M.; Lamichhane, B.; Yang, S.-H. A deep machine learning method for concurrent and interleaved human activity recognition. Sensors 2020, 20, 5770. [Google Scholar] [CrossRef]
- Siirtola, P.; Röning, J. Incremental learning to personalize human activity recognition models: The importance of human AI collaboration. Sensors 2019, 19, 5151. [Google Scholar] [CrossRef] [Green Version]
- Bayram, B.; İnce, G. An incremental class-learning approach with acoustic novelty detection for acoustic event recognition. Sensors 2021, 21, 6622. [Google Scholar] [CrossRef]
- Nawal, Y.; Oussalah, M.; Fergani, B.; Fleury, A. New incremental SVM algorithms for human activity recognition in smart homes. J. Ambient Intell. Humaniz. Comput. 2022, 28, 5450–5463. [Google Scholar] [CrossRef]
- Calabrese, F.; Regattieri, A.; Bortolini, M.; Galizia, F.G.; Visentini, L. Feature-based multi-class classification and novelty detection for fault diagnosis of industrial machinery. Appl. Sci. 2021, 11, 9580. [Google Scholar] [CrossRef]
- Del Buono, F.; Calabrese, F.; Baraldi, A.; Paganelli, M.; Guerra, F. Novelty detection with autoencoders for system health monitoring in industrial environments. Appl. Sci. 2022, 12, 4931. [Google Scholar] [CrossRef]
- Carino, J.A.; Delgado-Prieto, M.; Iglesias, J.A.; Sanchis, A.; Zurita, D.; Millan, M.; Ortega, R.; Juan, A.; Romero-Troncoso, R. Fault detection and identification methodology under an incremental learning framework applied to industrial machinery. IEEE Access 2018, 6, 49755–49766. [Google Scholar] [CrossRef]
- Pimentel, M.A.F.; Clifton, D.A.; Clifton, L.; Tarassenk, L. A review of novelty detection. Signal Process. 2014, 99, 215–249. [Google Scholar] [CrossRef]
- Seliya, N.; Abdollah Zadeh, A.; Khoshgoftaar, T.M. A literature review on one-class classification and its potential applications in big data. J. Big Data 2021, 8, 122. [Google Scholar] [CrossRef]
- Sadooghi, M.; Khadem, S. Improving one class support vector machine novelty detection scheme using nonlinear features. Pattern Recognit. 2018, 83, 14–33. [Google Scholar] [CrossRef]
- Perera, P.; Patel, V.M. Learning deep features for one-class classification. IEEE Trans. Image Process. 2019, 28, 5450–5463. [Google Scholar] [CrossRef] [Green Version]
- Yahaya, S.W.; Lotfi, A.; Mahmud, M. A consensus novelty detection ensemble approach for anomaly detection in activities of daily living. Appl. Soft Comput. 2019, 83, 105613. [Google Scholar] [CrossRef]
- Ye, J.; Callus, E. Evolving models for incrementally learning emerging activities. J. Ambient Intell. Smart. Environ. 2020, 12, 313–325. [Google Scholar] [CrossRef]
- Lima, W.S.; Bragança, H.L.S.; Souto, E.J.P. NOHAR—Novelty discrete data stream for human activity recognition based on smartphones with inertial sensors. Expert Syst. Appl. 2021, 16, 114093. [Google Scholar] [CrossRef]
- Neto, F.D.N.; Baptista, C.S.; Campelo, C.E.C. Combining Markov model and Prediction by Partial Matching compression technique for route and destination prediction. Knowl.-Based Syst. 2018, 154, 81–92. [Google Scholar] [CrossRef]
- Cleary, J.G.; Witten, I.H. Data compression using adaptive coding and partial string matching. IEEE Trans. Commun. 1984, 32, 396–402. [Google Scholar] [CrossRef]
- Chua, S.-L.; Foo, L.K.; Guesgen, H.W. Predicting activities of daily living with spatio-temporal information. Future Internet 2020, 12, 214. [Google Scholar] [CrossRef]
- Solomon, D. Data Compression: The Complete Reference, 3rd ed.; Springer: New York, NY, USA, 2004; pp. 10–14. [Google Scholar]
- Cook, D.J. Learning setting-generalized activity models for smart spaces. IEEE Intell. Syst. 2012, 27, 32–38. [Google Scholar] [CrossRef] [PubMed]
- Tapia, E.M.; Intille, S.S.; Larson, K. Activity recognition in the home using simple and ubiquitous sensors. In Proceedings of the 2nd International Conference on Pervasive, Vienna, Austria, 21–23 April 2004; pp. 158–175. [Google Scholar]
- van Kasteren, T.; Noulas, A.; Englebienne, G.; Kröse, B. Accurate activity recognition in a home setting. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Korea, 21–24 September 2008; pp. 1–9. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}
{kind=link}