1. Introduction
Image-to-image (I2I) translation aims to transfer an image from one domain to another while preserving the content of the given image. For example, we can take the famous horse to zebra translation, where the aim is to translate a horse image into a zebra image. The domains of zebra and horse images differ by some of characteristics given by the two sets of images (for example, zebras have stripes, and horses have bigger tails than zebras.)
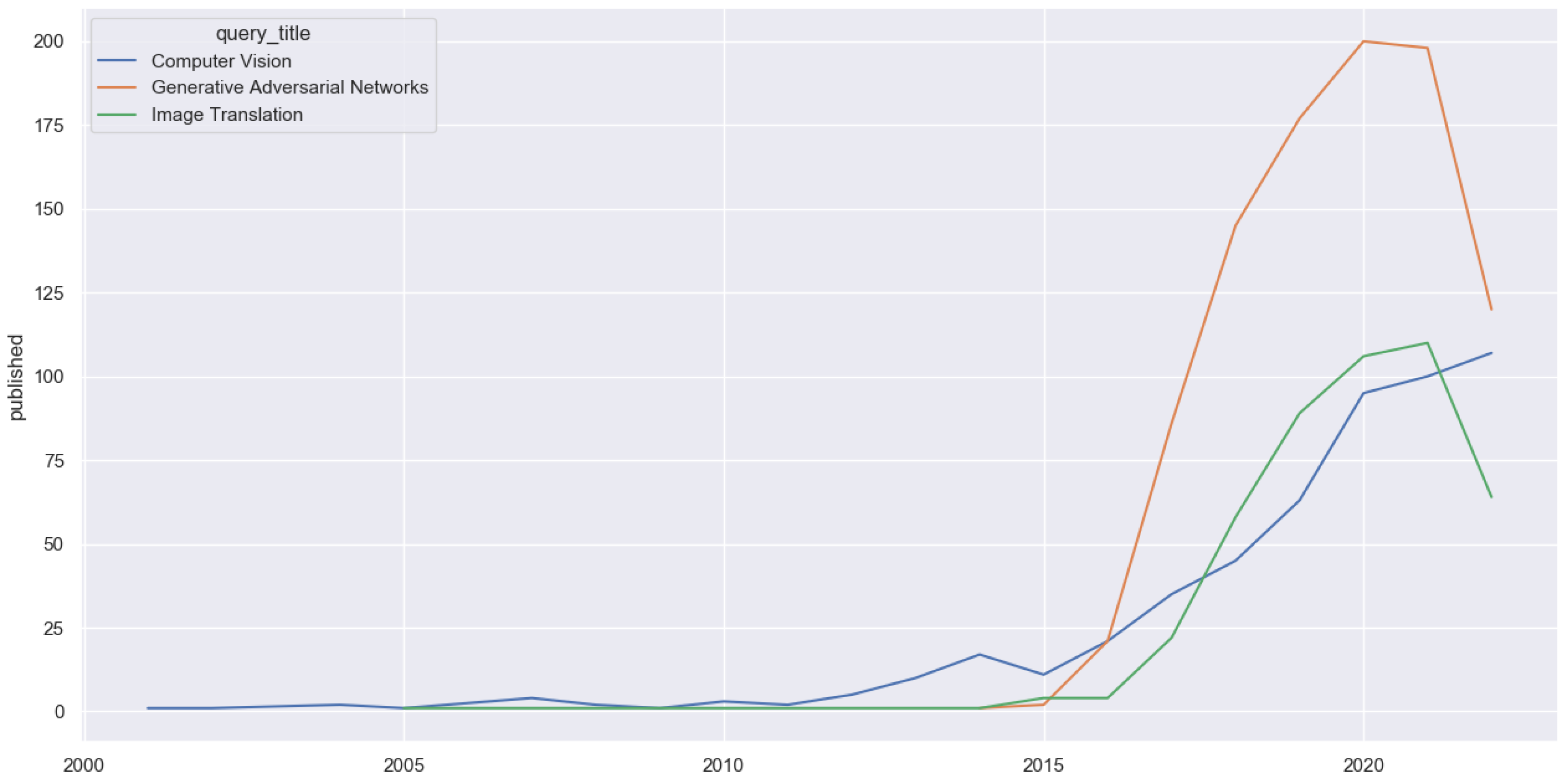
As shown in
Figure 1, the number of publications in image translation increased when generative adversarial networks (GANs) were proposed. In 2016 Isola et al. presented Pix2Pix [
1], a conditional model that is able to translate an image from one domain to another using paired training. This work was followed by Pix2PixHD [
2], which was translation of high-resolution images. However, even though these methods performed well when they were significant advances over the state-of-the-art, one major problem of these paired image-to-image translation methods is the paired dataset, a dataset where an image already has its translated counterpart. These paired datasets are hard, expensive or even impossible to obtain due to the parity constraint between the input and output.
Consequently, the research community has explored approaches to overcoming the need for paired datasets. For example, Bousmalis et al. [
3] tried an unsupervised image-to-image translation method with a domain adaptation on the pixel space. With a more probabilistic point of view, Liu et al. [
4] proposed an image translation method based on the shared latent space assumption. In the same way, Taigman et al. [
5] proposed another architecture composed of a GAN and an input function
f. The GAN is trained to generate wanted images and
f converts an image to a latent representation, which is used by the GAN for the generation.
In 2017, Zhu et al. introduced CycleGAN [
6], a network able to translate an image from one domain to another using cycle consistency. Nevertheless, despite this method breaking the paired constraint, it requires a lot of training iterations and suffers from instability. Since then, many applications have emerged (e.g., semantic to real [
1,
6,
7], maps to satellites [
1,
8] and satellites to street view [
9]).
There remain challenges, the most prominent being:
Complex Translations: Translations that need heavy modifications to match the target space, such as geometrical transformations; or diverse images, such as those of landscapes.
Effective Training: In the context of unsupervised translation, cycle consistency is often used. However, it can be too restrictive in some cases, such as glass removal tasks [
10]. This case forces the model to hide information in the translation in order to allow the backward translation to satisfy the cycle consistency [
11]. Since that time, some implementations try to do without cycle consistency by proposing alternative losses. On the other hand, other approaches try to propose new discriminator architectures to stabilize the training.
Data Scarcity: Sometimes data are missing or are particularly difficult to collect. Some works have tried to reduce the data requirements of translation models by augmentation methods or directly with architecture changes.
This paper is aims to give an overview of principal works on unsupervised image-to-image translation (UI2IT), along with the current challenges and limitations. To accomplish these ends, this review is organized as follows: In the first place, we detail the general process of UI2IT. Secondly, we give an overview of datasets and metrics used for UI2IT, followed by the classification of methods. Thereafter, the main parts of this review are presented, namely, architecture changes, complex translation, data issues, attribute editing, guidance, disentanglement learning and contrastive learning methods. A short discussion about method comparison and current challenges is presented afterward, followed by the conclusions of the article.
2. Problem Description
Image-to-image translation aims to convert an image
from a source domain
into an image
in a target domain
while preserving the content of
, and vice versa. More formally, it consists of two functions,
F and
G:
where
and
are learnable parameters. For example, in the horse to zebra translation task,
F translates a horse photo to a zebra photo, and
G does the reverse. From the deep learning point of view,
F and
G are generators and are trained against two models called discriminators, which aim to discriminate real images from generated images. As generators and discriminators are competing against each other, this training technique is defined as “adversarial training”.
In the early stage of I2I translation, the translation task consists of texture transformations, such as horse ↔ zebra, or season transfer. Nowadays, with the evolution of translation methods, the “content” and “style” significance have changed. The “content” features are more related to specificities we want to preserve during the translation, as opposed to “style”, which defines features we need to change.
Losses
Since we know which models are involved in I2I translation, we will briefly go over the learning objective of unsupervised image-to-image translation. We define as the generator, which translates an image from the domain to and vice versa. We also define and as the discriminators.
Adversarial Loss: The adversarial loss [
12]
symbolizes the adversarial interaction between generators and discriminators. For example,
tries to make a translation of
that resembles an image in the
domain and
tries to make the distinction between real samples
and translated samples
.
Cycle Consistency Loss: The cycle consistency loss was introduced by Zhu et al. in the CycleGAN paper [
6]. After describing that a given translation from
may not preserve all the characteristics of an image in
X, since there is an infinite number of mappings between
, the authors claimed that translation should be cycle-consistent. Therefore, for an image
from
:
and vice versa. This loss facilitated the use of an unpaired dataset but encouraged the generators to pass unnecessary information during the translation, thereby degrading performances [
11].
Identity Loss: To further encourage the mapping that conserves the source image features, Taigman et al. [
5] introduced a regularization term to restrict generator translations. This loss minimizes
, forcing the generator to translate relevant features (e.g., shapes and borders).
Full Objective: Finally, the full objective function can be formulated as the weighted sum of all previously listed losses, where , and denote parameters which control the relative importance levels of the adversarial loss, the cycle consistency loss and the identity loss, respectively. When these models are correctly trained and stabilized, the generator produces good results and the discriminator’s predictions are nearly random.
4. Classification of Image Translation Method
As this literature review is meant to give the reader a comprehensive understanding of the actual I2I translation field, we classified papers based on their main contributions. The categories follow:
Architecture Change: Due to the aforementioned challenges and new module propositions, some works exploit contributions coming from other fields [
51,
52]. Nevertheless, some proposals made changes specific to I2I translation [
53].
Complex Translation: In recent years, there has been a research interest in particularly difficult translations. This category introduces recent works that aim to bridge between highly different domains.
Data Issues: Generation models usually need a lot of data. However, in some cases, the data cannot be available in sufficient quantity. This part summarizes recent attempts to alleviate the data dependency.
Attribute Editing: Instead of translating the entire image, some works pay more attention to local feature modifications. In this part, we talk about works that force the model to translate specific features.
Guidance: This part talks about the different ways to guide the translation models.
Disentanglement Learning: Methods are based on the assumption that an image can be divided into specific sub-spaces. These sub-spaces can be used in order to translate an image with a particular content to a given style.
Contrastive learning methods: Contrastive learning is a self-supervised learning approach. In I2I translation, these methods try to solve inherent problems of cycle consistency. This subpart will describe general contrastive learning methods and summarize the current state-of-the-art in this sub-field.
5. Architecture Changes
Since the release of CycleGAN in 2017, some architectural changes have been released to alleviate some drawbacks of previous UI2IT methods. For example, Choi et al. [
13] pointed out the deterministic behavior of CycleGAN. They hence proposed an architecture called StarGAN composed of two elements, the former being a generator that translates an image conditioned by the target domain vector, and the latter a multi-task discriminator. This architecture has further been improved with StarGANv2 [
54], which introduces a new paradigm with three networks: a style encoder, a generator, and a multi-task discriminator.
Nowadays, in the era where smartphones are among the most used devices, researchers aim to develop faster, lightweight models, as in the case of the work of Chen et al. [
55], who used the generator’s encoder as a part of the discriminator. To stabilize the training process, they trained this common part with the discriminator objective. Following the idea of making less heavy models, Shaham et al. [
53] proposed a lightweight model that can be trained faster called ASAP-NET, which is composed of a small convolutional encoder and a spatially-varying pixelwise MLP. With this architecture, they qwew able to generate good translation within 35ms for an image of
pixels on an Nvidia GeForce 2080ti GPU. Following the idea to train fewer models, Richardson et al. [
56] trained an encoder for the
space of StyleGAN [
15] using a pyramidal feature extractor.
In general, a good translation model is a model that can generate diverse images. In medicine though, translation models should generate precise translations and produce unique images for each patient. Shen et al. [
57], inspired by the work [
24,
58], proposed a model able to perform a unique translation by forcing the model to be self-inverse (e.g.,
).
Currently, some research projects address high-resolution translation. The higher the quality of the images, the more complicated the translation task. To be able to perform these translations, Shao et al. proposed SpatchGAN [
59] to improve PatchGAN by releasing an architecture that is more able to shape changes and hence stabilize the training on challenging translation tasks. This model takes an image at different scales to be sure that this discriminator captures both global and local information. Another work that aims to generate high-resolution images is LPTN from Liang et al. [
60]. They profited from Laplacian pyramids to make high-resolution translations.
In another work, Gao et al. [
10] stated that cycle consistency forces the model to hide information to guide the model for the reverse translation and satisfy the cyclic constraint. To alleviate this issue, they proposed a wavelet-based skip connection to filter out low-frequency components inside of image information and propagate the high-frequency information directly at the end of the generator. Furthermore, they proposed a discriminator to force the model to generate highly detailed generations and a new loss called attribute regression loss.
8. Attribute Editing
CycleGAN was a breakthrough in the domain of unsupervised image-to-image translation, as it allows translating from one domain to another in an unsupervised manner. Nevertheless, it does not give a lot of control to the user. Since then, some work emerged with the idea of performing translations given some user constraints. One seminal work was StarGAN by Choi et al. [
13], which performs the translation given a source image and predefined labels. However, these predefined labels do not give to the users complete control over the translations. Later, Choi et al. came up with another version of StarGAN called StarGAN v2 [
54]. This method introduces another paradigm in UI2IT with three subnets, namely: a generator, a multi-task discriminator and a style encoder.
Figure 5 gives a brief overview of the starGAN framework.
Even after the StarGANv2 proposal, researchers tried to add even more control on the generation. For example, Dural et al. proposed FacialGAN [
90], which performs translation given a source image, a reference image and a segmentation mask. This method was inspired by StarGANv2, but with a modified version of StarGANv2’s generator, and they proposed a segmentation network to ensure the consistency of the translations. Even though some models can give control to users using a semantic segmentation mask, Liu et al. [
91] stated that the segmentation mask does not give complete control over the generations, since the user cannot generate images with clear delimitation on the same face. Hence, they proposed self-adaptative region translation (SART) and introduced region matching loss (RML) and region instance normalization (RIN) blocks. This method ensures that each region is translated separately.
On another hand, Wei et al. [
92] stated that a proposed model, such as STGAN [
93] makes unnecessary modifications. They also stated that face editing in high resolution is not widely explored. To tackle this problem, they propose Mask-Guided GAN (MagGAN), which is inspired by STGAN. They also proposed a soft segmentation mask and mask-guided reconstruction loss. In addition, they used a multi-level discriminator to stabilize the model’s training. Gao et al. [
10] tackled a problem related to cycle consistency. As another work in this review [
11], they stated that cycle consistency forces the generator to hide information during the translation to give enough information to satisfy the cycle consistency constraint. To be sure that the generator does not pass any information to satisfy the cycle consistency, they introduced another module called wavelet-based skip connection to ensure that the model does not take the easiest path. The work of Huang et al. [
94] talked about reference-based translation and label-based translation. They proposed to combine the best of both worlds by introducing a reference encoding module and a label encoding module.
9. Guidance
Although the models can generate translations that can be visually pleasing, training generative neural networks can be complicated because the training is unstable due to the adversarial mechanics involved. This section discusses articles introducing methods to guide models more easily to their final goals. These methods usually use contrastive learning settings first introduced in I2I translation by CUT [
86], the authors of which utilized a patch-based method for UI2IT. As mentioned in
Section 8, Wei et al. [
92] proposed a mask-guided reconstruction loss. This loss ensures that the model is guided to translate only the wanted facial part and hence make high-resolution face editing. To gain a better focus on certain objects during the translation, Bhattacharjee et al. [
95] propose to use an object detector to localize objects in a given scene and hence pay more attention to them during the translation. However, the use of this method is computationally inefficient and limited to the objects that the detection model has seen during training. From another point of view, Jeong et al. [
96] stated that cycle consistency imposes a determinism between the source and the target domain. They also stipulated that methods apply a global style during the translation, which is problematic for images with multiple objects. They hence introduced a class-aware memory network. This network memorizes the object style to guide the model to the correct translation. In the same vein, Tang et al. also stated that the translation often transfers unnecessary elements of the image. They hence proposed AttentionGAN [
51], which uses an attention mechanism to separate the main subject to be translated from the background. Another work from Jiang et al. [
52] states that some methods that utilize saliency maps to guide the translation are limited by low-level pixel modifications. They proposed another method that uses the saliency map to guide their translations. They proposed a saliency-guided attention module and saliency-guided global and local discriminators. Another particular work from Pizzati et al. [
97] notes that continuous translation requires supervision to realize the intermediate translation. To be able to perform continuous translations in an unsupervised manner, they introduced CoMoGAN. This method introduced a functional normalization Layer which is placed between the encoder and the decoder. This method enables cyclic translation of a particular image for continuous day-night translation.
9.1. Disentanglement Learning-Based Methods
Disentanglement learning is a subpart of representation learning. It aims to give models an optimized representation for a given task. This idea was first proposed by Rifai et al. in 2012 [
98] in expression recognition. This idea was firstly applied in UI2IT by Gonzalez-Garcia et al. in 2018 [
37], who made the choice to separate attributes into three different spaces—namely, the shared part, which stores the attributes shared across all images, and two exclusive parts that represent the specific attributes inside domains.
Later, Huang et al. [
45]. and Lee et al. [
99] proposed to separate an image into two spaces, a content space and an attribute space. Another type of disentanglement was proposed by [
8,
100], who considered the important features as content and the remaining ones as style features.
Recently, Li et al. [
101] stated that previous methods are deterministic. They also stated that StarGANv2 [
54] makes unnecessary manipulations during the generation (identity transformation or background transformation). They also stipulated that the previous methods do not provide fine-grained control over generation. To alleviate this, they proposed a hierarchical style disentanglement to organize labels as a hierarchical tree structure. For example, the label “glasses” could be disentangled as “sunglasses” and “myopic glasses”. This method proposes more controllable generations and scalability.
Ren et al. [
100] began their paper by stating that most content-style disentanglement methods depend on supervision to guide the disentanglement. They followed the work of Gabbay et al. [
102] and proposed an unsupervised content-style disentanglement module (C-S DisMo), which tries to isolate the most important features for the reconstruction from less important features. The former are called “content features”, and the latter, “style features”. Another work that tried to separate the content from the style features is that of Liu et al. [
8], who separated the content from the style by using a common task called the “domain-invariant high-level vision” task—face segmentation in this case. The most important features for the segmentation are also called content features, and the remaining ones are called style features.
In the same strategy, Kim et al. [
22] proposed to give more control over generation. To alleviate that, they proposed a style-aware discriminator that encodes style and sorts real images from generated ones.
In the same vein, Baek et al. [
87] stated that recent works rely on guidance available in the data or a paired dataset which constrains the data acquisition. To alleviate that, they introduced a new truly unsupervised image translation (TUNIT) as an UI2IT method that uses a guidance network and two-branch classifier that predicts either the pseudo-label or the style vector.
9.2. Contrastive Learning-Based Methods
Contrastive learning is a sub-field of self-supervised learning which consists of making more efficient use of the data. In this case, contrastive learning aims to make a representation with better class separation by adding an objective that constrains the model to add contrast to the learned representation. A visualization example can be found in
Figure 6. More deeply, it consists of two pairs, the positive pair which is composed of samples from the same class and the negative pair composed of samples from a different class. The objective function constrains the model to make similar representations for samples that behave in the same class and very different representations for samples in different classes.
To alleviate these problems, contrastive learning-based methods have been proposed to optimize the learned representation, especially with noise contrastive estimation (NCE) [
103]. Hereafter in 2020, Park et al. [
86] stated that image-to-image translation is a disentanglement learning problem because the goal is to transfer content (which does not change) to a specific style (which has to change). They introduced a contrastive learning technique to UI2IT by using the infoNCE loss to maximize mutual information between patches. Since then, the research community became more inspired by this contrastive learning idea.
One year later, in 2021, Han et al. [
104] and Zheng et al. [
7] further exploited this idea. The former’s method uses dual contrastive learning using the generator’s encoder and projection layers with a revisited PatchNCE loss to constrain generators during the translation. The latter’s method exploits contrastive learning to make the generator structurally aware using their proposed self-similarity to provide strong supervision on the structure.
Hu et al. [
105] found that the patches are sampled randomly, which is not optimal. Given this problem, they proposed to optimize the selection of patches location with a query-selected attention module. Jung et al. [
106] mentioned that recent methods did not take semantics into account and proposed semantic relation consistency (SRC) to force the model to keep spatial semantics during the translation and negative mining to further improve the model’s performance by avoiding easy image patches.
Another work that is used in the contrastive learning world is TUNNIT by Baek et al. [
87], where a contrastive learning scheme is used in the guiding network. This contrastive learning loss helps the guiding network to extract the style codes.
10. Method Comparison
We compare the discussed state-of-the-art current papers by collecting and summarizing their results on different datasets and using different metrics.
Figure 7 shows the six most used evaluation datasets in these papers. Cityscapes and Horse to Zebra are the current mainstream datasets for I2I Translation. For face translation methods, CelebA, celebA-HQ and Flickr Face HQ remain the best options for model evaluation.
As
Figure 7b shows, LPIPS, SSIM, PSNR and FID are the most used metrics in the reviewed papers, shortly followed by mean intersection over union (mIoU) to check the semantic consistency of recent methods.
In
Table 1, we can see the predominance of the FID, as it was nearly used by all studies. This metric can give us an approximation of the network generation quality. According to this metric, LSeSim [
7] seems to be the best model in terms of generation quality. However, this statement should be taken with a grain of salt because the authors did not evaluate their method using the SWD. QS-Attn had the best SWD.
In
Table 2, we can see that the CitySpaces dataset is useful for checking the semantic translation capabilities of methods. It can benefit from precise segmentation metrics such as pixel accuracy and class accuracy. TSIT obtained the best class accuracy.
In
Table 3, we can see that little attention has been given to time or space complexity metrics. This table shows that NICE-GAN is the fastest model.
Since we made a general comparison between papers, we now present a deeper comparison between papers classified in the same category:
Section 5 groups papers that brought progress to the I2I translation field through a change in architecture. These works tried to make faster translations [
53,
55] and higher resolution translations [
59].
Table 4 shows that, on one hand, these methods use mostly least-square adversarial [
107] loss and the PatchGAN discriminator [
1]. On the another hand, cycle consistency is not used by the majority of methods. As an example, SpatchGAN [
59] uses weak cycle loss and Pixel2Style2Pixel [
56] uses perceptual loss and regularization.
Section 6 presents more challenging translations that involve large shape modifications. As
Table 5 shows that methods in this category do not use the cycle consistency because this cycle consistency imposes a lot of constraints during the training. For example, deformation-aware GAN [
64] uses a shape and appearance constraint, TSIT [
67] uses perceptual loss and feature matching loss and RSMT [
28] proposed a specific type of loss for satellite-to-maps translation, the map consistency loss.
Section 7 groups works that reduce large dataset dependencies and hence increase the usefulness of the data.
Table 6 shows the methods extracted from the papers. It shows that these methods do not use cycle consistency. FUNIT [
83] and COCO-FUNIT [
84] use feature matching loss. ReMiX uses the adversarial loss for translation and another loss to force the generator to preserve the content of the original image.
In
Section 8, we can read about works that performed more precise translations on face datasets. From
Table 7, we can firstly see that these approaches have a wide variety of adversarial losses. For example, HiFaFace [
10] uses high-fidelity domain adversarial loss, and Nederhood et al. [
19] used the hinge version of the normal adversarial loss. Furthermore, the methods of this category use a wide range of discriminators. FacialGAN, inspired by StarGAN v2, uses a multitask discriminator. HifaFace [
10] proposed a high-frequency discriminator. Nederhood et al. [
19] uses the multi-resolution patch-based discriminator from SPADE [
108]. In contrast to other categories, these studies mostly used the cycle consistency, except for that of Huang et al. [
94], which involved latent cycle consistency. Regarding the used adversarial losses, we can notice that HifaFace proposed to use a new adversarial loss for high-fidelity face editing.
Section 9 groups methods that guide models to the wanted translation. For example, CoMoGAN [
97] uses Disentangled Residual Blocks between the encoder and the decoder to guide the generator’s translations. As
Table 8 shows, the cycle consistency is not used in these works. CUT prefers to maximize the information between patches and MagGAN [
92] using Mask guided reconstruction loss and an attribute classification loss. In the adversarial point of view, these methods use the original adversarial loss [
86], the hinge version of the adversarial loss [
70,
97], least-square adversarial loss [
107] or the WGAN-GP adversarial loss [
109]. We can also notice that the majority of the proposed methods are multi-modal.
Section 9.1 exhibits a disentanglement mechanism to provide I2I translation models with a better internal representation.
Table 9 shows that, due to the disentanglement properties, the cycle consistency is not used in works in this part. Lee et al. [
95] used a proposed cross-domain cycle consistency, Liu et al. [
8] used a perceptual loss and their proposed domain invariant high-level vision task, and the TUNIT [
87] generator is constrained by the style extractor and keeps the domain-invariant feature thanks to the multi-task discriminator outputs. If we focus on losses, we can see the original adversarial loss still has a prominent place over other losses.
Section 9.2 groups studies that used contrastive learning to train their translation models. As
Table 10 shows, these methods do not use the cycle consistency. Han et al. [
20] followed CUT and chose to maximize the mutual information between patches for the translation and constrained the network with similarity loss to preserve target domain features. Zheng et al. [
7] proposed to replace the cycle consistency loss with their proposed Learned self-similarity loss to constrain the network not only to translate, but also to preserve, the structure during the translation. In the adversarial point of view, these works are using the normal adversarial loss.
11. Current ChallengesDiscussion
In recent years, the research community has made huge improvements by increasing image resolution, making more challenging translations with the release of Front Face to Profile Face [
20], by releasing more lightweight and faster models and developing performance metrics such as sec/iter or the memory consumption. However, such metrics will irrevocably decrease with the advancement of technology. Moreover, the variety of computing stations in the research centers makes this comparison even more difficult. A solution could be to re-run the evaluation for the time of inferences or to find a metric that can take into account the different technologies used and unify time and memory consumption measures.
Moreover, actual deep translation models are constituted by a multitude of parameters and convolution operations. These two characteristics are not compatible with portable devices such as smartphones. Even though ASAPNET [
53] came with a lightweight and fast architecture, this proposed generator architecture has not been tested in unsupervised settings.
In addition, even unsupervised models need a big dataset to be correctly trained. Although these datasets can be easily generated or completed by web crawling data [
94], we cannot make a dataset for every world case. Whereas translation models that deal with small datasets show good results, such as TUIGAN [
68], generation contains artifacts, and the combination of all these models can be computationally intensive.
In
Section 8, we saw models that can be guided by additional inputs to match the user’s needs, as is the case for FacialGAN [
90]. However, this paper points out a problem that their method does not give full control over generations. This is explained because the discriminator forces the generator to generate realistic faces and hence cannot generate faces with no nose, for example.
One another problem came from the Google Maps dtaset. This dataset can be easily made by scrapping the Google Maps website. However, this causes a consistency problem during the evaluation because the map layout depends on the region where maps are extracted. For example, RSMT [
28] shows that a model trained on the Beijing maps does not perform well when tested on Los Angeles because of the structural difference between cities. A good contribution to the satellite-to-map translation field could be the release of a more complete Google Maps dataset with multiple cities in several regions (cities, villages, mountainous landscapes, cities near the sea, highly populated cities and lightly populated cities).
FID is the most used metric in the I2I translation field. This metric is a way to benchmark a given generation model on the state-of-the-art. However, Kynkäänniemi et al. [
110] wrote that the FID can be improved without making any improvements by generating a large set of images and selecting images that fit the fringe feature of the real data. Another work from Gu et al. [
49] stated that, since FID is based on a model trained on ImageNET, it can be the prey of outliers.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}