
Learning-Based Image Damage Area Detection for Old Photo Recovery


Abstract
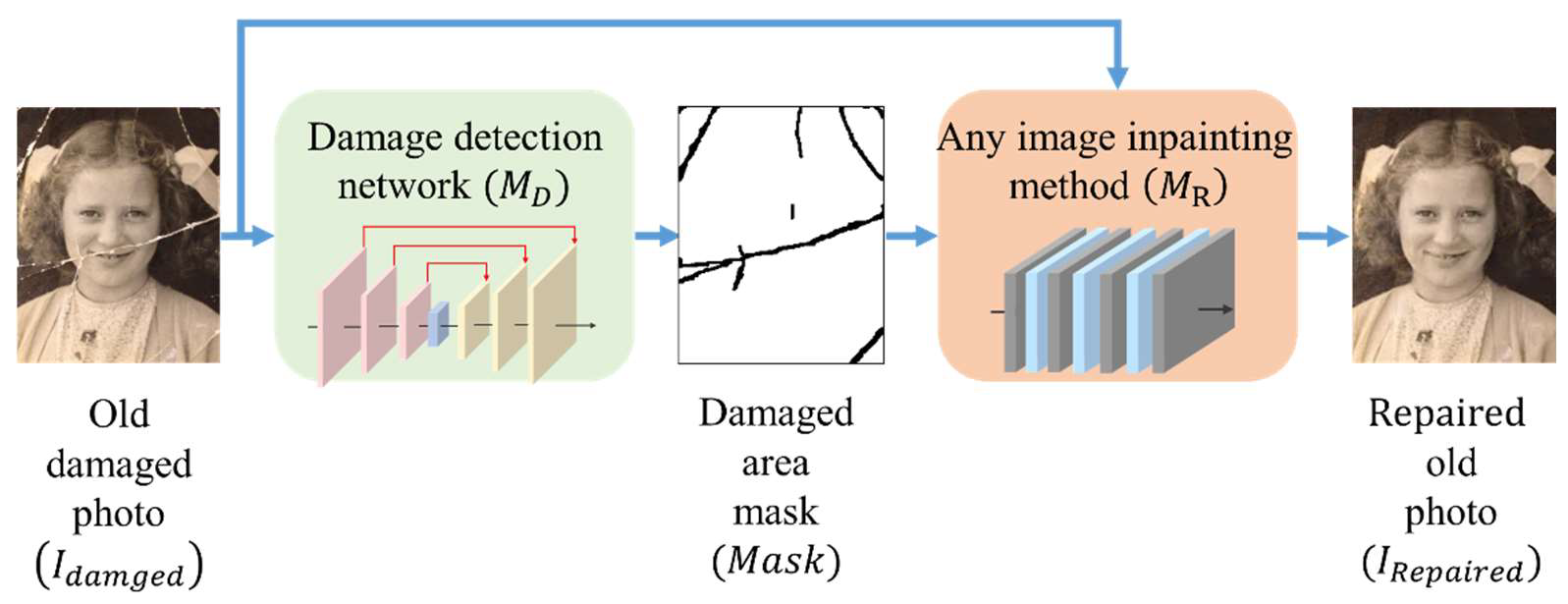
1. Introduction
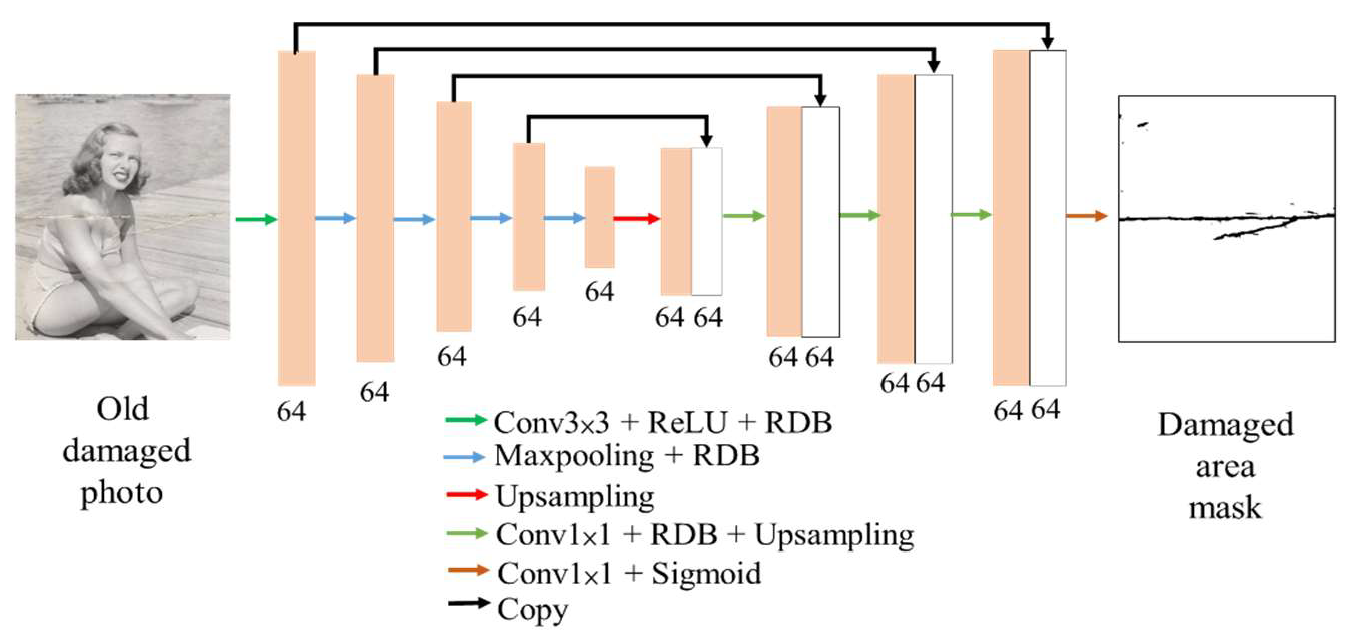
2. Proposed Method
3. Experiment Result
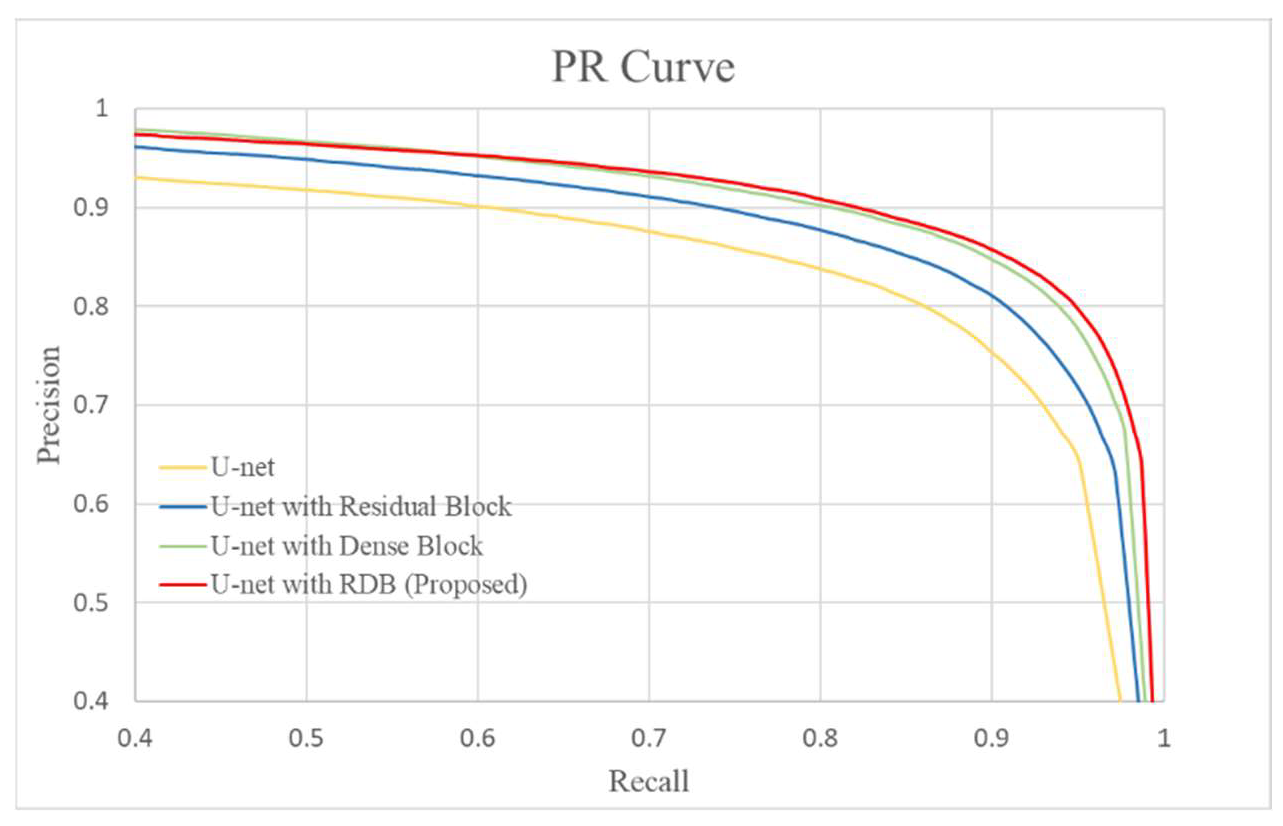
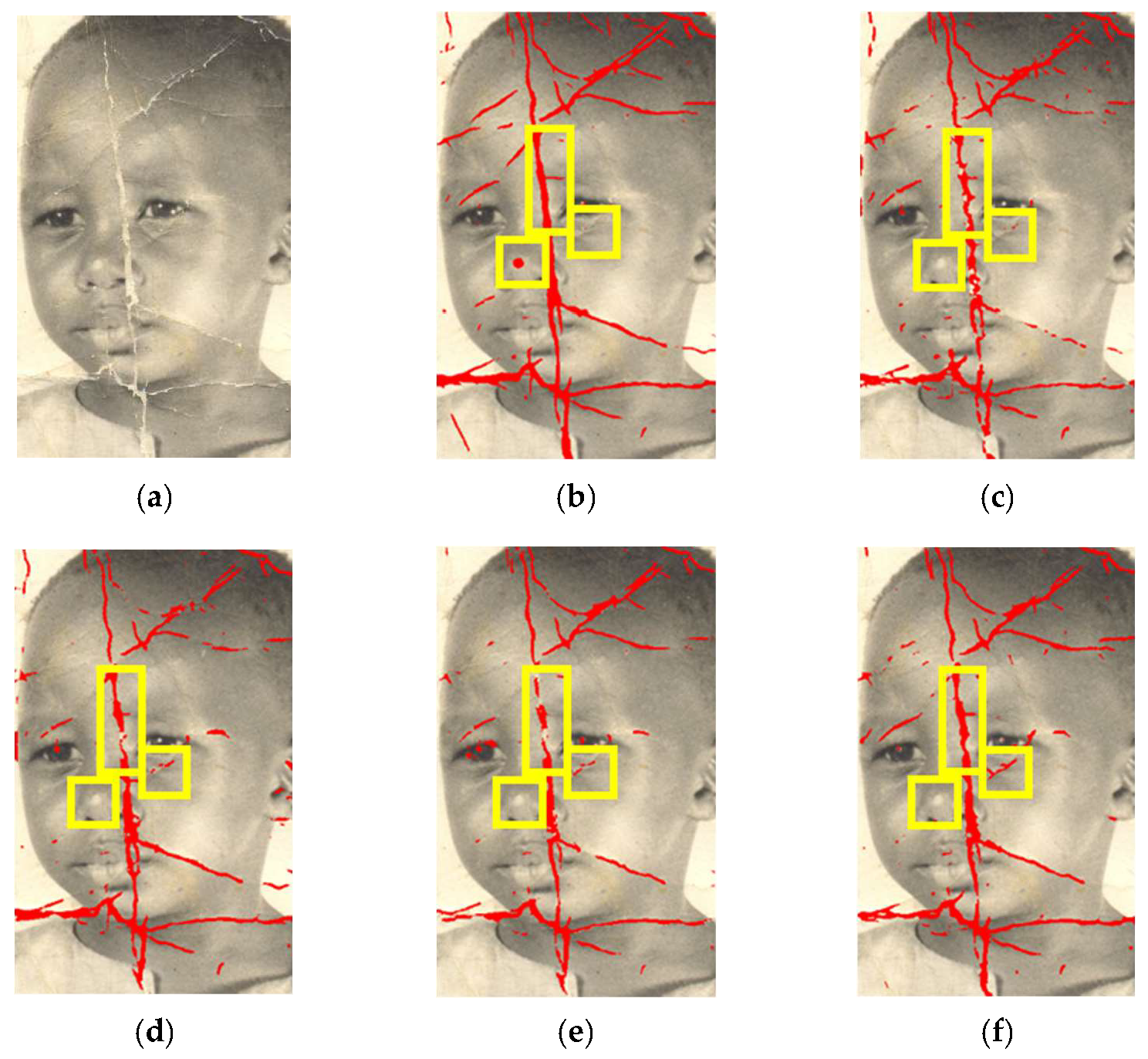
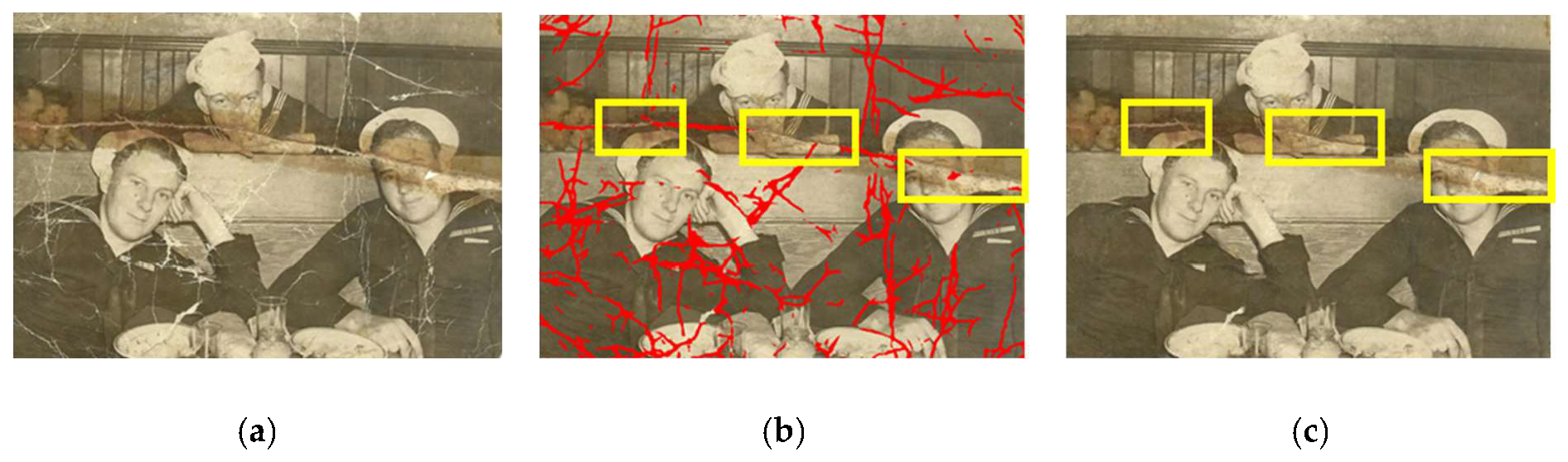
3.1. Comparison of Various Modules
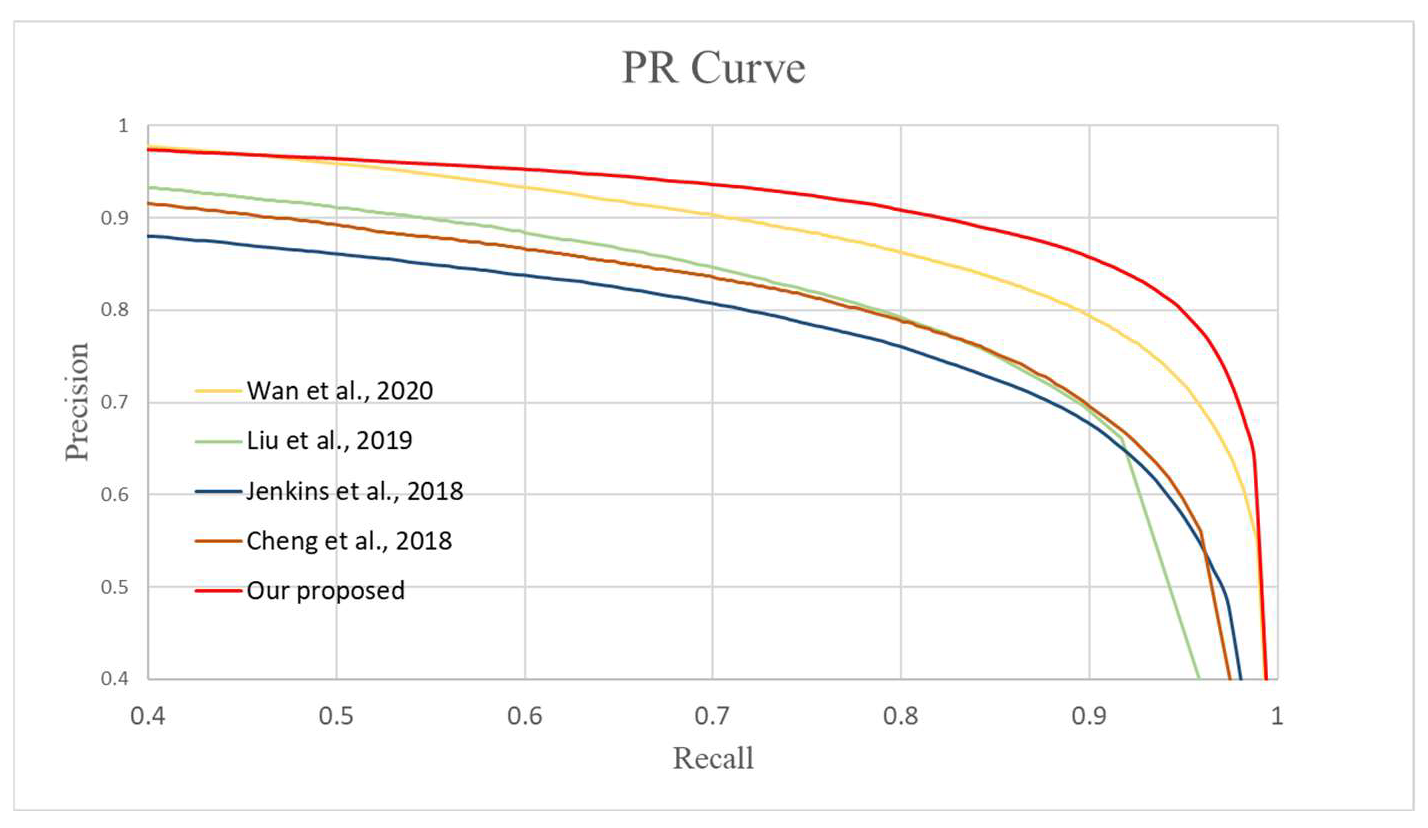
3.2. Comparison of Different Detection Methods
3.3. Combination with Inpainting Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Graphical Design Team. GIMP. Available online: https://www.gimp.org/ (accessed on 20 August 2022).
- Li, B.; Qi, Y.; Shen, X. An Image Inpainting Method. In Proceedings of the Ninth International Conference on Computer Aided Design and Computer Graphics (CAD-CG’05), Hong Kong, China, 7–10 December 2005; p. 6. [Google Scholar]
- Zhao, Y.; Po, L.-M.; Lin, T.; Wang, X.; Liu, K.; Zhang, Y.; Yu, W.-Y.; Xian, P.; Xiong, J. Legacy Photo Editing with Learned Noise prior. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Online, 5–9 January 2021; pp. 2103–2112. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Free-Form Image Inpainting with Gated Convolution. In Proceedings of the Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4471–4480. [Google Scholar]
- Wan, Z.; Zhang, B.; Chen, D.; Zhang, P.; Chen, D.; Liao, J.; Wen, F. Bringing Old Photos Back to Life. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 14–19 June 2020; pp. 2747–2757. [Google Scholar]
- Liu, J.; Chen, R.; An, S.; Zhang, H. CG-GAN: Class-Attribute Guided Generative Adversarial Network for Old Photo Restoration. In Proceedings of the Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 5391–5399. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Dong, C.; Li, L.; Yan, J.; Zhang, Z.; Pan, H.; Catbas, F.N. Pixel-level fatigue crack segmentation in large-scale images of steel structures using an encoder–decoder network. Sensors 2021, 21, 4135. [Google Scholar] [CrossRef] [PubMed]
- Jaidilert, S.; Farooque, G. Crack Detection and Images Inpainting Method for Thai Mural Painting Images. In Proceedings of the 2018 IEEE 3rd International Conference on Image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 143–148. [Google Scholar]
- Bhuvaneswari, S.; Subashini, T. Automatic scratch detection and inpainting. In Proceedings of the 2015 IEEE 9th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 9–10 January 2015; pp. 1–6. [Google Scholar]
- Ghosh, S.; Saha, R. A simple and robust algorithm for the detection of multidirectional scratch from digital images. In Proceedings of the 2015 Eighth International Conference on Advances in Pattern Recognition (ICAPR), Kolkata, India, 4–7 January 2015; pp. 1–6. [Google Scholar]
- Cornelis, B.; Ružić, T.; Gezels, E.; Dooms, A.; Pižurica, A.; Platiša, L.; Cornelis, J.; Martens, M.; De Mey, M.; Daubechies, I. Crack detection and inpainting for virtual restoration of paintings: The case of the Ghent Altarpiece. Signal Process. 2013, 93, 605–619. [Google Scholar] [CrossRef]
- König, J.; Jenkins, M.D.; Barrie, P.; Mannion, M.; Morison, G. A convolutional Neural Network for Pavement Surface Crack Segmentation Using Residual Connections and Attention Gating. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1460–1464. [Google Scholar]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature pyramid and hierarchical boosting network for pavement crack detection. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1525–1535. [Google Scholar] [CrossRef]
- Lau, S.L.; Wang, X.; Xu, Y.; Chong, E.K. Automated Pavement Crack Segmentation Using Fully Convolutional U-Net with a Pretrained ResNet-34 Encoder. arXiv 2020, arXiv:2001.01912. [Google Scholar]
- Liu, W.; Huang, Y.; Li, Y.; Chen, Q. FPCNet: Fast pavement crack detection network based on encoder-decoder architecture. arXiv 2019, arXiv:1907.02248. [Google Scholar]
- Zhang, K.; Zhang, Y.; Cheng, H.-D. CrackGAN: A Labor-Light Crack Detection Approach Using Industrial Pavement Images Based on Generative Adversarial Learning. arXiv 2019, arXiv:1909.08216. [Google Scholar]
- Jenkins, M.D.; Carr, T.A.; Iglesias, M.I.; Buggy, T.; Morison, G. A Deep Convolutional Neural Network for Semantic Pixel-Wise Segmentation of Road and Pavement Surface Cracks. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2120–2124. [Google Scholar]
- Cheng, J.; Xiong, W.; Chen, W.; Gu, Y.; Li, Y. Pixel-level Crack Detection using U-Net. In Proceedings of the TENCON 2018-2018 IEEE Region 10 Conference, Jeju, Korea, 28–31 October 2018; pp. 0462–0466. [Google Scholar]
- Adams, R.; Bischof, L. Seeded region growing. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 641–647. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2480–2495. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic road crack detection using random structured forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative Image Inpainting with Contextual Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.-C.; Tao, A.; Catanzaro, B. Image Inpainting for Irregular Holes using Partial Convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 85–100. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Li, S.; Zhang, Z.; Li, B.; Li, C. Multiscale rotated bounding box-based deep learning method for detecting ship targets in remote sensing images. Sensors 2018, 18, 2702. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Yan, J.; Liao, W.; Yang, X.; Tang, J.; He, T. Scrdet++: Detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing. IEEE Trans. Pattern Anal. Mach. Intell. 2022; early access. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Structure | Recall | Precision | F1 Measure |
|---|---|---|---|
| U-Net | 0.857 | 0.802 | 0.817 |
| U-Net with residual block | 0.876 | 0.833 | 0.846 |
| U-Net with dense block | 0.903 | 0.843 | 0.866 |
| U-Net with RDB (proposed) | 0.911 | 0.847 | 0.873 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuo, T.-Y.; Wei, Y.-J.; Su, P.-C.; Lin, T.-H. Learning-Based Image Damage Area Detection for Old Photo Recovery. Sensors 2022, 22, 8580. https://doi.org/10.3390/s22218580
Kuo T-Y, Wei Y-J, Su P-C, Lin T-H. Learning-Based Image Damage Area Detection for Old Photo Recovery. Sensors. 2022; 22(21):8580. https://doi.org/10.3390/s22218580
Chicago/Turabian StyleKuo, Tien-Ying, Yu-Jen Wei, Po-Chyi Su, and Tzu-Hao Lin. 2022. "Learning-Based Image Damage Area Detection for Old Photo Recovery" Sensors 22, no. 21: 8580. https://doi.org/10.3390/s22218580
APA StyleKuo, T.-Y., Wei, Y.-J., Su, P.-C., & Lin, T.-H. (2022). Learning-Based Image Damage Area Detection for Old Photo Recovery. Sensors, 22(21), 8580. https://doi.org/10.3390/s22218580