1. Introduction
Computer Vision is an application of Artificial Intelligence (AI) focused on implementing human-like cognition and visual processing in computer systems. It has extensive applications, including autonomous driving [
1], surveillance systems [
2], agriculture [
3] and healthcare [
4]. Computer vision consists of tasks such as classification, where an image is classified into one of two or more classes; segmentation, where regions of interest are extracted from an image; tracking, where objects of interest are tracked across a video. Object detection is another such computer vision task that localizes and identifies the objects in an image, and this is achieved by predicting the coordinates of the object and subsequently classifying the object. Object detection methods can be categorised into two types, namely, one-stage object [
5,
6,
7] and two-stage object detection [
8,
9,
10]. In the case of one-stage object detection, both the bounding box prediction and the classification is carried out in a single stage without using pre-generated region proposals. Instead of proposals, one-stage detectors divide the image into grids of equal size, and each grid is used for the detection and localisation of the object it contains. On the contrary, a two-stage object detector generates the region proposals in the first stage. Proposals are regions in the image where the object might be present. In the next stage, the objects in the proposals are classified. Two-stage detectors have higher localisation and object recognition accuracy, whereas one-stage detectors achieve higher inference speeds [
11].
The simple application of still-image object detectors is sub-optimal in challenging environments [
12,
13]. Furthermore, applying image object detection algorithms to video data would process it as a sequence of unrelated individual images, and this approach would result in losing the temporal information present across the frames. The fundamental obstacle in Video Object Detection (VOD) is the appearance degradation of objects [
14], which is caused by several challenging scenarios, as illustrated in
Figure 1 and explained below:
Motion Blur: Occurs due to the rapid or sudden movement of the objects, resulting in the object being blurry and losing its characteristics.
Defocus: Occurs when the camera is not able to focus on the object in motion or when the imaging system itself is being moved. This results in unclear and out-of-focus frames.
Occlusion: Occurs when the object is hidden behind other objects or elements in the environment. Occlusion results in a significant loss of information.
Illumination Variance: Variation in the intensity of light can cause the object to have significantly different characteristics, such as losing colour information under a shadow.
Scale Variance: The perceived size of the object changes as it moves towards or away from the camera and also when the camera zooms or moves with respect to the object.
Spatial Variance: When the camera angle changes, it introduces different viewpoints, rotations or locations of the object, which may result in significantly different characteristics at different viewpoints.
Figure 1.
Illustration of challenges in video object detection. Unlike object detection in still images, objects suffer from appearance deterioration in videos caused by several challenges.
Figure 1.
Illustration of challenges in video object detection. Unlike object detection in still images, objects suffer from appearance deterioration in videos caused by several challenges.
The challenges of blurriness, camera defocus, occlusion and illumination variance can be overcome by leveraging information from the adjacent frames. Therefore, one of the keys to efficient video object detection is effectively leveraging the temporal information across video frames. Recent works have devised various feature aggregation methods [
15,
16,
17] that leverage the attention mechanisms to aggregate features from video frames. Despite the remarkable improvement, the aggregation schemes in these approaches are naive and only operate on the semantic similarities among video frames. This yields sub-optimal performance due to the involved high intra-class similarity caused by spatial, scale and task in the video frames. Due to the fast motion in videos, objects in neighbouring frames can be of distinctive scales. Furthermore, since the object detection problem deals with multiple tasks, i.e., localisation and classification, we argue that learning task-specific features will produce better results. Similarly, due to high spatial variance among video frames, prior to aggregation learning, spatial-aware features will refine the target frame representation.
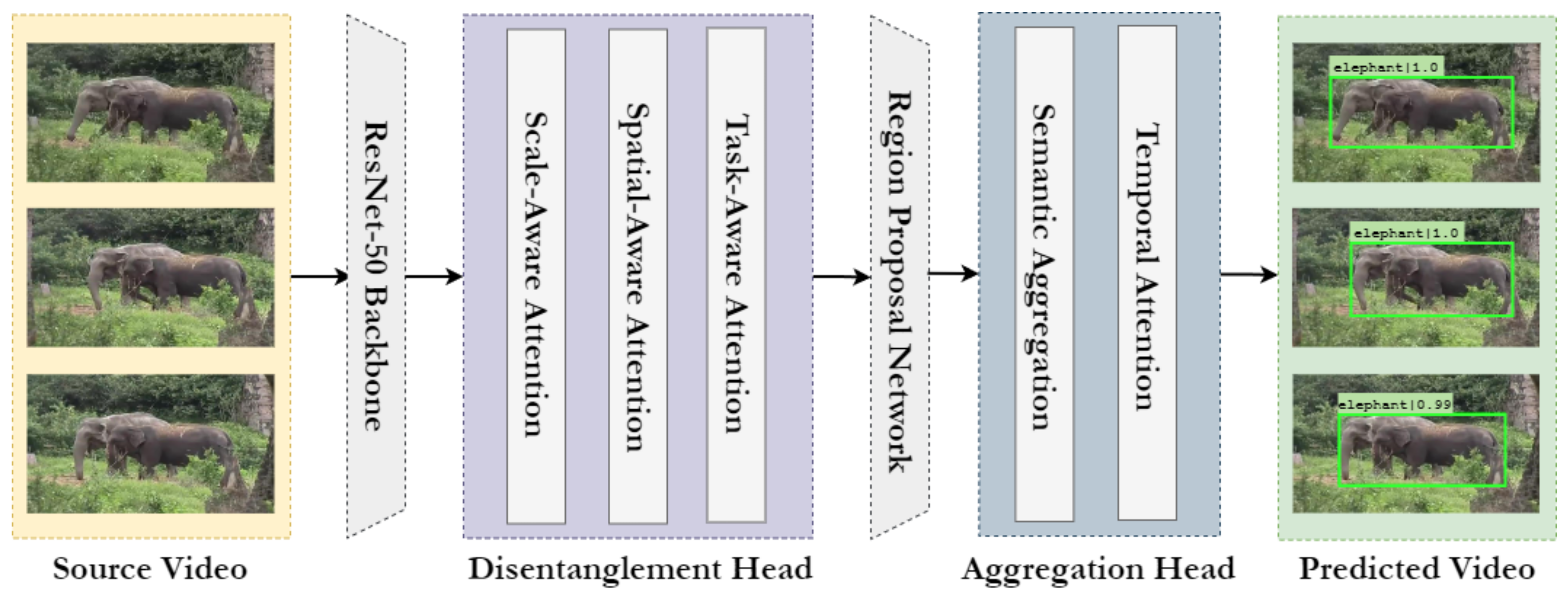
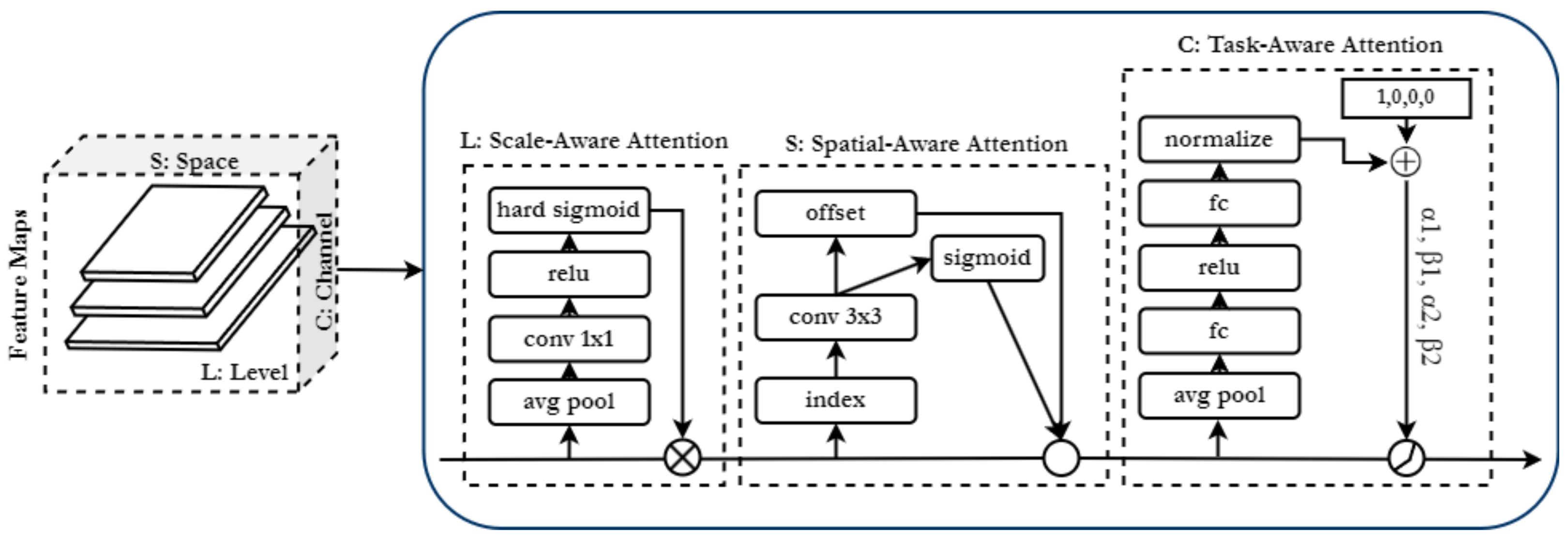
To validate this hypothesis, inspired by the unified attention head introduced in [
18], we disentangle the feature representation first by learning three different feature representations for each video frame. Following [
18], we name them scale-aware, spatial-aware and task-aware features. The attention head incorporates and integrates scale, spatial and task-aware attention, which assists in overcoming challenges of scale and spatial variance. We observe a consistent and significant rise in performance when these enhanced representations from support frames are aggregated with temporal attentional feature aggregation.
The use of attention also alleviates the challenge of processing large amounts of video data, as it focuses only on the relevant parts of the image.
To summarize, the primary contributions of this paper are as follows:
The rest of the paper is organized as follows: In
Section 2, we discuss the background, survey and categorize deep-learning-based approaches to video object detection. In
Section 3, we present the proposed attention-based framework for video object detection and discuss each framework component in detail.
Section 4 discusses the data and metrics used in the evaluation. The results and performance of the model are presented, discussed and visualised in
Section 5. In
Section 6, we conclude with a summary of our work.
2. Background and Related Works
Initial approaches to video object detection used handcrafted features, these included methods such as a histogram of oriented gradients (HOG) [
19], scale-invariant feature transform (SIFT) [
20], speed-up robust features (SURF) [
21] and binary robust independent elementary features (BRIEF) [
22]. The features used in these approaches have to be manually selected; therefore, the detector’s efficiency is highly dependent on the person’s expertise. Furthermore, as the number of classes increases, this process becomes cumbersome [
23]. Addressing this shortcoming in traditional approaches, deep learning-based methods present end-to-end learning [
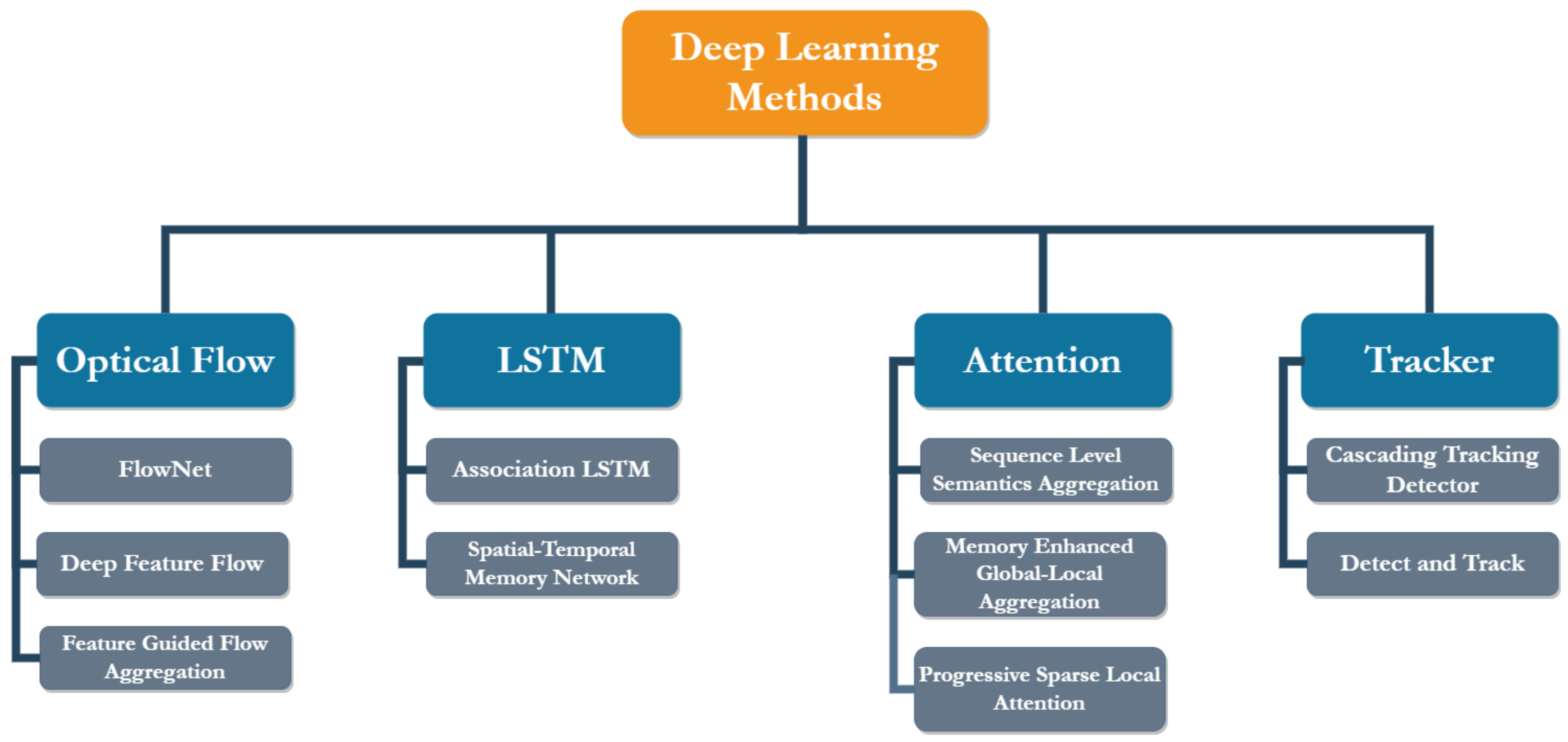
24], where the network is presented with the data and their corresponding annotations, and during training, it automatically learns the underlying patterns and important features for each class. In this section, we survey deep learning-based methods for video object detection, and we categorize these methods into flow-based, context-based, attention-based and tracking-based methods, as shown in
Figure 2.
2.1. Optical Flow-Based Methods
Optical flow algorithms detect object motion by assigning a velocity vector to each pixel [
25], and when the light flow field of a pixel associated with an object changes with respect to a stationary object next to it, the object motion is registered. FlowNet [
26], proposed by Dosovitskiy et al., extends this idea to deep learning, making it an end-to-end learning problem to predict optical flow.
Optical flow methods use the strong features from a key frame to strengthen the features in weaker frames. The challenge of selecting the key frame was addressed by Deep Feature Flow [
27] (DFF). In DFF, a convolutional subnetwork of ResNet-101 is used to extract features from the sparse key frames. The features of non-key frames were extracted by propagating the feature maps of the key frame using a flow field. As it avoids feature extraction on each non-key frame, it reduces the computation time and accelerates object detection.
The Flow-guided Feature Aggregation [
28] (FGFA) algorithm extends DFF, and the convolutional sub-network is applied to all the frames, i.e., every frame is treated as a key frame. For the current frame and a neighbour frame, a flow field is estimated, and the feature maps of the neighbour frame are warped onto the current frame according to the flow. The warped feature maps and the feature maps extracted from nearby frames are aggregated. The detection network utilizes the aggregated feature maps to perform detection on the current frame. FGFA achieves higher accuracy but at the cost of higher computation.
2.2. LSTM-Based Methods
Optical flow methods leverage the temporal context between only two frames and do not completely utilize the context present in the entire video data; an efficient object detector must be capable of utilizing the full contextual information across all frames. A convolutional LSTM [
29] is a type of recurrent neural network that can be used to learn long-term spatio-temporal information through gates that extract and propagate the features.
Lu et al. [
30] propose Association LSTM, a method that incorporates the association of objects between frames. Association LSTM consists of two modules; Single Shot Multibox Detector [
5] (SSD), an object detection network, and convolutional LSTM. The SSD performs object detection on each frame, and then the features of the object are extracted and stacked. The stacked features are given as the input to the LSTM for processing each frame. For the output of the LSTM on adjacent frames, an association error is calculated and optimizing this loss maintains the temporal information of the object across the entire video.
A shortcoming in association LSTM is that the temporal context is limited to adjacent frames and, therefore, it uses only short-term motion information. This lack of long-term motion information was addressed by spatial-temporal memory network [
31] (STMN). STMN receives the feature maps of the current frame and spatial-temporal memory with the information of all the previous frames. Subsequently, the spatial-temporal memory is updated with the current frame. It consists of two STMNs for bidirectional feature aggregation of both previous and future frames, and thereby the STMN encodes long-term information.
2.3. Attention-Based Methods
Another challenge with video data is the amount of information to be processed, which requires extensive computation. Unlike the previously discussed methods, attention-based methods aim to reduce the amount of computation by focusing only on certain parts of the data while ignoring the rest [
32]. In the work, we adopt an attention-based method for video object detection. Sequence Level Semantics Aggregation [
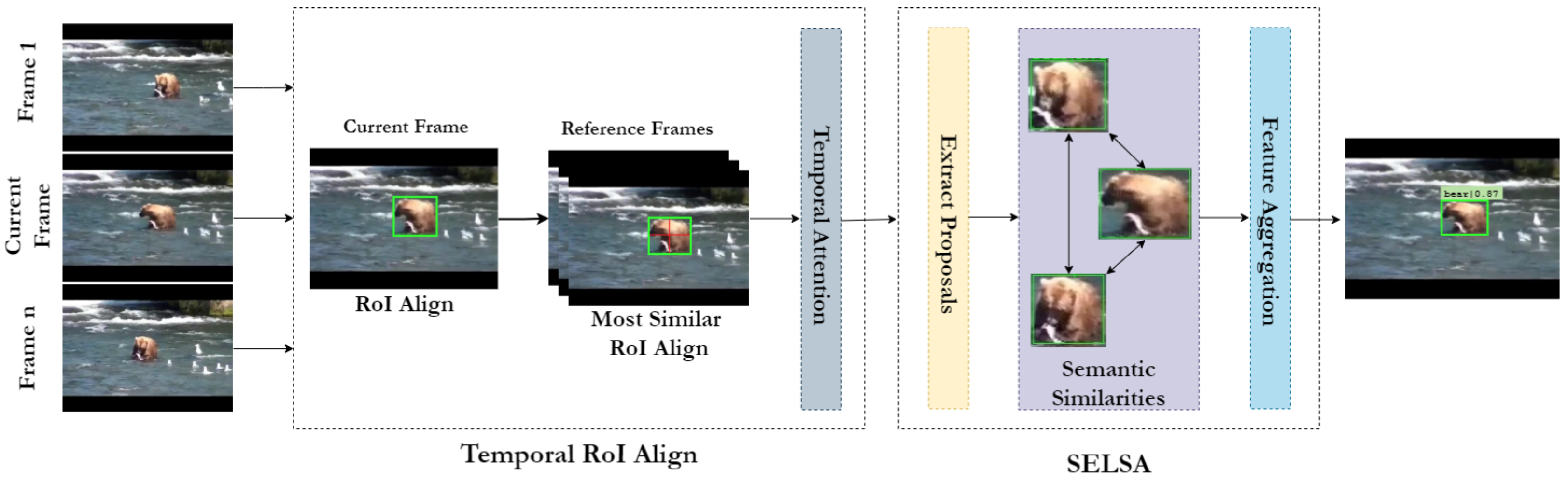
15] (SELSA) is one such method that extracts proposals from different frames and then computes the semantic similarity across the frames. Based on the similarities, the features from other frames are aggregated for robust detection. Performing aggregation on the proposal level instead of the feature map makes it more robust.
Memory-Enhanced Global–Local Aggregation [
33] (MEGA) is modelled by how human perceive objects in a video—through global semantic information and local localisation information. MEGA consists of the global–local aggregation or the base model, which exploits the global features to enhance the local features by integrating global information into the local frames. The proposed Long-Range Memory strengthens the base model to use both global and local features in detection.
The Progressive Sparse Local Attention [
34] (PSLA) module replaces the optical flow algorithm in establishing spatial correspondence between feature maps and propagating the features between frames. It performs feature extraction on the sparse key frames and then utilizes it for the non-key frames. PSLA proposes two methods, dense feature transformation (DenseFT), for propagating semantic information from the nearest key frame to the non-key frames. The recursive feature update (RFU) maintains long-term temporal information by updating the temporal feature at the key frames.
2.4. Tracking-Based Methods
The tracking algorithms process spatial and temporal information that can be leveraged for improving object detection. In contrast to optical flow methods that predict the trajectory of an object using a flow field, tracking-based methods are more accurate and have a longer trajectory. The cascading tracking detector [
35] (CaTDet) consists of a detector and tracker, and the latter is used for reducing the computations. The detector predicts the target area in each frame of the video. The object’s position in the next frame is predicted by tracking the boxes of high confidence in the current frame using the tracker. For each frame, the output from the detector and the tracker are combined and inputted into the refinement network to obtain the calibrated information.
The Detect and Track [
36] (D&T) approach integrates the detection and tracking modules into the same framework built upon the R-FCN [
37]. D&T takes two input frames and computes the feature maps that are shared for both detection and tracking. The proposals are generated by the RPN, and RoI pooling is finally utilised in the final detection. The D&T approach overcomes the shortcomings in CaTDet of detecting occluded objects or predicting new objects in subsequent frames, and as a result, also reduces the computation.
2.5. Attention in Image Object Detection
Inspired by the human visual system, attention mechanisms are employed in computer vision tasks to emphasize the most important regions of an image while disregarding the other regions. Attention can be regarded as a dynamic mechanism that assesses the importance of the features and adapts the weights accordingly [
32]. This section delves deeper into the use of attention mechanisms for object detection. Li et al. propose an adaptive attention mechanism [
38] that integrates three adaptive attention units, namely, channel, spatial and domain. The channel attention unit extends the Squeeze-and-Excitation [
39] structure by considering global max pooling in addition to global average pooling. Ying et al [
40]. apply a multi-attention model comprising spatial, pixel and channel attention modules for object detection in aerial images. The pixel attention fuses local and global information at the pixel level, increasing the receptive field.
Carion et al. [
41] introduce the Detection Transformer (DETR) architecture combining CNNs and transformer encoder–decoder. Through the use of transformers, DETR eliminates the need for methods such as non-maximum suppression and anchor generation, making it a truly end-to-end object detector. Addressing the limitations in DETR of slow convergence and poor performance in detecting small objects, Zhu et al. [
42] propose the Deformable DETR. This is achieved through the proposed multi-scale deformable attention module that replaces the transformer attention modules for processing feature maps found in DETR. Dai et al. propose Dynamic DETR [
43] for object detection using dynamic attention with transformers. Dynamic DETR implements attention in both the encoder and decoder, which overcomes the limitation of small feature resolution and training convergence in transformers.
Wang et al. tackle the challenge of scale variance by using spatial attention to refine multi-scale features [
44]. The authors propose a Receptive Field Expansion Block (RFEB), which increases the receptive field size, and the features generated pass through the spatial refinement module to repair the spatial details of multi-scale objects. In contrast to attention, which focuses on the relevant parts of the image, Inverted Attention [
45] proposed by Huang et al., inverts the attention and focuses on the complementary parts, resulting in diverse features. The attention is inverted along both spatial and channel dimensions.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}