1. Introduction
System dynamics can be represented as a set of differential equations in a space–state manner, and they are defined by using several techniques that explore the system’s energetic relationships, such as Newtonian, Lagrangian, or Hamiltonian mechanics. However, trying to describe some phenomena correctly without knowing the governing modeling equations or without a proper selection of the space–state variables results in inaccurate representations or a complex set of equations that could be represented in a more straightforward but unknown form [
1]. Data-driven system modeling refers to a set of optimization techniques intended to obtain a system’s description based on data observations and measurements of the system’s evolution. For example, the sparse identification of nonlinear dynamics (SINDY) [
2,
3] creates a matrix filled with proposed functions and a coefficient matrix, which must be obtained by using well-documented optimization techniques, such as least-square optimization, to replicate the proportionated data as closely as possible.
Artificial neural networks (ANNs) have tackled this challenge on multiple frontiers. Physics-informed neural networks (PINNs) use prior knowledge of the laws of general physics as a regularization agent during their training process, thus limiting the space of admissible solutions [
4]. For instance, a Kalman filter (KF) is a model-based technique that allows sensor fusion in order to construct a full space–state recovery based on preliminary knowledge of the system’s model and the nature of perturbation noise, which is useful for unknown perturbances or noisy sensor measurements [
5,
6]. In [
7], the proposal of KalmanNet replaced parts of the equations of the extended Kalman filter (EKF) with an ANN with gated recurrent units (GRUs) to find the proper Kalman gain matrix that would allow a full state recovery.
For example, robotic systems exhibit changing dynamics during their lifespan due to the attrition of joints or their interactions within a changing environment. Therefore, compact and energy-efficient learning platforms are required for any autonomous robotic solution [
8]. However, the Von Neumann computer architecture, which is present in all commercially available computing solutions, separates processing and storage into different functional units. Emulating an ANN, a computing strategy that inherently performs storage and processing as closely as possible creates a data bottleneck, as the interactions of neurons and synapses are represented in terms of massive matrix multiplication. The state-of-the-art research on ANNs is performed with sizable graphic processing units (GPUs) or multiple-core computing solutions, the power consumption of which is estimated to surpass humans’ current energy generation capacity if this rate continues [
9].
It is necessary to rethink how to perform computing in a move away from the Turing machine, which requires many layers of abstraction, into parallel hardware with distributed memory [
10]. Spiking neural networks (SNNs) are considered the third generation of ANNs. These models reflect complex biological and temporal dynamics in order to construct artificial software/hardware counterparts with the same behaviors as those of neurons and synapses [
11]. Neuromorphic computing has emerged as a branch in computer science that aims to create computer architectures that resemble the brain’s energy efficiency, learning plasticity, and computing capacity [
12]. This has become the inherited hardware platform for SNNs, which usually dictate the design of the building blocks for hardware solutions [
13] that are usable for robotic platforms. For instance, in [
14,
15], an SNN learned the inverse kinematics (IKs) of a robotic arm manipulator, which are usually hard to obtain. While such networks can be used to reconstruct IK values, the extraction of the specific modeling functions from the network is still a research topic.
On this basis, the development of neuromorphic accelerators based on existing complementary metal-oxide semiconductor (CMOS) digital technology is enabling research in neuromorphic computing. such technologies usually include peripheral devices and software/hardware bridges with conventional computing architectures, thus enabling network analysis, performance measurement, and reconfiguration, such as in Intel’s Loihi 2 chip with 130 million silicon neurons and 256 million synapses [
16], which is programmable with the Lava neuromorphic compiler, Truenorth from IBM with 1 million neurons and 256 synapses [
17], or BrainChip’s Akida [
18], which was built with TSCM’s 28 nm technology, among others. These have been used to obtain remarkable results in robotics [
19], sensing, and classification tasks. However, as the construction of these accelerators relies on expensive proprietary CMOS chip technologies, they face the same scaling and energy consumption limits [
20] as those of their Von Neumann counterparts.
From the perspective of analog electronics, a passive electric device called a memristor [
21], which was theorized by Leon Chua, can be used for in-memory computing. It maintains its internal conductance state based on the current that has flowed through its terminals. These passive devices can be used in high-density crossbar arrays (CBAs), which can perform parallel vector–matrix multiplication with ultra-low energy consumption. Analog neurons and synapses have been assembled to compute values that rely on current summation rather than digital Boolean operations [
20,
22], resulting in some already-built analog neuromorphic architectures [
23,
24].
This article explores the concept of KalmanNet by entirely replacing its ANN architecture with a proposed SNN architecture to assemble biologically plausible neuron and synapse models. In addition, we propose a new differentiable function for modeling the encoding/decoding algorithms. The proposed architecture was tested in numerical simulations using two well-known nonlinear systems, which showed the feasibility of the solution. At the same time, its possible construction requirements were explored with the aim of its construction in neuromorphic hardware that would be capable of online learning in a space- and energy-efficient neuromorphic hardware solution.
This article is structured as follows: In
Section 2 (Materials and Methods), neurons, synapses, and encoding/decoding models are described, and it is shown how these can be interconnected to create the proposed network solution.
Section 3 (Results) shows numerical simulations with the nonlinear canonical Van der Pol and Lorenz systems used to test the capabilities of the architecture.
Section 4 discusses the results, while
Section 5 closes this work by showing our conclusions and proposing future research.
2. Materials and Methods
In this section, we start by reviewing how neurons, synapses, and learning rules are modeled. Then, we show encoding/decoding algorithms to determine the current input for the neurons in order to represent the signals used in our proposal. Next, the Kalman filter algorithm is illustrated. After the building blocks are introduced, our proposal is shown at the end of this section.
2.1. Neuron Modeling
Leaky Integrate and Fire (LIF) is one of the simplest models available for neuron modeling. It resembles the dynamics of a low-pass filter [
25], as it considers a neuron as a switching resistance–capacitance circuit that is governed by:
In (
1),
represents the membrane’s potential,
is the membrane’s potential at rest,
stands for the membrane’s temporal charging constant,
is the membrane’s resistance, and
is the membrane’s capacitance.
acts as an excitatory input current for the neuron, which charges the membrane’s potential
until it passes a threshold voltage value
, at which point a spike is emitted. The spike’s voltage,
, is shaped as follows:
where
is the last moment at which a spike was produced, whereas
is the Dirac delta function that models the impulse’s decay alongside the synapses, which decay from a maximum value
at
to zero at the following post-synaptic rate
:
Once the spike is produced, resets to . The neuron will not spike again during a refractory period , as it does not admit an excitatory input current. When , .
Given a connection between the
j-th and
k-th neuron by a synapse with a certain conductance value
(the modeling of which will be reviewed in
Section 2.2), the input current for the postsynaptic neuron will be a function of each spike from the presynaptic neuron and its propagation through the corresponding synapse. For
j presynaptic neurons, the current
for the
k-th neuron is modeled by the following expression:
where
is the firing time of each presynaptic neuron. Equations (
1) and (
4) make up the conductance-based LIF model [
26], where
is the injection current time decay and
stands for the temporal injection current constant, which models the scale of the current injection of the presynaptic impulses.
Figure 1 shows a step impulse of
fed to a single neuron, which is modeled by Equation (
1), showing its internal state
and the produced spike voltage
. The parameters used for the neuron that is used are provided in
Table 1.
Frequency Response of the Neuron
To compute how much current has to be fed into the neuron to obtain a given frequency response, first, we need to compute how much time it will take for the neuron to pass from a resting stage to a firing stage by analytically solving the differential Equation (
1):
For
, we can rewrite
. Setting the initial conditions to the values of
, and
in Equation (
5), we can solve for
t to obtain the expression of the membrane’s potential charging time
:
As the firing frequency
, where
, we have:
Equation (
7) computes the frequency response of a neuron given a certain current. The inverse function computes the opposite—the amount of current needed for a given frequency:
Figure 1b shows the firing response of a neuron with respect to the firing frequency response for a given excitatory input current; this is called a
tuning curve, and it was obtained using Equation (
7) (analytical solution) and a numerical simulation of Equation (
1), with a sweep from 0 A to 6 nA, using the neuron parameter values that appeared in
Table 1. Setting
Hz, we obtain
nA. This is called the
riobase current of the neuron.
2.2. Synapse Modeling
Spike-time-dependent plasticity (STDP) is a Hebbian learning algorithm that reflects how a synapse’s conductivity increases or decreases according to the neuron spiking activity [
27]. Given the
j-th layer of
N presynaptic neurons and the
k-th layer of
M postsynaptic neurons, a matrix of
synapses will form between them, and its weight value will be modified by:
In Equation (
9),
is the difference between the firing times of the postsynaptic and presynaptic neurons.
are the
long-term potentiation (LTP) and
long-term depreciation (LTD) constants, which map the decay effect of a spike in the modification of the weight. For each spike, the synaptic weight is then modified by a learning rate of
. When
and
, the response is symmetrical, that is, the synapse modifies its value equally for presynaptic or postsynaptic spikes. STDP is included in the unsupervised learning paradigm [
8], as there is no
teaching signal involved, rather than the input and output signals to be processed.
2.3. Reward-Modulated STDP (RSTDP)
In order to introduce a teaching signal, some modifications to the STDP algorithm were described in [
8] based on dopamine’s modulation of the learning ability in the synapses observed in biological systems. Starting from Equation (
9), an eligibility trace
E can be defined by taking into account only the last pre- and postsynaptic spike potentials at time
t:
The eligibility trace is intended to model the tendency of the change in the synaptic weight value as a transient memory of all of the spiking activity, where
depicts its decay time. The rate of change in the synaptic weights
w is then obtained as follows:
where
is a reward signal, which is defined according to the network’s objectives. It is worth mentioning that when
, learning is deactivated, as no change in synapses is produced. When
, the weights are forced to converge in the opposite direction. Finally, when
, the eligibility trace remains unaltered.
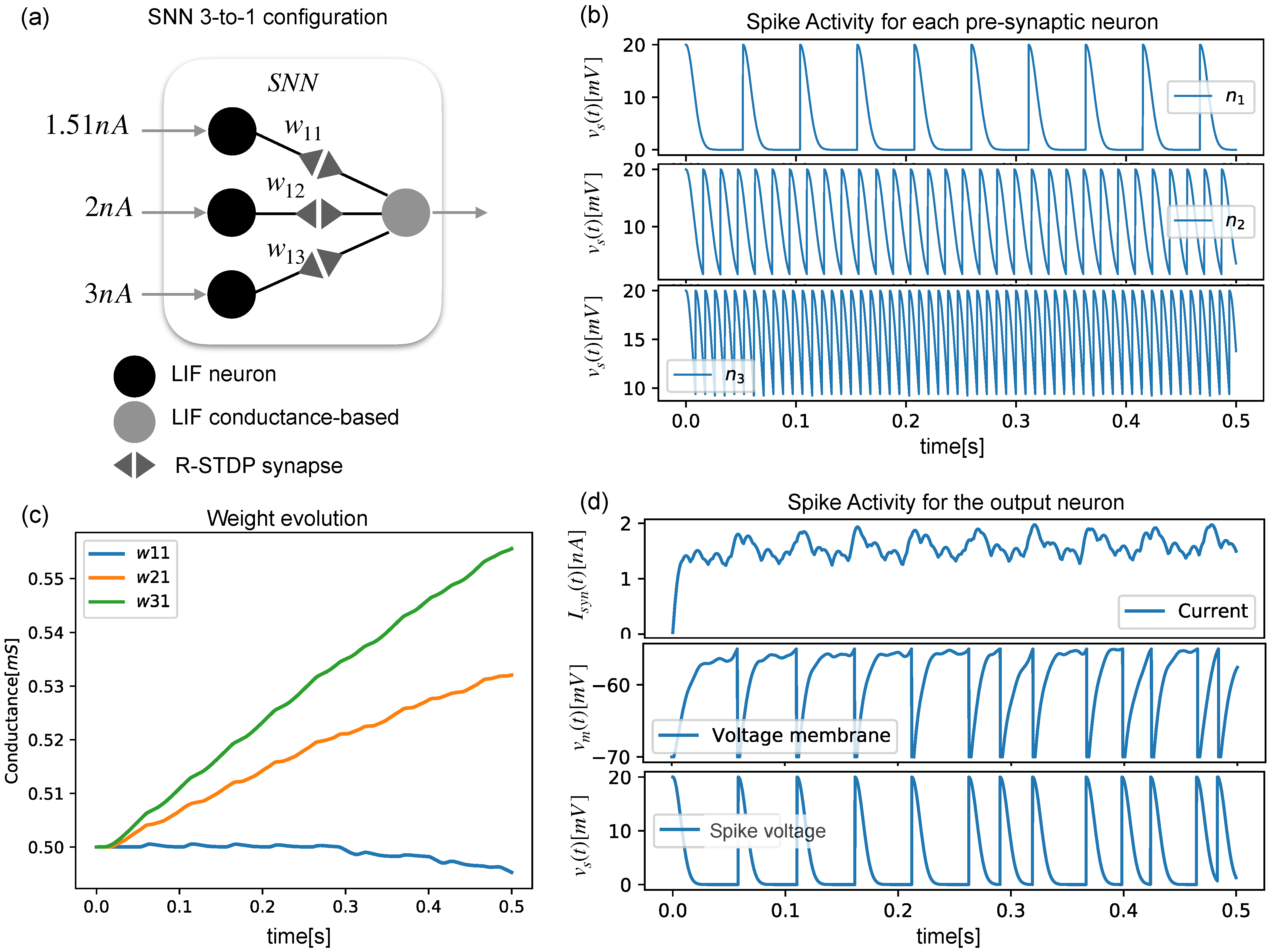
Three presynaptic neurons and one postsynaptic neuron were arranged as shown in
Figure 2a, and they produced different spiking activities (
Figure 2b), showing how the output neuron’s membrane voltage accumulated with each arriving spike (
Figure 2d). As each neuron spiked with a different frequency, the synaptic weight evolved into different values (
Figure 2c).
2.4. Encoding and Decoding in Spiking Neural Networks
Given an analog input signal that is intended to be processed by an SNN, a proper truly excitatory input current that represents every possible value from the input signal should be computed (encoding). Furthermore, the spiking activity of a neuron must be interpreted back from the spiking domain into the analog domain in order to interact with external systems (decoding).
Encoding Algorithm
There are several encoding and decoding algorithms that have been proposed in the literature. Some of them have the intention of reflecting biological plausibility, or easing the construction of neuromorphic devices.
Rate-based encoding takes an input signal
and a minimum and maximum spiking frequency operation of the neuron
, and it uses Equations (
7) and (
8) to encode/decode, respectively. Nonetheless, the encoding process can be performed as a function of the variability of the signal, which can be divided into
phase encoding and time-to-first-spike encoding, among others [
27,
28]. Step-forward encoding, which was described in [
29], is a temporal encoding algorithm that harnesses the low-pass filter dynamics of the LIF neuron in conjunction with a temporal encoding methodology. The input signal
is compared with an initial baseline signal
and a sensibility encoding threshold value
. If
, a certain current
is fed into an LIF neuron, which is denoted as
. However, if
, a fixed current
is then fed into another LIF neuron (denoted as
). Therefore,
will only spike for a growing signal, while
will spike for decreasing signals. In this work, the conditional part of this encoding algorithm is replaced with differentiable functions with the aim of easing future mathematical convergence analyses. Setting
,
where
c is a slope modulation constant, which, for high values, approximates
function as closely as the hardlim function. The baseline signal for the encoding is then updated by:
For decoding, the output signal
is computed with the following expression:
where
stands for the spiking time of the
neuron and
is the firing time of the
neuron.
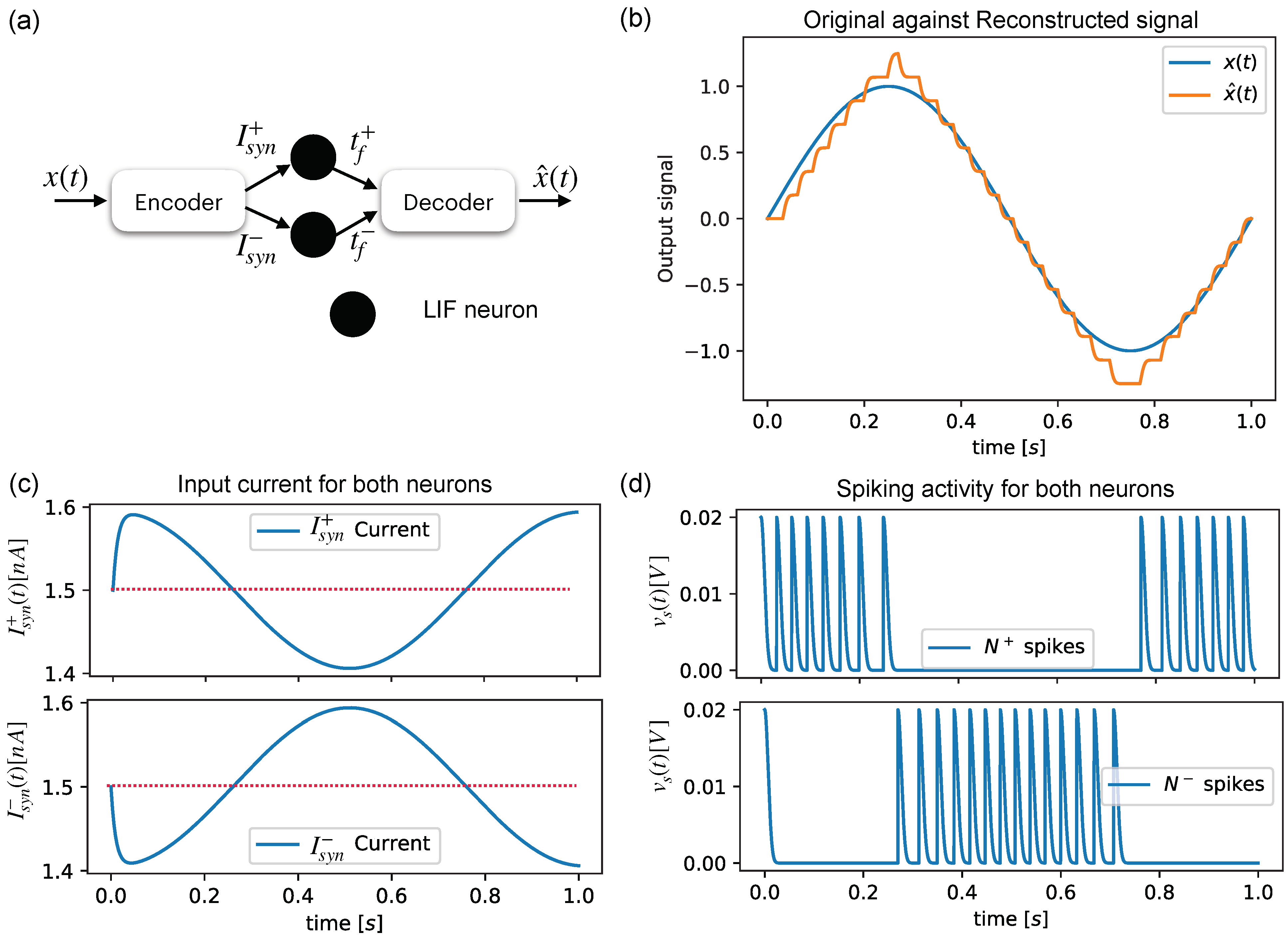
Figure 3a shows a simple configuration for reconstructing an input sine signal, which is shown in
Figure 3b, by using the spiking activities of two neurons (
Figure 3c) that are fed by an encoding block composed of Equations (
13) and (
14), which feed
and
with the current levels shown in
Figure 3d.
2.5. Discrete Extended Kalman Filter
The discrete
extended Kalman filter (EKF) allows full state estimation of system dynamics based on partial and/or noisy measurements. Given a system represented in a discrete space–state manner [
5],
where
is the state vector of the system, and
is nonlinear and describes the evolution of the dynamics given the state value at the previous timestep
and a control input
.
is the available output of the system, which is described by
.
and
are additive white Gaussian noise (AWGN) with a covariance matrix
and
, respectively, representing the system uncertainties given by perturbations or noisy measurements. The EKF algorithm retrieves an estimation
that ideally tends to
. As
are nonlinear, the EKF uses a linearized version of the system’s model by obtaining their respective Jacobians:
where
is the estimation of the EKF in the previous timestep. The
discrete EKF is a two-step procedure involving a
prediction and an
update:
- 1.
Prediction: First, a preliminary estimation
,
is computed by:
Then, a covariance estimate
is computed, and the noise covariance matrices
and the estimate in the previous timestep
are taken into account:
- 2.
Update: The second step consists of computing the Kalman gain matrix
with
in which the difference between the measurable output and estimated output of the prediction step is used:
We can obtain a final estimation
that considers errors in measurement and noise statistics:
Finally, the moment of the prediction
, which will be used for the next timestep in
prediction, is computed:
In order to successfully reconstruct the full state, both the KF and EKF demand full knowledge of the system dynamics, as the correct characterization of perturbations and measurement noise can become cumbersome or unavailable in real scenarios.
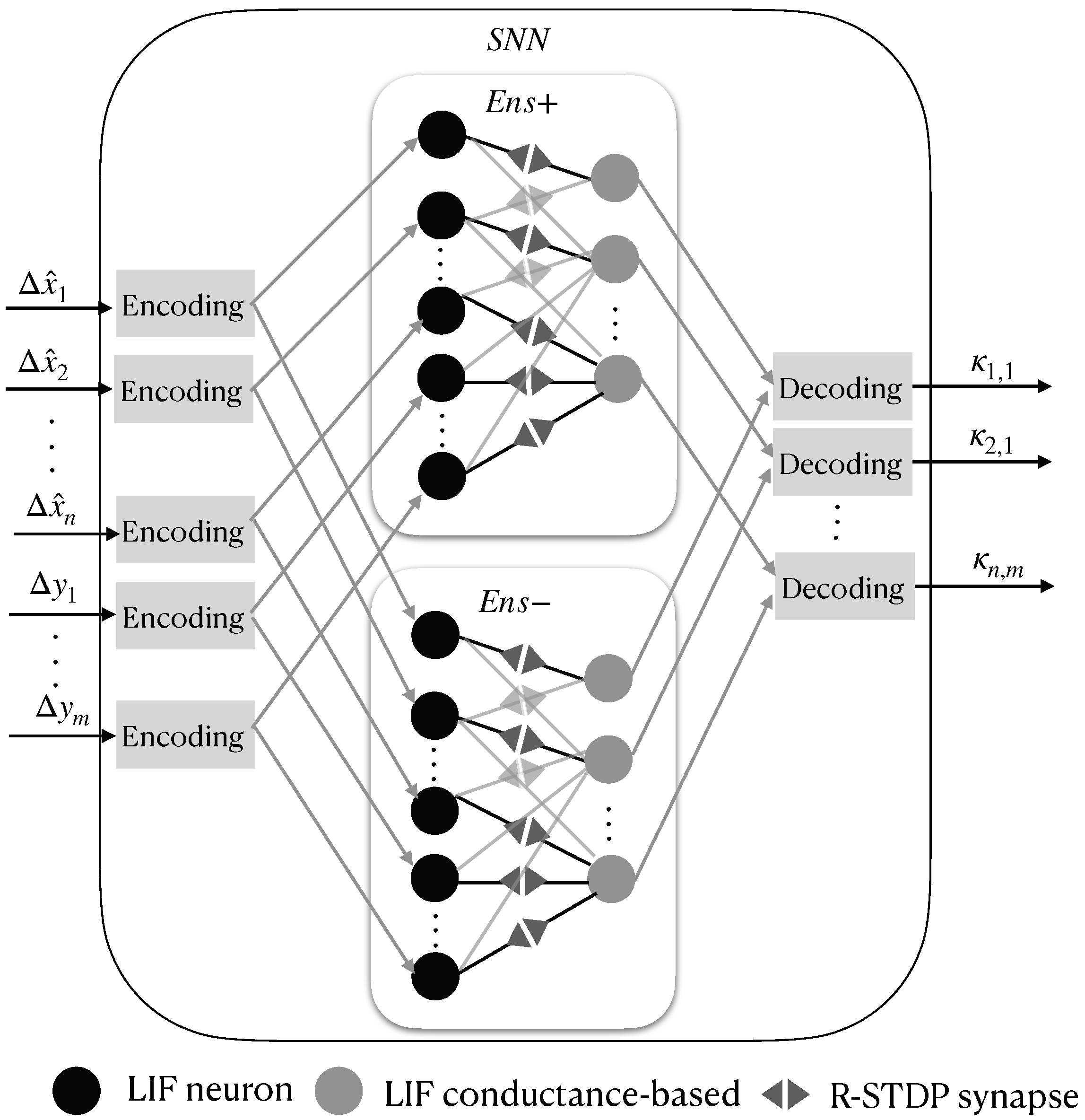
2.6. Proposed Kalman-Filtering SNN Structure
An SNN structure of an EKF that replaces Equations (
23), (
24), and (
28) is shown in
Figure 4. First, the error between the current and prior estimations is defined for all of the space–state variables:
Then,
and
are stacked into an input vector
for the SNN as follows:
This vector is encoded using Equation (
13), which produces excitatory input current vectors for two ensembles of neurons inside the SNN, which are called
and
, and they spike for increasing and decreasing input signals, respectively. Both ensembles count with two densely connected LIF neuron layers—the
j-th layer with
neurons, which is modeled by Equation (
1), and the
k-th layer with
LIF neurons, which is modeled by Equations (
1) and (
4). These are connected by
RSTDP synapses, as depicted in Equations (
11) and (
12), with the reward signal set to
. The spikes of the
k-th layer from
and
are finally decoded with Equation (
16) to obtain each value of the Kalman gain matrix in order to properly reconstruct the full state vector of the system.
Figure 5 shows the described SNN structure.
3. Results
In order to show the performance of the proposal, two nonlinear systems were used. For each system, the nonlinear equations were simulated to create noiseless ground-truth data
. Then, the resulting vector was noised as described in (
17) and (
18) by setting
with the diagonal covariance matrices
as follows:
where
would imply that the state noise and the observation noise have the same variance, i.e.,
. The resulting contaminated data then corresponded to a system with noisy measurements and unknown perturbations. The simulation was intended to compare the performance of a standard EKF against the SNN proposal under equal conditions; that is, only noisy measurements were provided. The SNN had to be able to recover this information, while for the EKF,
were set as identity matrices, as these were supposed to be unknown.
To create the system’s synthetic data, as the used models were shaped with
, the solution of the nonlinear system could be expressed as a Taylor series expansion with five terms, as in [
7], assuming that for a small timestep
,
. By doing this, we obtained a system that shaped as described in Equation (
17).
For the SNN, the neuron parameters in
Table 1 were used. The synapse, encoding/decoding, and simulation parameters are found in
Table 2. The synapses were randomly initialized in the range of
. To display the neural activity, the observed spike frequency for each neuron
was computed as follows:
where
counts how many spikes were produced inside a period of length
ms. The procedure was repeated for the whole simulation timeline of
s, with simulation a timestep of
s.
The simulation scripts were coded from scratch using Python (v+3.8) [
30] and the Numpy (v+1.20) and Sympy (v+1.8) [
31] libraries. However, during our testing, the Lorenz system’s SNN network was also coded using the SNNtorch (v+0.5.3) library [
32]. The resulting code is available in the Data Availability Statement section.
3.1. Van der Pol Simulation
Proposed by electrical engineer and physicist Balthasar Van der Pol, this nonlinear model is used to find oscillations on electric circuits using vacuum tubes, and it can be written in the
form as follows:
where
refers to the damping strength of the oscillations. For this test, we set our output to
, that is, only
was available for the measurement, while
was set to be recovered from the system.
Figure 6a shows a correct estimation of
. This can also be seen in the difference
shown in
Figure 6b. The
matrix values estimated by the SNN are displayed in
Figure 6c; these were obtained by using the spikes of the output layer. The evolution of the synaptic weight is also shown for both ensembles (
,
) in
Figure 6d,e, respectively. While the SNN’s estimation became noisier as the time moved forward, it can be seen in
Figure 6f that the EKF was not able to properly reconstruct the missing states at any point.
3.2. Lorenz System Simulation
A typical dynamic system for testing the obtention of unknown or partial dynamics is the Lorenz attractor, which is composed of the following nonlinear dynamics:
For this system, the EKF can be implemented by using five Taylor series approximation terms, as in [
7]. In this test, we set the output to
, which meant that only the
state was available for measurement. Therefore,
should be recovered.
Figure 7a shows the estimation of
. The error
is shown in
Figure 7b for the three states. The
matrix values estimated by the SNN are displayed in
Figure 7c. The weight evolution is also shown for both ensembles (
,
) in
Figure 7d,e, respectively. In this test, while the error estimation converged to close to zero for the three states (
Figure 7b),
Figure 7f shows that the EKF quickly diverged to infinity at
s due to the missing noise characterization of the system.
4. Discussion
A proper full state reconstruction of the space state was achieved. However, some considerations should be addressed. On the one hand, in the KalmanNet structure, the intention being the usage of GRUs is to use them as storage for the internal ANN’s memory
in order to jointly track the underlying second-order statistical moments required for implicitly computing the KG [
7]. In our SNN proposal, the intention is to replace them with the eligibility traces defined by the RSTDP weight update mechanism (Equation (
11)), as
E collects the weight changes proposed by STDP; thus, they represent the potentiation/degradation tendency of the synaptic weight [
8].
The energy consumption of an SNN relies on the spiking activity. Therefore, only the necessary spikes should be performed to represent our signals. Rate-based encoding mechanisms return a constant excitatory input current for a constant input signal (no matter its magnitude), resulting in spiking activity for non-changing signals. In temporal encoding schemes, such as the one used in this work, the neurons are only excited based on the rate of change in the input signal. The introduction of Equations (
13) and (
14) is intended to restrain the excitatory input current of the neurons to minimum and maximum values. In the range of
, for high rates of change, the maximum input current is
; according to Equation (
7) and the neuron parameters in
Table 1, this would correspond to a spike frequency of
Hz for a maximum input current of
. This can be seen in the resulting spike frequency graphs for both the Van der Pol and Lorenz tests (see the Data Availability section).
However, while the neuron parameters were selected to resemble biological plausibility, proper selection of the encoding/decoding sensibility and the values of the learning rates is fundamental. should proportionate enough to to produce a suitable spiking activity, though selecting sufficiently high values should appropriately modify the synaptic weights with the supplied spikes. Low learning rates may require a higher spike frequency but a higher precision, leading to slow convergence. In contrast, high learning rate values require less spiking activity but lead to a lower precision, which may result in divergence. In addition, to translate this SNN structure into a hardware implementation, the min/max synaptic weight values might be restricted to the observed values in available memristive devices.
A mathematical convergence analysis would determine the boundary conditions for selecting proper parameters. However, the LIF reset condition makes this dynamic non-differentiable, which disables this analysis or the adaptation of back-propagation for SNNs. A way to deal with this is to move the analysis to the frequency domain by solving the LIF model and obtaining the tuning curve produced by Equation (
7) and its corresponding graph (
Figure 1b). It can be seen that the function only is differentiable in the range of
. In [
15], the authors used a polynomial differentiable tuning curve (which can be obtained through least square regression) to avoid this restriction. In this work, the introduction of bounded and differentiable encoding/decoding functions and the usage of two (
) neuron ensembles allowed the usage of this approximation to be avoided, as the dynamics of
are only affected by the growth of input signals, while for
, only the decay is processed, thus creating a switching dynamical system [
33] that might allow us to propose a Lyapunov candidate function whose derivative is negatively defined.
5. Conclusions and Future Work
An SNN-embedded architecture inside the extended Kalman filter algorithm was used to perform the full state recovery of a nonlinear dynamic system based on partial knowledge while assuming unknown but bounded perturbations. Numerical simulations showed the feasibility of the system. While in other works, the encoding/decoding process was performed by using a function approximation relating the input current with the spike frequency, the proposed modifications allow this to be avoided by setting a switched current designation that lets each ensemble of neurons and their respective synapses evolve towards the growth/decay of the SNN input signals while bounding the excitatory input current, thus limiting the spike frequency.
In order to move towards a hardware construction, neuron design with a very large scale of integration (VLSI), the replacement of synapses with memristive devices, and a VLSI design of the encoding/decoding modules would define the building blocks for a system-on-a-chip proposal. However, moving to a hardware implementation in currently available technologies might lead to modifications, such as changes in the values of the memristive range or achievable spike frequencies. Therefore, a framework for mathematical convergence analysis should be defined to study the SNN’s performance with these new parameters. Nonetheless, it was shown that a few resources (in terms of the number of neurons, synapses, and energy consumption) were able to achieve proper performance by taking advantage of existing explainable PINN architectures.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}