
SGGformer: Shifted Graph Convolutional Graph-Transformer for Traffic Prediction



Abstract
:1. Introduction
- This paper constructs a prediction network that integrates a shifted window operation, GCN, and Transformer models, namely Shifted Graph Convolutional Graph-Transformer (SGGformer). GCN realizes complex spatial correlation characteristics extraction, and Graph Transformer extracts the nonlinear temporal correlation characteristics;
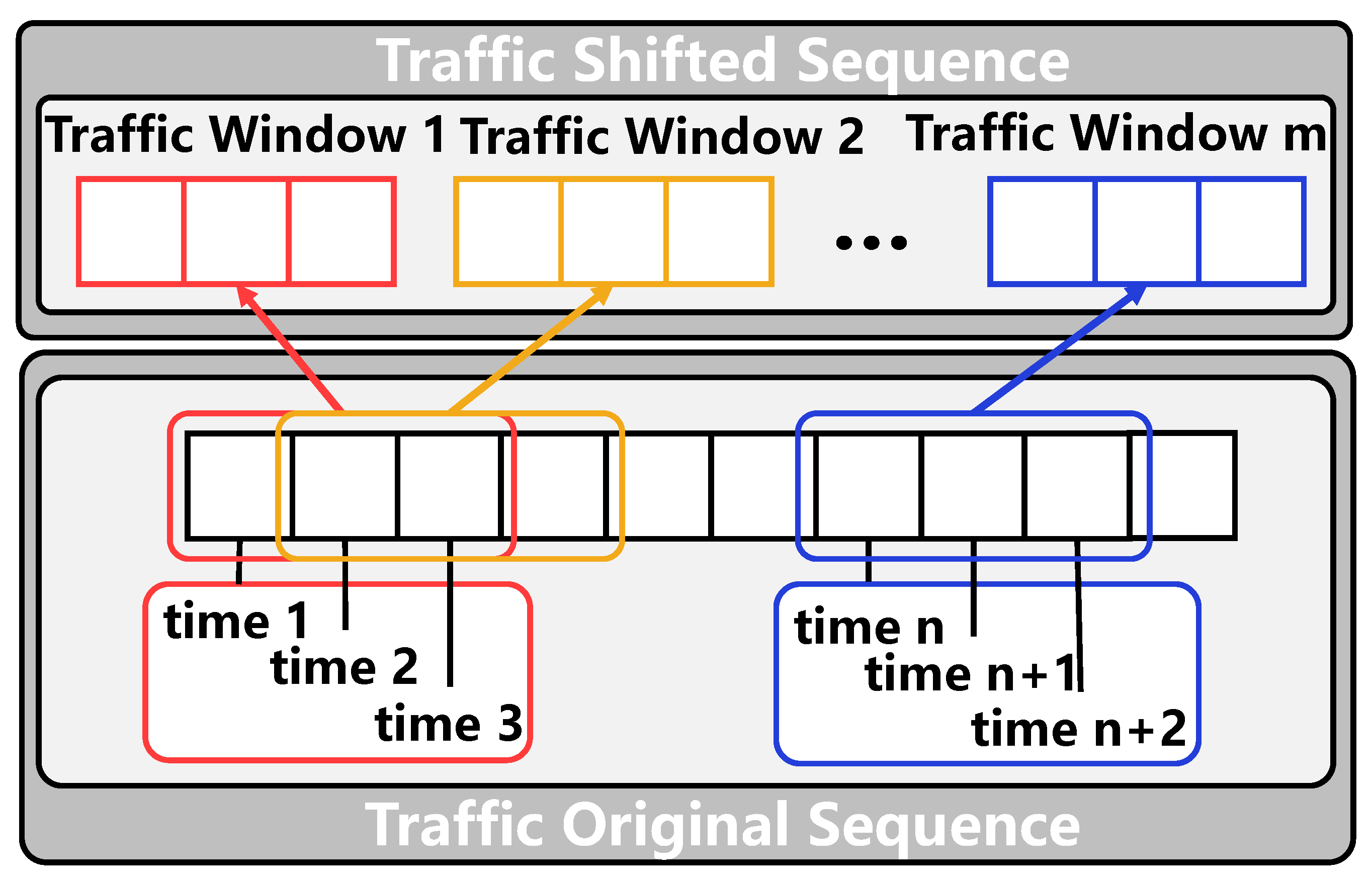
- The shifted window operation is developed to divide time segments, reduce computational complexity, and enhance the ability to capture features of different periods;
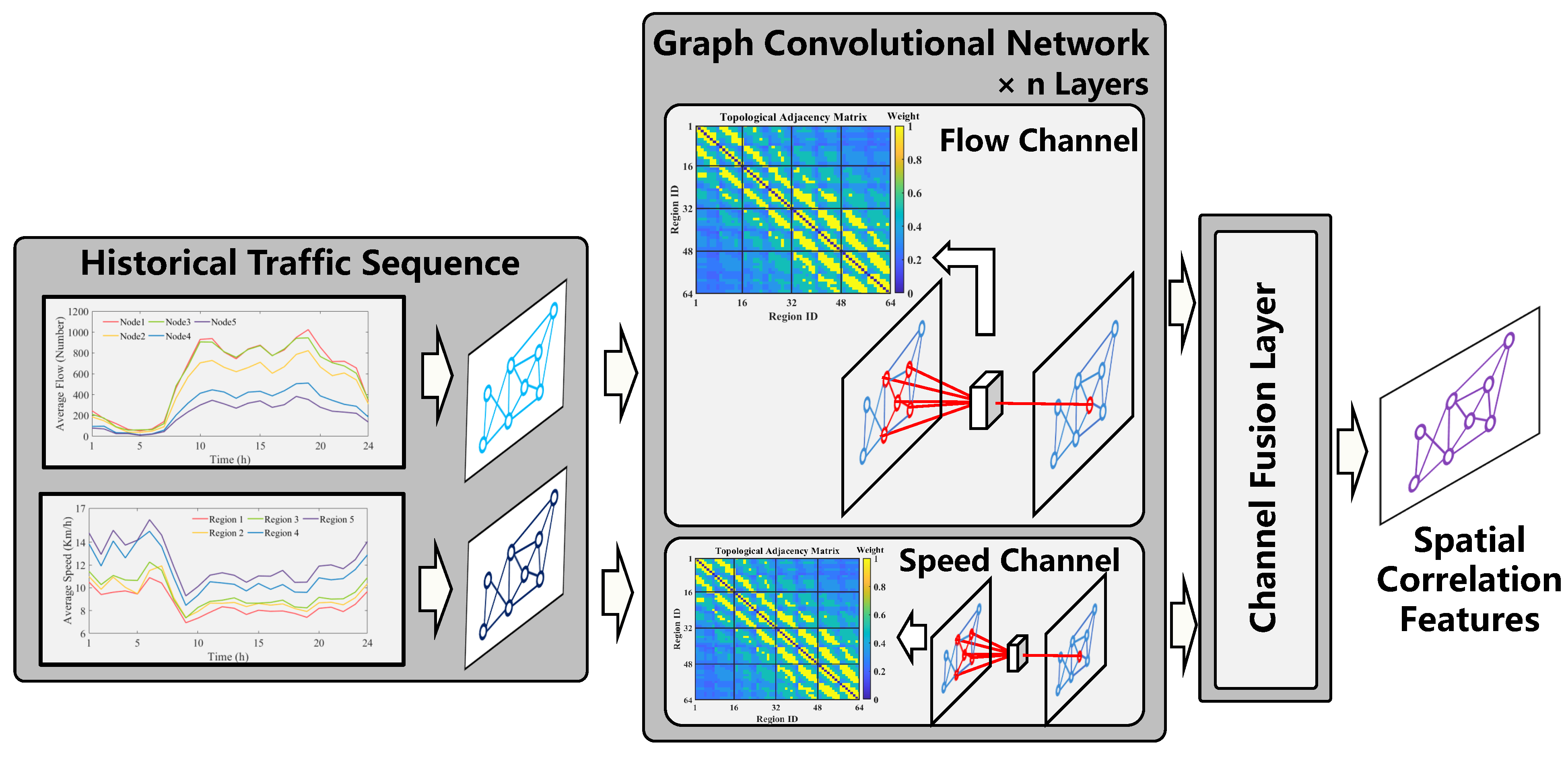
- The regional relationship with the graph network is defined, and the aggregation and mapping of regional nodes under the definition of a topology network is completed based on a multi-channel GCN;
- The improved Graph Transformer is used to process high-dimensional graph data. The generative decoder outputs long sequences in a single step to avoid cumulative errors and significantly reduce reasoning speed.
2. Related Works
2.1. Spatial Correlation Extraction
2.2. Temporal Correlation Extraction
3. Methodology
3.1. Problem Definition
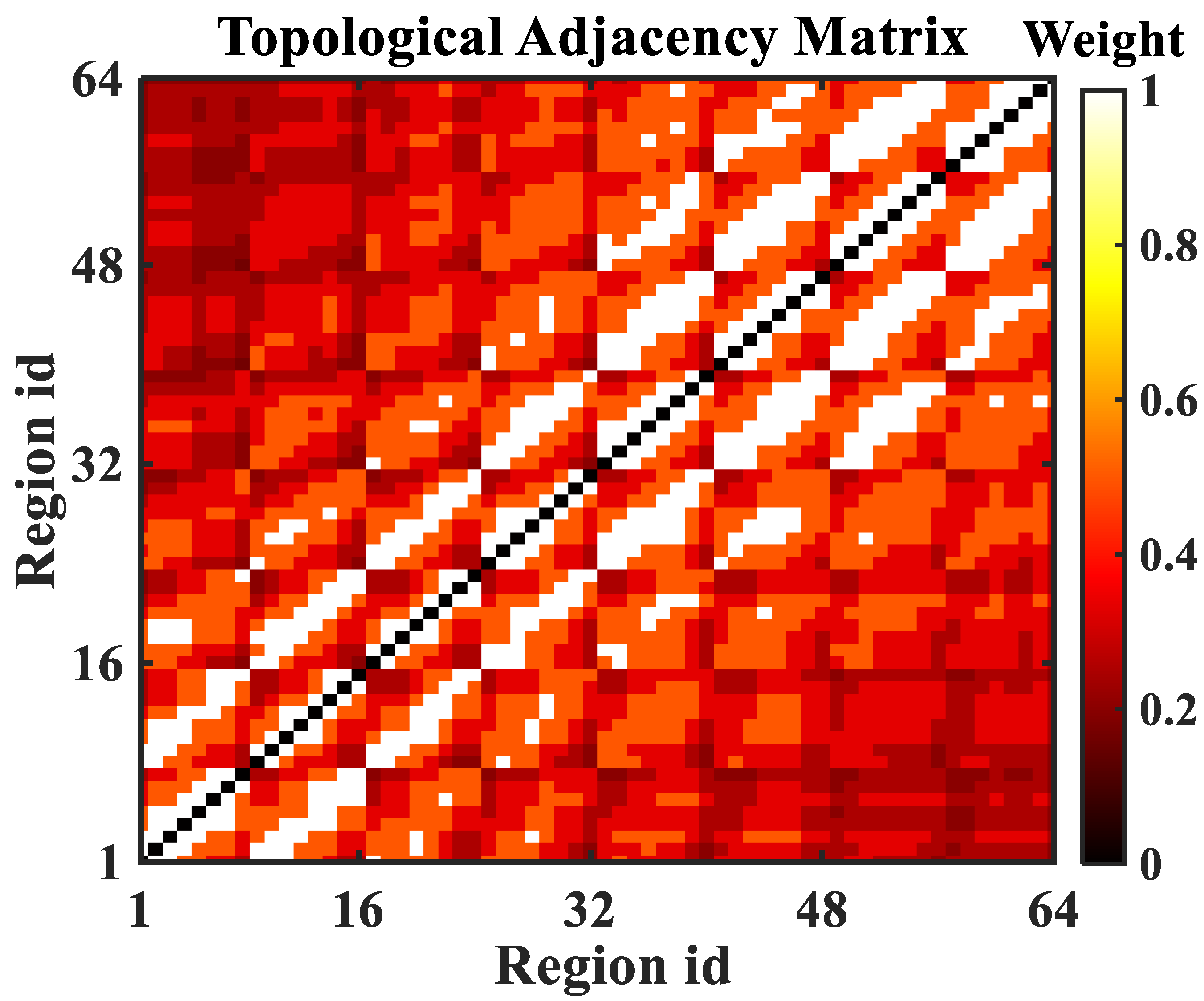
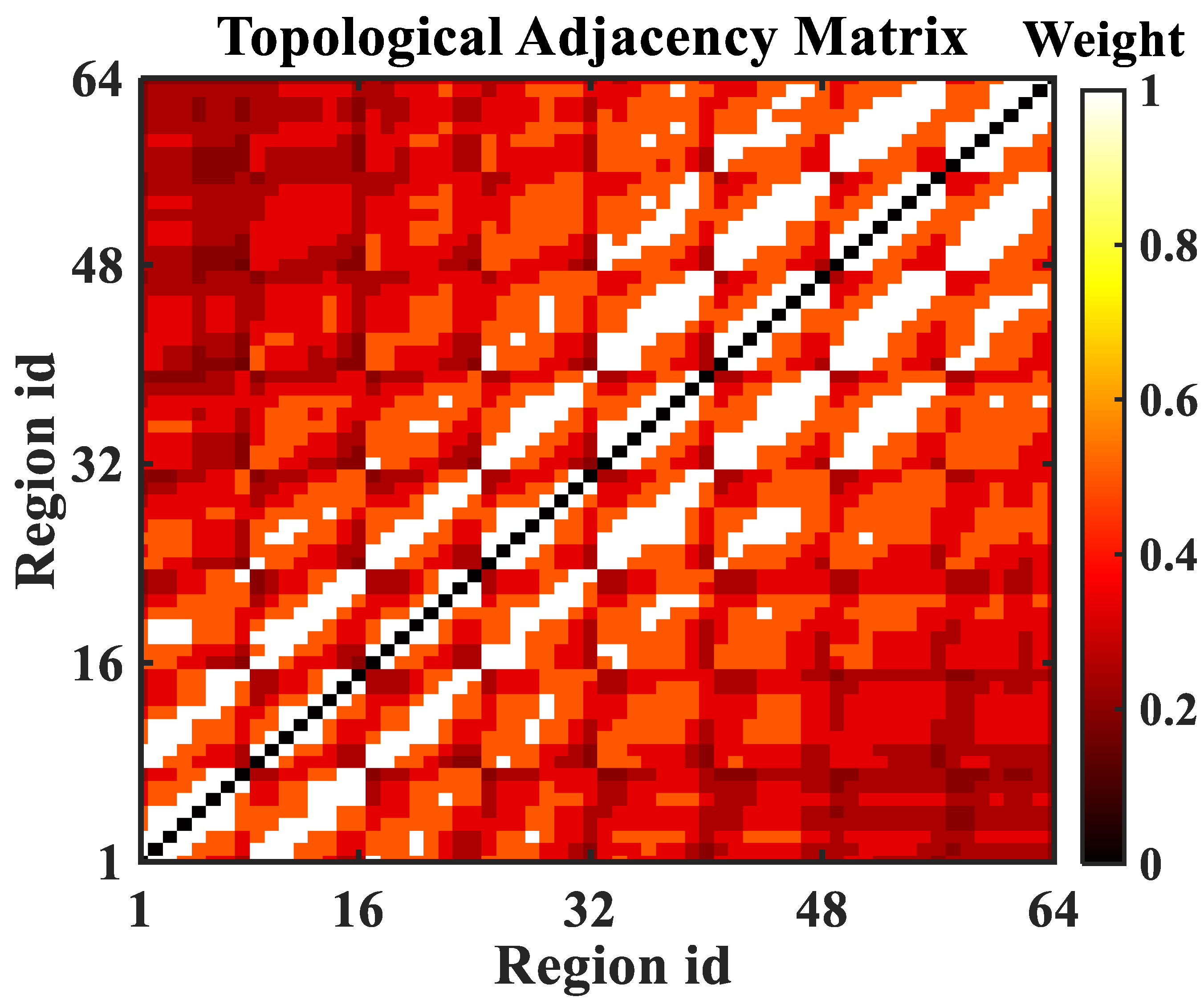
3.1.1. Definition 1: Regionally Topological Graph Network
3.1.2. Definition 2: Spatiotemporal Sequences
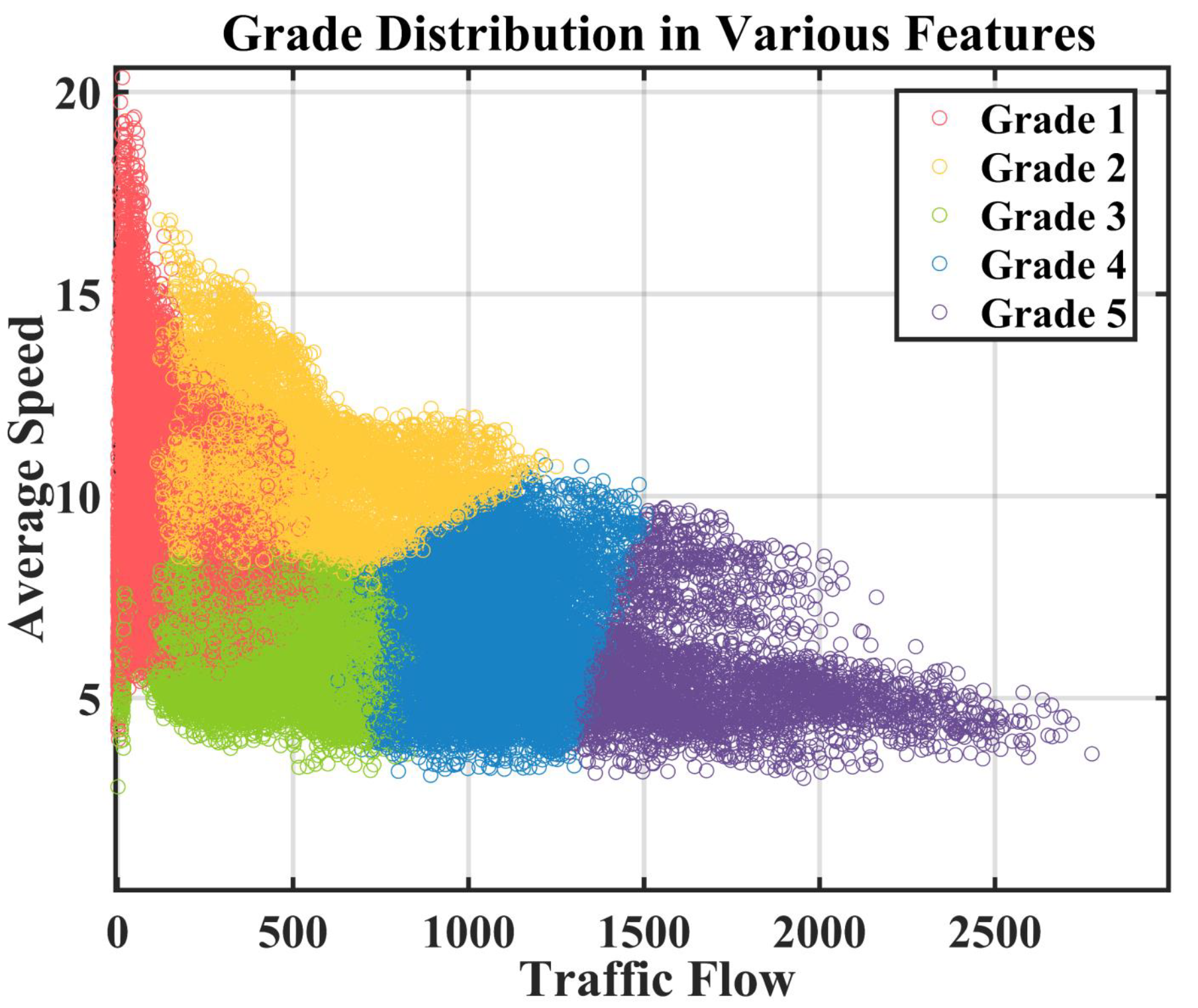
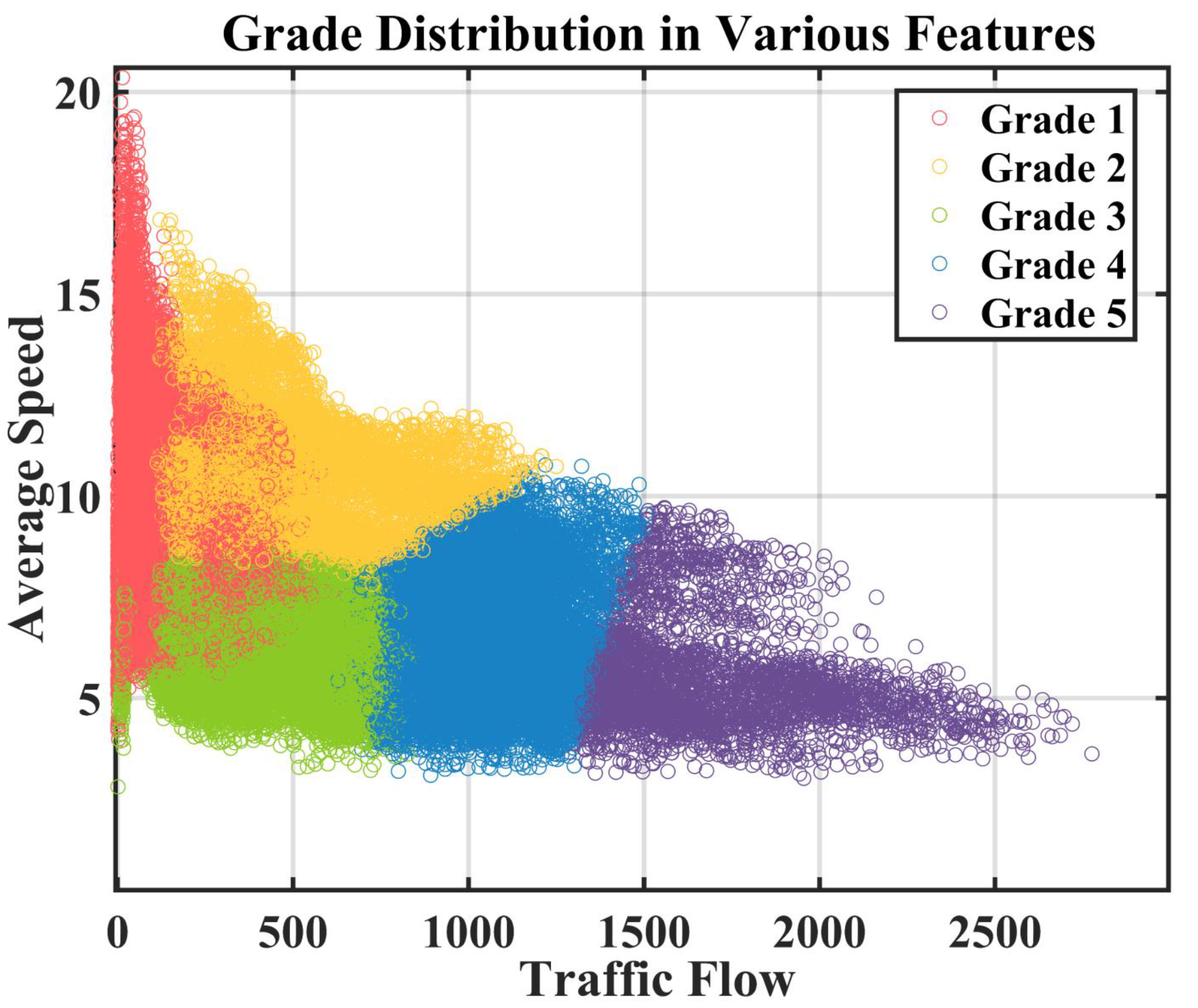
3.1.3. Definition 3: Traffic Grades
3.1.4. Definition 4: Traffic Prediction Task
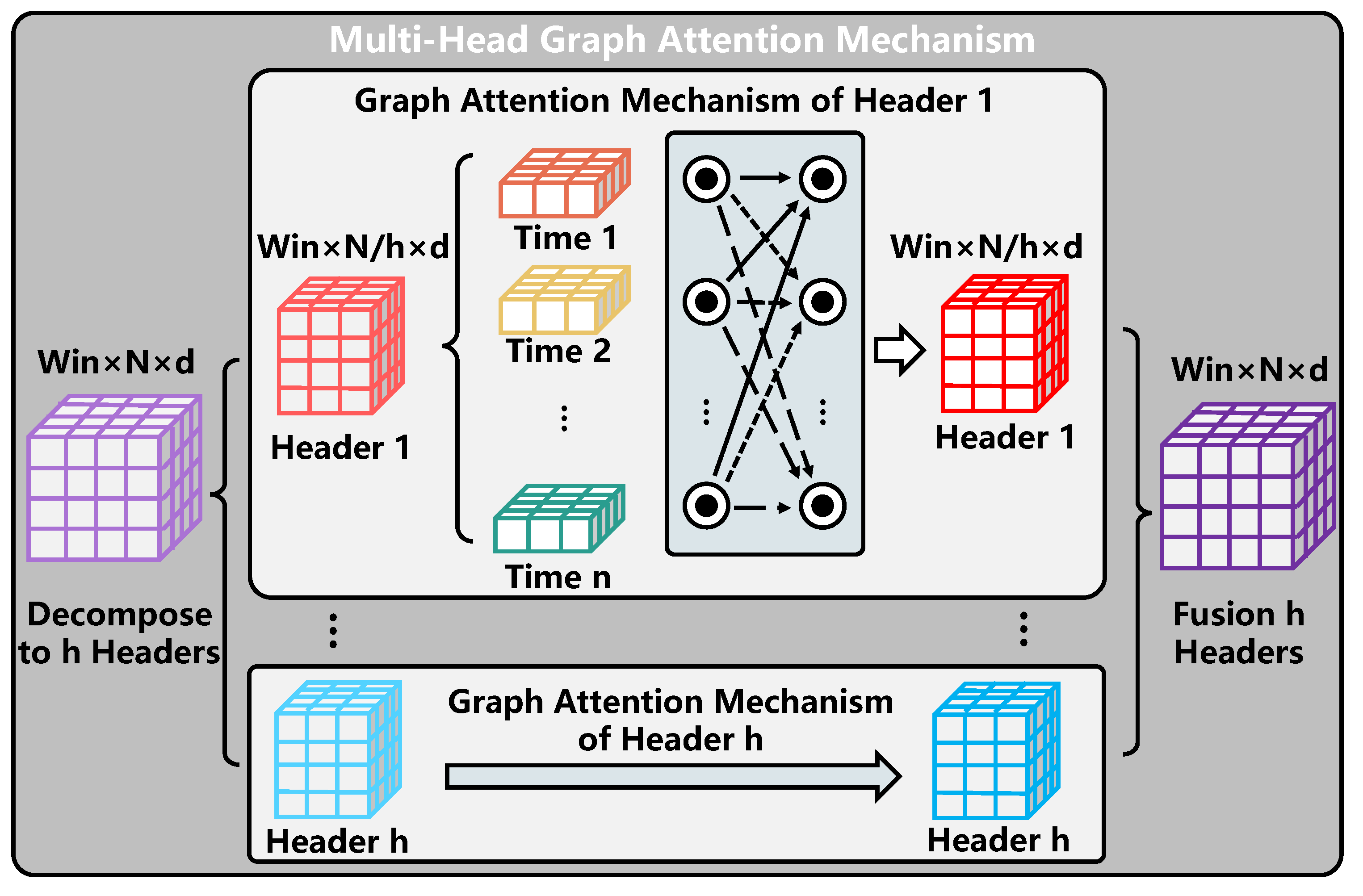
3.2. SGGformer
3.2.1. Shifted Window Operation
3.2.2. Spatial Correlation Modeling
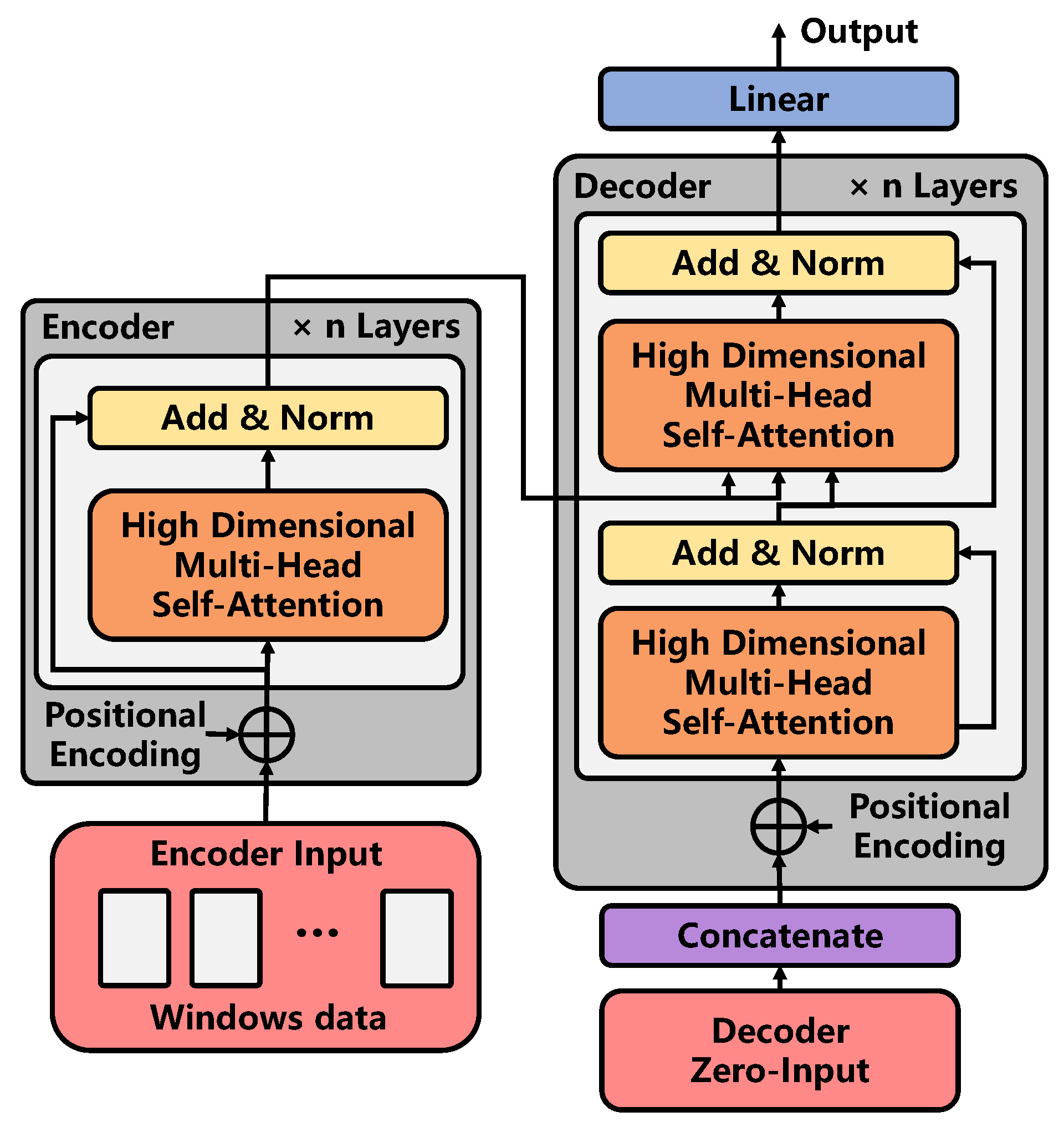
3.2.3. Temporal Correlation Modeling
- The encoder and decoder are composed of high-dimensional self-attention modules with residual connections. The purpose of constructing that module is to directly extract the time characteristics of multi-dimensional graph data obtained from graph convolution;
- In the decoder part, thanks to the inspiration of Informer [30], its generative decoder can output an extended sequence in a single step by inputting an input with zero occupation, thus avoiding cumulative error and greatly reducing the reasoning speed.
3.2.4. Loss Function
4. Experiment
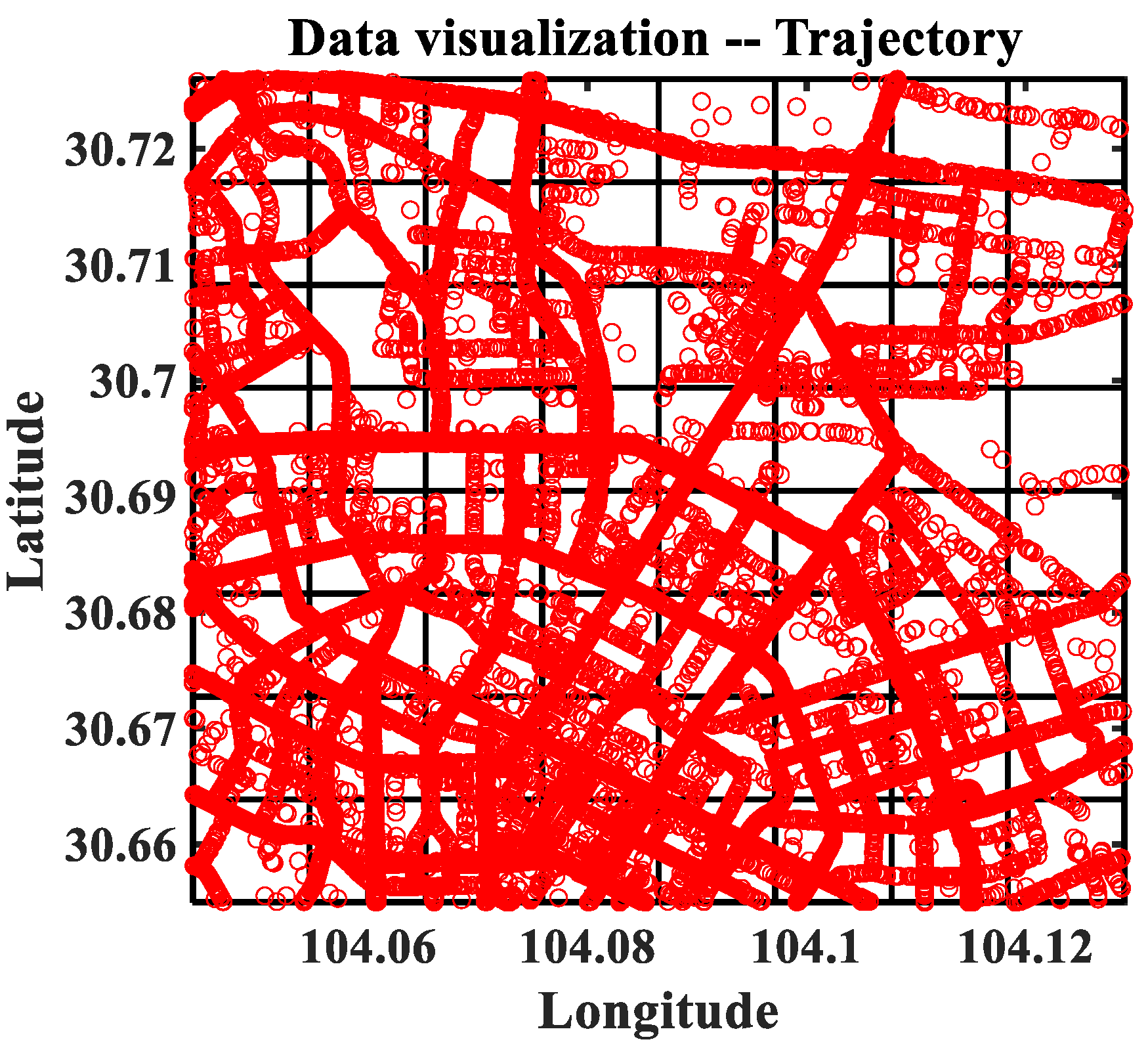
4.1. Data Description and Preprocessing
4.2. Assessment Indicators and Baseline Model
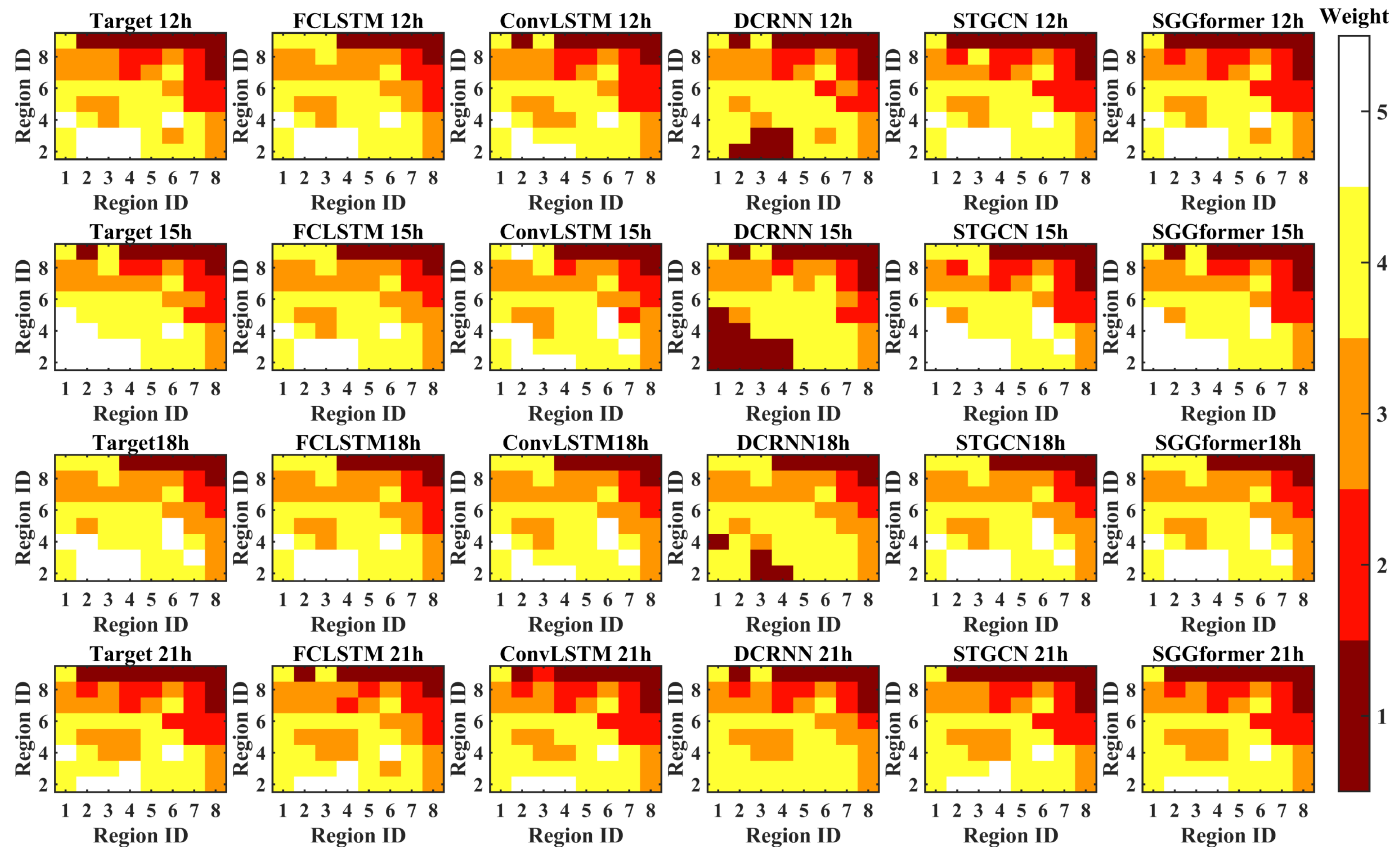
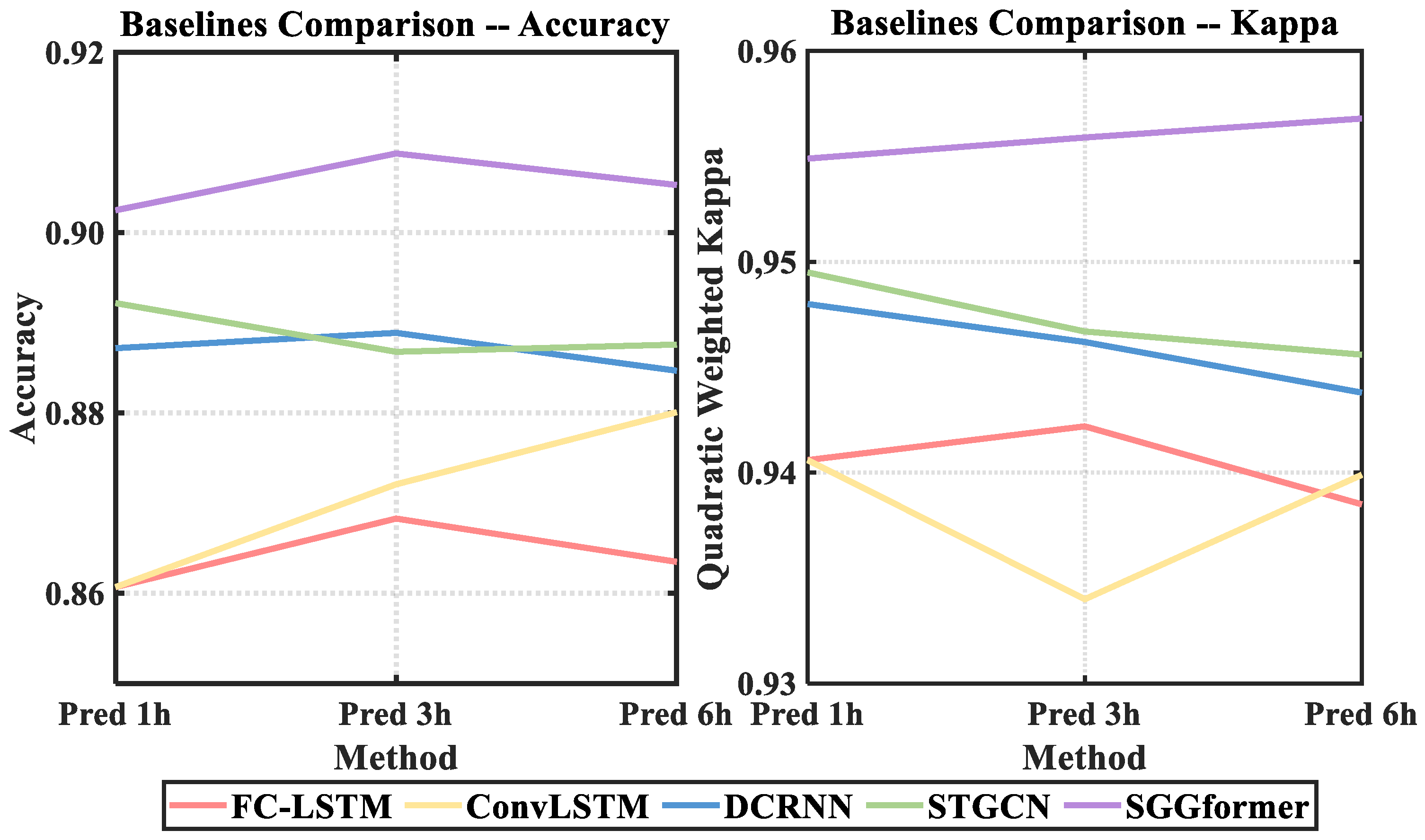
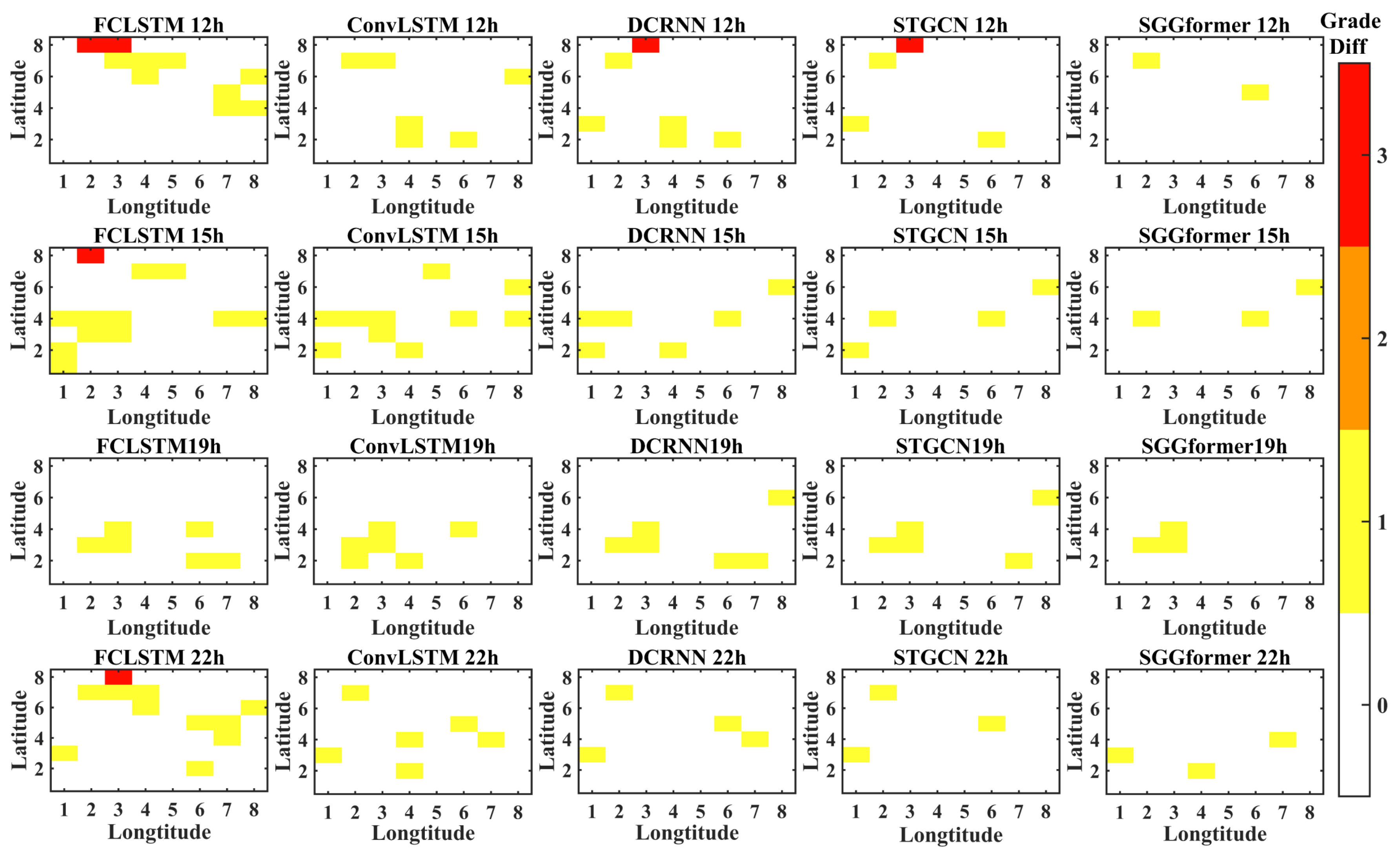
4.3. Comparison with Baseline
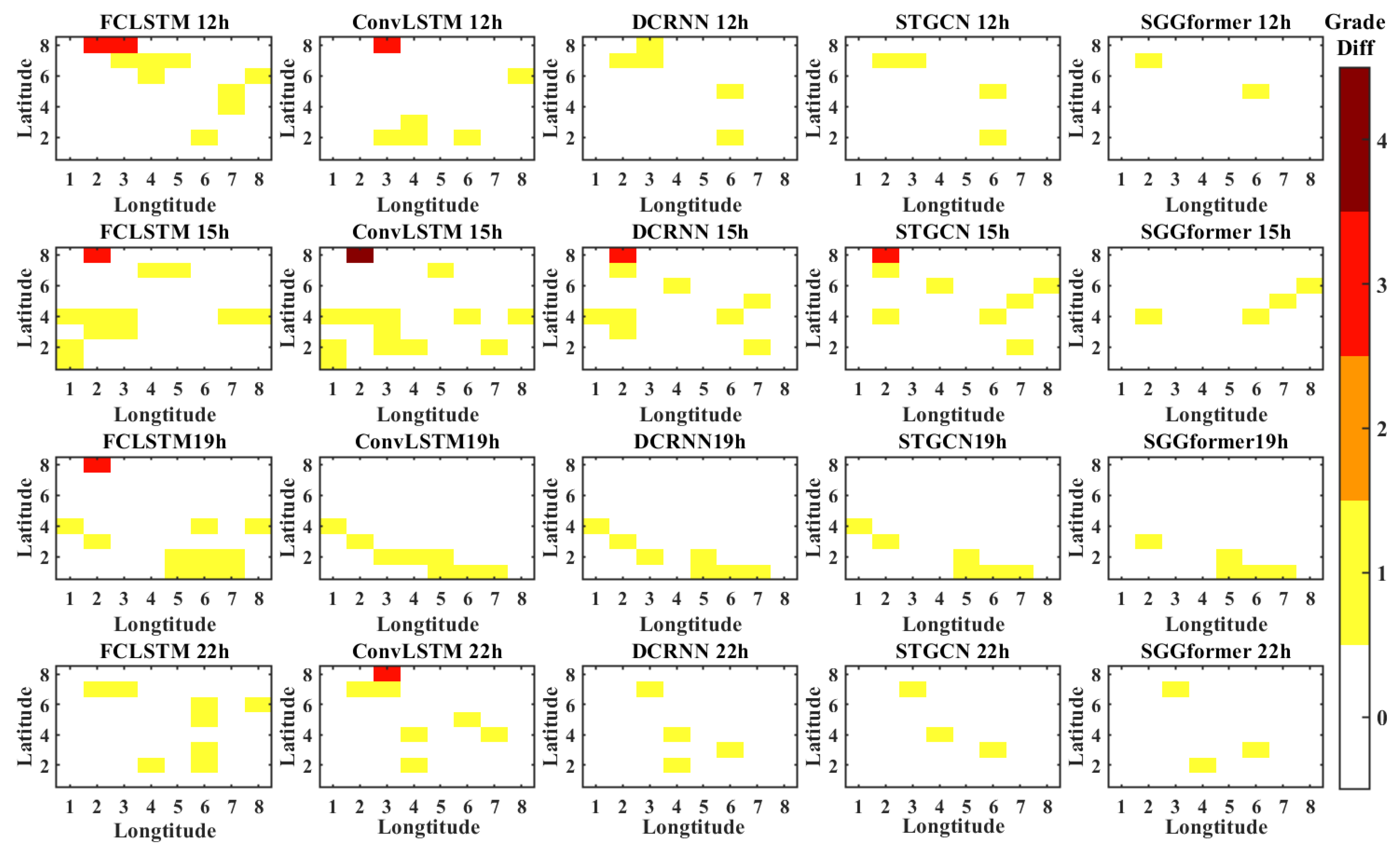
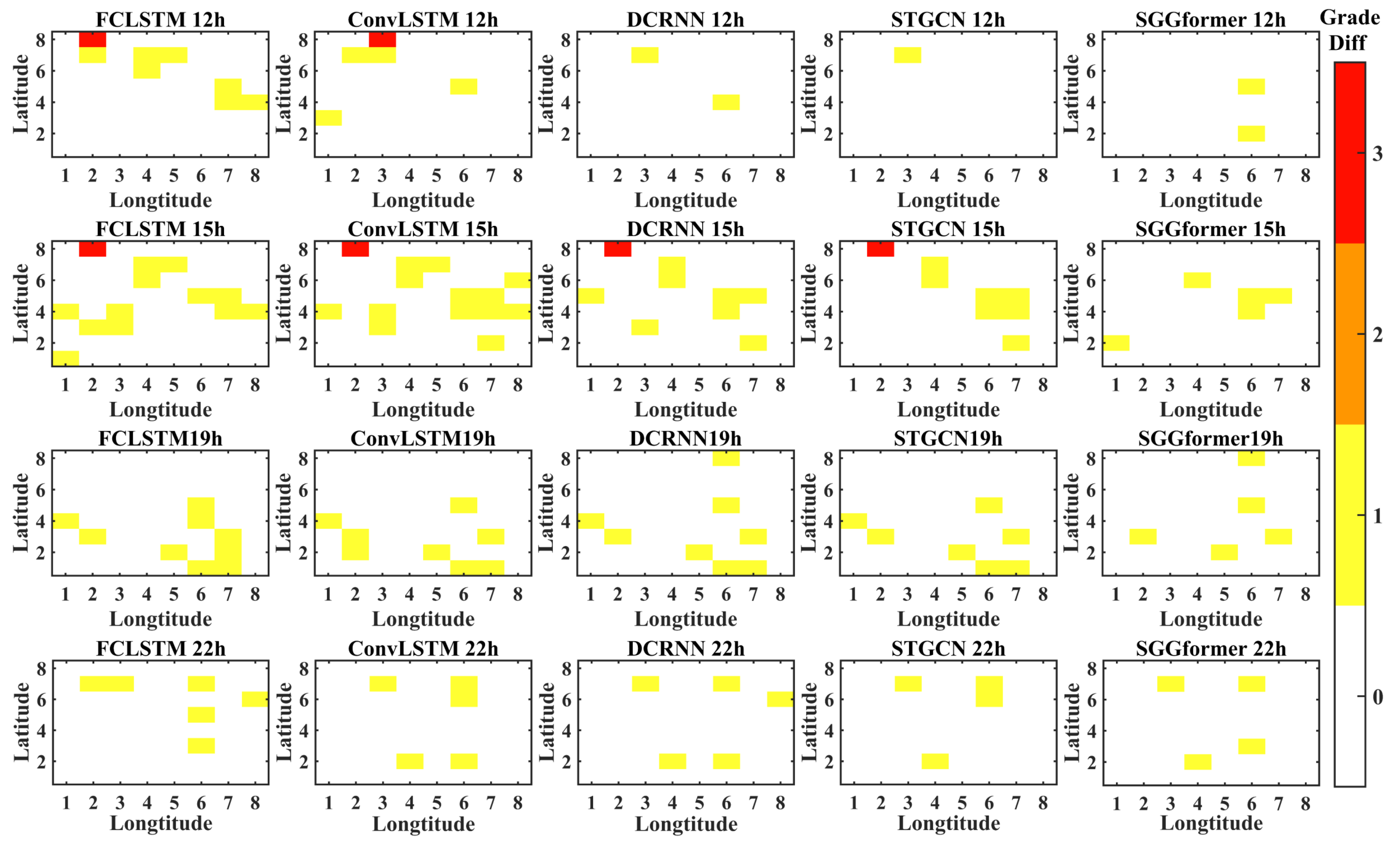
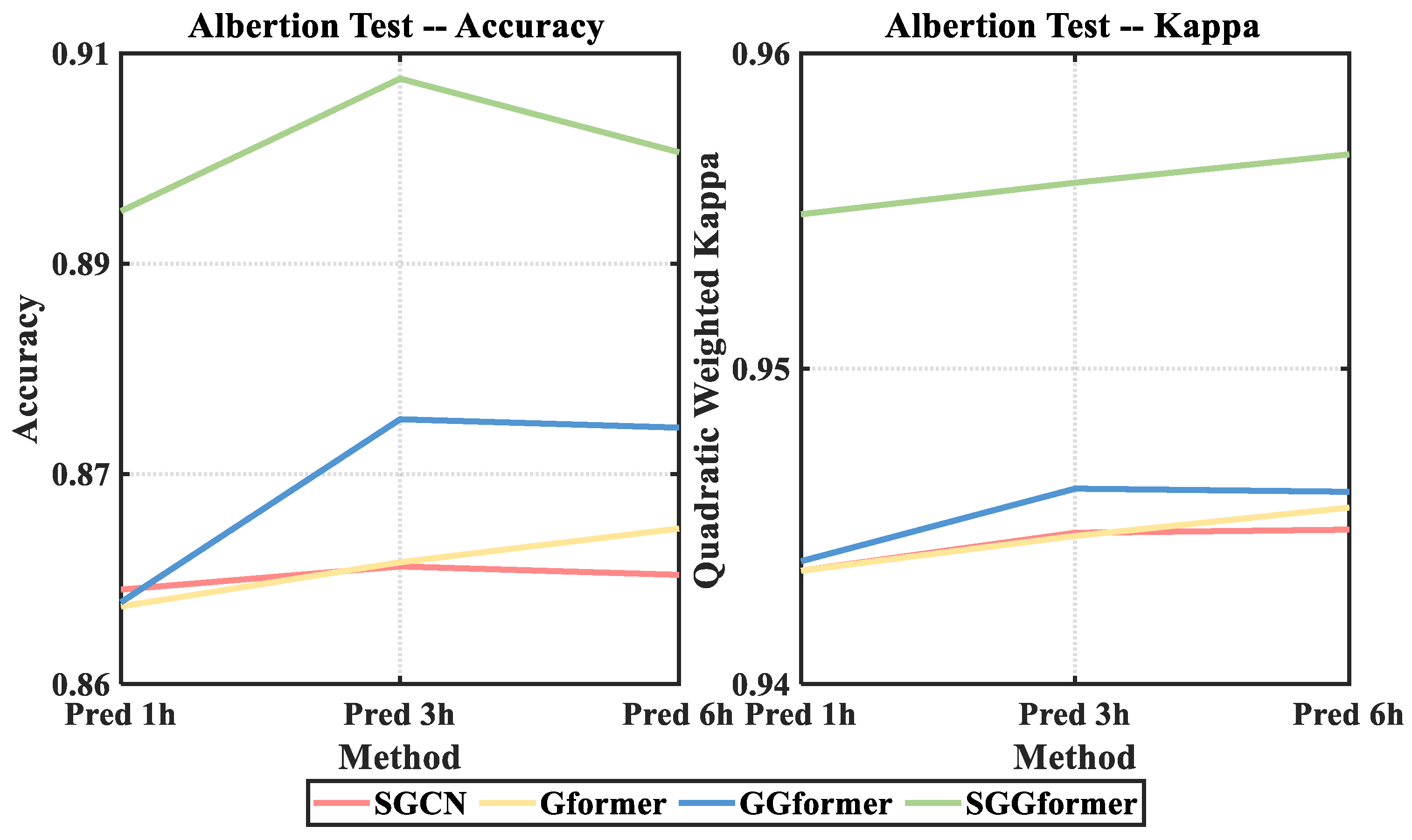
4.4. Ablation Research
- Based on SGGformer, the shifted window operation is removed, specifically, GCN combines Graph Transformer to build a model to verify the rationality of the shifted window;
- The GCN based on SGGformer is removed, specifically, the GCN is directly input into the Graph Transformer network after the shifted window to verify the effectiveness of GCN for spatial feature capture;
- The Graph Transformer based on the SGGformer is detached, specifically, SGCN is simply utilized to verify the rationality of the Graph Transformer.
5. Discussion
- It can be seen from the baseline comparison results that the graph convolution based on the sliding window combined with Graph Transformer is effective. Precisely, graph convolution can effectively capture the non-European spatial correlation characteristics in the traffic data, and Graph Transformer has greater advantages in capturing nonlinear temporal correlation of the traffic data. STGCN, also a spatiotemporal property acquisition network based on a graph convolution network, shows a slightly weaker performance, indicating that GCN is more appropriate in spatial correlation properties. However, compared with the use of a Graph Transformer to capture temporal-related characteristics, STGCN and DCRNN use Gated convolution and GRU to extract features, respectively, which shows some shortcomings in performance. Compared with the former, ConvLSTM and FC-LSTM both use the capture time characteristics of LSTM, showing poorer prediction performance. The difference between the two is that the former uses ordinary convolution to capture European spatial characteristics. In contrast, the latter uses a simple, fully connected network to capture spatial correlation characteristics. Simply flattening regions undoubtedly ignores the spatial relationship between regions, resulting in a relatively worse prediction effect.
- The comparison results of ablation experiments verify the effectiveness of different components of SGGformer. The G-Gformer cancels the shifted window operation, the S-Gformer deletes the GCN model and extracts the temporal-dependent characteristics through the Graph Transformer, while S-GCN uses the spatial feature extraction model for traffic prediction. The prediction effect of all variants is worse than that of all SGGformers, which proves that the three components contribute to improving the prediction effect. Among them, the prediction effect of the G-Gformer is second only to SGGformer in prediction performance, which is reasonable. Because this variant only removes the operation of the shifted window operation, it can still effectively extract spatial and temporal correlations in traffic data. However, it lacks the division of time phase by the shifted window, thus reducing specific performances. The S-Gformer and S-GCN are canceled, respectively, from the space extraction module and time extraction module, which significantly reduces the feature extraction ability for traffic data, thus showing the worst performance. By comparing the two, the S-Gformer is slightly better than S-GCN, which means that the time feature extracted by the Graph Transformer is more effective than the spatial feature extracted by GCN for traffic prediction.
- In this paper, the spatial feature extraction network, GCN, uses a fixed adjacency matrix to extract spatial features and does not fully consider the impact of time-varying traffic flow on space.
- This paper mainly finds that the performance of the Seq2Seq architecture is not fully utilized for traffic grade prediction at a particular time in the future. That is, the multi-step prediction task in the future is not involved.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ITS | Intelligent Transportation System |
| CNN(s) | Convolutional Neural Network(s) |
| GCN(s) | Graph Convolutional Network(s) |
| SVM | Support Vector Machine |
| ANN | Artificial Neural Network |
| RNN | Recurrent Neural Network |
| LSTM | Long Short Term Memory Neural Network |
| GRU | Gated Recurrent Unit |
| NLP | Natural Language Processing |
| Seq2Seq | Sequence-to-Sequence |
| GNN | Graph Neural Network |
| SOM | Self-Organizing Mapping Neural Network |
| STGCN | Spatial Temporal Graph Convolutional Networks |
| DCRNN | Diffusion Convolutional Recurrent Neural Network |
| STSGCN | Spatial-Temporal Synchronous Graph Convolutional Network |
| ASTGCN | Attention Based Spatial-Temporal |
| GAT | Graph Attention Network |
| TSTNet | Sequence to Sequence Spatial-Temporal Traffic Prediction model |
| T-MGCN | Temporal Multi-Graph Convolutional Network |
References
- Zhang, Y.; Chu, L.; Ou, Y.; Guo, C.; Liu, Y.; Tang, X. A Cyber-Physical System-Based Velocity-Profile Prediction Method and Case Study of Application in Plug-In Hybrid Electric Vehicle. IEEE Trans. Cybern. 2021, 51, 40–51. [Google Scholar] [CrossRef] [PubMed]
- Piro, G.; Cianci, I.; Grieco, L.; Boggia, G.; Camarda, P. Information centric services in Smart Cities. J. Syst. Softw. 2014, 88, 169–188. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Z.; Li, G.; Liu, Y.; Huang, Y.; Cunningham, G.; Early, J. Integrated Velocity Prediction Method and Application in Vehicle-Environment Cooperative Control Based on Internet of Vehicles. IEEE Trans. Veh. Technol. 2022, 71, 2639–2654. [Google Scholar] [CrossRef]
- Niu, K.; Cheng, C.; Chang, J.; Zhang, H.; Zhou, T. Real-Time Taxi-Passenger Prediction with L-CNN. IEEE Trans. Veh. Technol. 2019, 68, 4122–4129. [Google Scholar] [CrossRef]
- Qiu, J.; Du, L.; Zhang, D.; Su, S.; Tian, Z. Nei-TTE: Intelligent Traffic Time Estimation Based on Fine-Grained Time Derivation of Road Segments for Smart City. IEEE Trans. Ind. Informatics 2020, 16, 2659–2666. [Google Scholar] [CrossRef]
- Lv, Z.; Lou, R.; Singh, A.K. AI Empowered Communication Systems for Intelligent Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2021, 22, 4579–4587. [Google Scholar] [CrossRef]
- Xu, F.; Lin, Y.; Huang, J.; Wu, D.; Shi, H.; Song, J.; Li, Y. Big Data Driven Mobile Traffic Understanding and Forecasting: A Time Series Approach. IEEE Trans. Serv. Comput. 2016, 9, 796–805. [Google Scholar] [CrossRef]
- Zhao, J.; Sun, S. High-Order Gaussian Process Dynamical Models for Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2014–2019. [Google Scholar] [CrossRef]
- Xu, Y.; Kong, Q.J.; Klette, R.; Liu, Y. Accurate and Interpretable Bayesian MARS for Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2457–2469. [Google Scholar] [CrossRef]
- Liu, F.; Wei, Z.C.; Huang, Z.S.; Lu, Y.; Hu, X.G.; Shi, L. A Multi-Grouped LS-SVM Method for Short-term Urban Traffic Flow Prediction. In Proceedings of the IEEE Conference and Exhibition on Global Telecommunications (GLOBECOM), Big Island, HI, USA, 9–13 December 2019. [Google Scholar]
- Oh, S.d.; Kim, Y.j.; Hong, J.s. Urban Traffic Flow Prediction System Using a Multifactor Pattern Recognition Model. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2744–2755. [Google Scholar] [CrossRef]
- Toncharoen, R.; Piantanakulchai, M. Traffic State Prediction Using Convolutional Neural Network. In Proceedings of the International Joint Conference on Computer Science and Software Engineering, Nakhonpathom, Thailand, 11–13 July 2018. [Google Scholar]
- Yao, H.; Tang, X.; Wei, H.; Zheng, G.; Li, Z. Revisiting Spatial-Temporal Similarity: A Deep Learning Framework for Traffic Prediction. arXiv 2019, arXiv:1803.01254. [Google Scholar] [CrossRef] [Green Version]
- Wang, B.; Mohajerpoor, R.; Cai, C.; Kim, I.; Vu, H.L. Traffic4cast—Large-scale Traffic Prediction using 3DResNet and Sparse-UNet. arXiv 2021, arXiv:2111.05990. [Google Scholar]
- Jiang, W.; Luo, J. Graph neural network for traffic forecasting: A survey. Expert Syst. Appl. 2022, 207, 117921. [Google Scholar] [CrossRef]
- Ye, J.; Zhao, J.; Ye, K.; Xu, C. How to Build a Graph-Based Deep Learning Architecture in Traffic Domain: A Survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 3904–3924. [Google Scholar] [CrossRef]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. arXiv 2016, arXiv:1606.09375. [Google Scholar]
- Atwood, J.; Towsley, D. Diffusion-Convolutional Neural Networks. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting. arXiv 2017, arXiv:1709.04875. [Google Scholar]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting. arXiv 2017, arXiv:1707.01926. [Google Scholar]
- Song, C.; Lin, Y.F.; Guo, S.N.; Wan, H.Y.; Intelligence, A.A.A. Spatial-Temporal Synchronous Graph Convolutional Networks: A New Framework for Spatial-Temporal Network Data Forecasting. AAAI 2020, 34, AAAI-20. [Google Scholar] [CrossRef]
- Wu, Z.H.; Pan, S.R.; Long, G.D.; Jiang, J.; Zhang, C.Q. Graph WaveNet for Deep Spatial-Temporal Graph Modeling. arXiv 2019, arXiv:1906.00121. [Google Scholar]
- Guo, K.; Hu, Y.; Qian, Z.; Liu, H.; Zhang, K.; Sun, Y.; Gao, J.; Yin, B. Optimized Graph Convolution Recurrent Neural Network for Traffic Prediction. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1138–1149. [Google Scholar] [CrossRef]
- Xiao, Y.; Yin, Y. Hybrid LSTM Neural Network for Short-Term Traffic Flow Prediction. Information 2019, 10, 105. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Zhang, K.; Li, J.; Lin, X.; Yang, B. LSTM-based traffic flow prediction with missing data. Neurocomputing 2018, 318, 297–305. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.Y.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU neural network methods for traffic flow prediction. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar]
- Xu, M.; Dai, W.; Liu, C.; Gao, X.; Lin, W.; Qi, G.J.; Xiong, H. Spatial-Temporal Transformer Networks for Traffic Flow Forecasting. arXiv 2020, arXiv:2001.02908. [Google Scholar]
- Zhou, H.Y.; Zhang, S.H.; Peng, J.Q.; Zhang, S.; Li, J.X.; Xiong, H.; Zhang, W.C.; Intelligence, A.A.A. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. arXiv 2021, arXiv:2012.07436. [Google Scholar] [CrossRef]
- Bai, J.; Zhu, J.; Song, Y.; Zhao, L.; Hou, Z.; Du, R.; Li, H. A3T-GCN: Attention Temporal Graph Convolutional Network for Traffic Forecasting. ISPRS Int. J. Geo-Inf. 2021, 10, 485. [Google Scholar] [CrossRef]
- Guo, S.; Lin, Y.; Feng, N.; Song, C.; Wan, H. Attention Based Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting. In Proceedings of the National Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Song, X.Z.; Wu, Y.; Zhang, C.H. TSTNet: A Sequence to Sequence Transformer Network for Spatial-Temporal Traffic Prediction. In Proceedings of the International Conference on Artificial Neural Networks, Bratislava, Slovakia, 14–17 September 2021. [Google Scholar]
- Lv, M.; Hong, Z.; Chen, L.; Chen, T.; Zhu, T.; Ji, S. Temporal Multi-Graph Convolutional Network for Traffic Flow Prediction. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3337–3348. [Google Scholar] [CrossRef]
- Cao, J.; Guan, X.; Zhang, N.; Wang, X.; Wu, H. A Hybrid Deep Learning-Based Traffic Forecasting Approach Integrating Adjacency Filtering and Frequency Decomposition. IEEE Access 2020, 8, 81735–81746. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, Y.; Li, Z.; Wang, X.; Zhao, J.; Zhang, Z. Large-scale cellular traffic prediction based on graph convolutional networks with transfer learning. Neural Comput. Appl. 2022, 34, 5549–5559. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, Y.; Dong, S. Public Traffic Congestion Estimation Using an Artificial Neural Network. ISPRS Int. J. Geo-Inf. 2020, 9, 152. [Google Scholar] [CrossRef] [Green Version]
- Zhao, S.; Xiao, Y.; Ning, Y.; Zhou, Y.; Zhang, D. An Optimized K-means Clustering for Improving Accuracy in Traffic Classification. Wirel. Pers. Commun. 2021, 120, 81–93. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detailed Parameter Setting | |||
|---|---|---|---|
| Number of roads | 64 | Optimizer | ADAM |
| features of roads | 3 | Learning rate | 5 × 10 |
| Historical Length | 24 | Weight decay | 1 × 10 |
| GCN layer | 2 | Batch size | 24 |
| GCN hidden Dimension | 32 | Training Epoch | 500 |
| Linear hidden Dimension | 64 | Training set size | 576 |
| Linear layer | 2 | Validation set size | 72 |
| Number of traffic condition grades | 5 | Testing set size | 72 |
| Method/ Prediction Length | 1 h | 3 h | 6 h |
|---|---|---|---|
| FC-LSTM | 0.8602 | 0.8683 | 0.8635 |
| ConvLSTM | 0.8607 | 0.8721 | 0.8801 |
| DCRNN | 0.8872 | 0.8889 | 0.8847 |
| STGCN | 0.8922 | 0.8868 | 0.8876 |
| SGGformer | 0.9025 | 0.9088 | 0.9053 |
| Method/ Prediction Length | 1 h | 3 h | 6 h |
|---|---|---|---|
| FC-LSTM | 0.9399 | 0.9422 | 0.9385 |
| ConvLSTM | 0.9406 | 0.934 | 0.9399 |
| DCRNN | 0.9480 | 0.9462 | 0.9438 |
| STGCN | 0.9495 | 0.9467 | 0.9456 |
| SGGformer | 0.9549 | 0.9559 | 0.9568 |
| Method/ Prediction Length | 1 h | 3 h | 6 h |
|---|---|---|---|
| S-GCN | 0.8845 | 0.8856 | 0.8852 |
| S-Gformer | 0.8837 | 0.8858 | 0.8874 |
| G-Gformer | 0.8839 | 0.8926 | 0.8922 |
| SGGformer | 0.9025 | 0.9088 | 0.9053 |
| Method/ Prediction Length | 1 h | 3 h | 6 h |
|---|---|---|---|
| S-GCN | 0.9436 | 0.9448 | 0.9449 |
| S-Gformer | 0.9436 | 0.9447 | 0.9456 |
| G-Gformer | 0.9439 | 0.9462 | 0.9461 |
| SGGformer | 0.9549 | 0.9559 | 0.9568 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pu, S.; Chu, L.; Hu, J.; Li, S.; Li, J.; Sun, W. SGGformer: Shifted Graph Convolutional Graph-Transformer for Traffic Prediction. Sensors 2022, 22, 9024. https://doi.org/10.3390/s22229024
Pu S, Chu L, Hu J, Li S, Li J, Sun W. SGGformer: Shifted Graph Convolutional Graph-Transformer for Traffic Prediction. Sensors. 2022; 22(22):9024. https://doi.org/10.3390/s22229024
Chicago/Turabian StylePu, Shilin, Liang Chu, Jincheng Hu, Shibo Li, Jihao Li, and Wen Sun. 2022. "SGGformer: Shifted Graph Convolutional Graph-Transformer for Traffic Prediction" Sensors 22, no. 22: 9024. https://doi.org/10.3390/s22229024
APA StylePu, S., Chu, L., Hu, J., Li, S., Li, J., & Sun, W. (2022). SGGformer: Shifted Graph Convolutional Graph-Transformer for Traffic Prediction. Sensors, 22(22), 9024. https://doi.org/10.3390/s22229024