1. Introduction
1.1. Background and Motivation
In the past years, researchers have proposed different multi-user precoding techniques for the visible light communication (VLC) channel, assuming the availability of channel state information (CSI) at the transmitter side. In radio frequency (RF) systems, there are methods to acquire the CSI, such as those based on the exploitation of channel reciprocity between uplink (UL) and downlink (DL) in time division duplexing (TDD) or the use of a feedback channel in frequency division duplexing (FDD). Unfortunately, establishing an UL feedback channel in VLC is not straightforward. One possibility, which does not relay on channel reciprocity, is to send the UL signals through an RF channel. In this case, once the receivers have estimated the DL channel, the estimates can be fed back to the transmitter through the RF UL link. Consequently, the CSI available at the transmitter side will be far from being accurate, as it can be noisy, outdated, and will contain quantization errors.
In this paper, we address the design of a multi-user multiple-input single-output (MU-MISO) precoder robust against channel quantization errors, which will be the dominant source of error in the CSI if the signal to noise ratio (SNR) during the channel estimation is high or if the number of quantization bits is low. We model the quantization errors in the CSI through polyhedric uncertainty regions that contain the actual channel. Interestingly, for polyhedric uncertainty regions and the fact that, for VLC communications, the transmitted signals and the channels are positive real magnitudes allows us obtaining a non-approximated solution for the robust precoder. This design has not been developed before for RF or VLC channels. In particular, for VLC channels, the only available solutions are those considering estimation noise or outdated CSI, which do not fit the model corresponding to quantization errors, as explained in what follows.
1.2. Related Work
In Ref. [
1], the authors consider a MU-MISO VLC system in a scenario where the passengers in a train wagon receive data through the light emitting diodes (LEDs) placed at the ceiling. Similarly, in Refs. [
2,
3,
4,
5,
6] the authors address the design of the DL in VLC systems under the perfect CSI assumption. In this paper, as mentioned before, we consider a MU-MISO scenario similar to those considered in the previous references (and, in particular, in Ref. [
1]) but assuming that the CSI is not perfect. The scenario is summarized in
Section 2 for completeness.
Imperfect CSI has been considered in Refs. [
7,
8,
9,
10]. The authors of Refs. [
7,
8] model the channel error as zero-mean Gaussian distributed with a certain covariance matrix to account for noisy channel estimation. The authors of Ref. [
9] impose an upper bound on the Frobenius norm of the channel error to account for outdated CSI. Finally, the authors of Ref. [
10] consider both the stochastic and bounded error model to account for both channel estimation errors and outdated CSI. None of these papers [
7,
8,
9,
10], however, have considered channel estimation errors due to the quantization of the channel response. In this paper, we fill this gap by considering imperfect CSI due to the quantization of VLC channels. Note that, in the absence of channel reciprocity, for example if the UL cannot be optical, the receiver needs to report the channel response through a digital feedback channel. This makes quantization a primary CSI error source, particularly when the channel estimation SNR is good or when the number of quantization bits is low.
Finally, regarding the precoder designs, some authors design zero forcing (ZF) linear precoders while maximizing the weighted sum rate or other figures of merit, e.g., [
1,
6]. Other works do not relay on ZF and, instead, focus on minimizing the global mean square error (MSE), e.g., [
7], or the average MSE and the worst-case MSE, e.g., [
10], for the noisy CSI and the outdated CSI, respectively. Similarly, in Refs. [
8,
9], the authors address the maximization of the minimum signal to noise plus interference ratio (SNIR), also for the cases of noisy and outdated CSI, respectively. In our work, instead of ZF precoders as in Refs. [
1,
6], we minimize the optical power per LED subject to a target SNIR per user without forcing null interference, which makes the design more versatile, and account explicitly for quantization errors. On the other hand, instead of considering a global figure of merit that cannot guarantee the quality of individual users, such as the global or the average MSE, we deal with individual user SNIR constraints.
1.3. Main Contributions
Our main contributions and novelties in this paper are the following:
2. System Model
We consider a VLC system, where a transmitter equipped with L LEDs communicates simultaneously with K users (with indexes ) deployed in the same room.
The transmitter modulates the intensity of the light emitted by each LED according to the information symbols. Let be the vector containing the information-bearing real symbols, one per user, at time t, although the time index t is omitted for simplification. We model, without loss of generality, each symbol as a random variable (r.v.) taken from an alphabet with zero mean and unit variance . We assume that the dynamic range of each symbol is limited so that .
Using a set of real beamvectors
,
, the transmitter combines the set of transmitted symbols at time
t,
. Therefore, the vector
containing the
K optical transmitted symbols at time
t (omitted again for simplification) can be written as
where
is the direct current (DC) component equal to the average optical power emitted per LED. Each component of the vector
, at any given instant
t, corresponds to the optical transmit power per individual LED, which is a positive physical magnitude and is usually limited due the technological constraints and eye safety reasons. Therefore, the set of precoders
should be designed to guarantee that, for any combination of symbols, every component of
is positive and below the maximum allowed optical power,
. On the other hand,
determines the average light intensity. Because of this, in practice,
is a preset value, equal for all the LEDs, and we will assume so in this work.
At the receiver side, each user is equipped with a single photo diode (PD) that provides an electrical signal according to the incident light and the responsivity
of the PD (i.e., the ratio of the output photocurrent to the input optical power measured in [A/W]). The incident light depends on the light emitted by the set of LEDs and the channel gain between the
l-th LED and the
k-th PD denoted by
(a magnitude which is, again, real and positive). The channel gain,
, depends on the distance between the
l-th LED and the
k-th PD, the incident angle, and the irradiation angle, as well as other parameters (see [
1] for a full description). The column vector containing all the channel gains from all the LEDs to the
k-th user’s PD is given by
.
Accordingly, the electrical signal at the output of the
k-th PD,
, is equal to
where
is the real-valued additive white Gaussian noise with zero mean and variance
modeling the thermal and shot noise [
12]. The term
is a DC component that can be easily estimated and removed by the receiver as it does not provide any information about the transmitted symbols. After removing the DC component, the electrical SNIR at the
k-th PD can be written as (note that the receiver converts the optical power to current according to the responsivity factor
, which implies that the receiver electrical SNR in VLC is proportional to the square of the received optical average power, while in RF it is directly proportional to the received average power, as explained in Ref. [
1]):
The symbol error rate (SER) depends on the SNIR. This means that, if a minimum detection quality in terms of a maximum SER is required, this can be translated equivalently into a minimum SNIR requirement per user denoted by
. Note that the relation between the maximum SER and
depends on the size of the adopted modulation strategy (e.g.,
M-PAM), that is, the transmission rate [
12]. If different users use different modulations, the corresponding minimum required SNIRs will also differ.
3. Problem Formulation
In this section, we address the design of a robust MU-MISO precoder under imperfect CSI at the transmitter side for the VLC system described
Section 2. We assume that the receivers report the DL channels to the transmitter through a feedback channel. Accordingly, the informed channels may differ from the actual channels due to estimation and reporting errors:
If the three previous sources for CSI imperfection are simultaneously present, the global uncertainty region is a convolutive combination of the different regions [
13]. In this paper, we do not consider the channel estimation noise and the outdated channel information and assume that the quantization effect is dominant, which is a valid assumption in the case of having good channel estimation SNR or a low number of quantization bits and when the channel does not vary quickly. For simplicity, we also assume that each receiver
k quantizes the acquired channel response
independently.
For a channel quantizer based on
vector quantization and characterized by a set of
N reconstruction points
, the uncertainty region associated to each reconstruction point (or centroid)
is defined as:
The centroids
correspond to the
N codewords composing the quantizer codebook. Therefore, each receiver requires sending ceil
bits for CSI feedback. Note that
is the Voronoi partition around the centroid
with respect to (w.r.t.) the set
. As the space is a finite-dimensional Euclidean space, these Voronoi cells are convex polygons completely defined by their vertices [
11], that is, polyhedric uncertainty regions.
The previous notation encompasses, as a particular case, scalar quantization, that is, an independent quantization of each component of the channel vector. In this particular case, the uncertainty regions are rectangular and the number of vertices of each region is .
In what follows, we refer to the uncertainty region of the channel informed by the
k-th user as
. For the
k-th user,
will be one of the Voronoi regions within the set
. Each region is a convex polygon that can be expressed as the convex hull [
11] of its
vertices
, that is:
.
Having defined the uncertainty regions, in the following we formulate the design of a precoder fulfilling the SNIR constraint per user for any possible channel in the uncertainty region:
The C1 constraints impose the K minimum SNIR requirements (one per user). In C2, is a vector whose l-th element is equal to 1, and the rest of elements are zero. The C2 constraints imply that the optical power transmitted per LED is within the interval . The C3 constraint ensures that is within the interval , and, therefore, the optical power transmitted per LED is positive and not greater than .
With some basic manipulations, we can re-write the C1 constraints as follows:
Both alternative expressions of constraints C1 (either in (
5) or in (
6)) represent
K sets of infinite non-convex constraints because the constraint expressed in C1 for each
k has to be fulfilled for the infinite set of channels represented by
.
4. Solution for Polyhedric Uncertainty Regions
In this section, we show that, for polyhedric uncertainty regions
, problem (
5) can be re-formulated as a convex problem with a finite number of second-order cone constraints. Therefore, the problem becomes a SOCP problem, for which several efficient interior point methods are available [
11].
As a first step, we show in Lemma 1 that we can force, without any loss of generality, to be positive for any channel within the region .
Lemma 1. Any feasible precoder will be such that will be always positive or always negative for any .
Proof. We will prove it by contradiction. Let us assume that there is a feasible
, that is, a vector
that satisfies constraints C1, C2, and C3, and two channels in
, namely
, such that
and
. Therefore, we can find
such that
with
and
. In fact, we have:
As is convex, such . Therefore, due to the noise term, C1 is not fulfilled, and consequently, cannot be a feasible solution. □
As
is either always negative or always positive for all
for a feasible value of
, we can impose, without loss of generality, that
. Note that if the optimum precoder,
, was such that
was negative, we could multiply
by
without changing the values of the objective and constraint functions. Imposing strict positivity for any
allows us to remove the absolute value in the right-hand side of C1 in (
6). After removing that absolute value, we have
K infinite sets of convex constraints, because a convex constraint has to be fulfilled for a infinite set of channels
with
. To deal with this complexity, consider now the following lemma.
Lemma 2. Let us take a convex region formulated as and a function parameterized by and convex w.r.t. . If , , then .
Proof. As the uncertainty region
is the convex hull of their
vertices, any element in
can be expressed as a linear convex combination of their vertices:
Consider now the following function
that is convex w.r.t.
. Due to its convexity, it fulfills:
Therefore, if for all the vertices , then will be less than or equal to 0 for all . □
Thanks to Lemma 2, we can re-write problem (
5) as:
Note that we have been able to ensure the positiveness of
in the whole uncertainty region by just forcing it at its vertices through the finite set of
convex constraints in C4. As a result, the original problem turns out into a SOCP with a finite number of constraints for which several extremely efficient algorithms and tools are available, such as the interior point methods and the SeDuMi software package [
11,
14].
A problem similar to (
5) was considered in Ref. [
15] (Section 18.5.1) for RF MU-MISO channels, for which channel and beamformers are complex-valued vectors. First, the authors considered perfect CSI and solved the problem by forcing the imaginary part of
to be zero and the real part to be positive (Equation (18.29) in [
15]). Then, they extended the solution to a robust scheme modeling the uncertainty through the lower and upper bounds of the channel correlation matrix (Equation (18.4) in Ref. [
15]). Note that this model does not fit the case where the channel uncertainty comes from quantization, which results in uncertainty regions different from the ones considered in Ref. [
15]. In addition, the strategy followed in Ref. [
15] for the perfect CSI case cannot be directly applied when having an infinite set of channels (a region) in the constraints instead of a single channel. For RF channels, unless all the channels are 0, it is not possible to ensure a null imaginary part (and a positive real part) of
for all the channels in the region. Fortunately, in VLC systems, the channels do not have imaginary parts, and we have proved in Lemma 1 that the real part of
cannot change its sign within the whole uncertainty region.
5. Implementation Aspects
A practical implementation of the proposed scheme requires each user to estimate the DL channel from each LED and send a quantized version of this information through a feedback channel. In this section, we discuss some issues regarding the quantization and the impact on the complexity of the optimization problem presented in
Section 3 and
Section 4.
The most straightforward quantization strategy is to independently quantize the L channel components (scalar quantization) using a uniform quantizer of B bits per channel component. However, depending on the channel amplitudes distribution, some strategies can be taken to reduce the quantization error power without increasing the number of bits. For example, if lower amplitudes are more likely than higher amplitudes, more efficient usage of the available representation levels is achieved if a non-uniform quantizer is employed (for example, a uniform quantizer of the logarithm of the channel).
For uniform or non-uniform scalar quantization with B bits per channel component, the number of possible uncertainty regions is . As any uncertainty region reported has vertices, the total number of constraints represented by C1, , increases linearly with K and exponentially with L.
On the other hand, in the scenario considered, some combinations of the amplitudes of the LEDs are not possible. For example, as each LED location is different, a user cannot have a maximum channel simultaneously from all LEDs. A joint quantization of channel components (vector quantization) can exploit this feature to reduce the number of CSI information bits. The total number of constraints will depend again on the number of vertices of the uncertainty regions. Nevertheless, the vector quantization case is outside the scope of this paper and we will restrict the simulations to the scalar quantization case.
6. Simulation Results
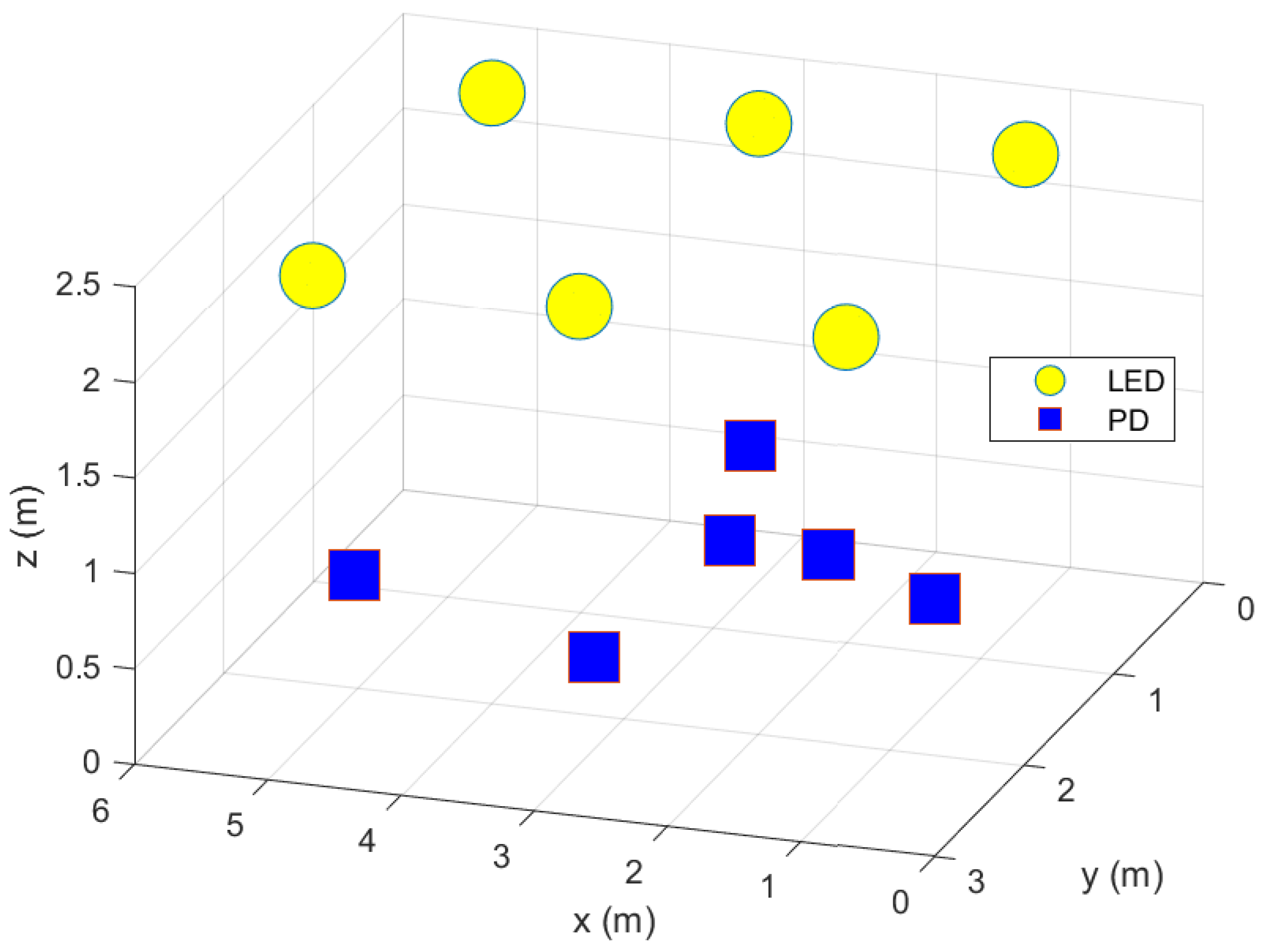
In this section, we present some simulation results. We consider
active LEDs serving
K users (see
Figure 1 as an example of the simulated setup, similar to the one considered in Ref. [
1]). We set the target SNIR to 15 dB for each user, the maximum power threshold to 20 W, and take the rest of the parameters from Ref. [
1]. All the simulation results presented in this section are averaged over different scenario realizations. For each scenario realization, the LEDs are positioned as shown in
Figure 1 with a fixed height of 2.4 m. The users’ (PDs) locations are random. The
x and
y coordinates of the PDs are drawn from a uniform random distribution in the simulated area, whereas the
z coordinate (height of PD) is drawn from a uniform random distribution between 0.5 and 1 m. The channels are then generated according to the relative positions between transmitters (LEDs) and receivers (PDs).
For each scenario realization, we design precoders that serve
K users jointly. The quantized channel is the only CSI available at the transmitter side to design robust and non-robust precoders. For the simulations, we have considered the particular case of independent quantization of the channel between each LED and each PD, that is, scalar quantization. Each of these channel coefficients is a real positive magnitude that can take a wide margin of values. To cope with this wide margin, we perform a logarithm transformation and then a uniform quantization. In other words, we consider a uniform quantization of the value in dB of the channel magnitude. The dynamic margin of the quantizer, i.e., the minimum and maximum values represented by the quantizer, are determined statistically using
realizations of users’ positions and channel values of the setup considered in the simulations. We design the non-robust precoder using the quantized channel as if it were the actual channel (despite being different). The actual channel is within an uncertainty region around the quantized channel. As explained in the previous sections, we design the robust precoder to achieve the target SNIR for any channel within this region. For the computation of the non-robust and robust solutions, we have used CVX, a package for specifying and solving convex programs [
16,
17].
The number of bits impacts the size of the channel uncertainty regions, making the constraints of the robust precoder design problem more challenging. As a result, a higher optical power is needed to fulfill the constraints. Note that, depending on the channel realizations, fulfilling the constraints may require an unacceptable amount of power or not be possible at all; that is, it is not possible to fulfill constraint C3. In
Figure 2, we show the percentage of feasibility (i.e., successful designs) for different numbers of jointly served users and quantization bits. As expected, the percentage reduces (i.e., the precoder design becomes more complex) as the number of bits decreases or as the number of users increases.
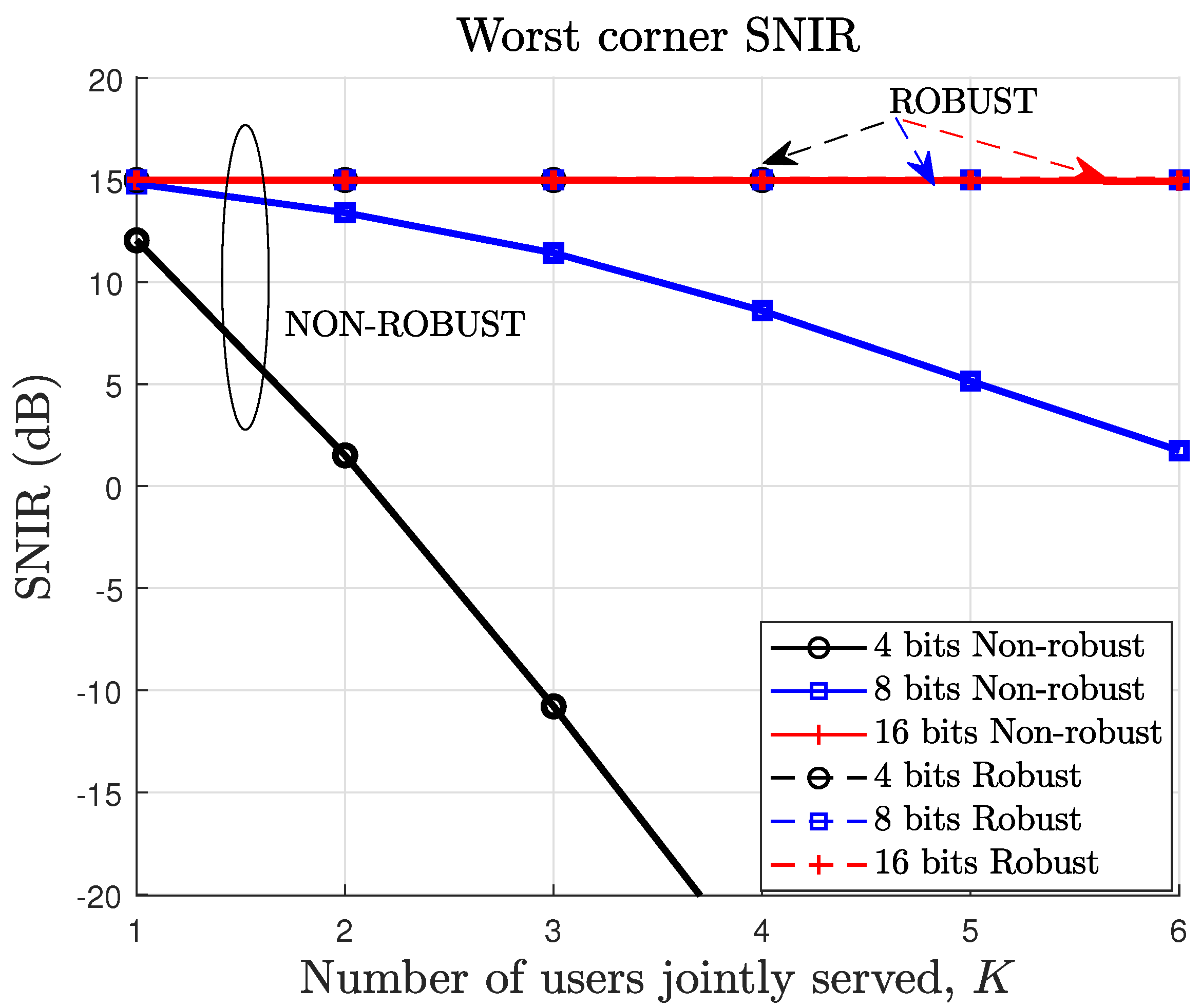
It is not surprising that the percentage of feasibility cases of the robust design is lower than for the non-robust design due to the much harder constraints of the robust approach. Note, however, that the non-robust solution will perform much worse than the robust counterpart for channels different from the quantized version. To illustrate this,
Figure 3 shows the SNIR for the worst possible channel, which always corresponds to a corner of the uncertainty region (
,
of constraint C1), as proved in this paper, for the non-robust and robust approaches. Therefore, if a feasible solution exists, the robust precoder fulfills the SNIR constraint with equality at this corner by design, which is set to 15 dB in these simulations, and, consequently, in all of the uncertainty region. As a result, as shown in
Figure 3, for the robust precoder, the SNIR at the worst-possible channel of the uncertainty region is always equal to the target SNIR. In contrast, the non-robust design cannot guarantee that, especially when the number of quantization bits is low.
In practice, we may be interested in finding how well the feasible designs will perform for the real channels experienced by the users. To that end, we compute the SNIR using the actual channels and the precoders designed using the quantized channels (as the actual channels information is not available at the design phase). In
Figure 4, we show the performance of the robust and non-robust precoders in terms of the actual SNIR of the worst user within each group of
K users, averaged over different channel realizations. The actual SNIR is the SNIR computed with the actual channels, which are different to the quantized channels used for the beamformer design. For the non-robust precoder, the achieved SNIR is below the target SNIR. This is because the non-robust design incorrectly assumes that the quantized channel is equal to the actual channel. On the other hand, the robust precoder is designed to achieve the target SNIR for any channel within the uncertainty region. The actual channel always lies within the uncertainty region. However, it is not necessarily the worst-case channel, which is located at a corner of the uncertainty region, as shown in previous sections. Consequently, with the robust beamformer, the actual users’ SNIR can be above the target SNIR, particularly if the uncertainty region increases, which happens when the number of quantization bits decreases. As illustrated previously in
Figure 2, for 4 bits and 5 users or more, no robust precoder can achieve the target SNIR with a power lower than or equal to
. This is the reason why no SNIR values are shown for these cases in
Figure 3 and
Figure 4. Note that this does not invalidate our approach. It just tells us that for 5 users or more, we need to increase the number of bits to fulfill the target SNIR under channel uncertainty with a power lower than or equal to
.
To ensure feasibility, given the number of bits
B, we can reduce the number of simultaneously served users
K until a feasible precoder can be found. Moreover, as proved in
Section 4, we can guarantee that the robust precoder will fulfill the target quality for all the users in the set.
Table 1 shows the SNIR of the worst user within each set of jointly served users (with the maximum number of users possible provided that a feasible solution can be found). Note that, in the case of the non-robust precoder, the target quality cannot be achieved. More importantly, it is impossible to decide beforehand if the non-robust precoders will or will not do the job because only the quantized channel information (and not the actual channel) is available at the design stage.
7. Conclusions and Discussion
In this paper, we have designed the optimum MU-MISO precoder robust against channel quantization errors in VLC systems that minimizes the transmitted optical power while guaranteeing a target SNIR per user. We show that the exact form for this precoder can be obtained as the solution of an SOCP problem. As expected, the precoder design becomes more difficult (i.e., requires more power) as the number of bits decreases or as the number of users increases. Nevertheless, provided the budget power is sufficient, we can guarantee that the robust designs achieve the target SNIR per user. In contrast, for non-robust designs, such a guarantee is not possible.
As future work, we will consider the robust precoding design problem in the presence of both quantization noise and channel estimation errors. This could include also the case of vector quantization as a way to improve the quality of the CSI without increasing the number of quantization bits. Another research line will be the extension of the proposed scheme to the multiple-input multiple-outpout (MIMO) case, where each receiver has more than one PD. Finally, and given the non-linear responses of the LEDs and the PDs, it will be convenient to study how these non-linearities affect the proposed designs and analyze how to modify the designs to be robust also against them.
8. Materials and Methods
The results in this paper can be replicated by implementing the algorithms described in it. The authors disclose that the code is protected and cannot be made public. Interested readers can get in touch with the authors to receive assistance.
Author Contributions
Conceptualization, O.M. and A.P.-I.; methodology, O.M. and A.P.-I.; software, O.M. and G.S.A.; validation, O.M., A.P.-I. and G.S.A.; formal analysis, O.M. and A.P.-I.; investigation, O.M. and A.P.-I.; writing—original draft preparation, O.M., A.P.-I. and G.S.A.; visualization, O.M.; supervision, O.M. and A.P.-I.; project administration, A.P.-I.; funding acquisition, A.P.-I. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been funded by the Agencia Estatal de Investigación, Ministerio de Ciencia e Innovación (Gobierno de España), MCIN/AEI/10.13039/501100011033, through the project ROUTE56 PID2019-104945GB-I00.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| CSI | Channel state information |
| DC | Direct current |
| DL | Downlink |
| FDD | Frequency division duplexing |
| LED | Light emitting diode |
| MIMO | Multiple-input multiple-outpout |
| MSE | Mean square error |
| MU-MISO | Multi-user multiple-input single-output |
| PD | Photo diode |
| RF | Radio frequency |
| SER | Symbol error rate |
| SNIR | Signal to noise plus interference ratio |
| SNR | Signal to noise ratio |
| SOCP | Second order cone programming |
| TDD | Time division duplexing |
| UL | Uplink |
| VLC | Visible light communication |
| w.r.t. | with respect to |
| ZF | Zero forcing |
References
- Viñals, R.; Muñoz, O.; Agustín, A.; Vidal, J. Cooperative Linear Precoding for Multi-User MISO Visible Light Communications. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Wang, J.; Zhang, R.; Shen, H.; Zhao, C.; Hanzo, L. Multiuser MISO Transceiver Design for Indoor Downlink Visible Light Communication Under Per-LED Optical Power Constraints. IEEE Photonics J. 2015, 7, 1–15. [Google Scholar] [CrossRef]
- Zhao, Q.; Fan, Y.; Kang, B. A joint precoding scheme for indoor downlink multi-user MIMO VLC systems. Opt. Commun. 2017, 403, 341–346. [Google Scholar] [CrossRef]
- Pham, T.V.; Pham, A.T. Coordination/Cooperation Strategies and Optimal Zero-Forcing Precoding Design for Multi-User Multi-Cell VLC Networks. IEEE Trans. Commun. 2019, 67, 4240–4251. [Google Scholar] [CrossRef]
- Duong, S.T.; Pham, T.V.; Nguyen, C.T.; Pham, A.T. Energy-Efficient Precoding Designs for Multi-User Visible Light Communication Systems With Confidential Messages. IEEE Trans. Green Commun. Netw. 2021, 5, 1974–1987. [Google Scholar] [CrossRef]
- Yu, Z.; Baxley, R.J.; Zhou, G.T. Multi-user MISO broadcasting for indoor visible light communication. In Proceedings of the ICASSP 2013—2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 4849–4853. [Google Scholar] [CrossRef]
- Shen, H.; Xu, W.; Zhao, K.; Bai, F.; Zhao, C. Non-Alternating Globally Optimal MMSE Precoding for Multiuser VLC Downlinks. IEEE Commun. Lett. 2019, 23, 608–611. [Google Scholar] [CrossRef]
- Sun, Z.G.; Yu, H.Y.; Tian, Z.J.; Zhu, Y.J. Linear Precoding for MU-MISO VLC Systems With Noisy Channel State Information. IEEE Commun. Lett. 2018, 22, 732–735. [Google Scholar] [CrossRef]
- Sifaou, H.; Kammoun, A.; Park, K.H.; Alouini, M.S. Robust Transceivers Design for Multi-Stream Multi-User MIMO Visible Light Communication. IEEE Access 2017, 5, 26387–26399. [Google Scholar] [CrossRef] [Green Version]
- Ma, H.; Lampe, L.; Hranilovic, S. Coordinated Broadcasting for Multiuser Indoor Visible Light Communication Systems. IEEE Trans. Commun. 2015, 63, 3313–3324. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Dimitrov, S.; Haas, H. Principles of LED Light Communications; Torwards Networked Li-Fi; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Pascual-Iserte, A.; Pérez-Neira, A.I.; Palomar, D.P.; Lagunas, M.A. A Robust Maximin Approach for MIMO Communications with Imperfect Channel State Information based on Convex Optimization. IEEE Trans. Signal Process. 2006, 54, 346–360. [Google Scholar] [CrossRef]
- Sturm, J.F. Using SEDUMI, a Matlab Toolbox for Optimization Over Symmetric Cones. Available online: https://sedumi.ie.lehigh.edu/ (accessed on 1 June 2022).
- Bengtsson, M.; Ottersten, B. Optimum and Suboptimum Transmit Beamforming. In Handbook of Antennas in Wireless Communications, 1st ed.; Godara, L.C., Ed.; CRC Press: Boca Raton, FL, USA, 2002; Chapter 18; pp. 18(1)–18(33). [Google Scholar]
- Grant, M.; Boyd, S. CVX: Matlab Software for Disciplined Convex Programming, Version 2.2; 2020. Available online: http://cvxr.com/cvx (accessed on 1 June 2022).
- Grant, M.; Boyd, S. Graph implementations for nonsmooth convex programs. In Recent Advances in Learning and Control; Lecture Notes in Control and Information Sciences; Blondel, V., Boyd, S., Kimura, H., Eds.; Springer: London, UK, 2008; pp. 95–110. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}
{kind=link}