Author Contributions
Conceptualization, Y.G.L., G.N. and J.B.; methodology, Y.G.L.; software, Y.G.L.; validation, Y.G.L., G.N. and J.B.; formal analysis, Y.G.L.; investigation, Y.G.L.; resources, G.N. and J.B.; data curation, Y.G.L., G.N. and J.B.; writing—original draft preparation, Y.G.L.; writing—review and editing, Y.G.L., G.N. and J.B.; visualization, Y.G.L.; supervision, Y.G.L.; project administration, Y.G.L.; funding acquisition, G.N. and J.B. All authors have read and agreed to the published version of the manuscript.
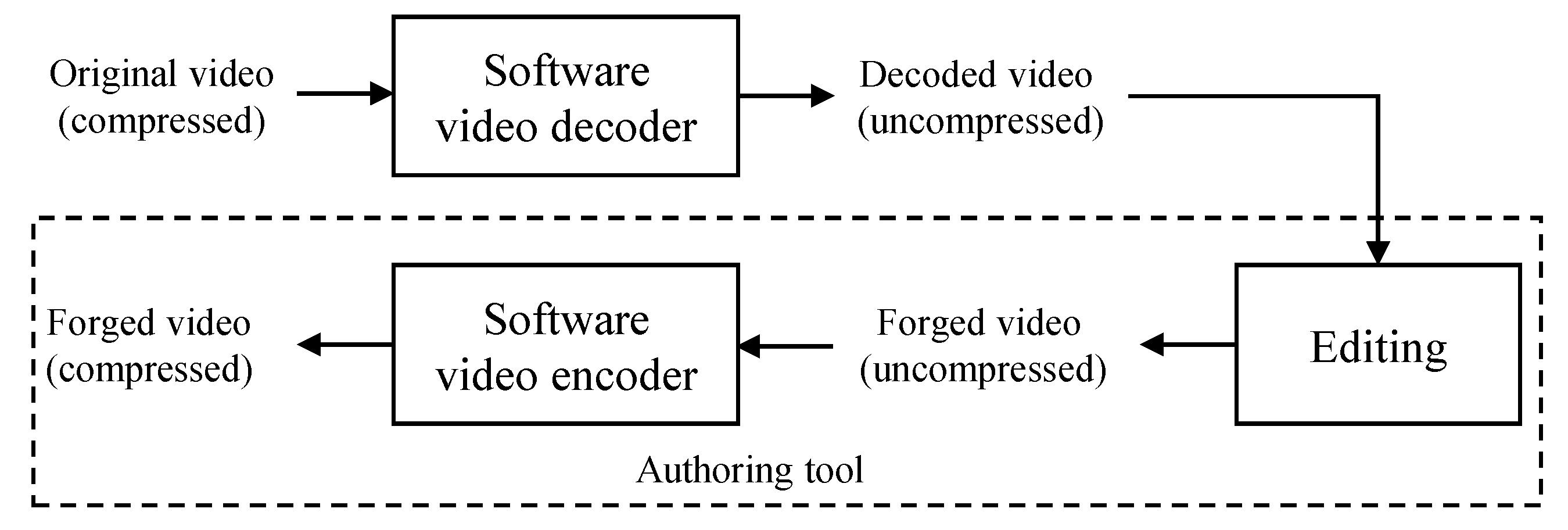
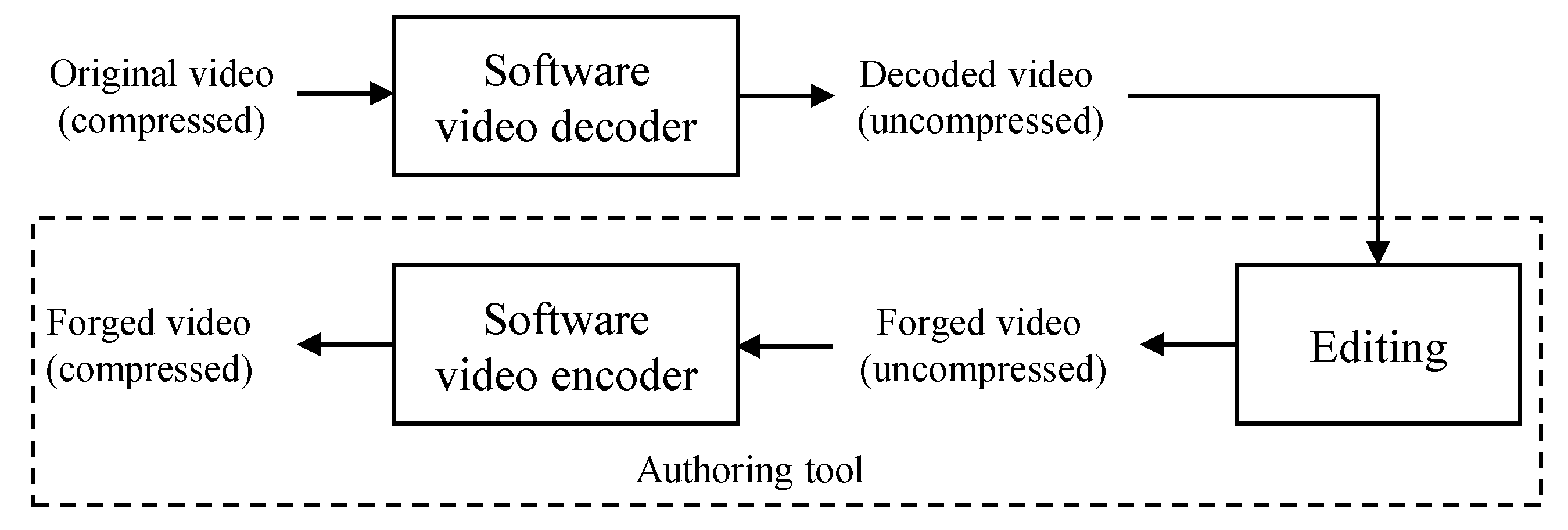
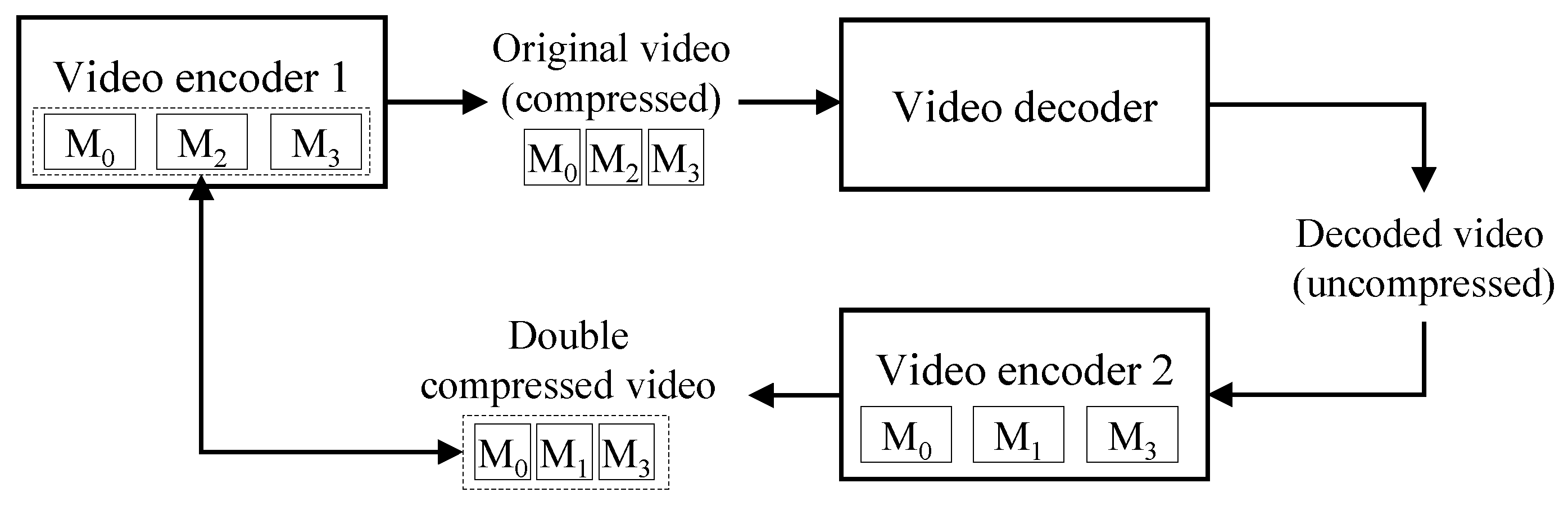
Figure 1.
Procedure of video forgery by double compression.
Figure 1.
Procedure of video forgery by double compression.
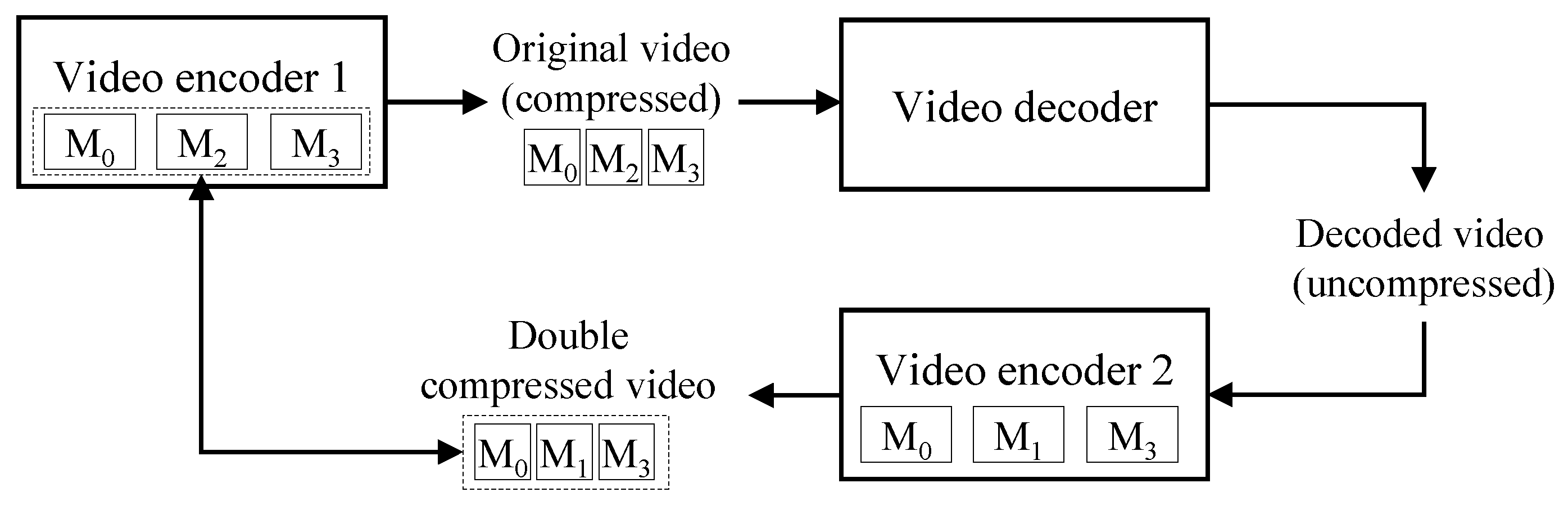
Figure 2.
Key idea of the proposed algorithm.
Figure 2.
Key idea of the proposed algorithm.
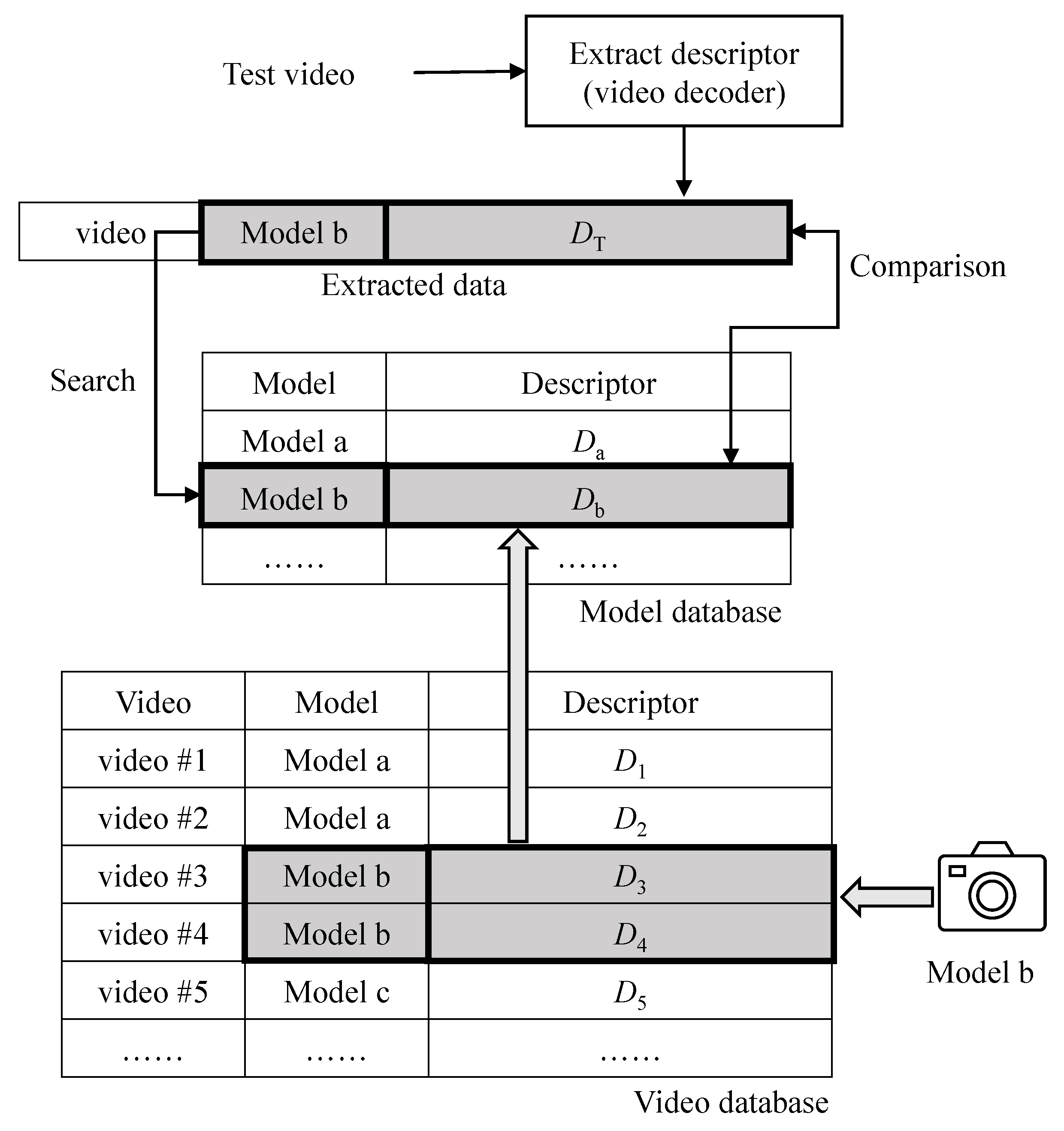
Figure 3.
Proposed detection system.
Figure 3.
Proposed detection system.
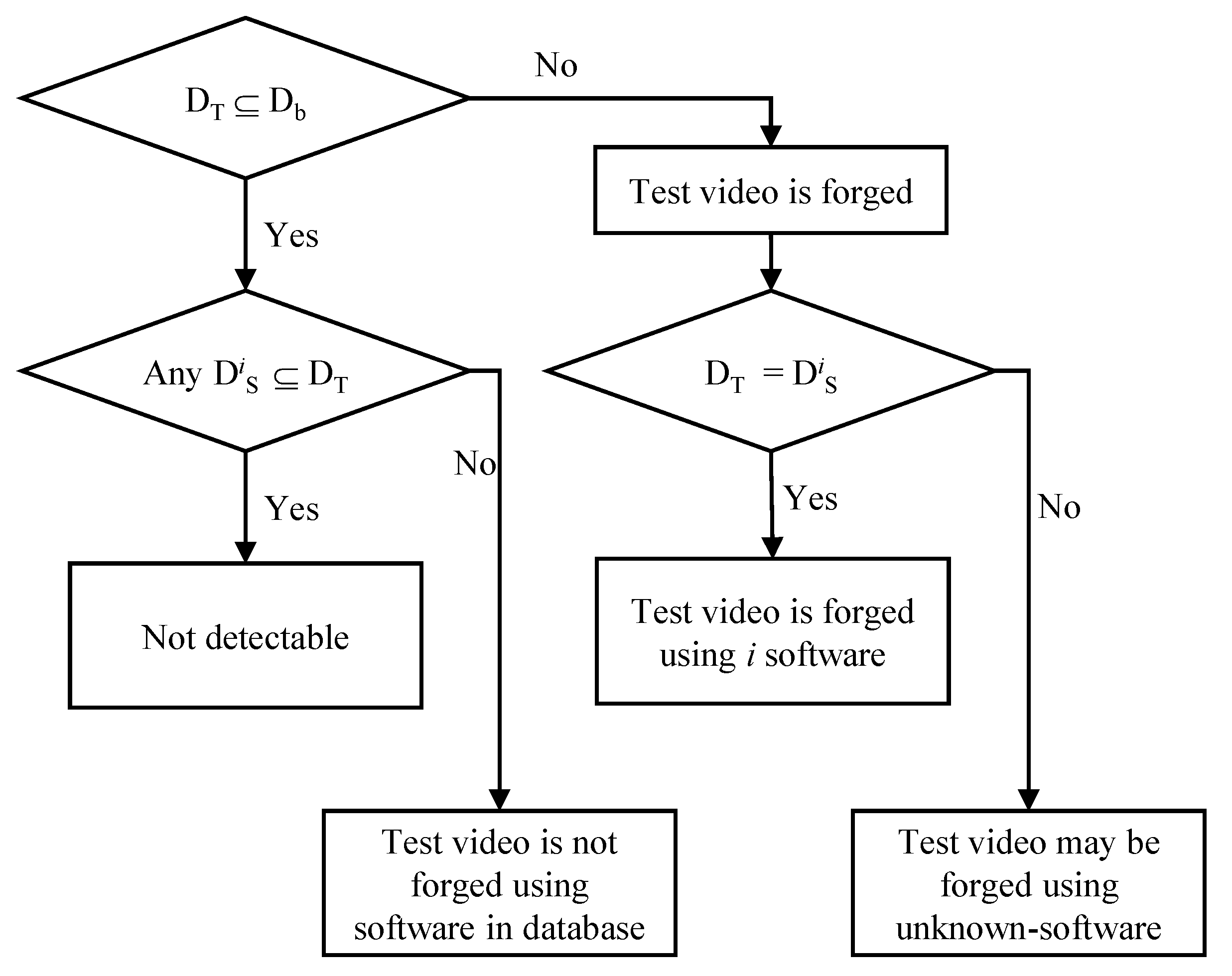
Figure 4.
Proposed decision rule. , , and are descriptors of the test video, the video encoder, and the i software video encoder, respectively.
Figure 4.
Proposed decision rule. , , and are descriptors of the test video, the video encoder, and the i software video encoder, respectively.
Figure 5.
Validation method of the proposed method.
Figure 5.
Validation method of the proposed method.
Table 1.
Example of the H.264 decoder’s descriptor. BL stands for baseline.
Table 1.
Example of the H.264 decoder’s descriptor. BL stands for baseline.
| Encoding Mode | Number |
|---|
| Profile | 66(BL) |
| Level | 3.1 |
| GOP size | 6 |
| | mode0 | 385,332 |
| Intra | mode1 | 30,440 |
| mode2 | 95,570 |
| | mode3 | 0 |
| | mode0 | 690,994 |
| | mode1 | 950,632 |
| | mode2 | 1,476,582 |
| Intra | mode3 | 0 |
| mode4 | 0 |
| | mode5 | 0 |
| | mode6 | 0 |
| | mode7 | 0 |
| | mode8 | 0 |
| | | 1,935,837 |
| | | 0 |
| Inter block | | 0 |
| partition | | 1,171,112 |
| | | 0 |
| | | 0 |
| | | 0 |
Table 2.
Example of CU sizes and types in HEVC encoder’s descriptor.
Table 2.
Example of CU sizes and types in HEVC encoder’s descriptor.
| CU Type | CU Size |
|---|
| | | |
|---|
| Skip CU | 11,609 | 48,399 | 35,748 | 28,864 |
| Intra CU | 0 | 35,040 | 35,838 | 26,458 |
| Inter CU | 16,097 | 32,277 | 14,679 | 6978 |
Table 3.
Example of intra prediction modes of CU in HEVC encoder’s descriptor. Here, IPMN stands for intra prediction mode number.
Table 3.
Example of intra prediction modes of CU in HEVC encoder’s descriptor. Here, IPMN stands for intra prediction mode number.
| IPMN | Number | IPMN | Number | IPMN | Number | IPMN | Number |
|---|
| 0 | 12,864 | 9 | 0 | 18 | 198 | 27 | 0 |
| 1 | 49,047 | 10 | 2908 | 19 | 0 | 28 | 0 |
| 2 | 1550 | 11 | 0 | 20 | 0 | 29 | 0 |
| 3 | 0 | 12 | 0 | 21 | 0 | 30 | 0 |
| 4 | 0 | 13 | 0 | 22 | 0 | 31 | 0 |
| 5 | 0 | 14 | 0 | 23 | 0 | 32 | 0 |
| 6 | 0 | 15 | 0 | 24 | 0 | 33 | 0 |
| 7 | 0 | 16 | 0 | 25 | 0 | 34 | 519 |
| 8 | 0 | 17 | 0 | 26 | 1854 | | |
Table 4.
Example of block partitioning information of inter coded CU in HEVC encoder’s descriptor.
Table 4.
Example of block partitioning information of inter coded CU in HEVC encoder’s descriptor.
| Size | Number | Size | Number |
|---|
| 1,535,249 | | 0 |
| 0 | | 0 |
| 0 | | 0 |
| 0 | | 0 |
Table 5.
Example of descriptor comparison. , , and are the number of times that each mode is used in Videos #1, #2, and #3.
Table 5.
Example of descriptor comparison. , , and are the number of times that each mode is used in Videos #1, #2, and #3.
| Mode | Video #1 | Video #2 | Video #3 |
|---|
| 142,342 | 51,244 | 15,249 |
| 522,342 | 123,142 | 292,342 |
| 152,342 | 24,922 | 0 |
| 0 | 0 | 125,242 |
| 0 | 0 | 8754 |
Table 6.
Example of intra prediction in H.264. Here, descriptors from two videos shot by the same camera are identical to each other. Here, O and × represent ‘used’ and ‘not used’, respectively.
Table 6.
Example of intra prediction in H.264. Here, descriptors from two videos shot by the same camera are identical to each other. Here, O and × represent ‘used’ and ‘not used’, respectively.
| Encoding Mode | Video DB | Model DB |
|---|
| ( Intra Pred.) | Video #1 | Used | Video #2 | Used |
|---|
| mode0 | 722,157 | O | 1,095,886 | O | O |
| mode1 | 747,453 | O | 1,490,516 | O | O |
| mode2 | 1,324,614 | O | 1,790,590 | O | O |
| mode3 | 0 | × | 0 | × | × |
| mode4 | 0 | × | 0 | × | × |
| mode5 | 0 | × | 0 | × | × |
| mode6 | 0 | × | 0 | × | × |
| mode7 | 0 | × | 0 | × | × |
| mode8 | 0 | × | 0 | × | × |
Table 7.
Example of intra prediction in CU in HEVC. Here, descriptors from two videos shot by the same camera are not identical to each other. Here, O and × represent ‘used’ and ‘not used’, respectively.
Table 7.
Example of intra prediction in CU in HEVC. Here, descriptors from two videos shot by the same camera are not identical to each other. Here, O and × represent ‘used’ and ‘not used’, respectively.
| Encoding Mode | Video DB | Model DB |
|---|
| ( Intra Pred.) | Video #1 | Used | Video #2 | Used |
|---|
| mode0 | 3210 | O | 25,622 | O | O |
| mode1 | 2702 | O | 31,559 | O | O |
| mode2 | 54 | O | 1205 | O | O |
| mode3 | 2 | O | 399 | O | O |
| mode4 | 0 | × | 14 | O | O |
| mode5 | 1 | O | 21 | O | O |
| mode6 | 0 | × | 183 | O | O |
| … | … | … | … | … | … |
| mode34 | 0 | × | 48 | O | O |
Table 8.
Three types of comparison results. Here, O and × represent ‘used’ and ‘not used’, respectively.
Table 8.
Three types of comparison results. Here, O and × represent ‘used’ and ‘not used’, respectively.
| Encoding Mode | Model DB | Test Video |
|---|
| Db | | | |
|---|
| A | O | O | O | O |
| B | O | O | O | O |
| C | O | O | × | × |
| D | × | × | × | O |
| D | × | × | × | × |
| F | O | O | × | O |
| G | O | O | O | × |
Table 9.
One example of peculiar results in some H.264 hardware video encoders.
Table 9.
One example of peculiar results in some H.264 hardware video encoders.
| Model | Intra Prediction Modes |
|---|
| Mode 0 | Mode 1 | Mode 2 | Mode 3 |
|---|
| Num | % | Num | % | Num | % | Num | % |
|---|
| a | 122,842 | 49.184 | 23,182 | 9.286 | 103,715 | 41.526 | 10 | 0.004 |
| b | 262,525 | 66.623 | 61987 | 15.731 | 69535 | 17.646 | 1 | 0.000 |
Table 10.
Example of intra prediction modes of , , and CUs in HEVC encoder’s descriptor. CM stands for camera model. Here, O and × represent ‘used’ and ‘not used’, respectively.
Table 10.
Example of intra prediction modes of , , and CUs in HEVC encoder’s descriptor. CM stands for camera model. Here, O and × represent ‘used’ and ‘not used’, respectively.
| CM | CU Size | Intra Prediction Modes |
|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | … | 33 | 34 |
|---|
| 1 | | O | O | O | × | × | × | × | × | × | × | O | × | … | × | O |
| O | O | O | × | O | × | O | × | O | × | O | × | … | × | O |
| O | O | O | O | O | O | O | O | O | O | O | O | … | O | O |
| 2 | | O | O | O | × | × | × | × | × | × | × | O | × | … | × | × |
| O | O | O | O | O | O | O | O | O | O | O | O | … | O | O |
| O | O | O | O | O | O | O | O | O | O | O | O | … | O | O |
| 3 | | O | O | × | × | × | × | × | × | × | × | O | × | … | × | O |
| O | O | O | O | O | O | O | O | O | O | O | O | … | O | O |
| O | O | O | O | O | O | O | O | O | O | O | O | … | O | O |
| 4 | | O | O | O | O | O | O | O | O | O | O | O | O | … | × | O |
| O | O | O | O | O | O | O | O | O | O | O | O | … | × | O |
| O | O | O | O | O | O | O | O | O | O | O | O | … | × | O |
| 5 | | O | O | O | O | O | O | O | O | O | O | O | O | … | O | O |
| O | O | O | O | O | O | O | O | O | O | O | O | … | O | O |
| O | O | O | O | O | O | O | O | O | O | O | O | … | O | O |
| 6 | | O | O | O | O | O | O | O | O | O | O | O | O | … | O | O |
| O | O | O | O | O | O | O | O | O | O | O | O | … | O | O |
Table 11.
Example of intra prediction modes of CU in HEVC encoder’s descriptors. Here, O and × represent ‘used’ and ‘not used’, respectively.
Table 11.
Example of intra prediction modes of CU in HEVC encoder’s descriptors. Here, O and × represent ‘used’ and ‘not used’, respectively.
| Camera | Intra Prediction Modes |
|---|
|
Model
|
0
|
1
|
2
|
3
|
4
|
5
|
6
|
7
|
8
|
9
|
10
|
…
|
33
|
34
|
|---|
| a | × | × | × | × | × | × | × | × | × | × | × | … | × | × |
| b | O | O | × | O | × | O | × | O | × | O | × | … | O | × |
| c | O | O | O | O | O | O | O | O | O | O | O | … | × | O |
| d | O | O | O | O | O | O | O | O | O | O | O | … | O | × |
| e | O | O | O | O | O | O | O | O | O | O | O | … | O | O |
Table 12.
Example of block partitioning of inter coded CU in HEVC encoder’s descriptors. Here, inter predict modes 0, 1, 2, 3, 4, 5, 6, and 7 correspond to , , , , , , , and PUs, respectively. Here, O and × represent ‘used’ and ‘not used’, respectively.
Table 12.
Example of block partitioning of inter coded CU in HEVC encoder’s descriptors. Here, inter predict modes 0, 1, 2, 3, 4, 5, 6, and 7 correspond to , , , , , , , and PUs, respectively. Here, O and × represent ‘used’ and ‘not used’, respectively.
| Camera | CU | Type of PU |
|---|
| Model | Size | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
| | | O | × | × | × | × | × | × | × |
| A | | O | × | × | × | × | × | × | × |
| | | O | × | × | × | × | × | × | × |
| | | O | O | O | × | × | × | × | × |
| B | | O | O | O | × | × | × | × | × |
| | | O | × | × | × | × | × | × | × |
| | | O | O | O | × | O | O | O | O |
| C | | O | O | O | × | O | O | O | O |
| | | O | O | O | × | × | × | × | × |
| D | | O | O | O | × | × | × | × | × |
| O | O | O | O | × | × | × | × |
Table 13.
Examples of basic parameters in H.264 encoder’s descriptors.
Table 13.
Examples of basic parameters in H.264 encoder’s descriptors.
| Model | Profile | Level | Width | Height |
|---|
| A | Baseline | 3 | 1280 | 720 |
| B | High | 4.1 | 1920 | 1080 |
| C | High | 4 | 1920 | 1080 |
| D | High | 4.2 | 1920 | 1080 |
| E | High | 4.2 | 1920 | 1080 |
| F | High | 4.2 | 1920 | 1080 |
| G | High | 4.1 | 1920 | 1080 |
| H | High | 4 | 1920 | 1080 |
| I | Main | 4 | 1920 | 1080 |
| J | Baseline | 3 | 1280 | 720 |
| K | Baseline | 3.1 | 1280 | 720 |
Table 14.
Examples of intra prediction modes in H.264 encoder’s descriptors. Here, O and × represent ‘used’ and ‘not used’, respectively.
Table 14.
Examples of intra prediction modes in H.264 encoder’s descriptors. Here, O and × represent ‘used’ and ‘not used’, respectively.
| Model | Intra | Intra |
|---|
| 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|
| A | O | O | O | × | × | × | × | × | × | × | × | × | × |
| B | O | O | O | O | O | O | O | O | O | O | O | O | O |
| C | O | O | O | × | O | O | O | × | × | × | × | × | × |
| D | O | O | O | O | × | × | × | × | × | × | × | × | × |
| E | O | O | O | O | × | × | × | × | × | × | × | × | × |
| F | O | O | O | O | × | × | × | × | × | × | × | × | × |
| G | O | O | O | × | × | × | × | × | × | × | × | × | × |
| H | O | O | O | × | O | O | O | O | O | O | O | O | O |
| I | O | O | O | × | O | O | O | × | × | × | × | × | × |
| J | O | O | O | × | × | × | × | × | × | × | × | × | × |
| K | O | O | O | × | O | O | O | O | O | O | O | O | O |
Table 15.
Examples of inter block partitions in H.264 encoder’s descriptors. Here, O and × represent ‘used’ and ‘not used’, respectively. The numbers 0, 1, 2, 3, 4, 5, and 6 in inter block partitions denote , , , , , , and , respectively.
Table 15.
Examples of inter block partitions in H.264 encoder’s descriptors. Here, O and × represent ‘used’ and ‘not used’, respectively. The numbers 0, 1, 2, 3, 4, 5, and 6 in inter block partitions denote , , , , , , and , respectively.
| Model | Inter Block Partition |
|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|
| A | O | O | O | O | × | × | × |
| B | O | O | O | O | × | × | × |
| C | O | × | × | O | × | × | × |
| D | O | × | × | × | × | × | × |
| E | O | × | × | × | × | × | × |
| F | O | O | O | O | O | O | O |
| G | O | O | O | O | × | × | × |
| H | O | O | O | O | × | × | × |
| I | O | × | × | O | × | × | × |
| J | O | O | O | O | × | × | × |
| K | O | O | O | O | × | × | × |
Table 16.
Results of the proposed double compression detection. Here, ‘Accuracy’ refers to the accuracy of detection results for detectable videos, not including undetectable videos.
Table 16.
Results of the proposed double compression detection. Here, ‘Accuracy’ refers to the accuracy of detection results for detectable videos, not including undetectable videos.
| Input | # of Camera Models | Detectable | Not
Detectable | Accuracy (%) |
|---|
| Unforged Video (HEVC) | | 13 | 0 | 100 |
| Forged Video (HEVC) using open-source | 13 | 13 | 0 | 100 |
| Forged Video (HEVC) using HM source | | 13 | 0 | 100 |
| Unforged Video (H.264) | | 10 | 1 | 100 |
| Forged Video (H.264) using open-source | 11 | 10 | 1 | 100 |
| Forged Video (H.264) using JM source | | 10 | 1 | 100 |




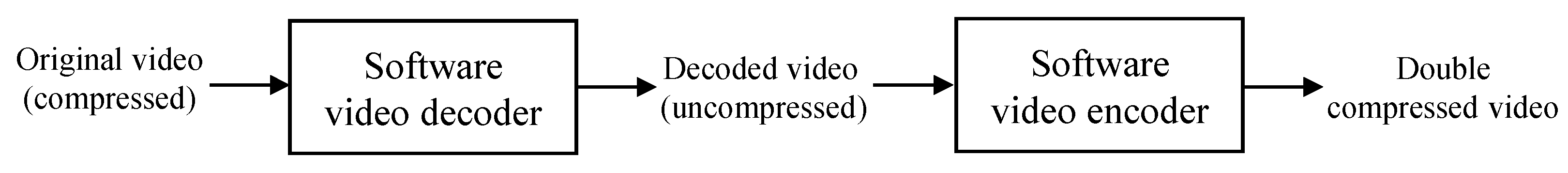

{kind=link}
{kind=link}
{kind=link}
{kind=link}
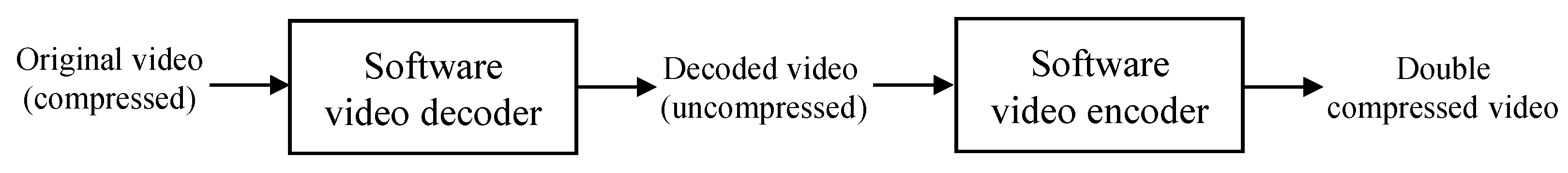{kind=link}