
Case Study: Improving the Quality of Dairy Cow Reconstruction with a Deep Learning-Based Framework

 , , ,
, , ,  , , , , , and
, , , , , and
Abstract
:1. Introduction
- We improved the depth image quality based on a convolutional neural network through the stereo data inputs;
- The 3D reconstruction framework is proposed to increase the accuracy of 3D point cloud registration from objects with little motion;
- Generated point clouds could be used as the input data for dairy cow characteristics analysis with a deep learning approach.
2. Related Work
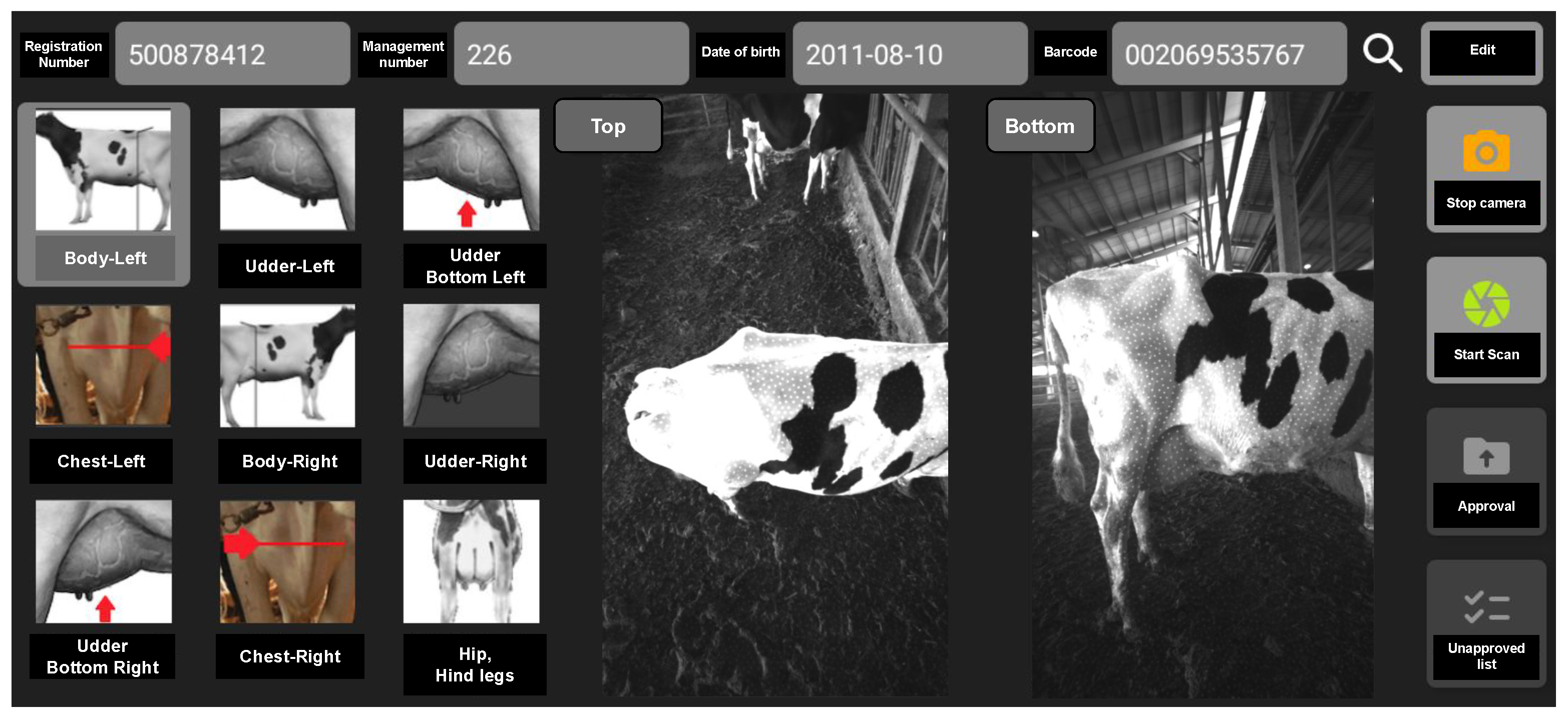
3. The Dairy Cow 3D Reconstruction Framework
- Data recording based on the CNN;
- Dairy cow 3D reconstruction.

3.1. Data Preparing for Dairy Cow 3D Reconstruction
3.2. Milk Cow 3D Reconstruction
3.2.1. Fragment Construction
3.2.2. Fragments Registration
3.2.3. Registration Refinement
3.2.4. Dairy Cow Full Body Integration
4. Experimental Results
4.1. Milk Cow Recording System
4.2. Depth Image Evaluation
4.3. Dairy Cow Point Cloud Registration Evaluation
4.4. Dairy Cow Point Cloud Registration Improvement
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ICP | Iterative Closest Point |
| FGR | Fast Global Registration |
| SIFT | Scale-Invariant Feature Transform |
| SURF | Speeded Up Robust Features |
| SGM | Semi-Global Matching |
| RUM | Recurrent Update Module |
| AGCL | Adaptive Group Correlation Layer |
| ORB | Oriented FAST and Rotated BRIEF) |
| RANSAC | Random Sample Consensus |
| FPFH | Fast Point Feature Histograms |
| TSDF | Truncated Signed Distance Function |
| SLAC | Simultaneous Localization and Calibration |
| CNN | Convolutional Neural Network |
| RMSE | Root Mean Squared Error |
References
- Dang, C.; Choi, T.; Lee, S.; Lee, S.; Alam, M.; Park, M.; Hoang, D. Machine Learning-Based Live Weight Estimation for Hanwoo Cow. Sustainability 2022, 14, 12661. [Google Scholar] [CrossRef]
- Rusinkiewicz, S.; Levoy, M. Efficient variants of the ICP algorithm. In Proceedings of the Third International Conference on 3-D Digital Imaging and Modeling, Quebec City, QC, Canada, 28 May–1 June 2001. [Google Scholar]
- Zhou, Q.-Y.; Park, J.; Koltun, V. Fast global registration. In Proceedings of the ECCV, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Yang, J.; Li, H.; Campbell, D.; Jia, Y. Go-ICP: A globally optimal solution to 3D ICP point-set registration. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2241–2254. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Besl, P.J.; McKay, N.D. A method for registration of 3-D shapes. In Proceedings of the ROBOTICS ’91, Boston, MA, USA, 14–15 November 1991. [Google Scholar]
- Park, J.; Zhou, Q.-Y.; Koltun, V. Colored Point Cloud Registration Revisited. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 143–152. [Google Scholar] [CrossRef]
- Choi, S.; Zhou, Q.-Y.; Koltun, V. Robust reconstruction of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–15 June 2015. [Google Scholar]
- Kerl, C.; Sturm, J.; Cremers, D. Dense visual SLAM for RGB-D cameras. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS 2013), Tokyo, Japan, 3–7 November 2013. [Google Scholar]
- Henry, P.; Krainin, M.; Herbst, E.; Ren, X.; Fox, D. RGBD mapping: Using Kinect-style depth cameras for dense 3D modeling of indoor environments. Int. J. Robot. Res. 2012, 31, 647–663. [Google Scholar] [CrossRef] [Green Version]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohli, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the ISMAR, Basel, Switzerland, 26–29 October 2011. [Google Scholar]
- Curless, B.; Levoy, M. A volumetric method for building complex models from range images. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996. [Google Scholar]
- Nister, D.; Naroditsky, O.; Bergen, J.R. Visual odometry. In Proceedings of the CVPR, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Newcombe, R.A.; Davison, A.J. Live dense reconstruction with a single moving camera. In Proceedings of the CVPR, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Endres, F.; Hess, J.; Sturm, J.; Cremers, D.; Burgard, W. 3-D mapping with an RGB-D camera. IEEE Trans. Robot. 2014, 30, 177–187. [Google Scholar] [CrossRef]
- Steinbrucker, F.; Kerl, C.; Cremers, D. Large-scale multi-resolution surface reconstruction from RGB-D sequences. In Proceedings of the ICCV, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Hirschmuller, H. Accurate and efficient stereo processing by semi-global matching and mutual information. In Proceedings of the CVPR, San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 807–814. [Google Scholar]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 4040–4048. [Google Scholar]
- Birchfield, S.; Tomasi, C. Depth discontinuities by pixel-to-pixel stereo. Int. J. Comput. Vis. 1999, 35, 269–293. [Google Scholar] [CrossRef]
- Sun, J.; Zheng, N.; Shum, H. Stereo matching using belief propagation. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 787–800. [Google Scholar]
- Li, J.; Wang, P.; Xiong, P.; Cai, T.; Yan, Z.; Yang, L.; Liu, J.; Fan, H.; Liu, S. Practical stereo matching via cascaded recurrent network with adaptive correlation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2022. [Google Scholar]
- Steinbrucker, F.; Sturm, J.; Cremers, D. Real-time visual odometry from dense RGB-D images. In Proceedings of the ICCV Workshops, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G.R. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the ICCV, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Stewenius, H.; Engels, C.; Nistér, D. Recent developments on direct relative orientation. ISPRS J. Photogramm. Remote Sens. 2006, 60, 284–294. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Theiler, P.W.; Wegner, J.D.; Schindler, K. Globally consistent registration of terrestrial laser scans via graph optimization. J. Photogramm. Remote Sens. 2015, 109, 126–138. [Google Scholar] [CrossRef]
- Huber, D.F.; Hebert, M. Fully automatic registration of multiple 3D data sets. Image Vis. Comput. 2003, 21, 637–650. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Medioni, G.G. Object modelling by registration of multiple range images. Image Vis. Comput. 1992, 10, 145–155. [Google Scholar] [CrossRef]
- Zhou, Q.-Y.; Koltun, V. Simultaneous localization and calibration: Self-calibration of consumer depth cameras. In Proceedings of the CVPR, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Mur-Artal, R.; Tardos, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 12551262. [Google Scholar] [CrossRef] [Green Version]
- Labbé, M.; Michaud, F. RTAB-Map as an open-source lidar and visual simultaneous localization and mapping library for large-scale and long-term online operation. J. Field Robot. 2019, 36, 416–446. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device | Specification |
|---|---|
| Depth Camera (Intel Realsense D435i) |
|
| Single Board Computer (LattePanda 2 Alpha ) |
|
| Evaluation | Point Cloud Registration | Registration Refinement | |||
|---|---|---|---|---|---|
| RANSAC | Current Approach | Point-to-Point ICP | Color ICP | Current Approach | |
| Fitness-Average | 0.48 | 0.50 | 0.5 | 0.49 | 0.5 |
| RMSE-Average | 0.0065 | 0.0063 | 0.0061 | 0.0063 | 0.0060 |
| Time (s) | 14.86 | 12.99 | 1.59 | 2.88 | 2.15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dang, C.; Choi, T.; Lee, S.; Lee, S.; Alam, M.; Lee, S.; Han, S.; Hoang, D.T.; Lee, J.; Nguyen, D.T. Case Study: Improving the Quality of Dairy Cow Reconstruction with a Deep Learning-Based Framework. Sensors 2022, 22, 9325. https://doi.org/10.3390/s22239325
Dang C, Choi T, Lee S, Lee S, Alam M, Lee S, Han S, Hoang DT, Lee J, Nguyen DT. Case Study: Improving the Quality of Dairy Cow Reconstruction with a Deep Learning-Based Framework. Sensors. 2022; 22(23):9325. https://doi.org/10.3390/s22239325
Chicago/Turabian StyleDang, Changgwon, Taejeong Choi, Seungsoo Lee, Soohyun Lee, Mahboob Alam, Sangmin Lee, Seungkyu Han, Duy Tang Hoang, Jaegu Lee, and Duc Toan Nguyen. 2022. "Case Study: Improving the Quality of Dairy Cow Reconstruction with a Deep Learning-Based Framework" Sensors 22, no. 23: 9325. https://doi.org/10.3390/s22239325