


Non-Contact Vibro-Acoustic Object Recognition Using Laser Doppler Vibrometry and Convolutional Neural Networks


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Data Collection and Preparation
2.1. Object Selection
2.2. Automated Data Acquisition System
2.3. Management of Measurement Challenges
2.4. Data Pre-Processing
3. Convolutional Neural Network Regularisation and Training
3.1. Summary of Fundamental Neural Network Concepts
3.2. Regularisation to Prevent Overfitting
3.3. Training Methodology for Response Classification
4. Response Classification Performance Assessment
4.1. The Effects of Pre-Processing and Training Set Size on Classification Accuracy
4.2. Sensitivity to Broader Object Classes
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LDV | Laser Doppler vibrometer |
| SLDV | Scanning laser Doppler vibrometer |
| AV | Autonomous vehicle |
| NN | Neural network |
| CNN | Convolutional neural network |
| TL | Transfer learning |
Appendix A



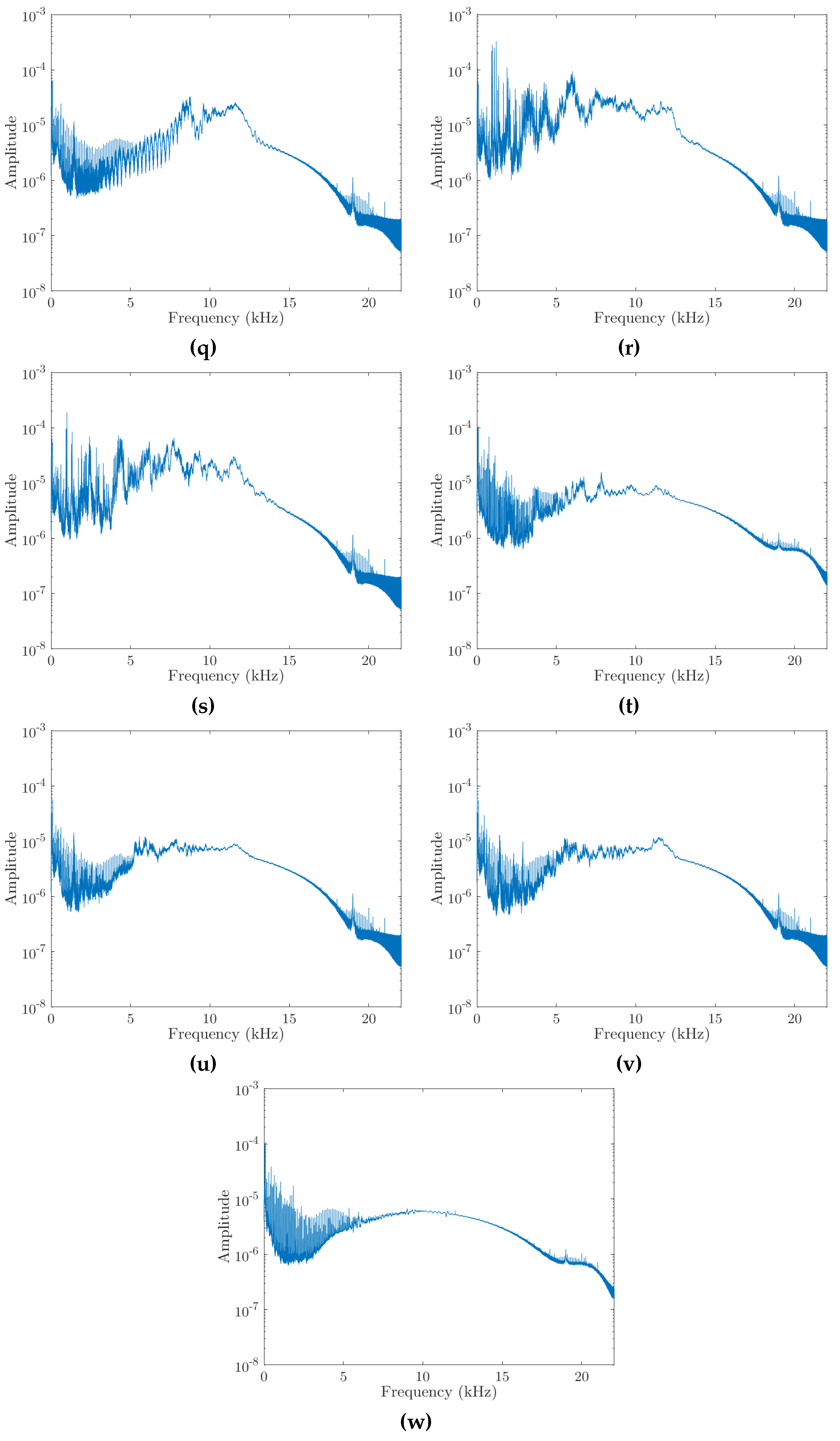
References
- Rothberg, S.J.; Allen, M.S.; Castellini, P.; Di Maio, D.; Dirckx, J.J.J.; Ewins, D.J.; Halkon, B.J.; Muyshondt, P.; Paone, N.; Ryan, T.; et al. An International Review of Laser Doppler Vibrometry: Making Light Work of Vibration Measurement. Opt. Lasers Eng. 2017, 99, 11–22. [Google Scholar] [CrossRef] [Green Version]
- Oberst, S.; Tuttle, S. Nonlinear Dynamics of Thin-Walled Elastic Structures for Applications in Space. Mech. Syst. Signal Process. 2018, 110, 469–484. [Google Scholar] [CrossRef]
- Yang, S.; Allen, M.S. Output-Only Modal Analysis Using Continuous-Scan Laser Doppler Vibrometry and Application to a 20 KW Wind Turbine. Mech. Syst. Signal Process. 2012, 31, 228–245. [Google Scholar] [CrossRef] [Green Version]
- Gwashavanhu, B.; Oberholster, A.J.; Heyns, P.S. Rotating Blade Vibration Analysis Using Photogrammetry and Tracking Laser Doppler Vibrometry. Mech. Syst. Signal Process. 2016, 76–77, 174–186. [Google Scholar] [CrossRef] [Green Version]
- Sabatier, J.M.; Xiang, N. Laser-Doppler-Based Acoustic-to-Seismic Detection of Buried Mines. In Proceedings of the Detection and Remediation Technologies for Mines and Minelike Targets IV 1999, Orlando, FL, USA, 5–9 April 1999. [Google Scholar]
- Avci, O.; Abdeljaber, O.; Kiranyaz, S.; Hussein, M.; Gabbouj, M.; Inman, D.J. A Review of Vibration-Based Damage Detection in Civil Structures: From Traditional Methods to Machine Learning and Deep Learning Applications. Mech. Syst. Signal Process. 2021, 147, 107077. [Google Scholar] [CrossRef]
- Cunha, B.; Droz, C.; Zine, A.; Foulard, F.; Ichchou, M. A Review of Machine Learning Methods Applied to Structural Dynamics and Vibroacoustic. arXiv 2022, arXiv:2204.06362. [Google Scholar]
- Ciaburro, G.; Iannace, G. Machine-Learning-Based Methods for Acoustic Emission Testing: A Review. Appl. Sci. 2022, 12, 10476. [Google Scholar] [CrossRef]
- Lameri, S.; Lombardi, F.; Bestagini, P.; Lualdi, M.; Tubaro, S. Landmine Detection from GPR Data Using Convolutional Neural Networks. In Proceedings of the 25th European Signal Processing Conference, Kos, Greece, 28 August–2 September 2017. [Google Scholar]
- Milton, J.; Halkon, B.; Oberst, S.; Chiang, Y.K.; Powell, D. Sonar-Based Buried Object Detection via Statistics of Recurrence Plot Quantification Measures. In Proceedings of the International Congress on Sound and Vibration Proceedings, Singapore, 24–28 July 2022. [Google Scholar]
- Richmond, J.L.; Halkon, B.J. Speaker Diarisation of Vibroacoustic Intelligence from Drone Mounted Laser Doppler Vibrometers. J. Phys. Conf. Ser. 2021, 2041, 012011. [Google Scholar] [CrossRef]
- Halkon, B.J.; Rothberg, S.J. Establishing Correction Solutions for Scanning Laser Doppler Vibrometer Measurements Affected by Sensor Head Vibration. Mech. Syst. Signal Process. 2021, 150, 107255. [Google Scholar] [CrossRef]
- Darwish, A.; Halkon, B.; Rothberg, S.; Oberst, S.; Fitch, R. A Comparison of Time and Frequency Domain-Based Approaches to Laser Doppler Vibrometer Instrument Vibration Correction. J. Sound Vib. 2022, 520, 116607. [Google Scholar] [CrossRef]
- Jiang, L.A.; Albota, M.A.; Haupt, R.W.; Chen, J.G.; Marino, R.M. Laser Vibrometry from a Moving Ground Vehicle. Appl. Opt. 2011, 50, 2263. [Google Scholar] [CrossRef] [PubMed]
- Courville, S.W.; Sava, P.C. Speckle Noise Attenuation in Orbital Laser Vibrometer Seismology. Acta Astronaut. 2020, 172, 16–32. [Google Scholar] [CrossRef]
- Courville, S.W.; Sava, P.C. Speckle Noise in Orbital Laser Doppler Vibrometry. Lunar Planet. Sci. Conf. 2019, 39, 697–699. [Google Scholar]
- Sava, P.; Asphaug, E. Seismology on Small Planetary Bodies by Orbital Laser Doppler Vibrometry. Adv. Sp. Res. 2019, 64, 527–544. [Google Scholar] [CrossRef]
- Dräbenstedt, A.; Cao, X.; Polom, U.; Pätzold, F.; Zeller, T.; Hecker, P.; Seyfried, V.; Rembe, C. Mobile seismic exploration. In Proceedings of the 12th International A.I.VE.LA. Conference on Vibration Measurements by Laser and Noncontact Techniques: Advances and Applications, Ancona, Italy, 29 June–1 July 2016. [Google Scholar]
- Ismail, M.A.A.; Bierig, A.; Hassan, S.R.; Kumme, R. Flyable Mirrors: Laser Scanning Vibrometry Method for Monitoring Large Engineering Structures Using Drones. In Proceedings of the Optics and Photonics International Congress, Pacifico Yokohama, Japan, 22–26 April 2019. [Google Scholar]
- Takamuku, S.; Hosoda, K.; Asada, M. Object Category Acquisition by Dynamic Touch. Adv. Robot. 2008, 22, 1143–1154. [Google Scholar] [CrossRef]
- Chen, C.L.; Snyder, J.O.; Ramadge, P.J. Learning to Identify Container Contents through Tactile Vibration Signatures. In Proceedings of the IEEE International Conference on Simulation, Modeling, and Programming for Autonomous Robots, San Francisco, CA, USA, 13–16 December 2016. [Google Scholar]
- Sinapov, J.; Bergquist, T.; Schenck, C.; Ohiri, U.; Griffith, S.; Stoytchev, A. Interactive Object Recognition Using Proprioceptive and Auditory Feedback. Int. J. Rob. Res. 2011, 30, 1250–1262. [Google Scholar] [CrossRef]
- Jin, S.; Liu, H.; Wang, B.; Sun, F. Open-Environment Robotic Acoustic Perception for Object Recognition. Front. Neurorobot. 2019, 13, 1–15. [Google Scholar] [CrossRef]
- Xiao, T.; Zhao, S.; Qiu, X.; Halkon, B. Using a Retro-Reflective Membrane and Laser Doppler Vibrometer for Real-Time Remote Acoustic Sensing and Control. Sensors 2021, 21, 3866. [Google Scholar] [CrossRef]
- Xiao, T.; Qiu, X.; Halkon, B. Ultra-Broadband Local Active Noise Control with Remote Acoustic Sensing. Sci. Rep. 2020, 10, 1–12. [Google Scholar] [CrossRef]
- Castellini, P.; Martarelli, M.; Tomasini, E.P. Laser Doppler Vibrometry: Development of Advanced Solutions Answering to Technology’s Needs. Mech. Syst. Signal Process. 2006, 20, 1265–1285. [Google Scholar] [CrossRef]
- Abeßer, J. A Review of Deep Learning Based Methods for Acoustic Scene Classification. Appl. Sci. 2020, 10, 2020. [Google Scholar] [CrossRef] [Green Version]
- Ciaburro, G.; Iannace, G. Improving Smart Cities Safety Using Sound Events Detection Based on Deep Neural Network Algorithms. Informatics 2020, 7, 23. [Google Scholar] [CrossRef]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and Music Signal Analysis in Python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- McCulloch, W.S.; Pitts, W. A Logical Calculus of the Ideas Immanent in Nervous Activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Gugger, S.; Howard, J. Deep Learning for Coders with Fastai and PyTorch: AI Applications without a PhD; O’Reilly Media: Sebastopol, CA, USA, 2020; ISBN 9781492045526. [Google Scholar]
- Prechelt, L. Early Stopping—But When? In Neural Networks: Tricks of the Trade, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 53–67. ISBN 978-3-642-35289-8. [Google Scholar]
- Olivas, E.S.; Guerrero, J.D.M.; Sober, M.M.; Benedito, J.R.M.; López, A.J.S. Handbook of Research on Machine Learning Applications and Trends; IGI Global: Hershey, PA, USA, 2010; ISBN 9781605667669. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; Miami, FL, USA, 20–25 June 2009.
- Howard, J.; Gugger, S. Fastai. 2018. Available online: https://github.com/fastai/fastai (accessed on 21 October 2022).
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Santa Rosa, CA, USA, 24–31 March 2017. [Google Scholar]
- Smith, L.N. A Disciplined Approach to Neural Network Hyper-Parameters: Part 1—Learning Rate, Batch Size, Momentum, and Weight Decay. arXiv 2018, arXiv:1803.09820. [Google Scholar]
- Smith, L.N.; Topin, N. Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates. arXiv 2018, arXiv:1708.07120. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: New York, NY, USA, 2013; ISBN 978-1-4614-6848-6. [Google Scholar]
- Krawczyk, B. Learning from Imbalanced Data: Open Challenges and Future Directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Swanson, P. Feasibility of Using Laser-Based Vibration Measurements to Detect Roof Fall Hazards in Underground Mines. In Proceedings of the Fifth International Conference on Vibration Measurements by Laser Techniques: Advances and Applications, Ancona, Italy, 18–21 June 2002. [Google Scholar]
- Brink, A.; Roberts, M.K.C. Early Warning and/or Continuous Risk Assessment of Rockfalls in Deep South African Mines. In Proceedings of the Fourth International Seminar on Deep and High Stress Mining, Perth, Australia, 7–9 November 2007. [Google Scholar]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Darwish, A.; Halkon, B.; Oberst, S. Non-Contact Vibro-Acoustic Object Recognition Using Laser Doppler Vibrometry and Convolutional Neural Networks. Sensors 2022, 22, 9360. https://doi.org/10.3390/s22239360
Darwish A, Halkon B, Oberst S. Non-Contact Vibro-Acoustic Object Recognition Using Laser Doppler Vibrometry and Convolutional Neural Networks. Sensors. 2022; 22(23):9360. https://doi.org/10.3390/s22239360
Chicago/Turabian StyleDarwish, Abdel, Benjamin Halkon, and Sebastian Oberst. 2022. "Non-Contact Vibro-Acoustic Object Recognition Using Laser Doppler Vibrometry and Convolutional Neural Networks" Sensors 22, no. 23: 9360. https://doi.org/10.3390/s22239360