1. Introduction
An important part of the urban transportation system, online car-hailing has become the transportation choice for more and more urban residents. In 2020, there were 214 online car-hailing platforms across China, with an average 21 million daily orders taking place. Accurately forecasting the travel demand for online car-hailing is of great significance for regard to reducing vehicle idling, improving operational efficiency, and reducing traffic congestion and energy consumption [
1,
2,
3,
4]. Reasonable forecasting results can provide data support for vehicle scheduling and allocation, which is beneficial for solving problems caused by asymmetric supply and demand, as well as maximizing benefits for passengers, drivers, and ride-hailing platforms [
5].
In the early stages in the development of online car-hailing, many scholars used questionnaires or interviews to make judgments concerning the future development status and changing trends with regard to the scale of travel. However, the survey process comes with problems such as low efficiency, not being able to guarantee timeliness, and in particular, a lack of an accurate description of travel demand [
6]. With the accumulation of historical data on online car-hailing, scholars have carried out quantitative forecasting research on the operation status of online car-hailing. The main representative models are the time series model [
7], historical average model, Kalman filter model, and the linear regression analysis method [
8]. In recent years, intelligent forecasting models have gradually become used widely in urban traffic prediction, and mainly comprise neural networks, non-parametric regression prediction methods, support vector machines, and other methods [
7]. Long short-term memory network (LSTM) is a time recurrent neural network, which is suitable for processing and predicting important events with relatively long intervals and delays in time series, and is suitable for traffic flow modeling and prediction. The unique unit structure of LSTM provides great advantages in dealing with temporal short-term traffic flow prediction problems. Ma et al. (2015) constructed a prediction model based on LSTM which effectively captured nonlinear traffic dynamics and automatically determined the optimal time delay. The efficiency of the model was verified by measured data [
9]. Tian et al. (2018) used LSTM to predict traffic flow in the absence of data, and achieved higher accuracy than traditional methods [
10]. Ye et al. (2020) combined deep learning model of LSTM + Attention for short-term demand forecasting of online car-hailing. The results show that the LSTM + Attention model is superior to other models [
1]. Niu K et al. (2019) proposed a new region partition-aided long short-term memory neural network for car-hailing service demand prediction [
11]. In 2017, the Transformer structure composed entirely of attentional mechanisms was proposed. In recent years, there have also been some studies applying it to traffic flow prediction [
12]. Li (2021) constructed a lightweight traffic flow prediction model based on Transformer, which can predict the traffic volume of any area in the next period [
13]. In order to predict the travel demand of online car-hailing more accurately, Bi et al. (2022) proposed a new spatio-temporal prediction method model based on Transformer architecture. Compared with the three most commonly used models, the results show that the model has the best prediction accuracy and prediction accuracy training speed [
14]. With the rapid development of online big data technology and the rise of non-parametric regression models in the field of forecasting, forecasting methods represented by the K-nearest neighbor method have started to be introduced into the field of transportation. The main technical ideas of this method include predictions being performed by searching for the K records in the historical database that are most similar to the feature vector of the predicted value, finding the K historical state vectors that are most similar to the current state vector, and, after weighting the historical state vector, the current state value being predicted. Smith et al. (1997) used the same historical data set and used the time series model, the ARIMA model, and the neural network model to forecast, and found that the K-nearest neighbor method had the best stability and error accuracy [
15]. There are three core problems in the K-nearest neighbor method: The first concern involves the issue of identification and classification of different patterns from historical data when classifying the historical data set. The second concern involves constructing a state vector: in the field of transportation, historical traffic data are often divided into several samples, each of which is a state vector. The third problem involves determining the K-value algorithm.
Regarding the classification of historical data sets, Liu Z et al. (2017) took the historical intersection traffic volume data set on the Portland Expressway in the United States as a whole, and did not classify them according to time or space distribution [
16]. Lin P et al. (2018) divided the passenger flow at the Guangzhou South Railway Station into ten daily passenger flow development models, but still used the whole-day historical data set for prediction [
17]. Wang X et al. (2015) analyzed the travel time of the Shanghai–Nanjing Expressway from Shanghai to Nanjing; according to changes in the expressway traffic, the historical data set was divided into a morning peak, an evening peak, a flat peak, and other categories, and a travel time prediction was carried out separately. However, the classification of historical data was mainly based on subjective judgments of traffic wave-forms, and there was a lack of scientific verification or analysis of data classification [
18].
The state vector is used to describe the comparison standard at different times. Since the traffic volume or passenger volume has the autocorrelation of time series, many scholars choose T times before the predicted time as the feature vector. For the selection of T, most scholars usually divide it according to one day or one week. For example, to predict the traffic volume of a certain hour, the preferred unit of time is days, and the first 23 h are used as the state vector. To predict the traffic data on a certain day, the week is used as the unit, and the first 6 days are used as the state vector [
19]. This method can lead to large errors in some fields occurring. Some scholars have noticed that the selection of T has a significant impact on prediction accuracy and the T value is selected by the correlation coefficient, but in-depth research on the relationship between the correlation coefficient ρ and the T value is lacking [
18]. Porwik P et al. found that “nearest neighbors” always appeared in a relatively narrow time period and that T was below 10 time periods in most cases, but did not propose a specific calculation method for the T value. By traversing the possible T values, Wang X et al. (2019) proposed a method for selecting the T value based on the smallest prediction error, which has great reference significance [
20].
In the K-nearest neighbor prediction algorithm, the value of K affects the accuracy of any short-term traffic flow prediction; choosing an appropriate K value plays a crucial role in short-term traffic flow prediction. There are many research theories on the selection of a K value. Zhou X et al. (2006) believe that the randomness of traffic flow is too high, and propose setting the number of K to different values according to different modes, thereby optimizing the prediction accuracy [
21]. Yu B et al. (2012) believe that after the K value satisfies the expected value, a smaller K value can be taken to improve the model calculation speed [
22]. Zhu B (2019) used a K-means clustering algorithm to divide the passenger flow into data sets under different conditions, and then performed K-Fold cross-validation on the data sets under different conditions to determine the value of the number of neighbors K under different conditions [
23]. Lei S (2017) took 20 sets of data from the historical database according to the three traffic states for experimental verification; a value of K from 5 to 12 was taken in order to carry out short-term traffic flow predictions, and they were compared so as to obtain the prediction results on short-term traffic flow. Compared with the constant K value, the prediction method using the variable K value has better prediction accuracy [
24]. The above scholars have proposed different approaches to K-value calculation from different perspectives, but their main core remains basically the same, namely the setting a range of K-value values and determining the evaluation method of prediction accuracy, traversing all K-values and determining the optimal K-value with the goal of the highest prediction accuracy or prediction accuracy reaching a certain threshold.
Existing research provides good methods for the short-term forecasting of urban online car-hailing demand, but there are also some shortcomings. Some model methods, such as the time series method, which perform well in the field of long-term forecasting are not fully adapted to the characteristics of a large quantity of data, strong volatility, and strong timeliness in the operation of online car-hailing, and expose a large deficiency in the aspect of prediction delay [
18]. The K-nearest neighbor model can better adapt to these features. The algorithm is simple and the theory is mature, which can be used for classification and regression, and it is more suitable for automatic classification of class domains with large sample size. However, there is still room for optimization in the selection of historical data set classification, the state vector K, and the K value in the existing K-nearest neighbor methods. Therefore, based on the order data of urban online car-hailing platform, aiming at the characteristics of online car-hailing operation, this paper explores the optimization of K and T values to improve the K-nearest neighbor algorithm model. In response to these problems, this paper aims to forecast the demand for online car-hailing. First, the data set is divided into “
n” categories according to the unit of day; secondly, the state vector dimension T takes values from 1 to
n − 1 and calculates the prediction error under different values. At the same time, for each K, the possible value range of K is traversed, and then the T and K are found with the highest prediction accuracy. Finally, the errors from different forecasting methods are compared in order to verify the scientific nature and feasibility of the research method.
2. Methods
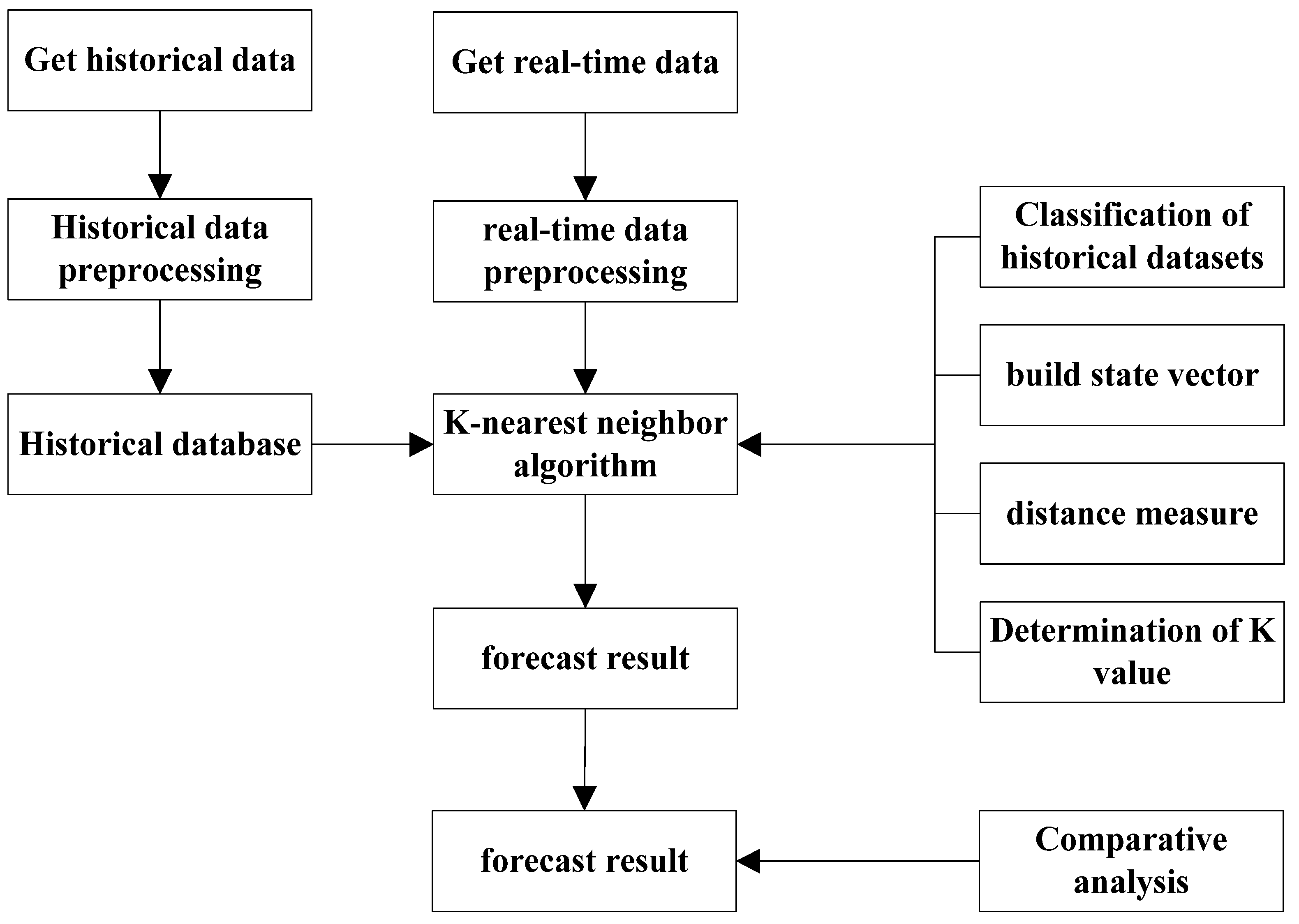
2.1. Basic Idea of the K-Nearest Neighbor Algorithm
The K-nearest Neighbor (KNN) algorithm is an efficient non-parametric classification algorithm proposed by Cover and Hart (1967) [
25]. It makes predictions by searching for the K records in a historical database that are most similar to the feature vector of the predicted value. It has strong stability and has been widely used in classification, regression, and pattern recognition in recent years. Based on the improved K-nearest neighbor model algorithm, this paper establishes a short-term forecasting model for online car-hailing demand, and constructs the basic flow of the algorithm for the short-term prediction of urban online car-hailing demand as follows:
- (1)
The original database is cleaned of historical orders, and one day is divided into 48 units (30 min per unit), which builds an order data set;
- (2)
The search mechanism of the model is determined, which is composed of the state vector, the distance measurement method, the value of the state vector T and the number of neighbors K;
- (3)
The K nearest neighbor prediction algorithm is determined and the prediction result is calculated;
- (4)
The mean absolute percentage error (MAPE) is used as an indicator in order to evaluate the prediction results, and a comparative analysis is conducted.
The algorithm flow chart is shown in
Figure 1.
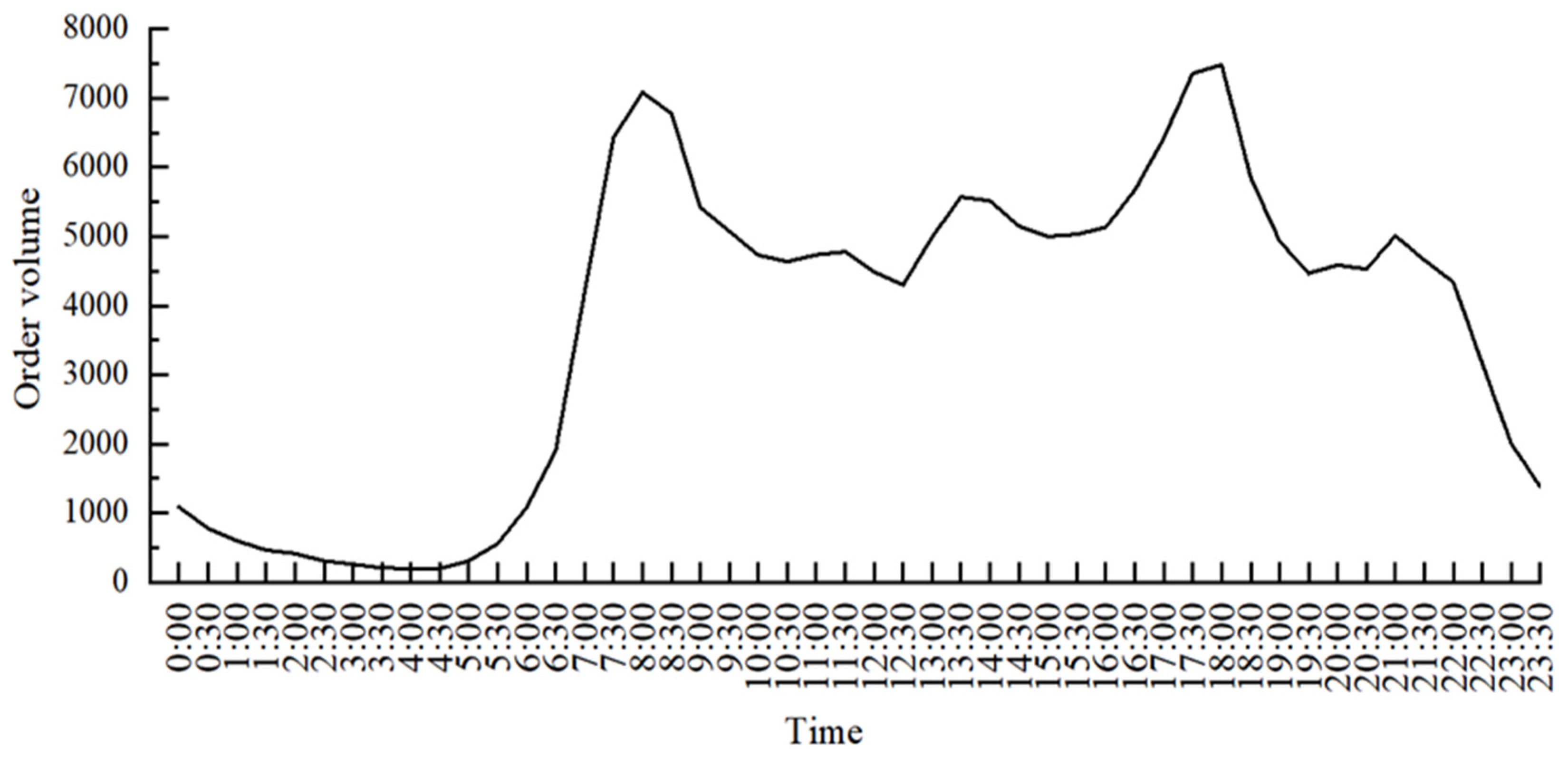
2.2. Classification of Historical Data
This paper divides 24 h a day into 48 time units, each time unit is 30 min, counts the number of online car-hailing orders in each time unit from the platform, and analyzes its change trends. In general, prediction accuracy increases as the classification of the data set increases, so the data is divided into 48 categories in order to improve the prediction accuracy, that is, 1 (00:00), 2 (00:30), 3 (01:00), 4 (01:30)...48 (23:30), as shown in
Figure 2.
2.3. Constructing the State Vector
The state vector is the standard for comparing the current data with the historical data. Generally, the factors that are most relevant to the prediction object are selected to predict [
22]. The real-time data on the forecast day can fully reflect the change trend of its passenger flow. Therefore, its nearest neighbor can be found in the historical database through variation of passenger flow presented by the real-time data, and the passenger flow at the next time can be calculated through the change law of real-time data and historical data so as to construct the state vector.
In the formula, n represents the nth day, and when n is 0, it represents the forecast day; xn(T − 1) is the number of urban online car-hailing orders in the period T − 1 on the nth day before the forecast date; because T must be smaller than the dimension of the data set (48), the value range of T is [1, 47]. In order to obtain the optimal T value, this paper intends to traverse all T values with the highest prediction accuracy as the goal.
2.4. Distance Measurement Method
The distance measurement method is used to measure the approximation of each historical sample in the historical database and the current data. Many previous studies have chosen Euclidean distance as the distance measurement method [
16,
17,
18]. And Euclidean distance is a time series alignment method aligned according to time points, calculate the sum of Euclidean distances between the same time points as the distance between two time series, which is suitable for prediction on online car-hailing demand comparison at different time points.
In the formula, dn is the distance between the data from each period of the forecast day and the data from each period of the historical day, xni is the number of online car-hailing orders in the city in the ith period of the nth day before the forecast date, and x0j is the delivery order volume for the city in the jth period of the forecast day.
2.5. Evaluation Method
Commonly used evaluation model indicators are Mean Absolute Error (
MAE), Mean Squared Error (
MSE), Mean Absolute Percentage Error (
MAPE), and Mean Squared Percentage Error (
MSPE).
MAPE is standardized on the basis of the other evaluation indicators, which more intuitively reflects the prediction accuracy and difference of this model and has good adaptability. Therefore, this paper uses the mean absolute percentage error (
MAPE) index as the performance evaluation of the model. The smaller the
MAPE, the better the model is. Its calculation formula is as follows:
In the formula, n is the number of samples, xi is the actual value of the sample, and is the predicted value of the sample.
2.6. Prediction Algorithms
The prediction algorithm is used to describe a way to use the searched K groups of neighbors to predict the demand at the next moment:
In the formula, is the predicted value for the current data, xi is the order quantity corresponding to the ith neighbor searched in the historical database, and di is the distance between the current data and the ith neighbor.
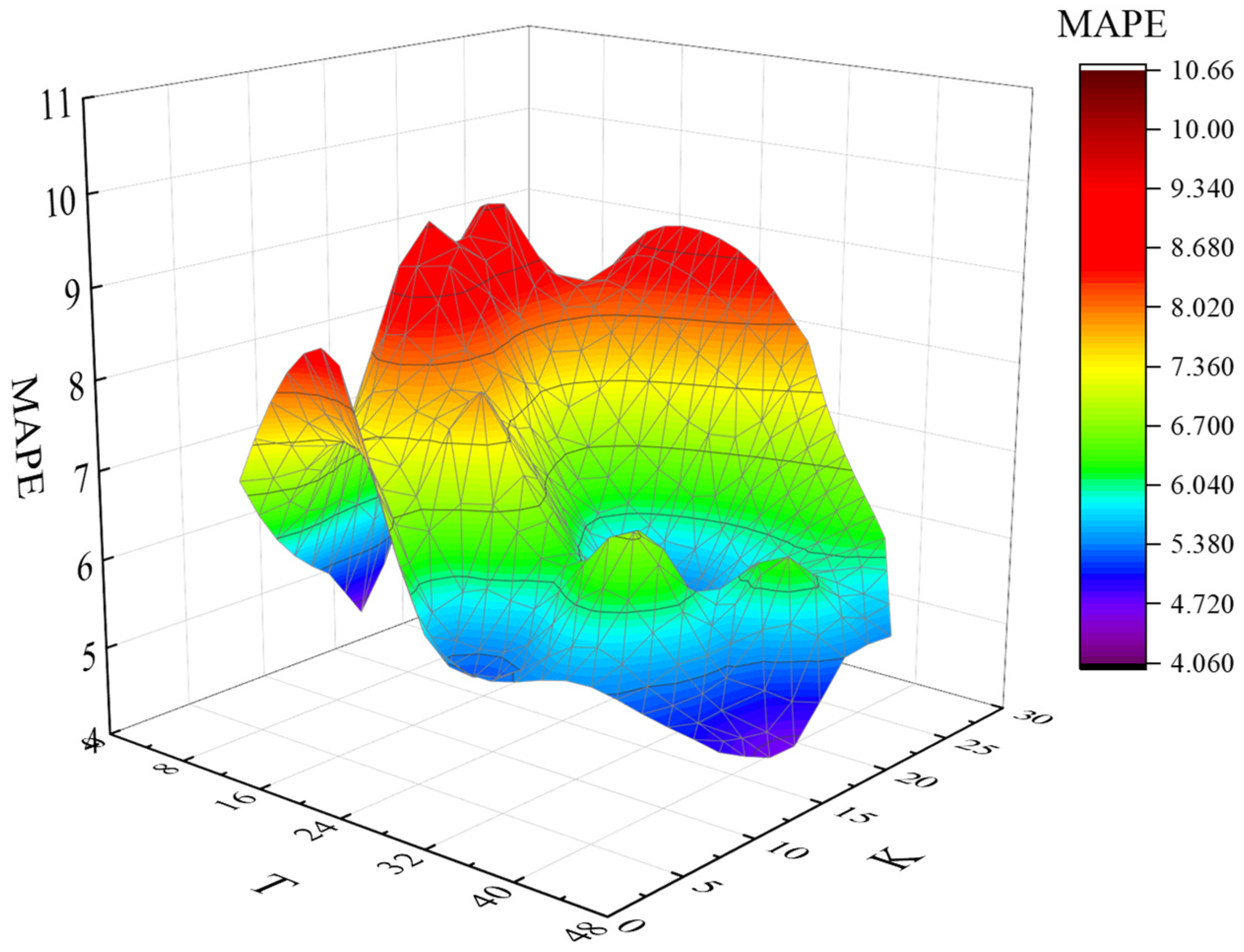
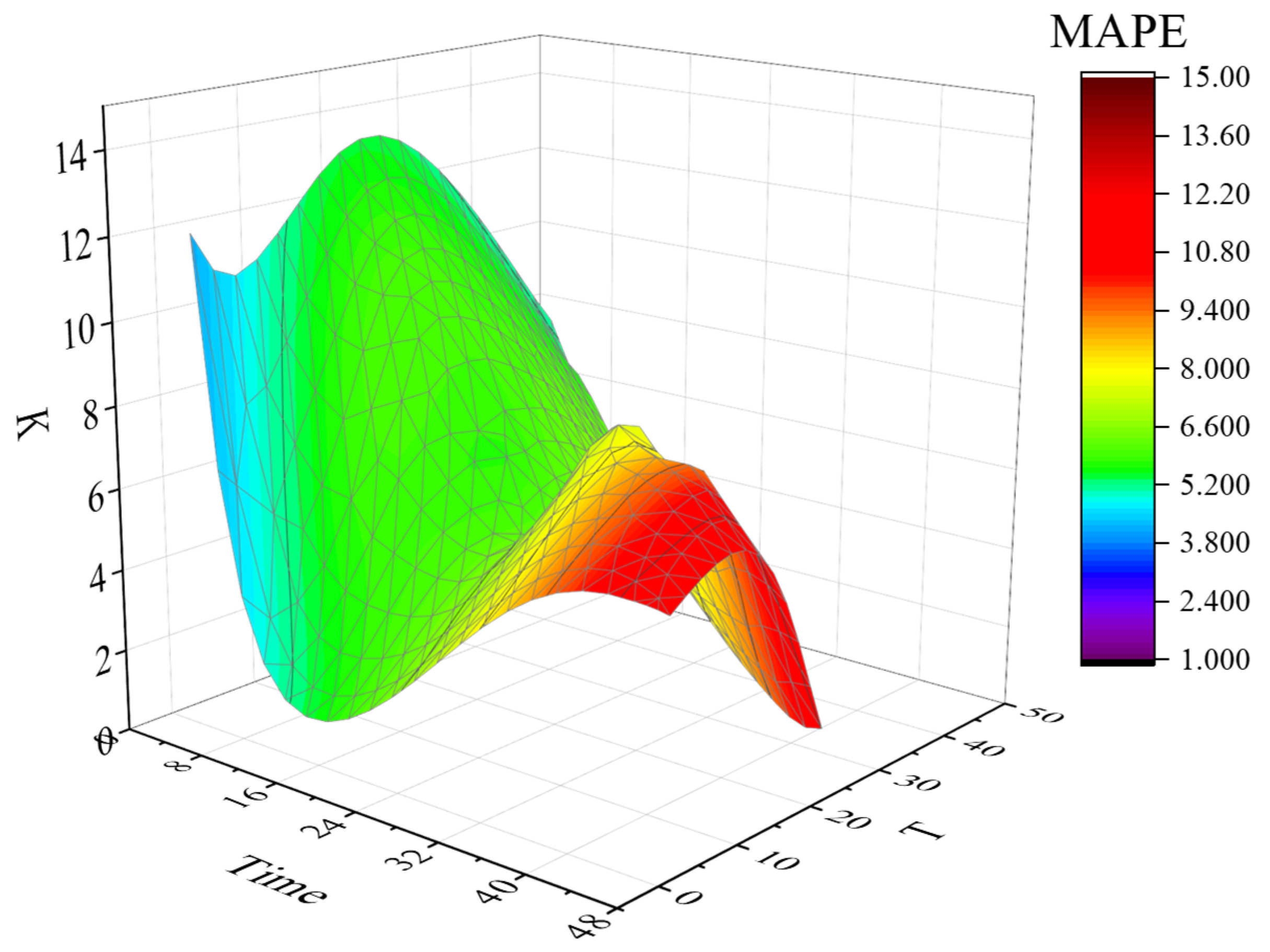
2.7. Calibration of Adaptive K Value and T Value
The way in which a reasonable K value and T value are chosen is key to the prediction model [
22]. In this paper, the prediction scenarios are classified, the error rate of change of the prediction results under different K and T values is calculated for each category, and the prediction accuracy is compared to select the better value.
Step 1: The predicted scenarios are classified, and the predicted values are divided into N categories, set n = ni.
Step 2: The value of the state vector T in the scene is determined, and T = Ti, Ti ∈ [1, 47] is set.
Step 3: K = Kj, Kj ∈ [1, Kmax] is set, and Kmax is comprehensively determined according to the quantity of historical data.
Step 4: Any one-day De from the historical data set is selected as the test data set, and other n − 1 days are selected as the training data set, in which each data set has 48 pieces of data. Forty-eight and a half hours of urban online car-hailing orders are represented.
Step 5: The mean absolute error percentage is calculated for the test data set De under
Ti and
Kj.
Step 6: The mean absolute error percentage is calculated for all test data sets
De under
Ti and
Kj.
Step 7: When the minimum value of MAPE is obtained, the predicted corresponding Ti and Kj are the optimal values of the data set in the ni prediction scenario.
4. Discussion
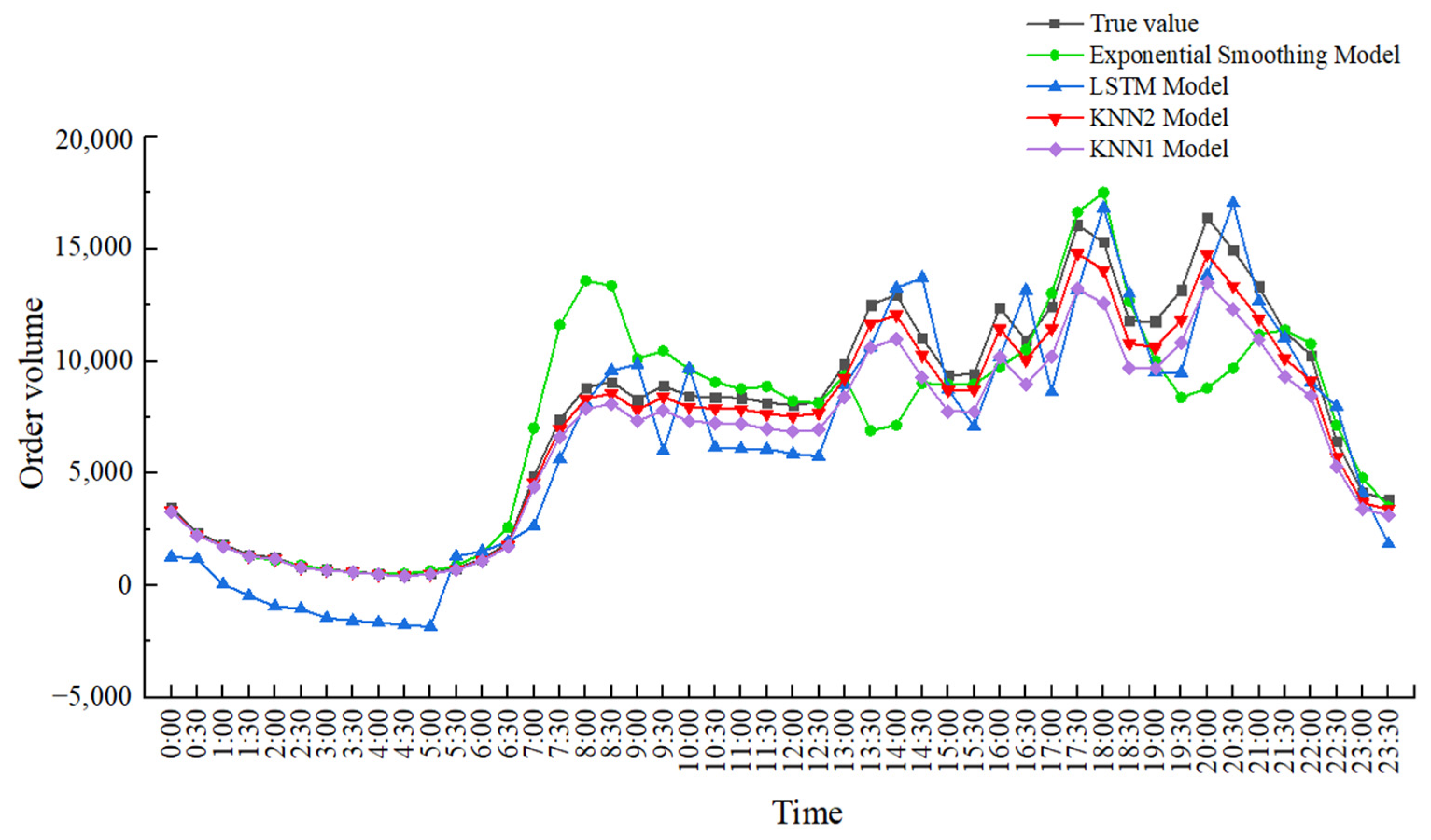
According to the characteristics of online car-hailing order data, a method of optimizing K value and T value to improve the K-nearest neighbor algorithm model is proposed. To better illustrate the prediction effect, the exponential smoothing prediction model, KNN1 model, LSTM model and KNN2 model are used to predict the online car-hailing order volume on 31 January 2021 and compare the results, as shown in
Figure 6. In addition, this paper selects the period 14:30 on 31 January 2021 as the prediction analysis sample.
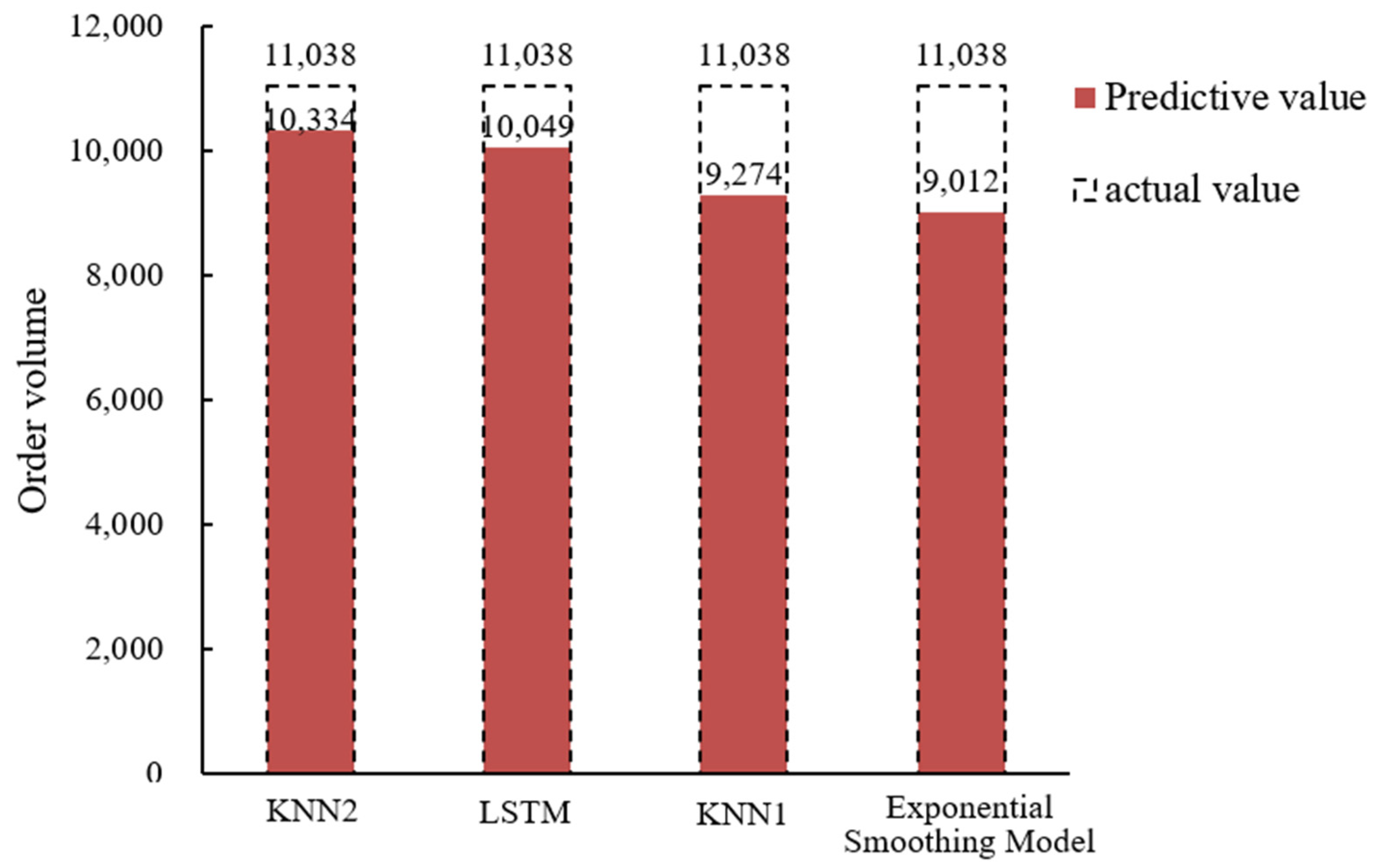
The exponential smoothing model, also known as exponential smoothing, is an important time series forecasting method. This paper uses SPSS for the exponential smoothing forecast, and the operation process is as follows: first, the date format is defined as a day; second, a time series prediction model is created, an exponential smoothing model is selected, and the steps are followed to complete the settings in order to obtain the prediction result value. This predicted value and the
MAPE calculation formula are used to calculate the
MAPE value predicted by the exponential smoothing model, and this can be found below in
Table 4.
The KNN1 is the model with a fixed T but improved K value. One day is divided into 48 time periods, so KNN1 model set the state vector T = 47. According to the minimum
MAPE, the optimal K value is calculated, and the prediction results are shown in
Table 4.
The LSTM model uses the MinMaxScaler scaler; all data are scaled between [0,1] to speed up convergence. The data in the form of time series is transformed into the form of supervised learning set, that is, the former number is taken as the input and the latter number as the corresponding output. An LSTM model was constructed and trained. The number of samples was 1, the number of trainings was 3, and the number of neurons in the LSTM layer was 5. After the predicted value is obtained, inverse scaling and inverse differentiation are performed to restore it to the original value range and traverse all test set data. The above operations are performed on each row of data and the final predicted value is saved; the prediction results are shown in
Table 4.
The KNN2 model is based on the above method to determine the appropriate T value and K value. For the time unit of 14:30, the corresponding optimal T value is 18 and K value is 9; Finally, the predicted value and
MAPE value are filled in
Table 4 below. The comparison of the prediction results of the four methods is shown in
Figure 7.
From
Figure 6 and
Table 4, it can be concluded that exponential smoothing model is modified on the basis of simple historical average model, but it lacks the ability to identify the turning point of the data, and the prediction accuracy is still low compared with KNN model. The KNN1 model optimizes the K value, but does not consider the influence of the fixed T value on the prediction results; compared with the exponential smoothing model, the prediction accuracy is improved while it is still low compared with the KNN2 model, indicating that the consideration of increasing the T value can make the prediction of the model more accurate. The LSTM model has an advantage in the time series problem because of its internal forgetting layer structure, which is relatively suitable for solving the problem of online car-hailing demand forecasting; the prediction results are relatively smooth and the average absolute percentage error can be optimized to 8.96%, which is similar to the prediction accuracy of the KNN2 model proposed in this paper. We believe that if the relevant parameters of LSTM are further optimized, its prediction effect can be further improved. The KNN2 model can better adapt to the prediction of the fluctuation data of the online car-hailing. Finally, the average absolute percentage errors of the exponential smoothing model, KNN1 model, LSTM model and the KNN2 model are 18.35%, 15.98%, 8.96% and 6.38%. Compared with the other three prediction methods, the prediction accuracy of the KNN2 model can reach 93.62%, which is much higher than the exponential smoothing model (81.65%) and the KNN1 model (84.02%), similar to LSTM model (91.04%). Yu Bin stated that the K-nearest neighbor prediction model has a high prediction accuracy in short-term predictions [
22], and the research in this paper also verifies this point of view. It can be seen that the K-nearest neighbor prediction model has high prediction accuracy and applicability in the short-term prediction of online car-hailing orders.
In summary, when comparing the four prediction methods through the analyses in this paper, it can be ascertained that the K-nearest neighbor algorithm is simple in theory, easy to implement, has a high accuracy, the highest prediction accuracy and a stronger adaptive ability. It can change with predicted environmental conditions, and through the classification of historical data sets and the adjustment of search algorithms and related parameters, the appropriate T value and K value are adopted. It can more accurately predict the demand for online car-hailing in cities, has good applicability in real time, and is more suitable for the short-term prediction of complex mutations, as well as being able to predict the trend of data changes in real time.












{kind=link}
{kind=link}
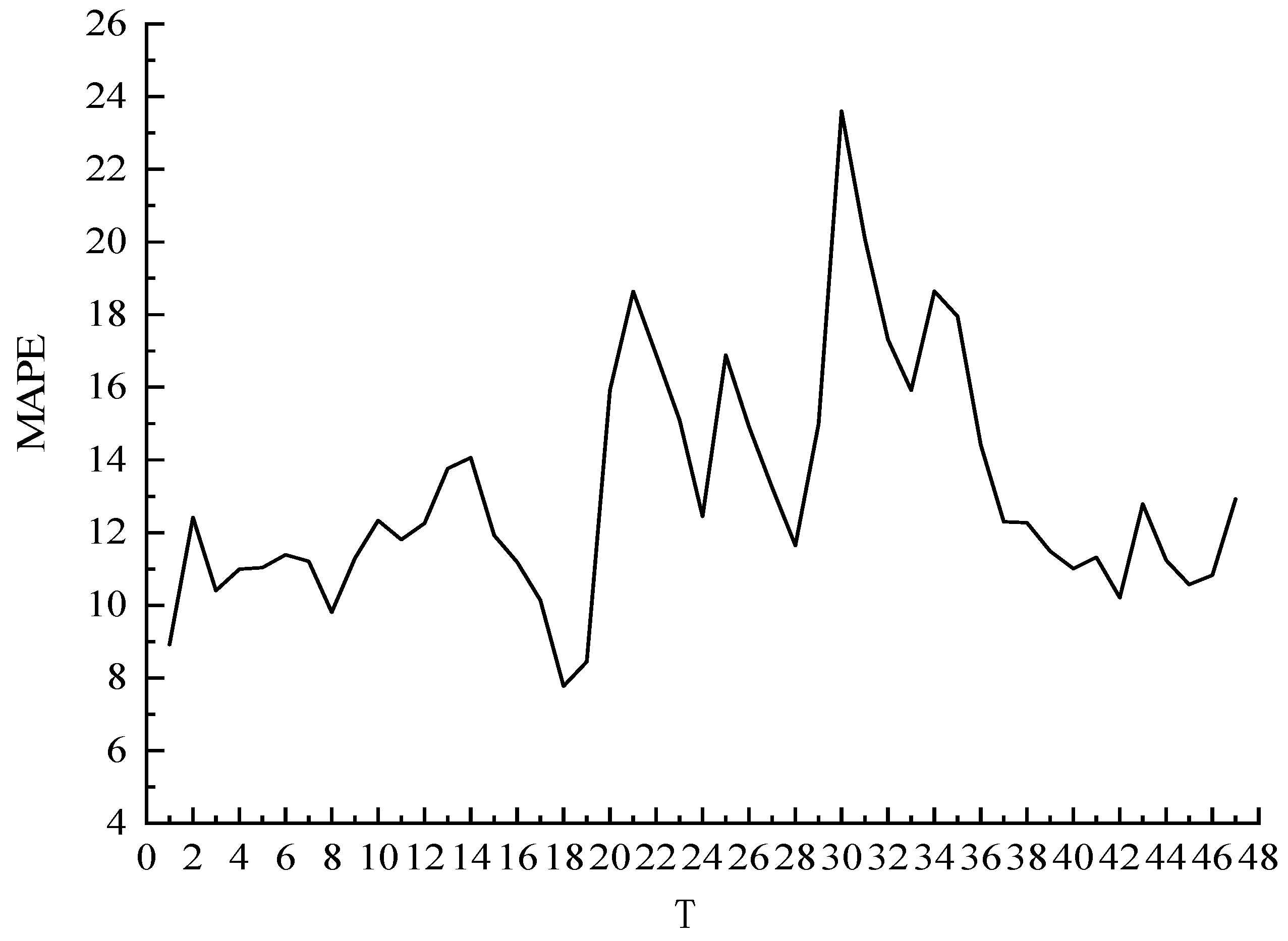{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}