



Automatic Recognition of Road Damage Based on Lightweight Attentional Convolutional Neural Network




Abstract
:1. Introduction
- Most pavement damage detection efforts obtain crack results by semantic segmentation of pixel-level images, which requires input images that must be high-quality images that closely match the pavement, undoubtedly increasing the cost and reducing the efficiency during initial image acquisition and making it difficult to meet the real-time warning required by ADAS.
- Although the state-of-the-artwork allows pixel-level segmentation of pavement cracks or potholes, no other pavement damage classification was considered. We believe that identifying specific pavement damage types, such as longitudinal or transverse cracks, alligator cracks, and potholes, is essential when performing road damage detection.
- Most related work cannot be automated end-to-end or lightweight model network construction due to the need for multi-stage operations, such as image pre-processing or post-processing.
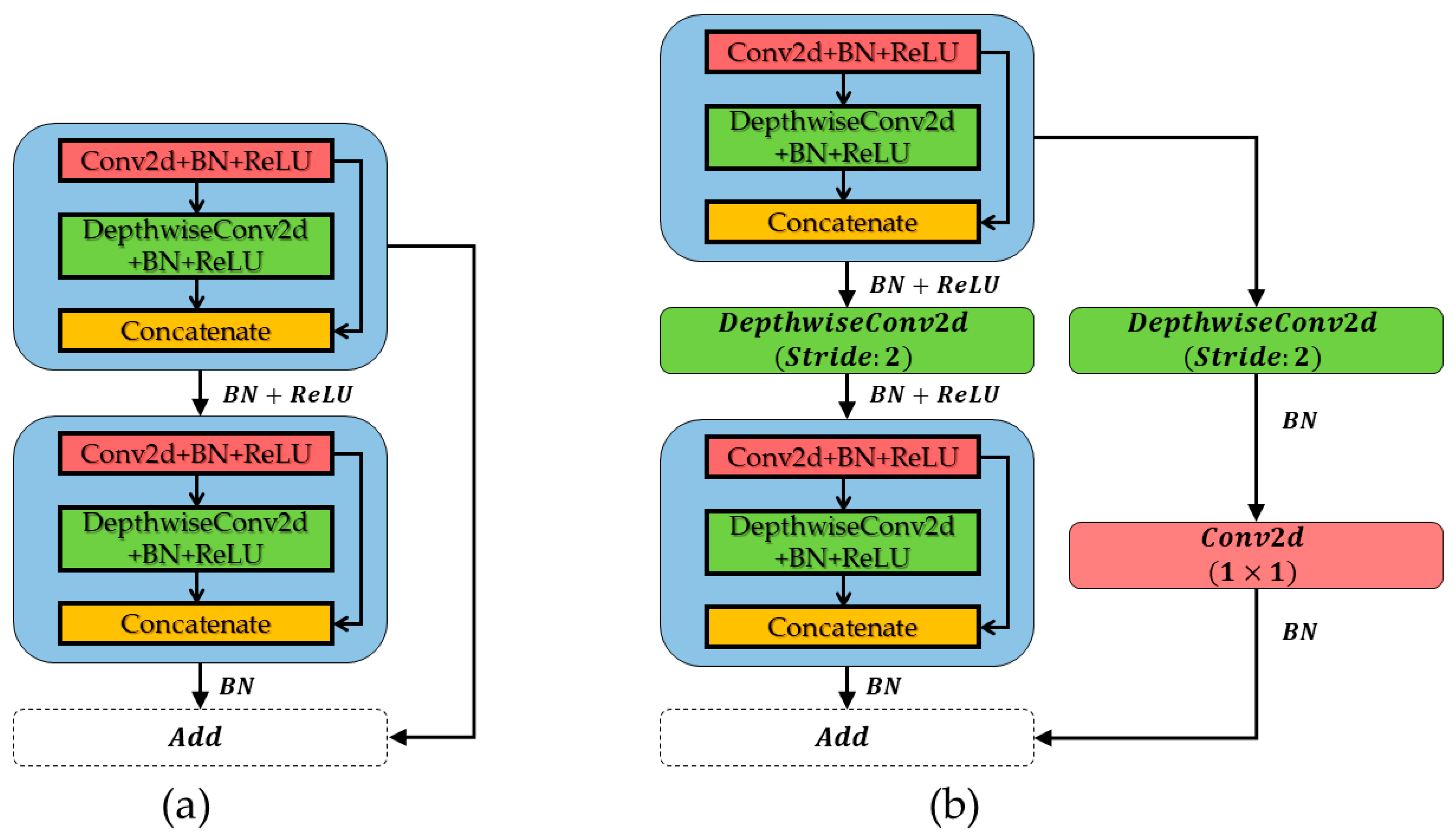
- We designed a backbone feature extraction network using a combination of lightweight feature detection modules to ensure efficient automatic feature extraction while making the model parameters smaller.
- Our proposed multi-scale fusion network enriches the diversity of road damage features, improves the detection robustness of the algorithm at different scales, and facilitates detection efficiency when the distance and viewpoint change.
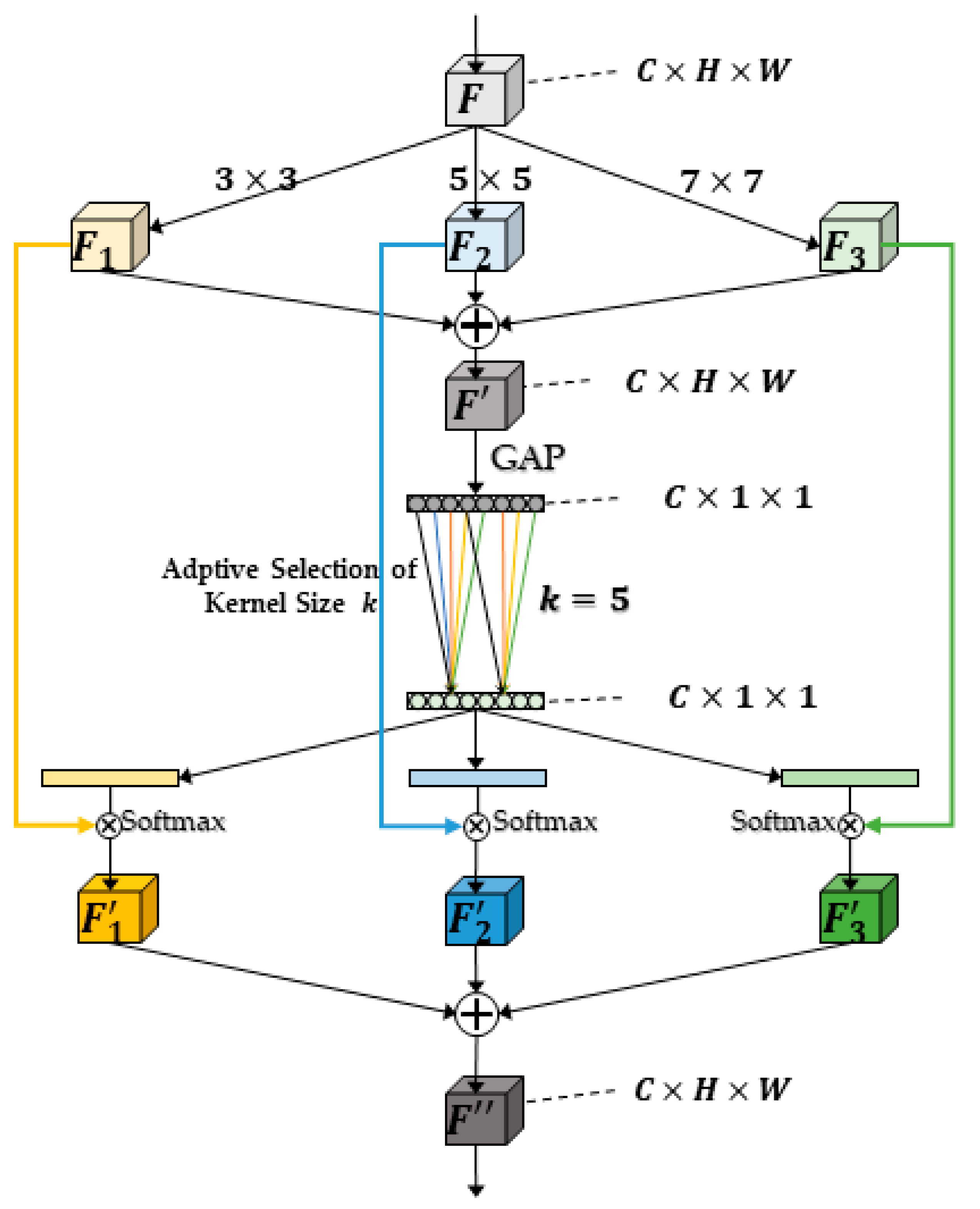
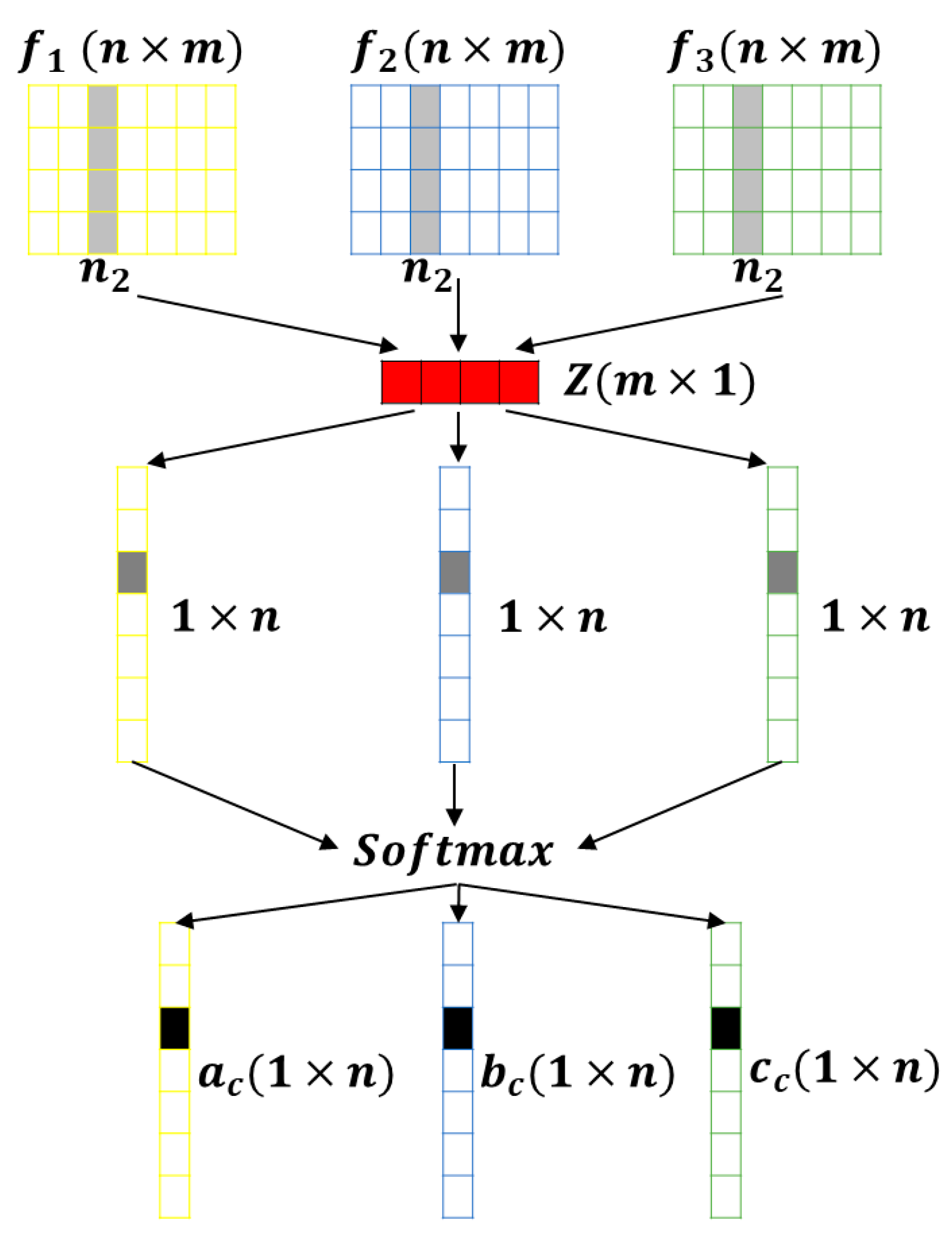
- We propose a lightweight multi-branch channel attention network (LMCA-Net) for the road damage detection task. This embedded attention module can enhance feature information by assigning weights to multi-scale convolutional kernels depending on the object size, aiming to improve detection accuracy with smaller parameters.
2. Related Work
2.1. Road Damage Detection Methods Based on Traditional Image Processing
2.2. Deep Learning-Based Road Damage Detection Methods
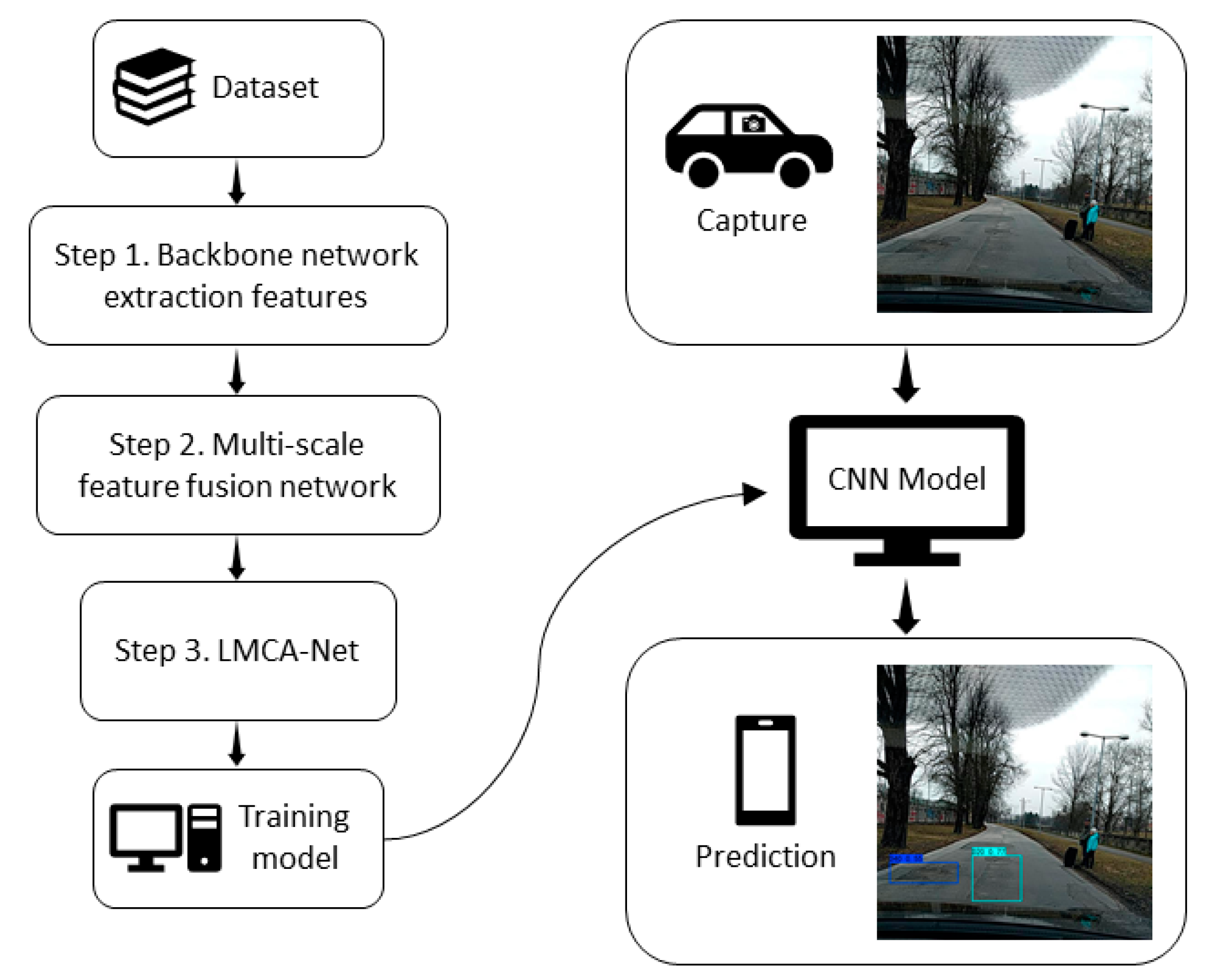
3. Methodologies
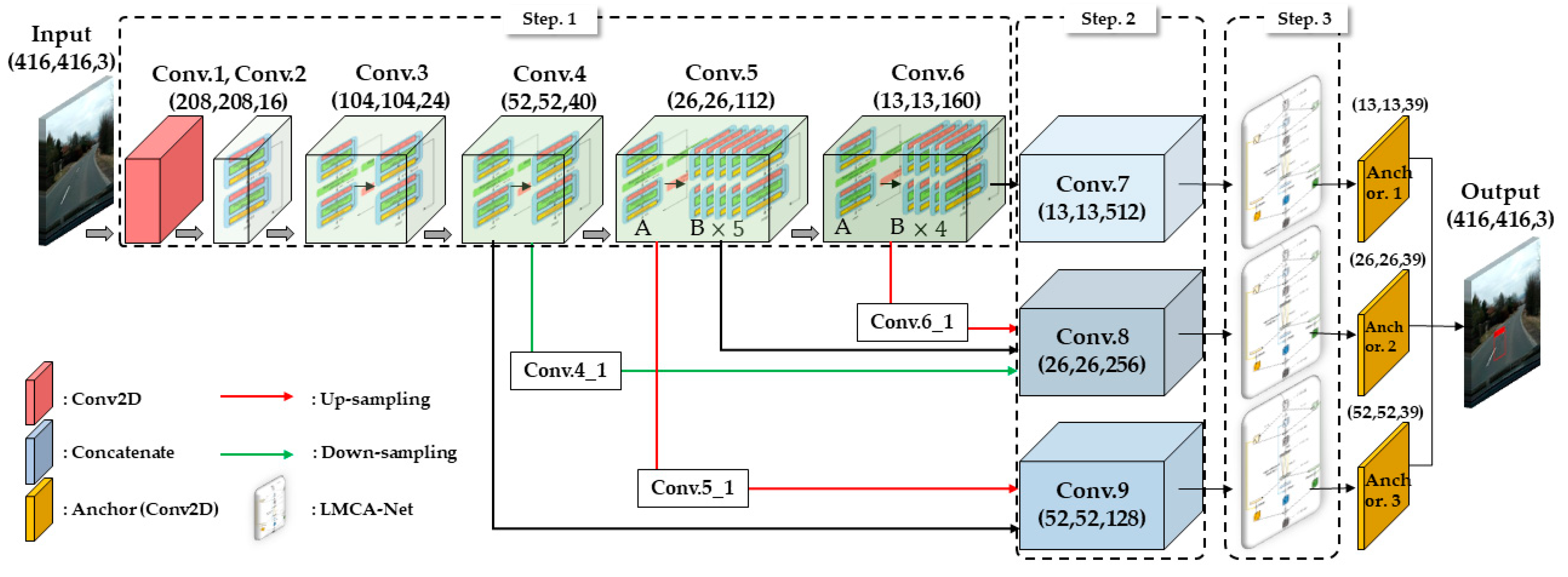
3.1. Selection and Design of Backbone Network (Step 1)
3.2. Multi-Scale Feature Fusion Network (Step 2)
3.3. Lightweight Multibranch Channel Attention Network (Step 3)
4. Experiments and Discussion
4.1. Dataset and Experimental Environment
4.2. Evaluation Metrics and Experimental Details
4.3. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kamal, I.; Bas, Y. Materials and technologies in road pavements-an overview. Mater. Today Proc. 2021, 42, 2660–2667. [Google Scholar] [CrossRef]
- Llopis-Castelló, D.; García-Segura, T.; Montalbán-Domingo, L.; Sanz-Benlloch, A.; Pellicer, E. Influence of pavement structure, traffic, and weather on urban flexible pavement deterioration. Sustainability 2020, 12, 9717. [Google Scholar] [CrossRef]
- Khan, M.H.; Babar, T.S.; AHMED, I.; Babar, K.S.; ZIA, N. Road traffic accidents: Study of risk factors. Prof. Med. J. 2007, 14, 323–327. [Google Scholar] [CrossRef]
- Tsubota, T.; Fernando, C.; Yoshii, T.; Shirayanagi, H. Effect of road pavement types and ages on traffic accident risks. Transp. Res. Procedia 2018, 34, 211–218. [Google Scholar] [CrossRef]
- Yang, C.H.; Kim, J.G.; Shin, S.P. Road hazard assessment using pothole and traffic data in South Korea. J. Adv. Transp. 2021, 2021, 5901203. [Google Scholar] [CrossRef]
- Do, M.; Jung, H. Enhancing road network resilience by considering the performance loss and asset value. Sustainability 2018, 10, 4188. [Google Scholar] [CrossRef] [Green Version]
- Veres, M.; Moussa, M. Deep learning for intelligent transportation systems: A survey of emerging trends. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3152–3168. [Google Scholar] [CrossRef]
- Liang, H.; Seo, S. Lightweight Deep Learning for Road Environment Recognition. Appl. Sci. 2022, 12, 3168. [Google Scholar] [CrossRef]
- Tighe, S.; Li, N.; Falls, L.C.; Haas, R. Incorporating road safety into pavement management. Transp. Res. Rec. 2000, 1699, 5901203. [Google Scholar] [CrossRef]
- Laurent, J.; Hébert, J.F.; Lefebvre, D.; Savard, Y. Using 3D laser profiling sensors for the automated measurement of road surface conditions. In 7th RILEM International Conference on Cracking in Pavements; Springer: Dordrecht, The Netherlands, 2012. [Google Scholar]
- Zhang, D.; Zou, Q.; Lin, H.; Xu, X.; He, L.; Gui, R.; Li, Q. Automatic pavement defect detection using 3D laser profiling technology. Autom. Constr. 2018, 96, 350–365. [Google Scholar] [CrossRef]
- Woźniak, M.; Zielonka, A.; Sikora, A. Driving support by type-2 fuzzy logic control model. Expert Syst. Appl. 2022, 207, 117798. [Google Scholar] [CrossRef]
- Vavrik, W.; Evans, L.; Sargand, S.; Stefanski, J. PCR Evaluation: Considering Transition from Manual to Semi-Automated Pavement Distress Collection and Analysis; Ohio Department of Transportation: Colombus, OH, USA, July 2013.
- Woo, S.; Yeo, H. Optimization of pavement inspection schedule with traffic demand prediction. Procedia-Soc. Behav. Sci. 2016, 218, 95–103. [Google Scholar] [CrossRef] [Green Version]
- Cao, W.; Liu, Q.; He, Z. Review of pavement defect detection methods. IEEE Access 2020, 8, 14531–14544. [Google Scholar] [CrossRef]
- Fan, R.; Bocus, M.J.; Zhu, Y.; Jiao, J.; Wang, L.; Ma, F.; Cheng, S.; Liu, M. Road crack detection using deep convolutional neural network and adaptive thresholding. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019. [Google Scholar]
- Feng, X.; Xiao, L.; Li, W.; Pei, L.; Sun, Z.; Ma, Z.; Shen, H.; Ju, H. Pavement crack detection and segmentation method based on improved deep learning fusion model. Math. Probl. Eng. 2020, 2020, 8515213. [Google Scholar] [CrossRef]
- Nguyen, N.H.T.; Perry, S.; Bone, D.; Le, H.T.; Nguyen, T.T. Two-stage convolutional neural network for road crack detection and segmentation. Expert Syst. Appl. 2021, 186, 115718. [Google Scholar] [CrossRef]
- Cheng, J.; Xiong, W.; Chen, W.; Gu, Y.; Li, Y. Pixel-level crack detection using U-net. In Proceedings of the TENCON 2018-2018 IEEE Region 10 Conference, Jeju, Republic of Korea, 28–31 October 2018. [Google Scholar]
- Rill-García, R.; Dokladalova, E.; Dokládal, P. Pixel-accurate road crack detection in presence of inaccurate annotations. Neurocomputing 2022, 480, 1–13. [Google Scholar] [CrossRef]
- Koch, C.; Brilakis, I. Pothole detection in asphalt pavement images. Adv. Eng. Inform. 2011, 25, 507–515. [Google Scholar] [CrossRef]
- Schiopu, I.; Saarinen, J.P.; Kettunen, L.; Tabus, I. Pothole detection and tracking in car video sequence. In Proceedings of the 2016 39th International Conference on Telecommunications and Signal Processing (TSP), Vienna, Austria, 27–29 June 2016. [Google Scholar]
- Jakštys, V.; Marcinkevičius, V.; Treigys, P.; Tichonov, J. Detection of the road pothole contour in raster images. Inf. Technol. Control 2016, 45, 300–307. [Google Scholar] [CrossRef] [Green Version]
- Akagic, A.; Buza, E.; Omanovic, S. Pothole detection: An efficient vision based method using rgb color space image segmentation. In Proceedings of the 2017 40th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 22–26 May 2017. [Google Scholar]
- Akagic, A.; Buza, E.; Omanovic, S.; Karabegovic, A. Pavement crack detection using Otsu thresholding for image segmentation. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018. [Google Scholar]
- Sari, Y.; Prakoso, P.B.; Baskara, A.R. Road crack detection using support vector machine (SVM) and OTSU algorithm. In Proceedings of the 2019 6th International Conference on Electric Vehicular Technology (ICEVT), Bali, Indonesia, 18–21 November 2019. [Google Scholar]
- Quan, Y.; Sun, J.; Zhang, Y.; Zhang, H. The method of the road surface crack detection by the improved Otsu threshold. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019. [Google Scholar]
- Chung, T.D.; Khan, M.K.A.A. Watershed-based real-time image processing for multi-potholes detection on asphalt road. In Proceedings of the 2019 IEEE 9th International Conference on System Engineering and Technology (ICSET), Shah Alam, Malaysia, 7 October 2019. [Google Scholar]
- Hoang, N.-D. An artificial intelligence method for asphalt pavement pothole detection using least squares support vector machine and neural network with steerable filter-based feature extraction. Adv. Civ. Eng. 2018, 2018, 7419058. [Google Scholar] [CrossRef] [Green Version]
- Gao, M.; Wang, X.; Zhu, S.; Guan, P. Detection and segmentation of cement concrete pavement pothole based on image processing technology. Math. Probl. Eng. 2020, 2020, 1360832. [Google Scholar] [CrossRef]
- An, K.E.; Lee, S.W.; Ryu, S.-K.; Seo, D. Detecting a pothole using deep convolutional neural network models for an adaptive shock observing in a vehicle driving. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 12–14 January 2018. [Google Scholar]
- Aparna; Bhatia, Y.; Rai, R.; Gupta, V.; Aggarwal, N.; Akula, A. Convolutional neural networks based potholes detection using thermal imaging. J. King Saud Univ.-Comput. Inf. Sci. 2019, 34, 578–588. [Google Scholar] [CrossRef]
- Fan, J.; Bocus, M.J.; Wang, L.; Fan, R. Deep convolutional neural networks for road crack detection: Qualitative and quantitative comparisons. In Proceedings of the 2021 IEEE International Conference on Imaging Systems and Techniques (IST), Kaohsiung, Taiwan, 24–26 August 2021. [Google Scholar]
- Pereira, V.; Tamura, S.; Hayamizu, S.; Fukai, H. Semantic segmentation of paved road and pothole image using u-net architecture. In Proceedings of the 2019 International Conference of Advanced Informatics: Concepts, Theory and Applications (ICAICTA), Yogyakarta, Indonesia, 20–21 September 2019. [Google Scholar]
- Fan, J.; Bocus, M.J.; Hosking, B.; Wu, R.; Liu, Y.; Vityazev, S.; Fan, R. Multi-scale feature fusion: Learning better semantic segmentation for road pothole detection. In Proceedings of the 2021 IEEE International Conference on Autonomous Systems (ICAS), Montreal, QC, Canada, 11–13 August 2021. [Google Scholar]
- Zhang, Y.; Deng, W. Deep Learning Pavement Crack Detection based on Atrous Convolution and Deep Supervision. In Proceedings of the 2022 14th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), Changsha, China, 15–16 January 2022. [Google Scholar]
- Fang, J.; Yang, C.; Shi, Y.; Wang, N.; Zhao, Y. External Attention Based TransUNet and Label Expansion Strategy for Crack Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19054–19063. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wang, W.; Wu, B.; Yang, S.; Wang, Z. Road damage detection and classification with faster R-CNN. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018. [Google Scholar]
- Yebes, J.J.; Montero, D.; Arriola, I. Learning to automatically catch potholes in worldwide road scene images. IEEE Intell. Transp. Syst. Mag. 2020, 13, 192–205. [Google Scholar] [CrossRef]
- Ukhwah, E.N.; Yuniarno, E.M.; Suprapto, Y.K. Asphalt pavement pothole detection using deep learning method based on YOLO neural network. In Proceedings of the 2019 International Seminar on Intelligent Technology and Its Applications (ISITIA), Surabaya, Indonesia, 28–29 August 2019. [Google Scholar]
- Dharneeshkar, J.; Aniruthan, S.A.; Karthika, R.; Parameswaran, L. Deep Learning based Detection of potholes in Indian roads using YOLO. In Proceedings of the 2020 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–28 February 2020. [Google Scholar]
- Gupta, S.; Sharma, P.; Sharma, D.; Gupta, V.; Sambyal, N. Detection and localization of potholes in thermal images using deep neural networks. Multimed. Tools Appl. 2020, 79, 26265–26284. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 13–19 June 2020. [Google Scholar]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Mraz, A.; Kashiyama, T.; Sekimoto, Y. Transfer learning-based road damage detection for multiple countries. arXiv 2020, arXiv:2008.13101. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on COMPUTER Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. Supplementary material for ‘ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Objective | Key Algorithm(s) | Reference |
|---|---|---|
| Pothole Detection | Histogram thresholds + Elliptical regression | Koch and Brilakis [21] |
| Geometric features + Decision tree labelling | Schiopu et al. [22] | |
| RGB colour space | Jakštys et al. [23] | |
| Otsu + Boundary elimination | Akagic et al. [24] | |
| Inverse Binary + Otsu + Watershed | Chung et al. [28] | |
| LS-SVM | Hoang [29] | |
| Crack Detection | Grayscale histograms + Otsu | Akagic et al. [25] |
| Otsu + GLCM + SVM | Sari et al. [26] | |
| Modified Otsu | Quan et al. [27] | |
| LIBSVM | Gao et al. [30] |
| Method | Objective | Key Algorithm(s) | Reference |
|---|---|---|---|
| Image Classification | Pothole | CNN | An et al. [31] |
| Pothole | ResNet | Bhatia et al. [32] | |
| Crack | PNASNet | Fan et al. [33] | |
| Semantic Segmentation | Pothole | U-Net | Pereira et al. [34] |
| Pothole | SPP + Channel attention | Fan et al. [35] | |
| Crack | AD-Net | Zhang et al. [36] | |
| Crack | Transformer Block + AD-Net | Fang et al. [37] | |
| Object Detection | Crack | ResNet-152 + Faster-RCNN | Wang et al. [44] |
| Crack | Resnet101 + Faster-RCNN | Yebes et al. [45] | |
| Pothole | YOLOv3 | Ukhwah et al. [46] | |
| Pothole | YOLOv3 | Dharneeshkar et al. [47] | |
| Pothole | SSD + RetinaNet | Gupta et al. [48] |
| Blocks | Layer | Output Shape | Parameters | Total Parameters |
|---|---|---|---|---|
| Image | Input | 416 × 416 × 3 | 0 | 2,408,184 |
| Conv.1 | Conv2d + BN + Leaky | 208 × 208 × 16 | 496 | |
| Conv.2 | Bottleneck A × 1, | 208 × 208 × 16 | 528 | |
| Conv.3 | Bottleneck A × 1, Bottleneck B × 1 | 104 × 104 × 24 | 2884 | |
| Conv.4 | Bottleneck A × 1, Bottleneck B × 1 | 52 × 52 × 40 | 12,496 | |
| Conv.5 | Bottleneck A × 1, Bottleneck B × 5 | 26 × 26 × 112 | 448,908 | |
| Conv.6 | Bottleneck A × 1, Bottleneck B × 4 | 13 × 13 × 160 | 1,942,872 |
| Blocks | Layer | Output Shape | Parameters | Total Parameters |
|---|---|---|---|---|
| Conv.6 | Input | 13 × 13 × 160 | 0 | 1,516,928 |
| Conv.7 | Conv2d + BN + Leaky, Depthwise_Conv2d + BN + Leaky, Conv2d + BN + Leaky, Conv2d + BN + Leaky | 13 × 13 × 512, 13 × 13 × 512, 13 × 13 × 1024, 13 × 13 × 512 | 1,145,344 | |
| Conv.6_1 | Conv2d + BN + Leaky, Up_Sampling2D | 26 × 26 × 256 | 132,096 | |
| Conv.5 | Input, Conv2d + BN + Leaky | 26 × 26 × 112, 26 × 26 × 256 | 29,696 | |
| Conv.4 | Input | 52 × 52 × 40 | 0 | |
| Conv.4_1 | Conv2d + BN + Leaky, Down_Sampling2D | 26 × 26 × 256 | 135,424 | |
| Conv.8 | Concatenate (Conv.6_1, Conv.5, Conv.4_1) | 26 × 26 × 256 | 0 | |
| Conv.5_1 | Conv2d + BN + Leaky, Up_Sampling2D | 52 × 52 × 128 | 68,736 | |
| Conv.4 | Conv2d + BN + Leaky | 52 × 52 × 128 | 5632 | |
| Conv.9 | Concatenate (Conv.5_1, Conv.4) | 52 × 52 × 128 | 0 |
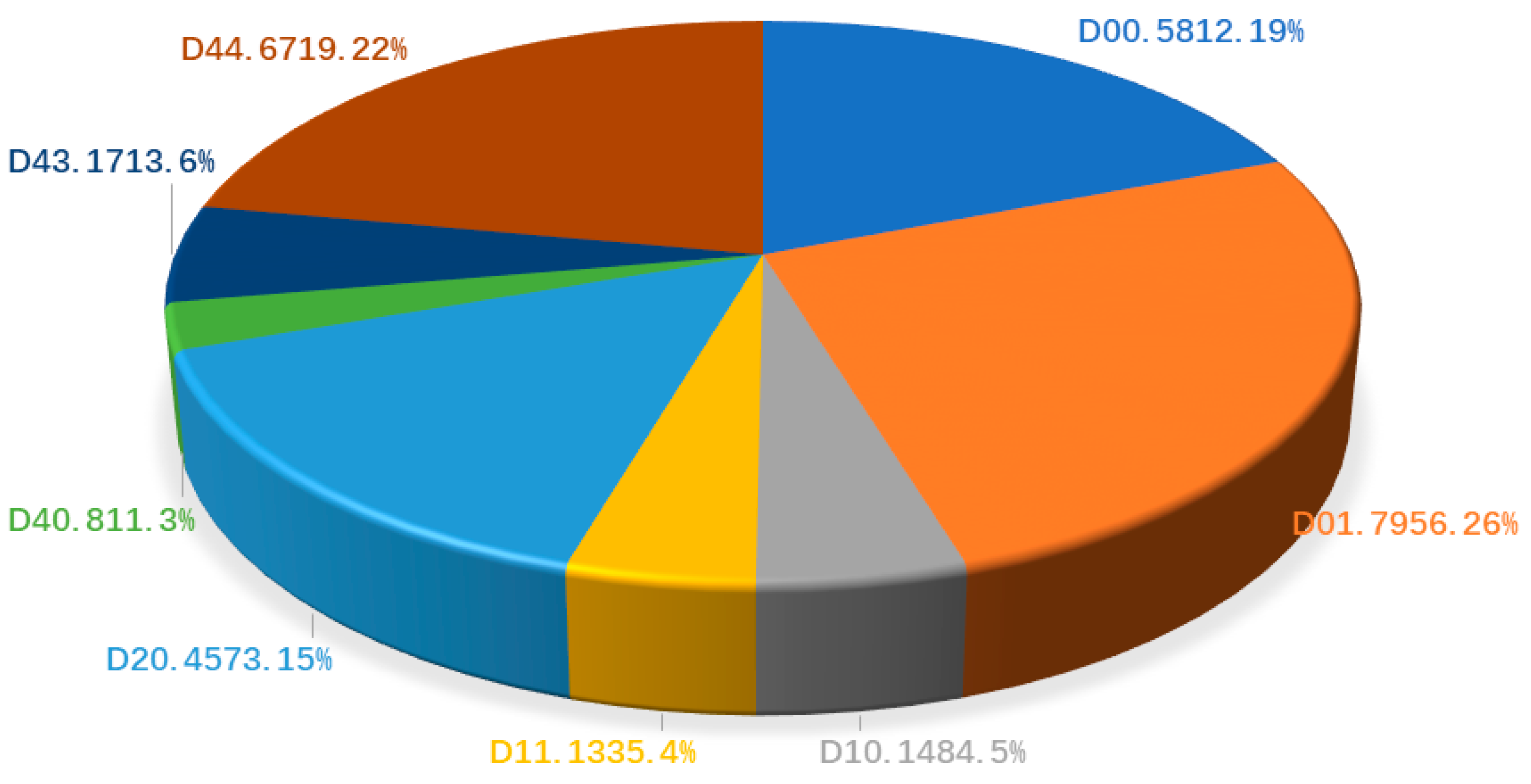
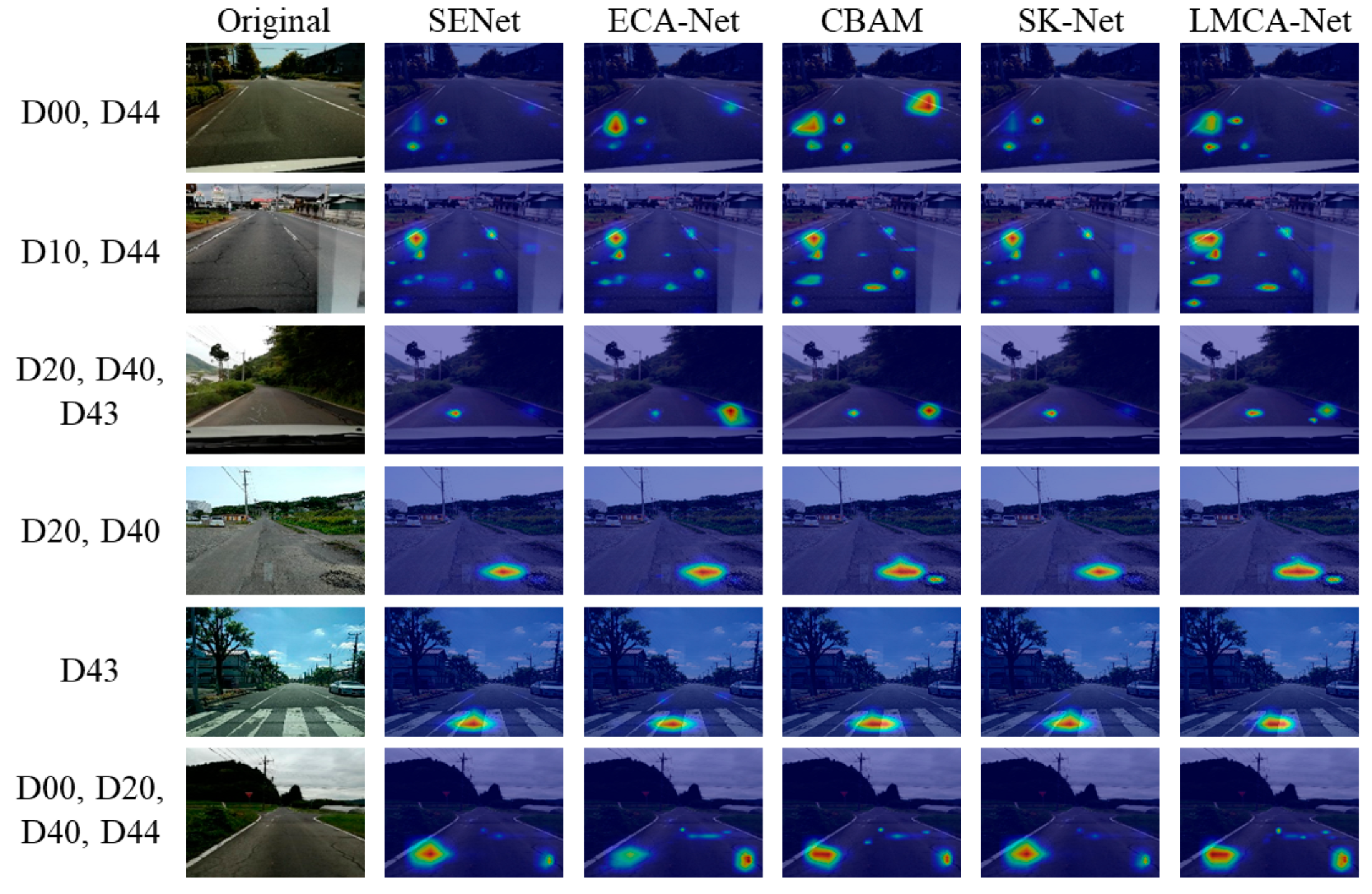
| Class Name | Damage Detail | Damage Type | |
|---|---|---|---|
| D00 | Tire indentation | Longitudinal linear crack | Linear crack |
| D01 | Construction joint | ||
| D10 | Equal interval | Transverse linear crack | |
| D11 | Construction joint | ||
| D20 | Partial or overall pavement | Alligator crack | |
| D40 | Rutting, bump, pothole, separation | Other corruption | |
| D43 | Crosswalk blur | ||
| D44 | lane line blur | ||
| Items | Description | |
|---|---|---|
| H/W | CPU | Intel(R) Core (TM) i5-11400F |
| RAM | 16 GB | |
| SSD | Samsung SSD 500GB | |
| Graphics Card | NVIDIA GeForce RTX 3050 | |
| S/W | Operating System | Windows 11 Pro, 64bit |
| Programming Language | Python 3.7 | |
| Learning Framework | TensorFlow 2.2.0 | |
| Input Settings | Loss Calculation | Data Enhancement | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Input shape | Batch size | Total Epoch | Loss function | Anchor-based | Max_lr | Min_lr | Decay type | Mosaic | Mixup |
| 416 × 416 | 16 | 500 | CIoU | True | 0.01 | 0.0001 | Cosine Annealing | True | True |
| Anchor Layer | Anchor Size (Width, Height) |
|---|---|
| Anchor. 1 | (29, 11); (23, 43); (42, 27) |
| Anchor. 2 | (72, 16); (55, 61); (128, 31) |
| Anchor. 3 | (106, 88); (155, 156); (322, 121) |
| MobileNetv1 | MobileNetv2 | MobileNetv3 | VGG16 | ResNet50 | DenseNet121 | Our Approach | ||
|---|---|---|---|---|---|---|---|---|
| Precision | D00 | 0.66 | 0.76 | 0.70 | 0.69 | 0.67 | 0.64 | 0.76 |
| D01 | 0.98 | 0.99 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 | |
| D10 | 0.70 | 0.83 | 0.65 | 1.00 | 0.63 | 0.72 | 0.80 | |
| D11 | 0.99 | 0.99 | 1.00 | 0.00 | 1.00 | 1.00 | 1.00 | |
| D20 | 0.75 | 0.82 | 0.80 | 0.82 | 0.76 | 0.74 | 0.79 | |
| D40 | 0.73 | 0.79 | 0.70 | 0.71 | 0.74 | 0.80 | 0.89 | |
| D43 | 0.89 | 0.92 | 0.93 | 0.80 | 0.93 | 0.96 | 0.96 | |
| D44 | 0.73 | 0.75 | 0.75 | 0.82 | 0.72 | 0.75 | 0.75 | |
| Recall | D00 | 0.19 | 0.14 | 0.17 | 0.06 | 0.22 | 0.22 | 0.15 |
| D01 | 0.04 | 0.04 | 0.00 | 0.04 | 0.00 | 0.00 | 0.04 | |
| D10 | 0.08 | 0.05 | 0.06 | 0.01 | 0.20 | 0.14 | 0.05 | |
| D11 | 0.33 | 0.33 | 0.33 | 0.00 | 0.33 | 0.33 | 0.33 | |
| D20 | 0.51 | 0.49 | 0.50 | 0.34 | 0.53 | 0.56 | 0.47 | |
| D40 | 0.27 | 0.20 | 0.19 | 0.18 | 0.31 | 0.32 | 0.37 | |
| D43 | 0.71 | 0.68 | 0.69 | 0.55 | 0.72 | 0.69 | 0.81 | |
| D44 | 0.51 | 0.48 | 0.45 | 0.25 | 0.57 | 0.53 | 0.49 | |
| F1 | D00 | 0.30 | 0.24 | 0.28 | 0.12 | 0.33 | 0.33 | 0.25 |
| D01 | 0.08 | 0.08 | 0.00 | 0.08 | 0.00 | 0.00 | 0.08 | |
| D10 | 0.15 | 0.10 | 0.12 | 0.01 | 0.31 | 0.24 | 0.10 | |
| D11 | 0.50 | 0.50 | 0.50 | 0.00 | 0.50 | 0.50 | 0.50 | |
| D20 | 0.61 | 0.61 | 0.61 | 0.48 | 0.63 | 0.64 | 0.59 | |
| D40 | 0.39 | 0.32 | 0.30 | 0.29 | 0.44 | 0.46 | 0.32 | |
| D43 | 0.79 | 0.78 | 0.80 | 0.65 | 0.81 | 0.80 | 0.85 | |
| D44 | 0.60 | 0.58 | 0.56 | 0.39 | 0.64 | 0.62 | 0.59 | |
| AP | D00 | 0.34 | 0.36 | 0.36 | 0.27 | 0.36 | 0.37 | 0.35 |
| D01 | 0.50 | 0.32 | 0.36 | 0.16 | 0.45 | 0.31 | 0.51 | |
| D10 | 0.30 | 0.35 | 0.30 | 0.19 | 0.34 | 0.37 | 0.31 | |
| D11 | 0.83 | 0.67 | 0.92 | 0.00 | 0.92 | 0.81 | 0.63 | |
| D20 | 0.60 | 0.64 | 0.61 | 0.53 | 0.62 | 0.62 | 0.61 | |
| D40 | 0.44 | 0.42 | 0.39 | 0.33 | 0.49 | 0.50 | 0.40 | |
| D43 | 0.81 | 0.80 | 0.78 | 0.69 | 0.81 | 0.82 | 0.91 | |
| D44 | 0.65 | 0.65 | 0.63 | 0.56 | 0.66 | 0.66 | 0.73 | |
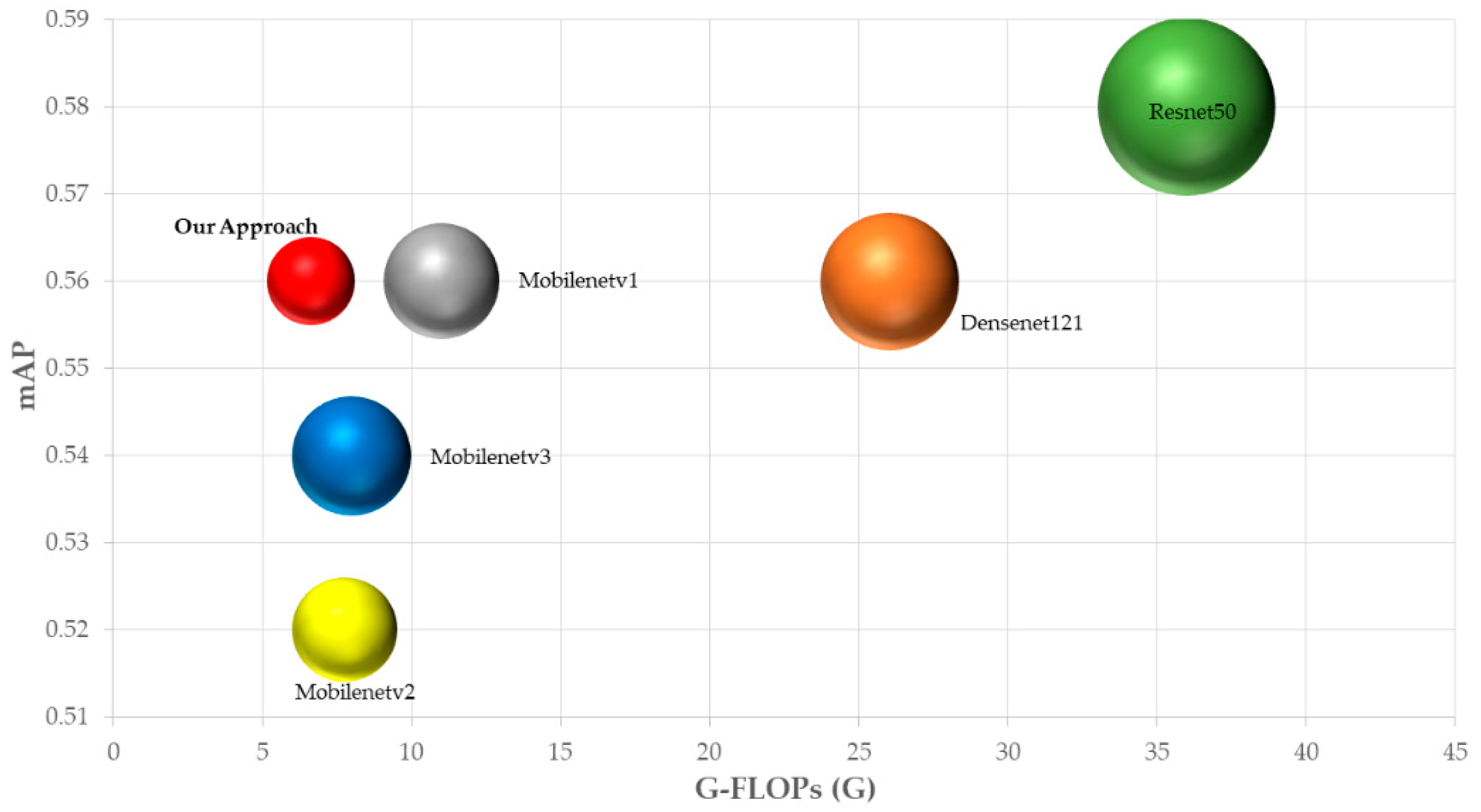
| mAP | 0.56 | 0.52 | 0.54 | 0.34 | 0.58 | 0.56 | 0.57 | |
| G-FLOPs (G) | 10.129 | 7.763 | 7.178 | 111.845 | 35.105 | 26.050 | 6.633 | |
| Parameters (Millions) | 12.304 | 11.413 | 13.341 | 23.550 | 33.293 | 18.051 | 11.041 | |
| Backbone Feature Extraction | Baseline | √ | √ | √ | √ | √ | √ |
| Multi-scale feature fusion | √ | √ | √ | √ | √ | √ | |
| SE-Net | √ | ||||||
| CBAM | √ | ||||||
| ECA-Net | √ | ||||||
| SK-Net | √ | ||||||
| LMCA-Net (Ours) | √ | ||||||
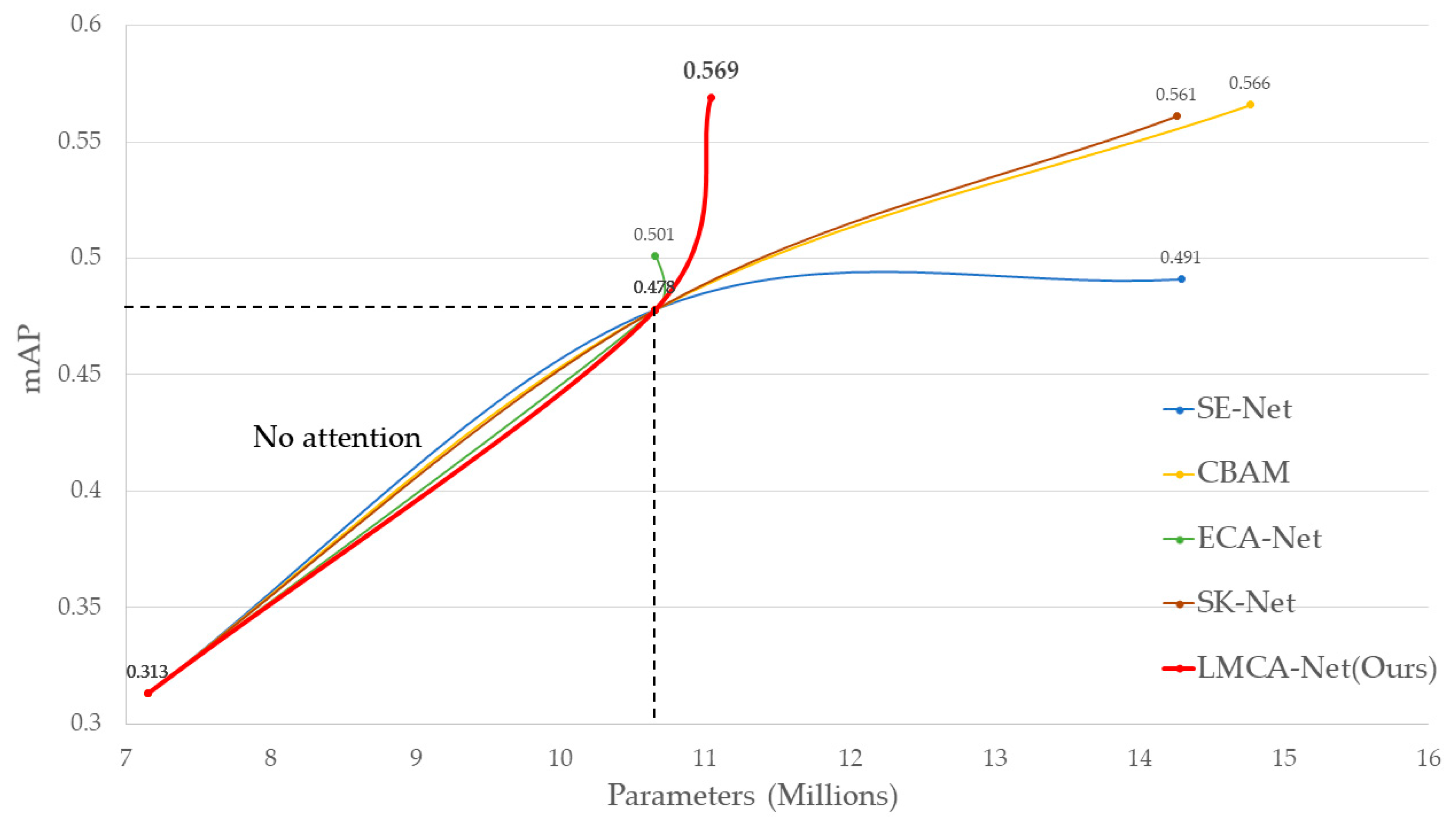
| Parameters (Millions) | 7.149 | 10.657 | 14.290 | 14.771 | 10.657 | 14.258 | 11.041 |
| mAP | 0.313 | 0.478 | 0.491 | 0.566 | 0.501 | 0.561 | 0.569 |
| The “√” in each column indicates that the leftmost component is used in the model. | |||||||
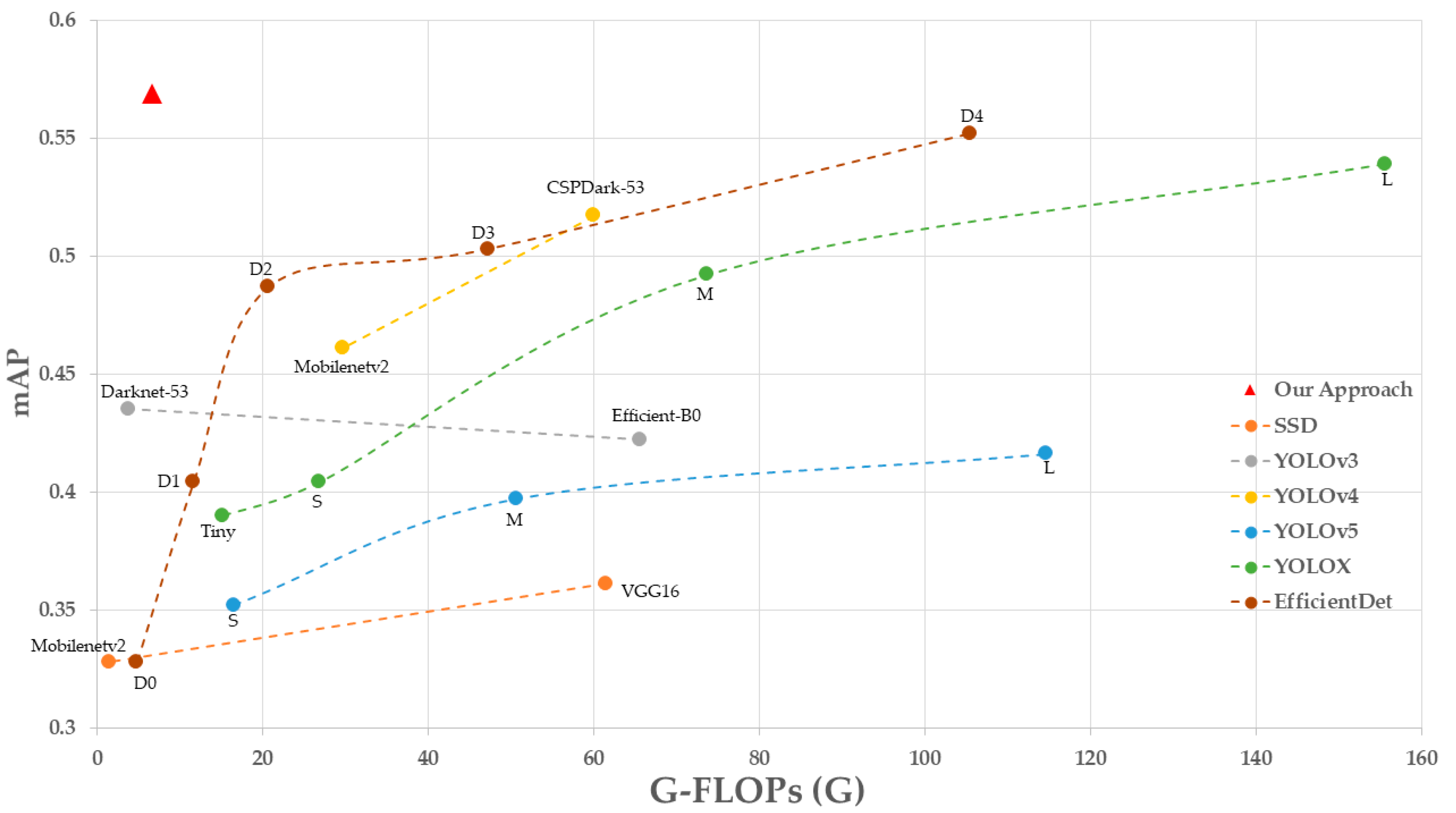
| Method | Input Size | Backbone | Parameters (Millions) | FPS | G-FLOPs (G) | mAP (%) | |
|---|---|---|---|---|---|---|---|
| SSD | 300 × 300 | VGG16 | 24.54 | 29 | 61.45 | 0.361 | |
| 300 × 300 | Mobilenetv2 | 4.47 | 35 | 1.53 | 0.328 | ||
| YOLOv3 | 416 × 416 | Darknet-53 | 61.56 | 27 | 65.65 | 0.422 | |
| 416 × 416 | Efficient-B0 | 7.02 | 21 | 3.84 | 0.435 | ||
| YOLOv4 | 416 × 416 | CSPDark-53 | 63.98 | 19 | 60.01 | 0.517 | |
| 416 × 416 | Mobilenetv2 | 39.06 | 28 | 29.74 | 0.461 | ||
| YOLOv5 | S | 640 × 640 | CSPDarknet53 + SPP | 7.08 | 36 | 16.54 | 0.352 |
| M | 640 × 640 | CSPDarknet53 + SPP | 21.09 | 23 | 50.69 | 0.397 | |
| L | 640 × 640 | CSPDarknet53 + SPP | 46.67 | 15 | 114.68 | 0.416 | |
| YOLOX | Tiny | 640 × 640 | Modified CSP | 5.03 | 31 | 15.24 | 0.390 |
| S | 640 × 640 | Modified CSP | 8.94 | 31 | 26.77 | 0.404 | |
| M | 640 × 640 | Modified CSP | 25.29 | 20 | 73.75 | 0.492 | |
| L | 640 × 640 | Modified CSP | 54.15 | 14 | 155.70 | 0.539 | |
| Faster-RCNN | 600 × 600 | VGG16 | 136.83 | 8 | 369.89 | 0.475 | |
| 600 × 600 | ResNet50 | 28.35 | 7 | 941.01 | 0.499 | ||
| EfficientDet | D0 | 512 × 512 | Efficient-B0 | 3.83 | 13 | 4.78 | 0.328 |
| D1 | 640 × 640 | Efficient-B1 | 6.56 | 10 | 11.59 | 0.404 | |
| D2 | 768 × 768 | Efficient-B2 | 8.01 | 9 | 20.71 | 0.487 | |
| D3 | 896 × 896 | Efficient-B3 | 11.91 | 7 | 47.23 | 0.503 | |
| D4 | 1024 × 1024 | Efficient-B4 | 20.56 | 4 | 105.55 | 0.552 | |
| Our Approach | 416 × 416 | Ghost module | 11.04 | 31 | 6.63 | 0.569 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, H.; Lee, S.-C.; Seo, S. Automatic Recognition of Road Damage Based on Lightweight Attentional Convolutional Neural Network. Sensors 2022, 22, 9599. https://doi.org/10.3390/s22249599
Liang H, Lee S-C, Seo S. Automatic Recognition of Road Damage Based on Lightweight Attentional Convolutional Neural Network. Sensors. 2022; 22(24):9599. https://doi.org/10.3390/s22249599
Chicago/Turabian StyleLiang, Han, Seong-Cheol Lee, and Suyoung Seo. 2022. "Automatic Recognition of Road Damage Based on Lightweight Attentional Convolutional Neural Network" Sensors 22, no. 24: 9599. https://doi.org/10.3390/s22249599
APA StyleLiang, H., Lee, S.-C., & Seo, S. (2022). Automatic Recognition of Road Damage Based on Lightweight Attentional Convolutional Neural Network. Sensors, 22(24), 9599. https://doi.org/10.3390/s22249599