1. Introduction
A Digital Twin (DT) is the virtual representation of a living entity (e.g., human beings, animals, plants, etc.) or nonliving entity (e.g., business model, product, process, system, event, machine, building, etc.) that allows real-time interaction and communication between both the real twin and the digital twin to help with the modelling, monitoring, understanding, and optimization of the functions and behaviour of the real twin [
1].
The development of high-fidelity virtual models (i.e., digital twins) is a critical step so that the behaviours and characteristics of the real twin can be simulated. DT can be developed using data-driven approaches, mathematical modelling approaches, or hybrid approaches (data and mathematical modelling).
DT technology, which we consider one of the primary technologies required to build and advance the metaverse, has already been used extensively in the manufacturing industry, but it is still in its infancy in the domain of human health and well-being [
2,
3].
For example, in the industrial manufacturing context, a state-of-the-art open-source framework and software tools for designing DTs (the IoTwins platform) have been proposed to enable users to develop, configure, and run DTs using distributed DT infrastructures based on the IoT, edge computing, and industrial cloud technologies [
4]. The DT IoTwins architecture is composed of three main computing infrastructure interactive layers; the IoT layer, the edge layer and the cloud layer. The IoT layer assists the DT with configuring and conducting computing/processing activities on the IoT device’s sensory data. The edge layer is responsible for data processing configuration, bulk data processing, data stream processing, and machine learning model execution. The cloud layer can perform the same functions as the edge layer, but the user can configure and run computing operations on data streams from the IoT or edge devices, as well as data stored in the cloud [
4].
Two recent surveys reviewed recent research with an emphasis on building DTs within the context of Industry 4.0. The first survey focused on covering and summarizing the methodological approaches used for designing, modelling, and implementing DTs, including details on how to synchronize real-time data between a DT’s physical and virtual components, as well as the current progress of providing DT implementation tools and an experimental testbed [
5]. The second survey presented a generic DT application architecture consisting of five layers to describe and specify the basic design requirements, related technologies, and integration interlayer process, with an emphasis on how to upgrade the legacy system in Industry 4.0 technologies to improve productivity, reduce costs, and upgrade the industrial process devices [
6].
Human DT is a new research area and has started attracting more attention recently. The human DT concept is mainly based on the collection of real twin (human) data and modelling it using machine learning (ML), a sub-field of Artificial Intelligence (AI), with the goal of extracting information pertaining to the real twin (human)’s health and well-being [
1,
7,
8]. This data collection in the domain of human health generally translates into a challenge for the individual to use and/or wear cumbersome health-sensing devices, which may cause discomfort to individuals and create an additional risk of disease transition.
Understating the concept of the digital twin and how it is implemented in the human DT domain is a challenging new research area, and there is a clear gap in the demonstration of how to design and implement DT technology for human health and well-being applications at the granular level.
Bio-signals, such as heart rate (HR), breathing rate (BR), blood oxygen saturation level (SpO2), and blood pressure (BP), can be used to diagnose human physical and psychological health states such as emotions, fatigue, heart rate variability, mental stress, and sleep patterns [
9]. These bio-signals are becoming crucial to accelerating the adaptation of virtual health and telemedicine services in the healthcare system, which have gained huge momentum in the post-pandemic era.
The authors of another more recent comprehensive survey [
10] revealed several gaps in the area of the remote measurement of heart rate using machine learning methods outside the context and area of human DT. These gaps are that (a) the literature focuses on a single vital sign and there is a need to fuse other bio-signals such as SpO2, (b) the proposed solutions are complex and cannot be applied in a real-time practical application, and (c) there is a need for diverse datasets that contain skin-tone variations.
To address all above mentioned gaps and to establish the groundwork and path forward for achieving a holistic human health and well-being DT model for practical virtual healthcare services in the metaverse, we propose building a data-driven digital twin solution capable of sensing and fusing human bio-signals remotely using modern computer vision/image processing and remote photoplethysmography (rPPG) technologies.
rPPG is considered a low-cost and accessible optical sensing technique that can detect tiny colour intensity changes caused by changes in facial blood flow due to cardiovascular activities under an ambient light environment. Such changes are invisible to the human eye but can be captured directly by a regular colour digital camera sensor. By capturing video and analyzing the data in red, green, and blue (RGB) channels, multiple bio-signals can be extracted from a distance [
11].
Our proposed DT technology has the potential to be applied to real-world applications, e.g., (a) in the emergency room in a hospital for quick bio-signal pre-screening processes, and (b) in long-term health units to monitor and detect elderly patients’ health and well-being signs remotely, and act as a diagnostic support tool that can raise the alarm as soon as an anomaly (i.e., abnormal health pattern) is detected to prevent further chronic problems and degradation in patients’ health.
The structure of this paper is as follows.
Section 2 describes the methods and materials used, and
Section 3 highlights our proposed DT system design and the developed framework utilized to perform offline ML experimentation, development, and testing on ML models required for multi-bio-signal modelling.
Section 4 presents the achieved results and the discussion presented in
Section 5, along with limitations and future work. Finally,
Section 6 presents the conclusion.
3. Digital Twin System Design
This work’s scientific contribution focuses on leveraging data-driven digital twin technology and how to implement it in the human digital twin domain for health and well-being applications, which is a very new area in the literature at this granular level.
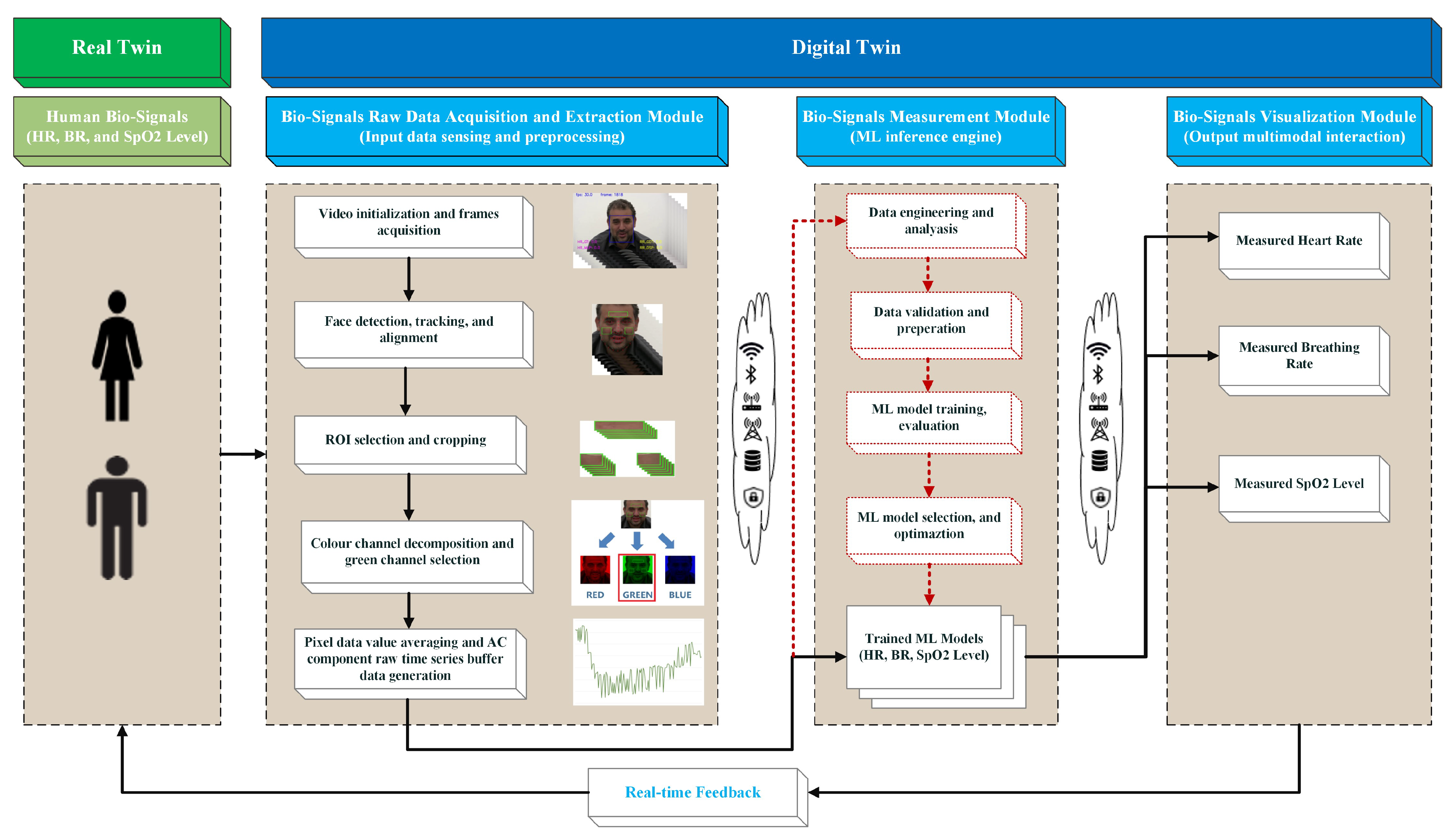
We designed our DT system using a simple architecture that consists of three integrated modules, as illustrated in
Figure 1. The bio-signal data extraction module is responsible for converting raw video frames into time-series data.
The bio-signal measurement module is responsible for processing the raw time-series data and producing each bio-signal using optimized ML-trained models. The bio-signal visualization and interaction module represents the last part of the DT system and should have the ability to provide real-time updates to all three bio-signal readings on a device screen.
The communication between the DT system’s modules is executed using Bluetooth, Wi-Fi/5G networks, or conventional communications services. We implemented the integrated modules using a Python-integrated development environment (PyCharm). The upcoming sub-sections provide an in-depth look at the processes of the mechanics of each module.
3.1. Bio-Signal Raw Data Acquisition and Extraction Module
This module is responsible for the sensing, preprocessing, and extraction of bio-signal raw data from video images taken either directly from a digital camera (real-time mode) or pre-recorded (offline mode) and generates a single time-series output (e.g., 150 green-channel AC-component data points). The inputs of this module are raw video frames (e.g., 150 frames) acquired from a set of short video clips, with synchronized bio-signal ground-truth data taken from each dataset (e.g., a total of 2378 video clips from the VIPL dataset).
The outputs are time-series data per region of interest (ROI) per image (e.g., 150 green-channel AC-component data points) stored in a set of files in “csv” format with essential formatted information (e.g., a total of 7134 files for all three ROIs were generated from the VIPL dataset). Each file contains the participant numbers and physical ground truth for the applicable bio-signal, and 150 points of buffered data are extracted and synchronized with each physical ground truth. The steps we executed during this stage are discussed below.
3.1.1. Video Source (Camera) Initialization and Video Frame Acquisition
There are two types of inputs that can be used as video sources: (i) image frames collected in real-time from a computer webcam, or (ii) image frames collected from pre-recorded offline video files. The system takes one frame from the source until the video-capturing or file-reading process ends.
3.1.2. Face Detection and Tracking
The OpenCV Haar cascade classifier, an open-source Python library, well-known for its effectiveness in real-time object detection applications in computer vision, is applied to detect a human face in the currently processed frame. If an OpenCV facial detector identifies the face on the input video frame, a face frame is tracked and cropped. If the detected face is not correctly positioned in the face frame, we apply an open-source Python facial alignment library (Imutils) to straighten up the face pose before the cropping (i.e., minimize the impact of the head/face pose on the accuracy of dlib for landmark placement). The tracking algorithm resets when the designed buffer is filled or the face is no longer detectable. The motivation behind using the OpenCV Haar cascade classifier in our DT system design research is driven by its proven capability to provide real-time face detection and its availability as a highly optimized open-source Python library.
3.1.3. Facial Landmark Detection and System Authorization
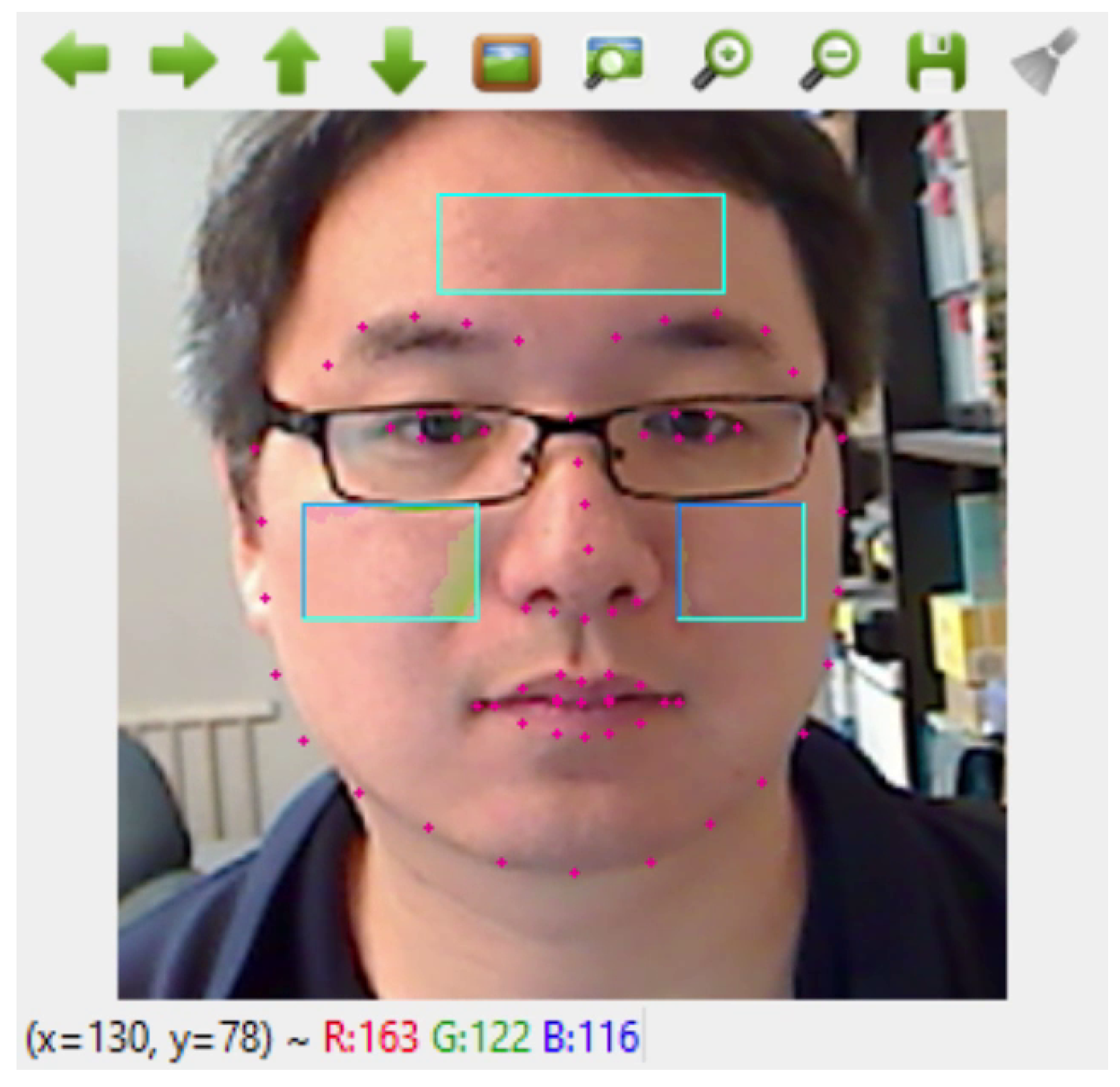
In this stage, we employed a 68-point facial landmark detection open-source Python library (DLib). The DLib pre-trained model uses the regression trees technique to measure 68 facial landmarks based on pixel intensities instead of facial features, producing high-quality face detection in real time (See
Figure 2). After the video frame acquisition and face detection, the locations of the facial landmarks are identified and extracted.
3.1.4. Region of Interest (ROI) Cropping and Selection
The DLib 68-point version was used to identify three ROIs on the face frame, such as two on the left and right cheeks and one on the forehead; this is because the signals related to the absorption bands for oxy- and de-oxy hemoglobin had the strongest signal-to-noise ratio (SNR) corresponding to blood volume changes in these facial skin regions [
20].
3.1.5. Colour Channel Decomposition and Green-Channel Selection
Previous research [
21] indicates that the green-channel data in the RGB colour space remain the most robust for bio-signal extraction (e.g., heart-rate signal extraction). Hence, the green channel is selected as our choice for implementation in the scope of our research due to the presence of the highest signal-to-noise ratio on bio-signal data in this channel.
3.1.6. Pixel Value Averaging and Buffer Data Generation
This step transforms the large sizes of 2D image sequences into a 1D time-series data array and has the advantage of reducing computational expense, despite the reduced size of the input data. The average colour-intensity values based on the green channel and its corresponding ROI images are calculated and stored temporarily in the data buffers.
Each buffer is designed to accept a maximum of 150 data values so it is full when 150 ROI image frames have been successfully received and processed. This takes five seconds at a frame rate of 30 FPS with 0% overlapping between each pair of adjacent windows. The processing time is calculated by dividing the buffer size by the camera frame rate. A frame rate of 30 FPS is the most common frame rate found in many commercial-grade webcams. The sample video clips in all datasets that we utilized in this research were also collected at a frame rate of 30 FPS.
The buffer length was designed after performing a massive number of experiments to achieve optimal performance of the DT real-time system by providing enough data samples and retaining accuracy while updating the bio-signal measurements in nearly real time. By choosing 150-point data as the size of the buffer window, the DT system could run and update bio-signal readings efficiently in real time and retain at least one cycle of the BR and usually five cycles of the HR. This is a crucial factor for the design of an accurate system running in real time, even with hardware constraints.
In addition, from a signal-processing perspective, the sampling rate needs to be fast enough to enable the detection of the heart rate at its maximum possible frequency, which we have set at 180 BPM or 3Hz. According to the Nyquist limit, the highest frequency component that can be accurately reconstructed should be equal to or less than half of the sampling rate [
22].
A frame rate of 30 FPS is not a mandatory camera speed since our system sampling rate is determined by how fast our data buffer is filled during the digital camera video recording in real time. Therefore, a minimum of 6 FPS (or 6 Hz) as a frame acquisition speed should be maintained to perform accurate bio-signal measurements for obtaining an HR at a detection mode of 180 BPM or less.
3.2. Bio-Signal Data Measurement Module
This module represents the ML inference engine, which we consider the core of the DT, and has two main functions: (i) perform data and ML model engineering in offline experimentation setting to produce optimized, trained ML models, as indicated in
Figure 1 by the red dotted communication lines and boxes, and (ii) consume the raw time-series-shaped buffer data (e.g., 150 green-channel AC-component data points) and produce three bio-signal measurements simultaneously in real time using the optimized trained ML models. Each step of the process is explained in more depth below.
3.2.1. Data Engineering and Analysis
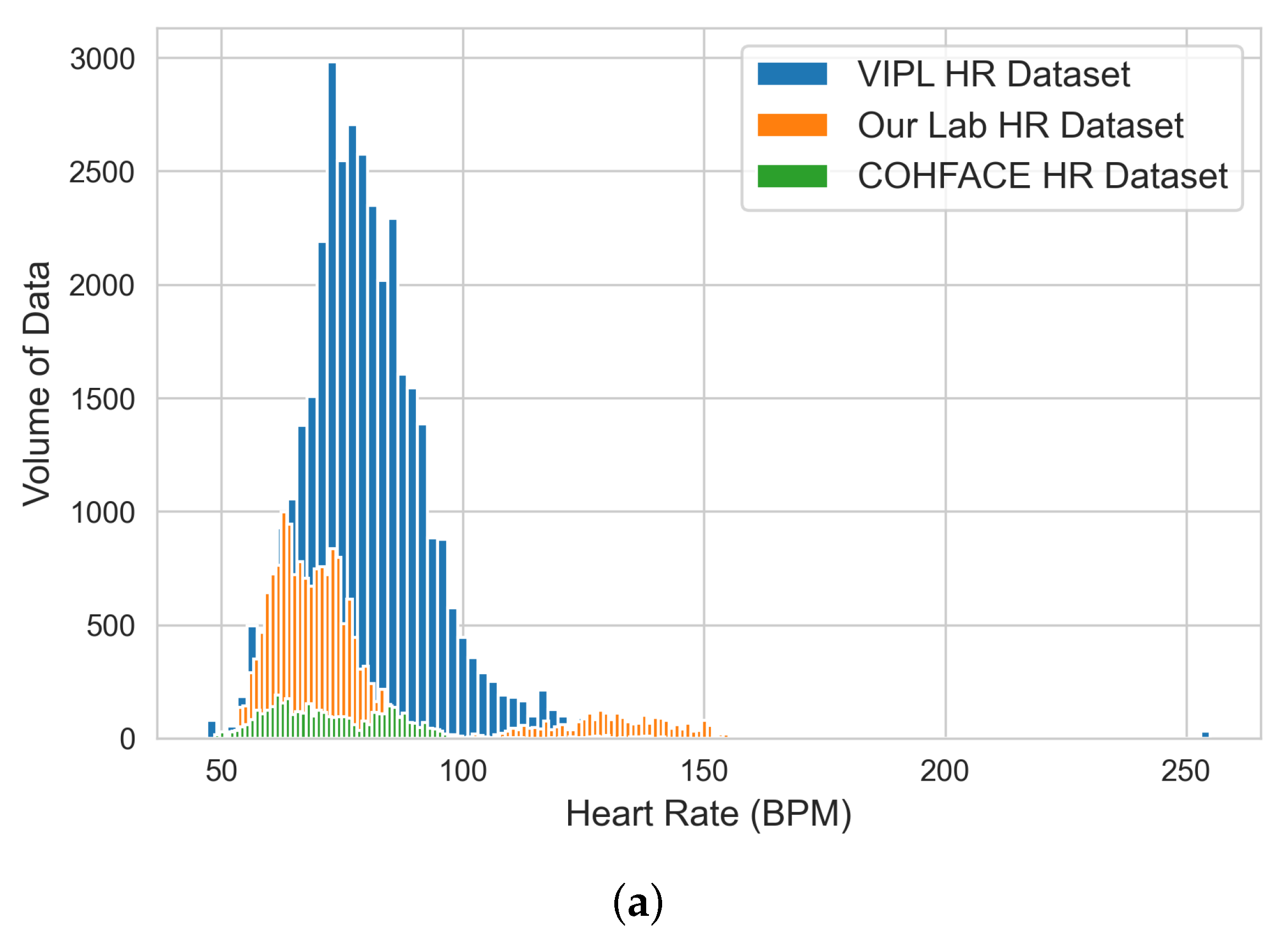
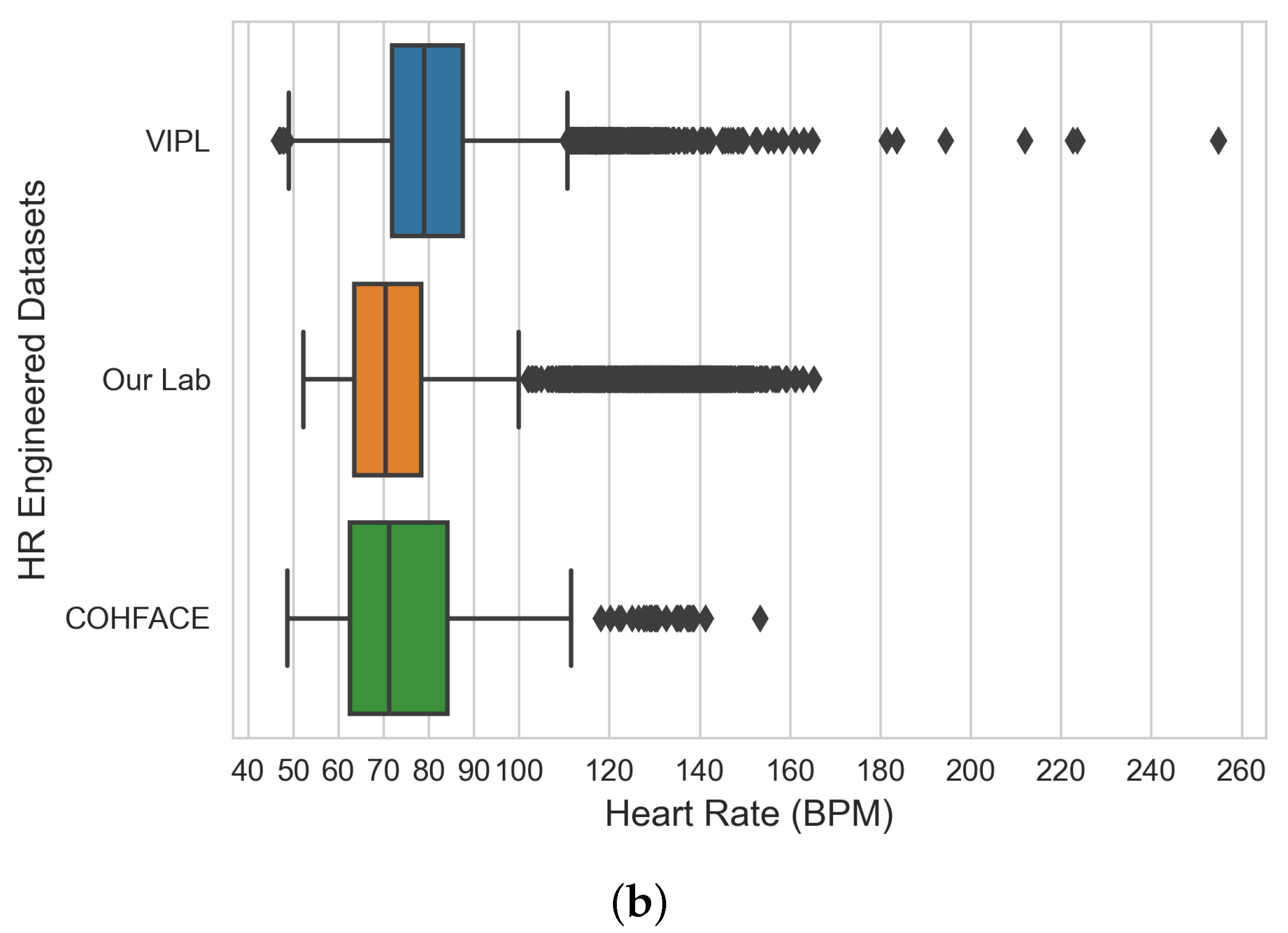
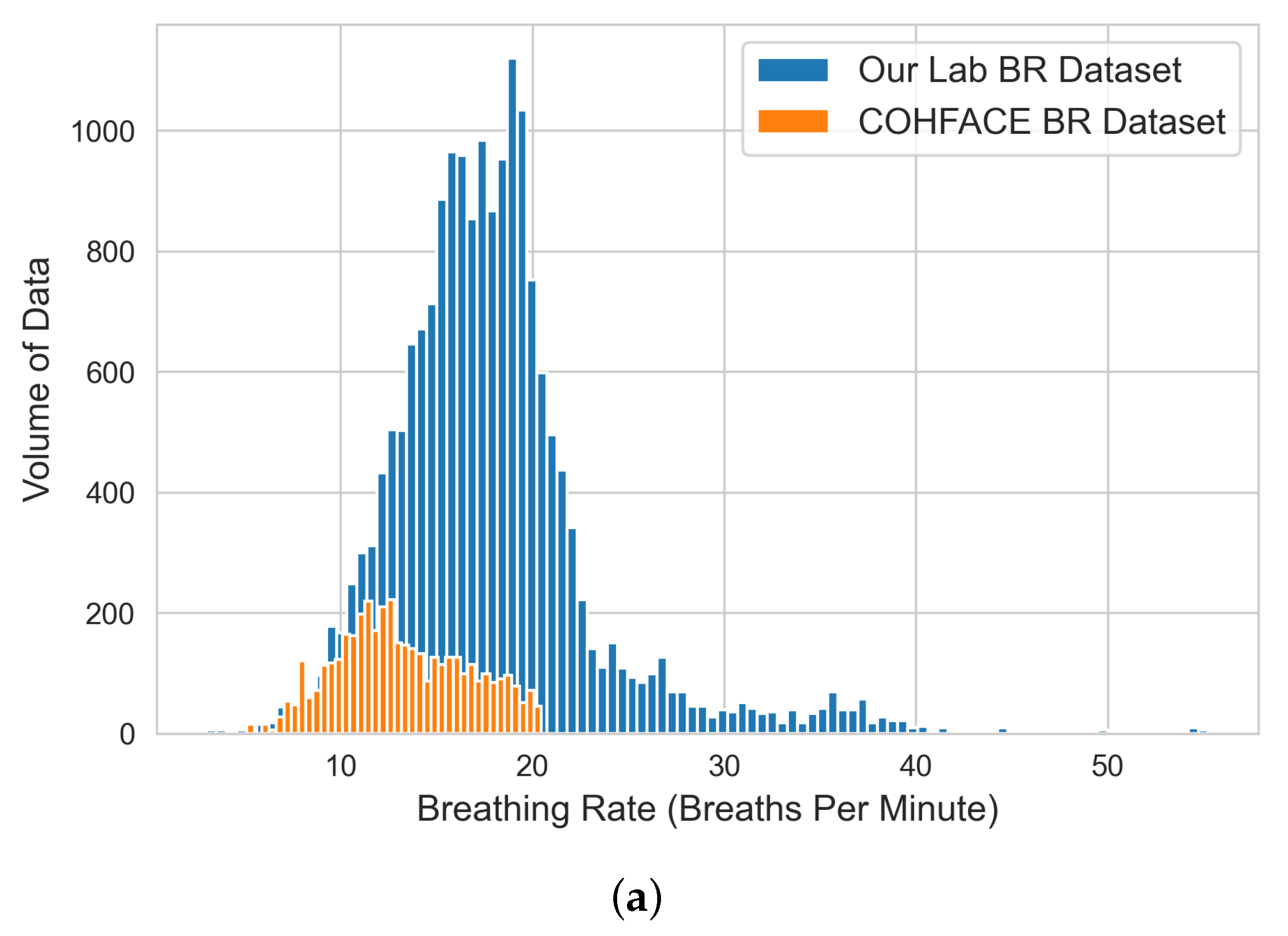
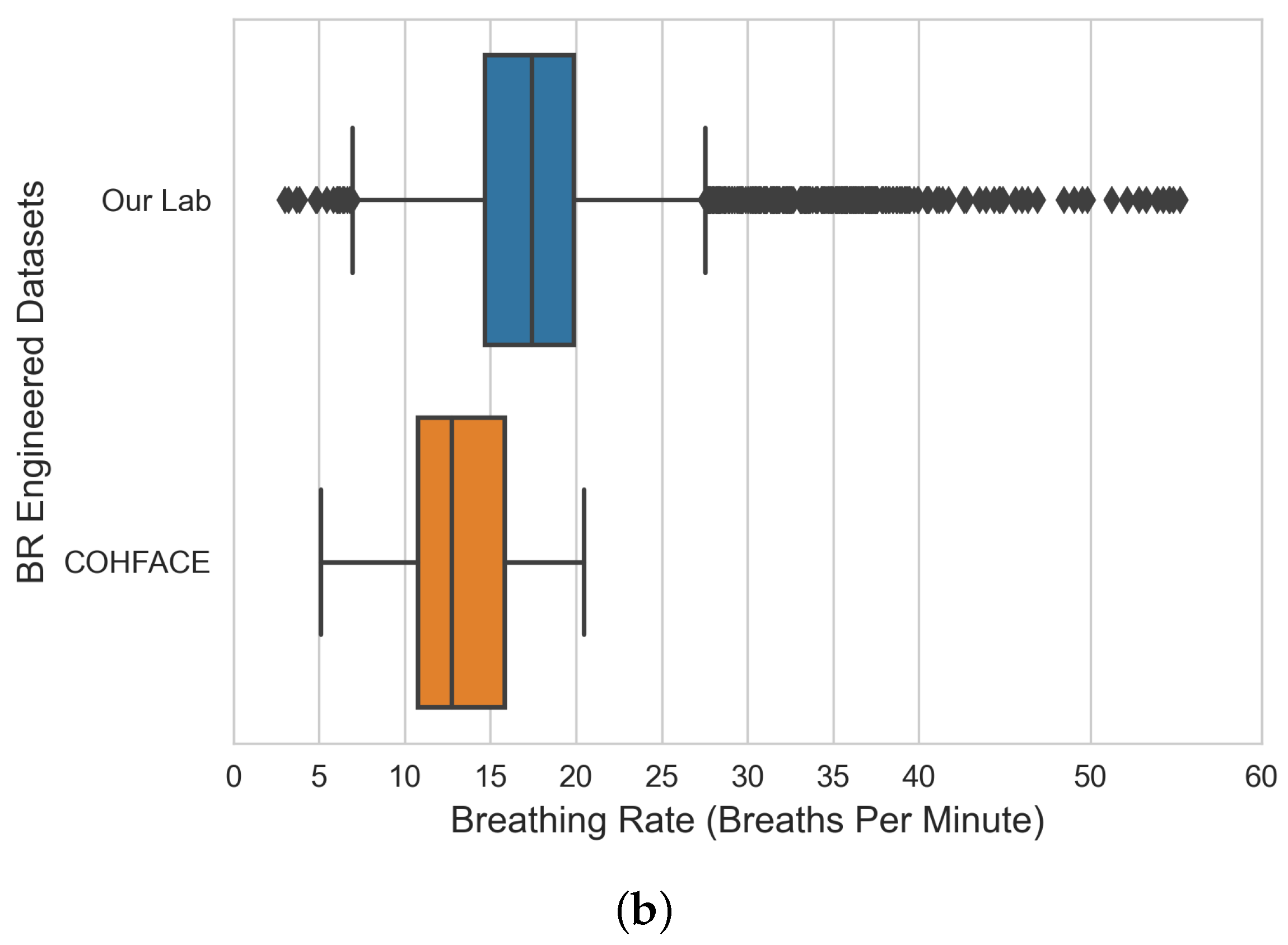
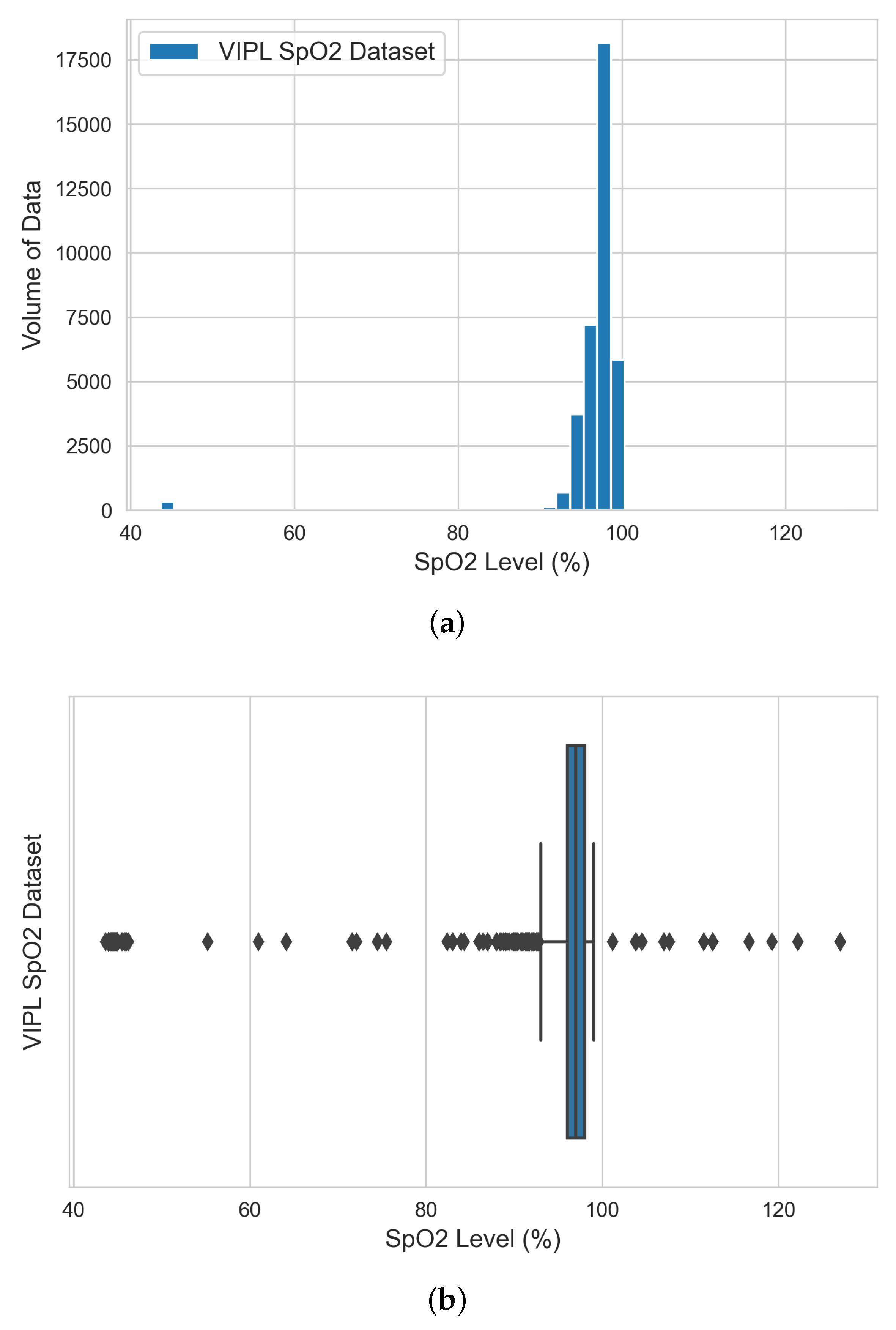
The input of this stage is a set of raw time-series data files in “csv” format and the outputs are three engineered raw datasets (i.e., VIPL, COHFACE, and our lab dataset). The steps of the data engineering and analysis stage are (i) aggregating all the generated raw time-series data (green-channel AC-component data) from the previous stage for each dataset; before data aggregation, empty files that resulted from no face detection are sorted and filtered; (ii) performing exploratory data analysis (EDA) to analyze and understand the statistical characteristics of each bio-signal dataset and identify potential outliers before model experimentation; and (iii) producing three engineered datasets: the VIPL dataset that contains HR and SpO2 bio-signal data, our lab dataset that contains HR and BR bio-signal data, and COHFACE that contains HR and BR bio-signal data.
3.2.2. Data Validation and Preparation
The inputs of this stage are three datasets (i.e., VIPL, COHFACE, and our lab datasets) and the outputs are three clean (training, validation, and testing) datasets for each bio-signal (i.e., HR, BR, and SpO2). The steps of the data preparation stage are (i) performing dataset cleaning based on the observations highlighted in the previous stage, as well as ensuring all three datasets are free of rows with zero values if any; (ii) splitting each vital dataset into training (60%), validation (20%), and testing (20%); the data split should include all the subject data in the respected dataset to avoid data leakage (i.e., a case where the participant data are split among the training, validation, and testing datasets). Data leak prevention is essential for producing an accurate model parameter capable of providing predictive power once we deploy them in the production environment; and (iii) aggregating and creating three separate datasets for training, validation, and testing purposes (e.g., the final training dataset is an aggregation of 60% of VIPL dataset, 60% of our lab dataset, and 60% of COHFACE dataset)
The data split was performed by applying filters in Panda’s Python package to maintain proper dataset partitioning, where each participant’s data are present in one dataset and do not appear in other datasets to avoid the leakage of any single participant in the training, validation, and testing datasets. The 60/20/20 division of the data samples generated from all subjects was chosen since the length of each participant video was variable and the generated data samples were not equal among all participants. The percentage refers to the split in the data samples across all samples for each dataset.
3.2.3. ML Model Training and Validation
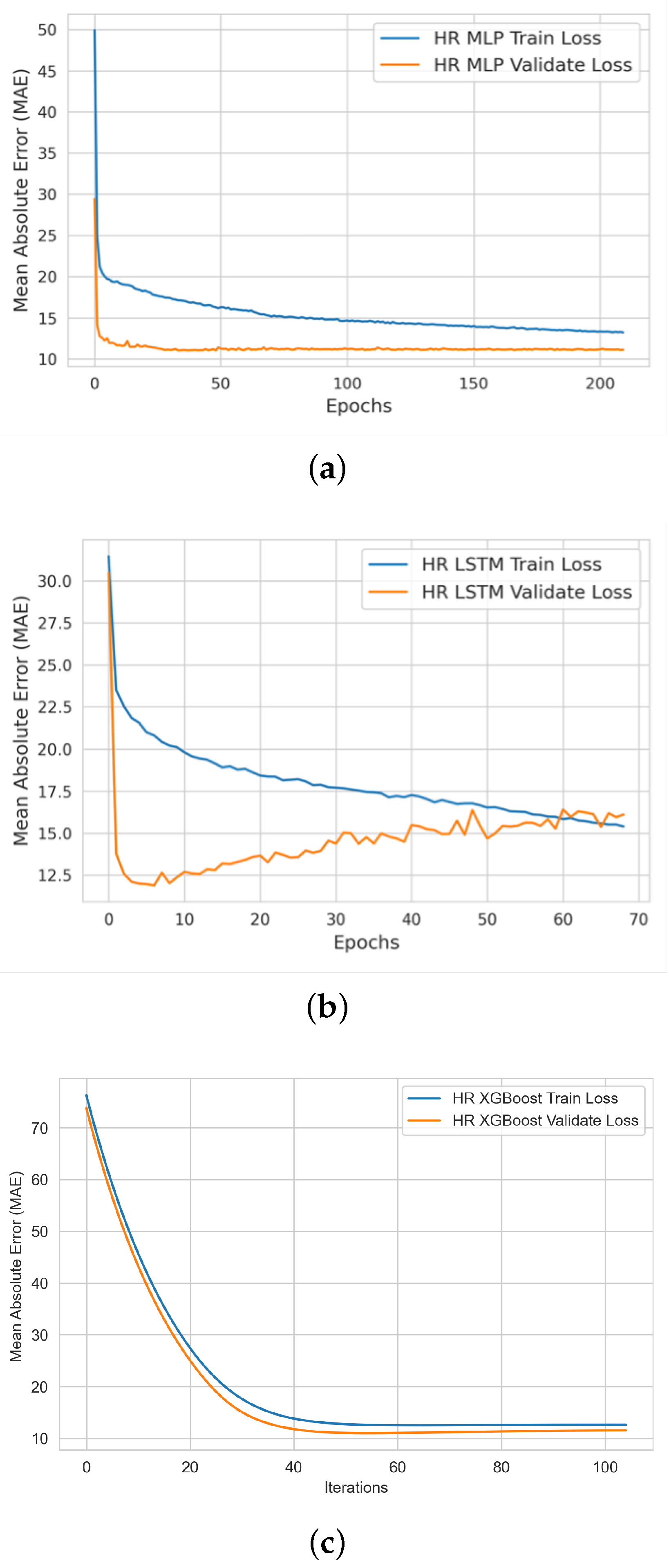
The input of this stage is a clean training dataset ready to perform experimentation on three ML algorithms (i.e., XGBoost, MLP, and LSTM) and the outputs are three trained models prepared for testing.
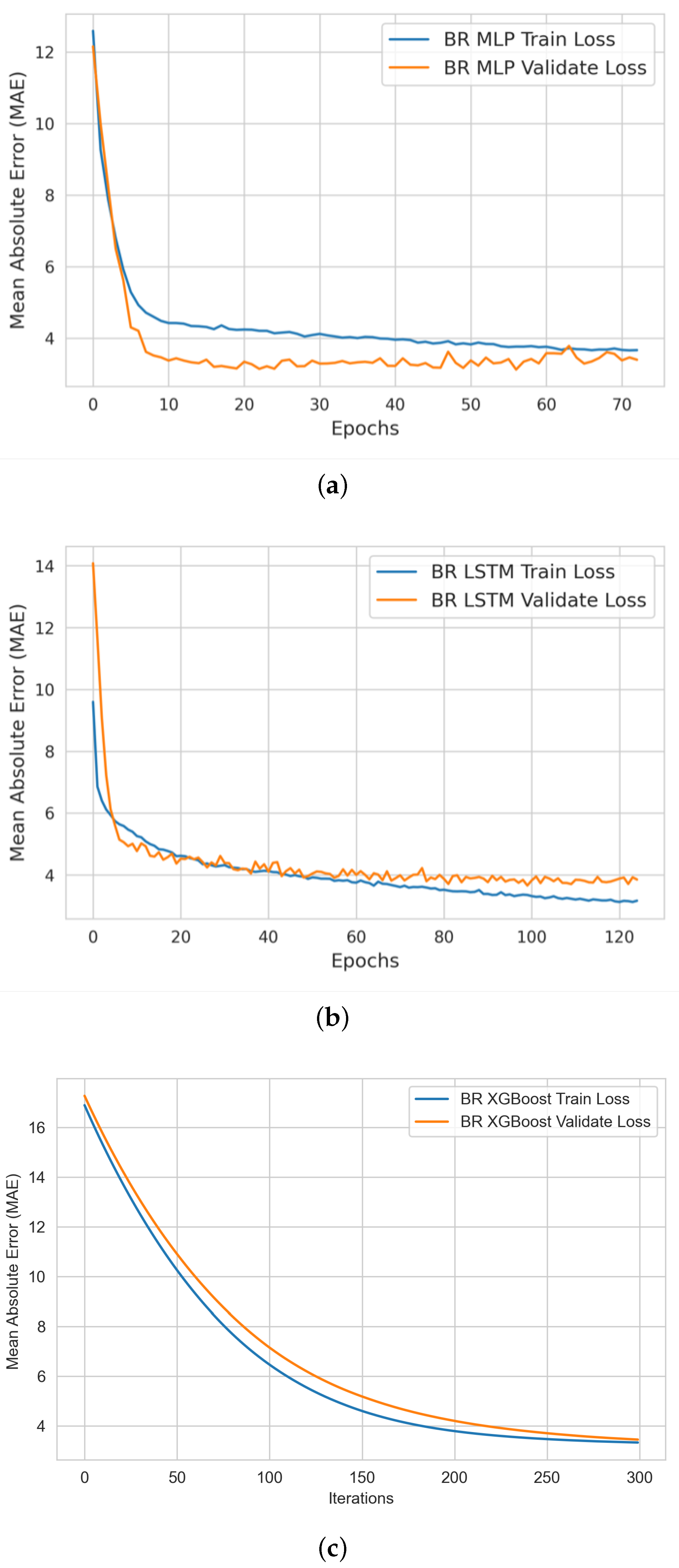
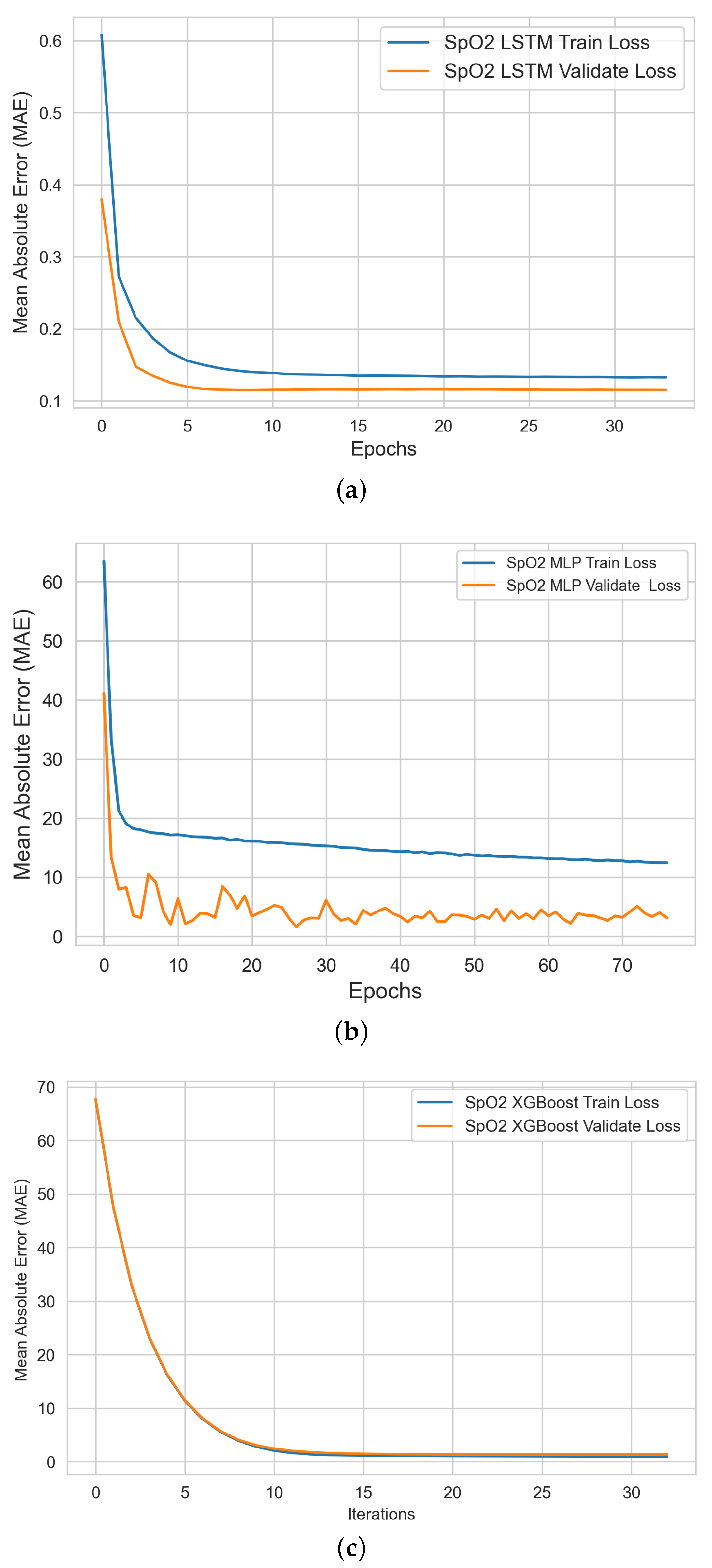
The steps of the ML model training and validation stage are (i) establishing a list of potential ML regression algorithms for designing and developing various ML models capable of accurately detecting and estimating bio-signals; (ii) establishing model performance evaluation metrics to assess model prediction quality; (iii) performing model training experimentation based on the engineered training dataset from the previous stage; (iv) performing model validation experimentation based on the engineered validation (holdout) dataset from the previous stage; (v) visualizing the learning profile during training and validation for each ML model per bio-signal; and (vi) performing hyperparameter tuning and producing the best-trained ML models for the upcoming testing stage.
3.2.4. ML Model Testing, Selection, and Tuning
The input of this stage is nine trained ML models with three models per bio-signal (i.e., MLP, LSTM, and XGBoost) and the outputs are the best-three performing models selected for each bio-signal, saved in tuple format and ready for deployment in the operating environment.
The steps of the ML model testing, selection, and tuning stage are (i) establishing performance validation and selection metrics; (ii) analyzing and reporting each model’s testing performance; and (iii) selecting, saving, and transferring the best-performing model’s parameters/weights in tuple format for the system design, deployment, and operation phases.
3.3. Bio-Signal Visualization Module
This module represents the last part of the DT twin system and facilitates the output’s visualization and interaction with the real twin through Bluetooth, Wi-Fi/5G networks, or conventional communications services. In our proposed system, the ML-based bio-signal DT model’s output interface should have the capability to provide real-time updates to all three bio-signal readings on a device screen.
5. Discussion
5.1. System Runtime
The ML-based bio-signal DT model’s output interface is shown in
Figure 9. The real-time window updates the bio-signal readings every 30 frames (i.e., every second if the camera recording speed is 30 FPS). The system takes 40–60 milliseconds to process all stages of the bio-signal data extraction module and takes 64–66 milliseconds to measure all bio-signals in real time. This computational measurement is based on the hardware specification stated in
Appendix A.
Figure 9a shows the system’s output interface using a video camera as a real-time input source, where HR denotes the heart rate, BR denotes the breathing rate, and SpO2 denotes the blood oxygen level.
Figure 9b shows the system’s output interface based on an offline video input source. The remotely measured HR, BR, and SpO2 are published on the screen. The system reads and updates the ground-truth values for the heart rate and breathing rate (HR GT and BR GT), respectively, from pre-synchronized data files for easy comparison purposes.
The DT system showed great performance in modelling and measuring the HR, BR, and SpO2 bio-signals because the testing environment conditions were identical or close to those of the lab environment during the dataset collections. This is because machine learning theory only deals with generalizations within the same distribution between the training and validation/testing datasets, i.e., independent and identically distributed (i.i.d.) assumptions.
Two measures were considered during the DT system design to manage system sensitivity to noise: (i) we used the green-channel data in the RGB colour space due to its robustness to bio-signal extraction (the presence of the highest signal-to-noise ratio (SNR) on the bio-signal data was in this channel); (ii) we used three regions of interest (ROI) on the face frame (left and right cheeks and the forehead) because the signals related to the absorption bands for oxy- and de-oxy hemoglobin had the strongest SNR corresponding to blood volume changes in these facial skin regions.
The merits of this initial system are that it (1) demonstrates a simple DT architecture that uses a shared common (bio-signal data extraction) module that takes a single input (raw video frames), processes it using a light-weight pre-trained ML model for each bio-signal and produces multiple outputs (three estimated outputs: heart rate, respiratory rate, and blood oxygen saturation level); (2) demonstrates promising modelling and fusion performance; (3) engineers light-weighted ML DT models capable of working in both real-time and offline modes and enables rapid deployment in the production environment due to its fast processing time and efficient hardware requirements, which establishes our pioneering research work as a new milestone for adapting ML-based DT technology solutions to real-time metaverse digital health applications; and (4) enables potential digital health data security through computer vision and biometrics with the data fusion of multiple bio-signals.
Our XGBoost model showed consistently outstanding performance in estimating all three bio-signals. The advantages of XGBoost over the MLP and LSTM models are that (1) it has immunity and robustness against anomalies and outliers; this is because it is a tree-based ensemble learning technique that uses the boosting method to build each tree on previous tree residuals/errors. Outliers will have much larger residuals than non-outliers, will not be considered during tree splitting, and will not contribute to the overall model error value during training; (2) it is built on a simple architecture with a small number of parameters for optimization; (3) it can be configured, trained, and tested quickly; and (4) it does not require input data normalization; (5) it generates a small, trained model size, which is light enough (less than 700 KB) to enable rapid deployment in future production environments.
The XGBoost model performance was optimized after tuning three hyperparameters (learning rate, no. of estimators (number of trees), and maximum depth (depth of trees)). In addition, we fixed the random state value to enable reproducible results. We applied the early stopping technique to prevent the model from overfitting the training data (e.g., stopping the model training when the validation loss stopped improving after 50 iterations for the HR model). The full design parameters of the best-performing XGBoost regression models used in our DT system are shown in
Table 7.
5.2. Limitations and Future Work
The limitations we experienced during this work were as follows: (a) Since most of the heart rate data we collected were within the 65–85 BPM spectrum, heart rate data beyond this spectrum are highly desired for further model refinement, particularly for detecting heart rates at an exercising level; (b) Some datasets, for example, the COHFACE dataset, came with highly compressed video files and the original recordings were noisy. These could not contribute to the model training because weak signals representing blood volume changes were already filtered during the video compression process; (c) The hardware variations, such as different webcam specifications and real-time light conditions, can all contribute to reducing accuracy in the performance; and (d) We noticed that the COHFACE dataset provided raw blood volume pulse (BVP) and breathing recordings and we needed to convert them into HR and BR data in the frequency domain using BioSPPy (Python bio-signal processing library) before we could use them as ground truths. However, this introduced a slight delay in the video physical data synchronization as every processed HR/BR data required a set of raw inputs before making calculations.
Although light and vibration/motion are factors that are involved in ML models’ robustness, our research focused on the accuracy of the DT system itself. Studying the impact of such factors, including quality index analysis, is a potential area of future research.
Therefore, to tackle these challenges, our future work will focus on (i) using generative models to enrich each bio-signal dataset with more data and features such as age, gender, and skin colour; (ii) adding a motion-based feature to improve the accuracy of the BR model; and (iii) developing advanced hybrid ML ensemble model architectures with transfer learning (e.g., autoencoder with MLP or XGBoost).
6. Conclusions
The contribution of this research paper focused on addressing an important gap in the literature. This gap involved the need to demonstrate how to develop and implement DT technology concept for modern human health and well-being applications in the metaverse at a granular level. To the best of the authors’ knowledge, no previous work has demonstrated a fully functional human DT prototype that integrates machine learning and computer vision/rPPG technologies, capable of detecting tiny colour-intensity changes directly from human facial video frames without making physical contact, and then fusing three human physiological bio-signals in real time concurrently (heart rate, breathing rate, and blood oxygen saturation level) using simple ML regression models with minimum pre-processing/processing time and very efficient memory hardware requirements.
Understanding the concept of the DT and how it is implemented in the human DT domain is a challenging research area. To address this challenge, we presented the novelty of our work simply and comprehensively. The engineered solution was experimented with and validated under both real-time and offline configurations. The system performances under our testing achieved strong accuracy in the modeling and measuring of HR, BR, and SpO2 bio-signals. The HR ML model’s testing results showed that the XGBoost model provided the lowest testing performance error rate (9.5%) in comparison with the MLP and LSTM models, which meant a 91% accuracy in modeling and measuring the HR bio-signal; the BR XGBoost model provided the lowest testing performance error rate (13.4%, i.e., 87% accuracy); and the SpO2 XGBoost model provided the lowest testing performance error rate (1.1%, i.e., 99% accuracy).
We consider our pioneering research work a new milestone in establishing the foundation and path forward for realizing a holistic human health and well-being DT model for real-world personalized health applications and virtual telemedicine services.




 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}