
A Comparison of Deep Neural Networks for Monocular Depth Map Estimation in Natural Environments Flying at Low Altitude

 ,
,  , and
, and
Abstract
:1. Introduction
- A qualitative and quantitative analysis of the performance of four state-of-the-art neural networks for monocular depth estimations of synthetic images of complex forested environments.
- We propose a new model resulting from the combination of GLPDepth and Boosting Monocular Depth networks, increasing the accuracy of depth maps compared with GLPDepth alone and decreasing the inference time in the Boosting Monocular Depth structure.
- A discussion of the main open challenges of the monocular depth estimation with neural networks in natural environments.
2. Related Work
2.1. Monocular Depth Estimation Networks
2.2. Datasets for Monocular Depth Map Estimation
3. Monocular Depth Estimation Networks Analyzed in This Work
4. Comparison of the Monocular Depth Estimation Networks
4.1. TartanAir Dataset
4.2. Metrics for Monocular Depth Estimation
4.3. Qualitative Analysis of Networks
4.4. Quantitative Analysis of Networks
5. Challenges in Monocular Depth Estimation to Navigate in Complex Natural Environments
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| UAVs | Unmanned Aerial Vehicles |
| DL | Deep Learning |
| ANN | Artificial Neural Network |
| FE | Feature Engineering |
| CNN | Convolutional Neural Networks |
| WSL | Weakly Supervised Data |
| DPT | Dense Prediction Transform |
| MSFM | Multi-Scale Feature Modulation |
| GPU | Graphics Processing Unit |
| SFF | Selective Feature Fusion |
References
- Alsamhi, S.H.; Shvetsov, A.V.; Kumar, S.; Shvetsova, S.V.; Alhartomi, M.A.; Hawbani, A.; Rajput, N.S.; Srivastava, S.; Saif, A.; Nyangaresi, V.O. UAV Computing-Assisted Search and Rescue Mission Framework for Disaster and Harsh Environment Mitigation. Drones 2022, 6, 154. [Google Scholar] [CrossRef]
- Tsouros, D.C.; Bibi, S.; Sarigiannidis, P.G. A review on UAV-based applications for precision agriculture. Information 2019, 10, 349. [Google Scholar] [CrossRef] [Green Version]
- Diez, Y.; Kentsch, S.; Fukuda, M.; Caceres, M.L.L.; Moritake, K.; Cabezas, M. Deep learning in forestry using uav-acquired rgb data: A practical review. Remote Sens. 2021, 13, 2387. [Google Scholar] [CrossRef]
- Yasuda, Y.D.V.; Martins, L.E.G.; Cappabianco, F.A.M. Autonomous visual navigation for mobile robots: A systematic literature review. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.; Xue, Z.; Xia, G.-S.; Zhang, L. A survey on vision-based UAV navigation. Geo-Spat. Inf. Sci. 2018, 21, 21–32. [Google Scholar] [CrossRef] [Green Version]
- Loquercio, A.; Kaufmann, E.; Ranftl, R.; Müller, M.; Koltun, V.; Scaramuzza, D. Learning high-speed flight in the wild. Sci. Robot. 2021, 6, 59. [Google Scholar] [CrossRef] [PubMed]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep learning An MIT Press Book; MIT Press: Cambridge, MA, USA, 2016; pp. 1–8. [Google Scholar]
- Amer, K.; Samy, M.; Shaker, M.; ElHelw, M. Deep convolutional neural network-based autonomous drone navigation. arXiv 2019. [Google Scholar] [CrossRef]
- Tai, L.; Li, S.; Liu, M. A deep-network solution towards model-less obstacle avoidance. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems. Daejeon, Republic of Korea, 9–14 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2759–2764. [Google Scholar] [CrossRef]
- Khan, F.; Salahuddin, S.; Javidnia, H. Deep learning-based monocular depth estimation methods—A state-of-the-art review. Sensors 2020, 20, 2272. [Google Scholar] [CrossRef]
- Dong, X.; Garratt, M.A.; Anavatti, S.G.; Abbass, H.A. Towards Real-Time Monocular Depth Estimation for Robotics: A Survey. arXiv 2021. [Google Scholar] [CrossRef]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1623–1637. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Fan, X.; Shi, P.; Xin, Y. R-MSFM: Recurrent Multi-Scale Feature Modulation for Monocular Depth Estimating. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Miangoleh, S.H.M.; Dille, S.; Mai, L.; Paris, S.; Aksoy, Y. Boosting Monocular Depth Estimation Models to High-resolution via Content-adaptive Multi-Resolution Merging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Xian, K.; Zhang, J.; Wang, O.; Mai, L.; Lin, Z.; Cao, Z. Structure-Guided Ranking Loss for Single Image Depth Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Lecture Notes in Computer Science, Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Denmark, 2015; Volume 9351. [Google Scholar] [CrossRef] [Green Version]
- Yin, W.; Zhang, J.; Wang, O.; Niklaus, S.; Mai, L.; Chen, S.; Shen, C. Learning to Recover 3D Scene Shape from a Single Image. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Kim, D.; Ga, W.; Ahn, P.; Joo, D.; Chun, S.; Kim, J. Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth. arXiv 2022. [Google Scholar] [CrossRef]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? Adv. Neural Inf. Proc. Syst. 2017, 30, 5574–5584. [Google Scholar]
- Teed, Z.; Jia, D. DeepV2D: Video to depth with differentiable structure from motion, International Conference on Learning Representations (ICLR). arXiv 2020. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, H.; Hu, Z.; Peng, J. Attention-based context aggregation network for monocular depth estimation. Int. J. Mach. Learn. Cybern. 2021, 12, 1583–1596. [Google Scholar] [CrossRef]
- Alhashim, I.; Wonka, P. High quality monocular depth estimation via transfer learning. arXiv 2018. [Google Scholar] [CrossRef]
- Yin, W.; Liu, Y.; Shen, C.; Yan, Y. Enforcing geometric constraints of virtual normal for depth prediction. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.H.; Han, M.K.; Ko, D.W.; Suh, I.H. From big to small: Multi-scale local planar guidance for monocular depth estimation. arXiv 2019. [Google Scholar] [CrossRef]
- Wofk, D.; Ma, F.; Yang, T.J.; Karaman, S.; Sze, V. FastDepth: Fast monocular depth estimation on embedded systems. In Proceedings of the IEEE International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019. [Google Scholar] [CrossRef] [Green Version]
- Zhao, S.; Fu, H.; Gong, M.; Tao, D. Geometry-aware symmetric domain adaptation for monocular depth estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Goldman, M.; Hassner, T.; Avidan, S. Learn stereo, infer mono: Siamese networks for self-supervised, monocular, depth estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Andraghetti, L.; Myriokefalitakis, P.; Dovesi, P.L.; Luque, B.; Poggi, M.; Pieropan, A.; Mattoccia, S. Enhancing Self-Supervised Monocular Depth Estimation with Traditional Visual Odometry. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Quebec City, QC, Canada, 16–19 September 2019. [Google Scholar] [CrossRef] [Green Version]
- Garg, R.; Vijay Kumar, B.G.; Carneiro, G.; Reid, I. Unsupervised CNN for single view depth estimation: Geometry to the rescue. In European Conference on Computer Vision; Springer: Cham, Denmark, 2016; Volume 9912, pp. 740–756. [Google Scholar] [CrossRef] [Green Version]
- Eigen, D.; Fergus, R. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-scale Convolutional Architecture. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar] [CrossRef]
- Tosi, F.; Aleotti, F.; Poggi, M.; Mattoccia, S. Learning monocular depth estimation infusing traditional stereo knowledge. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Guizilini, V.; Ambrus, R.; Pillai, S.; Gaidon, A. 3D Packing for Self-Supervised Monocular Depth Estimation. arXiv 2019. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32. [Google Scholar] [CrossRef] [Green Version]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from RGBD images. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7576, No. Part 5. [Google Scholar] [CrossRef]
- Giusti, A.; Guzzi, J.; Cireşan, D.C.; He, F.-L.; Rodríguez, J.P.; Fontana, F.; Faessler, M.; Forster, C.; Schmidhuber, J.; Caro, G.D.; et al. A Machine Learning Approach to Visual Perception of Forest Trails for Mobile Robots. IEEE Robot. Autom. Lett. 2016, 1, 661–667. [Google Scholar] [CrossRef] [Green Version]
- Howard, A.; Nate Koenig, N. Gazebo: Robot simulation made easy. Open Robot. Found. 2002. Available online: https://gazebosim.org/home (accessed on 19 September 2021).
- Microsoft Research, AirSim. 2021. Available online: https://microsoft.github.io/AirSim/ (accessed on 5 June 2021).
- Wang, W.; Zhu, D.; Wang, X.; Hu, Y.; Qiu, Y.; Wang, C.; Hu, Y.; Kapoor, A.; Scherer, S. TartanAir: A Dataset to Push the Limits of Visual SLAM. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021. [Google Scholar] [CrossRef]
- Fonder, M.; Droogenbroeck, M.V. Mid-air: A multi-modal dataset for extremely low altitude drone flights. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Xian, K.; Shen, C.; Cao, Z.; Lu, H.; Xiao, Y.; Li, R.; Luo, Z. Monocular Relative Depth Perception with Web Stereo Data Supervision. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision Transformers for Dense Prediction. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv 2015. [Google Scholar] [CrossRef]
- Miangoleh, S.H.M.; Dille, S.; Mai, L.; Paris, S.; Aksoy, Y. Github repository of Boosting Monocular Depth Network. Available online: https://github.com/compphoto/BoostingMonocularDepth (accessed on 15 October 2022).
- De Sousa Ribeiro, F.; Calivá, F.; Swainson, M.; Gudmundsson, K.; Leontidis, G.; Kollias, S. Deep bayesian self-training. Neural Comput. Appl. 2020, 32, 4275–4291. [Google Scholar] [CrossRef]

| Networks | Datasets | AbsRel | RMSE |
|---|---|---|---|
| MiDaS [13] | ETH3D | 0.129 | - |
| R-MSFM [14] | KITTI | 0.108 | 4.470 |
| Boosting [15] | Middlebury | - | 0.156 |
| Ibims-1 | - | 0.160 | |
| GLPDepth [20] | KITTI | 0.057 | 2.297 |
| Ibims-1 | 0.200 | 1.010 |
| Details | Gascola | Season Forest | Season Forest Winter |
|---|---|---|---|
| Size of the set | 1.38 GB | 1.24 GB | 1.22 GB |
| Image resolution | 640 × 480 | 640 × 480 | 640 × 480 |
| Number of images | 382 | 301 | 330 |
| Trajectories | RGB | RGB | RGB |
|---|---|---|---|
| (a) Gascola |  |  |  |
| (b) Season Forest |  |  |  |
| (c) Season Forest Winter |  |  |  |
| RGB | Ground Truth | R-MSFM | MiDaS | GLPDepth | Boosting Monocular Depth |
|---|---|---|---|---|---|
 | 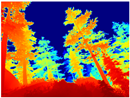 |  |  |  |  |
 |  | 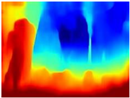 | 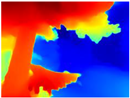 |  |  |
 |  | 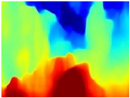 | 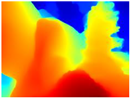 |  |  |
 |  |  |  |  |  |
 |  | 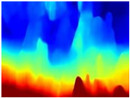 |  |  |  |
 |  |  |  |  |  |
 |  | 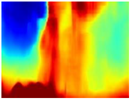 |  |  |  |
 |  |  |  |  |  |
 |  | 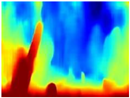 |  |  |  |
| RGB | Ground Truth | GLPDepth | Boosting Monocular Depth (LeReS) |
|---|---|---|---|
 |  | 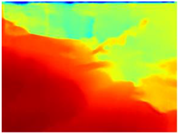 |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
| Gascola | Season Forest | Season Forest Winter | ||||
|---|---|---|---|---|---|---|
| Metrics | GLPDepth | Boosting Monocular Depth (LeReS) | GLPDepth | Boosting Monocular Depth (LeReS) | GLPDepth | Boosting Monocular Depth (LeReS) |
| RMSE | 0.086 | 0.023 | 0.133 | 0.089 | 0.201 | 0.092 |
| ORD | 0.633 | 0.295 | 0.771 | 0.611 | 0.576 | 0.624 |
| 0.761 | 0.489 | 0.839 | 0.742 | 0.695 | 0.540 | |
| δ >1.25 | 0.771 | 0.658 | 0.893 | 0.908 | 0.868 | 0.909 |
| δ > | 0.572 | 0.392 | 0.785 | 0.819 | 0.736 | 0.807 |
| δ > | 0.416 | 0.224 | 0.673 | 0.726 | 0.608 | 0.696 |
| RMSElog | 0.313 | 0.205 | 0.504 | 0.576 | 0.443 | 0.507 |
| Abs.Rel. | 0.925 | 0.487 | 2.009 | 1.477 | 2.165 | 1.460 |
| Sq.Rel. | 0.165 | 0.073 | 0.217 | 0.193 | 0.255 | 0.167 |
| Gascola | Season Forest | Season Forest Winter | ||||
|---|---|---|---|---|---|---|
| Runtime (ms) | GLPDepth | Boosting Monocular Depth (LeRes) | GLPDepth | Boosting Monocular Depth (LeRes) | GLPDepth | Boosting Monocular Depth (LeRes) |
| maximum | 1405 | 3424 | 796 | 2502 | 1552 | 1851 |
| minimum | 235 | 1626 | 250 | 1578 | 124 | 1510 |
| 215 | 167 | 163 | 122 | 230 | 42 | |
| average | 514 | 1796 | 436 | 1776 | 346 | 1604 |
| RGB | Ground Truth | GLPDepth | Boosting Monocular Depth (LeReS) | Boosting Monocular Depth (GLPDepth) |
|---|---|---|---|---|
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 | 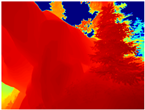 |  |  |  |
| Metrics | GLPDepth | Boosting Monocular Depth (LeReS) | Boosting Monocular Depth (GLPDepth) |
|---|---|---|---|
| RMSE | 0.086 | 0.023 | 0.082 |
| ORD | 0.633 | 0.295 | 0.721 |
| 0.761 | 0.489 | 0.763 | |
| δ > 1.25 | 0.771 | 0.658 | 0.775 |
| δ > | 0.572 | 0.392 | 0.584 |
| δ > | 0.416 | 0.224 | 0.436 |
| RMSElog | 0.313 | 0.205 | 0.325 |
| Abs.Rel. | 0.925 | 0.487 | 1.280 |
| Sq.Rel. | 0.165 | 0.073 | 0.274 |
| Runtime (ms) | GLPDepth | Boosting Monocular Depth (LeReS) | Boosting Monocular Depth (GLPDepth) |
|---|---|---|---|
| Maximum | 1405 | 3424 | 2094 |
| Minimum | 235 | 1626 | 1359 |
| 215 | 167 | 086 | |
| Average | 514 | 1796 | 1519 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Romero-Lugo, A.; Magadan-Salazar, A.; Fuentes-Pacheco, J.; Pinto-Elías, R. A Comparison of Deep Neural Networks for Monocular Depth Map Estimation in Natural Environments Flying at Low Altitude. Sensors 2022, 22, 9830. https://doi.org/10.3390/s22249830
Romero-Lugo A, Magadan-Salazar A, Fuentes-Pacheco J, Pinto-Elías R. A Comparison of Deep Neural Networks for Monocular Depth Map Estimation in Natural Environments Flying at Low Altitude. Sensors. 2022; 22(24):9830. https://doi.org/10.3390/s22249830
Chicago/Turabian StyleRomero-Lugo, Alexandra, Andrea Magadan-Salazar, Jorge Fuentes-Pacheco, and Raúl Pinto-Elías. 2022. "A Comparison of Deep Neural Networks for Monocular Depth Map Estimation in Natural Environments Flying at Low Altitude" Sensors 22, no. 24: 9830. https://doi.org/10.3390/s22249830