1. Introduction
A railway comprises ballasts, sleepers, rails, and fasteners. Each component plays an important role, among which the rail fasteners can fasten the rail tracks to the sleepers and have a buffering effect to disperse the weight, which can slow down the disturbance of the rails so that the rails can be stably fixed on the rail tracks. Damaged or dropped fasteners may derail the train, so track inspection is among the essential work items.
Current track inspection is conducted manually and divided into foot and vehicle inspections. The inspection personnel inspect the track visually and record any damage in paper form, then send maintenance personnel to fix it. In May 2021, the Taiwan Railway Administration (TRA) used a mobile phone APP [
1] to replace the traditional paper record to enhance the efficiency and reliability of rail route inspection. The digitization of inspection data reduces the likelihood of records being lost. However, it does not prevent human errors, and only the first version of Android has been developed for track inspectors to test.
Moreover, because the human eye way inspection is limited to the human visual inspection angle, inspection speed cannot be too fast so that the naked eye can see clearly. During foot inspection, the person must also beware of passing trains to avoid collisions. The cost of in terms of manpower and time is very high to complete inspection. Given the current workforce of the railway station, inspection can only be performed once a week. If the frequency of inspection is increased, this may cause the inspection staff to be overworked and even less able to inspect carefully. This also makes the transportation and security of the TRA impossible to be effectively refine. In order to improve the efficiency of patrol inspection, a real-time identification system for defective track components is developed based on computer vision to improve the inspection problem effectively.
In recent years, there has been much research on detecting track defects. We want to use artificial intelligence to carry out automatic detection, focusing on improving accuracy and real-time computing. If the recognition rate and stability can be higher than manual inspection, it can replace the current manual inspection to improve the efficiency of rail inspection. By comparing the current commercial patrol equipment products,
Table 1 shows that most of them are measuring geometric property of track and components when the types of track components are pretty diverse. Moreover, because the whole equipment is quite expensive, only a very few copies of the systems can be purchased for a track operator. For example, there is only one automatic track inspection system running for Taipei Mass Rapid Transit and one track image recording system for the TRA. Due to the limited budget, there are few inspection vehicles, resulting in slow inspection efficiency.
An automatic detection system is emerging using computer vision technology to overcome the effort spent on human manual inspection of track defects. Two approaches have been developed for this task: traditional pattern recognition [
7] and deep neural networks [
8,
9] based. The former approach first identifies the features that effectively classify defective track components from standard track components. Additionally, then a recognition engine was developed such as a classification tree [
10], k-Near Neighbor (k-NN) [
11], Support Vector Machine (SVM) [
12], and neural network (NN) [
13]. Recently, the deep learning-based approach has gained much attention for the impressive advance in object recognition and object detection. With the rapid computation provided by the graphic processing unit, the time spent is significantly reduced and could be deployed in real-world applications. Therefore, this work adopts the deep learning-based approach for rail track safety inspection.
Training deep learning neural networks needs a certain number of datasets to produce good identification results. However, the defective component images are not easy to obtain, so the number of images for the seriously damaged components can only be limited to less than ten. Therefore, this study needs to overcome the difficulties in data collection. Data augmentation methods such as resizing, rotation, and translation could be used to enlarge the dataset to obtain possible images in the actual situation. This research will use the manual treatment to generate the cracks on the regular rail by repairing the image, but the manual treatment can only produce a small amount of data. Thus, a Generative Adversarial Network (GAN) [
14] is used to automatically generate the rail fracture dataset, as far as possible, to expand the data and to achieve good training results.
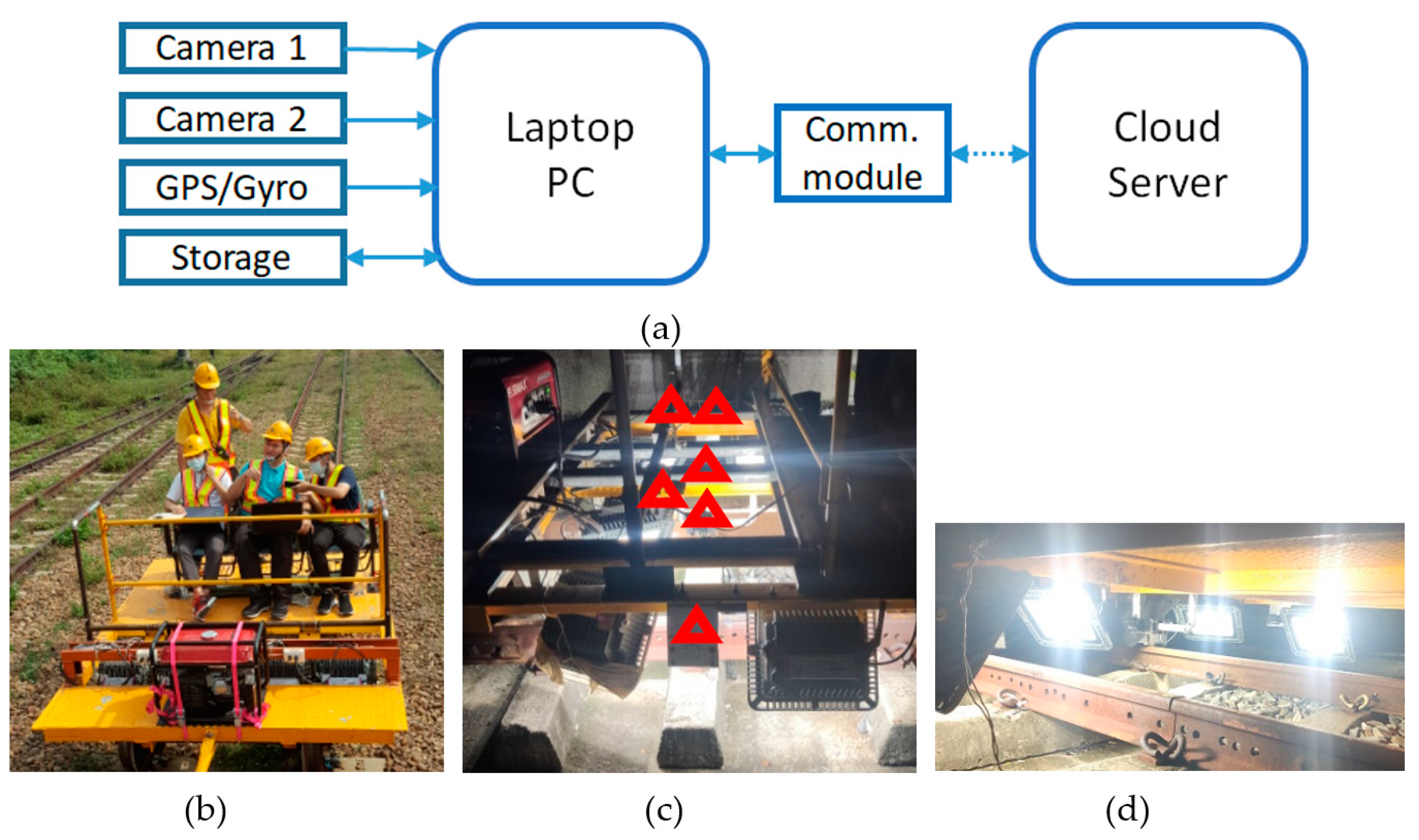
In this study, we want to develop a real-time identification system for rail defect components with good identification accuracy and relatively low cost using object detection and identification methods. GoPro (It is based in San Mateo, CA, USA. GoPro, Inc. Woodman Labs, Inc. U.S.) Hero8 Black and GoPro Hero7 Black motion cameras are used to capture images. Motion cameras have sound shock-resistant processing and high frames per second (FPS). Then, deep learning-based object detection is trained to identify defective track fasteners automatically. This study divides rail inspection into two modes: overhead and side inspection. The two models are trained separately. The complete fastener defect categories are also built from the two perspectives. Using the multi-thread technique, the computer can process the image transmitted by two cameras in real time. Our goal is to develop an automatic real-time identification system that can replace the present manual inspection, keep a reasonable accuracy rate to reduce the cost of inspection staff effectively, and improve the overall efficiency of inspection.
This study is divided into five sections. This section is an introduction to the motivation and background of the research and the research objectives and difficulties. The
Section 2 is the literature review, divided into three parts. The first part introduces the current situation of rail track inspection; the second part will compare the differences between this study and other related studies; the third part introduces the AI identification model used in this research. In the
Section 3, the system architecture is described in detail. Firstly, the system is designed and constructed, and includes a real-time defective component identification neural network model, two high-speed cameras, a GPS inertial navigation device, and a flat patrol car. The number of classes for the regular and defective rail components and the collected datasets for each class are described. The experimental results and analysis are presented in detail in the
Section 4. The identification results of different neural networks are compared, and field tests verify the feasibility of the whole system. The
Section 5 is the conclusion and prospects of this study.
2. Related Works
The vehicle wheels can apply vertical, lateral, and creep loads to the rails, while bulk stress, such as bending stress, thermal stress, and residual stresses, can also be applied to the rails. Different rail defects such as rail corrugations, rolling contact fatigue defects, squat defects, shatter cracking, split head, and wheel burns have their causes and characteristics, lead to different effects, and thus require corresponding treatments [
15]. Defects and deteriorated conditions on the rail track can normally be seen by human eyes; therefore, manual inspection by patrollers can identify and locate the defects and monitor the condition. However, such inspections are labor intensive and can only be arranged during non-operating hours in order not to disrupt the regular service operations. Rail inspection vehicle and sensor technologies are being deployed as an efficient and cost-effective data collection technology solution to support rail maintenance operations and can capture vast amounts of data. Data-driven automatic condition monitoring and detection and classification of rail track anomalies have been attracting attention from researchers at universities and railway institutes.
Ma et al. [
16] proposed a switched median filter coupled with improved Canny edge detection to extract the features of fastener edges. Due to the fastener’s fixed shape, the defective fastener’s contour differs from that of the standard fastener and the real-time missing identification could be carried out. The final fastener identification rate was 85.8%, and the average processing time was 245.61 ms. Gibert et al. [
17] proposed a method for fastener detection by (1) carefully aligning the training data, (2) reducing intra-class variation, and (3) bootstrapping complex samples to improve the classification margin. The system can inspect ties for missing or defective rail fasteners using the histogram of oriented gradient as features and classified by a combination of linear SVM classifiers. The detection rate is 98%, and the false alarm rate of 1.23% on a new dataset of 85 miles of concrete tie images collected in the US Northeast Corridor.
Stella et al. [
18] used wavelet transform and principal component analysis for fastener image pre-processing and employed a neural network classifier to detect defective hook-shaped fasteners. The AdaBoost algorithm was used by Li et al. [
7] and Xia et al. [
19] for detecting fasteners from rail images. In recent years, the application of deep learning methods for rail track inspection has gained significant importance due to the increase in computing power and the development of graphical processing units (GPU). Deep learning methods are producing success in various applications with recent technological advances. Deep learning has neural networks as its functional unit to mimic how the human brain solves complex problems based on data. Convolutional neural networks (CNN) [
20] and object detection neural networks such as You Only Look Once (YOLO) [
21] propelled the development of deep learning, which has been reported with convincing performances for rail track monitoring and anomaly detection. The performances in the prediction and learning of these methods are improving with the increasing amount of data available [
22].
According to the review on deep learning approaches for rail track condition monitoring [
9], the authors find research works published from 2013 to 2021. In total, they identified 62 relevant research publications to review. The trend over time indicates that the rail industries are adopting deep learning methods with growing interests. As for the detection/localizing/classification targets, it is observed that rail surface defects including various components (rail, insulator, valves, fasteners, switches, track intrusions, etc.) are the most common items. As for the deployed deep learning models, many deep learning models are adopted by researchers. Ji et al. [
9] summarizes the distribution of deep learning models. CNN is the most popular one being adopted that results using ResNet [
23,
24] and LSTM [
25]; however, many researchers created their own structure [
26] or divided their tasks into a few stages such as SSD + VGG [
27] and Faster RCNN + CNN [
28]. Some deep learning methods just adopted one-stage object detection such as YOLOv2 [
29], YOLOv3 [
30], and YOLOv5 [
31]. The effectiveness and the results differ from each other depending on the tasks.
Various deep learning methods are reported to produce promising results for rail track condition monitoring. However, there is a consistent process flow [
9] for these deep learning methods. First, how to capture the raw image is the most critical step, which requires the installation of cameras/recording devices on rail maintenance vehicles. Second, the raw image data are transmitted to the image processing subsystem for pre-processing such as resizing, noise removal, or enhancement. Third, the collected images are labeled accordingly by the experts of rail workers to build the dataset. Fourth, the selected deep learning model is trained with the randomly selected training data and validated by the testing data. Depending on the selected strategy, a one-stage deep learning model could perform classification directly, or multi-stage deep learning methods require localization tasks for track components and then a classification task. It is also possible to perform localization and classification concurrently. Fifth, the trained deep learning model is put in operation with the trained parameters for real-world applications. Due to the criticality of rail track inspection, double checking the recorded rail track images by human operators is necessary to confirm the system accuracy. Finally, the efficiency and effectiveness of the deep learning models are reviewed and enhanced for improved performances.
Still, there is a key problem that needs to be addressed—the lack of images of the defective rail track component. The nature of rail operations causes the data distribution of defective rail track to be disproportionate, which could cause class imbalance problems in deep learning applications. Data augmentation is often used to produce more training data by resizing, rotating, and translating the original dataset. However, some gaps exist between the real image and the augmented one.
In this research, we follow the general process flow to construct a real-time online rail track inspection system by the one-stage approach. Online means the captured image is immediately transmitted to the recognition engine for defective component detection, unlike offline recognition, where the recognition engine works at the backend server. The recorded video is sent to the server when the whole rail segment is finished checking. The significant contribution of our research work is that we encapsulate the recognition engine as a parallel running process waiting to process received images. The second contribution is using the latest version of object detection models YOLOv4 and YOLOX for one-stage detection of defective components. Due to the lack of image data of defective components, the third contribution is using GAN for data augmentation, which could generate image data close to real ones. The last contribution but not the least, is the classification of defective rail components into two categories. There are ten defects covering fasteners, rail surfaces, and sleepers from the upward and six defects about the rail waist and fishplate from the sideward.
4. Experimental Results and Analysis
Section 4.1 presents the training results and comparison of each neural network model in this study in detail.
Section 4.2 gives the results of the field test of the real-time identification system of this study to verify its feasibility. The last section carries out the cost calculation of this system.
4.1. AI Model Training
The training environment of this study uses a self-assembled personal computer with an AMD Ryzen 7 2700X processor, a GeForce RTX 2080Ti graphics card, and 16G memory. We compare five neural network models, namely YOLOv4, YOLOv4-Tiny, YOLOX-Tiny, SSD512, and SSD300. The neural network model used in the real-time recognition system must have a reasonable recognition rate and recognition speed to avoid frame loss. The reference indicators for comparison are mAP, the recall rate, precision, and FPS.
The evaluation Index of the AI model is mainly focused on the confusion matrix. TP (True Positive) means that the prediction is positive and the ground truth is also true. TN (True Negative (TN) means that the prediction is negative and the ground truth is true. FP (False Positive) means the prediction is positive, but the ground truth is false. FN (False Negative) means that the prediction is negative and the ground truth is positive. Precision is the ratio (TP/TP + FP) that is predicted to be positive and is positive. The recall rate means the ratio (TP/TP + FN) that is positive and is indeed predicted as positive. The mAP is the average of all category Aps. As for AP, it is the area covered by precision and the recall rate under different confidence values (precision-recall curve).
4.1.1. YOLOv4 and YOLOv4-TinyModel Training
In this experiment, the YOLOv4 model is trained with 12,000 epochs. The total time for top-view training was approximately 11 h, and the side-view training took approximately 9 h. The training of YOLOv4-Tiny has 12,000 iterations, the total time for top-view training is approximately 4 h, and the side-view training takes approximately 3 h. The amount of top-view training data used is 3800, and the amount of side-view training data is 967. Before training, it is necessary to mark all the components in the image. This study uses LabelImg [
40] data labeling tool, as shown in
Figure 9. When marking the defective components, the marking scope will also be extended to the peripheral sleepers and a part of the rail surface.
There are ten types of top-view data in this study. At first, the result of the first version of YOLOv4 training was 82% precision, a 95% recall rate, and 83.16% mAP. The first version of YOLOv4-Tiny training results has a precision of 82%, a recall rate of 96%, and an mAP of 90.77%. Among them, the results of precision and mAP are not ideal, and it was found that the main reason is that there are too many FPs. Most of these FPs are standard components that were misjudged as defective. Therefore, this study added all misjudged test data to the training set during the second version of the training and relabeled these data as background data.
Moreover, review all markup data to avoid markup inconsistencies. Retrain the neural network to reduce the chance of misjudgment. After this adjustment, the mAP of YOLOv4 top-view training results increased to 94.47%, the precision increased to 94%, and the recall rate increased to 91%. YOLOv4-Tiny training results mAP increased to 91.66%, precision increased to 92%, and recall rate was 91%. Among them, the recall rate has slightly decreased because, in the data of the minor defect category of the E buckle clip, the displacement of the buckle clip is less clear. The dataset will be continuously updated to improve this situation. The performance comparison between the first version and the second version for YOLOv4 and YOLOv4-Tiny is shown in
Table 7 and
Table 8, respectively. It can be seen from the training process that the loss has continued to decline while the mAP has continued to rise. The confusion matrix for each category is shown in
Table 9 and
Table 10.
Figure 10 is an example of the recognized defective components in the top view.
This study’s first version of side-view track component detection by the YOLOv4-Tiny neural network model was trained with the side-view dataset. Only four missing categories are used for training. The training result mAP is 99.00%, precision is 100%, and the recall rate is 99%. The data seems to be good. However, there are too many false positives in the actual test, and almost all the welds in the entire rail are regarded as weld fractures. Therefore, this study added two categories of normal welding and regular fishtail in the second edition of training to reduce the misjudgment of the actual test. The result of YOLOv4 training mAP is 99.24%, precision is 97%, and the recall rate is 95%. The YOLOv4-Tiny training result mAP is 99.16%, precision is 96%, and the recall rate is 94%. The overall mAP has also continued to rise. After the actual test, the misjudgment of the whole video also dropped a lot. The detailed confusion matrix of each category is shown in
Table 11 and
Table 12. Observing the data in the table, we can find that the number of FPS with fractured welds is still not zero, and these are regular welds that have been misjudged as weld cracks. In the future, these misjudged data will continue to be added back to the training dataset to improve the overall recognition rate as much as possible. In addition, there are multiple FNs at the regular welds, and these FNs are because the side rails will be captured together with the rear rails when shooting. However, the welding image on the rear track is too small to be recognized by the neural network, as shown in
Figure 11.
Figure 12 shows some examples of side-view defective track component identification.
4.1.2. YOLOX-Tiny Training
For comparison with the YOLOv4-Tiny neural network, the same dataset was used for training. The original dataset is allocated 80% as the training set and the other 20% as the test set. The top-view training iterates 3000 times and takes approximately 72 h in total. The number of iterations of side-view training is 3000 times, and it takes approximately 30 h in total. The overall training time of YOLOX-Tiny is relatively long. The mAP of the top view training is 85.22%, the precision is 83%, and the recall rate is 78%. The result of side-view training is that the mAP is 75.26%, the precision is 89%, and the recall rate is 77%. The comprehensive data of YOLOX-Tiny is not ideal. The detailed confusion matrix of each category is shown in
Table 13 and
Table 14.
On examining all the incorrectly identified pictures, it was found that FN and FP mostly appear in blurred or rotated and toned pictures, as shown in
Figure 13a. Photos of this type account for a relatively small percentage of all datasets. It is inferred that the recognition performance may be degraded due to the lack of such data. Therefore, we redistribute the dataset, setting 90% of the photos as the training set and 10% as the test set. Retrain the model using the same number of iterations. The top-view result of this training was 86.87% mAP, 92% precision, and a 82% recall rate. The mAP of the side-view result is 97.55%, the precision is 99%, and the recall rate is 99%. The overall performance has increased significantly; the comparison is shown in
Table 15. Although the YOLOX-Tiny neural network model is relatively low in data, it can effectively identify far and small objects. For example, the side-view rail and the rear rail will be included in the shot. The welds on the rear track can also be identified by YOLOX-Tiny, as shown in
Figure 13b.
4.1.3. SSD Training
This study also compares the SSD neural network with the YOLOv4-Tiny neural network. The same dataset is used for training and testing during training. On the training data, SSD adopts the VOC data format. During the initial training, it was found that the training speed was slow, and it was found that the overall training speed was slowed down when the picture was resized. Therefore, before training, this study takes image pre-processing and resizes all images (416 × 416) to reduce the overall training time. The top-view training time SSD512 takes approximately 48 h, the precision is 90%, the mAP is 91.10%, and the recall rate is 89%. The SSD 300 took approximately 24 h, the precision was 93%, the mAP was 91.20%, and the recall rate was 96%. Detailed top-view training results are shown in
Table 16.
The side-view training time for SSD512 takes approximately 48 h, the precision is 91%, the recall rate is 95%, and the mAP is 99.98%. The SSD 300 took approximately 24 h, the precision was 92%, the recall rate was 94%, and the mAP was 99.49%. The detailed training results of the side view are shown in
Table 17.
4.1.4. Comparisons of the Neural Models
Table 18 compares the results of top-view training, and
Table 19 compares the results of side-view training. From the perspective of the recall rate, SSD300 will be a better choice. From the perspective of precision and mAP, YOLOv4 is the better choice. However, from the comparison table, it can be found that YOLOv4-Tiny is not inferior to other neural network models. In the side view training results, the precision of YOLOv4-Tiny is 7% higher than that of SSD512. In addition, this research advocates a real-time identification system, so in addition to considering various data, the identification speed (FPS) is also essential.
Based on the above data, YOLOv4-Tiny has an excellent performance in various data indicators. Moreover, the recognition speed is 3~7-fold higher than other neural networks. Therefore, this research considers speed without losing accuracy and finally chooses YOLOv4-Tiny as the neural network model used in the real-time identification system of this research.
4.2. Field Test Results
This study conducts field AI detection of the rail track component on the East–West Main Line between Taichung Port Station and Qingshui Station and conducts mutual verification with human detection. First, the defective component needs to be fabricated. Due to the difficulty in producing defective components, it is impossible to produce all defect categories. Therefore, the top-view defect components are mainly the severe defect of the e-clip, while the side-view defect components are mainly the cracks of the rail and the falling off of the fishplate bolts. Moreover, because it is impossible to create natural rail cracks, the cracks on the rail side of the rail were simulated with a marker pen, aluminum tape, and black tape. The simulated crack images were discussed with the personnel of Dajia Railway Station in advance, and they are all similar to the actual rail crack images, as shown in
Figure 14. A total of 32 artificial markings were made by hand, including 13 severely missing(XX) e-Clips, one fishtail plate bolt falling off, and 18 simulated rail cracks.
A total of 13 top-view defective components were artificially fabricated. AI detected 14, and the detection rate was 14/13 = 107%. Manual foot inspections found 15. Although AI patrol inspection is less than manual foot inspection by one, the overall time and human resources spent are relatively much less. In the future, we will continue to increase the dataset to reduce misjudgment. The detailed fault track component detection is shown in
Table 20.
A total of 19 side-view defect track components were manually fabricated. The AI detected eight, and the human visual inspection by walking detected five. The defective components that AI cannot detect are all images of simulated broken rails on, such as rail head, rail belly, and rail bottom, as shown in
Figure 15. The failure to detect is because the features of these simulated broken tracks are too small, so the images of these broken tracks cannot be captured. Because of this, AI cannot detect it correctly. AI can correctly detect other prominent simulated broken rails. The overall AI detection is also three more than the manual detection on foot. The details are shown in
Table 21.
4.3. Robustness Test
To validate the robustness of the proposed defective rail track classification system, we collected another track dataset of mass rapid transportation that differed from the previously used dataset. The total number of images in the training dataset was 528, and the number of defect categories was five. During the training stage, YOLOv4 took approximately 10 h for 12,000 iterations, while YOLOv4-Tiny took approximately 3 h for the same number of iterations.
After testing, as shown in
Table 22, we obtained a 97% precision rate, a 96% recall rate, and 97.3% mAP for YOLOv4. On the other hand, we obtained a 98% precision rate, a 94% recall rate, and 97.5% mAP for YOLOv4-Tiny. Although the mAP and precision rate of YOLOv4-Tiny are good, the recall rate is lower than for YOLOv4. The reason is that there are too many false negatives, and there is a slight overfitting phenomenon. In this test, we successfully demonstrated that the proposed methodology using YOLOv4-Tiny is quite robust. The performance indexes are all over 90%, which could be deployed for various track applications.
5. Conclusions
In this study, five neural network models were compared, namely YOLOv4, YOLOv4-Tiny, YOLOX-Tiny, SSD512, and SSD300. After considering precision, the recall rate, mAP, and FPS, YOLOv4-Tiny was finally selected as the neural network model used in this real-time recognition system. Since the railway track is not open to the outside world, it is challenging to collect damaged samples, which also leads to insufficient data for some defect categories in training. In this regard, this study uses data augmentation methods to increase the diversity of data as much as possible using rotation and grayscale. In the side-view data, Cycle Gan is also used to automatically generate images of track cracks to avoid overfitting as much as possible due to insufficient training data.
This system uses a GoPro camera to capture images. We used the multi-process method to write programs and execute three processes concurrently. The recognition results are packaged object oriented so that the system can quickly access data. Combined with the flat maintenance car, real-time identification can be performed at approximately 30 km/h. Moreover, inertial navigation can locate the position of defective components. This system will integrate all the identification results into an excel report and record the storage location of the identification results, 100 m piles, and photos of defective components in detail so that users can view them in real time. While maintaining a reasonable recognition rate, the efficiency of track inspection is greatly improved. Furthermore, it can have lower costs and a safer maintenance environment compared with manual inspection.
Collecting the image data of track defects required in this study is difficult. Although multiple defective component data have been generated through methods such as data enhancement or Cycle GAN, the same photo is still used for rotation and grayscale. There is a slight improvement in overall data richness. In the future, we plan to cooperate with the Taiwan Railway branches in various counties and cities to obtain more missing component data to increase the dataset required for training.
The inertial navigation module used in this research can work in a short tunnel within 500 m, and the positioning error can be less than 10 m. However, since the inertial navigation error will accumulate over time, the positioning error will also increase when encountering a long tunnel. In the future, we hope to find an inertial navigation module with automatic correction or use the track map information provided by the Taiwan Railway Administration to perform positioning correction. This system directly uses a high-performance notebook computer for real-time identification. We want to use lighter neural network models and embedded systems, such as TX2 or Xavier, for real-time recognition. This progress can make the process more convenient to users.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













