
Real-Time Φ-OTDR Vibration Event Recognition Based on Image Target Detection



Abstract
:1. Introduction
2. Baseline System
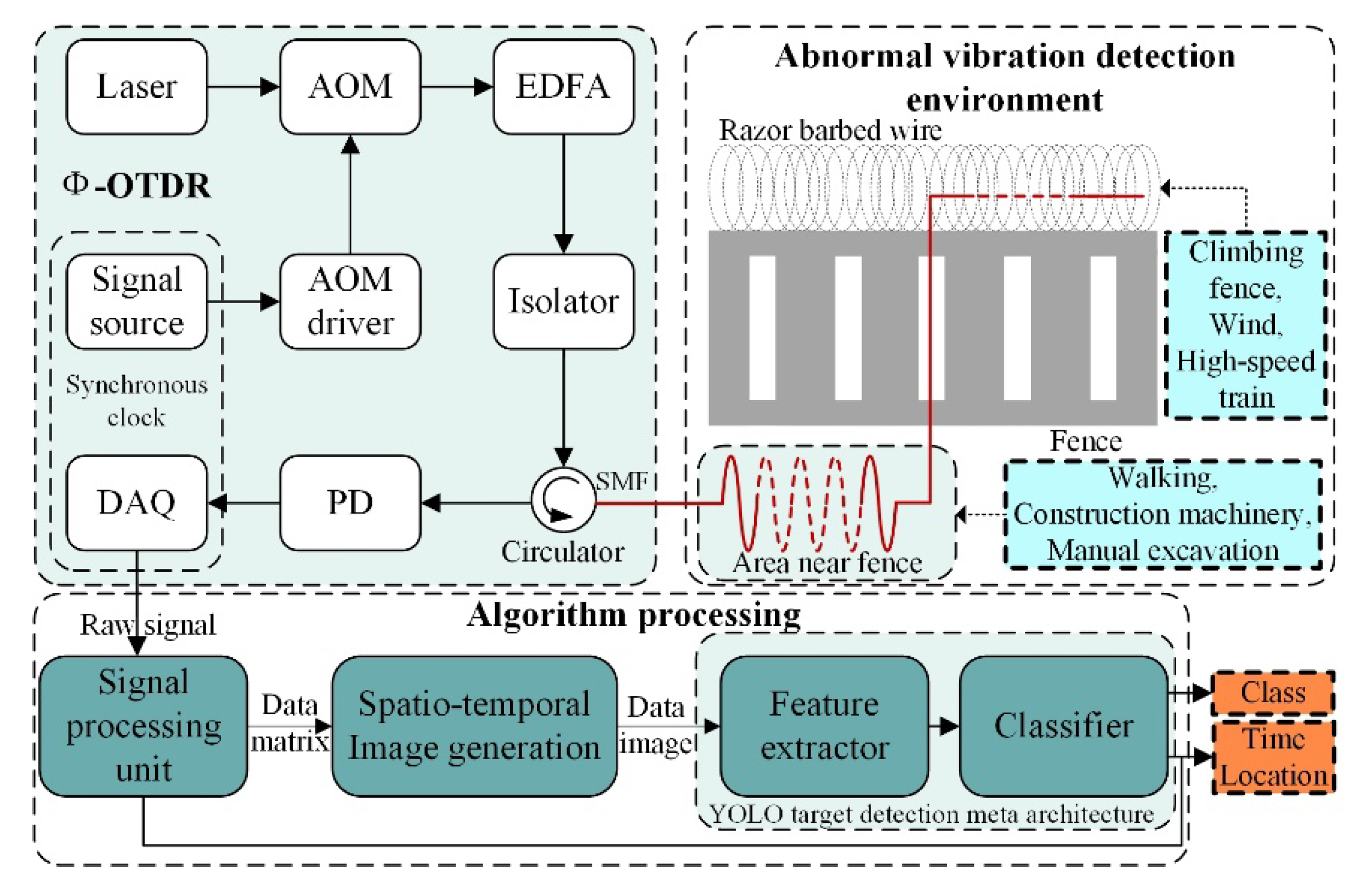
2.1. System Overview
- The original digital signal is processed by the signal processing unit to accomplish pulse accumulation, pulse cancellers, maximum value processing to generate the primary data matrix, and then determine the location of the vibration signal appearing on the detection fiber and the corresponding time according to the statistical detection principle;
- On this basis, the data matrix is converted into grayscale images and then processed by median filtering and pseudo-color to generate the final spatio-temporal image of vibration data to be detected;
- The images are detected by the improved YOLO target detector, which first completes the multi-scale feature conversion by the feature extraction network, then uses the classifier to achieve the detection of multiple vibration targets in a single image, and eventually improves the detection accuracy and reduces the false-alarm rate of the system.
2.2. Φ-OTDR Raw Signal Statistical Characteristics
3. Raw Signal Pre-Processing and Image Generation
3.1. Analysis of Vibration Detection Principles
3.2. Signal Pre-Processing Procedure
3.3. Median Filtering and Pseudo-Color Processing
3.4. Vibration Data Collection
4. Experimental Image Dataset and Methodology
4.1. Image Data Augmentation
4.2. Dataset Generation
4.3. Target Detection Meta-Architecture Analysis
- Backbone and Neck are the most dominant feature extraction networks of the model, and these parts extract feature maps at different scales by linear and nonlinear operations;
- The detection Head contains multiple scales to be detected, the number of which depends on the number of different scales of the feature map after the aforementioned downsampling feature extraction, and the feature map width and height on each scale depends on the number of times the original spatio-temporal image has been downsampled;
- The loss function defined by the YOLO detector includes three types of loss values: target confidence loss, localization loss [36,37], and classification loss. The difference between system detection results and prior knowledge in target detection and localization can be judged by these three types of loss scores.
4.4. Network Construction
4.5. Evaluation Metrics
5. Experimental Procedure
5.1. Experimental Setup
- The YOLO target detection models composed of different feature extraction networks are trained using the training set, the training effect is tested using the validation set, and the optimal model in each type is selected; the performance metrics of the selected models in each type as described in Section 4.5 are measured using the test set, and the one with a better balance of various metrics is chosen as the final improved model;
- Various combinations of vibration type data in the test set are selected to simulate different mixed vibration activities to test and discuss the qualitative detection results of the final improved model;
- The metrics of the final improved model and other SOTA models arere counted using the test set and comparisons are made.
5.2. Network Training
5.3. Qualitative Results
5.4. Comparison with Other State-of-the-Art Models
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Juarez, J.C.; Maier, E.W.; Kyoo Nam, C.; Taylor, H.F. Distributed fiber-optic intrusion sensor system. J. Lightwave Technol. 2005, 23, 2081–2087. [Google Scholar] [CrossRef]
- Juarez, J.C.; Taylor, H.F. Field test of a distributed fiber-optic intrusion sensor system for long perimeters. Appl. Opt. 2007, 46, 1968–1971. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.N.; Zeng, J.J.; Li, J.; Fan, M.Q.; Wu, H.; Peng, F.; Zhang, L.; Zhou, Y.; Rao, Y.J. Ultra-long phase-sensitive OTDR with hybrid distributed amplification. Opt. Lett. 2014, 39, 5866–5869. [Google Scholar] [CrossRef] [PubMed]
- Bao, X.; Zhou, D.P.; Baker, C.; Chen, L. Recent Development in the Distributed Fiber Optic Acoustic and Ultrasonic Detection. J. Lightwave Technol. 2017, 35, 3256–3267. [Google Scholar] [CrossRef]
- Peng, F.; Wu, H.; Jia, X.-H.; Rao, Y.-J.; Wang, Z.-N.; Peng, Z.-P. Ultra-long high-sensitivity Φ-OTDR for high spatial resolution intrusion detection of pipelines. Opt. Express 2014, 22, 13804–13810. [Google Scholar] [CrossRef]
- Wu, H.; Qian, Y.; Zhang, W.; Tang, C. Feature extraction and identification in distributed optical-fiber vibration sensing system for oil pipeline safety monitoring. Photonic Sens. 2017, 7, 305–310. [Google Scholar] [CrossRef] [Green Version]
- Tejedor, J.; Martins, H.F.; Piote, D.; Macias-Guarasa, J.; Pastor-Graells, J.; Martin-Lopez, S.; Guillén, P.C.; Smet, F.D.; Postvoll, W.; González-Herráez, M. Toward Prevention of Pipeline Integrity Threats Using a Smart Fiber-Optic Surveillance System. J. Lightwave Technol. 2016, 34, 4445–4453. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Guan, J.; Bao, M.; Lu, J.; Ye, W. Pattern recognition based on time-frequency analysis and convolutional neural networks for vibrational events in φ-OTDR. Opt. Eng. 2018, 57, 016103. [Google Scholar] [CrossRef]
- Tejedor, J.; Macias-Guarasa, J.; Martins, H.F.; Piote, D.; Pastor-Graells, J.; Martin-Lopez, S.; Corredera, P.; Gonzalez-Herraez, M. A Novel Fiber Optic Based Surveillance System for Prevention of Pipeline Integrity Threats. Sensors 2017, 17, 355. [Google Scholar] [CrossRef]
- Sun, Q.; Feng, H.; Yan, X.; Zeng, Z. Recognition of a Phase-Sensitivity OTDR Sensing System Based on Morphologic Feature Extraction. Sensors 2015, 15, 15179–15197. [Google Scholar] [CrossRef] [Green Version]
- Sun, Q.; Li, Q.; Chen, L.; Quan, J.; Li, L. Pattern recognition based on pulse scanning imaging and convolutional neural network for vibrational events in Φ-OTDR. Optik 2020, 219, 165205. [Google Scholar] [CrossRef]
- Shi, Y.; Wang, Y.; Zhao, L.; Fan, Z. An Event Recognition Method for Φ-OTDR Sensing System Based on Deep Learning. Sensors 2019, 19, 3421. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2016, arXiv:1512.02325. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Guo, F.; Qian, Y.; Shi, Y. Real-time railroad track components inspection based on the improved YOLOv4 framework. Autom. Constr. 2021, 125, 103596. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312, 740–755. [Google Scholar]
- Healey, P. Fading in heterodyne OTDR. In Electronics Letters; Institution of Engineering and Technology: London, UK, 1984; Volume 20, pp. 30–32. [Google Scholar] [CrossRef]
- Izumita, H.; Koyamada, Y.; Furukawa, S.; Sankawa, I. Stochastic amplitude fluctuation in coherent OTDR and a new technique for its reduction by stimulating synchronous optical frequency hopping. J. Lightwave Technol. 1997, 15, 267–278. [Google Scholar] [CrossRef]
- Fedorov, A.K.; Anufriev, M.N.; Zhirnov, A.A.; Stepanov, K.V.; Nesterov, E.T.; Namiot, D.E.; Karasik, V.E.; Pnev, A.B. Note: Gaussian mixture model for event recognition in optical time-domain reflectometry based sensing systems. Rev. Sci. Instrum. 2016, 87, 036107. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maini, R.; Aggarwal, H. A Comprehensive Review of Image Enhancement Techniques. arXiv 2010, arXiv:1003.4053. [Google Scholar]
- Zheng, D.; Da, F.; Kemao, Q.; Seah, H.S. Phase-shifting profilometry combined with Gray-code patterns projection: Unwrapping error removal by an adaptive median filter. Opt. Express 2017, 25, 4700–4713. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Lu, S.; Chen, J. Application of Pseudo-color Image Feature-Level Fusion in Nondestructive Testing of Wire Ropes. J. Fail. Anal. Prev. 2020, 20, 1541–1553. [Google Scholar] [CrossRef]
- Zhu, Q.; Zheng, H.; Wang, Y.; Cao, Y.; Guo, S. Study on the Evaluation Method of Sound Phase Cloud Maps Based on an Improved YOLOv4 Algorithm. Sensors 2020, 20, 4314. [Google Scholar] [CrossRef]
- Peng, F.; Duan, N.; Rao, Y.; Li, J. Real-Time Position and Speed Monitoring of Trains Using Phase-Sensitive OTDR. IEEE Photonics Technol. Lett. 2014, 26, 2055–2057. [Google Scholar] [CrossRef]
- Meng, H.; Wang, S.; Gao, C.; Liu, F. Research on Recognition Method of Railway Perimeter Intrusions Based on Φ-OTDR Optical Fiber Sensing Technology. IEEE Sens. J. 2021, 21, 9852–9859. [Google Scholar] [CrossRef]
- Ghiasi, G.; Lin, T.-Y.; Le, Q.V. DropBlock: A regularization method for convolutional networks. arXiv 2018, arXiv:1810.12890. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:1911.08287. [Google Scholar] [CrossRef]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Swish: A Self-Gated Activation Function. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fiber Optic Laying Method | Activity | Activity Simulation | Amount of Collected Data | Collection Location | Duration of a Collection | Total Data Amount with Data Augmentation | Alarm Type |
|---|---|---|---|---|---|---|---|
| Optical fiber cable buried underground | Construction machinery | Pneumatic hammer | 1357 | 0–1 km | 3–6 s | 2714 | Early Warning |
| Manual excavation | Shovel type construction | 1051 | 0–1 km | 3–6 s | 2102 | Early Warning | |
| Walking | People walking within the warning area nearby the fence | 137 | 0–1 km | 3–15 s | 819 | Early Warning | |
| Optical fiber cable hung on razor barbed wire | Climbing over fence | Shaking Razor Barbed Wire | 200 | 1–5 km | 5–18 s | 798 | Real-time alarm |
| Airflow | Natural wind or high-speed rail passing by | 1636 | 1–5 km | Variable | 1636 | False alarm |
| Model | Backbone | Neck | Head | Number of Convolutional Layers | ||||
|---|---|---|---|---|---|---|---|---|
| Focus | ResBlock | CSPNet | SPP block | FPN | PANet | YOLO | ||
| YOLOV3-tiny | √ | √ | 13 | |||||
| YOLOV3 | √ | √ | √ | 52 | ||||
| YOLO-RP | √ | √ | √ | 30 | ||||
| YOLO-RCP | √ | √ | √ | √ | 30 | |||
| YOLO-A30 | √ | √ | √ | √ | √ | √ | 30 | |
| YOLO-A78 | √ | √ | √ | √ | √ | √ | 78 |
| Model | Class | Precision (%) | Recall without Airflow (%) | F1 (%) | [email protected] (%) | mAP@[.5:.95] (%) | Parameters (MB) | Inference (ms) |
|---|---|---|---|---|---|---|---|---|
| YOLOV3-tiny | All | 91.6 | 99.6 | 95.1 | 95.4 | 59.9 | 17.4 | 1.3 |
| Construction machinery | 98.2 | 99.0 | 98.6 | 99.4 | 58.1 | |||
| Manual excavation | 99.0 | 99.2 | 99.1 | 99.6 | 58.1 | |||
| Walking | 99.4 | 100.0 | 99.7 | 99.5 | 75.2 | |||
| Climbing fence | 99.5 | 100.0 | 99.7 | 99.6 | 69.4 | |||
| Airflow | 62.0 | 75.2 | 78.8 | 38.9 | ||||
| YOLOV3 | All | 98.6 | 99.7 | 99.1 | 99.4 | 68.3 | 123.5 | 6.2 |
| Construction machinery | 97.2 | 99.0 | 98.1 | 99.3 | 62.8 | |||
| Manual excavation | 98.9 | 99.6 | 99.2 | 99.6 | 58.5 | |||
| Walking | 99.4 | 100.0 | 99.7 | 99.5 | 81.4 | |||
| Climbing fence | 99.3 | 100.0 | 99.6 | 99.5 | 71.1 | |||
| Airflow | 98.2 | 99.1 | 99.2 | 67.4 | ||||
| YOLO-RP | All | 96.7 | 99.7 | 98.0 | 98.8 | 68.6 | 20 | 1.8 |
| Construction machinery | 97.8 | 99.0 | 98.4 | 99.5 | 64.0 | |||
| Manual excavation | 100.0 | 99.8 | 99.9 | 99.6 | 59.8 | |||
| Walking | 99.4 | 100.0 | 99.7 | 99.5 | 82.3 | |||
| Climbing fence | 99.9 | 100.0 | 99.9 | 99.6 | 73.2 | |||
| Airflow | 86.4 | 91.9 | 95.8 | 63.5 | ||||
| YOLO-RCP | All | 97.0 | 99.8 | 98.1 | 98.9 | 68.2 | 17.8 | 1.7 |
| Construction machinery | 97.6 | 99.4 | 98.5 | 99.5 | 63.5 | |||
| Manual excavation | 99.6 | 99.8 | 99.7 | 99.5 | 60.5 | |||
| Walking | 99.4 | 100.0 | 99.7 | 99.5 | 82.2 | |||
| Climbing fence | 98.8 | 100.0 | 99.4 | 99.5 | 71.7 | |||
| Airflow | 89.7 | 93.2 | 96.1 | 63.3 | ||||
| YOLO-A30 | All | 99.2 | 99.8 | 99.2 | 99.5 | 69.3 | 14.4 | 1.8 |
| Construction machinery | 98.8 | 99.4 | 99.1 | 99.5 | 62.5 | |||
| Manual excavation | 99.5 | 99.6 | 99.5 | 99.4 | 59.3 | |||
| Walking | 99.6 | 100.0 | 99.8 | 99.5 | 83.5 | |||
| Climbing fence | 99.6 | 100.0 | 99.8 | 99.6 | 71.7 | |||
| Airflow | 98.7 | 97.8 | 99.4 | 69.6 | ||||
| YOLO-A78 | All | 98.8 | 99.7 | 99.1 | 99.5 | 69.4 | 16.4 | 2.3 |
| Construction machinery | 98.6 | 99.7 | 99.1 | 99.6 | 61.6 | |||
| Manual excavation | 99.0 | 99.2 | 99.1 | 99.5 | 59.6 | |||
| Walking | 99.5 | 100.0 | 99.7 | 99.5 | 82.3 | |||
| Climbing fence | 99.5 | 100.0 | 99.7 | 99.5 | 73.4 | |||
| Airflow | 97.6 | 98.2 | 99.2 | 70.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, N.; Zhao, Y.; Chen, J. Real-Time Φ-OTDR Vibration Event Recognition Based on Image Target Detection. Sensors 2022, 22, 1127. https://doi.org/10.3390/s22031127
Yang N, Zhao Y, Chen J. Real-Time Φ-OTDR Vibration Event Recognition Based on Image Target Detection. Sensors. 2022; 22(3):1127. https://doi.org/10.3390/s22031127
Chicago/Turabian StyleYang, Nachuan, Yongjun Zhao, and Jinyang Chen. 2022. "Real-Time Φ-OTDR Vibration Event Recognition Based on Image Target Detection" Sensors 22, no. 3: 1127. https://doi.org/10.3390/s22031127