1. Introduction
Since the 1990s, Automatic Target Recognition (ATR) has been a very active field of study, given the diversity of its applications and the growing development of remote-sensing technologies [
1]. In this context, Synthetic Aperture Radar (SAR) appears to be an outstanding tool for producing high-resolution terrain images. Such sensors stand out for three reasons: (i) radar is an active sensor that provides its own illumination, which gives it the ability to operate in the dark; (ii) clouds and rain do not prevent the passage of electromagnetic waves at common radar operating frequencies; (iii) the radar energy backscattered by different materials allows a complementary detail for target discrimination [
2].
The human eye is conditioned to differentiate objects based on the reflection properties of sunlight wavelengths [
3]. In turn, SAR images are formed from the backscattering of electromagnetic microwaves and their interaction with the geometry and target material. However, although rich in details, the focused image is not friendly for human eye interpretation. To successfully address this problem, it is necessary to automate the process using an intelligent computer system.
SAR ATR algorithms can be divided into three basic tasks: Pre-screening, Low-Level Classifier (LLC), and High-Level Classifier (HLC), which can also be called Detection, Discrimination, and Classification, respectively [
4]. The detection task consists of extracting regions that may contain targets from an image that comprises the entire imaged area. Then, the detection output feeds the discriminator, which rejects spurious noises and clutter originating from natural and artificial formations that have characteristics different from those of the targets of interest. Finally, the classification task assigns a label that refers to the most likely class of each target candidate remaining from the discrimination task.
Over the last 30 years of research on target classification with SAR images, different approaches and algorithms have been proposed to maximize the Percentage of Correct Classification (PCC). In the literature, while some authors follow a taxonomy that separates the classification algorithms into template-based and feature-based [
3], others consider template-based and feature-based to be one and suggest instead model-based and semi-model-based categories [
4].
Regardless of the category of the algorithm, it is supported by features of three types: (1) Geometric features that describe the target by its area [
5,
6,
7,
8,
9], contour [
10,
11] or shadow [
11,
12]; (2) Transformation features that reduce the dimensionality of the target data by representing it in another domain such as Discrete Cosine Transform (DCT) [
13], Non-Negative Matrix Factorization (NMF) [
14,
15], Linear Discriminant Analysis (LDA) [
16] and Principal Component Analysis (PCA) [
17]; and (3) Scattering Centers Features which are based on the highest amplitude returns of the targets [
18] and based on a statistical distance, such as Euclidean [
19,
20,
21,
22,
23,
24,
25,
26], Mahalanobis [
27,
28,
29,
30], or another statistical distance [
31,
32,
33,
34,
35,
36,
37].
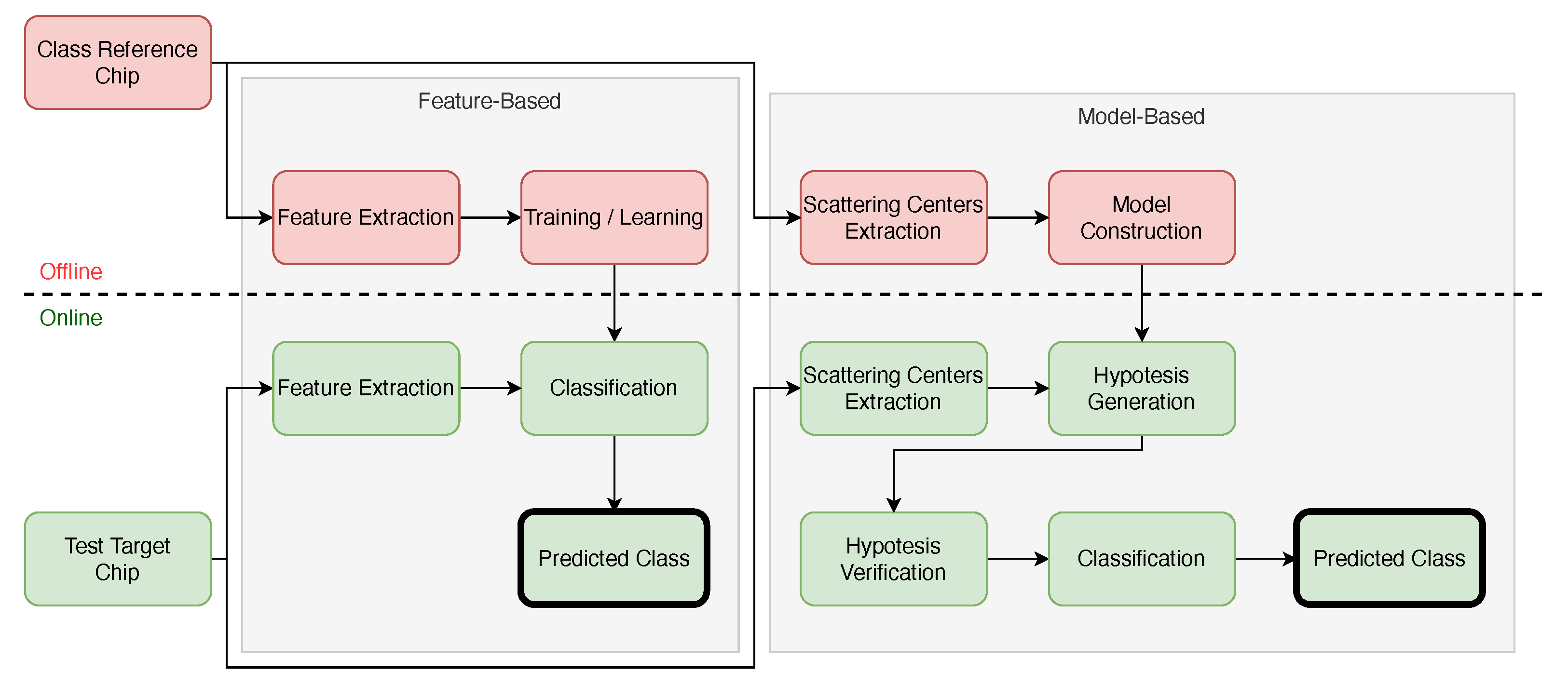
Feature-based algorithms are those with methods that run offline training supported exclusively by features extracted from the targets of interest. Among the methods employed by feature-based algorithms, we can highlight the following: Template Matching (TM) [
5,
6,
7,
11,
30,
37], Hidden Markov Model (HMM) [
12,
13,
22], K-Nearest Neighbor (KNN) [
27,
28], Sparse Representation-based Classification (SRC) [
8,
29], Convolutional Neural Networks (CNN) [
17,
18,
36,
38,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48], Support Vectors Machine (SVM) [
9] and Gaussian Mixture Model (GMM) [
10].
Model-based classifiers are distinguished from feature-based classifiers mainly by the approach adopted [
19,
20,
21,
23,
24,
25,
26,
31,
32,
33,
34,
35,
49]. Model-based classifiers try to find similarities in constructed models from the image, while feature-based classifiers start from a training task to find similarities in the image. Features are extracted from potential targets, and similarities are sought in the models using hypothesis testing [
4]. The tasks of a model-based classifier are performed in two steps: (i) offline construction of the class models and (ii) online prediction of the target class. During online classification, model-based methods rely on features extracted from the target candidates to generate hypotheses. Each hypothesis gives a score that assigns a target to a class from a class book. The scores are then compared, and the most likely class is identified.
Figure 1 illustrates the steps of both feature-based and model-based classifications.
Some model-based algorithms, prior to feature extraction, employ the Hungarian Algorithm [
23,
24,
29,
30,
31,
32,
33,
36] to assign each scattering center of the model to a scattering center of the target. Then, features are created for both the target and the models of each class.
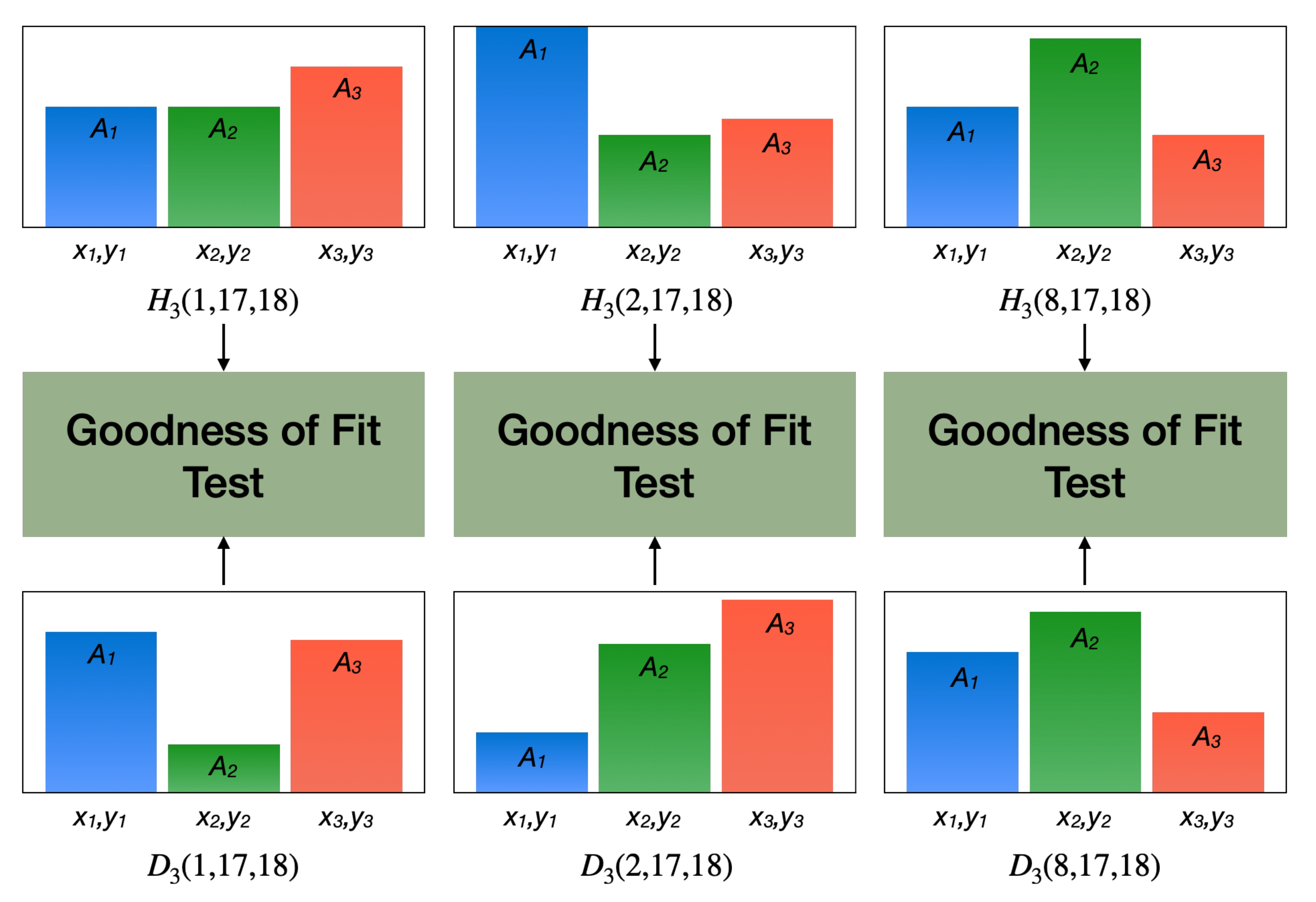
Ding and Wen [
32] used a statistical-based distance measure between pairs of scattering centers assigned by the Hungarian Algorithm to compute global similarity and triangular structures of scattering centers to identify local similarities, as shown in
Figure 2.
Shan et al. [
49] used morphological opening and closing operations to create Dominant Scattering Areas (DSA) in the original image. Subtracting the DSA of the test image from those of different classes of models resulted in the residues representing the differences between the test image and the classes. An example is presented in
Figure 3.
Fan and Thomas [
35] created masks by drawing circles centered on each scattering center of the target under test. The masks were then used by the Neighbor Matching Algorithm (NMA) to filter the scattering centers of each model class. This last approach, illustrated in
Figure 4, was implemented for comparison purposes with the proposed algorithm, and the results are presented in
Section 3.3.
Unlike these approaches, the proposed algorithm does not need to assign pairs of scattering centers or perform morphological or filtering operations; it is directly applicable, simple and fast, as the features are the scattering centers themselves.
This article proposes an approach to solve the problem of non-cooperative target classification in SAR images. It is taken as a premise that the targets are non-cooperative, i.e., they are not exposed frequently, so there are not enough SAR images of the targets to be used in a classification algorithm based on measured data. Therefore, the proposed approach considers only synthetic data to train the algorithm. Synthetic data, also known as simulated data, are generated through computer simulations. The most common way to produce synthetic data is by using asymptotic electromagnetic scattering prediction codes with the support of Three-Dimensional Computer-Aided Design (3D-CAD) [
40].
The proposed algorithm is model-based and uses scattering centers as features. The hypotheses were verified through a Modified Goodness of Fit (MGoF) test, consisting of a weighted GoF test. The algorithm was tested by varying the following parameters—the scattering center-extraction method, the hypothesis-generation method, and the GoF test—to determine the configuration that achieved the best performance under Standard Operating Conditions (SOCs). Moreover, the performance of the algorithm was also verified under Extended Operating Conditions (EOCs), which involved images contaminated with noise and different target configurations. The works [
19,
20,
21,
23,
24,
25,
26,
31,
32,
33,
34,
35] that most resembled this one are those where the implemented algorithms aimed at the model-based classification of targets in the Moving and Stationary Target Acquisition and Recognition (MSTAR) dataset [
50].
The recently released SAMPLE dataset [
38], which is presented in
Section 2.1, is a set of SAR images containing synthetic and measured data with very high fidelity. This dataset has great potential to become the main benchmark for SAR ATR classification algorithms, replacing or improving the MSTAR dataset, which has already been extensively explored. Therefore, there is an enormous demand for works that address the SAMPLE dataset [
51]. So far, few works [
38,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48] have been carried out that focus on the SAMPLE dataset for classifying measured data based exclusively on synthetic data, and they all use a feature-based approach with machine-learning algorithms like CNN or DenseNet.
There a two main contributions from this work:
A simple but efficient model-based algorithm for target classification using a modified Goodness of Fit test in its decision rule that significantly reduces the dimensionality of the data because it works with a small number of scattering centers; and
The SAMPLE dataset was used to evaluate the proposed algorithm, the performance of which was assessed under an EOC, which considered only synthetic data for training and only measured data for testing. Various combinations of hypothesis generation and verification were evaluated.
In the remainder of this article,
Section 2 details the SAMPLE dataset and the proposed SAR model-based target classification algorithm.
Section 3 presents all the experiments and their results using the SAMPLE dataset.
Section 4 provides insightful discussion comparing the proposed algorithm to other recent solutions addressing the SAMPLE dataset.
Section 5 concludes the article.
4. Discussion
The first experiment reported in this article compares different Goodness of Fit tests. As seen in
Section 3.1.1, the LRT stood out regarding PXS and MSE variation. This result refers to the small samples due to a large number of categories (scattering centers). For small samples, the chi-square approximation in many cases did not fit well with the actual distribution [
58]. In building the model, the expected value of each category had an average value of
, where
N was the number of scattering centers in the model. In an example with
, the average expected value was
, much less than 5, which is the minimum expected value required by PXS.
In
Section 3.1.2, better accuracy in the results was observed when the hypotheses were generated based on the scattering centers of the test image (SC-based approach) compared to those obtained when the entire test image was used (SLC-based approach). In the SLC-based approach, when using the observed value of all scattering centers, the assumed risk was that the observed scattering centers would present random values as they tend to be very close to the noise level. As their amplitudes were very low, the randomness caused a substantial error to the categorical partial score. The SC-based approach addressed this problem by assigning zero to the observed value of scattering centers not found within the
N ones extracted from the test image and then fixing a partial error of
for the category.
The goodness-of-fit test with weighting function was also efficient based on the intersection of the scattering center sets present in both the model and the test image. A greater coincidence of scattering centers was expected for the true class than the false classes. Therefore, assigning the number of elements at the intersection of the two sets of scattering centers as an inversely proportional weight further reduced the true hypothesis test score.
The simplification of the Point Spread Function (PSF) used by the CLEAN algorithm did not significantly improve accuracy. However, since it did not compromise the results, it is recommended for applications limited by processing resources and execution time.
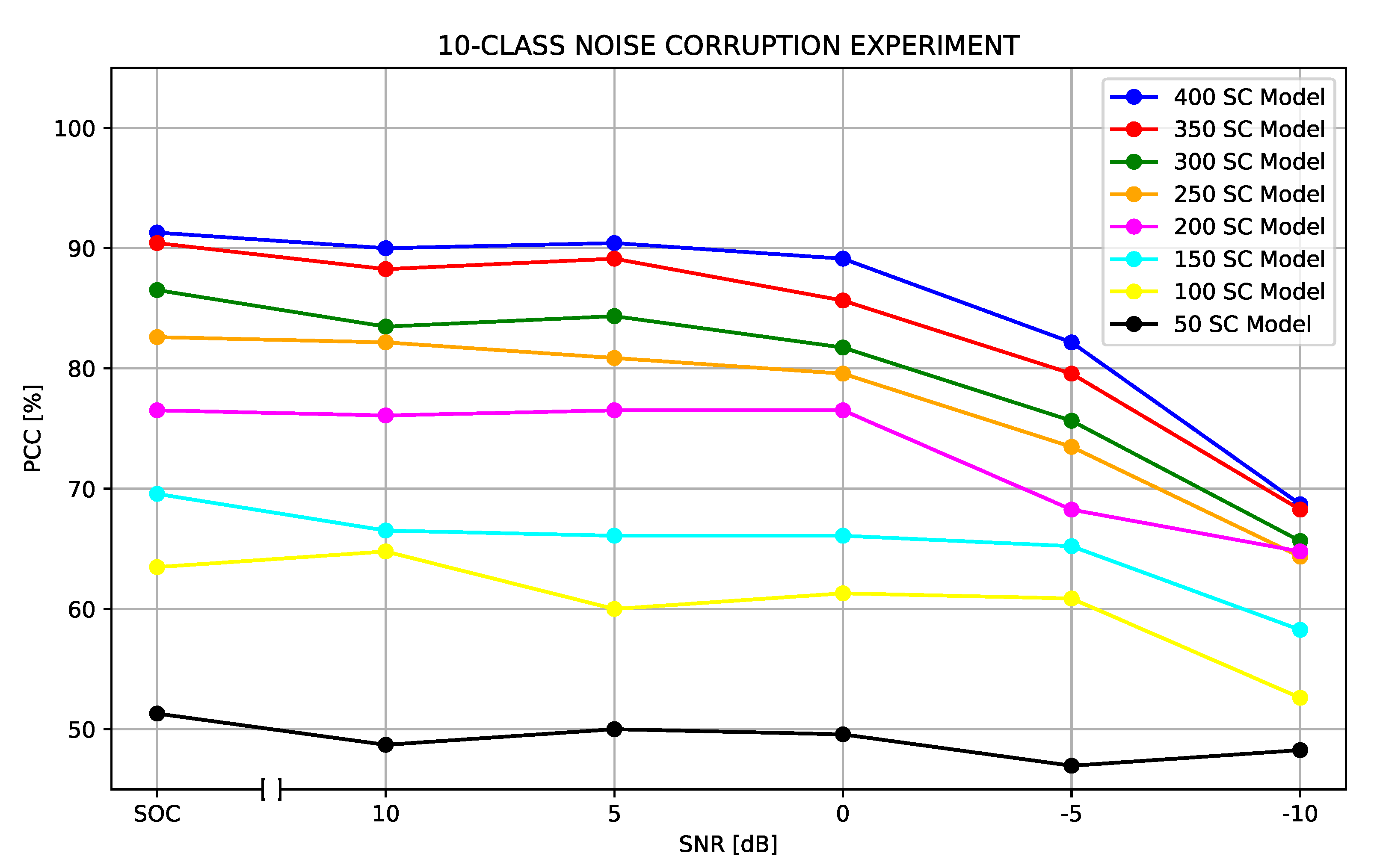
It was observed that the SCR-based approach achieved the best performance among all implementations, indicating that the exclusion of low-ranking scattering centers from the target was worthy. The number of scattering centers to be excluded was approximated experimentally, showing that the PCC started to drop using a larger number of scattering centers. This result showed that there was an adequate number of scattering centers to represent the target properly, and more than that may have jeopardized the performance.
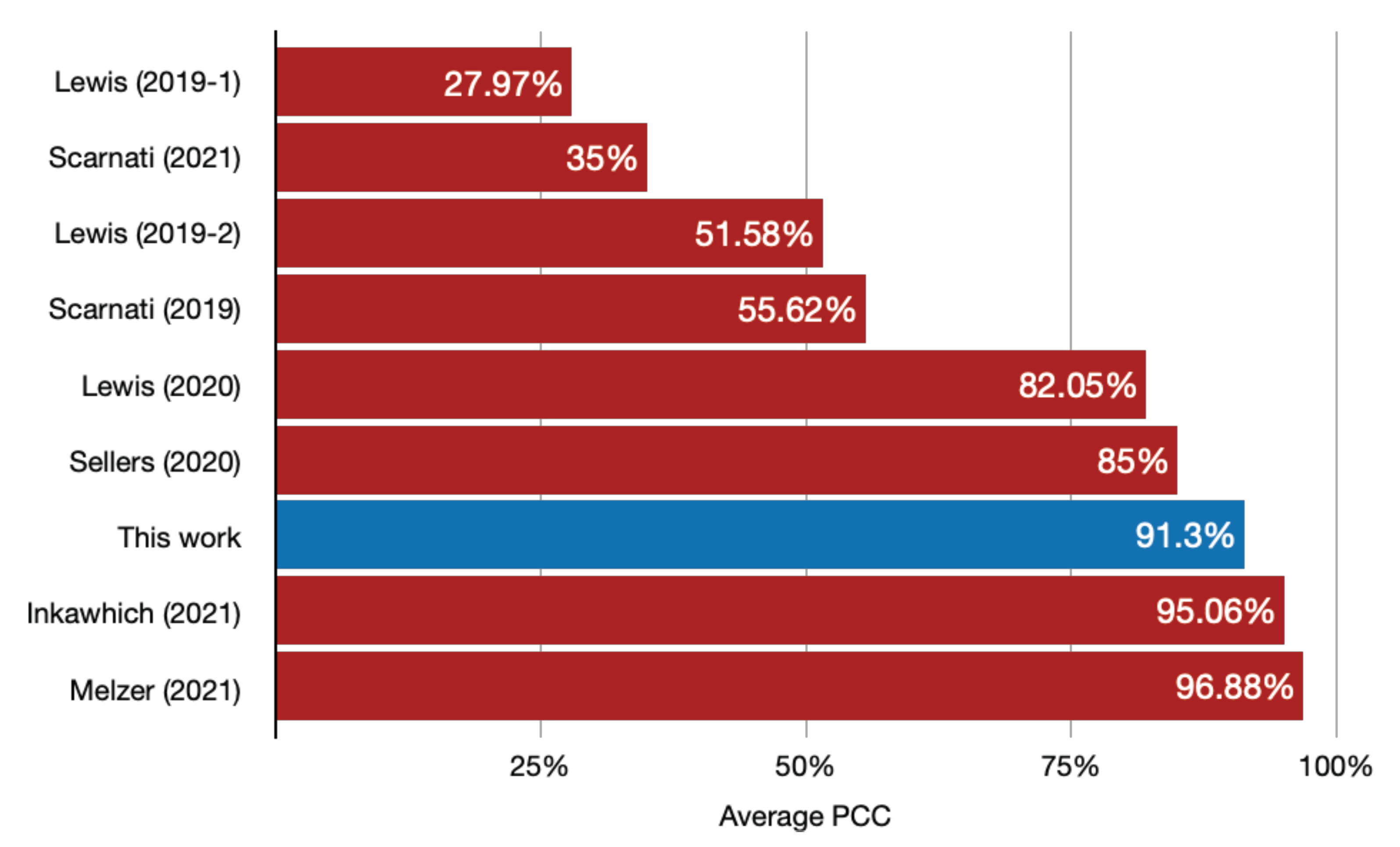
Lewis et al. [
38], the developers of the SAMPLE dataset, provided not only measured and synthetic data but also some results of potential experiments and suggested performance metrics so that researchers could compare experimental results appropriately. In one of those experiments, the 10 classes were used for training and testing, varying the proportion of measured and synthetic data in the training batch. Using an algorithm based on a Convolutional Neural Network (CNN) with four convolutional layers and four fully connected layers, the average PCC was
when only synthetic data were used in the training batch.
Consideration must be made regarding a self-imposed constraint that potentially affected the accuracy of the reference experiments. Perhaps to maintain certain compatibility with previous works focused on the MSTAR dataset, thereby enabling a comparison of results, they used the 17-degree depression angle images exclusively for testing. The same condition was not applied in the proposed algorithm since its success was directly connected to the similarity between synthetic and measured data. Therefore, there was no reason to generate hypotheses based on models with different aspect angles. Furthermore, as the SAMPLE dataset lacked images at some aspect angles, the entire set was used to extract the maximum amount of images with the same aspect angles.
Lewis et al., in their most recent work, achieved average accuracies of
[
39] and
[
43] by training a DenseNet with the assistance of a Generative Adversarial Network (GAN). Scarnati et al. reached an accuracy of
[
41] also by using DenseNet and no more than
[
45] when using Complex-Valued Neural Networks (CVNN). To preprocess images and augment data with adversarial training, Inkawhich et al. used Deep Neural Networks (DNN) to achieve an average PCC of
[
44]. Seller et al. [
42] developed an algorithm based on CNN capable of achieving an accuracy of
when synthetic data correspond to
of the data used in training. However, when using
of synthetic data in training, the PCC dropped below
. Jennison et al. [
47] achieved an accuracy of
although their synthetic data were transformed based on measured data, which in some ways can be considered a leak between test and training data. Finally, the best result obtained so far can be considered to be the one achieved by Melzer et al. [
48]. They tested 53 different neural networks achieving an average PCC of
with a CNN VGG HAS.
As can be seen in
Figure 13e and
Table 5, for the 10 classes the best SOC classification accuracy reached by our proposed algorithm was
. All classification results considering the SAMPLE dataset with purely synthetic data are summarized in
Figure 21.
Although the proposed algorithm has been outperformed by two of the referenced works, its applicability can be recommended based on processing-speed requirements. All other works used machine learning/deep learning to train their algorithms. Although this work does not contemplate a study of processing speed, it is a fact that DNN and CNN require a high processing time for training. The proposed algorithm replace the training process with a direct data inspection method for building the model. During online classification, the proposed algorithm performed a single set of operations for a reduced number of scattering centers (400). The other algorithms performed, for all 16,384 image pixels, a large number of operations in each layer of their networks.
However, some constraints can characterize disadvantages in applying the proposed algorithm. The main one is dependence on the discriminator stage. If the discriminator stage cannot perfectly center the target on the chip and estimate its pose within the tolerance limits, the classification results will not be successful. Another drawback is the dependence on database completeness. To achieve operationally satisfactory results, it is necessary to simulate a wide range of target poses.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






